为了解决上述问题,Larochelle等[1]于2008年提出了零样本学习这一概念,主要研究训练类与测试类互斥时的分类问题,即当测试类的样本数据没有在训练过程中出现时,利用有限有标签的训练样本对测试样本进行分类。尽管人们很难对于从未见过的事物准确分类,但是人类却可以根据以前学到过的知识通过其特征来描述该事物的类别,如从未见过“鸭嘴兽”,但是可以将其描述为“有嘴”“有尾巴”“有毛”“有蹼”等信息,这些信息即为样本的属性,而通过将样本的属性引入到分类过程中,便可以有效地解决零样本图像分类问题。
典型的零样本学习模型[2-4]的训练过程只包含已知类的样本和所有类的语义特征。由于已知类与未知类只在语义空间中存在联系,零样本学习通常采用视觉特征嵌入语义空间或语义特征嵌入视觉空间的方法[5-7]。近年来,由于生成对抗网络(Generative Adversarial Network,GAN)[8]的飞速发展,出现了一些利用生成对抗网络来解决零样本图像分类问题的方法[9-10]。这些方法的主要思想是通过生成未知类的图像特征使得零样本图像分类问题转化为经典的图像分类问题。
生成对抗网络由生成网络和判别网络2部分组成,这2个网络以互相对抗的方式进行训练。生成网络试图输入噪声产生虚假图像来欺骗判别网络,而判别网络则试图区分真实图像与虚假图像。通过2个网络间的互相对抗学习,使产生的图像更加真实。尽管生成对抗网络已经取得了较好的结果,但其仍然难以训练。而WGAN(Wasserstein GAN)[11]的提出解决了以往生成对抗网络训练困难的情况,其能使网络的训练过程更加稳定,同时还提供了可以指导训练进程的损失函数。另外,文献[12]中的条件生成对抗网络可以把类标签和其他信息引入生成过程中,以此来生成想要获得的结果。
本文采用生成对抗网络解决零样本图像分类问题,主要思路是:利用随机噪声和未知类的语义描述生成未知类图像的特征,再训练一个分类器对生成的图像特征进行分类。虽然通过上述方法间接解决了零样本图像分类问题,但是该方法却引入了一个新问题,即如何训练一个能够准确生成图像特征的生成对抗网络。在一般生成对抗网络生成图像特征的过程中,现有方法仅以语义信息来判别生成图像特征的真实性,而这无疑会产生一定的偏差。因此,本文改进了生成对抗网络中的判别网络,将语义信息转换为图像特征,从而使得判别更加准确,得到更好的分类结果。
本文主要贡献如下:①引入图像特征生成方法,通过一种间接的方式解决了零样本图像分类问题;②对生成对抗网络中的判别网络做出改进,提出了一种更为合理的方式来判断生成图像特征的真实性,从而提高了生成图像特征的质量,进一步提高分类准确率。
1 零样本图像分类 人类能够根据一个事物的语义描述来识别物体,受此启发,零样本学习旨在通过语义描述来学习一个具有良好泛化能力的模型,从而对未知类进行分类。如图 1所示,在训练样本中有“北极熊”“马”“狗”“熊猫”,而测试样本中的“斑点狗” “斑马”没有出现在训练过程中。虽然模型从未见过“斑点狗”“斑马”,但却可以对这2类的特征进行描述,随后便可以根据这些描述来区分不同的类别。
 |
| 图 1 零样本学习示例 Fig. 1 An example of zero-shot learning |
| 图选项 |
对于图像分类问题,通常训练的模型在测试时只能预测训练集中已有的类别。而在零样本图像分类中,测试集的类别与训练集的类别不存在交集。因此,需要寻找一种新的方法来解决零样本图像分类问题。文献[13]中给出了最初的解决方法,即类间属性迁移。在零样本图像分类问题中,虽然物体的类别不同,但是物体间存在相同的属性,可以挑选出每一个类别对应的属性并进行学习。在测试时,对未知类的属性进行预测,再将预测出的属性组合对应到类别,从而实现对未知类的分类。
虽然上述方法能够在一定程度上解决零样本图像分类问题,但其最终取得的分类效果却不理想。文献[9]给出了一种利用生成对抗网络来生成未知类图像特征的方式解决零样本图像分类问题,经过实验验证,其最终的分类结果要优于一般的零样本图像分类方法,其主要思路是:利用未知类的语义信息来生成未知类的图像特征,这一部分是通过一个生成网络来完成的;同时利用一个判别网络来对生成的图像特征进行判别,使最终获得的图像特征更加真实。
2 特征生成网络 零样本图像分类的主要难点在于无法区分未知类的类别,本文利用生成对抗网络来生成未知类的图像特征,从而间接地解决零样本图像分类问题,将其转换为一般的分类问题。本文对f-CLSWGAN[9]模型中的判别网络做出改进,以进一步提高分类准确率。
2.1 特征生成模型f-CLSWGAN f-CLSWGAN模型是一种生成对抗网络的变体,生成对抗网络由生成网络G与判别网络D组成,通过使2个网络相互博弈来进行学习。该模型的主要目的是:通过语义信息来生成图像特征,而不是直接生成未知类图像,以此来获得更准确的分类结果。
首先,f-CLSWGAN模型对生成网络与判别网络添加条件变量,使原始的生成对抗网络扩展为条件生成对抗网络;其次,由于生成对抗网络对于图像本身的生成效果仍不是很理想,因此,f-CLSWGAN模型将会生成未知类的图像特征而不是未知类的图像,从而使得条件生成对抗网络变体为f-GAN;再次,模型将WGAN引入f-GAN中,使模型的训练过程更加稳定,并且可以确保生成特征的多样性,使其进一步变体为f-WGAN;最后,模型将生成的图像特征送入一个分类器,得到一个分类结果,由此便形成了最终的f-CLSWGAN模型。具体的网络结构如图 2所示。图中:z为随机噪声,c(y)为语义信息,x为已知类的图像特征,

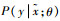
 |
| 图 2 f-CLWSGAN模型的网络结构 Fig. 2 Network structure of f-CLSWGAN model |
| 图选项 |
f-CLSWGAN模型的损失函数为
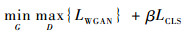 | (1) |
