Boosting�㷨�Ƿ�������һ����ϲ��ԣ�ӵ�м�ʵ�����ۻ������ܽ�ֻ������²��һЩ��������������Ϊ���ྫ�ȸߵ�ǿ����������ʵ����Ҳ�õ��������о��㷺��Ӧ�á���Ϊһ���㷨���, Boosting�㷨��������Ӧ��������Ŀǰ���еĻ���ѧϰ�㷨���Խ�һ����ǿԭ�㷨��Ԥ�⾫��, Ӧ��ʮ�ֹ㷺��AdaBoost�㷨��������ɹ��Ĵ���, ����Ϊ�����ھ�ʮ���㷨֮һ[1]�����㷨��Ӧ��������д����ʶ����AdaBoost�㷨����Ҳ����Ϊ�ɹ���ʵ��Ӧ��֮һ[2]�����ı�����ͼ�����ͼ��ʶ��ͼ���������ʶ��ͼ�����д���ַ�ʶ��ͻ�е������ϵ����õ��˹㷺Ӧ�á�
�ں��շ�������������о������У�������������[3]��AdaBoost�㷨��������Ĺ��Ϸ�����������������֤�˹��Ϸ�����������������ߺ�����³���Եĸ��ơ�������ʹ���Ϊ[4]��ģ������Ĺ�����Boosting�㷨��ϣ��ڹ�����й���������Ҳȡ���˽Ϻõ����Ч�����ﳬӢ��[5]��֧��������(SVM)��Ϊ����������ͨ��Boosting�㷨�ļ�Ȩ�ںϣ�����ʵ��������֤����ϵ�ȷ����SVM��79.4%��ߵ�Boosting-SVM�㷨��85.7%������[6-7]Ҳ��AdaBoost�㷨���ں��շ���������������˴���������Ӧ���о�����ˣ�����ͨ��AdaBoost����㷨�Ľ�ϣ���SVM��Ϊ����������������һ�ֶ����AdaBoost�ķ������������ģ�͡�
1 �����AdaBoost�㷨 1.1 AdaBoost�㷨 Kearns��Vliant[8]���о�PACѧϰģ��ʱ�����һ����Ȥ�����⣺��ѧϰ�Ƿ�ȼ���ǿ��ѧϰ����Boosting���⡣��һ���⣬��Schapire֤�������˿϶��Ļش𣬲���Schapire��Freund[9-10]�������о��������AdaBoost�㷨�����㷨�ĺ���˼���ǣ��Ӵ�������������ֲ�Ȩ�أ����ͷ�����ȷ�������ֲ�Ȩ�أ��Ӷ��õ��µ������ֲ������µ������ֲ����ٴ�ѵ���õ��µ������������Դ����ƣ��õ�����������������һ��Ȩ�صĵ���(boost)���Ӷ��γ�ǿ����������ͼ 1��ʾ��
 |
| ͼ 1 AdaBoost�㷨�ṹ Fig. 1 Structure of AdaBoost algorithm |
| ͼѡ�� |
1.1.1 �����������AdaBoost.M1�㷨 ����������һ����AdaBoost.M1�㷨���������ͼ 1�У�T(1), T(2), ��, T(M)���㷨��M��ѭ���в�����M������������������ÿ��ѭ���У�����������T(m)�����ļ�Ȩ�������������err(m)��������һ�ֵ����������������������ռȨ����(m), err(m)Ҳ��������һ�ַ��������ķֲ�Ȩ����i+1���ڽ���M��ѭ����M���������ķ��������м�Ȩ��ϣ��ۺ��жϽ��C(x)������ѡ��
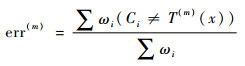 | (1) |
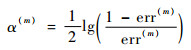 | (2) |
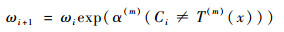 | (3) |
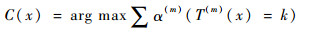 | (4) |
��ʽ(1)��ʽ(2)֪��err(m)����������Ȩ������ڼ�������л�ʹ������Խ��Խ���Ǵ�����������Ҫ�ԣ���������(m)����ֱ�۷�ӳ��������Ҫ�̶ȣ�����(m)����ʽ��֪��������err(m)ԽС����(m)����Խ��������Ȩ����i+1����һ�������µ�����Ȩ�طֲ��£�������һ��ѭ�����ɴˣ��ɵõ�M����Ȩ������������
AdaBoost.M1�㷨ֻ��Ҫ����ѵ������M��Ҫ����(m)Ϊ��������1��err(m) > 1/2�������Զ�������������Ҫ��ֻ�����50%�����������þͿ��ԣ�����ȷ�ʻ�����ѵ����M�����Ӷ����ӣ������Ͽ���������1��ʵ���У����ڹ���רע�����������������ܻᵼ�����ݲ�ƽ����˻�����[11]���Դ˿���ͨ��AdaBoostһЩ�Ľ��㷨�������˻���
