热效应对缓冲器插入的影响已有文献对其研究[2, 3],但主要说明热效应对缓冲器插入位置的影响,即不考虑温度效应的缓冲器插入位于线的中间,而考虑驱动单元的热效应缓冲器插入位置向负载端移动,如果考虑线上的热效应会使插入缓冲器的位置向驱动端移动,如果同时考虑驱动端和线上的热效应插入缓冲器的位置也是向驱动端移动,这是由于线上的热效应比驱动单元的热效应明显,如果驱动一个长线可能增加额外的缓冲器.为了估计由于热效应额外插入的缓冲器必须在布局布线之前知道热条件下的时序预算.文献[4]已经开发一个在布局阶段估计片内温度分布的工具,文献[5]提出通过Hotspot工具进行热条件下布局.为了满足时序收敛,基于温度分布的缓冲器插入时序优化技术也必须被开发.根据最近研究结果,43.6%的缓冲器被插在块与块间的互连线上[6, 7].基于以上分析,存在的考虑温度效应的缓冲器插入技术很少并且不充分.
1 热条件下的布局规划 1.1 热条件下布局规划定义 热条件下布局规划问题是存在温度分布的条件下放置n个矩形块使其满足:
1) 每个模块i有一个固定的面积Ai并且其纵横比满足一定约束,也就是纵横比是有界的.
2) 芯片面积给定为A=W×H,W为芯片的宽度,H为芯片的高度,其纵横比也是有界的.
3) 给定每个模块的能量消耗Pi,其用于计算模块温度.
4) 布局规划的目标是低芯片面积、低总线长度L和低最高温度.
1.2 模拟退火算法 模拟退火是一种通用概率算法,用来在固定时间内在一个大的搜索空间内找到最优解[8],其流程如图 1所示.模拟退火算法与初值和算法迭代的起点无关,具有渐进收敛性,已在理论上证明是一种以概率为1收敛于全局最优的优化算法,并且具有并行性.
 |
| 图 1 模拟退火算法流程Fig. 1 Flow of simulated annealing algorithm |
| 图选项 |
实验表明,初温越大,获得高质量解的几率越大,本文初始温度选择为Tinit=30 000.假定一个设计有N个块,温度以一个因子ω < 1速率降低可表示为

式中:Tcurrent为当前温度;Told为之前温度.
本文降温方式为在初始阶段快速降温结束阶段降温很慢,也就是初始阶段ω=0.85,结束阶段ω=0.98.因此大部分退火时间花费在低温部分.
考虑热条件布局的目标函数可表示为

式中:CA、CW和CT分别为面积、线长和最高温度的权重;CAR=0.2为纵横比权重,并且CA、CW、CAR和CT之和总为1.由于式(2)在不同模块单元都要被测量,因此会取得一个线性关系的目标函数.为此,归一化此目标函数的每一项,具体为

式中:ΔA、ΔW和ΔT分别为归一化的面积、线长和最高温度;Carea、Cwl和Cmt分别为当前解的面积、线长和最高温度;Marea、Mwl和Mmt分别为修改后解的面积、线长和最高温度.因此经过归一化后的目标函数可表示为
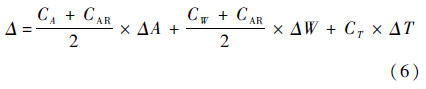
当Δ为负值时表示相对于以前解的改进;如果
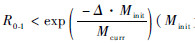 为初始的面积、线长和最高温度参数值;Mcurr为当前上述相应参数值),Δ可以为正值(R0-1为0到1之间的随机数),这说明接受一个错误移动的概率在降低,也就是随着Mcurr降低而降低.
