目前,使用单一的彩色图像或深度图像进行人体姿态估计均已取得了一定的成果[4-8]。相对来说,由于彩色图像更易获得,所以针对单一彩色图像的人体姿态估计的研究更为广泛[9-13],可供利用的公开数据集也更为充足,如用于2D人体姿态估计研究的LSP[14]和MPII[15],以及用于3D人体姿态估计的Human 3.6M[16]等。而对于深度图像,由于其记录的是深度相机到目标人体之间的距离信息,不包含颜色及纹理细节等信息,因此,基于深度图像的3D人体姿态估计方法,一方面不易因人体着装、肤色和光照等复杂外界环境的变化而受到影响,另一方面使用该图像在保护用户隐私方面也具有很好的优势。但由于深度相机对光照、背景等较为敏感,深度图像获取的条件较为严苛。现有的深度图像数据集一般是在实验室环境下拍摄获得的,其姿态变化有限。而关节点标签基本采用先相机标定后人工检错的方式获得[8]。由于人工检错仍存在随机性等问题,因而很少有公开的深度图像数据集可以提供充足且准确的3D关节点标签。而为获得较为准确的深度图像3D关节点标签,需要研究者准备训练样本及标签,使得研究成本增加,同时也限制了深度图像在3D姿态估计领域的研究进程。因此,对现有缺乏准确深度标签的深度图像数据集进行研究,提出可行的算法,实现对深度图像的3D人体姿态估计是值得探索与鼓励的。
为此,本文提出了一种端到端的多源图像弱监督学习方法。该方法利用多源图像融合训练的方法解决深度图像姿态单一引起的模型泛化能力不高的问题,同时使用弱监督学习技术来解决标签不足的问题,并对网络中的残差模块进行改进,提高姿态估计的准确率。
1 相关方法 在深度学习领域,基于图像的2D或3D人体姿态估计均已取得一定的成果。其中,对于单一深度图像来说,在2D人体姿态估计上,文献[3]采用MatchNet[17]计算全卷积网络(Fully Convolutional Networks, FCN)预测的关节区域和模板之间相似度的方法,并结合相邻关节之间的配置关系,来达到优化关节点位置的目的。文献[18]介绍了一种基于模型的递归匹配(MRM)人体姿态的新方法,先对深度图像进行预处理以获得个性化参数,再使用模板匹配和线性拟合来估计人体骨架信息。在3D人体姿态估计上,文献[8]采用长短期记忆网络架构(Long Short-Term Memory, LSTM),学习局部视点不变特征,并利用自顶向下的错误反馈机制,纠正姿态位置,从而获得良好的3D人体姿态估计,但该方法采用强监督学习的方式完成3D人体姿态估计,其训练样本及标签为研究者自行准备,研究成本较高,同时也存在训练样本关节点标注不准的问题。
对于彩色图像的研究,在2D人体姿态估计上,文献[11]提出卷积姿态机器的方法,利用多阶段联合训练的方式,充分学习图像中的特征信息,来提高网络的姿态回归结果。文献[12]则提出了沙漏网络结构,利用多尺度特征来识别姿态,从而提高估计姿态的准确性。而对于3D人体姿态估计的研究方法,文献[19]提出强监督学习技术训练3D回归模型的方法。文献[1, 13, 20-23]采用了2D人体姿态估计结果辅助3D回归模型训练的方法。其中,文献[1]证明了该方法相较于直接训练3D回归模型,姿态估计准确率更高,而文献[21]则介绍了一种分别学习2D回归模型和深度回归模型的网络框架;不同于文献[1, 20-23]分阶段分别训练3D回归模型的方法,文献[13]针对室外人体姿态数据库缺乏深度标签的问题,提出一种端到端联合训练2D模型和深度模型的网络结构,该方法充分利用了实验室环境下充足且准确的标签数据及室外环境下的复杂人体姿态信息,通过该弱监督学习技术,以端到端的方式,获得较好的室外图像3D人体姿态估计。最近,文献[24]提出一个Graph-CNN网络,在网络中使用SMPL模板网格来回归人体姿态。文献[25]提出了一种基于单目图像的3D人体姿态估计的全卷积网络,使用肢体方向作为一种新的3D表示方法。
从上述研究可以发现,研究者基本采用强监督学习技术来完成对图像的3D人体姿态估计,利用充足的3D关节点标注信息来辅助回归模型的训练。但当训练样本中缺乏标签时,上述强监督学习方法不再适用,而弱监督学习技术的优点便显露出来。基于弱监督学习的网络模型不要求训练样本提供充足的标签,即可完成对回归模型的训练,可有效解决本文深度图像缺乏深度标签的问题。因此,基于上述研究背景,受文献[13]的启发,本文提出了一个基于多源图像弱监督学习的3D人体姿态估计方法。该方法使用多源图像作为训练样本,利用彩色图像姿态多变且3D标签充足的特点,来弥补深度图像姿态单一和缺乏深度标签的问题;同时为提高姿态估计准确性,还对现有的残差模块进行改善设计,从而实现对深度图像的3D人体姿态估计。
2 多源图像弱监督学习方法 面对深度图像缺乏准确深度标签的问题,可利用实验室环境下获取充足的彩色图像及其准确的人体运动关节点深度信息,辅助深度图像学习到相应的人体关节点深度信息,以实现对深度图像的3D人体姿态估计。基于上述研究思想,本文提出了一个基于多源图像端到端弱监督的3D人体姿态估计框架,通过多源图像混合训练的方式,完成对缺乏标注的深度图像3D回归模型训练任务。
2.1 多源图像3D人体姿态估计框架 本文基于多源图像弱监督学习的整体架构如图 1所示。训练样本由多源图像构成,包含带2D标签的深度图像和彩色图像,以及带3D标签的彩色图像。网络结构分为2D回归子网络模块和深度回归子网络模块两部分。
 |
