舌图像分析系统[1]通常分为以下步骤:①采集带有舌体区域的人体面部图像; ②对面部图像进行分割,获取舌体区域; ③提取舌体的颜色、纹理、裂纹、红刺等特征,对舌色和舌苔进行定量分析和定性描述; ④将分割后的舌图像、提取的特征和评价结果保存在患者数据库中,协助医生进行后续诊断。在上述步骤中,舌体区域的分割是一个关键步骤。在采集到的面部图像中有许多干扰物,包括背景、面部器官,有时还包括颜色标准色卡等,因此对舌体区域分割的准确度将直接影响到最终舌诊的分析结果。
传统的舌图像分割算法可分为以下几类:基于阈值的方法[2-3]、基于边缘检测的方法[4-6]、基于图论的方法[7-9]和基于主动轮廓模型[10-11]。这些方法在一定条件下可以得到较好的分割效果。但是,它们有以下缺点:①自动化程度较低,往往需要一些人工操作,如边界框或标定轮廓点[4, 7];②分割精度较差,并且舌体边缘存在较多齿痕。由于颜色相似,算法无法准确区分舌头和嘴唇[12]。
近年来, 深度卷积神经网络(DCNN)在计算机视觉方面取得良好的表现, 包括图像分类[13-14]、目标检测[15-17]和语义分割[18-21]。通过端到端的方式,DCNN比手工选取特征得到了更好的结果。尽管如此,利用DCNN进行舌部分割的算法还很少。最新的算法[22-23]使用DCNN进行舌部分割,优于一些传统的分割算法。然而,它们还需要一些额外的预处理,如亮度辨别和图像增强,这使得整个过程复杂。
本文提出了一种基于DCNN和全连接条件随机场(CRF)的舌图像分割算法,主要工作如下:①提出了一种基于DCNN的舌图像分割网络;②使用孔卷积算法在不增加网络参数的条件下扩大了特征图谱的尺寸;③使用孔卷积空间金字塔池化(ASPP)模块提取舌图像的多尺度特征;④将DCNN与全连接CRF相结合,细化分割边缘。
1 舌图像分割算法 本节提出了一种舌图像分割算法,算法的网络结构如图 1所示。该算法由3部分组成:①使用孔卷积的DCNN;②ASPP模块;③全连接的CRF。首先,将舌图像输入到DCNN进行特征提取,在网络层中使用孔卷积算法扩大感受野。然后,利用ASPP模块通过结合多个不同大小的感受野来提取多尺度信息。最后,利用全连接CRF对网络输出图像进行处理,对分割边缘进行细化。
 |
| 图 1 舌图像分割算法网络结构 Fig. 1 Network structure of tongue image segmentation algorithm |
| 图选项 |
1.1 孔卷积 在计算机视觉领域,DCNN通常会使用较多的卷积层和池化层,如在分类任务中,将卷积层和最大池化层在连续层上面重复组合使用,可以提取物体高维特征,分类效果表现良好。然而,这种重复使用卷积和池化的操作在分割任务中存在很严重的问题。在对图像中的舌体区域进行分割时,舌体的边界信息和语义信息是至关重要的。经过反复的卷积和池化操作后,网络的特征图谱会逐渐缩小,损失了较多的边界信息,不利于舌体边缘的精确分割。
为了减少边界信息的丢失,应避免在卷积和池化操作中使特征图谱缩减过小。如图 1所示,算法的网络结构共有5个最大池化层,它们在网络中分别为第3、6、10、14、18层。将网络中的第4池化层和第5池化层的步长参数设置为1,而不是前3个池化层中的2,这样可以使特征图谱不会过度减小,保持为一个较大尺寸。对于用于图像分类任务的DCNN[13],最终的特征图(全连接层或全局池化层之前)比输入图像尺寸小32倍。使用上述操作,特征图谱只会减少为原尺寸的8倍。
上述方法可以增大网络的特征图谱,获得更好的边界信息,但同时会导致网络中较深层的感受野尺寸减小,不利于语义信息的获取。在语义分割任务中,边界信息和语义信息都是至关重要的,语义信息的损失同样会影响分割的准确率。所以,如果能在增大网络特征图谱的同时保证感受野尺寸不会缩小,分割结果会较为精确。感受野的公式如式(1)所示,相邻特征的距离如式(2)所示,其与步长s成正比。当步长固定时,扩大感受野的唯一方法是增加卷积核尺寸的大小。然而增大卷积核的尺寸会增加参数的数量,导致网络效率大幅降低。
 | (1) |
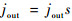 | (2) |
式中:rin为前一层的感受野尺寸;rout为当前层感受野尺寸;k为核大小;jin为前一层相邻特征的距离;jout为当前层相邻特征的距离。
为了解决此问题,本文使用了孔卷积算法,其最初是为了高效计算非抽取小波变换而开发的[24],可以在保持参数个数不变的情况下,增大卷积核的大小。算法在一维运算中如式(3)所示:
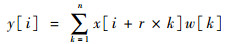 | (3) |
式中:x[i]为输入信号;y[i]为输出信号;w[k]为卷积核;参数r控制卷积的间隔。
