关键词:一年生簇毛麦; α-醇溶蛋白; 原核表达; 品质分析; 蛋白质串联质谱鉴定 Cloning, Prokaryotic Expression andin vitro Functional Analysis of α-Gliadin Genes fromDasypyrum villosum YANG Fan1, CHEN Qi-Jiao1,2, GAO Xiang1,2,*, ZHAO Wan-Chun1,2,*, JIANG Qin-Qin1, WU Dan1, MENG Min1 1 College of Agronomy, Northwest A&F University, Yangling 712100, China
2 New Varieties Cultivation of Wheat Engineering Research Centre of Shaanxi Province, Yangling 712100, China
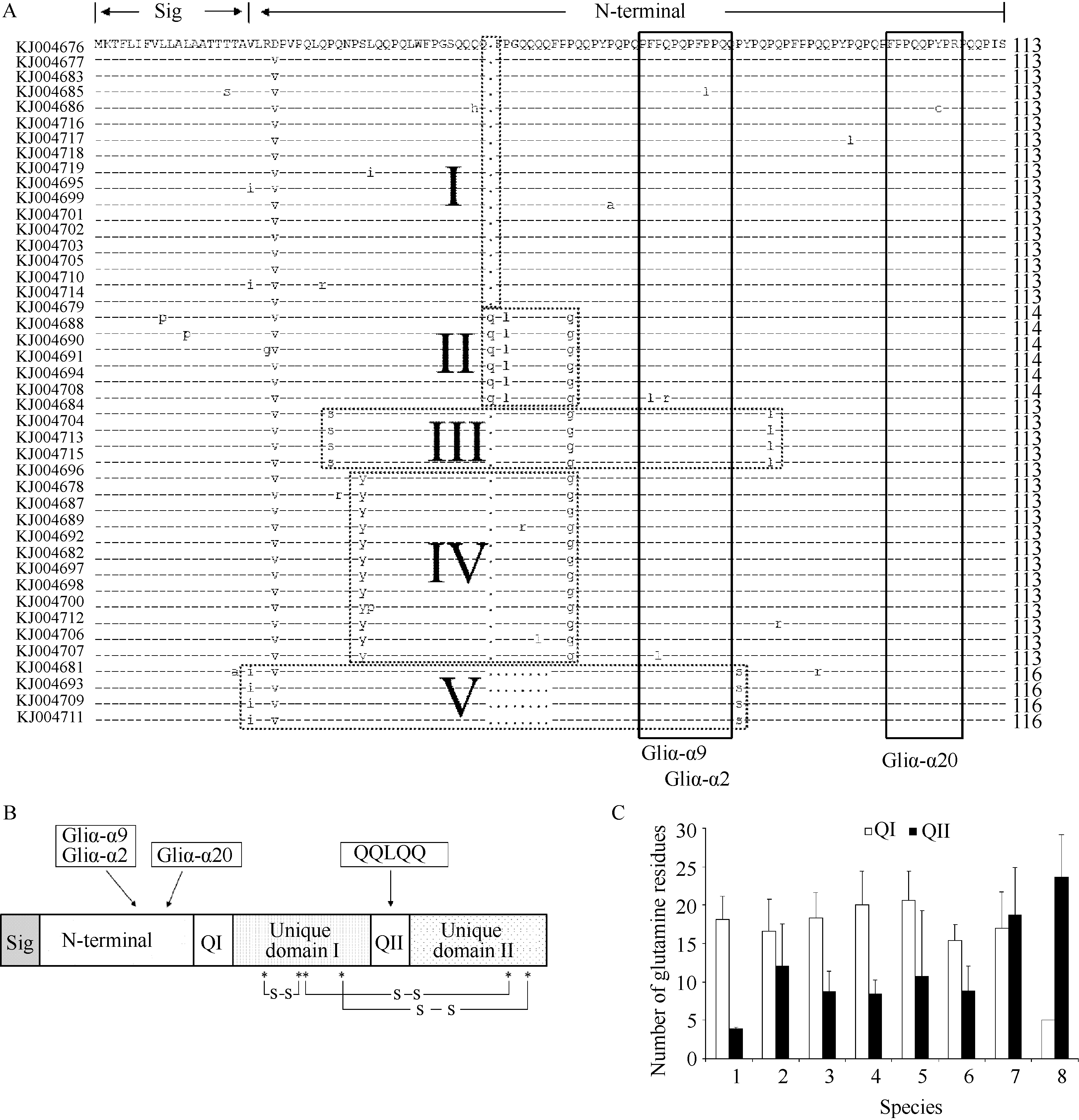
Fund: AbstractGliadin, which has a great effect on wheat quality, is one of main components in gluten. According to the full lengths of α-gliadin genes deposited in NCBI database, a conserved primer pair was designed to clone α-gliadin genes in fiveDasypyrum villosum lines. A total 52 sequences (816 to 873 bp in length) were isolated (GenBank accession numbers: KJ004676 to KJ004727) including eight pseudogenes and another sequence KJ004680 without stop codon. Deduced amino acid sequence anaylsis showed that KJ004677, KJ004686, and KJ004714 contain an extra Cys from the Tyr → Cys mutation, whereas, the extra Cys in KJ004696 resulted from the Ser → Cys mutation. Amino acid variation mainly occurred in N-terminal repetitive region and polyglutamine domain I. Variation in N-terminal repetitive region formed five groups in the 43 α-gliadins. To study the effects of an extra Cys on dough quality, we constructed the prokaryotic expression vectors for KJ004708 (with the typical six Cys residues) and KJ004714 (with an extra Cys) and