�����ھ�Ļ���˼����Cook��Wolf[3]�����Ŀ���Ǵ��������̵��¼���־���Զ����ֹ���ģ�͡�Agrawal��[4]���罫�����ھ��㷨Ӧ�õ������������У�����֮������������û֮����Ⱥ��ϵ����֮��������ԡ�Pinter��Golani[5]��Agrawal��[4]���㷨��������չ������Ŀ�ʼʱ������ʱ��ֿ����Ӷ��������֮��IJ��й�ϵ��Herbst��Karagiannis[6]��һ���������¼���־�д��ڵ�������Ի������ϵʶ���Ӱ�죬��ǰ�˵Ļ����ϼ����������ʶ���Ԥ�������̣������MerfeSeq��SplitSeq��SplitPar 3���㷨��Schimm[7]�����һ���Ի�ȡ�걸����С����ģ��ΪĿ����㷨����ģ����Ҫ������־�м�¼��ȫ��������Ǹ�ģ���ڳ������ػ���߷�����ѡ��ṹʱ�������Greco��[8]���ھ����ģ�͵IJ����ΪĿ�꣬��Щģ�ʹӲ�ͬ�ij����������¼���־��Ŀǰ���Թ����ھ��㷨�о�����������van der Aalst���ڼ����Ŷӡ�2004�꣬van der Aalst��[9]��������˻��ڹ���������(Workflow net��WF-net)��Ϊ���������㷨���������¼���־�걸������£����ֺ�����SWF-net(Structural Workflow net)��Ϊ�˽���������д��ڵĸ�������ṹ�����⣬���㷨��չ��Ϊһϵ�е��㷨������ϵ���㷨����+�㷨[10]�����㷨�Ļ����ϣ������˶�ѭ���ṹ���ھ��Գɹ������¼���־�е�ѭ���ṹ���õ�һ��������SWF-net��tsinghua-���㷨[11]�������¼���־�еĻ��Ϊԭ�ӻ����ÿ�������һ��START��һ��COMPLETION���ɣ��û֮����ص���ϵ���������㷨�еĹ���ʹ�������㷨�����Ͻ������Ǹ��㷨���¼���־��Ҫ��ϸߣ�ʵ���Բ����ߡ���++�㷨[12]������+�㷨�����ϵ���չ���������¼���־�еķ�����ѡ��ṹ�����㷨�����3�����������ϵ�ķ��������Է�����־�д��ڵ����з�����ѡ��ṹ��������Ǹ��㷨���ھ�̫�������ϵ�����ֽ����صĹ�����������#�㷨[13]������+�㷨�ϵ���һ��չ�����ھ����ػ���֣������ػ�Ͳ��ɼ�������Ϊ������ѡ��ṹ�Ĺ���Ҫ�ء���*�㷨[14]���ھ������㷨�ϵ���չ������˿��Է����¼���־��������Ĺ����㷨��Ϊ���㷨��Ԥ�������裬����ʶ����־��������ͬ�������ظ��Ļ��ʹ�����㷨��ȷ��������ߡ���ϵ���㷨�ڹ�����ģ�ͻ����ṹ������ṹ��ʶ�����нϸߵ�ȷ�ʣ������������������ĸ��ţ��ڶԺ����������¼���־�����ھ�ʱ��ȷ�ʻ������½���
Ϊ�������¼���־�е�����Ӱ�죬van der Aalst��[15]�����Petri��ģ��ͬ��������Ĺ�ϵ������ʽ����Petri��ת������ѧ���ľ���ģ�ͣ����������Ŵ��㷨�Թ�����ģ�ͽ��е����ͽ������Ӷ�����������־�е��������ţ�ͬʱ�õ���Ϊ���ƵĽ��ۡ������[16]���û��������˼�룬����������Ⱥ�㷨������ھ��ں���������ǿ�㷨�����ֲ����ŵ�������������㷨�������ٶȡ���쿺���ǿ[17]ͬ�����������������£�����ģ���˻��㷨ʵ�ֹ����ھ�ʵ���˶Թ������л����ṹ������ṹ���ھ����[18]�������[16]�Ļ����϶������ʱ����Ϊ���ϻ����ӣ��������˹����Ķ���ȺЭ��������Ӧ���ԣ�������Ⱥ�㷨���иĽ���������㷨���ȶ��Ժ������ٶȡ����϶��ǻ��ڽ����㷨�Ĺ����ھ��㷨����Щ�㷨��ȷ�����кܺõı��֣����ǵ���ʼ�������Ƚϸ��ӣ������������Ƚϴ�ʱ����������̫�����㷨����ʱ��ܳ����㷨Ч�ʽϵ͡�
���������һ�ֻ���ͳ�����㷨�Ĺ����ھ��㷨��ּ��ͬʱ�����ȷ�Ժ�Ч��2��Ŀ�꣬����ϵ���㷨�ͽ����㷨�����ƽ��������������Ҫ�������£��������һ�������ʶ��ʹ����������������ϵ���㷨Ŀǰû�н����������������������ʶ��ʹ�����Ϊ���㷨��Ԥ��������������������������ϵʶ���Ӱ�죬����������㷨��ȷ�ʡ��������һ��ͳ�����㷨��ͨ�����ʼ�����Ч�������¼���־�е�����Ӱ�죬����������㷨��ȷ�ʣ�����֤���㷨������Ч�ʡ��ۿ����˹������г������ֵķ�����ѡ��ṹ�����һ���µ�ʶ�������ѡ��ṹ���㷨���ھ����ٵ����Ӽ��������ϵ��ǰ���£���֤�˷�����ѡ��ṹ��ʶ���ʺ�ȷ�ԡ�
1 ͳ�����㷨��ϵ ��������Ļ���ͳ�����㷨�Ĺ����ھ��㷨������ͼ 1��ʾ����Ҫ����2��ģ�飺Ԥ����ģ������ھ�ģ�顣���У�Ԥ����ģ����Ҫ�����걸�¼���־����ȡ��ѭ���ṹʶ���봦���������ʶ���봦��3�����衣���ȸ����걸�¼���־�Ķ�������ݿ�����ѡ�����������¼���־��Ϊ�����ھ�Ļ�����Ȼ���������[19]�ж���ѭ���ṹ��ʶ������ھ�����Ȳ�ͬ��ѭ���ṹ������ѭ���ṹ����һ������������棬�Ӷ�����ѭ���ṹ�����������Ӱ�죻������ñ�������������ʶ���㷨�����¼���־�е���������з���ʶ��ʹ�������������������ڻ������ϵ�жϵ�Ӱ�졣�ڹ����ھ�ģ���У����ȸ����������ϵ���壬��˵��ֱ��������������֮��IJ����ԣ�Ȼ���ڴ˻����ϸ���ͳ�����㷨����ϸ�㷨˼·�������ͳ�����㷨�õ���ֱ��������ϵ�Ļ����ϣ���һ���Է�����ѡ��ṹ�в����ļ�����������ھӶ����ƻ���������ϵ�õ����ϵ�����ڵõ����յĻ��ϵ����֮�����������Ĺ�������Խ����ϵ����ת���������������õ���Ӧ��WF-net[15]��
 |