| 图 1 3D人体姿态估计整体框架 Fig. 1 Overall framework of 3D human pose estimation |
| 图选项 |
整个框架的具体训练流程如下:①将多源图像训练样本作为网络的输入;②利用所有带2D标签的训练样本训练2D回归子网络模块,得到2D回归模型;③带3D标签的彩色图像经过2D回归子网络模块输出热图特征,将其作为深度回归子网络模块的输入进行训练,得到深度回归模型;④将2个回归模型的结果进行连接,从而完成对3D回归模型的训练任务。
本文的网络结构分为2D回归子网络模块和深度回归子网络模块两部分,具体结构如图 2所示。其中,2D回归子网络模块由2个沙漏模块构成,通过重复使用自顶向下和自底向上的方式对2D关节点坐标位置进行推导,在每个沙漏模块后均使用了热图对关节点坐标进行预测,即在网络结构中引入了中继监督技术,可有效避免训练过程中,由于网络层数过深而导致的梯度消失问题,加快网络模型收敛速度;同时由于热图中包含了关节点之间的相互关系,因此,将热图预测结果作为下一个沙漏模块的输入特征继续训练,有助于提高整体网络结构的回归性能。而深度回归子网络模块则采用文献[13]网络设计,由残差模块、池化层及线性回归器构成,紧接在2D回归子网络模块的后面,使其可利用2D回归子网络模块中充分学习到的特征作为输入进行训练,同时由于2D回归子网络模块的输出特征中包含关节点热图结果,因而使得该模块也可充分利用热图中关节点相互关系,有助于在弱监督学习下获得更为准确的关节点深度值。
 |
| 图 2 基于弱监督学习网络结构框架 Fig. 2 Network structure framework based on weakly-supervised learning |
| 图选项 |
在网络测试阶段,将测试图像输入到本文网络中,2D回归模型输出各关节点的预测热图,即2D关节点坐标


为改善现有网络结构的关节点回归性能,本文对上述网络结构提出改进设计,使得本文方法可以在提高回归模型准确度的同时,降低网络的训练时间及存储空间。
2.2 残差模块设计 一个较好的回归网络结构能在较少的训练时间内获得较优的关节点回归精度。但模型的训练时间及回归准确度与卷积网络的构成有很强的关联性。若适当地加深网络深度及特征维度,虽可获得较好的回归精度,但网络参数也大幅增加,同时也会加大模型的存储空间及训练时间;而若简单的降低网络深度及特征维度,虽可降低训练时间,但模型性能则会随之下降。因此,本文针对上述问题,为提高网络回归模型的准确度,同时降低模型训练时间,对网络结构的残差模块进行了改善。
图 2为本文基于弱监督学习的3D人体姿态估计网络结构框架,其中每个矩形块(C1, …,C4, C1a, …,C4a, C1b, …,C4b)均表示的是2个残差模块,因而可以说本文网络结构基本是由残差模块构成的。而现有的残差模块(见图 3(a)),其输入和输出特征维度均为256,通过交叉使用1×1、3×3和1×1的卷积进行充分的特征提取,并通过Shortcut连接,将卷积之后的特征和原始输入特征进行融合,使得残差模块可在提取较高层次特征的同时,又保留了原有层次的信息,这一多尺度特征信息在精准人体关节点预测方面,提供了较好的帮助[12-13]。但较高的特征维度也引起了训练时间变长,因此本文降低了残差模块的输入维度,从256降为128,降低特征维度后,1×1卷积的特征重组效果则会大大降低,因而,本文将3×3的卷积替换了1×1卷积,使得网络可对输入特征进一步提取,从而弥补特征维度降低造成的性能损失,甚至提高网络的回归精度,本文改进的残差模块如图 3(b)所示。
 |
| 图 3 残差模块 Fig. 3 Residual module |
| 图选项 |
2.3 3D人体姿态估计
2.3.1 2D回归子网络模块 本文利用沙漏网络可提取多尺度特征的特点,采用沙漏网络作为2D回归子网络模块训练2D回归模型,用于预测人体各关节点的位置坐标,以实现对图像的2D人体姿态估计。由于深度图像是在实验室环境下获取的,姿态单一且有限,因此,为提高2D回归模型的泛化能力,本文提出同时使用深度图像和彩色图像的混合多源图像的方式来训练2D回归模型。即输入数据为带2D标签的多源图像,输出一系列J(J=16)的低分辨率的关节点热图。
由于深度图像记录的是目标距离相机的距离信息,不包含颜色及纹理信息,若直接将深度图像和彩色图像混合作为网络的输入,会对模型训练造成干扰。因此,需对图像做预处理。考虑到深度图像在视觉上也可看做是灰度图像,因此使用加权平均法将训练所需的彩色图像进行灰度处理,去除里面的颜色干扰信息,减少由于训练样本变化而引起的模型精度损失,提高模型的回归精度。
沙漏网络训练的输入为上述预处理后的所有带2D标签的混合多源图像,图像分辨率为256×256,输出为预测到的各关节点的热图,图像分辨率为64×64,其关节点坐标为热图中概率最高的点。2D估计效果及其对应热图结果如图 4所示,(a)、(c)为深度图像,(b)、(d)为预测的热图结果,从左到右,从上到下依次为:右脚踝、右膝盖、右胯、左胯、左膝盖、左脚踝、臀部、胸部、脖子、头、右手腕、右手肘、右肩膀、左肩膀、左手肘、左手腕,共16个关节点热图,在热图中概率最高,也就是亮度最高的点即为预测的该关节点坐标位置。
 |
| 图 4 ITOP数据集的2D人体姿态估计及其对应的热图结果 Fig. 4 Two-dimensional human pose estimation and corresponding heat-map results in ITOP dataset |