obtained proteins of ~30 kD fromEscherichia coli BL21(DE3) under the induction of isopropyl-β-D-thiogalactoside (IPTG) with the predicted molecular weight. These expressed proteins were verified by matrix-assisted laser desorption-ionization time-of-flight MALDI-TOF/TOF tandem mass spectrometry analysis. The result showed that these α-gliadins were expressed correctly inE. coli. After purification, renaturation, and freeze-drying process, the functions of the expressed proteins were tested with 4 g Farinograph. Both KJ004708 and KJ004714 had positive effects on flour quality, especially KJ004714 with an extra Cys.
Keyword:Dasypyrum villosum; Alfa-gliadin; Prokaryotic expression; Functional analysis; MALDI-TOF/TOF tandem mass spectrometer Show Figures Show Figures
表2 不同物种α-醇溶蛋白中毒性多肽位点数量的比较 Table 2 Comparison of the quantity of T cell stimulatory epitopes in α-gliadins among different species
物种 Species
α-醇溶蛋白数 No. of α-gliadins
Gliα-α
Gliα-α2
Gliα-α9
Gliα-α20
一年生簇毛麦 Dasypyrum villosum
43
0
0
0
0
冰草属 Agropyr on
15
0
0
0
0
旱麦草属 Eremopyrum
8
0.875
0
0
0
黑麦属 Secale
26
0.615
0.615
0.615
0
偃麦草属 Thinopyrum
120
0.419
0.015
0.015
0.015
山羊草属 Aegilops
130
0.759
0.616
0.536
0.812
小麦属 Triticum
350
0.420
0.363
0.534
0.537
冰草属、偃麦草属、山羊草属和小麦属数据来自Chen et al.[ 29]; 旱麦草属和黑麦属来自NCBI数据库(http://www.ncbi.nlm.nih.gov/)。 Data of Agropyron, Thinopyrum, Aegilops, and Triticum genus originated from Chen et al.[ 29]; data of Er e mopyrumand Secale genus were collected from NCBI (http://www.ncbi.nlm.nih.gov/).