在进行标准卷积时,即参数r=1,从图 2(a)可以看到,在较高一层的神经元中,相邻神经元的感受野具有较高的重合性,虽然能够包含低一层神经元中所有的信息,但是由于对像素进行了连续的遍历卷积,图像中的许多特征会被重复地进行提取,从而产生大量的冗余信息。如果将像素点间断地进行卷积运算(间隔由参数r控制),如图 2(b)所示,感受野的交集将会被最小化,保证了在不损失图像信息的前提下,减少冗余信息。合理的组合不同层中孔卷积的参数r,可以使卷积层既能提取到图像的全部特征,又能在不增加参数的情况下扩大感受野,提高语义信息的提取能力。在图 1中,网络中的孔卷积层被标记为每个通道的第一层,且参数r=2。通过改变池化层的步长,以及使用孔卷积的方法,网络提取边缘信息和语义信息的能力有所提升,这有利于提高舌图像分割的准确率。
 |
| 图 2 一维孔卷积示意图 Fig. 2 Schematic diagram of 1D atrous convolution |
| 图选项 |
使用孔卷积还可以显式地控制在DCNN中计算特征响应的密度。用输出比率来表示输入图像空间分辨率与最终输出分辨率的比值, 对于用于图像分类任务的DCNN[13],最终的特征响应(在全连接层或全局池化层之前)比输入图像尺寸小32倍,因此输出比率为32。如果想将DCNN中计算的特征响应的空间密度提高一倍(即输出比率为16),则将最后一个缩小特征图谱的卷积层或池化层的步长设置为1,以避免信号抽取。所有后续的卷积层都替换为r=2的孔卷积层即可。通过调整参数r,可以在任意分辨率下计算最终的DCNN响应。
1.2 孔卷积空间金字塔池化模块 在DCNN中通常使用固定大小的卷积核进行卷积运算,如3×3或5×5。通过重复的卷积运算,网络可以提取图像中所包含的深层特征。然而,具有固定尺寸的卷积核只能提取单一尺寸的特征,不能对图像在多个尺度上进行特征提取。
孔卷积能够控制感受野的大小,通过设置不同的卷积参数r,感受野的大小也会发生变化。单独使用一个孔卷积层,网络可以在这个指定尺度下提取特征。同时使用多个具有不同感受野的孔卷积层,网络即可以对物体提取多尺度特征。孔卷积ASPP模块并行地排列4种不同参数的孔卷积层,通过多种感受野提取多尺度特征。每个通道提取到的特征通过2个卷积层进一步处理(卷积核为1×1)。将4个通道提取到的特征通过一个卷积核大小为1、深度为4的卷积层进行融合,结果作为最终的特征。ASPP模块如图 3所示。
 |
| 图 3 ASPP模块 Fig. 3 ASPP module |
| 图选项 |
除此之外,由于拍摄设备、拍摄距离和患者年龄的不同,图像中舌体区域尺寸的大小可能会存在差异。因此,需要分割算法能够准确地分割不同大小的舌体。为了解决此问题,一般的分割算法通常是使用包含不同尺寸物体的数据集来训练网络,确保模型对不同大小物体分割的鲁棒性。然而,由于舌图像数据获取困难,舌图像的数量有限,没有足够的各种尺度的带标签的图像来对网络进行训练。ASPP模块由于使用了不同大小的感受野,可以对单尺寸舌图像在多个尺度上进行特征提取,在一定程度上解决了样本不同尺寸数据量不足的问题。
1.3 全连接条件随机场 定位精度和分类性能之间的权衡是DCNN固有的争论,具有多个卷积层和最大池化层的深层网络模型在分类任务中被证明是成功的,但是顶层节点的不变性和较小的特征图谱的网络只能产生平滑的响应。DCNN的不变性对语义分割有一定的限制,因为不变性意味着无论如何平移图像,最终的分类都是相同的。在语义分割任务中,物体的位置是有用的信息,DCNN的不变性导致网络中位置信息的丢失。1.1节中提到了DCNN可以可靠地预测图像中物体的存在和粗略位置,但不能精确地定位物体轮廓。因为重复地进行下采样操作,导致大量的边缘信息丢失,使得物体边缘处的像素点较为平滑。但语义分割任务需要清晰的边缘信息。除此之外,卷积运算是局部连接的,其只能提取一个像素周围矩形区域的信息,重复卷积运算虽然能使矩形面积逐渐变大,但即使到最后一个卷积层,也无法提取整个图像中一个像素与其他所有像素之间的相关性。为了解决这些问题,提高分割的准确率,将DCNN与全连接CRF相结合[25],通过计算任意2个像素之间的相似性来判断它们是否属于同一个类。通过这种方式利用整幅图像的信息,而不是在DCNN中只提取局部信息。全连接CRF可以突出物体的边缘,弥补了DCNN带来的边界平滑问题。
传统的CRF通常被用来平滑噪声[7],通过将相邻的节点耦合在一起,使得空间上邻近的像素获得相同的标签。这些短程CRF的主要功能是清除基于手工特征构建的弱分类器的虚假预测。
然而,DCNN不同于这些较弱的分类器。DCNN获得的边缘是十分平滑的,在这种情况下,使用短程CRF是不适合的[25],因为目标是得到清晰的物体边缘,而不是进一步平滑。为了解决短程CRF的局限性,用全连接CRF代替。将DCNN模型与全连接CRF相结合,用来精确地分割边界。模型能量函数如下:
 | (4) |
式中:xi代表像素i的标签;一元势为θi(xi)=-lg P(xi),P(xi)代表由DCNN预测出的像素i为舌体或者背景的概率;二元势[25]为以下表达:
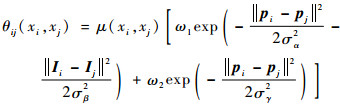 | (5) |