| 图选项 |
本文2D回归模型训练的loss函数使用L2距离[13],其公式如下:
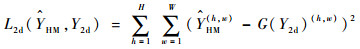 | (1) |
式中:

2.3.2 深度回归子网络模块 此阶段的主要目标是获得人体各关节点的深度值,而现有的针对无深度标签的数据,一般是采用模板匹配的方式预测关节点深度值。但这种方法未考虑图像中人体信息在深度值预测的重要性。
本文在一个网络结构中构建了2个回归子网络,并将深度回归子网络模块接在2D回归子网络模块的后面,将2D回归子网络模块中学习到的包含语义信息及多尺度信息的输出特征作为输入继续训练,可有效利用端到端网络训练的优势,充分利用权重共享功能从而获得更好的姿态估计结果。
深度回归网络训练收敛的loss函数使用L2距离,其公式如下:
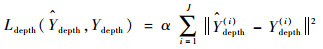 | (2) |
式中:
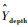
3 实验及结果分析 在本节中,为探讨本文弱监督学习姿态估计方法的预测性能,分别在深度图像数据集ITOP[8]和K2HGD[3]、彩色图像数据集MPII[15]和Human 3.6M[16]上进行训练及测试,并与相关姿态估计模型进行对比[13],用以评估本文方法的性能。
3.1 数据库
3.1.1 深度图像数据库 ITOP[8]是由20个人各做15个动作序列拍摄而成的,包含侧拍和顶拍2个视角的图像,其标签使用Kinect自带的SDK预测,虽然已通过人工检测的方式检错,但3D标签标定仍存在较大误差。因此本文仅使用经过前期标签检错筛查后的侧拍图像数据库进行实验,其中训练样本中仅使用了提供的2D关节点标签,约11 000张,而测试图像则使用了3D标签纠正后的图像数据,约2 979张,用于判断本文回归模型3D关节点的预测性能。
K2HGD[3]由30个人拍摄获得,共有10万张深度图像,提供相应的2D关节点标签。本文使用其中约6万张作为训练图像。
3.1.2 彩色图像数据库 MPII[15]是一个大型室外姿态估计数据库,提供相应的2D关节点标签。本文使用约25 000张图像进行训练。
Human 3.6M[16]由11个人各做17组动作,由4个角度上拍摄获得,共包含有360万张带3D标签的彩色图像,本文使用其中30万张图像作为训练图像,2 874张图像作为测试图像。
3.2 评价标准 为评估回归的关节点坐标准确性,本文使用PDJ (Percentage of Detected Joints) [3]作为评定标准,若关节预测坐标与标签之间的误差与归一化躯干长度的比值在一定阈值内,便可将其判定预测正确。使用阈值不同,检测到的关节点准确率也不同。
3.3 训练细节 本文训练平台为Torch7[22],并基于公开代码[12-13]构建本文2D回归子网络模块及深度回归子网络模块,如图 2所示。输入图像分辨率为256×256,2D回归子网络模块的输出为预测的人体各关节点的热图,分辨率为64×64,其热图概率值最高的点,作为此关节点的2D坐标预测结果,同时深度值由深度回归模型输出获得。
为达到快速训练的目的,本文网络结构的主体由2个沙漏模块串联而成。在训练时,采用的学习率为2.5×10-4,mini-batch的尺寸为6。为获得更好的3D回归模型准确率,本文分2个阶段训练3D回归网络,每个阶段均迭代了28万batch[13]。第1阶段,利用混合多源图像仅训练2D回归模型,第2阶段则以端到端的方式,训练3D回归模型。其中,2D回归模块的参数采用第1阶段的2D回归模型的权重进行初始化,在继续训练2D回归模型的同时,利用带深度标签的彩色图像更新深度回归子网络模块的权重参数,从而训练获得更好的3D回归模型。
由于存在训练图像中包含多个目标人体的现象,因此,本文在训练前,首先将样本进行预处理,对于每张训练及测试样本,均以人体臀部为中心进行裁剪,将目标人体放在图像的中间,其裁剪尺寸比在1.3~1.7之间,并归一化图像大小分辨率为256×256,同时对图像做加权平均的灰度处理,尽量保证训练图像的一致性。为提高模型的泛化能力,本文对数据进行了扩充处理,即对样本进行左右翻转及旋转处理,旋转角度在-6°~6°之间随机选择。本文训练及测试样本的标签统一为头、脖子、左右肩、左右肘、左右手腕、左右胯、左右膝盖、左右脚踝、胸部及臀部共16个关节点。
3.4 结果对比 由于使用的网络结构及训练数据不同,本文共获得的模型如表 1所示。其中,M-H36M、I-H36M、IK-H36M及IKM-H36M模型均是在本文改善后的网络结构上,通过不同的多源图像组合方式训练获得的,用于探讨本文所提使用多源图像混合训练的方式,对3D回归模型准确率的影响。其中,M-H36M训练样本同文献[13],即以MPII和Human 3.6M作为训练样本,而网络结构中的残差模块则使用了本文所提的改善设计(见图 3(b)),用于探讨本文改善后的网络结构在训练准确率及训练时间上的优越性能。
表 1 不同模型对应的训练图像 Table 1 Training images corresponding to different models
| 模型 | 训练数据 | ||||
| 深度图像数据库 | 彩色图像数据库 | ||||