��AdaBoost�㷨�ĸĽ���Ҫ����������3�����棺�ٵ���Ȩֵ���·��������������������ܡ������˻��ȣ��ڸĽ�AdaBoost��ѵ��������ʹAdaBoost�ܸ���Ч�ؽ�����չ���۽�������㷨��һЩ������Ϣ�����������㷨���ﵽ��߾�ȷ�ȵ�Ŀ��[12]��
1.1.2 ����������AdaBoost.SAMME�㷨 �������������������һ����������⣬AdaBoost���ڶ��������ʱ���ɲ���AdaBoost.SAMME�㷨�����㷨�Ƕ�AdaBoost.M1�㷨���еĸĽ���Zhu��[13]ͨ���ı�Ȩ�ط�����(m)�Ĺ�������˷��ϵ�1������ĸĽ�������(m)=

1.2 AdaBoost�㷨������������ѡ�� ����AdaBoost�㷨ֻ��һ�������������ྫ�ȵ���ϲ��ԣ��㷨���������ܶ��������з��࣬��˽�������������ʱ������Ҫѡ���ʺ���Ҫ�������Ļ�����������
SVM����ͳ��ѧϰ���ۣ����ýṹ������С���������ѧϰ����������������С�����������ԡ���άģʽ������£��ܻ�����õ�ͳ�ƹ��ɣ������ں��շ���������������Ŀ�ٵ��������ģʽʶ��������У�SVM�Ļ���˼���ǣ�Ѱ���������������ŷ����档
���Է���ʱ����n������ѵ����D={(xi, yi)|i=1, 2, ��, n}, x��R, y��{��1, 1}��
���������Կɷ�ʱ�����ڶ�������������ŷ��೬ƽ��Ϊ������x+b=0����ʱ�ķ�����Ϊ2/||��||����||��||��Сʱ���������������ת��Ϊ��Լ�������µ��Ż�����:
 | (5) |
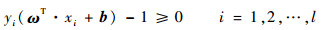 | (6) |
��ѵ���������Բ��ɷ��Ҵ�����������ʱ����Ҫ����Ǹ��ɳڱ�����i, i=1, 2, ��, n��������ŷ���������ת��Ϊ
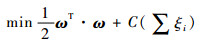 | (7) |
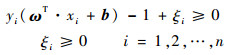 | (8) |
ʽ�У�CΪ������(�ͷ�����)������Ȩ�⾭����ա���i��С���븴����(VCά)����ֵԽ��ʾ�Է������ͷ�Խ��
ͨ�������������պ�����
 | (9) |
������ת��Ϊ��ż�����������õ����ߺ�����
 | (10) |
�����Է���ʱ����Ҫͨ���˺���K(xi, xj)������xӳ�䵽�µĸ�ά�ռ䣬�ڸ�ά�ռ��ж������������Ի��֡����ڸ�ά������и����ԣ���˿���Hilbert-Schmidt���ۺ�Mercer�����£�ѡ���ض��˺�������С���㸴���ԡ����õĺ˺���Ϊ����ʽ�˺�����sigmoid��֪�˺�������˹�˺��������������˺����ȡ����IJ����Ը�˹�˺���
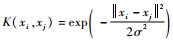
AdaBoost�㷨��SVM�㷨��ϣ�������AdaBoost-SVM�㷨�����㷨����AdaBoost�㷨�Ľ���ʩ�е�3�ָĽ��㷨���������������㷨��ϵķ����������Ľ����㷨����SVMRBF (��˹������˺���SVM)��ΪAdaBoost�㷨������������������AdaBoost�㷨��Ҫ��������������̫ǿҲ����̫����̫ǿ�����������˻����⣬̫��ҲҪ���������²�Ҫ�á���SVM������������ʱ��Ϊ����������������߶���أ���ͨ���˲�����������C�ĵ��������ı�SVMRBF�ķ������ܸ���Ҫ����AdaBoost-SVM�㷨�����������ʱ������Ӧ��������C������ֵ��Ӧ����ѧϰ������SVM�����ֺ��ʵ�Cֵ���䣬�ڶ���ѭ����ʹ����һ��ֵ��ֱ��������ȷ�ʵ�����ֵ����ʱ��ֻ�����������ֵ����ߺ���ѭ������ʹ�÷������ķ��ྫ�ȣ����μ���ѭ����ʵ�ֶ�SVMʹ��AdaBoost�㷨����ȷ�ȵ���ߡ�
1.3 ����������������ϵ�������� ���AdaBoost.SAMME�㷨��AdaBoost-SVM�㷨����SVM��Ϊ�����������������������һ�ֶ�����AdaBoost�㷨���ں��շ������Ĺ�����ϡ�
�㷨����������ͼ 2��ʾ��
 |
| ͼ 2 ������������ϵĶ����AdaBoost�㷨����ͼ Fig. 2 Flowchart of multi-classification AdaBoost algorithm for engine fault diagnosis |
| ͼѡ�� |
������ѵ���������ݽ�����֤����ѡ��SVM������Χ���趨�ʵ�ѵ��ѭ����M��������Cֵ������ʼֵ��ini��������ֵ��min�Լ�����С������step������AdaBoost.SAMME�㷨�Է�����Ȩ����(m)���е�����ʹ������������ڷ������������͵Ķ���������������SVMΪ����������������Ӧ���շ�������������й������������١����Գơ���ά�ȵ��ص㡣�Դ�����AdaBoost�㷨����������ʹ��SVM���з�����������ϵ�������
2 �������������ģ�� 2.1 ����Ԥ����
2.1.1 ������Դ �������������ָӡͼ(��ͼ 3)��ʵ������е���Ҫ���ߣ���ʶ�˲�ͬ���϶�Ӧ�ķ�������Ҫ���ܲ�����Сƫ����������Сƫ��������ݵ����Թ�ϵ����ͬ�̶ȵ�ͬ���������֮����ڱ�ֵ��ϵ��ʵ��ƫ��������ָӡͼƫ�����ݱ�ֵΪ1ʱ����ʾ�ù�����ָӡͼ�ж�Ӧ���ϵ����ͺͳ̶���ȫһ�£�����ֵΪNʱ����ʾ�ù�����ָӡͼ�ж�Ӧ���ϵ�����һ�£����̶Ȳ�ͬ������������ָӡͼ���й������ʱ����Ӧ���������ȷʶ����Ϸ�չ�γ̶Ȳ�ͬ��ͬһ���ϡ�
 |
| ͼ 3 �������������ָӡͼ Fig. 3 Fingerprint map for engine fault diagnosis |
| ͼѡ�� |
Ϊ��ʹͨ��ָӡͼ���������ܹ�����ʵ����ϣ�Ӧ��ָӡͼ�й��ϱ�ʶ���ݽ��д������Ա�õ���Ӧ��Χ�����ѵ�����ݡ����IJο�����[16]�е����ϵ�����ͱ�ֵϵ�������ڴ˻���������˵�λ����������ָӡͼ����Сƫ��������Ϊ����ѵ�����ݡ�
ѡȡPW4000������ָӡͼ��Ϊ�������ݣ���ȡ���ܲ���Сƫ�����ݣ����� 1��ʾ��
�� 1 PW4000ָӡͼ����ƫ������ Table 1 Fault deviation data of PW4000 fingerprint map
| ������� | ������� | ��EGT/�� | ��FF/% | ��N2/% | ��N1/% |
| 1 | +5�� TAT | -17.0 | -1.4 | -1.0 | -1.0 |
| 2 | -5�� TAT | 17.0 | 1.4 | 1.0 | 1.0 |
| 3 | +0.02MACH | 2.0 | -2.2 | -0.1 | -0.1 |
| 4 | -0.02MACH | -2.0 | 2.2 | 0.1 | 0.1 |
| 5 | +500 ALT | 0 | 2.4 | 0 | 0 |
| 6 | -500 ALT | 0 | -2.4 | 0 | 0 |
| 7 | -2% HPC | 12.0 | 1.6 | 0 | 0 |
| �� | |||||
| 24 | -2% LPT | -2.0 | -2.1 | 0.7 | -1.7 |
��ѡ��
Ϊ������ͬ�̶ȵ����й��ϲ��õ�ģ������ѵ�����ݣ���Ի������ݽ������䡣��ֵϵ�����ǽ�ָӡͼ������ƫ�����ݦ�EGT(�����¶�ƫ��)����FF(ȼ������ƫ��)����N2(��ѹת��ת��ƫ��)����N1(��ѹת��ת��ƫ��)ת��Ϊ��EGT/��FF����N2/��FF����N1/��FF���ù������ݵ���Ա�ֵ����������������ϵ��������ԭʼ����ƫ������֮�䣬ijһ�����������֮����������ϵ������4ά�������ݱ�Ϊ24ά��
��λ�������ǽ�ָӡͼ�и�ƫ�����ݽ��е�λ��������ʹ�������������ڵ�λ������ɵġ��ռ��У��Ӷ����ͬһ���ϳ̶Ȳ����Ӱ�죬���� 2��ʾ����ͼ 3��ʾָӡͼ�У�������һ�����ݦ�EGT/��FF��Ϊ��ϵ�ָ�꣬�ڵ�λ�������£����릤EGT/��FFָ������������ʶ��ά�ȣ���Ϊ�÷����IJ��䡣
�� 2 ��λ���������ϱ�ʶ Table 2 Fault identification of unit vector method
