在20世纪末,硬件演化(Evolvable Hardware,EHW) 技术的提出为提高电子系统的可靠性和实现故障修复提供了一种全新的途径。其具有自组织、自适应等特点,采用EHW技术实现故障电路自组织,从而保证电子系统正常工作。以上称为常规的基于EHW的电子电路故障自修复策略,但仍存在一些弊端。
1) 故障修复模式较为简单,故障修复类型有限,故障现场及时修复的能力受到了一定约束。如深空、深海等环境中的电子系统出现故障时,若不能实现故障现场及时修复,将直接影响系统正常运行,甚至造成整个系统瘫痪。当被测单元(Unit Under Test,UUT)出现故障时(UUT是可编程器件),需要将其隔离,再进行电路演化配置。在配置过程中,可能会因UUT进行电路配置使得整个电子系统停止运行,此时电子系统是否具有故障在线修复能力将显得格外重要。
2) 电路演化耗时较长。常规的基于EHW的故障修复策略需要对整个出现故障的电路系统进行演化,电路演化规模伴随着演化电路的输入输出端数量的增加而增长。当演化电路规模较大时,由于搜索空间大,成功搜索到预期目标电路的时间较长,甚至有在规定的时间内根本搜索不到预期目标电路的可能性,造成故障很难及时修复。
针对以上问题,前期工作中提出了基于EHW和补偿平衡技术(Reparation Balance Technology,RBT)的电子电路故障自修复策略[8]。采用了RBT技术,针对正在运行的电子系统出现的故障,能够快速演化出矫正电路,通过多路选择器(Multiplexer,MUX)的切换,实现故障现场、在线及时修复,从而克服了常规基于EHW的电子电路故障自修复策略中遇到的各种问题。
本文从故障自修复能力、故障修复时间、硬件资源消耗3个角度,对提出的基于EHW和RBT的电路故障自修复策略和常规的基于EHW的故障自修复策略的性能进行了对比分析,论证了所提出的基于EHW和RBT的电路故障自修复策略的有效性、优越性和可行性。
1 硬件演化基本原理 EHW技术是以演化算法(Evolutionary Algorithm,EA)为组合优化和全局搜索工具,通过模拟进化来获得具备预期功能的电路和系统结构[8-12]。将需要设计的电路(结构位串)、参数等作为演化算法的染色体编码,通过不断交叉、变异等演化操作,找到与电路预期输入输出特性一致的电路编码。利用EHW技术具有的良好的鲁棒性、自组织、自适应、自修复的优点,为故障自修复提供了技术保障[13-17]。
EHW公式可表示为:演化算法+可编程逻辑器件=硬件演化[8, 13-14, 17]。即:EAs+PLDs=EHW。
EHW演化过程如图 1所示。首先演化算法会初始化一段既定长度的结构位串编码010110011011101111011,其对应的电路如图 1(a)所示;在一定的约束条件和适应度评判函数的作用下,通过演化算法,结构位串编码进化成010110011011101110010,对应的电路是目标电路,如图 1(b)所示。从电路演变过程可以明显地看出,演化算法能从混沌无规则的结构位串编码按一定的规则找到符合目标电路的结构位串编码[8]。
 |
| 图 1 EHW基本原理 Fig. 1 Basic theory scheme of EHW |
| 图选项 |
2 新颖故障自修复策略模型建立 EHW技术是近年来新兴的技术,已被众多的研究机构和****所重视,设计了许多基于EHW的硬件系统。
国外的Lohn[15]、Gregory[16]、Pauline[17]、Chang[18]和James[19]等的研究成果阐述了整个电路演化系统包括软件和硬件两部分,软件主要实现电路编码、演化及译码,硬件主要实现对电路演化的具体结果进行执行和故障检测。国内武汉大学的朱继祥和李元香[20-21]、南京航空航天大学的姚睿和王友仁[22-24]、张强[25]等提出了多种硬件演化、容错、重构系统,这些系统都具有相同模块,它们包括用于电路演化的PC、UUT、故障检测模块等。
综合以上分析,可将常规的基于EHW的电子电路故障自修复通用模型用图 2表示。通用模型主要包括UUT、上位机、下位机、MUX和串口通信等模块。除串口通信模块外,其他模块都是自修复通用模型必要的组成部分。
 |
| 图 2 常规的基于EHW的故障自修复通用模型 Fig. 2 Universal model of general fault self-repaircircuit system based on EHW |
| 图选项 |
MUX指多路开关,即当UUT出现故障的时候,切断UUT与整个电路系统的连接,直至电路成功演化重新配置之后,恢复UUT与整个电路系统的连接。即形成三通的通路,便于信号(包括故障信号、无故障信号、补偿平衡信号)在FPGA、UUT、输入输出电路之间的互连。
此时,UUT需要是可编程器件,可为复杂可编程逻辑器件(Complex Programmable Logic Device,CPLD)/FPGA。上位机可以是个人计算机(Personal Computer,PC),也可以是最小系统,其能够运行演化算法,并能够配置演化出的数据。下位机需要和UUT相结合,主要实现对UUT电路的故障检测、分析,并根据故障信息实现对MUX开关控制。此时的下位机可以和UUT合并在一起,也可以与UUT相分离。现有的电子系统都具备BIT检测的功能,BIT检测模块可以融合在插件/电路系统(UUT)之中。
串口通信模块主要实现信号在模块之间的传递,串口通信只是信号传递的一种方式,也可以进行有线传输。
而在前期的研究中,提出了基于EHW和RBT的电子电路故障自修复策略[8],其通用模型如图 3所示。
 |
| 图 3 基于EHW和RBT的故障自修复通用模型 Fig. 3 Universal model of fault self-repair circuit systembased on EHW and RBT |
| 图选项 |
基于EHW和RBT的故障自修复策略,主要实现对UUT出现的故障信号进行矫正修复,不需要进行精确的故障定位分析,只需要对UUT的输入输出信号进行检测,进行故障分析,对不符合预期输入的输出组合进行矫正修复,详细的矫正修复原理见文献[8]。
从图 3可以看出,在常规的基于EHW的故障自修复模型的基础上,基于EHW和RBT的故障自修复通用模型只额外增加了用于产生矫正信号的FPGA,一些因额外增加FPGA而增加的布线,可以忽略。
3 故障自修复能力分析 分析故障自修复能力,主要包含故障修复机制和故障修复类型2个指标。
3.1 故障修复机制 在故障修复机制方面,常规的基于EHW的故障自修复策略的故障修复示意图如图 4所示。而基于EHW和RBT的故障自修复策略的故障修复示意图如图 5所示。
 |
| 图 4 常规的基于EHW的故障自修复机制 Fig. 4 Mechanism of general fault self-repair circuit system based on EHW |
| 图选项 |
 |
| 图 5 基于EHW和RBT的故障自修复机制 Fig. 5 Mechanism of fault self-repair circuitsystem based on EHW and RBT |
| 图选项 |
在图 4中,在采用CPLD/FPGA作为硬件实现平台时,采用常规的EHW技术,如果采用片外演化,需要检测出存在故障的开关节点或逻辑块,以便于修复时绕开故障节点。图 4(a1)中出现故障的节点对应的第2行未被使用,此时交换第1行AND线和第2行AND线,可实现故障修复(图 4(a2));图 4(b1)中编号12的逻辑块出现故障,将第3行中使用的逻辑块顺序后移,可绕开故障单元,实现故障修复(图 4(b2))。如果采用片内演化,需要演化一次,下载配置一次,检测一次。如果检测后还存在故障,还需要再进行演化、配置下载、检测,依次循环,直到所有故障消失为止。无论是片外演化还是片内演化,新配置的电路均绕开了故障节点。