为初始的面积、线长和最高温度参数值;Mcurr为当前上述相应参数值),Δ可以为正值(R0-1为0到1之间的随机数),这说明接受一个错误移动的概率在降低,也就是随着Mcurr降低而降低.1.3 HotSpot热建模工具 HotSpot能精确而快速进行热建模,主要用于处理器结构研究[9].针对输入布局图HotSpot产生等效热阻热容电路来计算温度分布.本文主要利用其计算布局中所有块中的最高温度,此最高温度被用于模拟退火算法的优化布局,同时给出最优布局的温度分布用于缓冲器插入.基于热条件布局的流程如图 2所示.
 |
| 图 2 基于热条件布局流程Fig. 2 Placement flow based on thermal condition |
| 图选项 |
HotSpot中有很多模型可用于温度计算[10],本文主要利用块模型即基本模型来计算温度.该模型利用输入的功耗迹文件和布局文件,产生相应块的温度迹分布.本文进行修改使其根据温度迹文件和布局文件生成此布局的最高温度.
1.4 缓冲器插入 在一个驱动单元驱动一根长线或多个负载条件下,缓冲器插入是有效减少延时的方法.为了在布局阶段进行时序估计,假定互连网络为块与块之间通过引脚互连,连接最近的驱动端和负载端,具体如图 3所示[7].全局布线是通过互连所有内部块网络,其中网络拓扑基于最小生成树被提取.经典的时序优化是在给定布线树下,从负载端到驱动端通过van Ginneken[11]算法找到优化的缓冲器插入位置和数目,使其满足整个网络弛豫时间最大和负载电容最小.但传统的缓冲器插入算法没有考虑互连模块之间的热效应.为了找到优化的缓冲器插入位置和数目,延时模型必须包括线延时和驱动端延时部分.van Ginneken算法用的线模型是π模型,延时模型用的是一阶近似Elmore延时模型[12, 13].为求节点i和节点j之间的延时,下面分两种情况说明.
 |
| D—输入端;Q—输出端;Q-—输出取反端;CLR—复位端;SET—置位端.图 3 布局阶段缓冲器插入拓扑[7]Fig. 3 Buffer insertion topology in placement stage[7] |
| 图选项 |
1) 插入线时的延时为
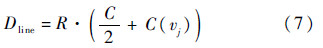
式中:R和C分别为节点i与节点j之间的线电阻和线电容;C(vj)为节点j处的向下负载电容.
2) 如果一个缓冲器插入在i节点,则插入缓冲器后的延时为
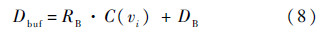
式中:RB和DB分别为缓冲器的驱动电阻和内在延时;C(vi)为i节点处的向下负载电容.
2 热条件最优布局延时优化方法 大规模集成电路特别是SoC系统包含许多功能模块,由于这些功能模块功耗不一致,导致芯片内温度梯度分布.在基于缓冲器插入优化延时过程中,如果不考虑温度对互连线和驱动端的影响,可能会错误地估计路径延时和所插入的缓冲器数目.缓冲器插入数目不足可能引起关键路径时序违反,因此在布局阶段就考虑温度对布局和缓冲器插入的影响显得十分必要.下面分别从考虑温度延时建模和考虑温度最优布局两方面说明基于热条件最优布局的延时模型.
首先给出插入互连线时考虑温度的延时模型.互连电阻特性受温度影响的程度远大于电容,文献[3, 4]对此进行了说明,因此本文忽略电容随温度变化.互连线电阻随温度变化的模型可表示为
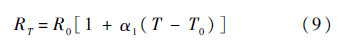
式中:R0为温度为T0=293 K下的电阻;RT为温度为T下的电阻;α1为电阻温度系数.首先把布局平面划分成面积相等的小网格叫做热网格,每个小网格内温度相同,不同网格间温度不同,具体网格大小由待布局电路的最小模块大小和精度决定,具体如图 4[7]所示.假定节点i和节点j之间连线经过n个热网格单元,则i和j两节点间的延时可表示为
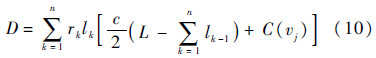
式中:rk和lk分别是在第k个热网格单元的单位电阻和线长;L为节点i和节点j间的总线长;c为单位长度的线电容,其不随温度变化.