其中:若xi≠xj,则μ(xi, xj)=1,否则为0,这意味着只惩罚具有不同标签的节点。公式的后半部分为2个在不同特征空间中的高斯核。第1个核同时依赖于像素位置(2个不同的像素点坐标向量分别表示为pi和pj)和RGB颜色(2个不同像素点的颜色向量分别表示为Ii和Ij),第2个核只依赖于像素位置。超参数ω1、ω2控制高斯核的权重,σα、σβ和σγ控制高斯核的尺度。
式(5)的作用是判别相似的像素点是否属于同一类。如果像素点属于同一类,则能量函数值相对较小。反之,如果像素点不属于同一类,则能量函数相对较大。在舌图像分割中,唇部区域往往被错误地划分为舌形区域,影响了后续的分析。利用该能量函数,使与唇部连接的舌体分割更加精确。舌体部分像素的RGB值相似,舌体与唇部像素的RGB值存在差异。当对相似区域的像素点判别为不同类时,会产生较大的能量函数值。当存在差异的区域判别为同一类时,也会产生较大的值。通过多次迭代,使能量函数的值最小化来获得最终结果。通过这种方式,利用整个图像的信息来细化舌体边缘,提高分割的准确性。
2 实验结果分析 为了评估本文提出的舌图像分割算法的性能,进行了一系列的实验和分析。首先,比较了在网络上使用不同大小卷积核和参数r的孔卷积,对网络性能产生的影响。然后,比较了使用不同参数r的ASPP模块对网络性能产生的影响。最后,将本文算法与传统的舌图像分割算法及常用的DCNN算法进行了比较,验证了本文算法的有效性。
2.1 数据集
2.1.1 PASCAL VOC 2012 PASCAL VOC 2012是一个语义分割数据集,共分为21个类别,其中包括20个前景物体和1个背景。原始数据集分别包含用于训练(1 464幅)、验证(1 449幅)和测试(1 456幅)的像素级标记图像。数据集通过提供的方法进行扩充[26],得到10 582幅训练图像。数据集每个部分的数量如表 1所示。
表 1 三个数据集的图片数量 Table 1 Number of images on three datasets
| 数据集 | 类型 | 图片数量 |
| PASCAL VOC 2012 | 训练 | 10 582 |
| 验证 | 1 449 | |
| 测试 | 1 456 | |
| Tongue dataset 1 | 训练 | 1 440 |
| 测试 | 250 | |
| Tongue dataset 2 | 训练 | 160 |
| 测试 | 40 |
表选项
2.1.2 舌图像数据集 Tongue dataset 1采用佳能EOS 1100D相机拍摄,图像分辨率为4 272×2 848。数据集中共有1 690幅图像,其中包含训练集(1 440幅)和测试集(250幅)。
Tongue dataset 2采用尼康E4500相机拍摄,灯光和背景条件与Tongue dataset 1不同,拍摄的场景也存在差异,图像分辨率为1 600×1 200。数据集中共有200幅图像,其中包含训练集(160幅)和测试集(40幅)。
数据集原始图像和人工标注的标签如图 4所示。所有受试者在参与研究前均已知情同意纳入研究。
 |
| 图 4 数据集原始图像和人工标注的标签 Fig. 4 Original images in dataset with corresponding artificial segmentation marks |
| 图选项 |
2.2 实验设置 为了训练舌图像分割模型,使用Caffe框架搭建网络。所有实验都是在一台配置为Intel Xeon E5-2623 v3 CPU @ 2.4G Hz, 64 GB RAM的电脑上进行的,GPU型号为NVIDIA GeForce GTX TITAN。
在实验中,mini-batch设置为20,初始学习率为0.001,每2 000次迭代将学习率乘以0.1,动量固定为0.9,对应的权值衰减为0.000 5。
2.3 评判标准 本文采用像素精度(PA)、平均像素精度(MPA)和平均交并比(MIOU)3个标准来评价模型对舌图像的分割精度。PA、MPA、MIOU的公式如下:
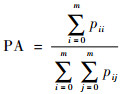 | (6) |
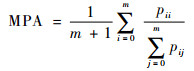 | (7) |
 | (8) |
式中:pii为将第i类正确地分割为第i类的像素点数量,pij为将第i类错误地分割为第j类的像素点数量,pji为将第j类错误地分割为第i类的像素点数量。
2.4 结果分析 先将网络在PASCAL VOC 2012数据集上进行预训练,再在舌图像数据集上对网络进行微调。在对DCNN进行微调后,使用交叉验证来优化CRF参数。初始化参数ω2=3,σγ=3,通过对验证集的小部分数据进行交叉验证(本文使用20幅图像)来寻找最佳参数ω1、σα和σβ。
采用由粗到精的搜索方案,参数的初始搜索区间为:ω1为[2 : 6],σα为[10 : 10 : 100],σβ为[10 : 10 : 100]。算法共迭代10次。