| ITOP | K2HGD | MPII | Human 3.6M | ||
| 文献[13] | √ | √ | |||
| M-H36M(本文) | √ | √ | |||
| I-H36M(本文) | √ | √ | |||
| IK-H36M(本文) | √ | √ | √ | ||
| IKM-H36M(本文) | √ | √ | √ | √ | |
表选项
3.4.1 网络性能对比 为验证本文残差模块改进方案对关节点位置回归精度的影响,分别使用不同的残差模块网络结构在相同条件下进行实验,其对比结果如表 2所示。其中文献[13]的131~256表示残差模块(见图 3(a))对应的卷积依次为1×1、3×3和1×1,输入和输出通道数为256,表内其他方法数据物理含义同上。与文献[13]结果相比,本文模型(131~128)的准确率最低,降低约2.16%左右;而本文模型(333~256)的准确率最高,提升约0.66%左右,但其参数量和训练所需时间均成倍增加。这说明在保持残差模块卷积核大小不变的情况下,仅是简单地将输入输出通道数降低,其准确率会有所降低;而在保持输入输出特征维度不变的情况下,将卷积核大小放大,提高模型感受野,虽能提高模型的回归精度,但其参数量和训练所需时间也大幅增加。故本文选用333~128的残差模块改善方案(见图 3(b))以获得更优的回归性能。该方法可在减少模型参数的同时提高训练准确率,并且训练一个batch的时间与原始沙漏网络相比,下降了约28%。因此,实验表明,本文改善残差模块后的网络结构可在有效降低训练时间的同时提高模型准确率。
表 2 不同模型准确率、参数量及训练时间对比 Table 2 Comparison of accuracy rate, parameter quantity and training time among different models
| 模型 | 准确率/ % | 参数量/ 106 | 训练时间/ (s·batch-1) |
| 本文模型(131~128) | 90.10 | 31.00 | 0.16 |
| 文献[13] (131~256) | 92.26 | 116.60 | 0.29 |
| 本文模型(333~128) | 92.48 | 101.10 | 0.21 |
| 本文模型(333~256) | 92.92 | 390.00 | 0.41 |
表选项
本文还验证了沙漏模块的数量对回归模型准确率的影响,如表 3所示。其中,本文模型(4 stack)代表的是将2D回归子网络模块中的沙漏模块增加至4个,并基于本文改善后的残差模块结构训练获得的3D回归模型,与使用2个沙漏模块的本文模型(2 stack)相比,回归准确率提高了约0.35%左右,但每个batch的训练时间会增加约52%,即每个epoch训练周期会增加近一半的训练时间。实验表明,增加网络层数可进一步提升回归模型的准确率,但其训练时间和模型参数量会大幅增加,因此,为达到快速训练的目的,将使用本文模型(2 stack)对应的网络结构进行实验。
表 3 不同沙漏网络个数准确率、参数量及训练时间对比 Table 3 Comparison of accuracy rate, parameter quantity and training time with different numbers of hourglass network
| 模型 | 准确率/ % | 参数量/ 106 | 训练时间/ (s·batch-1) |
| 文献[13] (2 stack) | 92.26 | 116.60 | 0.29 |
| 本文模型(2 stack) | 92.48 | 101.10 | 0.21 |
| 本文模型(4 stack) | 92.83 | 185.30 | 0.32 |
表选项
3.4.2 深度图像3D人体姿态估计的模型对比 为验证不同训练数据库对回归模型性能的影响,本文基于PDJ评判标准,使用本文基于不同训练数据获得的3D回归模型,分别在ITOP深度图像数据集的测试图像上进行人体姿态估计(该测试图像标签已经过人工纠正)。将测试结果进行对比,探讨最优的基于弱监督学习的3D回归模型。
使用本文不同数据集训练得到的回归模型,在ITOP深度图像数据集测试图像手腕和膝盖3D关节点的预测结果对比,如图 5所示。可以看出,本文IKM-H36M模型的性能最优,IK-H36M性能次之,说明对深度图像的3D人体姿态估计任务中,随着深度图像训练样本的增多,其回归模型在大部分关节点的预测精度也会逐步提高。并且从IKM-H36M和IK-H36M曲线对比可以看出,在训练样本中引入带2D标签的彩色图像数据MPII,可进一步提高模型的预测准确率,验证了本文所提使用多源图像进行混合训练的方法,可有效提高模型的关节点回归精度。
 |
| 图 5 基于PDJ评价指标,不同训练模型在ITOP数据集手腕和膝盖3D关节点的准确率 Fig. 5 Three-dimensional articulation point accurary rate of wrist and knee using different training models based on PDJ evaluation criteria in ITOP database |
| 图选项 |