表2 不同物种α-醇溶蛋白中毒性多肽位点数量的比较 Table 2 Comparison of the quantity of T cell stimulatory epitopes in α-gliadins among different species
表3 原核表达的α-醇溶蛋白串联质谱鉴定 Table 3 Identification of prokaryotically expressed α-gliadins using MALDI-TOF/TOF tandem mass spectrometer
项目 Item
KJ004708匹配肽段 KJ004708 matched peptides (MPS)
KJ004714匹配肽段 KJ004714 matched peptides (MPS)
MPS-1
MPS-2
MPS-3
MPS-4
MPS-5
MPS-6
理论分子量 Theoretical MW (Da)
858.4792
1516.8595
2751.2615
858.4792
1502.8439
2737.2458
观测分子量 Observed MW (Da)
858.4792
1516.785
2751.0918
858.4754
1502.7788
2737.1099
误差 Difference (Da)
0
-0.0745
-0.1697
-0.0038
-0.0651
-0.1359
蛋白质得分 Protein score
198
229
蛋白得分置性度 C.I. %
100
100
等电点 Isoelectric point
8.28
8.23
与其他α-醇溶蛋白序列相似度 Similarity to other α-gliadins (%)
推导氨基酸序列 Deduced sequence
100
100
100
100
100
100
原核表达产物 Prokaryotic expression
100
100
100
100
100
100
Australopyrum retrofractum(ABW79851)
86
62
95
86
69
100
Dasypyrum ho r deaceum(ACY71755)
71
100
95
71
92
100
Dasypyrum vi l losum(ABY48872)
71
69
86
71
62
90