式中:β为分类器的一个超参数。
LWGAN和LCLS的损失计算如下:
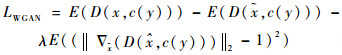 | (2) |
式中:等号右边第3项为惩罚项,λ为惩罚系数,

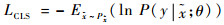 | (3) |
相较一般的零样本图像分类方法,该方法采用了一种新的思路,即利用语义信息生成未知类的图像特征,而不是去学习语义与图像之间的映射关系。使用该方法,可以将目标转变为如何更好地通过语义信息生成未知类的图像特征与如何对图像特征进行分类。同时,该模型采用了WGAN这种生成对抗网络作为基础,相较于其他类型的生成对抗网络,WGAN具有以下优点:①训练过程更加稳定;②能够通过损失函数来指导训练过程;③生成的样本具有多样性。由于f-CLSWGAN模型具有以上优势,从而使生成的图像特征更加真实,以得到更好的分类结果。
2.2 改进模型FD-fGAN 由于在f-CLSWGAN模型中的判别条件为原始的语义信息,而语义与图像特征之间存在着很大的差异。因此本文改进了f-CLSWGAN模型中判别网络的判别条件,将语义信息嵌入到视觉特征空间中,得到的新模型命名为FD-fGAN。具体网络模型结构与图 2类似,图 3显示了改进后FD-fGAN模型的网络结构。首先,将语义信息c(y)通过2个全连接层(FC),得到一个图像特征xc;然后,利用该图像特征对生成网络生成的图像特征进行判别。对于生成网络,则不对其进行修改。
 |
| 图 3 FD-fGAN模型的网络结构 Fig. 3 Network structure of FD-fGAN model |
| 图选项 |
通过本文方法,生成对抗网络中的损失函数LWGAN的计算由式(2)变为了式(4),即将判别网络中的语义信息c(y)替换为图像特征xc。
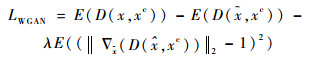 | (4) |
本文方法将未知类的语义信息嵌入到视觉特征空间中,以获得一个图像特征。通过该图像特征可以减小判别特征与生成特征间的差异,使判别的过程更加准确,从而提高判别网络的判别性能,这也就使得生成网络生成的图像特征更加真实。最终能够得到一个更好的分类结果。
由于希望网络的训练过程足够稳定,且能够在训练过程中随时观察到最终的分类准确率,本文采用了WGAN作为网络结构的基础模型,构建了FD-fGAN模型。
3 实验 3.1 实验数据集 本节实验采用了3种不同的经典数据集,分别为AWA[13]、CUB[14]及SUN[15]。AWA数据集是由Lampert等[13]在2009年构建的,由50个动物类别的37 322幅图像组成,每个图像都具有预先提取的特征表示,且每个类别都有85个不同的属性。CUB数据集由加州理工学院在2010年构建,由200个不同鸟类的11 788幅图像组成,每个类别都有312个不同的属性。SUN数据集是一个场景属性数据集,其是在细粒度的SUN分类数据集之上构建得到的,由717个场景的14 340幅图像组成,每个类别都有102个不同的属性。3个数据集的具体划分情况如表 1所示。将表 1中的已知类作为训练集,未知类作为测试集,已知类与未知类没有交集。
表 1 三个数据集的划分情况 Table 1 Division of three datasets
| 数据集 | 类别数 | 已知类别数 | 未知类别数 |
| AWA | 50 | 40 | 10 |
| CUB | 200 | 150 | 50 |
| SUN | 717 | 645 | 72 |
表选项
3.2 实验结果与分析 参考Xian等的工作[9],实验中的图像特征是利用ResNet-101提取的,并且在ImageNet数据集上进行了预训练。而对于语义描述,使用数据集中包含的默认属性。实验参数配置也与f-CLSWGAN模型相同。实验在AWA、CUB和SUN三个不同数据集上分别进行了70轮训练。图 4为不同数据集上的分类准确率趋势。可以看出,在AWA数据集上,只用了30轮左右分类准确率就达到了最高水平,随后开始缓慢下降;在CUB数据集上,训练20轮以后分类准确率便开始在一个范围内波动,并在43轮时达到最高;在SUN数据集上,训练25轮以后分类准确率基本保持不变。分类准确率能很快达到稳定的主要原因是采用了WGAN作为FD-fGAN模型的基础。
 |
| 图 4 不同数据集上的分类准确率 Fig. 4 Classification accuracy on different datasets |
| 图选项 |
表 2给出了不同方法在3个数据集上的对比结果。可以看出,本文所设计的FD-fGAN模型取得的结果要优于其他模型。其中,基于生成对抗网络的方法都要优于其他零样本图像分类方法,证明了将生成对抗网络引入零样本图像分类问题的合理性。
表 2 不同方法在3个数据集上的分类准确率比较 Table 2 Comparison of classification accuracy of different methods on three datasets
| 方法 | 分类准确率/% | ||
| AWA | CUB | SUN | |
| DAP[6] | 44.1 | 40.4 | 39.9 |
| CONSE[16] | 45.6 | 34.3 | 38.8 |
| SSE[17] | 60.1 | 43.9 | 51.5 |
| DeViSE[18] | 54.2 | 52.0 | 56.5 |
| SJE[19] | 65.6 | 53.9 | 53.7 |
| ESZSL[7] | 58.2 | 53.9 | 54.5 |
| ALE[20] | 59.9 | 54.9 | 58.1 |
| SYNC[2] | 54.0 | 55.6 | 56.3 |
| f-CLSWGAN[9] | 68.2 | 57.3 | 60.8 |