3.4.3 彩色图像3D人体姿态估计的模型对比 本节测试了本文方法针对彩色图像的3D人体姿态估计效果。使用本文不同数据集训练得到的回归模型,在Human 3.6M彩色图像数据集测试图像上脚踝和膝盖3D关节点的预测结果对比,如图 6所示。可以看出,各回归模型的检测性能相近,说明利用多源图像混合训练的回归模型,虽在训练样本中引入了深度图像,但并不会对彩色图像上的3D人体姿态估计精度造成太大的影响。图 6中画圈部分为各回归模型检测精度提升由快到慢转变的区域,其中在归一化阈值0.25处为检测精度变化转折点,意味着在该归一化阈值之后,回归模型的检测精度即将趋于平稳,此时各回归模型已能将测试样本中绝大部分关节点正确定位。因此,为更清楚地看到各关节点在不同模型的检测差别,比较了各关节点在归一化阈值0.25处的准确率,如表 4所示。可以看出,使用本文改善残差模块后的网络M-H36M,对彩色图像的预测性能最优,相比文献[13]的预测精度提升了约4%,而基于多源图像混合训练获得的模型,其平均检测精度由高到低,分别为IKM-H36M>IK-H36M>I-H36M,这也说明了使用多源图像进行训练回归模型,训练的数据越多,其检测精度越高,同时这3个模型的平均检测精度均高于文献[13]方法,这也又一次证明了本文改善后的网络结构有助于提高姿态估计准确性。而从M-H36M和IKM-36M平均检测结果比较来看,使用多源图像训练获得的IKM-H36M模型,平均检测性能略低于M-H36M模型,检测准确度下降约0.50%,这是因为在训练样本中,除彩色图像外,还引入了深度图像,即等于引入了干扰项,使得模型的回归性能略有下降。但从下降0.50%的结果上来看,使用多源图像训练的3D回归模型,虽然在关节点检测精度上具有轻微下降,但并不影响测试图像在各关节点的总体回归性能。
 |
| 图 6 基于PDJ评价指标,不同训练模型在Human 3.6M数据集脚踝和膝盖3D关节点的准确率 Fig. 6 Three-dimensional articulation point accurary rate of ankle and knee using different training models based on PDJ evaluation criteria in Human 3.6M database |
| 图选项 |
表 4 基于PDJ评价指标,不同训练模型在Human 3.6M测试图像上的3D人体姿态估计结果 Table 4 Three-dimensional pose estimation results of different regression models on Human 3.6M test images base on based on PDJ evaluation criteria
| 方法 | 准确率/% | |||||||
| 脚踝 | 膝盖 | 髋 | 手腕 | 手肘 | 肩膀 | 头 | 平均 | |
| 文献[13] | 65.00 | 82.90 | 89.27 | 77.91 | 86.46 | 94.73 | 94.42 | 84.38 |
| M-H36M(本文) | 75.07 | 90.33 | 94.69 | 80.92 | 86.24 | 96.38 | 94.69 | 88.33 |
| I-H36M(本文) | 71.52 | 88.03 | 92.52 | 76.46 | 82.55 | 94.07 | 95.30 | 85.78 |
| IK-H36M(本文) | 79.23 | 91.60 | 94.40 | 77.61 | 81.40 | 92.69 | 93.34 | 87.18 |
| IKM-H36M(本文) | 74.98 | 91.06 | 94.33 | 78.65 | 85.21 | 95.77 | 95.16 | 87.88 |
表选项
3.4.4 可视化3D估计结果 为更直观地看到本文模型在深度图像和彩色图像上的3D估计结果,本文可视化了使用IKM-H36M模型分别在ITOP和Human 3.6M测试图像上的姿态估计图,如图 7和图 8所示。其中每幅估计图中均包含测试图像、groundtruth及本文估计结果3部分,(b)和(e)为groundtruth姿态效果,(c)和(f)为本文模型估计效果。
 |
| 图 7 ITOP数据集上的3D人体姿态估计 Fig. 7 Three-dimensional human pose estimation on ITOP dataset |
| 图选项 |
 |
| 图 8 Human 3.6M数据集上的3D人体姿态估计 Fig. 8 Three-dimensional human pose estimation on Human 3.6M dataset |
| 图选项 |
从图 7和图 8中可以看出,使用本文弱监督学习方法的IKM-H36M模型可对深度图像和彩色图像预测其相应的3D人体姿态,并且预测结果也较为接近groundtruth姿态。图 7为本文针对ITOP深度图像数据集上进行的3D人体姿态估计效果图,可以看出,即使是对较为复杂的自遮挡人体侧视图,也可获得较好的3D人体姿态估计。由于人体下肢的自由度比上肢自由度大,使得该方法在膝盖和脚踝处的深度预测结果不如上肢预测效果理想,但本文方法也对无深度标签的深度图像实现3D人体姿态估计提供了可能。同时从图 8结果图中可看出,本文模型对彩色图像同样可实现较为理想的3D人体姿态估计。