2.4.1 不同尺寸和参数的孔卷积 本节讨论使用不同尺寸和参数的孔卷积对网络性能的影响。为了便于实验结果的观察,在fc6中使用了一个分支,来代替在ASPP模块中使用的4个分支。如表 2所示,在孔卷积层中使用大小为7×7,参数r=2的卷积核。由于卷积核尺寸较大,网络的感受野较大,可以提取更多的特征,分割效果较好,该模型在CRF后的性能为93.29%。但是7×7的卷积核导致网络参数庞大,运行缓慢(训练时每秒1.57幅图像)。通过将核的尺寸减小到5×5(r=2),将模型速度提高到每秒2.47幅图像,将核大小减小到3×3(r=2),将模型速度提高到每秒4.92幅图像。由于减小了卷积核的大小,参数数量大幅减少,运行速度更快。然而感受野的减小导致网络性能下降,分割精度降低。当使用3×3的卷积核(r=2)时,CRF后的模型性能为83.47%。不同参数下的模型结果如图 5所示。
表 2 不同尺寸和参数的孔卷积对网络性能的影响 Table 2 Effect of atrous convolution with different size and parameters on network performance
| 核尺寸 | r | 参数数量/106 | 时间/s | MIOU/% |
| 7×7 | 2 | 134.3 | 1.57 | 93.29 |
| 5×5 | 2 | 94.6 | 2.47 | 89.16 |
| 3×3 | 2 | 20.5 | 4.92 | 83.47 |
| 3×3 | 4 | 20.5 | 4.92 | 86.13 |
| 3×3 | 6 | 20.5 | 4.92 | 90.06 |
| 3×3 | 8 | 20.5 | 4.92 | 93.27 |
表选项
 |
| 图 5 不同尺寸和参数的孔卷积MIOU结果 Fig. 5 MIOU of atrous convolution with different sizes and parameters |
| 图选项 |
为了在不增加参数的情况下提高模型的精度,在fc6层增大参数以扩大网络的感受野。当使用3×3卷积核,参数设置为r=8时,模型的性能可以与之前的结果(卷积核大小7×7,r=2)相媲美。使用这种方法,能够令网络在不增加参数的条件下,增大网络的感受野。
2.4.2 不同参数的孔卷积空间金字塔池化模块 本节讨论在ASPP模块中使用不同孔卷积参数r的效果。如图 3所示,ASPP模块在fc6-fc7-fc8中使用多个并行分支,最后融合生成结果。实验中卷积核的大小均为3×3,每个分支的参数r不同。表 3展示了几种参数的实验结果。表中:单分支是基准模型,即fc6为单分支,r=8。另外4个实验使用的是ASPP模块,有4个分支,参数不同。ASPP-2代表r=(2, 4, 6, 8),ASPP-4代表r=(4, 8, 12, 16),ASPP-6代表r=(6, 12, 18, 24),ASPP-8代表r=(8, 16, 24, 32)。实验结果如表 3所示,使用ASPP模块的性能优于单个分支。在使用ASPP模块进行的4个用于舌图像分割的实验中,ASPP-4(4, 8, 12, 16)的性能最好,CRF后分割的MIOU达到95.41%。从图 6中可以观察到不同参数下模型的分割结果。
表 3 不同参数的ASPP模块对网络性能的影响 Table 3 Effect of different parameters of ASPP module on network performance
| 方法 | 各通道参数 | MIOU/% |
| 单分支 | 8 | 93.27 |
| ASPP-2 | (2, 4, 6, 8) | 94.18 |
| ASPP-4 | (4, 8, 12, 16) | 95.41 |
| ASPP-6 | (6, 12, 18, 24) | 94.79 |
| ASPP-8 | (8, 16, 24, 32) | 94.57 |
表选项
 |
| 图 6 不同参数的ASPP模块MIOU结果 Fig. 6 MIOU of ASPP module with different parameters |
| 图选项 |
2.4.3 不同模块效果 为证明网络结构的有效性,本节比较使用不同模块对分割结果的影响。实验中使用了2个不同的舌图像数据集。使用Tongue dataset 1中的训练集对模型进行训练,并用测试集对模型结果进行测试,实验结果如表 4所示。结果表明,在网络中使用ASPP模块和CRF对分割结果有3%的提升。使用ASPP模块与全连接CRF的方法取得了较好的效果,在舌图像数据集中测试MIOU达到了95.41%。可视化分割结果示例如图 7所示。
表 4 不同模块对网络性能的影响 Table 4 Effect of different modules on network performance
| 单分支 | ASPP | CRF | MIOU/% | |
| Tongue dataset 1 | Tongue dataset 2 | |||
