����״̬����(Echo State Network, ESN)��һ�ֻ��ڴ����ؼ���ģ�͵����͵ݹ�������[4]���䴢�������ɶ�����ѵ�����̣��ڲ���Ԫ���ϡ�����ӣ�ֻ��Դ��������Ȩֵ�������Իع鷽������ѵ����ESN����ѵ���㷨�����ʵ�֣����ܻ��ȫ�����ŵ����Ȩֵ���ڷ�����Ԥ������������ѧ����Ĺ㷺��ע�����ѵõ��ɹ�Ӧ��[5-8]������ģʽʶ���������Ӧ���о���������[9-10]��
��ȻESN��չDZ����������һЩ���ۺ�ʵ�������д���������ڴ��������ɵ�����ԣ���������ģ��������������ⲻ��أ��������ص���Ӧ���������������������Ҫ��Ŀǰ�йش������Ż����о���Ҫ�����ڸı���Ԫ����[5]���Ľ��������˽ṹ[11]���Ż��������[12]�ȷ��档ͬʱ��ESN��ѵ���㷨�������죬Ϊ����ģ��ģ�����****ͨ���Ӽ�ѡ��[13]����������ڵ㣬�������ֻ����ݶȵķ���Ч�ʲ�����[14]�������õ����Ž������������һ����Ч������ѡ�������ܹ��ڼ������Ȩֵ��ͬʱ����ģ�͵ĸ��ӳ̶ȣ����****�����˶�������ϡ��ģ�͵��о�[15-18]��ȡ�������õ�Ч�����ڼ�����ܵ�ͬʱ����һ�������ģ�͵Ŀɽ����ԡ�
�������Ϸ��������������һ�ֻ���L1/2�������ĸĽ�ESN��������Ӧ���ڹ�����������С�ͨ�������Ի��ƶԴ����ؽ����Ż�������BCM����(Bienenstock-Cooper-Munro rule)���д���������Ȩ����Ԥѵ�����������������صĶ�̬��Ӧ���ܡ������Ȩֵ����ѵ����������У���L1/2����������Ŀ�꺯���ͷ�������иĽ�ʹ������㸽���⻬���Կ˷�������ֵ�����⣬ͨ������ֵ���������ģ�͵������̡����������ģ����ĩ�Ƶ��״�ͻ��ص�̨�Ĺ��������ȡ�������õ�Ӧ��Ч�������нϸߵ�ȷ�ʡ�
1 ����ESN�ķ������ԭ�� ��ͳESNģ�ͽṹ��ͼ 1��ʾ��ͼ�У�u(n)��RL��x(n)��RN��y(n)��RM�ֱ�Ϊnʱ�̵������źš�״̬���������������ESN��״̬����[19]Ϊ
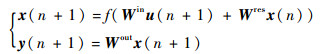 | (1) |
 |
| ͼ 1 ESNģ�ͽṹ Fig. 1 Architecture of ESN model |
| ͼѡ�� |
ʽ�У�Win��RN��L��Wres��RN��N��Wout��RM��N�ֱ�Ϊ����Ȩֵ������������Ȩ��������Ȩ����Win��Wres��ѵ��ǰ������ɲ����ֲ��䣬Wout��Ψһ��Ҫͨ��ѵ������õ���Ȩֵ����f(��)Ϊ�������ڲ���Ԫ�ļ���������ͨ��ΪS�ͺ�����
�ڷ��������У�����K��ѵ��������{u(n), y(n)}n=1K��u(n)Ϊ�������ݣ��������y(n)Ϊ���Ӧ������ʶ��������������������j���ʱ������Ӧ��j�������ԪΪ+1�����ԪΪ0����������Ļ���״̬���ԣ�Ϊ�����������ȶ�֮ǰ�����ʼ״̬�Ա�����Ӱ�죬ͨ����������ʼ����̬���̡���������������״̬����ΪK0��������״̬����X���������Y���Ա�ʾΪ
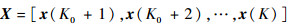 | (2) |
 | (3) |
ʽ�У�ʵ��ѵ������
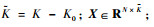

��ˣ������ѵ�����̼�Ϊ����������Իع����⣺
 | (4) |
�ع鷽�̿���ͨ��α�淨���õ�����Ŀ�꺯��L(��)�����Ȩֵ���ƾ���
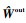
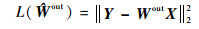 | (5) |
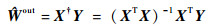 | (6) |
ʽ�У�������2ΪL2������X?Ϊ����X��α�档
α�淨��Ȼ�����ݣ������ȨֵΪ��ƫ���ƣ����Ǵ��ڹ�������⣬��ѵ������С�����������ȴ�ܴ��������ڼ�������л�����ϴ����Ӱ����ģ�͵ķ���������
2 ����������Ȩ�����Ż� �ڴ�ͳESNģ���У��������ڲ������ӹ�ϵ������Ȩ����Wres��Ϊ�������������ѵ�������б��ֲ��䣬Ȼ�������ص��ڲ��ṹ��ESN���༰Ԥ�����ܾ�����ҪӰ�졣����ͻ�������Ի����ܹ����������źŴ̼��Ļ�ı䴢�����ڲ�ͻ����ǿ�ȣ��ڿ�������������£������ź������̺��Ľṹ��Ϣ�����ڴ�����ѵ�������еõ�ѧϰ��ʵ������Ȩֵ����������������BCM����Դ������ڲ�����Ȩֵ���иĽ���
BCM����[20]��ѭHebbianѧϰԭ������ͨ��һ���൱���ȶ������ܵĻ�����ֵ������ͻ���ı仯����ֵ�ĸı��ܹ�������Ԫ�����ǿ���������һ���ҵ��ڵĿ��������ܹ����ƴ����ص�ѧϰ�ȶ��ԡ�BCM������ǰ��ͻ����ʱ���ƶ�ƽ��ֵ�����ã����ܹ�����ͻ����Ļ��������Ȩֵ�仯ˮƽ�ϸ�ʱ��������Ӧ�ĸı�������BCM�����£���ֵ��С��ͻ���仯���ʳʷ��ȹ�ϵ����ͻ���仯��������ʱ����ֵ���ڽ�Сֵ����֮��ֵҲ��Ӧ���ӣ���Ҳ����ζ��������ֵ������ͻ��Ч�ܸı�ķ���ԭ����ͼ 2��ʾ��
BCM�����ж��ֱ�ʽ�����IJ�������һ����ʽ��
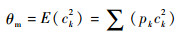 | (7) |
 | (8) |
 |
| ͼ 2 ͻ��Ȩֵ�������� Fig. 2 Synaptic weight modification rule |
| ͼѡ�� |
ʽ�У�xjΪͻ��ǰ��Ԫ���룻ckΪͻ������Ԫ��������������������Ԫ�ļ�Ȩ�ͣ���ck=

��ʽ(8)��ͼ 2���Կ�����BCM�������ʹ��Ԫ�����ض������γ�һ��ѡ������[21]������w=0ʱȨֵ��������ʱ��Ӧ��Ԫ���c=0��c=��m����������⣬������Ҳ��BCM�����һ����Ҫ�ص㣬���ĸĽ���ʽ(7)�У�1/��mΪѧϰ���ʣ����BCM������ѧϰ����Ϊ�㶨������ͬ��������ֲ��仯ʹ��Ӧ�����ı�ʱ����Ԫ����Ȩ�ؾͲ����ȶ�����չ��Ϊ��һ��ѡ�����ԡ�
����ESN������Ȩֵ������һ������塰���⡱�ص�ͨ�������ʽ������ͨ������BCM����Դ���������Ȩֵ��������֯�Ż���ʹ��Ȩֵ��ѵ������������������Ӧ�����ɸ������������ĸı��������Ӧ��������ǿ��ESNϵͳ����Ӧ�Ժ�����ѵ�������е������������������ʵ����߲�����������ȷ�ȵ�Ŀ�ġ�
3 ����L1/2�������Ļ���״̬���� 3.1 �⻬L1/2��������ģ�� Ϊ�˷���ͨ������С���˷����ֵIJ�̬���ʶ����⣬ƽ��ģ�͵���������뷺��������������ESN��Ŀ�꺯������������������������ѳ�Ϊ���ϡ���������Ч���ߣ���һ�����������ʽ��
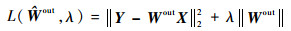 | (9) |
ʽ�У��Ⱥ��ұߵ�1��Ϊ������2��Ϊ���ͷ����Ϊ���ƺ����С�ijͷ�ϵ����
����ģ����һ��ϵ���������������óͷ���ƽ��ģ�͵�ƫ���뷽��������Ȩֵ��ֵ������ģ�������ȶ��ԡ�
�����ڸ��ƻ���ѧϰ����������ϵ�������֣�����L2����������ع�ģ��[15]����ESN����Ȩ��ѧϰ�㷨�еõ��㷺Ӧ�ã���Ϊһ�ֹ⻬���Ż�ģ�ͣ���ع��㷨�������������ʽ��Ȩֵ�⣺
 | (10) |
��ʽ(10)���Կ���������XTX�ĶԽ�Ԫ��������������������������Իع������г��ֲ������״̬������L2��������ģ�����õ�ϡ�軯�Ľ⣬����ͨ������ѡ��������ģ��ģ��
Ϊ��ʹʽ(9)�õ�ϡ�軯�Ľ⣬����L1��������ģ��[22]���о���ʼ�����С�ģ�ͳͷ���ѡ����L2�����ŵ��L1��������������������ѡ����������ϡ��⣬�����������ģ[23]������L1��������ģ�͵�Ŀ�꺯������㸽���ǹ⻬�Ҳ������������Ż���������ֱ��Ӧ�ã�������ģ�����ĸ��ӳ̶ȣ�����ģ�͵õ�������������ϡ��Ľ⣬������ijЩ����ѡ������¿��ܻ������һ��������[24]��
L1/2������[25]Ϊ���������ȡ������ѡ�������ṩ��һ���µ�˼·��ʵ��[26]�Ѿ�֤��L1/2��������ģ�ͽ����е�L1����ģ���и�ϡ��Ľ⣬��³���Ը��š���������L1/2�����ӵ��������ʣ�������ESN��ϣ���Ŀ�꺯��������L1/2�����
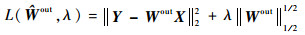 | (11) |
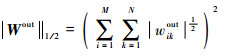 | (12) |
����L1/2����������㴦���ǹ⻬����������ֵѧϰѵ������������Ϊ�˷��������⣬�������Ч�ʣ�����ͨ��һ����㸽���Ĺ⻬����g(x)�ƽ�|x|�������Ľ�L1/2������Ľ�������Ŀ�꺯�����⻬����Ϊ
 | (13) |
 | (14) |
ʽ�У����Ȩ������g(Wout)��RM��N��aΪһ����С����������
3.2 L1/2-ESNģ�� ����L1/2��������ģ�͵���⣬��Ȼͨ���ظ�Ȩ�����㷨[26]���Խ���ת��ΪL1/2����ģ�ͽ�����⣬���Ǽ����ٶȼ����Ӷ���Ȼ�������롣��Ӧ����Ӳ��ֵ�����㷨������ֵ������[27]�ǽ��L1/2���������һ�ֿ��ٶ���Ч���ֶΣ���˱��Ľ�ϰ���ֵ��������Թ⻬L1/2-ESNģ�͵����Ȩֵ��������Ƶ���
��R0M��N={Z=(z1, z2, ��, zM)T, zi��0}����W��R0M��NΪʽ(11)��ʾ����ģ�͵Ľ⣬����W�����Ż�һ���������ɵ�
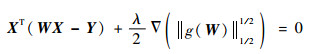 | (15) |
ʽ�У�?(������1/21/2)Ϊ��������ݶȡ�
��ʽ(15)����ͬ������������������Ϊ
 | (16) |
���?(������1/21/2)���ڣ����������R��, 1/2(��)=(I+?(������1/21/2))-1��������ʵ���������������ж��壬����
 | (17) |
����B��(W)=W+��XT(Y-WX)��������ģ�͵Ľ���Թ̶���ʾΪW=R�˦�,1/2(B��(W))����һ����������R��,1/2�Ķ��庯����
��
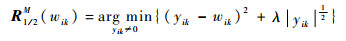 | (18) |
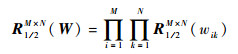 | (19) |
 | (20) |
 | (21) |
����[27]�Ѿ�֤������D1/2Mӳ�䵽R1/2M�����Ӵ��ڷ����ԶԽǻ�����ʽ���ؼ�Ϊ
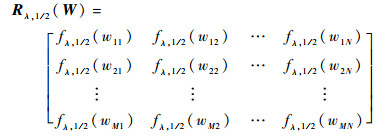 | (22) |
ʽ�У�
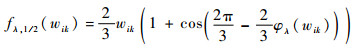 | (23) |
 | (24) |
��ʱ������С��Ŀ�꺯���Ľ�Ϊ
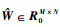
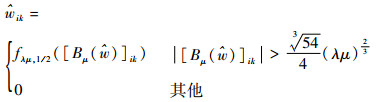 | (25) |
�����������⻬L1/2-ESNģ�͵����Ȩֵ����ͨ��ʽ(26)���е������£�
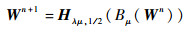 | (26) |
ʽ�У�H�˦�, 1/2Ϊ����ֵ�������ӡ���?Z��RM��N�������Ӷ���Ϊ
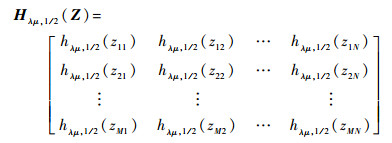 | (27) |
ʽ�У�
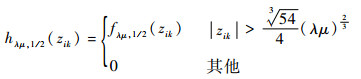 | (28) |
�㷨�IJ���ѡȡ��������֤���ɲμ�����[27-28]��
3.3 L1/2-PESNģ�� ���ESN������������ɵ�ϡ������ṹ����������BCM��������Ȩ�ؽ��е����Ը��ƴ����صĶ�̬���ܣ��������������ݵ���Ӧ�ԡ�ͬʱ������ѵ��ѧϰ�Σ�������Ŀ�꺯�������ӹ⻬L1/2�����������ʽ(11)��ʾ������L1/2-PESN(L1/2-Plasticity Echo State Network)ģ�͡��봫ͳESNģ����ȣ�L1/2-PESNģ���ڱ�֤���������Ļ����ϣ��ܹ�������ϡ��Ľ⣬�Ը������³����������ʵ�ֶ�ģ��ģ����Ч���ơ���ϰ���ֵ�����������Զ�ģ�ͽ��п�����Ч����⣬���������L1/2-PESNģ�ͽṹ��ͼ 3��ʾ����ѵ���㷨����ʵ�ֲ������£�
 |