 |
| 图 4 互连线穿过热网格示意图[7]Fig. 4 Sketch of interconnect cross thermal grid[7] |
| 图选项 |
接下来给出插入缓冲器时考虑温度的延时模型.缓冲器受温度的影响主要改变其驱动电阻和内在延时[14],具体为
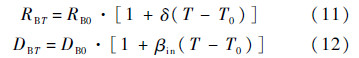
式中:RBT和RB0分别为温度T和0时缓冲器驱动电阻;DBT和DB0分别为温度T和0时缓冲器内在延时;βin=S·τ为缓冲器内在延时随温度变化的温度系数,S为缓冲器的大小;当S等于10倍到70倍最小尺寸时,δ和τ为常数,其值分别为0.005和0.000 013.因此插入缓冲器时考虑温度的延时模型为
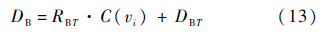
该模型充分考虑了热分布的局部特性,互连线的电阻和驱动器的输出电阻在不同位置上其大小随温度变化,基于热网格的方法能有效地加快考虑温度条件下缓冲器插入延时优化计算.
热条件下的最优布局是找到基于面积、线长和温度成本函数最优的布局.同时热条件下的布局也是一种降低芯片温度的一种有效方式,热量通过横向的临近衬底进行扩散[15],也就是一个温度高的模块旁边紧邻一个温度低的模块,整体温度就较低,如图 5所示,而图 6布局温度就比较高,由于两个高温模块放在一起.具体布局理论已经在第1节叙述,在此不再累述.下面主要给出基于热条件最优布局的延时优化的实现流程.
 |
| 图 5 热块离得比较远布局Fig. 5 Placement based on far from thermal block |
| 图选项 |
 |
| 图 6 热块离得比较近布局Fig. 6 Placement based on near thermal block |
| 图选项 |
基于热条件最优布局实现的延时优化如图 7所示.输入网表文件来源于MCNC(Microelectronics Center of North Carolina)和GSRC(Gigascale Silicon Research Center)标准测试电路[16],首先基于热条件下的最优布局生成布局文件和热分布文件;接着调用考虑温度条件的缓冲器插入时序优化程序,输出优化结果.下面主要说明一下考虑温度分布的FBI(Fast Buffer Insertion)快速时序优化方法.
 |
| 图 7 热条件最优布局的延时优化结构Fig. 7 Delay optimization structure in thermal optimal layout condition |
| 图选项 |
首先假定一个给定的路由树T=(V,E),其中:V为所有节点,E为节点之间的连接弧.每个终端负载节点包括负载电容Cs和要求到达时间(Required Arrival Time,RAT).整个路径的延时采用第1.4节的延时模型计算,在此不再累述.给定任意节点,假定T(v)是节点v以下的子树,也就是节点v被看做根节点.如果已经知道在T(v)中哪里插入缓冲器,用一个参数α来标识,从节点v到终端负载节点s的延时表示为
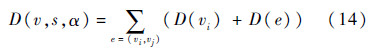
式中:求和为从v到s的所有连接弧.如果节点vi插入缓冲器,则D(vi)是插入缓冲器的延时;如果vi节点没有缓冲器插入则D(vi)=0.因此从节点v到节点s的弛豫时间Q为
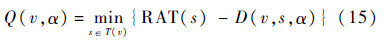
缓冲器插入算法本质上可能从两方面改进:快速计算解方案和冗余解裁剪.FBI算法在快速计算方面已有很大改进,本文主要从冗余裁剪方面进行改进,下面基于定理1给出详细说明.
定理1 假设在节点v处,经过van Ginneken算法裁剪后剩下的解方案αi、αj和αk,将其按Q值从小到大进行排列,如果αj位于αi和αk连线下与Q轴形成的区域内,则αj冗余.