匹配肽段序列分别为SQVLQQR (MPS-1和MPS-4); DVLLQQHNIAPIR (MPS-2)和DVLLQQHNVAPIR (MPS-5); TYQELQQQCCQQ LWQI PEQSR (MPS-3)和SYQELQQQCCQQLWQIPEQSR (MPS-6)。下画线表示相同多肽片段的不相同氨基酸位点。 Matched peptide sequences are SQVLQQR (MPS-1 and MPS-4); DVLLQQHNIAPIR (MPS-2) and DVLLQQHNVAPIR (MPS-5); and TYQELQQQCCQQLWQIPEQSR (MPS-3) and SYQELQQQCCQQLWQIPEQSR (MPS-6). Amino acid site variations are underlined.
表3 原核表达的α-醇溶蛋白串联质谱鉴定 Table 3 Identification of prokaryotically expressed α-gliadins using MALDI-TOF/TOF tandem mass spectrometer
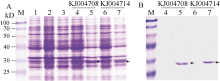
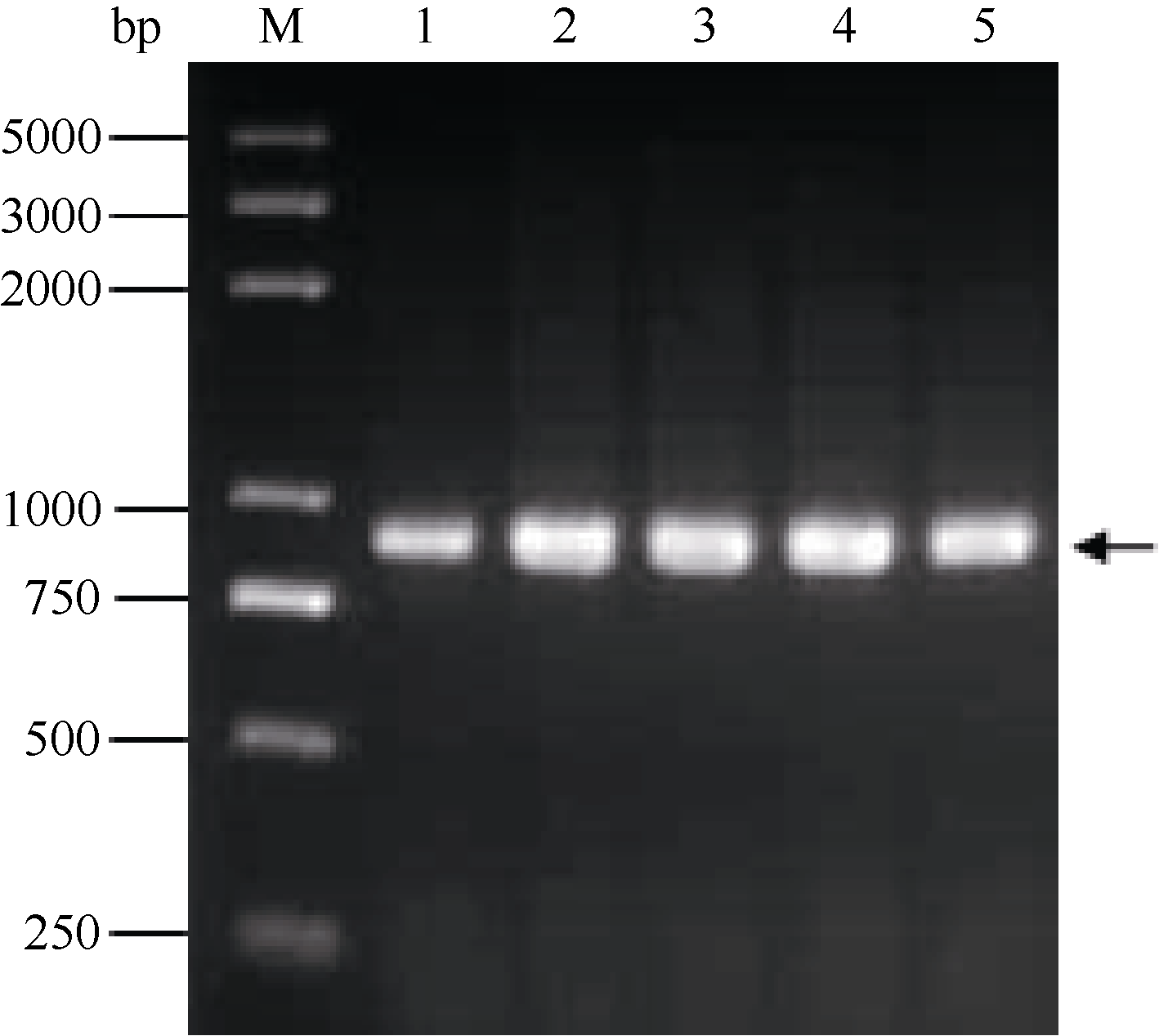
图4 蛋白表达和纯化的SDS-PAGE分析A: 诱导表达产物的SDS-PAGE分析; B: 纯化产物的SDS-PAGE分析。M: Blue Plus protein marker; 1: 未诱导的表达菌株(DE3); 2: 未诱导空载体; 3: 诱导空载体; 4和6: 未诱导的重组质粒; 5和7: 诱导后的重组质粒。箭头示目的蛋白。Fig. 4 SDS-PAGE analysis of protein expression and protein purificationA: analysis of expressed proteins by SDS-PAGE; B: analysis of purified proteins by SDS-PAGE. M: Blue Plus protein marker; 1: protein of BL21 (DE3) expression strain without induction; 2, protein of non-recombinant plasmid without induction; 3, protein of non-recombinant plasmid after induction; 4 and 6, protein of recombinant plasmid without induction; 5 and 7, protein of recombinant plasmid after induction. Target proteins are indicated by arrows.