| ͼ 3 L1/2-PESNģ�ͽṹ Fig. 3 Architecture of L1/2-PESN model |
| ͼѡ�� |
����1??�趨���������������������ع�ģ���װ뾶��ϡ��̶ȣ������ʼ������������ȨֵWin���ڲ�����ȨֵWres��
����2??����ȨֵWresԤѵ��������BCM�������Wres���ලѧϰѵ��������Wres���Ż������ض���������Ӧ�ԡ�
����3??����״̬�������������緽�̸���״̬������������̬���̵�Ԥ�����ݣ��γ�״̬����X��
����4??�������ȨֵWout�����ð���ֵ��������Ŀ�꺯���Ĺ⻬L1/2��������ģ�ͽ�����⣬�õ�Wout��
4 ���ص�̨�������ʵ������ ij�ͳ��̲�����ͨ�ŵ�̨���п�����ͨ�Ź��ܣ������ִ�����ս�����µĵؿպͿտ�ָ��ͨ�ţ�����վ����۵ؿճ��̲�������ͨ��ϵͳʵ�ּ��ݡ��õ�̨����ģ�黯��ƽṹ���������ͼ 4��ʾ��������ǰ���ģ�顢�����ջ�ģ�顢�������ջ�ģ�顢������ģ�顢ͬ��ģ�顢Ƶ�ʺϳ���ģ�顢����ģ�顢�������ģ�����ģ�鹲9��SRU(Shop Replaceable Unit)��ɡ�
 |
| ͼ 4 ����ͨ�ŵ�̨��� Fig. 4 Composition of airborne communication station |
| ͼѡ�� |
�ԡ���̨���ܿ��ơ���һ��������Ϊ�����Ե�̨���й���ģ�鶨λ���漰�IJ��Բ�������+5 V��ѹ(c1)��1553B���ߵ�ѹ(c2)��UUT���Ŷ˵�ѹ(c3)��UUT���Ŷ˵�ѹ(c4)��UUT���Ŷ˹���(c5)��UUT���Ŷ˹���(c6)�����ܴ��ڹ��ϵ�ģ��Ϊǰ���ģ��(d1)��������ģ��(d2)����ij����175��ʵ���������Ϊ�������� 1�����˾�����ȷ��ɢ��������IJ���������ݣ���1����ʾ��������0���͡�2���ֱ��ʾ�������������������
�� 1 ��ɢ�������Ĺ������� Table 1 Fault data after discrete processing
| ��� | ���Բ��� | ����ģ�� | |||||
| c1 | c2 | c3 | c4 | c5 | c6 | ||
| 1 | 2 | 0 | 1 | 1 | 1 | 1 | d1 |
| 2 | 1 | 2 | 1 | 2 | 1 | 2 | d2 |
| �� | �� | �� | �� | �� | �� | �� | �� |
| 174 | 1 | 1 | 1 | 1 | 1 | 2 | d2 |
| 175 | 1 | 2 | 1 | 0 | 1 | 1 | d1 |
��ѡ��
���ѡȡ�������ݵ�80%��Ϊѵ��������ʣ��20%Ϊ��������������ESN�����ع�ģN=50���װ뾶��max=0.75��ϡ��̶�D=20%�����뵥ԪL=8�������ԪM=3�����L1/2-PESNģ�ͣ���ѵ����ʼǰ������BCM�����Wres����50�ε�����Ԥѵ����Ϊ�ȽϷ���������Ч�������������ڹ����������㷺Ӧ�õ�BP������(Back Propagation Neural Network, BPNN)����ͳESN��BCM-ESN��L1/2-ESN�뱾�������L1/2-PESNģ�ͽ��жԱȣ�����BPNN���õ������3������ṹ������ڵ��������ý�����֤��ã����㼤���ΪS�ͺ������� 2�����˸����������ܶԱȽ����ѵ������ʱ�估��Ͻ��Ϊ�ֱ����100��ʵ���õ���ƽ��ֵ��
�� 2 ��Ϸ������ܶԱ� Table 2 Performance comparison of diagnostic methods
| ���� | ����������ʱ��/s | ѵ��ʱ��/s | �����ȷ��/% |
| BPNN | 43.76 | 79.6 | |
| ��ͳESN | 0.49 | 14.13 | 88.4 |
| BCM-ESN | 6.04 | 14.37 | 90.5 |
| L1/2-ESN | 0.36 | 16.78 | 91.2 |
| L1/2-PESN | 6.58 | 16.64 | 93.1 |
��ѡ��
���� 2��BPNN�봫ͳESN�Աȵ�ʵ�������Կ���������BPNN��ѵ�������������ٶȽ���������ͳESN��ѵ�����̵��Լ������˴�ͳ������������ֲ���С�����⣬ʹ�ô�ͳESN�������ȷ�ʽ�BPNN��������8.8%��ѵ��ʱ�������Ҳ�������ͣ���Ҳ֤���˴�ͳESN���б�BPNN������������ܱ��֡�
��һ���۲������֪��������BCM�����ESN��Wres�����Ż������ص�����ʱ�����Ը��ڴ�ͳESNģ�ͣ���������Ҫ��Wres����Ԥѵ������ѧϰ��ɵġ����ǹ�����ϵ���ȷ������һ����ߣ���Ҳ֤����BCM��Դ�������Ӧ�Ե��Ż��Ǻ�����Ч�ġ���һ���Ƚ�L1/2-ESN�봫ͳESN��֪�����ߵ�ѵ��ʱ���൱��L1/2-ESN����ESN�����Ը�һЩ����������������L1/2�����ͷ����Ч�����˹���ϣ�������ģ�͵�����ѡ�������������ȷ���Ͻϴ�ͳESN���˸���Խ�ı��֡�
�ۺ϶Աȸ����ģ�͵����ܱ��֣����������L1/2-PESNģ�;�����õ�Ч���������ȷ����ߣ���Ҳ֤���˱��ķ��������������ض�̬���ܺ�����ESN���������ϵ���Խ�ԡ�ͬ��ͳESN��ȣ���Ȼ������������Ҫһ����ʱ�����ģ�������һ������ѵ����ʼǰ�������еģ�����ⲿ�ֶ����ʱ�����Ķ�ʵ��Ӧ��Ӱ�첻��ʵ����������L1/2-PESNģ���ڻ��ص�̨ģ�鼶������������о��в�����Ӧ��ǰ����
5 ���� 1) ���������L1/2-PESNģ���ڴ��������ɹ�����ͨ������BCM����Դ���������Ȩֵ��������֯�Ż���ʹ��Ȩֵ��ѵ������������������Ӧ�����ɸ������������ĸı��������Ӧ�����������˴����صĶ�̬��Ӧ���ܺ�����ѵ�������е��������������
2) ������L1/2�����������ϡ���Ա��֣��Դ����ؽ�������Ч���������ѡ���ڿ��������ģ��ͬʱ������ģ�͵ķ������������ڻ��ص�̨�Ĺ������ʵ�������������ķ�����BPNN�ʹ�ͳESNģ�ͣ��������õ��ȶ��Լ����ߵ����ȷ�ʡ�
�����
| [1] | CHINE W, MELLIT A, LUGHI V, et al. A novel fault diagnosis technique for photovoltaic systems based on artificial neural networks[J].Renewable Energy, 2016, 90: 501�C512.DOI:10.1016/j.renene.2016.01.036 |
| [2] | UNAL M, ONAT M, DEMETGUL M, et al. Fault diagnosis of rolling bearings using a genetic algorithm optimized neural network[J].Measurement, 2014, 58: 187�C196.DOI:10.1016/j.measurement.2014.08.041 |
| [3] | SHATNAWI Y, AL-KHASSAWENEH M. Fault diagnosis in internal combustion engines using extension neural network[J].IEEE Transactions on Industrial Electronics, 2014, 61(3): 1434�C1443.DOI:10.1109/TIE.2013.2261033 |
| [4] | JAEGER H. The "echo state" approach to analysing and training recurrent neural networks-with an erratum note[R]. Bonn: German National Research Center for Information Technology GMD Technical Report, 2001. |
| [5] | LUN S X, YAO X S, QI H Y, et al. A novel model of leaky integrator echo state network for time-series prediction[J].Neurocomputing, 2015, 159: 58�C66. |
| [6] | VARSHNEY S, VERMA T. Half hourly electricity load prediction using echo state network[J].International Journal of Science and Research, 2014, 3(6): 885�C888. |