| ������� | ��EGT/�� | ��FF/% | ��N2/% | ��N1/% | ��EGT/��FF |
| 1 | -0.993 | -0.082 | -0.058 | -0.058 | 12 |
| 2 | 0.993 | 0.082 | 0.058 | 0.058 | 12 |
| 3 | 0.672 | -0.739 | -0.034 | -0.034 | -1 |
| 4 | -0.672 | 0.739 | 0.034 | 0.034 | -1 |
| 5 | 0 | 1 | 0 | 0 | 0 |
| 6 | 0 | -1 | 0 | 0 | 0 |
| 7 | 0.991 | 0.132 | 0 | 0 | 8 |
| �� | |||||
| 24 | -0.583 | -0.612 | 0.204 | -0.495 | 1 |
��ѡ��
2.1.2 �������������ӷ��� ���������ӿ���ʹ���ģ����Ӧ���ƫ���Ӱ�죬����ģ�͵�³���ԡ�����ָӡͼ����ƫ������������������ѵ��ʱ������2����������˼·��
1) ���� 1��ʾԭʼƫ�����ݼ���һ���̶ȵ����������Ȼ���ñ�ֵϵ�����ȷ����������������ݣ���Ϊѵ���Ͳ������������ʱ����Ҫ��ʵ�ʲ�����ƫ�����ݽ��б�ֵ�����ȴ����õ������� 2�е�ת�����ݣ��ٽ�����ϡ�
2) ���� 2�������У�ֱ�Ӹ����Ѿ�ת��������ݽ����������ӡ���ʱ���ֱ������ͬһ�̶ȵ��������Ȼ�Ը���ʶ����Ӱ��̶Ȳ�ͬ�����Ӧ����������ֵһ���̶�(����)��ƫ�����֤��������һ���̶�Ҳ�ʹ��ϵ����Ա�����
�ڵ�1��˼·�£����ڲ��ñ�ֵϵ���������Ὣƫ��Ŵ�λ���������ϱ�ʶ����֮���ֵ��С����ˣ�ԭʼ���ݲ��˼�����������������ϵ������ά������������������ʹ���⸴�ӻ���������������ʱ���ʺ���һ������ڵ�2��˼·�£����Լ���ϴ����������Ӧ���ݾ�����ϱ�ʶ���ݲ��ò�ͬ�̶ȵ��������ӡ�
2.2 �����AdaBoost�㷨�������ģ�͵ķ����ͼ��� ѵ�������������IJ�ͬ��ѵ�����������ϴ��Ӱ�졣Ϊ���ܹ�����ϴ�����������AdaBoost�㷨������Ч�������õ�2����������˼·���������ģ�͵ķ�����������Ӧ�����µ�ѵ����24��200�顢���Լ�24��100�����ݽ���ѵ���Ͳ��ԡ��ڶ����AdaBoost���ģ�ͽ���֮ǰ��Ҫ���ý�����֤�����ֱ�Ѱ��3�ַ����Ļ�������������SVM����C�������ʵ�ȡֵ��Χ�������ڶ����AdaBoost���ģ��ѵ��ʱ��Ԥ����ѵ������MΪ50�����۲�ѵ�������������[14]֪�����ļ�С������step�����ö����յ�����Ӱ�첻��ͨ������Ϊ1~3��ʵ����������Ϊ1��
ͼ 4��ʾ���ڽ�����֤����£�����SVM���ò�ͬ��������������õ�ѵ�����ݣ�����4�����ģ�͵������ȷ�ʡ�ͼ�У�C=2c, ��=2g�����Կ��������������˽ϴ�����������һ���ģ����ȷ�ʲ����ߡ���ѵ���У���������ѡȡ���ŵ�Cֵ�ͺ˲���������£�������������(��˹������˺���C-֧�����������)�������ȷ������ 3��ʾ��ͨ��ͼ 4�е���SVM��ȷ����˲����ı仯��Χ�����ԶԶ����AdaBoost�㷨�е���ز����������á��������AdaBoost�㷨ѵ���õ�M����Ȩ��������������ϡ��Ա�ֵϵ�����е�ѵ������Ϊ������M=50ʱ����50�εĵ����в�����50������������ѵ����������ͼ 5��ʾ�����Կ��������õĸ���������������ȷ�ʾ����ڵ������������������ȷ�ʡ�
 |
| ͼ 4 ��ͬѵ�������µ���SVMģ�͵���ȷ�� Fig. 4 Accuracy of single SVM under different training data |
| ͼѡ�� |
�� 3 ������֤�������Ų����µ���ȷ�ʺ;�AdaBoost�㷨���������ȷ�� Table 3 Comparison between accuracy of cross-validation method with the best parameters and that improved by AdaBoost algorithm