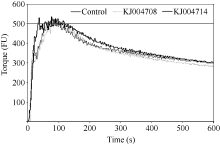
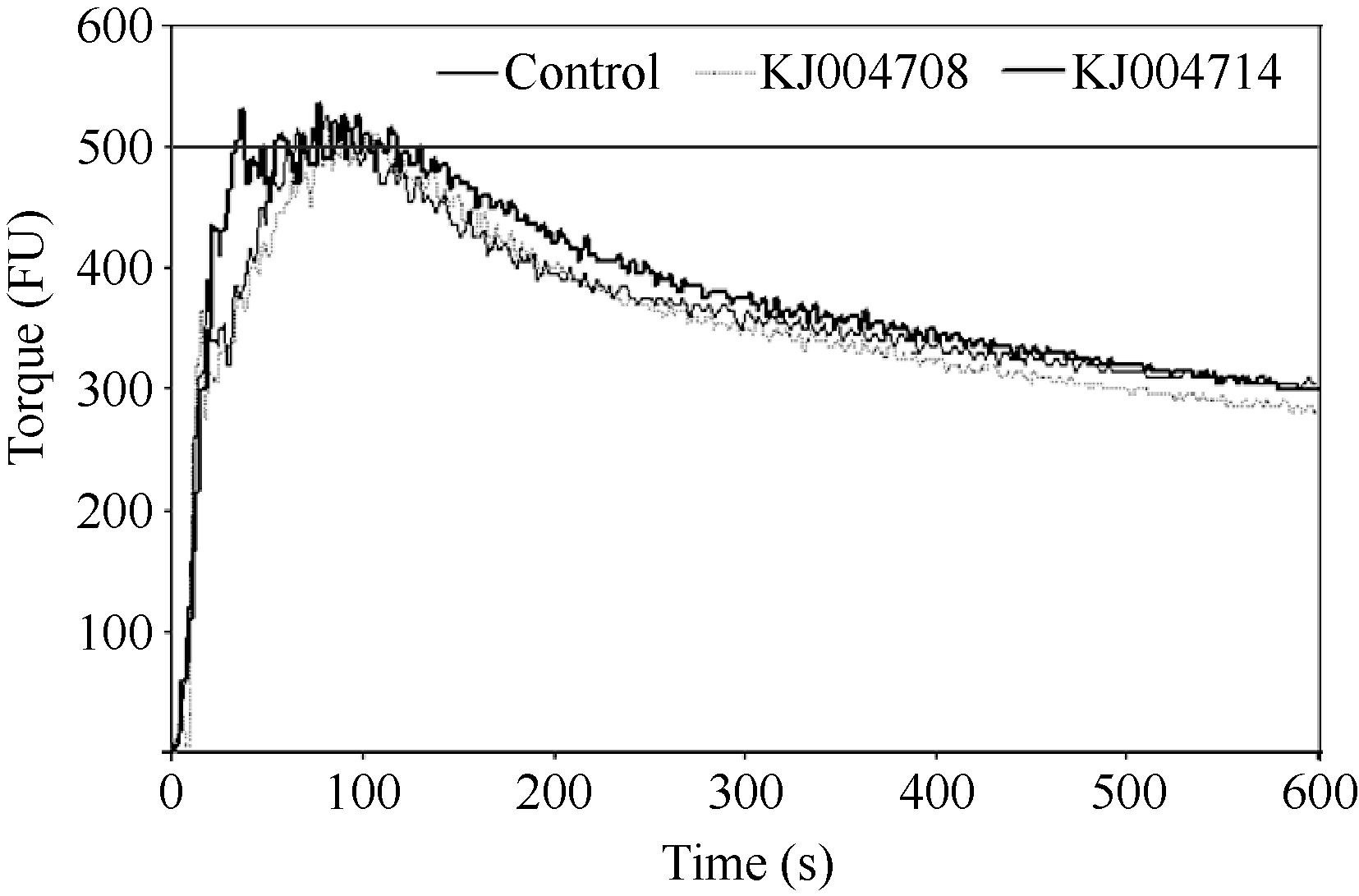
图5 纯化的α-醇溶蛋白亚基对粉质曲线的影响Fig. 5 Effects of purified α-gliadin subunits on the Farinograph parameters
表4 Table 4 表4(Table 4)
表4 添加KJ004708和KJ004714对小麦面团粉质特性的影响 Table 4 Effects of KJ004708 and KJ004714 on Farinograph parameters
添加物 Additive
断裂时间 BdT (min)
形成时间 DvT (min)
稳定时间 ST (min)
带宽 WC (FU)
弱化度 DS (FU)
公差指数 MTI (FU)
粉质质量指数 FQN (mm)
DTT, KIO3(control)
2.1 b
1.4 b
1.0 b
50 b
159.9 b
155 b
17.5 b
DTT, KIO3, KJ004708
2.2 ab
1.6 a
1.1 b
50 b
169.9 a
170 a
20.2 a
DTT, KIO3, KJ004714
2.6 a
1.6 a
1.7 a
55 a
154.9 c
150 c
21.5 a
表中数据为3次重复取平均值, 同列中不同字母表示差异显著( P < 0.05)。 Data are the means of three replicates. Values followed by different letters within columns are significantly different at P < 0.05. BdT: breakdown time; DvT: development time; ST: stability time; WC: width of curve; DS: softening of dough; MTI: mixing tolerance index; FQN: farinograph quality number.