| ͼ 1 ����ͳ�����㷨�Ĺ����ھ� Fig. 1 Scheme of process mining based on statistical ��-algorithm |
| ͼѡ�� |
1.1 ������ϵ���걸�¼���־ �¼���־�ǹ�����ִ�й����в�������Ҫ��Ϣ�����¼���־���������¼��������ÿ��������ơ���ʼʱ���ִ���˵���Ϣ�����ǵ��¼���־��������ȱʧ��Ľ���ʱ�䣬ÿ����ij���ʱ�䲢����һ������ֱ�Ӵ��¼���־�еõ�����Ϣ��������WF-net���������ʱ���������ʱWF-net����Ŀǰ���¼���־�еõ�����ˣ���������Ĺ����ھ��㷨�ص����ڻ֮��������ϵ���ھ�ͨ��������ϵ����ӵõ��������������WF-net��
�����ھ�Ļ������ϵ��Ϊֱ�������ͼ������2�����档���л����T�������¼���־W?T����a, b��T����a��b��������ϵ��
1) ������a���ɡ�b��?�š�a��b����?�����a��b����ֱ��������ֱ��������ϵ��Ҫ���� 1��4�ֹ�ϵ��
�� 1 ֱ��������ϵ�����붨�� Table 1 Classification and definition of direct relations
| ֱ��������ϵ���� | ���� | ���� |
| ˳���ϵ | a > Wb | a, b����={��, a, b, ��} |
| �����ϵ | a��Wb | a > Wb��b��Wa |
| ѡ���ϵ | a#Wb | a��Wb��b��Wa |
| ���й�ϵ | a��Wb | a > Wb��b > Wa |
��ѡ��
2) ��������a���ɡ�b��?�š�a��b����?�����a��b���ڼ�����������������ϵ��Ҫָ��������ϵ���üǺ�a?Wb��ʾ��
��ֱ��������ϵ������Կ����������ھ��㷨���ھ���ͬ�¼���־���걸��������Ҫ��ϵ�����걸���¼���־�����õ�����Ľ������ˣ���ʹ�ù����ھ��㷨֮ǰ��Ҫ�����걸�¼���־�Ķ��塣
����1(�걸�¼���־)????��TΪ����ϣ����¼���־W?T��WΪ�걸�¼���־���ҽ������ٶ���������־W��?T������>W��?>W�ġ�W��?��W��#W��?#W�ġ�W��?��W���ڶ�������t��T������?��?W:t������
�걸�¼���־���жϻ��������ϵ��ǰ����������־���걸��Ҫ��ÿ�ֿ��ܳ��ֵ����̹켣���ٳ���һ�Ρ������������㷨���ǻ����걸�¼���־����֮�ϵģ��ڵ�������ݵĻ����У������������㹻������Ϊ�õ����¼���־�����걸�ġ�
1.2 �����ʶ���㷨 ������ǹ����ھ���һ�ֳ���������ṹ���� 2������ij�ٴ�·�����������¼���־�������ݣ��t25��t45��¼��ͬ���Ļ��ҽ������������t25��t45Ϊ�������Ϊ������ͬһ�����̹켣�е���������üǺ���i(A, ni)��ʾ�����̹켣��i�е�ni���A��Ȼ��ͨ�������¼���־���ݵľ���������Է��֣�t25����ʾ�ġ�ҽ��������ָ��������ǰҽ�����������Ĺ�ͨ��t45��Ȼ����������ҽ�����ڻ��ߵ�ѯ�ʡ���Ȼt25��t45������ͬ�������������������ߵ�ʵ�����岢����ͬ����������ߵ�����������жϻᵼ�»������ϵ�б���ִ��������Ҫ��������б���Ϊ�����ھ��Ԥ�������衣
�� 2 ij�ٴ�·���¼���־�������� Table 2 Event log of a clinical pathway (part)
| ���� | ����� |
| �� | �� |
| 25 | ҽ������ |
| 26 | �������� |
| 27 | ҩ���� |
| 28 | ���������� |
| 29 | ���ȷ�� |
| �� | ������ |
| 41 | �������� |
| 42 | �Ͳ��˻ز��� |
| 43 | ��ˮ��ҩ |
| 44 | ������Ϣ |
| 45 | ҽ������ |
| 46 | �������� |
| �� | �� |
��ѡ��
ѭ���ṹͬ���ǹ������г���������ṹ��������ڷ�����Դ�ȴ����߷���������¡���ѭ���ṹ����ʱ����Ȼ����ִ���������������֣�Ϊ�˼�������б���̣�����ʹ������[19]�и����Ķ���ѭ���ṹ��ʶ����ΪԤ������������ѭ���ṹ����������б��Ӱ�졣
���Ķ�����������б���������֮�ϣ�������Щ������ͬ�Ļ�Ƿ���庬��Ҳ��ͬ�����������������������Ƿ���ͬ��Ϊ2�֣��������ͬ�ij�Ϊ�ظ��������������ظ��(Duplicate Activities��DA)������ݲ�ͬ�ij�Ϊ���ظ��������(Homonyms Activities��HA)��Ϊ��̽��������ں�ʱΪ�ظ���������Ի��(activities group)Ϊ��λ���������ڻ����ظ���Ķ��塣
����2(���)????�����������̹켣��i��W�������i�лA����i��A��2��ǰ���Tp��Tpp��2����̻Ts��Tss����{Tpp��Tp��A��Ts��Tss}����һ�����ϼ���һ����飬����GA�������i�д����������i(A, n), ��i(A, m)����i�������߶�Ӧ�Ļ��ֱ�ΪGA��GA�䣬��GA��GA���а����ij���A֮���Ԫ����ͬ����Ԫ������˳��ͬ�����Ϊ2�������ȣ�����GA=GA�䡣
����3(�ظ��)????�����������̹켣��i��W�������i�д����������i(A, n), ��i(A, m)����i�������߶�Ӧ�Ļ��ֱ�ΪGA��GA�䣬��GA��GA���г��˻A֮����������Ӧ��ȣ�����i(A, n)�ͻ��i(A, m)���Զ���Ϊ�ظ����
�����¼���־W�е�ij�����̹켣��i��W���������i�д����������i(A, n), ��i(A, m)����i��Tp��Ts�ֱ�Ϊ���i(A, n)��ǰ������ͺ������TppΪTp��ǰ�����TssΪTs�ĺ�̻��Tp���Ts��ֱ�Ϊ���i(A, m)��ǰ������ͺ������Tpp��ΪTp���ǰ�����Tss��ΪTs��ĺ�̻�����i(A, n)�ͻ��i(A, m)��Ӧ�Ļ��ֱ�ΪGA��GA�䣬UΪ�ظ�����ϡ������������2�Ͷ���3�������ظ���б�������£�
1) ��GA=GA�䣬Tp=Tp����Ts=Ts�䣬����i(A, n), ��i(A, m)����U��
2) ��GA=GA�䣬Tp=Tp�䣬Ts��Ts�䣬Ts=Tss�䣬��Tss=Ts�䣬����i(A, n), ��i(A, m)����U��
3) ��GA=GA�䣬Tp��Tp�䣬Ts=Ts�䣬Tp=Tpp�䣬��Tpp=Tp�䣬����i(A, n), ��i(A, m)����U��
4) ��GA=GA�䣬Tp��Tp�䣬Ts��Ts�䣬Tp=Tpp�䣬Tpp=Tp�䣬Ts=Tss�䣬��Tss=Ts�䣬����i(A, n), ��i(A, m)����U��
5) ��GA��GA�䣬Tp=Tp�䣬Ts��Ts����Ts #WTs�䣬����i(A, n), ��i(A, m)����U��
6) ��GA��GA�䣬Tp��Tp�䣬Ts=Ts����Tp #WTp�䣬����i(A, n), ��i(A, m)����U��
7) ��GA��GA�䣬Tp��Tp�䣬Tp #WTp�䣬Ts��Ts����Ts #WTs�䣬����i(A, n), ��i(A, m)����U��
8) ��GA��GA�䣬Tp��Tp�䣬Tp #WTp�䣬Ts��Ts�䣬Ts=Tss�䣬��Tss=Ts�䣬����i(A, n), ��i(A, m)����U��
9) ��GA��GA�䣬Ts��Ts�䣬Ts #WTs�䣬Tp��Tp�䣬Tp=Tpp�䣬��Tpp=Tp�䣬����i(A, n), ��i(A, m)����U��
1.3 ������ѡ��ṹʶ������� ������ѡ��ṹ�ǹ���������һ�ֳ���������ṹ��ͨ������·�����ѡ��ṹ�ɼ�����������ϵ���¡�������ѭ���ṹ��Ӱ�죬������ѡ��ṹ�ɷ�Ϊ��ͼ 2��ʾ�������ࣺ�ֲ�������ѡ��ȫ�ַ�����ѡ��Ͳ��з�����ѡ����ͼ 2(a)�У����ڻE��F��ѡ��ȡ������֮ǰ�ԻB��C��ѡ��2��ѡ�������ͬһ�����л�У�ѡ��Ľ���������յ������O����Ӱ���������������˳�Ϊ�ֲ�������ѡ����ͼ 2(b)�У����ڻD��E��ѡ��ȡ���ڶ��ڻA��B��ѡ����2��ѡ��ṹ������ͬһ���ṹ֮�£��������м�������ɸ������˳�Ϊȫ�ַ�����ѡ����ͼ 2(c)�У��������Ǽ���������������ԻD��G֮���������ϵ������ʱ���ڲ��й�ϵ�Ĵ��ڣ�����ڻB��D֮��ѡ����D����ᷢ������������F�������������������ͬ��ͼ 2(a)����Ϊ���з�����ѡ��
 |
| ͼ 2 ������ѡ��ṹ���� Fig. 2 Classification of non-free-choice constructs |
| ͼѡ�� |
ͨ�����Ϸ������Է��֣�������ѡ��ṹ�IJ�����������һ��ѡ��ṹ���µģ�ǰһ��ѡ��ṹ���ڻ��ѡ�����������˺���ij��ѡ��ṹ�Ľ�������Ϊ��̽��������ѡ��ṹ����Ҫ�������ѡ��ṹ֮��Ĺ�����̽������֮����ܴ��ڵ�������ϵ��Ϊ�˱������ȸ����������ϵ���塣
����4(���ϵ����)????��N=(P, T, F)Ϊһ��������ѭ���ṹ�Ĺ��������磬FΪ����ϵ��WΪ�������¼���־��TΪ����ϣ�����a, b��T��
1) a?Wb�����ҽ���a#Wb, ��?c��T, c��Wa, c��Wb��
2) a?Wb�����ҽ���a#Wb, ��?c��T, a��Wc, b��Wc��
3) a?Wb�����ҽ���a��Wb���������̹켣��={t1, t2, ��, tn}����i, j��{1, 2, ��, n}����i < j, ti=a, tj=b����������k��{i+1, ��, j-1}������tk��a��tk��b��?(tk?Wa or tk?Wa)��
���ڶ���4���ڲ�����ѭ���ṹ������£������������(?W)�жϹ�����WΪ�걸�¼���־��N=(P, T, F)=��(W)��Ϊ����ͳ�����㷨���¼���־W�����ھ�õ���WF-net����N����2��ѡ���ϵa#Wb, x#Wy����ѡ���ϵa#Wb��������x#Wy֮��
����1????��a?Wx��b?Wy��?(a?Wy��b?Wx), ��a?Wx��b?Wy��
����2????��?(a?Wx)��(a?Wy)��?(b?Wx)��?(b?Wy), a?Wx��b?Wy, ?(a?Wy)��?(b?Wx), ��a?Wx��b?Wy��
����3????��?(a?Wx)��?(a?Wy)��?(b?Wx)��?(b?Wy), ?p, t, p��, t��:a?Wp, b?Wt��x?Wp��, y?Wt�䣬��p?Wp���t?Wt���?(p?Wt��)��?(t?Wp��), ��a?Wx��b?Wy��
������3�������У�����1���ȫ�ַ�����ѡ��ṹ����ͼ 3(a)��ʾ��ѡ��ṹa#Wb, x#Wy��ʱ���ϴ�����һ����ǰ��˳������a?Wx��b?Wy���������¼���־ȴ������a?Wy��b?Wx��˵������x, y��ѡ����ѡ��ṹa#Wb�����������Ҫ������������ϵa?Wx��b?Wy(��ͼ 3(b))������2������3��Ծֲ��Ͳ��з�����ѡ��ṹ����ͼ 3(c)��(e)��ʾ��2��ѡ��ṹa#Wb, x#Wy��ʱ���ϲ�����ǰ��˳��4����ķ�������ȷ������ʱ����ѡ���ϵ֮��Ļ��������a?Wx��b?Wy����?(a?Wy)��?(b?Wx)����ʱ2��ѡ��ṹ��Ϊ������ѡ�a��x���벢�з��������b��y���з�������˻a��x��b��y�֮����ڼ��������ϵ(��ͼ 3(d))����������a?Wx��b?Wy������2�����й�ϵ�ĺ���������лp, t, p��, t��:a?Wp, b?Wt, x?Wp��, y?Wt�䣬�������2�е�������p?Wp���t?Wt���?(p?Wt��)��?(t?Wp��)����ͬ����a?Wx��b?Wy��
 |
| ͼ 3 ��������жϹ��� Fig. 3 Rules to judge indirect relations |
| ͼѡ�� |
1.4 ͳ�����㷨 ���ھ�����ϵ���㷨Ҫ���¼���־�в�����������ͬʱҪ���¼���־�걸�����������������������������£��걸�¼���־������һ�����Դﵽ�����������¼���־�е�����ȴ��Ϊһ�������Ƶĸ������ء�Ϊ�˽�������ĸ��ţ���****��������㷨���Ŵ��㷨�Ƚ����㷨��������������������Ϊ�����㷨�Ļ������ӣ����ܸ÷������������������нϺõ�Ч��������ȴ���ڱ��졢����������ർ���㷨����ʱ��ϳ����㷨Ч�ʽϵ͡����������ͳ�����㷨�����˸��ʼ����˼��������������������㷨ȷ�ʣ�ͬʱ�㷨������ʱ��Ҳ����ά���ڽϵ͵�ˮƽ����������Ļ���ͳ�����㷨�Ĺ����ھ���巽����ͼ 4��ʾ��
 |
| ͼ 4 ����ͳ�����㷨�Ĺ����ھ��� Fig. 4 Steps of process mining based on statistical ��-algorithm |
| ͼѡ�� |
���������ͳ�����㷨�Ի��Ϊ��λ��ͨ��ÿ2���֮��Ļ��ϵ��һ�����������������������л�����ع�ϵ�����ȸ�����ԵĶ��塣
����5(���)????��������һ���¼���־W�����������̹켣��i={��, Ti, Ti+1, ��}?W(i=1, 2, ��)�����̹켣�е�Ԫ�ذ���ִ��ʱ����Ⱥ�˳�����У�����(Activities Couple��AC)�ɶ������£�
���{
FA����1�������(Ti)��
SA����2�������(Ti+1)��
f���������ʣ�
R�����ϵ=˳���ϵ(Ĭ��)
}
�����һ�����ж�����ԵĽṹ�塣
����6(ͬǰ���)????����������AC(A, B)��������һ����Ժ�������ͬ�ĵ�1���A����2���ȴ����ͬ�����֮ΪAC(A, B)��ͬǰ��ԣ�����#AC(A, B)��
����7(ת�û��)????����������AC(A, B)��������1����Եĵ�1����������ĵ�2�������2����������ĵ�1��������֮ΪAC(A, B)��ת�û�ԣ�����-AC(A, B)��
����еķ�������f���ݸû�����¼���־�еij��ִ�������õ������ڻ��AC(Ti, Ti+1)�ĸ��ʣ�
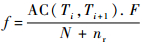 |
ʽ�У�f=AC(Ti, Ti+1).F��ʾ�û�Եij��ִ�������Ҫ���������¼���־��ã�NΪ���̹켣����nr=nr(Ti)+nr(Ti+1)Ϊ�Ti�ͻTi+1���������Ŀ�ܺ͡�
�ڼ����Ը���֮�����ڴ˻����Ͻ�һ���б��ԵĻ��ϵR�������㷨������ͼ 5��ʾ��
 |
| ͼ 5 ͳ�����㷨�㷨���� Fig. 5 Steps of statistical ��-algorithm |
| ͼѡ�� |
����1????������Թ�ϵ�б𡣱��Ķ��ڻ��ϵ���б�����ÿ����ԵĹ�ϵ֮�ϣ������ڵ�����ԵĹ�ϵ�б����ǻ��ھ������㷨�е��б������ԸĽ��������㷨���¡�
���룺��Լ���Array(AC)��������ˮƽ����
��������»��ϵ��Ļ�Լ��ϡ�
Foreach(AC(a, b) in Array(AC))
??If(AC(a, b).F < ��){
????AC(a, b)��������;
????Array(AC).Remove(AC(a, b))}
??Else{
????-AC(a, b)=AC(b, a)//ת�û��
????If(AC(b, a).F>��){
??????a��Wb}
????Else{
??????#AC(a, b)=AC(a, c)//ͬǰ���
??????If(AC(a, c).F < ��){
????????a��Wb}
??????Else{
????????a>Wb; a>Wc
????????If(AC(b, c).F>�� & & AC(c, b).F>��){
??????????b��Wc}
????????Else{
??????????b#Wc
????????If(AC(x, b).F>�� & & AC(x, c).F>��){
??????????b?Wc}
??????????If(AC(b, y).F>�� & & AC(c, y).F>��){
????????????b?Wc}
????}}}
}
����2????�ֱ��������ϵʶ���ڵõ��˵�����Թ�ϵ֮����Ҫ����Լ�Ĺ�ϵ���������Եõ�������Ĺ�ϵ����������������ϵ���Ϲ���
1) �����ϵ�Ĵ����ԣ�����a��Wb��b��Wc����a��Wc��
2) ���й�ϵ�IJ�ȷ���ԣ���a��Wb��b��Wcʱ������a��Wc����a��Wb��Wc����a#Wc����(a��Wb)#W(b��Wc)��2��ѡ���ϵ����ͬһ���Ļb(�����ظ��b)��
3) ѡ���ϵ�IJ�ȷ���ԣ���a#Wb��b#Wcʱ������a#Wc����a#Wb#Wc����a��Wc����(a#Wb)��W(b#Wc)��2��ѡ���ϵ����ͬһ���b(�����ظ��b)����������������ַ�����ѡ��ṹ����Ҫ��һ���б�
����3????����������ϵʶ������ɻֱ�ӹ�ϵ��ʶ��������ĵ���������Ҫ���¶�ѡ���ϵ����п��죬�ھ�ѡ���ϵ֮����ܴ��ڵļ��������ϵ�������ƻ��ϵ��
����4????���ɹ��������硣��ֱ�ӻ��ϵ�ͼ�ӻ��ϵ�������ϣ��õ����ϵ�������ϵ����ת��Ϊ��������ݴ����ɹ��������硣
2 ʵ��������֤ ���IJ��÷������ݺ���ʵ�����ֱ��������㷨������Ч����֤�����ڱ���������㷨���ڴ������ݵĻ���֮�ϣ����Ϊ��ʵ���������������ϵ�Ҫ�����Է������ݽ���ʵ��Ϊ������ʵ��������Ϊ�˽�һ�����㷨������֤���������ݵIJ���ԭ��������[20]�Ļ����ϼ��ԸĽ�����Ҫ��Ϊ����4�����裺
����1????ȷ�����̹켣���ȡ����̹켣��������Ӱ���㷨����Ч�ʵ�ָ�꣬��Ϊ�˾�����ó��ְ������ֲ�ͬ�Ļ��ϵ����Ҫ�켣�ﵽһ���ij��ȡ�Ϊ�˾�������֮���ì�ܣ����Ľ��������ݷ�Ϊ3�࣬�ֱ����ڶ��������������ѡ��ṹ��ͳ�����㷨������֤��
����2????ȷ���¼���־��ģ���¼���־��ģ��Ҫָ���̹켣����Ŀ������Ŀ��Ҫ��֤�㹻���������ȷ���¼���־���걸�ԡ����Ŀ���5���¼���־��ģ��200��400��600��800��1 000�����̹켣��
����3????ȷ��������ģ������������Ҫ��Ϊ5�֣���ɾ�����̹켣��ij������ڵ������̹켣��ij2�����������滻���̹켣�е�ij���������������̹켣����һ������������Ϊ�������������������滻���еĻ��������ģ��������[20]�еı���������������һ�������ɳ����켣���ȵ�1/3�����Ľ�������ģ��Ҫ��Ϊ5%��10%��20% 3�ֹ�ģ���Լ�ⲻͬ�����ͳ�����㷨���������Ŀ������ԡ�
����4????ȷ���ִ�е����ȶȡ�Ϊ�˵õ�������ѡ��ṹ�����Ľ���ѡ��ṹ�еĻ��Ϊ����ִ�����ȶȣ����ȶ�Խ�ߣ�ѡ��ṹ�иû�ķ�������Խ�ߡ�ִ�����ȶȵȼ�����Ϊ����4�֣�
1) Level1�������ȼ������л��ͬ����ִ�����ȶȣ���Ϊ0.5��
2) Level2�������ȼ����ִ�����ȶ���0.4~0.6֮�䡣
3) Level3�������ȼ����ִ�����ȶ���0.25~0.75֮�䡣
4) Level4�������ȼ����ִ�����ȶ���0.01~0.09֮�䡣
2.1 ����ʵ�����㷨���ܷ��� ����Ϊ�˶����֤��������㷨����Ч�ԣ���ʵ���Ϊ3�����֣������ʶ���㷨��֤ʵ�顢ͳ�����㷨��֤ʵ��ͷ�����ѡ��ṹʶ���㷨��֤ʵ�顣3��ʵ���и��ԵIJ��ص㣬��˶���ʵ�����ݵİ���ͬ����������
2.1.1 �����ʶ���㷨����֤ʵ�� ���������ʶ������ͳ�����㷨֮ǰ������������ʶ������ʱ�����ǻִ�е����ȶȵȼ���ͬʱΪ�˱�֤����������������������ţ���������Ҳֻѡ�����͢ݣ�������ģ����5%��10%��20% 3��������ʵ�飬ʵ�����ݰ������� 3��ʾ����ʵ�������ָ����3����ʶ����(�Ƿ���ȷ��ÿһ�������)��ȷ��(��������ظ��ʶ��ȷ��)������Ч��(�㷨����ʱ��)����ʵ��ĶԱ��㷨ΪHerbst��Karagiannis[6]����������ʶ���㷨��
�� 3 �����ʶ���㷨��֤ʵ�����ݰ��� Table 3 Experimental data arrangement for cognominal activity identification algorithm verification
| ���ݱ�� | ���̹켣���� | �¼���־��ģ | �������� | ������ģ/% | ���ȶȵȼ� |
| C1 | 22 | 200 | �� | 5 | Level1 |
| C2 | 22 | 200 | �� | 10 | Level1 |
| C3 | 22 | 200 | �� | 20 | Level1 |
| C4 | 42 | 200 | �� | 5 | Level1 |
| C5 | 42 | 200 | �� | 10 | Level1 |
| C6 | 42 | 200 | �� | 20 | Level1 |
��ѡ��
�õ���ʵ�������� 4��ʾ��2���㷨��ʶ���ʺ�ȷ����һ�£������������������������Ĺ�ϵ����������2������û���κβ��졣������ʱ���ϣ�����������㷨Ҫ��������[6]�㷨����Ϊ�����������ʶ��ʱ���Ի����Ϊ��С��λ���������㷨�����ͱȽϵ����ݣ��㷨ʱ���������Լ��١�
�� 4 �����ʶ���㷨�Ա�ʵ���� Table 4 Comparison of experimental results of cognominal activity identification algorithm
| ���ݱ�� | ��������� | �����㷨 | ����[6]�㷨 | |||||
| ʶ����/% | ȷ��/% | ����ʱ��/ms | ʶ����/% | ȷ��/% | ����ʱ��/ms | |||
| C1 | 2�� | 100 | 100 | 10.12 | 100 | 100 | 15.12 | |
| C2 | 3�� | 100 | 100 | 10.14 | 100 | 100 | 15.36 | |
| C3 | 5�� | 100 | 100 | 10.80 | 100 | 100 | 15.66 | |
| C4 | 3�� | 100 | 100 | 21.33 | 100 | 100 | 30.54 | |
| C5 | 5�� | 100 | 100 | 21.35 | 100 | 100 | 30.87 | |
| C6 | 9�� | 100 | 100 | 21.55 | 100 | 100 | 31.03 | |
��ѡ��
2.1.2 ͳ�����㷨����֤ʵ�� ���ڷ�����ѡ��ṹʶ������ͳ�����㷨֮����У���˱�����ʱ�����Ƿ�����ѡ��ṹ��Ӱ�죬���ȶȵȼ�ͳһ����ΪLevel1������ͳ�����㷨�������ʶ��Ļ���֮�ϣ��������������������Ϊ��~�ܡ���Ҫ���ǵ�ʵ������Ϊ�¼���־��ģ��������ģ����һ������ˮƽ����һ������ˮƽ��ʵ�飬����ʵ�����ݰ������� 5��ʾ����ʵ��ĺ���ָ����3����������g(��������������2/3��Ϊ�㷨ѵ����������ʣ�µ�1/3���ݽ�����ϣ�������g=Nd/Nm+noise��NdΪ��������л��Ŀ��NmΪ�㷨�õ�ģ���еĻ��Ŀ��noise��ʾ������ģ��g��ֵԽ�ӽ�1Խ�ã�g��ֵ����1��ʾ�㷨�õ���ģ�����������࣬g��ֵ̫С�����㷨����©�Ļ̫��)��ȷ��a(���ϵȷ��)������ʱ��t���ò��ֵĶԱ��㷨Ϊ�������㷨[9]�����ڱ�������Ⱥ�㷨�Ĺ����ھ��㷨(HAC-PSO)[16]��
�� 5 ͳ�����㷨��֤ʵ�����ݰ��� Table 5 Experimental data arrangement for statistical ��-algorithm verification
| ���ݱ�� | ���̹켣���� | �¼���־��ģ | �������� | ������ģ/% | ���ȶȵȼ� |
| S1~S5 | 42 | 200~1 000 | ��~�� | 5 | Level1 |
| S6~S10 | 42 | 200~1 000 | ��~�� | 10 | Level1 |
| S11~S15 | 42 | 200~1 000 | ��~�� | 20 | Level1 |
��ѡ��
ʵ�������� 6��ʾ��Ϊ�˷ֱ�Ƚ��¼���־��ģ��������ģ�����ս����Ӱ�죬���IJ��ÿ��Ʊ����ķ����ֱ���2�����ض�3������ָ���Ӱ�졣ͼ 6Ϊ3���㷨��������ģͬ��Ϊ5%������£������ԡ�ȷ�ʺ�����ʱ��3��ָ��ĶԱ���������Կ�������������ģ��ͬ������£�ͳ�����㷨��HAC-PSO�ķ����Ժ�ȷ�ʱ��ֲ�࣬���߶��DZȽϽӽ�100%�����������㷨�ڷ������ϳ��������Եij���100%������˵���ܵ��������Ľϴ�Ӱ�죬ͬ���������㷨��ȷ��Ҳ�ǵ�������2���㷨5%���ң�������������ģ�Ĵ�С��������ʱ���ϣ��������㷨��ͳ�����㷨��ά����һ���ϵ͵�ˮƽ������HAC-PSO������ʱ��ȴԶԶ������2���㷨����������ģΪ10%��15%ʱ�������ƵĽ����
�� 6 ͳ�����㷨�Ա�ʵ���� Table 6 Comparison of experimental results of statistical ��-algorithm
| ���ݱ�� | �����㷨(��=0.05) | �������㷨[9] | HAC-PSO[16] | ||||||||
| ������/% | ȷ��/% | ����ʱ��/ms | ������/% | ȷ��/% | ����ʱ��/ms | ������/% | ȷ��/% | ����ʱ��/ms | |||
| S1 | 99.10 | 97.98 | 3 350 | 105.00 | 92.98 | 2 289 | 99.65 | 98.56 | 12 651 | ||
| S2 | 99.16 | 98.88 | 5 830 | 104.90 | 93.86 | 4 820 | 99.58 | 98.96 | 33 624 | ||
| S3 | 99.52 | 98.82 | 7316 | 104.88 | 93.82 | 9 213 | 99.58 | 99.19 | 75 623 | ||
| S4 | 99.36 | 99.25 | 9 833 | 104.95 | 94.22 | 15 632 | 99.69 | 99.69 | 136 362 | ||
| S5 | 99.88 | 99.65 | 11 369 | 104.36 | 94.65 | 30 205 | 99.78 | 99.96 | 206 534 | ||
| S6 | 101.02 | 97.23 | 4 069 | 111.02 | 86.88 | 2 441 | 99.16 | 98.03 | 12 543 | ||
| S7 | 100.56 | 97.79 | 6 151 | 110.56 | 87.25 | 4 922 | 99.23 | 98.15 | 34 123 | ||
| S8 | 100.23 | 98.56 | 8 536 | 110.23 | 88.36 | 9 365 | 99.26 | 98.45 | 76 245 | ||
| S9 | 100.20 | 98.33 | 10 623 | 110.20 | 89.12 | 15 664 | 99.32 | 98.32 | 132 013 | ||
| S10 | 99.93 | 99.21 | 12 988 | 109.93 | 89.35 | 30 157 | 99.49 | 98.98 | 214 756 | ||
| S11 | 100.98 | 97.56 | 4 419 | 114.98 | 82.36 | 2 674 | 98.52 | 97.23 | 13 025 | ||
| S12 | 100.56 | 97.88 | 6 496 | 114.56 | 83.65 | 5 155 | 98.62 | 97.53 | 34 216 | ||
| S13 | 100.23 | 98.65 | 9 441 | 114.43 | 82.98 | 9 998 | 99.15 | 98.68 | 77 487 | ||
| S14 | 100.59 | 98.98 | 14 635 | 115.09 | 84.98 | 17 897 | 99.48 | 99.32 | 140 259 | ||
| S15 | 100.20 | 99.52 | 19 062 | 114.35 | 83.66 | 32 390 | 99.60 | 99.56 | 219 874 | ||
��ѡ��
 |
| ͼ 6 ��ͬ������ģ�µ��㷨����Ա� Fig. 6 Comparison of algorithm results under the same noise scale |
| ͼѡ�� |
ͼ 7�������¼���־��ģΪ600��������ģ��ͬ����£������ԡ�ȷ�ʺ�����ʱ��3��ָ��ĶԱ���������Կ�������������ģ���ӵ�����£�ͳ�����㷨��HAC-PSO�����ڷ����Ժ�ȷ���ϱ��ֽϺõ�ˮƽ�����������㷨����������ģ�����ӣ������Կ������ӣ����ҳ���100%��ȷ��ֱ���½����ɼ��������㷨��������Ӱ��ʮ�ִ�����������ģ���ӣ�ͳ�����㷨����ʱ��Ҳ��С�����ӣ����������㷨��������ֲ��䣬HAC-PSO������ʱ��Զ����ǰ2���㷨��
 |
| ͼ 7 ��ͬ�¼���־��ģ�µ��㷨����Ա� Fig. 7 Comparison of algorithm results under the same event log scale |
| ͼѡ�� |
�ܽ���˵��ͳ�����㷨�ڷ����Ժ�ȷ����Ҫ�������ھ������㷨����HAC-PSO������ƽ���������㷨����ʱ����ȴ��������HAC-PSO�������뾭�����㷨��ƽ����������ߵ��ŵ㣬ʵ�����㷨�ĸ�ȷ�ʺ�Ч�ʡ�
2.1.3 ������ѡ��ṹʶ���㷨����֤ʵ�� ������ѡ��ṹ��ͳ�����㷨�Ļ����������������Ļ���֮�Ͻ��еģ�������ﲻ�ٿ����������㷨��Ӱ�졣Ϊ��ʹ������ѡ��ṹ���������㹻�ִ�����ȶȵȼ�ֱ������ΪLevel4������ʵ�����ݰ������� 7��ʾ�����㷨�ĺ���ָ����3����ʶ����(�Ƿ���ʶ��ÿһ��������ѡ��ṹ����������ʶ����Ŀ������ʶ����)��ȷ��(ʶ������ķ�����ѡ��ṹ�Ƿ�ȷ)�����������Ŀ(���������Ŀ���ٻᵼ�·�����ѡ��ṹ����©������ᵼ��ģ�������࣬����������Ч�ʵ͡���ȷ�ʺ�ʶ���ʴﵽ�ϸ�ˮƽʱ�����������ĿԽ��Խ��)������ʱ��(������ͳ�����㷨��ʱ��)�����㷨�ĶԱ��㷨Ϊ��++�㷨��
�� 7 ������ѡ��ṹʶ���㷨��֤ʵ�����ݰ��� Table 7 Experimental data arrangement for non-free-choice construct identification algorithm verification
| ���ݱ�� | ���̹켣���� | �¼���־��ģ | ���ȶȵȼ� |
| F1 | 50 | 600 | Level4 |
| F2 | 60 | 600 | Level4 |
| F3 | 70 | 600 | Level4 |
| F4 | 80 | 600 | Level4 |
| F5 | 90 | 600 | Level4 |
��ѡ��
ʵ�������� 8��ʾ�����Կ���������������㷨��ʶ������ż���������++�㷨����ȷ���ܴﵽ�Ϻõ�ˮƽ����2���㷨�ھ���ļ��������Ŀ��������++�㷨[12]�ھ������ļ������������2���㷨��ȷ�ʱ���ȴû�в��죬�ɼ���++�㷨�в�������������������ϵ��������ʱ�䷽�棬�����㷨�������++�㷨�������ơ��ۺ���������Ȼ�����㷨��ʶ�����ϱ��ֲ�����++�㷨�����Ǹ��㷨���ھ����ٵļ��������Ŀ�µõ�ͬ��ȷ�ʵĽ������˱����㷨ͬ�������㹻�ľ�������
�� 8 ������ѡ��ṹʶ���㷨�Ա�ʵ���� Table 8 Comparison of experimental results of non-free-choice construct identification algorithm
| ���ݱ�� | ������ѡ��ṹ���� | �����㷨 | ��++�㷨[12] | |||||||
| ʶ����Ŀ | ȷ��/% | ���������Ŀ | ����ʱ��/ms | ʶ����Ŀ | ȷ��/% | ���������Ŀ | ����ʱ��/ms | |||
| F1 | 5 | 5 | 100 | 14 | 1 025 | 5 | 100 | 20 | 1 562 | |
| F2 | 6 | 6 | 100 | 18 | 1 365 | 6 | 100 | 32 | 1 845 | |
| F3 | 7 | 7 | 100 | 20 | 1 852 | 7 | 100 | 36 | 2 214 | |
| F4 | 8 | 7 | 100 | 22 | 1 955 | 8 | 100 | 42 | 2 456 | |
| F5 | 9 | 9 | 100 | 28 | 2 123 | 9 | 100 | 50 | 2 814 | |
��ѡ��
2.2 ��ʵ����ʵ������� ������ʵ�������������ɹ�ij����ҽԺ�ٴ�·��ϵͳ�в������¼���־������ѡ�ü�����β���¼���־��Ϊʵ�����ݣ��� 9�����ò����¼���־������Ļ�����Ϣ����ʵ����ʵ����Ҫѡȡ���º���ָ�꣺�����ʶ����cr�������ȷ��ca��ģ�ͷ�����mg��ģ��ȷ��ma��������ѡ��ṹʶ����fr��������ѡ��ṹȷ��fa������ʱ��t��ʵ��Ա��㷨Ϊ��++�㷨[12]�������Ŵ��㷨�Ĺ����ھ�(GA)[15]������[6]�㷨��HAC-PSO[16]��
�� 9 ������β�ײ����¼���־��Ϣ Table 9 Description for event logs of acute appendicitis
| �������� | ���̹켣���� | �¼���־��ģ | ��������� | �������� | ������ģ/% | ������ѡ��ṹ���� |
| ������� | 53 | 200 | 10�� | ��~�� | 6 | 2 |
��ѡ��
ʵ�������� 10��ʾ�����Կ���������������㷨�����������ƣ��ٿ��Դ������������ṹ�����������������ѡ��ṹ�ȣ�����ʶ���ʺ�ȷ�����������㷨��Ȳ�û��ʲô��ࣻ���ڱ�֤ȷ�ʵ������ͬ����֤������Ч�ʣ�����ʱ��Զ����GA��HAC-PSO��
�� 10 ��ʵ����ʵ���� Table 10 Experimental results for real data
| �㷨 | �����ʶ����/% | �����ȷ��/% | ģ�ͷ�����/% | ģ��ȷ��/% | ������ѡ��ṹʶ����/% | ������ѡ��ṹȷ��/% | ����ʱ��/ms |
| �����㷨 | 100 | 100 | 100.56 | 99.36 | 100 | 100 | 4 036 |
| ��++�㷨[12] | 106.88 | 94.50 | 100 | 100 | 3 855 | ||
| GA[15] | 99.89 | 99.36 | 100 | 100 | 39 558 | ||
| ����[6]�㷨 | 100 | 100 | 103.33 | 89.89 | 2 011 | ||
| HAC-PSO[16] | 98.78 | 96.85 | 50 | 50 | 10 254 |
��ѡ��
3 ���� ���������һ�ֻ���ͳ�����㷨�Ĺ����ھ��㷨���ӹ������¼���־���ھ����õ���Ϣ��ʵ���˹�����ģ�͵Ľ�����
1) �ھ�����ϵ���㷨�Ļ����������������ʶ���봦���������ù�����Ϊ���㷨��Ԥ�������������������Ի������ϵʶ��ĸ��š�
2) ����ͳ��ѧ��˼���Ͼ������㷨�Ĺ����γ�ͳ�����㷨���������¼���־�������ĸ������⣬ͬʱ��֤���㷨�ϸߵ�����Ч�ʡ�
3) �����һ���µķ�����ѡ��ṹʶ���㷨���ڱ�֤�˽ϸߵ�ʶ���ʺ�ȷ�ʵ�����£������ٵ����Ӽ��������ϵ������������Ļ������ϵ��
ͨ������ʵ�����ʵ����ʵ�飬��֤�˱����㷨����Ч�Ժ���Խ�ԡ�����������Ҫ�Ƿ�����ѡ��ṹʶ���ʵĽ�һ������Լ����ػ���ھ�һ�����Ƹ��㷨��
�����
| [1] | ������. ���ڹ��������Ĺ����ھ��㷨�о�[D]. ����: �廪��ѧ, 2007. WEN L J. Studies on algorithms for process mining based on WF-net[D]. Beijing: Tsinghua University, 2007(in Chinese).http://cdmd.cnki.com.cn/Article/CDMD-10003-2008088148.htm |
| [2] | ������. �����ھ���о���״����������[J].ϵͳ����ѧ��, 2007, 19(s1): 275�C280. ZENG Q T. A survey of research issues and approaches on process mining[J].Journal of System Simulation, 2007, 19(s1): 275�C280.(in Chinese) |
| [3] | COOK J E, WOLF A L. Automating process discovery through event-data analysis[C]//Proceedings of the 17th International Conference on Software Engineering. New York: ACM, 1995: 73-82. |
| [4] | AGRAWAL R, GUNOPULOS D, LEYMANN F. Mining process models from workflow logs[C]//International Conference on Extending Database Technology. Berlin: Springer, 1998: 467-483. |