在图 5中,采用FPGA作为硬件的实现平台,均不需要进行故障定位,只需要检测出存在故障的输入输出组合即可。修复是对输出状态进行矫正,详细原理可参考文献[8]。
以上可以看出,常规的基于EHW的故障自修复策略,在片外演化中会因故障定位的难度大于直接对输出状态判决的难度,或在片内演化中因检测不合格而循环演化,这些都会消耗较长的时间,造成故障不能及时修复的现象。而基于EHW和RBT的故障自修复策略,没有前者存在的问题,在故障信息判断方面能够节约时间,这是后者的主要优点。
3.2 故障修复类型 数字电路出现的故障类型较多,根据不同故障类型具有的特点,紧密结合常规的基于EHW的故障自修复策略和基于EHW和RBT的故障自修复策略的故障修复机制,不同故障类型下的故障修复能力见表 1。表 1中t表示故障修复时间,其包括以下几部分:检测故障(t1)、故障信息分析(t2)、电路演化(t3)、串口通信(t4)、数据配置(t5)、开关切换(t6),且t=t1+t2+t3+t4+t5+t6; tt表示间歇性故障时间间隔。
针对固定型故障和时滞故障,如表 1所示,由于常规的基于EHW的故障自修复策略的故障修复机制是针对出现的故障,直接演化出新的电路重新配置,绕开故障单元,所以这2种故障能够被修复,只有在冗余单元不足以替换故障单元时,故障修复才会失败。而基于EHW和RBT的故障自修复策略能够修复这2种故障。
表 1 不同故障类型下的2种策略的故障自修复能力 Table 1 Fault self-repair ability of two strategieswith different fault types
| 故障类型 | 能否修复故障 | ||
| 常规的基于 EHW的故障 自修复策略 | 基于EHW和 RBT的故障 自修复策略 | ||
| 固定型故障 | 能 | 能 | |
| 时滞故障 | 能 | 能 | |
| 瞬态故障 | 能 | 能 | |
| 桥接故障 | 不能 | 能 | |
| 间歇性故障 | t≥ts | 不能 | 能 |
| t <ts | 不一定 | 能 | |
表选项
针对桥接故障,由于信号已经不能形成通路,这种故障和UUT内部电路没有任何关系,因此常规的基于EHW的故障自修复策略不能修复桥接故障。而基于EHW和RBT的故障自修复策略能够修复桥接故障,在旁路FPGA内部,配置需要的电路,通过MUX转接,对存在故障的输出状态进行矫正修复。
由于瞬态故障不是由电路或系统中硬件引起的,多是由外部原因造成,通过重启等可以复原。即使不重启,两种演化策略均可修复。
重点在于分析2种故障修复策略在间歇性故障时的故障修复能力。目前,MUX多由互补金属氧化物半导体(Complementary Metal Oxide Semiconductor,CMOS)构成,MUX切换速度很快,耗时在几纳秒至几百纳秒之间[26-28],而纳秒级的时间间隔相对于间歇性故障时间间隔(ts)是可以忽略不计的。此时基于EHW和RBT的故障自修复策略可根据间歇性故障时间间隔、自适应地判断MUX接通和断开时机,实现故障修复。
而常规的基于EHW的故障自修复策略,在对间歇性故障进行修复时,和ts有直接关系。当t≥ts时,在电路演化好的时候又会出现新的故障,此时故障不能修复;当t <ts时,此时只在ts-t的时间内实现了故障修复,而当出现新故障后,电路又需要重新演化,此时常规的基于EHW的故障自修复策略表现出了其局限性。
综上分析可得,基于EHW和RBT的故障自修复策略在对桥接故障、间歇性故障进行修复的时候具有明显的优势,而常规的基于EHW的故障自修复策略此时故障修复能力明显不足。
4 故障修复时间 故障修复时间是衡量故障修复速度的重要指标。在常规的基于EHW的故障自修复过程中,且在3.2节中所示,故障修复时间存在以下关系:t=t1+t2+t3+t4+t5+t6。而在基于EHW和RBT的电子电路故障自修复策略过程中,时间消耗的位置和常规的基于EHW的故障自修复策略一致,只是电路演化时间t3消耗量不一样,具有明显的区别,这也是所提出的EHW和RBT故障自修复策略的优势所在。
串口通信RS232标准接口的传输速率可达到115 200 b/s,RS485最高则可达到10 Mb/s,常规情况下的数据能够在几秒内传输完毕。基于CMOS组成的MUX开关切换时间可忽略不计。由于所提出的基于EHW和RBT的故障自修复策略,只需检测出哪些端口的哪些组合存在故障,不需关心电路内部到底出现了什么类型的故障。因此,检测故障就显得容易,最简单的方法就是将测量值和预期值进行比对。
而信号测量与信号的时钟频率有直接关系。信号的频率越高,其周期越短,根据奈奎斯特采样定理,只要能采样一个周期的信号,就能对信号进行评判。绝大多数数字信号的周期都在1 s之内,也就是信号检测和比较能够在1 s内完成。
数据配置耗时与配置文件大小和DCLK频率有直接关系,通常情况下的数据配置耗时可控制在几秒内[29]。
而电路演化时间受演化算法、硬件配置、电路演化规模影响。不同硬件配置的PC,运行速度有所不同。当在同一配置的PC对不同规模的电路进行演化的时候,所消耗的时间将不同。在基于处理器为AMD Athlon X2 250双核,内存为2 GB,显卡为ATI Radeon 3000的PC上,采用遗传离散粒子群算法作为演化算法,使用MATLAB软件,对4输入1输出和4输入2输出的电路进行演化,进化次数从0~120 000次,对每增加6 000次的进化时间消耗进行了统计,统计后的数据经过最小二乘支持向量机(Least Square Support Vector Machine,LS-SVM)拟合,得到如图 6所示的曲线。深究其原因:当演化电路规模越大,演化过程中电路编码长度越长,解空间就会很大,寻找到目标解的耗时将直接增加。假设编码长度为H,其二进制编码的解空间为2H;当编码长度为H+1时的解空间为2H+1,新增量为2H。当电路规模越大时,H越大,解空间的新增量呈2H指数增长。目前国内外的很多研究者[30-32]都在致力于解决大规模电路快速演化问题。当电路规模增加时,电路成功演化的难度也相应增加,电路演化成功率会逐渐降低,且电路演化时间消耗也增加。
 |
| 图 6 演化算法进化次数与时间消耗量之间的关系 Fig. 6 Relationship between iterative number of EA and time consumption |
| 图选项 |
如图 6所示,论编码长度,4输入2输出大于4输入1输出。就相同的进化次数而言,前者所消耗的时间明显长于后者。随着进化次数的增加,时间消耗的差距会越来越大。随着电路规模增大,因搜索空间增大而成功搜索到目标电路的进化次数也将增加,对应的时间也将增加。从图 6可以看出,K1点的演化迭代次数大于K2点,且前者的时间消耗明显大于后者。
基于此,前期提出的基于EHW和RBT的故障自修复策略相比于常规的基于EHW的故障自修复策略,在电路演化时间上具有明显优势。无论是组合逻辑电路,还是时序逻辑电路,前者只针对出现故障的输出端进行电路演化,演化电路的规模得到了降低,演化电路规模如图 7所示。
 |
| 图 7 基于EHW和RBT的故障自修复策略中电路演化规模 Fig. 7 Circuit evolutionary scales of fault self-repair strategy based on EHW and RBT |