| [7] | MORANDO S, JEMEI S, HISSEL D, et al. ANOVA method applied to proton exchange membrane fuel cell ageing forecasting using an echo state network[J].Mathematics and Computers in Simulation, 2017, 131: 283�C294.DOI:10.1016/j.matcom.2015.06.009 |
| [8] | ������, ����. ��Ԫ����ʱ�����е����ӻ���״̬����Ԥ��ģ��[J].�Զ���ѧ��, 2015, 41(5): 1042�C1046. XU M L, HAN M. The model of factor echo state network prediction for multivariate chaotic time series[J].Acta Automatica Sinica, 2015, 41(5): 1042�C1046.(in Chinese) |
| [9] | ����, ����, ��ϲԪ. ������Ӧ�ػ���״̬���羲̬�����[J].����ѧ��, 2011, 39(3A): 14�C18. GUO J, LEI M, PENG X Y. Static classification method based on corresponding cluster echo state network[J].Acta Sinica, 2011, 39(3A): 14�C18.(in Chinese) |
| [10] | SCARDAPANE S, UNCINI A. Semi-supervised echo state networks for audio classification[J].Cognitive Computation, 2017, 9(1): 125�C135.DOI:10.1007/s12559-016-9439-z |
| [11] | SONG Q S, FENG Z R. Effects of connectivity structure of complex echo state network on its prediction performance for nonlinear time series[J].Neurocomputing, 2010, 73(10-12): 2177�C2185.DOI:10.1016/j.neucom.2010.01.015 |
| [12] | MARTIN C E, REGGIA J A. Fusing swarm intelligence and self-assembly for optimizing echo state networks[J].Computational Intelligence and Neuroscience, 2015, 2015(5-6): 642429. |
| [13] | DUTOIT X, SCHRAUWEN B, VAN CAMPENHOUT J, et al. Pruning and regularization in reservoir computing[J].Neurocomputing, 2009, 72(7): 1534�C1546. |
| [14] | KUMP P, BAI E W, CHAN K, et al. Variable selection via RIVAL(removing irrelevant variables amidst Lasso iterations) and its application to nuclear material detection[J].Automatica, 2012, 48(9): 2107�C2115.DOI:10.1016/j.automatica.2012.06.051 |
| [15] | SHI Z, HAN M. Support vector echo-state machine for chaotic time-series prediction[J].IEEE Transactions on Neural Networks, 2007, 18(2): 359�C372.DOI:10.1109/TNN.2006.885113 |
| [16] | ����ΰ, ��˫��, ������. p��������֧�������������㷨[J].�Զ���ѧ��, 2012, 38(1): 76�C87. LIU J W, LI S C, LUO X L. Classification algorithm of support vector machine via p-norm regularization[J].Acta Automatica Sinica, 2012, 38(1): 76�C87.(in Chinese) |
| [17] | ����, ��²�. ���������������Ҷ˹��ܵ�1����ELM�㷨[J].�Զ���ѧ��, 2011, 37(11): 1344�C1350. HAN M, LI D C. An norm 1 regularization term ELM algorithm based on surrogate function and Bayesian framework[J].Acta Automatica Sinica, 2011, 37(11): 1344�C1350.(in Chinese) |