| [5] | PINTER S S, GOLANI M. Discovering workflow models from activities' lifespans[J].Computers in Industry, 2004, 53(3): 283�C296.DOI:10.1016/j.compind.2003.10.004 |
| [6] | HERBST J, KARAGIANNIS D. Workflow mining with InWoLvE[J].Computers in Industry, 2004, 53(3): 245�C264.DOI:10.1016/j.compind.2003.10.002 |
| [7] | SCHIMM G. Mining exact models of concurrent workflows[J].Computers in Industry, 2004, 53(3): 265�C281.DOI:10.1016/j.compind.2003.10.003 |
| [8] | GRECO G, GUZZO A, PONTIERI L, et al. Discovering expre-ssive process models by clustering log traces[J].IEEE Transactions on Knowledge and Data Engineering, 2006, 18(8): 1010�C1027.DOI:10.1109/TKDE.2006.123 |
| [9] | VAN DER AALST W M P, WEIJTERS T, MARUSTER L. Workflow mining:Discovering process models from event logs[J].IEEE Transactions on Knowledge and Data Engineering, 2004, 16(9): 1128�C1142.DOI:10.1109/TKDE.2004.47 |
| [10] | DEMEDEIROS A K A, DONGEN B F, VAN DER AALST W M P, et al. Process mining for ubiquitous mobile systems: An overview and a concrete algorithm[C]//International Workshop on Ubiquitous Mobile Information and Collaboration Systems. Berlin: Springer, 2004: 151-165. |
| [11] | WEN L, WANG J, VAN DER AALST W M P, et al. A novel approach for process mining based on event types[J].Journal of Intelligent Information Systems, 2009, 32(2): 163�C190.DOI:10.1007/s10844-007-0052-1 |
| [12] | WEN L, VAN DER AALST W M P, WANG J, et al. Mining process models with non-free-choice constructs[J].Data Mi-ning and Knowledge Discovery, 2007, 15(2): 145�C180.DOI:10.1007/s10618-007-0065-y |
| [13] | WEN L, WANG J, SUN J. Mining invisible tasks from event logs[M]//LI Q, FENG L, PEI J, et al. Advances in data and web management. Berlin: Springer, 2007: 358-365. |
| [14] | LI J, LIU D, YANG B. Process mining: Extending ��-algorithm to mine duplicate tasks in process logs[M]//SUI Q, YANG D, WANG T. Advances in web and network technologies, and information management. Berlin: Springer, 2007: 396-407. |
| [15] | DEMEDEIROS A K A, WEIJTERS A J M M, VAN DER AALST W M P. Using genetic algorithms to mine process models: Representation, operators and results[R]. Eindhoven: Eindhoven University of Technology, 2005. |
| [16] | ����, �����, л����. ���ڱ�������Ⱥ�㷨�Ĺ����ھ�[J].�������������ϵͳ, 2012, 18(3): 634�C638. LI L, LI H Q, XIE S L. Process mining based on mutation-particle swarm optimization[J].Computer Integrated Manufacturing System, 2012, 18(3): 634�C638.(in Chinese) |
| [17] | ���, ��ǿ. ����ģ���˻��㷨�Ĺ����ھ��о�[J].����ѧ��, 2009, 37(s1): 135�C139. SONG W, LIU Q. Business process mining based on simulated annealing[J].Acta Electronica Sinica, 2009, 37(s1): 135�C139.(in Chinese) |
| [18] | ����, ̷�İ�, ��С��. һ�ֻ���ʱ����Ϊ��������Эͬ�ع��㷨[J].������������ѧ, 2017, 39(5): 897�C903. HUANG L, TAN W A, XU X Y. Cooperative streaming process reengineering based on sequential behaviors[J].Computer Engineering & Science, 2017, 39(5): 897�C903.(in Chinese) |
| [19] | DEMEDEIROS A K A, DONGEN B F, VAN DER AALST W M P, et al. Process mining: Extending the ��-algorithm to mine short loops[R]. Eindhoven: Eindhoven University of Technology, 2004. |
| [20] | VAN DER AALST W M P, DONGEN B F, HERBST J, et al. Workflow mining:A survey of issues and approaches[J].Data & Knowledge Engineering, 2003, 47(2): 237�C267. |