4 结论 本文针对缺乏深度标签的深度图像训练样本进行研究,提出了一种基于多源图像弱监督学习的3D人体姿态估计方法,以实现对深度图像的3D人体姿态估计任务。同时为改善网络的估计性能,本文对网络结构中的残差模块进行了改善设计。
1) 针对深度图像训练样本中3D标注不足的问题,使用弱监督学习技术来完成3D回归模型训练任务。
2) 针对深度图像姿态单一造成的模型泛化能力不高的问题,提出一种多源图像融合训练技术。该方法主要利用彩色图像姿态多变的特点,在网络训练阶段引入较为充分的人体姿态信息,提高模型的回归性能。
3) 为提高姿态估计结果,基于提升回归模型准确率的基本思想,对残差模块的构成提出改善设计,并且通过实验结果证明该设计方案可在降低训练时间及模型存储空间基础上提高对图像的3D人体姿态估计准确度。
实验验证了在训练回归模型的网络结构中,一个合适的残差模块对提高回归模型准确率、降低参数量及训练时间等均有重要影响,因此接下来,本文将对如何更好地改善残差模块进行研究。
参考文献
| [1] | PARK S, HWANG J, KWAK N.3D human pose estimation using convolutional neural networks with 2D pose information[C]//European Conference on Computer Vision.Berlin: Springer, 2016: 156-169. |
| [2] | YANG W, OUYANG W, LI H, et al.End-to-end learning of deformable mixture of parts and deep convolutional neural networks for human pose estimation[C]//IEEE Computer Society Conference on Computer Vision and Patter Recognition.Piscataway, NJ: IEEE Press, 2016: 3073-3082. https://www.researchgate.net/publication/311610573_End-to-End_Learning_of_Deformable_Mixture_of_Parts_and_Deep_Convolutional_Neural_Networks_for_Human_Pose_Estimation |
| [3] | ZE W K, FU Z S, HUI C, et al.Human pose estimation from depth images via inference embedded multi-task learning[C]//Proceedings of the 2016 ACM on Multimedia Conference.New York: ACM, 2016: 1227-1236. https://www.researchgate.net/publication/310819871_Human_Pose_Estimation_from_Depth_Images_via_Inference_Embedded_Multi-task_Learning |
| [4] | SHEN W, DENG K, BAI X, et al. Exemplar-based human action pose correction[J]. IEEE Transactions on Cybernetics, 2014, 44(7): 1053-1066. DOI:10.1109/TCYB.2013.2279071 |
| [5] | GULER R A, KOKKINOS L, NEVEROVA N, et al.DensePose: Dense human pose estimation in the wild[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 7297-7306. https://www.researchgate.net/publication/329754451_DensePose_Dense_Human_Pose_Estimation_in_the_Wild |
| [6] | RHODIN H, SALZMANN M, FUA P.Unsupervised geometry-aware representation for 3D human pose estimation[C]//European Conference on Computer Vision.Berlin: Springer, 2018: 765-782. https://link.springer.com/chapter/10.1007/978-3-030-01249-6_46 |
| [7] | OMRAN M, LASSNER C, PONS-MOLL G, et al.Neural body fitting: Unifying deep learning and model based human pose and shape estimation[C]//International Conference on 3D Vision.Piscataway, NJ: IEEE Press, 2018: 484-494. |