| % | ||
| �������ģ�� | �������������ȷ�� | Ӧ��AdaBoost�㷨����ȷ�� |
| ?��ֵϵ���� | 77.00 | 97.3 |
| ?���ϵ���� | 70.10 | 87.50 |
| ?������� | 64.38 | 86.52 |
| ?��λ������ (���릤EGT/��FF) | 83.04 | 87.45 |
��ѡ��
 |
| ͼ 5 M=50ʱ������������ѵ����� Fig. 5 Training errors of each weak classifier when M=50 |
| ͼѡ�� |
��ѡ��ѵ�����ݺ�ѵ�����������������ĸ���ѡ���ֱ��Ӱ�쵽ѵ��ʱ��;��ȡ�ͼ 6��ʾ������AdaBoost�㷨����ͬ���ģ�͵Ĵ����������������������ӵı仯��������Կ�������ʼʱ�������������ľ��Ȳ����ߣ�������������������(С��5��)������£�������������������������������������������ʱ�������������½��������������ȶ��IJ�����AdaBoost�㷨֮������������ȷ�ʣ�����ѵ�����ģ������ϣ�ģ������������ѵ��ʱ�䣬��һ�㷨ʵ����������ʱ��Ч���������ȷ�ʣ���˿ɸ��ݼ���ʱ������ȷ���ۺ�ȷ������������������������������������Ϊ20���ɡ�
 |
| ͼ 6 ��ͬģ����ϴ��������������������ı仯 Fig. 6 Variation of diagnosis error rate of different models with number of weak classifier |
| ͼѡ�� |
ע���ͼ 6�У����ϵ�����͵�λ��������������ģ�ʹ�����û����������������������������һ����С���Դ˽��з������֣����ֵϵ������ȣ��������ϵ�����͵�λ����������һЩ�������ݱ�ʶ���ڽӽ�(���� 4�е�7��8��9��3�ֹ���)������ijЩ��������һ�ֹ�������������AdaBoost.SAMME�㷨��Ȼ�ſ������������������ƣ�����û�й�ע���������������������ܱ�֤ÿ�α�����������ȷ�����ѵ������Ȩֵһ����������ֵ�������һ����ѵ������Ȩ�أ��Ӷ�����ȷ������ǿ��������ȷ�ʵ�����[17]�����㷨�ж������������ijһ���Ϲ̶������Ϊ��һ�ֹ���������ϴ���
�� 4 ���ϵ��������ֵ���ƵĹ��ϱ�ʶ Table 4 Numerical approximation fault identification of correlation coefficient method
| ������� | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | �� | 24 |
| 1 | 1 | -1 | -0.803 | 0.803 | 0.311 | -0.311 | -0.994 | -0.995 | -0.993 | �� | 0.377 |
| �� | |||||||||||
| 7 | -0.994 | 0.994 | 0.734 | -0.734 | -0.208 | 0.208 | 1 | 0.999 | 0.999 | �� | -0.435 |
| 8 | -0.995 | 0.995 | 0.740 | -0.740 | -0.217 | 0.217 | 1 | 1 | 1 | �� | -0.422 |
| 9 | -0.994 | 0.994 | 0.734 | -0.734 | -0.208 | 0.208 | 0.999 | 1 | 1 | �� | -0.405 |
| �� | |||||||||||
| 24 | 0.377 | -0.377 | 0.031 | -0.031 | -0.414 | 0.414 | -0.435 | -0.422 | -0.405 | �� | 1 |
��ѡ��
ͨ����2��˼·���������Ӵ������������������ö����AdaBoost�㷨�ڽ���20�ε���ѵ����ģ�������ȷ������ 3��ʾ��
ͨ���� 3�ܹ���������ͬѵ�����ݼ�����ͬ�̶ȵ���������SVM������ȷ�ʲ����ߣ����ڵ�λ��������ѵ��������ֵ�ȽϽӽ�����������������������ȷ�ʱ�����2�ַ����ͣ�����������һ��ά�Ⱥ���ȷ������������ߡ������������������ȷ�ʽϵ͵�����£������AdaBoost�㷨���M����ȷ�ʽϵ͵�������������Ͻ����ȴ��������������ϵ���ȷ�ʡ�
������������֪�����ö����AdaBoost�㷨��ģ�������ȷ�ʾ�������������ͬʱ���֣���ʼѵ�����ݶ���Ͻ��Ҳ������ϴ�Ӱ�죬��Ҳ��ӳ�˸��������������������������ڷ�ӳ��ͬ��������ʱ�IJ��졣
���Ͽ�֪����ʵ������У�ֻͨ��ij��ѵ����������ģ�ͽ�����ϣ��������ijЩ�����г��ִ�����ˣ�Ϊ��ȫ�淴ӳ���ϵ�������������ָӡͼ�������������Ϻ���Ļ����ϣ�ͨ������ѵ�����ݽ��н�ģ���ٽ����ֽ�ģ���ͬʱ���ڷ�����ϣ����Ի�ñȽϿɿ�����Ͻ����
2.3 ������� ѡȡij���չ�˾3��δ������غ����ֻ�������������������Ĺ��ϰ���������Ϸ�����ͨ����������۲쵽������������ʱ���нϴ�仯������������״̬���������ɸ����������ֵ��ƫ��������õ���Ӧ����ƫ��ֵ[18]����֪3���������ܲ���Сƫ��ֵ���¡�����1����EGT=22��, ��FF=2.8%, ��N2=1%����N1=0.2%������2����EGT=8�棬��FF=1%����N2=0%����N1=-0.2%������3����EGT=-50.3�棬��FF=-1.13%����N2=-2.7%����N1=-22.57%����������4��ģ�ͽ�����ϣ�������� 5��ʾ(�� 5��(1)��(2)�ֱ��ʾ�ڵ�1�֡���2���������ӷ������������ģ�͵���Ͻ������Ͻ���ı��ֵ��ʾָӡͼ�б�ʶ�ĵڼ��ֹ���)��
�� 5 ������Ͻ�� Table 5 Cases' diagnosis results
| �������ģ�� | ������� | ||
| ����1 | ����2 | ����3 | |
| ��ֵϵ����(1) | 7 | 7 | 20 |
| ��ֵϵ����(2) | 7 | 7 | 1 |
| ���ϵ����(2) | 8 | 7 | 1 |
| �������(1) | 7 | 7 | 1 |
| �������(2) | 7 | 12 | 1 |
| ��λ������(���릤EGT/��FF)(2) | 7 | 7 | 2 |
��ѡ��
����һЩ���ϱ�ʶ���ݼ���ڸ߶�������(���� 3)��һЩ�������ʹ�������ԣ���ģ�������ȷ�ʲ�����ͬ�����ģ����Ͽ��ܴ���һ��ƫ���ͨ���� 5�и�����ģ����Ͻ���ۺϷ��������п��ܵĹ���Ϊ7��7��1������ָӡͼ��֪��7�����Ϊ��ѹѹ�������������ʧ����1��Ϊ����ָʾƫ�ʵ�ʹ������������1Ϊ��ѹѹ����ҶƬ������(��ͼ 7)������2Ϊij2.5�����������������������ӻ��������䣬����3ΪTt2̽ͷ�������⡣����1�Ͱ���3��Ͻ����ȫ��ȷ������1�У�����������ѹѹ����ҶƬ��������ʱ��������ѹ��Ч�ʻή�ͣ�����Ҳ�ή�ͣ�Ϊ���������ȶ�����Ҫ����ȼ����ʹѹ����ת�����ӣ��������ѹ�ȣ���˸��������������ӣ�����2�У�2.5����������ȫ������ʹ���������٣�ѹ����Ч�ʱ��ֳ��½�����˻�Ӱ���ѹѹ�������Ч�ʣ�����3�У�Tt2̽ͷ��������ʱ�����ڲ���������Ҫ�������½����������ڷ�����EPR�����������ı�ʱ����4����·��������ͬ���������ƫ��Ҧ�EGTƫ������쳣������ָʾϵͳ���ϵĿ����Խϸߡ�
 |
| ͼ 7 ����1��ʵ���Źʼ���� Fig. 7 Actual detection and troubleshooting results of Instance 1 |
| ͼѡ�� |
���Ͽɼ�����������������������ģ�ͣ���ʵ����������ȷ�Ժܸߣ����ڹ�����Ͼ��нϴ��ָ�����塣����ָӡͼ�б�ʶ��һЩ����ֻ����ص�Ԫ����������⣬�簸��2�в�δָ�����¹��Ͼ���ԭ�������ʵ�ʹ��������������ÿ�̽�������ֶν�һ���ķ�����̽�顣