| √ | 92.48 | 90.87 | ||
| √ | √ | 93.27 | 91.21 | |
| √ | 94.36 | 92.54 | ||
| √ | √ | 95.41 | 93.75 | |
表选项
 |
| 图 7 舌图像的分割结果示例 Fig. 7 Examples of tongue image segmentation results |
| 图选项 |
在实际应用中,舌图像采集时的环境通常会有所不同,采用训练好的模型对新环境下的舌形图像进行分割,分割效果会下降。因此,当设备应用于新的环境时,可以使用少量的新数据对网络参数进行微调,提高模型的泛化能力。
基于在Tongue dataset 1中训练的模型,使用Tongue dataset 2中的40幅图像进行微调,并使用测试集进行测试。Tongue dataset 2的分割结果略低于Tongue dataset 1,但相差不多,最佳分割效果可达93.75%。
2.4.4 与现有算法对比 表 5为GrabCut[7]、Snake[4]、FCN-8s[18]、U-net[27]、SegNet[20]及本文算法在2个舌图像数据集上分割结果的对比。在GrabCut模型中,手动选择一个边界框,来标定舌体区域,然后迭代算法10次,得到最终的分割结果。在Snake模型中,手工将舌体边缘标定15个标记以此作为分割初始边界,通过算法计算得到最终的分割结果。
表 5 不同算法在舌图像数据集上的分割结果 Table 5 Segmentation results on tongue image dataset by different algorithms
| 算法 | Tongue dataset 1 | Tongue dataset 2 | |||||||
| PA/% | MPA/% | MIOU/% | 时间/s | PA/% | MPA/% | MIOU/% | 时间/s | ||
| GrabCut[7] | 96.22 | 95.47 | 83.89 | 7.25 | 96.63 | 95.38 | 86.81 | 6.87 | |
| Snake[4] | 97.15 | 96.39 | 90.43 | 6.33 | 98.50 | 96.71 | 93.54 | 6.57 | |
| FCN-8s[18] | 97.36 | 96.04 | 91.37 | 0.37 | 96.84 | 95.27 | 90.36 | 0.31 | |
| U-net[27] | 98.65 | 96.88 | 93.69 | 0.68 | 97.83 | 96.19 | 92.17 | 0.64 | |
| SegNet[20] | 99.71 | 98.09 | 94.81 | 0.48 | 98.02 | 96.51 | 92.63 | 0.42 | |
| 本文算法 | 99.85 | 98.29 | 95.41 | 0.83 | 98.97 | 97.60 | 93.75 | 0.75 | |
表选项
由于GrabCut[7]和Snake[4]算法的自动化程度较低,需要手工标记操作,分割时间分别为7.25 s和6.33 s,分割效率较低。本文算法不需要人工干预,对模型进行训练后,在2个不同的数据集上进行测试,运行时间分别为0.83 s和0.75 s,速度优于GrabCut和Snake算法。然而,由于在网络的末端使用全连接CRF,计算复杂度较高,因此速度低于FCN-8s、U-net和SegNet网络。
在精度方面,传统算法为了缩短计算时间,通常对图像进行降采样,降低图像的分辨率,再对图像进行分割。由于在降低图像分辨率时会丢失大量的图像信息,使用这种方法会导致分割后的舌体区域存在较为明显的棱角,舌体区域不完整,分割效果较差。本文算法对原始图像进行分割,并且网络的特征图谱尺寸较大,舌体分割后存在的齿痕较少,舌体区域更加完整。分割结果的示例如图 8所示。使用GrabCut和Snake算法得到的分割结果如图 8(b)和图 8(e)所示,舌体的边缘没有分割完整,并且有一些缺失的部分会影响舌体的纹理特征。图 8(c)和图 8(f)是本文算法的分割结果,与传统算法相比,其得到的舌体边缘更加精确和完整。
 |
| 图 8 舌体不完整的分割结果示例 Fig. 8 Examples of segmentation results of tongue defect |
| 图选项 |
此外,由于舌体和嘴唇区域存在交集,并且2种颜色较为相似,传统算法在这种情况下有时分割错误,将部分嘴唇区域判断为舌体区域。由于DCNN可以自动提取抽象特征,并利用全连接CRF对边缘进行细化,在这种情况下,本文算法可以更加准确地分割舌体区域,分割精度更高。如图 9所示,图 9(b)和图 9(e)分别为GrabCut和Snake算法处理后的分割结果。传统的分割算法有时将嘴唇误判为舌体,分割效果较差。在这种情况下,本文算法可以比传统算法更好地区分舌体和嘴唇,获得良好的分割结果。图 9(c)和图 9(f)是使用本文算法得到的分割结果。在分割精度方面,本文算法在PA、MPA、MIOU三个方面都优于其他分割算法。不同算法的分割结果示例如图 10所示。