| FD-fGAN | 68.6 | 57.7 | 61.3 |
表选项
原始f-CLSWGAN模型直接利用语义信息进行判别,而在语义信息与图像特征之间存在着巨大的差异。本文FD-fGAN模型将这一语义信息通过2个全连接层嵌入到视觉特征空间,以减小语义信息与图像特征之间的巨大差异,从而使得分类准确率有所提升。本文所设计的FD-fGAN模型在AWA数据集上取得了68.6%的分类准确率,比f-CLSWGAN模型提高了0.4%;在CUB和SUN数据集上分别取得了57.7%与61.3%的分类准确率,比f-CLSWGAN模型提高了0.4%和0.5%。经过实验证明,本文通过改进判别网络设计出的FD-fGAN模型能够取得更高的分类准确率,表明利用图像特征作为判别条件是可行的。
4 结论 1) 本文提出了一种利用图像特征进行判别的生成对抗网络FD-fGAN,以此来解决零样本图像分类问题。经过实验验证,本文方法在AWA、CUB、SUN三个不同的数据集上分别提高了0.4%、0.4%与0.5%。
2) 本文所提出的利用图像特征作为判别条件来进行判别的方法,减少了语义信息与图像特征之间存在的巨大差异,加强了判别网络的判别能力。
本文的工作主要是针对生成对抗网络进行的,未来将研究如何使得由语义信息生成的图像特征更加准确,并对生成对抗网络作进一步改进。
参考文献
| [1] | LAROCHELLE H, ERHAN D, BENGIO Y.Zero-data learning of new tasks[C]//Proceedings of the Association for the Advancement of Artificial Intelligence. Palo Alto: AAAI Press, 2008: 646-651. http://www.cs.toronto.edu/~larocheh/publications/aaai2008_zero-data.pdf |
| [2] | CHANGPINYO S, CHAO W, GONG B, et al.Synthesized classifiers for zero-shot learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 5327-5336. https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Changpinyo_Synthesized_Classifiers_for_CVPR_2016_paper.pdf |
| [3] | KODIROV E, XIANG T, GONG S.Semantic auto-encoder for zero-shot learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 4447-4456. http://openaccess.thecvf.com/content_cvpr_2017/papers/Kodirov_Semantic_Autoencoder_for_CVPR_2017_paper.pdf |
| [4] | XIAN Y, SCHIELE B, AKATA Z.Zero-shot learning-the good, the bad and the ugly[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 3077-3086. https://arxiv.org/pdf/1703.04394.pdf |
| [5] | DING Z, SHAO M, FU Y.Low-rank embedded ensemble semantic dictionary for zero-shot learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 6005-6013. http://openaccess.thecvf.com/content_cvpr_2017/papers/Ding_Low-Rank_Embedded_Ensemble_CVPR_2017_paper.pdf |
| [6] | LAMPERT C H, NICKISCH H, HARMELING S. Attribute-based classification for zero-shot visual object categorization[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(3): 453-465. DOI:10.1109/TPAMI.2013.140 |
| [7] | ROMERA-PAREDES B, TORR P.An embarrassingly simple approach to zero-shot learning[C]//Proceedings of the International Conference on Machine Learning.Madison: Omnipress, 2015: 2152-2161. http://proceedings.mlr.press/v37/romera-paredes15.pdf |
| [8] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al.Generative adversarial nets[C]//Proceedings of the Neural Information Processing Systems.Cambridge: MIT Press, 2014: 2672-2680. https://arxiv.org/pdf/1406.2661v1.pdf |