| 图选项 |
针对规模为M×N的电路(X1,X2,…,XM为输入端编号,Y1,Y2,…,YN为输出端编号),当1个输出端出现故障时,演化电路的规模为M×1;当2个输出端出现故障时,演化电路的规模为M×2;当i(i∈[1,N],且i为整数)个输出端出现故障时,演化电路的规模为M×i;只有当N个输出端都出现故障时,演化电路的规模才是故障UUT电路的规模(即演化电路规模为M×N)。
由于故障自修复的时间主要消耗在电路演化上,因此缩减电路演化规模,在尽量短时间内成功演化出目标电路,将显得格外重要。缩减演化电路规模、缩短演化时间、提高电路演化成功率和保证故障自修复的速度四者具有递进关系,而基于EHW和RBT的电子电路故障自修复策略在此方面具有明显的优势和重要的工程应用价值。
5 硬件资源消耗 硬件资源消耗主要从定量/微观、定性/宏观2个层面进行分析。对比分析图 2和图 3,排除相同的单元/模块,基于EHW和RBT的故障自修复策略新增硬件资源包括3个部分:MUX、与输出端口对应的XOR门和配置矫正电路的FPGA。
5.1 定量/微观的分析角度 在分析硬件资源消耗时,可以将CMOS或基本门等变化量作为分析指标。CMOS和基本门之间存在固定的数值关系:1输入的非门(NOT)需要2个CMOS,2输入的与门(AND)需要6个CMOS,2输入的或门(OR)需要6个CMOS,而一个典型的单刀单掷开关需要4个CMOS[33-34]。基本门和FPGA逻辑资源之间也存在一定的换算关系,采用等效门数原则,即实现相同的功能电路,在标准门阵列中需要的门数就是FPGA该资源的等效门数。以Xilinx的XC4000系列的FPGA为例,一个4输入的查找表(Look Up Table,LUT)等价于1~9个基本门,一个触发器等价于6~12个基本门,一个基本可编程逻辑单元(Configurable Logic Block,CLB)等价于15~48个基本门[35]。当使用一个CLB、LUT或者触发器实现不同功能的时候,对应的等价基本门数量会发生变化。由于XOR和MUX可独立于FPGA存在,因此可采用CMOS指标进行衡量。
根据RBT技术基本原理,每个输出端需要使用1个2输入的异或门(XOR),1个2输入的XOR总的CMOS消耗量为22。针对一个具有M个输入端N个输出端的电路,假设每个输出端都受到所有输入端的影响。由于需将UUT输入信号引入到FPGA,此时新增M个单刀单掷开关(等价于4M个CMOS);由于UUT的故障信号需引入FPGA,且UUT的矫正信号需引出,此时1个输出端口新增2个单刀单掷开关(等价于8个CMOS)。用Smxr表示为修复故障时XOR和MUX的CMOS使用量,修复i个输出端口新增CMOS数量用Smxri表示:
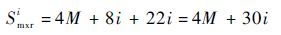 | (1) |
式中:i∈[1:N],i为整数。从式(1)可以看出,在故障修复率为100%时,当M和i值越小,对应越少;反之则越多。
以ISCAS85电路库中的C17和C6288电路为例,对故障修复中Smxr进行分析。此时仍假设每个输出端都受到所有输入端的影响,一个LUT等价于8个基本门,且一个基本门等价于6个CMOS,此时得到了如图 8和图 9所示数据。
 |
| 图 8 故障输出端个数与Smxr的关系 Fig. 8 Relationship between number of faultoutput ports and Smxr |
| 图选项 |
从图 8和图 9可以看出,针对同一个UUT,随着故障输出端数量的增加,采用RBT技术后,Smxr 消耗量呈线性增长,但增长较为缓慢。由于C17电路规模小,且输入/输出端数量少,所以Smxr消耗量占C17电路的比值偏大;而C6288电路规模较大,且新增输入/输出端数量较少,所以Smxr消耗量占C6288电路的比值远远小于C17。即使当C6288的故障修复率达到了100%,Smxr消耗量占C6288电路的比值还不到4%。
 |
| 图 9 故障修复率与Smxr增量百分比的关系 Fig. 9 Relationship between fault repair rate andincrement percentage of Smxr |
| 图选项 |
因此可以得到以下结论:当UUT规模越大,且其输入端/输出端数目越少时,采用RBT技术,修复故障时Smxr和UUT本身的CMOS使用数量的比值将越小,甚至可忽略;反之则越大。
最后重点比较用于修复UUT的RTC的硬件资源消耗。由于现阶段EHW主要实现平台是FPGA,因此选取FPGA的基本组成单元(LUT、Slice和可编程输入输出单元(Input Output Block,IOB))作为衡量电路硬件资源消耗的评价标准。目前主流的FPGA整合了许多常用功能,大多是基于4输入LUT技术。
数字电路的单个输出端存在只使用电路系统一部分输入端的可能性,针对多个故障输出端演化出的RTC电路可能存在共用LUT的可能性,共用的LUT数量用L表示。输出端个数的增加也势必影响LUT数量的增加。针对同一个输出端,因电路复杂度增加可能额外增加一些LUT,用Q表示。为了便于统计分析,需3个约束条件:
1) 针对每个故障输出端,根据补偿修复技术演化出的RTC电路,均受所有输入端的影响。
2) 同一电路的不同输出端不存在共用LUT的情形,即L=0。
3) 针对同一个输出端因电路复杂度而新增的LUT数量为0,即Q=0。
为了定量分析硬件资源消耗,首先选取了ISCAS85中的2个典型电路进行分析比较,分别是C17电路和C432电路。根据表 2所示的电路规模划分原则,C17属于小规模电路,C432属于大规模电路。
表 2 集成电路的集成度分类 Table 2 Integration level classification of integrated ciruit (IC)
| 名称 | SSI | MSI | LSI | VLSI |
| 门数量 | 1~10 | 10~100 | 100~100 000 | ≥100 000 |
表选项
C17电路具有5个输入端和2个输出端,每个输出端只与其中4个输入端有关系。不同数量输出端出现故障时采用RBT技术后,得到的RTC的硬件资源消耗见表 3。表中的OC (Original Circuit) 为原始电路,CRTC(Corresponding RTC)为与之对应的矫正电路。
表 3 C17电路不同数量输出端故障时RTC硬件资源消耗 Table 3 Consumption of hardware resource of RTC whenC17 circuit has different numbers of fault output ports
| 故障输出 端口数量 | 使用的逻辑 单元名称 | OC | CRTC | (CRTC/OC)/% |
| 1 | Slices | 1 | 1 | 100.000 |
| 4输入LUT | 2 | 1 | 50.000 | |
| IOB | 7 | 5 | 71.429 | |
| 2 | Slices | 1 | 1 | 100.000 |
| 4输入LUT | 2 | 2 | 100.000 | |
| IOB | 7 | 7 | 100.000 |
表选项
从表 3可以看出,针对中规模电路,由于其本身的硬件资源消耗较少,在进行补偿平衡修复时,当只有1个输出端出现故障时,设计的RTC电路硬件资源消耗Slices增加了100%,LUT增加了50%,IOB增加了71.429%。当2个输出端出现故障时,Slices、LUT及IOB都增加了100%。