3 ���� ���ö����AdaBoost�㷨���ۺϸĽ��㷨����SVMΪ�����������������������ϵ�ȷ�ʡ���ʵ�ʰ�������У����ò�ͬѵ�����ݽ����˶��AdaBoost���ģ�ͣ���������ʵ�ʹ��ϵ���ϣ�ͨ���ۺϷ�����Ͻ�������Ը���ȷ���жϹ������ࡣ
��ָ�����ǣ����IJ��õ�AdaBoost�㷨����Ľ��㷨���и��ƿռ�[17]������������ֵ����������ٴ����ȷ����������ں����о��м������ƣ��Ӷ��ܹ���һ�����ѵ��ģ�͵���ȷ�ʡ�
�����
| [1] | WU X, KUMAR V. The top ten algorithms in data mining[M].Boca Raton: CRC Press, 2009: 127-149. |
| [2] | ��Ө, ������, ���ҳ�, ��. AdaBoost�㷨�о���չ��չ��[J].�Զ���ѧ��, 2013, 39(6): 745�C758. CAO Y, MIAO Q G, LIU J C, et al. Advance and prospects of AdaBoost algorithm[J].Acta Automatica Sinica, 2013, 39(6): 745�C758.(in Chinese) |
| [3] | ������, ����. ����AdaBoost�㷨�Ĺ�����Ϸ����о�[J].��������������, 2005, 26(12): 3210�C3212. XU Q H, YANG R. Simulation research on fault diagnosis using AdaBoost algorithm[J].Computer Engineering and Design, 2005, 26(12): 3210�C3212.DOI:10.3969/j.issn.1000-7024.2005.12.016(in Chinese) |
| [4] | ������, ����Ϊ. ����Boostingģ������Ĺ�����й������[J].ģʽʶ�����˹�����, 2003, 16(3): 323�C327. XIA L M, DAI R W. Fault testing on rolling bearing based on Boosting fuzzy classification[J].Pattern Recognition and Artificial Intelligence, 2003, 16(3): 323�C327.DOI:10.3969/j.issn.1003-6059.2003.03.011(in Chinese) |
| [5] | �ﳬӢ, ��³, ������. ����Boosting-SVM�㷨�ĺ��շ������������[J].���ն���ѧ��, 2010, 25(11): 2584�C2588. SUN C Y, LIU L, LIU C W. Aero-engine fault diagnosis based on Boosting-SVM[J].Journal of Aerospace Power, 2010, 25(11): 2584�C2588.(in Chinese) |
| [6] | ����, л����, �̿���, ��. Diverse AdaBoost-SVM����������ں��շ�������������е�Ӧ��[J].����ѧ��, 2007, 28(5): 1085�C1090. HU J H, XIE S S, CAI K L, et al. Classification method of diverse AdaBoost-SVM and its application to fault diagnosis of aero-engine[J].Acta Aeronautica et Astronautica Sinica, 2007, 28(5): 1085�C1090.DOI:10.3321/j.issn:1000-6893.2007.05.010(in Chinese) |
| [7] | ����, �����, ��Ӧ��, ��. һ�ֻ���ָ����ʧ�����Ķ������AdaBoost�㷨����Ӧ��[J].����ѧ��, 2008, 29(4): 811�C816. HU J H, LUO G Q, LI Y H, et al. An AdaBoost algorithm for multi-class classification based on exponential loss function and its application[J].Acta Aeronautica et Astronautica Sinica, 2008, 29(4): 811�C816.DOI:10.3321/j.issn:1000-6893.2008.04.007(in Chinese) |
| [8] | KEARNS M, VALIANT L. Cryptographic limitations on learning Boolean formulae and finite automata[J].Journal of the ACM, 1994, 41(1): 67�C95.DOI:10.1145/174644.174647 |