表4 添加KJ004708和KJ004714对小麦面团粉质特性的影响 Table 4 Effects of KJ004708 and KJ004714 on Farinograph parameters
QualsetC O, ZhongG Y, DePace C, McGuireP E. Population biology and evaluation of genetic resources of Dasypyrum villosum. In: Damania A B ed. Biodiversity and wheat improvement. Chichester: John Wiley & Sons, 1993. pp227-233[本文引用:1]
[2]
DePace C, QualsetC O. Mating system and genetic differentiation in Dasypyrum villosum (Poaceae) in Italy. Plant Syst Evol, 1995, 197: 123-147[本文引用:1][JCR: 1.312]
[3]
FrederiksenS. Taxonomic studies in Dasypyrum (Poaceae). Nord J Bot, 1991, 11: 135-142[本文引用:1][JCR: 0.595]
[4]
NielsenJ. Host range of the smut species Ustilago nuda and Ustilago tritici in the tribe Triticeae. Can J Bot, 1978, 56: 901-915[本文引用:1][JCR: 1.397]
[5]
ChenX, ShiA N, ShangL M, LeathS, MurphyJ P. The resistance of H. villosa to powdery mildew isolates and its expression in wheat background. Acta Phytopathol Sin, 1997, 27: 17-22[本文引用:1][CJCR: 1.088]
[6]
MinelliS, CeccarelliM, MarianiM, DePace C, CioniniP G. Cytogenetics of Triticum · Dasypyrum hybrids and derived lines. Cytogenet Genome Res, 2005, 109: 385-392[本文引用:1][JCR: 1.839]
[7]
YildirimA, JonesS S, MurrayT D. Mapping a gene conferring resistance to Pseudocercosporella herpotrichoides on chromosome 4V of Dasypyrum villosum in a wheat background. Genome, 1998, 41: 1-6[本文引用:1][JCR: 1.668]
[8]
JanC C, DePace C, Mc Guire P E, QualsetC O. Hybrids and amphiploids of Triticum aestivum L. and T. turgidum L. with Dasypyrum villosum (L. ) Cand argy. Z P?anzenzücht, 1986, 96: 97-106[本文引用:1]
[9]
SmithJ G, KidwellK K, EvansM A, CookR J, SmileyR W. Evaluation of spring sereal grains and wild Triticum germplasm for resistance to Rhizoctonia solani AG-8. Crop Sci, 2003, 43: 701-709[本文引用:1][JCR: 1.513]
[10]
ZhongG Y, DvorákJ. Evidence for common genetic mechanisms controlling the tolerance of sudden salt stress in the tribe Triticeae. Plant Breed, 1995, 114: 297-302[本文引用:1][JCR: 1.175]
[11]
MonteboveL, DePace C, JanC C, Scarascia-MugnozzaG T, QualsetC O. Chromosomal location of isozyme and seed storage protein genes in Dasypyrum villosum (L. ) Cand argy. Theor Appl Genet, 1987, 73: 836-845[本文引用:1][JCR: 3.658]
[12]
ShewryP R, ParmarS, Pappin D J C. Characterization and genetic control of the prolamins of Haynaldia villosa: relationship to cultivated species of the Triticeae (rye, wheat and barley). Biochem Genet, 1987, 25: 309-325[本文引用:1][JCR: 0.938]
[13]
BlancoA, RestaP, SimeoneR, ParmarS, ShewryP R, SabelliP, Lafiand raD. Chromosomal location of seed storage protein genes in the genome of Dasypyrum villosum (L. ) Cand argy. Theor Appl Genet, 1991, 82: 358-362[本文引用:1][JCR: 3.658]
[14]
LiuC J, ChaoS, GaleM D. Wsp-1, a set of genes controlling water-soluble proteins in wheat and related species. Genet Res, 1989, 54: 173-181[本文引用:1][JCR: 2.0]
[15]
LiJ M, YangZ M, TianH Q, HuangF, GangP T. Somatic cell clone establishment and amphiploid synthesis in a Triticum aestivum · Haynaldia villosa intergeneric hybrid. Hereditas (Beijing), 1991, 13: 1-3[本文引用:1]
[16]