而C432电路具有36个输入端,7个输出端。输出端N223和N329受共同的18个输入端的影响,剩余的5个输出端都受全部32个输入端的影响。对应的C432电路单个输出端出现故障之后,对应的RTC硬件资源消耗见表 4。
表 4 C432电路单个输出端故障时RTC硬件资源消耗 Table 4 Consumption of hardware resource of RTC whenC432 circuit has one fault output port
| 故障输出 端口名称 | 使用的 逻辑单元名称 | OC | CRTC | (CRTC/OC)/% |
| N223 N329 | Slices | 56 | 3 | 5.357 |
| 4输入LUT | 109 | 5 | 4.587 | |
| IOB | 43 | 19 | 44.186 | |
| N370 N421 N430 N431 N432 | Slices | 56 | 5 | 8.929 |
| 4输入LUT | 109 | 9 | 8.257 | |
| IOB | 43 | 37 | 86.047 |
表选项
从表 4可以看出,当输出端口N223和N329出现故障时,对应的硬件资源消耗Slices增加了5.357%,LUT增加了4.587%,IOB增加了44.186%。当输出端口剩余的5个输出端出现故障时,对应的硬件资源消耗Slices增加了8.929%,LUT增加了8.257%,IOB增加了86.047%。
相比于C17电路,在单个输出端出现故障时,C432电路的Slices、LUT和IOB的增加量占OC硬件资源消耗量的百分比在逐渐下降。就C432电路而言,与输出端有关系的输入端的数量也直接影响RTC电路的硬件资源消耗。
为了更加直观定量地分析输入端个数、电路规模等指标对RTC电路硬件消耗的影响,对ISCAS85中的10个不同规模电路(C499、C880、C880a、C1355、C1908、C1908a、C2670、C3540、C5315、C6288)进行了分析。此时假设L=0,单输出端出现故障对应的Slices、LUT和IOB硬件资源消耗如表 5~表 7所示。
表 5 Slice消耗对比表 Table 5 Contrastive table of Slice consumption
| 电路名称 | C499 | C880 | C880a | C1355 | C1908 | C1908a | C2670 | C3540 | C5315 | C6288 |
| OC | 45 | 59 | 63 | 45 | 57 | 43 | 84 | 187 | 210 | 387 |
| CRTC | 6 | 8 | 8 | 6 | 5 | 5 | 30 | 7 | 23 | 4 |
| (CRTC/OC)/% | 13.33 | 13.56 | 12.70 | 13.33 | 8.77 | 11.63 | 35.71 | 3.74 | 10.95 | 1.03 |
表选项
表 6 LUT消耗对比表 Table 6 Contrastive table of LUT consumption
| 电路名称 | C499 | C880 | C880a | C1355 | C1908 | C1908a | C2670 | C3540 | C5315 | C6288 |
| OC | 78 | 112 | 108 | 78 | 101 | 75 | 160 | 331 | 399 | 690 |
| CRTC | 11 | 15 | 15 | 11 | 9 | 9 | 59 | 13 | 45 | 8 |
| (CRTC/OC)/% | 14.10 | 13.39 | 13.89 | 14.10 | 8.91 | 12.00 | 36.88 | 3.93 | 11.28 | 1.16 |
表选项
表 7 IOB消耗对比表 Table 7 Contrastive table of IOB consumption
| 电路名称 | C499 | C880 | C880a | C1355 | C1908 | C1908a | C2670 | C3540 | C5315 | C6288 |
| OC | 73 | 86 | 86 | 73 | 58 | 58 | 373 | 72 | 301 | 64 |
| CRTC | 42 | 61 | 61 | 42 | 34 | 34 | 234 | 51 | 179 | 33 |
| (CRTC/OC)/% | 57.53 | 70.93 | 70.93 | 57.53 | 58.62 | 58.62 | 62.73 | 70.83 | 59.47 | 51.56 |
表选项
由于不易清晰从表 5~表 7中看出变化规律,得到了如图 10所示的曲线图。在图 10中,横坐标按照10个典型电路硬件资源消耗从少到多的顺序排序,与之对应括号中的数值表示所消耗的Slice数量;左边的纵坐标表示的是矫正电路与之对应的原始电路的IOB和LUT消耗的比值;右边纵坐标表示的10个电路对应的输入端的数量。由于1个Slice包含2个LUT,所以图 10中Slice和LUT的曲线走势一致,因此只需要分析其中一个数据即可。
 |
| 图 10 不同规模电路单输出端故障时RTC硬件资源消耗对比曲线 Fig. 10 Contrastive curves of consumption of hardwareresource of corresponding RTC when single faultoutput port of different scale circuits occurs |
| 图选项 |
在电路单个输出端出现故障时,从图 10中能够清晰地看出,10个典型电路的输入端数量的变化趋势和Slice的ORTC/OC的值走势一致。即当电路的输入端数量增加(减少)的时候,对应的Slice和LUT的ORTC/OC的值都随着增加(减少)。就具体的电路而言,当10个电路均无故障时,C1908a电路消耗的Slice数量最少,为43个;C6288消耗的Slice数量最多,为387个。就Slice的ORTC/OC而言,C6288电路的矫正电路Slice增加百分比最少,为1.03%;C2670电路的矫正电路Slice增加百分比最大,为35.71%。
相反地,C499电路本身需要消耗45个Slice,其对应的ORTC/OC的值达到了13.33%,对应的输入端为41个。如果是表 3中的C17电路,只消耗1个Slice,而对应的ORTC/OC的值达到了100%,对应的输入端个数为5个。
从表 5和表 6还可以看出,C880和C880a电路、C1908和C1908a电路,这2组电路的输入端和输出端数量相等,但由于其内部电路结构复杂度不一样,即L和Q不一样,Slice和LUT的ORTC/OC的值均不相等,当Q-L越大时,ORTC/OC值越小,反之当Q-L越小时,ORTC/OC值越大。
从以上分析可以得到以下结论:无故障UUT电路的总硬件资源消耗越大,且输入端个数越少时,则UUT故障后对应的矫正电路所消耗的硬件资源(Slice、LUT、IOB)越少;反之,UUT总的硬件资源消耗越小,或输入端个数越多,则故障UUT对应的矫正电路所消耗的硬件资源(Slice、LUT、IOB)越多。
以上是在单输出端存在故障的情况下进行的定量分析,根据前面的约束条件,现对多个输出端出现故障进行分析。对单输出端故障对应的表 5、表 6和表 7中的数据进行反推,由于同一个电路不同输出端可使用1个Slice中的不同LUT,因此对LUT的使用量进行分析,得到了表 8所示的数据。