| [9] | FREUND Y, SCHAPIRE R E. A decision-theoretic generalization of on-line learning and an application to Boosting[J].Journal of Computer and System Sciences, 1997, 55(1): 119�C139.DOI:10.1006/jcss.1997.1504 |
| [10] | FREUND Y, SCHAPIRE R E.Experiments with a new Boosting algorithm[C]//Proceedings of the 13th Conference on Machine Learning, 1996: 148-156. |
| [11] | ���, ����ʯ, ����, ��. AdaBoost�㷨��һ�ָĽ�����[J].С���ͼ����ϵͳ, 2004, 25(5): 869�C871. LI B, WANG Z S, WANG W, et al. Enhancing method for AdaBoost[J].Mini-Micro Systems, 2004, 25(5): 869�C871.DOI:10.3969/j.issn.1000-1220.2004.05.020(in Chinese) |
| [12] | �κ���, �ܵ���. AdaBoost����Ľ��㷨����[J].�����ϵͳӦ��, 2012, 21(5): 240�C244. LIAO H W, ZHOU D L. Review of AdaBoost and its improvement[J].Computer Systems & Applications, 2012, 21(5): 240�C244.(in Chinese) |
| [13] | ZHU J, ZOU H, ROSSET S, et al. Multi-class AdaBoost[J].Statistics and Its Interface, 2009, 2(3): 349�C360.DOI:10.4310/SII.2009.v2.n3.a8 |
| [14] | ��Ӧ��, ξѯ��. ���շ�������������ϡ���ģ��Ԥ�ⷽ��[M].����: ��ѧ������, 2013: 82-85. LI Y H, WEI X K. The methods of aero-engine's modeling, intelligent fault diagnosis and prognosis[M].Beijing: Science Press, 2013: 82-85.(in Chinese) |
| [15] | FRIEDMAN J, HASTIE T, TIBSHIRANI R. Additive logistic regression:A statistical view of boosting[J].Annals of Statistics, 2000, 28(2): 337�C407. |
| [16] | ��.����SVM������PW4000��������о�[D].���: �й���ѧ, 2015: 42-49. ZHANG Z.Research on fault diagnosis of PW4000 based on SVM multi-classification[D].Tianjin: Civil Aviation University of China, 2015: 42-49(in Chinese). |
| [17] | ������, ��׳, Ԭ˳. �����������������Ķ����AdaBoost�㷨[J].��������Ϣѧ��, 2016, 38(2): 373�C380. YANG X W, MA Z, YUAN S. Multi-class AdaBoost algorithm based on the adjusted weak classifier[J].Journal of Electronics & Information Technology, 2016, 38(2): 373�C380.(in Chinese) |
| [18] | �ܻ���, ��˼��, Ѧ��, ��. ����˫������ĺ��շ�����������Ϸ����о�[J].�й���ѧѧ��, 2014, 32(3): 41�C44. CAO H L, PANG S K, XUE P, et al. Research of aero-engine fault diagnosis method based on monitoring of twin differences[J].Journal of Civil Aviation University of China, 2014, 32(3): 41�C44.DOI:10.3969/j.issn.1674-5590.2014.03.010(in Chinese) |