 |
| 图 9 包含嘴唇部分的舌图像分割结果示例 Fig. 9 Examples of segmentation results of tongue image containing lips |
| 图选项 |
 |
| 图 10 不同算法的舌图像分割结果示例 Fig. 10 Examples of tongue image segmentation results by different algorithms |
| 图选项 |
3 结论 针对传统舌图像分割算法需要预处理、人工标定候选区及分割准确率低等问题,本文提出了将DCNN与全连接CRF相结合的舌图像分割算法。
1) 使用孔卷积算法,使得网络能够在较大的特征图谱尺寸上进行特征提取,保证了边缘信息的提取。通过改变孔卷积参数,使得在不增加网络参数的条件下增大了感受野,保证了语义信息的提取。
2) 使用ASPP模块,使网络能够在不同感受野下对图像提取多尺度特征。
3) 使用全连接CRF,通过计算整幅图像中像素点之间的相关性进行分割,细化分割边缘。
本文提出的舌图像分割网络能够自动提取图像的多尺度特征,对舌体区域进行分割。与传统算法相比,本文算法自动化程度较高,不需要手工标定操作。与其他分割网络相比,本文算法在精度方面有所提高。在接下来的研究中,将把本文算法与最新的DCNN相结合,以提高舌图像分割的效率。
致谢 感谢拍摄舌图像的志愿者,以及在制作舌图像数据集过程中对数据进行处理和拍照的同学。
参考文献
| [1] | SHEN L S, WANG A M, WEI B G, et al. Image analysis for tongue characterization[J]. Acta Electronica Sinica, 2001, 12(3): 317-323. |
| [2] | 张灵, 秦鉴. 基于灰度投影和阈值自动选取的舌像分割方法[J]. 中国组织工程研究与临床康复, 2010, 14(9): 1638-1641. ZHANG L, QIN J. Tongue-image segmentation based on gray projection and threshold-adaptive method[J]. Journal of Clinical Rehabilitative Tissue Engineering Research, 2010, 14(9): 1638-1641. DOI:10.3969/j.issn.1673-8225.2010.09.027 (in Chinese) |
| [3] | 李丹霞, 韦玉科. 基于自适应阈值的舌像分割方法[J]. 计算机技术与发展, 2011, 21(9): 63-65. LI D X, WEI Y K. Tongue image segmentation method based on adaptive thresholds[J]. Computer Technology & Development, 2011, 21(9): 63-65. DOI:10.3969/j.issn.1673-629X.2011.09.016 (in Chinese) |
| [4] | KASS M, WITKIN A, TERZOPOULOS D. Snakes:Active, contour models[J]. International Journal of Computer Vision, 1988, 1(4): 321-331. DOI:10.1007/BF00133570 |
| [5] | 傅之成, 李晓强, 李福凤. 基于径向边缘检测和Snake模型的舌像分割[J]. 中国图象图形学报, 2009, 14(4): 688-693. FU Z C, LI X Q, LI F F. Tongue image segmentation based on snake model and radial edge detection[J]. Journal of Image & Graphics, 2009, 14(4): 688-693. (in Chinese) |
| [6] | LI Q L, XUE Y Q, WANG J Y, et al. Automated tongue segmentation algorithm based on hyperspectral image[J]. Journal of Infrared & Millimeter Waves, 2007, 26(1): 77-80. |