| [18] | ZOU H, HASTIE T. Regularization and variable selection via the elastic net[J].Journal of the Royal Statistical Society, 2005, 67(2): 301�C320. |
| [19] | LUKO?EVI?IUS M, JAEGER H. Reservoir computing approaches to recurrent neural network training[J].Computer Science Review, 2009, 3(3): 127�C149.DOI:10.1016/j.cosrev.2009.03.005 |
| [20] | CASTELLANI G C, INTRATOR N, SHOUVAL H, et al. Solutions of the BCM learning rule in a network of lateral interacting nonlinear neurons[J].Network:Computation in Neural Systems, 1999, 10(2): 111�C121.DOI:10.1088/0954-898X_10_2_001 |
| [21] | LEFORT M, BONIFACE Y, GIRAU B. Self-organization of neural maps using a modulated BCM rule within a multimodal architecture[C]//Brain Inspired Cognitive Systems 2010. Berlin: Springer, 2010: 26-38. |
| [22] | TIBSHIRANI R. Regression shrinkage and selection via the lasso[J].Journal of the Royal Statistical Society, 1996, 58(1): 267�C288. |
| [23] | �����, ������, ������, ��. ��ѹ�����е����Ⱦ���ָ�:������Ӧ��[J].�Զ���ѧ��, 2013, 39(7): 981�C994. PENG Y G, SUO J L, DAI Q H, et al. From compressed sensing to low-rank matrix recovery:Theory and applications[J].Acta Automatica Sinica, 2013, 39(7): 981�C994.(in Chinese) |
| [24] | ZOU H. The adaptive lasso and its oracle properties[J].Journal of the American Statistical Association, 2006, 101(476): 1418�C1429.DOI:10.1198/016214506000000735 |
| [25] | XU Z, ZHANG H, WANG Y, et al. L 1/2 regularization[J].Science China Information Sciences, 2010, 53(6): 1159�C1169.DOI:10.1007/s11432-010-0090-0 |
| [26] | DAUBECHIES I, DEVORE R, FORNASIER M, et al. Iteratively reweighted least squares minimization for sparse recovery[J].Communications on Pure and Applied Mathematics, 2010, 63(1): 1�C38. |
| [27] | XU Z, CHANG X, XU F, et al. L1/2 regularization:A thresholding representation theory and a fast solver[J].IEEE Transactions on Neural Networks and Learning Systems, 2012, 23(7): 1013�C1027.DOI:10.1109/TNNLS.2012.2197412 |
| [28] | ZENG J, LIN S, WANG Y, et al. L1/2 regularization:Convergence of iterative half thresholding algorithm[J].IEEE Transactions on Signal Processing, 2014, 62(9): 2317�C2329.DOI:10.1109/TSP.2014.2309076 |