| [8] | HAQUE A, PENG B, LUO Z, et al.Towards viewpoint invariant 3D human pose estimation[C]//European Conference on Computer Vision.Berlin: Springer, 2016: 160-177. https://link.springer.com/chapter/10.1007%2F978-3-319-46448-0_10 |
| [9] | TOSHEV A, SZEGEDY C.DeepPose: Human pose estimation via deep neural networks[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2014: 1653-1660. https://www.researchgate.net/publication/259335300_DeepPose_Human_Pose_Estimation_via_Deep_Neural_Networks |
| [10] | CAO Z, SIMON T, WEI S E, et al.Realtime multi-person 2D pose estimation using part affinity fields[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 7291-7299. https://www.researchgate.net/publication/310953055_Realtime_Multi-Person_2D_Pose_Estimation_using_Part_Affinity_Fields |
| [11] | WEI S E, RAMAKRISHNA V, KANADE T, et al.Convolutional pose machines[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 4724-4732. https://www.researchgate.net/publication/319770228_Convolutional_Pose_Machines?ev=auth_pub |
| [12] | NEWELL A, YANG K, DENG J, et al.Stacked hourglass networks for human pose estimation[C]//European Conference on Computer Vision.Berlin: Springer, 2016: 483-499. https://link.springer.com/chapter/10.1007%2F978-3-319-46484-8_29 |
| [13] | YI Z X, XING H Q, XIAO S, et al.Towards 3D pose estimation in the wild: A weakly-supervised approach[C]//IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2017: 398-407. https://www.researchgate.net/publication/322060193_Towards_3D_Human_Pose_Estimation_in_the_Wild_A_Weakly-Supervised_Approach?ev=auth_pub |
| [14] | SAM J, MARK E.Clustered pose and nonlinear appearance models for human pose estimation[C]//Proceedings of the 21st British Machine Vision Conference, 2010: 12.1-12.11. |
| [15] | ANDRILUKA M, PISHCHULIN L, GEHLER P, et al.2D human pose estimation: New benchmark and state of the art analysis[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2014: 3686-3693. https://www.researchgate.net/publication/269332682_2D_Human_Pose_Estimation_New_Benchmark_and_State_of_the_Art_Analysis |
| [16] | CTALIN I, DRAGOS P, VLAD O, et al.Human 3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(7): 1325-1339. https://www.ncbi.nlm.nih.gov/pubmed/26353306 |