| [7] | ROTHER C, KOLMOGOROV V, BLAKE A. GrabCut:Interactive foreground extraction using iterated graph cuts[J]. ACM Transactions on Graphics, 2004, 23(3): 309-314. DOI:10.1145/1015706.1015720 |
| [8] | 韦玉科, 范鹏, 曾贵. 改进的GrabCut方法在舌诊系统中的应用[J]. 传感器与微系统, 2014, 33(10): 157-160. WEI Y K, FAN P, ZENG G. Application of improved GrabCut method in tongue diagnosis system[J]. Transducer & Microsystem Technologies, 2014, 33(10): 157-160. (in Chinese) |
| [9] | 陈善超, 符红光, 王颖. 改进的一种图论分割方法在舌像分割中的应用[J]. 计算机工程与应用, 2012, 48(5): 201-203. CHEN S C, FU H G, WANG Y. Application of improved graph theory image segmentation algorithm in tongue image segmentation[J]. Computer Engineering & Applications, 2012, 48(5): 201-203. DOI:10.3778/j.issn.1002-8331.2012.05.058 (in Chinese) |
| [10] | GUO J Y, YANG Y K, WU Q W, et al.Adaptive active contour model based automatic tongue image segmentation[C]//International Congress on Image and Signal Processing, Biomedical Engineering and Informatics, 2017: 1386-1390. https://www.researchgate.net/publication/313807601_Adaptive_active_contour_model_based_automatic_tongue_image_segmentation |
| [11] | SHI M J, LI G Z, LI F F. C2G2FSnake:Automatic tongue image segmentation utilizing prior knowledge[J]. Science China:Information Sciences, 2013, 56(9): 1-14. |
| [12] | LIN B Q, XIE J W, LI C H.Deeptongue: Tongue segmentation via resnet[C]//IEEE International Conference on Acoustics, Speech and Signal Processing.Piscataway, NJ: IEEE Press, 2018: 1035-1039. |
| [13] | KRIZHEVSKY A, SUTSKEVER I, HINTON G.ImageNet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems, 2013: 1097-1105. https://www.researchgate.net/publication/267960550_ImageNet_Classification_with_Deep_Convolutional_Neural_Networks |
| [14] | SIMONYAN K, ZISSERMAN A.Very deep convolutional networks for large-scale image recognition[EB/OL].(2014-09-04)[2019-01-28].https://arxiv.org/abs/1409.1556. |
| [15] | GIRSHICK R, DONAHUE J, DARRELL T, et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2014: 580-587. |
| [16] | GIRSHICK R.Fast R-CNN[C]//IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2015: 15801732. |
| [17] | REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN:Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. DOI:10.1109/TPAMI.2016.2577031 |