选取表 8中的几个典型电路进行对比分析。当L=0且Q=0时,在硬件资源消耗不大于无故障电路的情况下,并采用补偿平衡技术,C2670无故障时的LUT消耗量为160,且存在140个输出端口,其故障修复率只有1.43%,主要是因为其输出端口和输入端口太多,而其无故障电路的Q-L远远小于0,即Q-L=-8 100;C6288无故障时的LUT消耗量为690,且存在32个输出端口,其故障修复率能够达到65.63%,其无故障电路的Q-L大于0;C3540无故障时的LUT消耗量为331,其故障修复率能够达到100.00%,主要因为其无故障电路的Q-L=45,远远大于0。
因此可以得到以下结论:当L=0且Q=0时,在硬件资源消耗不大于无故障电路的情况下,输出端数量越少,且无故障电路的硬件资源消耗越多,采用RBT技术后,对应的故障修复率将越高。
表 8 硬件资源消耗不大于无故障电路情况下RBT的故障修复率 Table 8 Fault repair rate based on RBT when consumption of LUT is less than that of original circuit
| 电路名称 | C499 | C880 | C880a | C1355 | C1908 | C1908a | C2670 | C3540 | C5315 | C6288 |
| 原电路LUT数量 | 78 | 112 | 108 | 78 | 101 | 75 | 160 | 331 | 399 | 690 |
| 对应矫正电路LUT数量 | 11 | 15 | 15 | 11 | 9 | 9 | 59 | 13 | 45 | 8 |
| 总端口数量 | 73 | 86 | 86 | 73 | 58 | 58 | 373 | 72 | 301 | 64 |
| 输出端口数量 | 32 | 26 | 26 | 32 | 25 | 25 | 140 | 22 | 123 | 32 |
| 最大能够修复故障端口数量 | 7 | 7 | 7 | 7 | 11 | 8 | 2 | 22 | 8 | 21 |
| 故障修复率/% | 21.88 | 26.92 | 26.92 | 21.88 | 44.00 | 32.00 | 1.43 | 100.00 | 6.50 | 65.63 |
| 注:当C3540 故障修复率达到100%时,只使用了286个LUT,且CRTC/OC的比值是86.40%(L=0且Q=0)。 | ||||||||||
表选项
以上是对10个典型电路的对比分析。针对一个具有M个输入端N个输出端的电路,UUT电路本身LUT的消耗量为SOC,在RBT技术下修复单个输出端的LUT消耗量为SRO。则得到
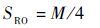 | (2) |
当修复多个输出端出现故障时,存在因复杂度增加的LUT,因共用LUT而减少使用LUT。存在修正参数Rlq:
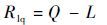 | (3) |
在硬件资源消耗不大于无故障电路的情况下,采用RBT技术后的故障修复率用Pre表示:
 | (4) |
从式(4)中同样可以看出,在硬件资源消耗不大于无故障电路的情况下,M×N越小,即对应的输入端和输出端数量乘积越小,修正参数Rlq越小,SOC越大,在采用RBT技术下的故障修复率越高,即验证了表 8中各个电路的故障修复率。当M×N、Rlq更小,修复故障的矫正电路的硬件消耗相对于无故障电路的硬件消耗的比值将更小,尤其是在少量输出端口出现故障的情况下,新增的硬件资源消耗基本可忽略不计。
另外,通过演化算法实现电路进化,修复故障所使用的硬件资源还能够进一步降低,其原因如下:
1) 以上分析的过程中,均假设Q=L=0,而在实际电路演化过程中,通过演化算法,能够消除一些冗余单元,使得L>0。
2) 以上分析过程均假设每个输出端均受所有输入端的影响,这是一个最大值。而通过演化算法,能够消除与输出端无关的输入端,MUX的使用量和LUT的使用量能够进一步缩减。
从以上分析综合来看,UUT硬件资源消耗越大,输入/输出端个数越少,且出现故障的输出端个数较少,修复故障所使用的硬件资源(RTC)占UUT本身硬件消耗的比值将越小,甚至可能显得微不足道。此时基于EHW和RBT的故障自修复策略优势将得到体现。设计者还能够采用式(1)和式(4),对故障修复的硬件资源消耗和故障修复率进行预先评估。
5.2 定性/宏观的分析角度 在定性/宏观的分析角度,主要基于芯片的重量、体积、面积等成本进行评估。在详细分析常规的基于EHW的故障自修复电路系统和EHW与RBT相结合的故障自修复电路系统之间的区别后,排除两者必备的模块,实质上后者只增加了一片FPGA和相应的布线。布线可以忽略,下面主要评估新增FPGA对整个硬件系统的影响。
目前,CPLD/FPGA制造工艺已经达到了16 nm,系统门数已经达到近千万门。以Xilinx的产品为例,早期的中低端产品FPGA Spartan-3E系列的XC3S500E芯片[36],包含了1 164个CLB、73 K的Distributed RAM、360 K的Block RAM、用户能使用的最大I/O数量为232。其封装面积为0.64~9 cm2,厚度为1.1~4.1 mm,重量为0.1~5.3 g,价格几十到几百元人民币不等[36]。Xilinx的最新高端产品FPGA XCVU13P芯片,具有1 636个CLB、432 Mb的UltraRAM、94.5 Mb的Total Block RAM、51.6 Mb的Max. Distributed RAM,I/O总数达到了832,其封装面积约为5×5 cm2。功耗低,成本更低,整体性能大幅提升,可利用资源大幅扩大。而重量、面积、体积保持不变,价格在10 000美元左右[37]。CPLD/FPGA的工作环境温度范围为-40~100℃,能够满足工作要求。其价格随着芯片资源、功能的丰富呈增加之势[38]。
针对基于EHW和RBT的电子电路故障自修复系统,一方面,系统中的一片CPLD/FPGA可以配置多个RTC电路,通过MUX转接,实现对多个UUT进行修复,修复原理示意图如图 11所示。
 |
| 图 11 单个FPGA对多个UUT实现故障自修复的电路系统简化模型 Fig. 11 Simplified circuit system model for fault self-repair multiple UUTs by single FPGA |
| 图选项 |
图 11为单个FPGA实现对多个UUT进行故障修复电路系统的简化模型。从模型中可以清晰地看出,每个UUT模块均能通过各自两侧的MUX,实现和FPGA间信号互通。这样可以减少硬件系统中CPLD/FPGA的使用量,降低硬件成本。
另一方面,根据设计的自修复电路系统的功能、用途不同(主要指使用环境),可以有选择地增加CPLD/FPGA的数量,控制硬件成本。针对一个较大的电路系统,采用RBT技术,图 3中的UUT不局限于一个芯片,可为一个局部电路或者一个小/中/大规模电路系统。此时,相对与整个电路系统,所增加的硬件资源将显得微不足道。
设计在不同环境中工作的电子系统的主导因素不一样,有时是价格,有时是重量、面积、体积,使用者可根据自己需求进行权衡。
MUX能实现信号转接,因此也需要关注MUX的硬件资源开销。90%以上的集成电路生产技术都是属于CMOS生产工艺,MUX也不例外。