| [9] | XIAN Y, LORENZ T, SCHIELE B, et al.Feature generating networks for zero-shot learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 5542-5551. https://arxiv.org/pdf/1712.00981.pdf |
| [10] | ZHU Y, ELHOSEINY M, LIU B, et al.A generative adversarial approach for zero-shot learning from noisy texts[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 1004-1013. http://openaccess.thecvf.com/content_cvpr_2018/papers/Zhu_A_Generative_Adversarial_CVPR_2018_paper.pdf |
| [11] | ARJOVSKY M, CHINTALA S, BOTTOU L.Wasserstein generative adversarial networks[C]//Proceedings of the International Conference on Machine Learning.Madison: Omnipress, 2017: 214-223. |
| [12] | MIRZA M, OSINDERO S.Conditional generative adversarial nets[EB/OL].(2014-11-06)[2019-07-01].https://arxiv.org/abs/1411.1784. |
| [13] | LAMPERT C H, NICKISCH H, HARMELING S.Learning to detect unseen object classes by between-class attribute transfer[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2009: 951-958. https://blog.csdn.net/u011070272/article/details/73250102 |
| [14] | WAH C, BRANSON S, WELINDER P, et al. The Caltech-UCSD Birds-200-2011 dataset:CNS-TR-2011-001[J]. Pasadena:California Institute of Technology, 2011. |
| [15] | PATTERSON G, HAYS J.SUN attribute database: Discovering, annotating, and recognizing scene attributes[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2012: 2751-2758. |
| [16] | NOROUZI M, MIKOLOV T, BENGIO S.Zero-shot learning by convex combination of semantic embeddings[C]//Proceedings of the International Conference on Learning Representations.Brookline: Microtome Publishing, 2014: 10-19. https://arxiv.org/abs/1312.5650 |
| [17] | ZHANG Z, SALIGRAMA V.Zero-shot learning via semantic similarity embedding[C]//Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2015: 4166-4174. https://arxiv.org/pdf/1509.04767.pdf |
| [18] | FROME A, CORRADO G S, SHLENS J, et al.DeViSE: A deep visual semantic embedding model[C]//Proceedings of the Neural Information Processing Systems.Cambridge: MIT Press, 2013: 2121-2129. http://www.cs.toronto.edu/~ranzato/publications/frome_nips2013.pdf |
| [19] | AKATA Z, REED S, WALTER D, et al.Evaluation of output embeddings for fine-grained image classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2015: 2927-2936. https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Akata_Evaluation_of_Output_2015_CVPR_paper.pdf |
| [20] | AKATA Z, PERRONNIN F, HARCHAOUI Z, et al. Label-embedding for image classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(7): 1425-1438. DOI:10.1109/TPAMI.2015.2487986 |