MohammadP, HossainM A, KhodarkerN A, ShiraishiM. Study for morphological characteristics of species alien to wheat in Bangladesh. Sarhad J Agric, 1997, 13: 541-550[本文引用:1]
[17]
OkochaP I. Peculiarities of nucleo-cytoplasmic interactions in allocytoplasmic forms of wheat. Global J Pure Appl Sci, 1999, 5: 431-435[本文引用:1]
[18]
DePace C, SnidaroD, CiaffiM, VittoriD, CiofoA, CenciA, TanzarellaO A, QualsetC O, Scarascia Mugnozza G T. Introgression of Dasypyrum villosum chromatin into common wheat improves grain protein quality. Euphytica, 2001, 117: 67-75[本文引用:1][JCR: 1.643]
[19]
谷淑波, 于振文, 王东, 张永丽. 小麦贮藏蛋白对加工品质的影响及对环境的反应. 山东农业大学学报(自然科学版), 2009, 40: 309-312GuS B, YuZ W, WangD, ZhangY L. Effects of wheat storage protein on processing quality and reacting to environment. J Shandong Agric Univ (Nat Sci Edn), 2009, 40: 309-312 (in Chinese)[本文引用:1]
[20]
PayneP I, HoltL M, JacksonE A, LawC N, DamaniaA B. Wheat storage proteins: their genetics and their potential for manipulation by plant breeding. Philos Trans R Soc Lond, 1984, 304: 359-379[本文引用:1]
[21]
ShewryP R, HalfordN G. Cereal seed storage proteins: structures, properties and role in grain utilization. J Exp Bot, 2002, 53: 947-958[本文引用:2][JCR: 5.242]
[22]
朱西平, 李鑫, 李雅轩, 晏月明. 普通小麦及近缘粗山羊草α-醇溶蛋白基因的克隆、定位与进化分析. 作物学报, 2010, 36: 580-589ZhuX P, LiX, LiY X, YanY M. Cloning, chromosomal location, and evolutionary analysis of α-gliadin genes from Aegilops tauschii and common wheat (Triticum aestivum L. ). Acta Agron Sin, 2010, 36: 580-589 (in Chinese with English abstract)[本文引用:2][CJCR: 1.667]
[23]
QiP F, WeiY M, YueY W, YanZ H, ZhengY L. Biochemical and molecular characterization of gliadins. Mol Biol, 2006, 140: 713-723[本文引用:1][JCR: 3.518]
[24]
MurrayH G, ThompsonW F. Rapid isolation of high molecular weight DNA. Nucl Acids Res, 1980, 8: 4321-4325[本文引用:1]
[25]
van Herpen T W, GoryunovaS V, van der Schoot J, MitrevaM, SalentijnE, VorstO, SchenkM F, van Veelen P A, KoningF, van Soest L J, VosmanB, BoschD, HamerR J, GilissenL J, SmuldersM J. Alpha-gliadin genes from the A, B, and D genomes of wheat contain different sets of celiac disease epitopes. BMC Genomics, 2006, 7: 1[本文引用:4][JCR: 4.397]
[26]
李光蓉, 任正隆, 刘成, 周建平, 杨足君. 多年生簇毛麦α-醇溶蛋白基因的分离与序列分析. 作物学报, 2008, 34: 1097-1103LiG R, RenZ L, LiuC, ZhouJ P, YangZ J. Isolation and sequence analysis of α-gliadin genes from Dasypyrum breviaristatum. Acta Agron Sin, 2008, 34: 1097-1103 (in Chinese with English abstract)[本文引用:4][CJCR: 1.667]
[27]
MolbergO, UhlenA K, JensenT, FlaeteN S, FleckensteinB, Arentz-HansenH, RakiM, LundinK E, SollidL M. Mapping of gluten T cell epitopes in the bread wheat ancestors: implications for celiac disease. Gastroenterology, 2005, 128: 393-401[本文引用:1][JCR: 12.821]
[28]
LiG R, LiuC, ZengZ X, JiaJ Q, ZhangT, ZhouJ P, RenZ L, YangZ J. Identification of α-gliadin genes in Dasypyrum in relation to evolution and breeding. Euphytica, 2009, 165: 155-163[本文引用:7][JCR: 1.643]
[29]
ChenG X, LvD W, LiW D, SubburajS, YuZ T, WangY J, LiX H, WangK, YeX G, MaW, YanY M. The α-gliadin genes from Brachypodium distachyon L. provide evidence for a significant gap in the current genome assembly. Funct Integr Genomics, 2014, 14: 149-160[本文引用:1][JCR: 3.292]