| [18] | SHELHAMER E, JONATHAN L, TREVOR D. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651. DOI:10.1109/TPAMI.2016.2572683 |
| [19] | NOH H, HONG S, HAN B.Learning deconvolution network for semantic segmentation[C]//IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2015: 1520-1528. |
| [20] | BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet:A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495. DOI:10.1109/TPAMI.2016.2644615 |
| [21] | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab:Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. DOI:10.1109/TPAMI.2017.2699184 |
| [22] | LI J, XU B C, BAN X J.A tongue image segmentation method based on enhanced HSV convolutional neural network[C]//International Conference on Cooperative Design, Visualization and Engineering.Berlin: Springer, 2017: 252-260. https://link.springer.com/chapter/10.1007/978-3-319-66805-5_32 |
| [23] | QU P L, ZHANG H, ZHUO L, et al.Automatic tongue image segmentation for traditional Chinese medicine using deep neural network[C]//Intelligent Computing Theories and Application.Berlin: Springer, 2017: 247-259. https://link.springer.com/chapter/10.1007%2F978-3-319-63309-1_23 |
| [24] | HOSCHNEIDER M, KRONLAND-MARTINET R, MORLET J, et al.A real-time algorithm for signal analysis with the help of the wavelet transform[C]//Wavelets: Time-Frequency Methods Phase Space, 1989: 289-297. https://link.springer.com/chapter/10.1007%2F978-3-642-75988-8_28 |
| [25] | PHILIPP K, KOLTUN V. Efficient inference in fully connected CRFs with Gaussian edge potentials[J]. Advances in Neural Information Processing Systems, 2011, 24(1): 109-117. |
| [26] | HARIHARAN B, ARBELAEZ P, BOURDEV L, et al.Semantic contours from inverse detectors[C]//IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2011: 991-998. https://ieeexplore.ieee.org/document/6126343 |
| [27] | RONNEBERGER O, FISCHER P, BROX T.U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention.Berlin: Springer, 2015: 234-241. https://link.springer.com/chapter/10.1007/978-3-319-24574-4_28 |