现今,集成电路实现的超高速数字电路速率已超过10 Gb/s,射频电路的最高工作频率已超过6 GHz。工艺从1999年的0.18 μm,到2009年已经达到了0.07 μm。CMOS集成电路的温度稳定性好,抗辐射能力强,因此适合于在特殊环境下工作。基于CMOS的存储单元ROM的面积只有几平方微米,基于CMOS的电容大小为l~ 4 fF/μm2 [26]。CMOS模拟电路的工作频率也越来越高,现在它已经能处理5 GHz以上的信号[27]。例如,ADG715、ADG5207、ADG918等多路开关芯片[28],ADG715的封装RU-24 TSSOP的表面积只有7.8×4.4 mm2,厚度才1.2 mm[28]。ADG5207芯片的温度范围为-40~125℃,面积约42 mm2 [27]。ADG5209芯片的面积只有30 mm2 [28],ADG918功耗低,小于1 μA,工作频率高,达到了1 GHz,封装面积不到10 mm2 [28]。现在有很多基于BiMOS的集成电路,能够满足射频和模拟电路的需求。而且BiMOS门电路的功耗极低,约为0.0003~7.5 mW,信号传输时间极小,约为3 ns[39]。另外,一片FPGA里面有大量的开关盒,具有很小的体积和面积,这些开关盒完全可以用来替代MUX。
综上可以看出,在基于EHW和RBT的故障自修复电路系统中,所增加的硬件资消耗,无论是面积、重量、体积,亦或是数量、成本等都能够容忍,即使在对体积、面积和重量极为苛刻的宇航、深海等领域的电子系统,所增加的硬件消耗都在可控范围内,都不存在技术层面的障碍。
6 结 论 为解决常规的基于EHW的故障自修复策略存在故障定位难度大、演化电路规模大、故障在线修复不及时和电路演化速度慢等问题,首先建立了常规的基于EHW的故障自修复策略模型,提出了基于EHW 和RBT的故障自修复策略模型,并对模型中各模块的功能进行了简要分析。本文主要对后者的性能进行了详细分析。
1) 对2种故障修复策略的故障自修复能力进行了详细的分析,主要包含故障修复机制和故障修复时间两个指标。相比于常规的基于EHW的故障自修复策略,基于EHW和RBT的故障自修复策略不需关注故障电路内部的故障信息,只需关心电路外部哪个输出口出现了故障,根据故障信息和补偿平衡修复原理,实现对故障信号矫正修复。在故障修复类型方面,尤其是在对桥接故障和间歇性故障进行修复时,前者的故障修复能力受到了一定的限制,而基于EHW和RBT的故障自修复策略的优势比较明显。
2) 对比分析了2种故障修复策略的故障修复时间。通过分析得到故障修复时间的长短主要取决于电路演化时长的结论。而相比于常规的基于EHW的自故障修复策略,基于EHW和RBT的故障自修复策略能够直接缩减电路演化规模,从而缩短了电路演化时间,保证电路演化的时效性,具有明显的优势。
3) 在硬件资源消耗方面,从定量/定性、微观/宏观等角度分析了新增硬件的成本、数量、体积、面积、重量等指标。在定量/微观方面,设计者能够依据式(1)和式(4),对故障修复的硬件资源消耗和故障修复率进行预先评估。当无故障UUT的硬件消耗越大,且输入端/输出端个数越少时,Smxr增量将越小,CRTC/OC的值也越小。在定性/宏观方面,新增硬件资源都是能够容忍可控。
综合以上多个角度的分析,基于EHW和RBT的电路故障自修复策略的有效性、可行性得到充分的论证。实现了故障在线修复,缩减了电路演化规模,缩短了电路演化时间,保证了故障修复速度,缩短故障修复时间,且新增硬件资源消耗具有可控性。
参考文献
| [1] | JESSICA D, ROGER D, ROGER M G, et al. Multi-agent control of high redundancy actuation[J].International Journal of Automation and Computing, 2014, 11(1): 1–9.DOI:10.1007/s11633-014-0759-8 |
| [2] | NORDSTROM S G, SHETTY S S, NEEMA S K, et al. Modeling reflex-healing autonomy for large-scale embedded systems[J].IEEE Transactions on Systems,Man,and Cybernetics,Part C:Applications and Reviews, 2006, 36(3): 292–303.DOI:10.1109/TSMCC.2006.871597 |
| [3] | EBRAHIMI M, MIREMADI S G, ASADI H, et al. Low-cost scan-chain-based technique to recover multiple errors in TMR systems[J].IEEE Transactions on Very Large Scale Integration(VLSI) Systems, 2013, 21(8): 1454–1468.DOI:10.1109/TVLSI.2012.2213102 |
| [4] | ALMUKHAIZIM S, SINANOGLU O. Novel hazard-free majority voter for n-modular redundancy-based fault tolerance in asynchronous circuits[J].IET Computers & Digital Techniques, 2011, 5(4): 306–315. |
| [5] | 姜昱光, 韩建伟, 朱翔, 等. SRAM 型FPGA 单粒子翻转效应加固方法[J].北京航空航天大学学报, 2014, 40(8): 1073–1077.JIANG Y G, HAN J W, ZHU X, et al. Single event upset mitigation testing of SRAM-based FPGAs[J].Journal of Beijing University of Aeronautics and Astronautics, 2014, 40(8): 1073–1077.(in Chinese) |
| [6] | 赵磊, 王祖林, 周丽娜, 等. 星载SRAM型FPGA可靠性快速评估技术[J].北京航空航天大学学报, 2013, 39(7): 863–868.ZHAO L, WANG Z L, ZHOU L N, et al. Fast reliability evaluation for SRAM-based space borne FPGAs[J].Journal of Beijing University of Aeronautics and Astronautics, 2013, 39(7): 863–868.(in Chinese) |
| [7] | PENG J J, LIU Y P, CHEN Y Y. A dependability model for TMR system[J].International Journal of Automation & Computing, 2012, 9(3): 315–324. |
| [8] | ZHANG J B, CAI J Y, MENG Y F, et al. The fault self-repair strategy based on evolvable hardware and reparation balance technology[J].Chinese Journal of Aeronautics, 2014, 27(5): 1211–1222.DOI:10.1016/j.cja.2014.09.006 |