| [17] | HAN X F, LEUNG T, JIA Y Q, et al.MatchNet: Unifying feature and metric learning for patch-based matching[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2015: 3279-3286. |
| [18] | XU G H, LI M, CHEN L T, et al. Human pose estimation method based on single depth image[J]. IEEE Transactions on Computer Vision, 2018, 12(6): 919-924. DOI:10.1049/iet-cvi.2017.0536 |
| [19] | SI J L, ANTONI B.3D human pose estimation from monocular images with deep convolutional neural network[C]//Asian Conference on Computer Vision.Berlin: Springer, 2014: 332-347. https://link.springer.com/chapter/10.1007/978-3-319-16808-1_23 |
| [20] | GHEZELGHIEH M F, KASTURI R, SARKAR S.Learning camera viewpoint using CNN to improve 3D body pose estimation[C]//International Conference on 3D Vision.Piscataway, NJ: IEEE Press, 2016: 685-693. https://www.researchgate.net/publication/308349713_Learning_camera_viewpoint_using_CNN_to_improve_3D_body_pose_estimation |
| [21] | CHEN C H, RAMANAN D.3D human pose estimation=2D pose estimation+matching[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 5759-5767. https://www.researchgate.net/publication/320968127_3D_Human_Pose_Estimation_2D_Pose_Estimation_Matching |
| [22] | POPA A I, ZANFIR M, SMINCHISESCU C.Deep multitask architecture for integrated 2D and 3D human sensing[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 4714-4723. https://www.researchgate.net/publication/320971314_Deep_Multitask_Architecture_for_Integrated_2D_and_3D_Human_Sensing |
| [23] | COLLOBERT R, KAVUKCUOGLU K, FARABET C.Torch7: A Matlab-like environment for machine learning[C]//Conference and Workshop on Neural Information Processing Systems, 2011: 1-6. |
| [24] | NIKOS K, GEORGIOS P, KOSTAS D.Convolutional mesh regression for single-image human shape reconstruction[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2019: 4510-4519. https://www.researchgate.net/publication/332960783_Convolutional_Mesh_Regression_for_Single-Image_Human_Shape_Reconstruction |
| [25] | CHENXU L, XIAO C, ALAN Y.OriNet: A fully convolutional network for 3D human pose estimation[C]//British Machine Vision Conference, 2018: 321-333. https://www.researchgate.net/publication/328939243_OriNet_A_Fully_Convolutional_Network_for_3D_Human_Pose_Estimation?_sg=r3piujM19hvLkXZ06fh_A65IavXt1ylZplaAFT5xxxEkliWoBfnMJOyUqBeXT1vAQNH9dJe6XugzQptjC78z9Z9x9wxgcg |