[30]
LiG R, ZhangT, BanY R, YangZ J. Molecular characterization and evolutionary analysis of α-gliadin genes from Eremopyrum bonaepartis (Triticeae). J Agric Sci, 2010, 2: 30-36[本文引用:1][JCR: 2.041]
[31]
张晓霞, 焦浈, 董振营, 李世明, 王燃, 凌宏清, 秦广雍, 王道文. 普通小麦品种小偃54中α/β-醇溶蛋白编码基因的克隆与序列分析. 作物学报, 2011, 37: 1497-1502ZhangX X, JiaoZ, DongZ Y, LiS M, WangR, LingH Q, QinG Y, WangD W. Cloning and sequence analysis of α/β-gliadin genes from common wheat variety Xiaoyan 54. Acta Agron Sin, 2011, 37: 1497-1502 (in Chinese with English abstract)[本文引用:3][CJCR: 1.667]
[32]
李玉阁, 邢冉冉, 李锁平. 栽培一粒小麦α-醇溶蛋白新基因的克隆与序列分析. 麦类作物学报, 2012, 32: 387-392LiY G, XingR R, LiS P. Cloning and sequence analysis of new α-gliadin genes from Triticum monococcum. J Triticeae Crops, 2012, 32: 387-392 (in Chinese with English abstract)[本文引用:1]
[33]
AndersonO D, LittsJ C, GreeneF C. The α-gliadin gene family: I. Characterization of ten new wheat α-gliadin genomic clones, evidence for limited sequence conservation of flanking DNA, and southern analysis of the gene family. Theor Appl Genet, 1997, 95: 50-58[本文引用:2][JCR: 3.658]
[34]
李敏, 高翔, 陈其皎, 董剑, 赵万春, 王明霞. 普通小麦中α-醇溶蛋白基因(GQ891685)的克隆、表达及品质效应鉴定. 中国农业科学, 2010, 43: 4765-4774LiM, GaoX, ChenQ J, DongJ, ZhaoW C, WangM X. Cloning, prokaryotic expression and in vitro functional analysis of α-gliadin gene from common wheat. Sci Agric Sin, 2010, 43: 4765-4774 (in Chinese with English abstract)[本文引用:5][CJCR: 1.889]
[35]
李光蓉, 郎涛, 刘成, 周建平, 任正隆, 杨足君. 小麦新品种“成电麦1号”α-醇溶蛋白基因的分离与序列分析. 中国农学通报, 2011, 27(1): 203-208LiG R, LangT, LiuC, ZhouJ P, RenZ L, YangZ J. Isolation and sequence analysis of α-gliadin genes from wheat cultivar Chengdianmai 1. Chin Agric Sci Bull, 2011, 27(1): 203-208 (in Chinese with English abstract)[本文引用:1]
[36]
AndersonO D, GreeneF C. The α-gliadin gene family: II. DNA and protein sequence variation, subfamily structure, and origins of pseudogenes. Theor Appl Genet, 1997, 95: 59-65[本文引用:1][JCR: 3.658]
[37]
刘千, 龙海, 魏育明, 颜泽洪, 郑有良. 小麦品种‘川农16’α-醇溶蛋白基因序列分析. 中国农业科学, 2008, 41: 2168-2173LiuQ, LongH, WeiY M, YanZ H, ZhengY L. Sequence analysis of α-gliadin genes from wheat variety Chuannong 16. SciAgric Sin, 2008, 41: 2168-2173 (in Chinese with English abstract)[本文引用:1]
[38]
XieZ, WangC, WangK, WangS, LiX, ZhangZ, MaW, YanY. Molecular characterization of the celiac disease epitope domains in α-gliadin genes in Aegilops tauschii and hexaploid wheats (Triticum aestivum L. ). Theor Appl Genet, 2010, 121: 1239-1251[本文引用:1][JCR: 3.658]
[39]
田纪春. 谷物品质测试理论与方法. 北京: 科学出版社, 2006. pp338-340TianJ C. Theory and Method of Test in Grain Quality. Beijing: Science Press, 2006. pp338-340(in Chinese)[本文引用:1]
[40]
姜薇莉, 孙辉, 凌家煜. 粉质质量指数(FQN)对于评价小麦粉品质的实用价值研究. 中国粮油学报, 2004, 19(2): 42-48JiangW L, SunH, LingJ Y. Applicability of FQN in evaluation of wheat flour quality. J Chin Cereals Oils Assoc, 2004, 19(2): 42-48 (in Chinese with English abstract)[本文引用:1]
 , 赵万春
, 赵万春




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}