| [9] | YAO X, TETSUYA H. Promises and challenges of evolvable hardware[J].IEEE Transactions on Systems,Man,and Cybernetics,Part C:Applications and Reviews, 1999, 29(1): 87–97.DOI:10.1109/5326.740672 |
| [10] | VASSILEV V K,MILLER J F.Scalability problems of digital circuit evolution:Evolvability and efficient designs[C]//The 2nd NASA/DoD Workshop on Evolvable Hardware.Piscataway,NJ:IEEE Press,2000:55-64.http://cn.bing.com/academic/profile?id=2152938581&encoded=0&v=paper_preview&mkt=zh-cn |
| [11] | LIANG H J, LUO W J, WANG X F. A three-step decomposition method for the evolutionary design of sequential logic circuits[J].Genetic Programming and Evolvable Machines, 2009, 10(3): 231–262.DOI:10.1007/s10710-009-9083-4 |
| [12] | 何国良, 李元香, 史忠植. 基于精英池演化算法的数字电路在片演化方法[J].计算机学报, 2010, 33(2): 365–372.HE G L, LI Y X, SHI Z Z. Elitist pool evolutionary algorithm for on-line evolution of digital circuits[J].Chinese Journal of Computers, 2010, 33(2): 365–372.DOI:10.3724/SP.J.1016.2010.00365(in Chinese) |
| [13] | VASICEK Z, SEKANINA L. Formal verification of candidate solutions for post-synthesis evolutionary optimization in evolvable hardware[J].Genetic Programming and Evolvable Machines, 2011, 12(3): 305–327.DOI:10.1007/s10710-011-9132-7 |
| [14] | WANG J, CHEN Q S, LEE C. Design and implementation of a virtual reconfigurable architecture for different applications of intrinsic evolvable hardware[J].IET Computers & Digital Techniques, 2008, 22(5): 386–400. |
| [15] | LOHN J D, HORNBY G S, LINDEN D S. Evolutionary antenna design for a NASA spacecraft[M].Berlin: Springer, 2004: 301-315. |
| [16] | GREGORY S H, JASON D L, DEREK S L. Computer-automated evolution of an X-band antenna for NASA's space technology 5 mission[J].Evolutionary Computation, 2011, 19(1): 1–23.DOI:10.1162/EVCO_a_00005 |
| [17] | PAULINE C H, ANDY M T. Challenges of evolvable hardware:Past,present and the path to a promising future[J].Genetic Programming and Evolvable Machines, 2011, 12(3): 183–215.DOI:10.1007/s10710-011-9141-6 |
| [18] | CHANG P C, WANG Y W, TSAI C Y. Evolving neural network for printed circuit board sales forecasting[J].Expert Systems with Applications, 2005, 29(1): 83–92.DOI:10.1016/j.eswa.2005.01.012 |
| [19] | JAMES M H. Fault-tolerant sensor systems using evolvable hardware[J].IEEE Transactions on Instrumentation and Measurement, 2006, 55(3): 846–853.DOI:10.1109/TIM.2006.873791 |
| [20] | 朱继祥, 李元香, 邢建国. 可重构系统的演化修复机制[J].计算机学报, 2014, 37(7): 1599–1606.ZHU J X, LI Y X, XING J G. The evolvable recovery of reconfigurable system[J].Chinese Journal of Computers, 2014, 37(7): 1599–1606.(in Chinese) |
| [21] | 朱继祥, 李元香, 夏学文. 演化硬件的容错模式研究[J].小型微型计算机系统, 2010, 31(12): 2472–2475.ZHU J X, LI Y X, XIA X W. Research on fault tolerance of evolvable hardware[J].Journal of Chinese Computer Systems, 2010, 31(12): 2472–2475.(in Chinese) |
| [22] | 姚睿, 王友仁, 于盛林, 等. 具有在线修复能力的强容错三模冗余系统设计及实验研究[J].电子学报, 2010, 38(1): 177–183.YAO R, WANG Y R, YU S L, et al. Design and experiments of enhanced fault-tolerant triple-module redundancy systems capable of online self-repairing[J].Acta Electronica Sinica, 2010, 38(1): 177–183.(in Chinese) |
| [23] | YAO R, CHEN Q Q, LI Z W, et al. Multi-objective evolutionary design of selective triple modular redundancy systems against SEUs[J].Chinese Journal of Aeronautics, 2015, 28(3): 804–813.DOI:10.1016/j.cja.2015.03.005 |
| [24] | 姚睿, 于盛林, 王友仁, 等. 采用主流FPGA 的数字电路在线生长进化方法[J].南京航空航天大学学报, 2007, 39(5): 582–587.YAO R, YU S L, WANG Y R, et al. Online growing evolution and evaluation approach based on mainstream FPGA[J].Journal of Nanjing University of Aeronautics and Astronautics, 2007, 39(5): 582–587.(in Chinese) |
| [25] | 张强, 周军, 于晓洲. 一种可局部动态实时重构的演化硬件平台[J].西北工业大学学报, 2011, 29(5): 761–765.ZHANG Q, ZHOU J, YU X Z. An efficient high-speed real-time partially reconfigurable platform for evolvable hardware[J].Journal of Northwestern Polytechnic University, 2011, 29(5): 761–765.(in Chinese) |
| [26] | 李本俊, 刘丽华, 辛德禄. CMOS集成电路原理与设计[M].北京: 北京邮电大学出版社, 1997: 88-94.LI B J, LIU L H, XIN D L. CMOS integrated circuit theory and design[M].Beijing: Beijing University of Posts and Telecommunications Press, 1997: 88-94.(in Chinese) |
| [27] | 赵巍. 数字电子技术[M].北京: 北京邮电大学出版社, 2010: 81-93.ZHAO W. Digital electronic technology[M].Beijing: Beijing University of Posts and Telecommunications Press, 2010: 81-93.(in Chinese) |
| [28] | REV C.High voltage,latch-up proof,4-/8-channel multiplexers data sheet adg5208/adg5209[R].Norword MA:Analog Devices Inc.,2011:1. |
| [29] | 李春雨, 张丽霞. 利用CPLD 提高FPGA 加载速度[J].电子器件, 2013, 36(4): 550–553.LI C Y, ZHANG L X. Using CPLD improve FPGA loading speed[J].Chinese Journal of Electron Devices, 2013, 36(4): 550–553.(in Chinese) |
| [30] | LI X D, YAO X. Cooperatively coevolving particle swarms for large scale optimization[J].IEEE Transactions on Evolutionary Computation, 2012, 16(2): 210–224.DOI:10.1109/TEVC.2011.2112662 |
| [31] | ASAFUDDOULA M, RAY T, SARKER R. A decomposition-based evolutionary algorithm for many objective optimization[J].IEEE Transactions on Evolutionary Computation, 2015, 19(3): 445–160.DOI:10.1109/TEVC.2014.2339823 |
| [32] | 姚睿, 陈芹芹, 孙艳梅, 等. 采用输入输出分解的分区分段演化机制[J].哈尔滨工程大学学报, 2015, 36(4): 522–527.YAO R, CHEN Q Q, SUN Y M, et al. In-partition in-stage evolutionary mechanism by applying input and output decomposition[J].Journal of Harbin Engineering University, 2015, 36(4): 522–527.(in Chinese) |
| [33] | 宋吉江, 牛轶霞, 于春战, 等. CMOS模拟开关及其选择问题[J].微电子技术, 2011, 29(3): 58–60.SONG J J, NIU Y X, YU C Z, et al. CMOS analog switch and its choices[J].Microelectronic Technology, 2011, 29(3): 58–60.(in Chinese) |
| [34] | 王迎栋, 孙明杰. 基于CMOS模拟开关实现平衡混频器[J].计算机与网络, 2012(15): 70–72.WANG Y D, SUN M J. Design of balanced mixer based on CMOS analog switch[J].Computer & Network, 2012(15): 70–72.(in Chinese) |
| [35] | Xilinx Inc..Application note:Gate account capacity metrics for FPGAs XAPP 059(Version 1.1)[R].San Jose:Xilinx Inc.,1997:1-2. |
| [36] | Xilinx Inc..Product specification:Spartan-3 FPGA family data sheet(v4.1)[R].San Jose:Xilinx Inc.,2013:1-2. |
| [37] | Xilinx Inc..Ultrascale+FPGAs product tables and product selection guide[R].San Jose:Xilinx Inc.,2013:2-3. |
| [38] | Xilinx Inc..Spartan-3 generation FPGAs[R].San Jose:Xilinx Inc.,2008:8. |
| [39] | 杨之廉, 许军. 集成电路导论[M].3版北京: 清华大学出版社, 2012: 123-127,141.YANG Z L, XU J. Integrate circuit introduction[M].3rd edBeijing: Tsinghua University Press, 2012: 123-127,141.(in Chinese) |