证明 αi、αj、αk和αm解方案分布如图 8所示,αj位于αi和αk连线之下与Q轴形成的区域内,则其满足:
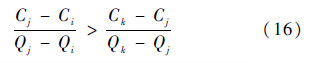
假设v*是离v最近插入缓冲器的节点并且靠近驱动节点,同时令D=Dwire+Dbuf,R=Rwire+Rbuf和C(v,α)为节点v处的负载电容.根据式(7)、式(8)、式(14)和式(15)可以得到v*处的弛豫时间Q为
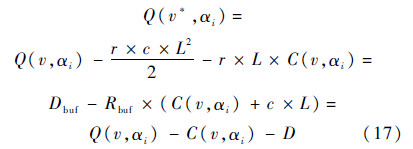
式中:r和c分别为单位长度的线电阻和线电容;L为v*节点和v节点之间的总线长;Dwire和Dbuf分别为线延时和缓冲器延时;Rwire和Rbuf分别为线电阻和缓冲器输出电阻.因此在节点v*从节点v继承的解方案的弛豫时间之差可表示为
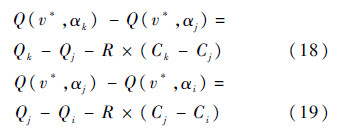
同时节点v*从节点v继承的负载电容为
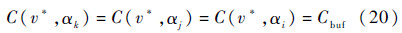
基于式(18)和式(19)大于0、小于0和等于0所有6种情况分别讨论:
1) 如果Q(v*,αk)-Q(v*,αj)>0,且Q(v*,αj)-Q(v*,αi)>0,由式(18)、式(19)和式(16)可得
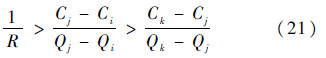
基于式(20)和式(21),由van Ginneken冗余裁剪规则[11],αj冗余.
2) 如果Q(v*,αk)-Q(v*,αj) < 0,且Q(v*,αj)-Q(v*,αi)>0和Q(v*,αk)-Q(v*,αj)>0、Q(v*,αj)-Q(v*,αi)>0情况类似,可以得到
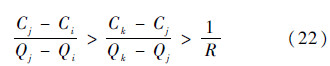
基于式(20)和式(22),由van Ginneken冗余裁剪规则,αj冗余.
3) 如果Q(v*,αk)-Q(v*,αj)>0,且Q(v*,αj)-Q(v*,αi) < 0,由式(16)、式(18)和式(19)可得
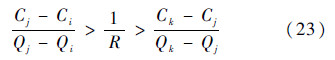
基于式(20)和式(23),由van Ginneken冗余裁剪规则,αj冗余.
4) 如果Q(v*,αk)-Q(v*,αj) < 0,且Q(v*,αj)-Q(v*,αi)>0则
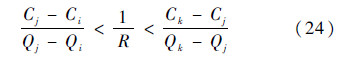
这与式(16)相矛盾,因此不满足图 8所示分布.
 |
| 图 8 按Q值大小排列的解方案集合Fig. 8 Solution set based on Q value by size |
| 图选项 |
5) 如果Q(v*,αk)-Q(v*,αj)=0,Q(v*,αj)-Q(v*,αi)任意,同时基于式(20),由van Ginneken冗余裁剪规则明显αj冗余.
6) 如果Q(v*,αk)-Q(v*,αj)任意,Q(v*,αj)-Q(v*,αi)=0,同时基于式(20),由van Ginneken冗余裁剪规则明显αj冗余.
3 仿真结果与分析 输入网表文件来源于MCNC和GSRC标准测试电路,软件实现主要用到C++和Perl脚本语言,在Linux操作系统下完成,Gcc版本为3.46.CPU主频2.4 GHz,内存12 GB.目标CMOS工艺技术为65 nm,并且互连线和缓冲器所有参数参考预测技术模型PTM (Predictive Technology Model)[17],详细参数如表 1所示.为了和参考文献对比,也只用一种固定类型缓冲器在293 K温度下输出电阻为363 Ω,输入负载电容为23.4 fF,固有延时为36.4 ps.
在给出考虑温度分布的布局测试结果之前,首先给出如何产生功耗迹文件.功耗迹文件是利用Perl脚本语言自动生成,其中块名来自预布局生成的文件.每一个在功耗迹文件中的块有100个功耗数,其由一个随机数发生器产生,并且高功耗数、中等功耗数和低功耗数分布是随机分布.考虑温度分布的布局与不考虑温度分布布局的结果对比如图 9所示.图 9中hp和apte为MCNC标准测试电路测试结果,n10、n30和n200为GSRC标准测试电路测试结果.图 10给出考虑热效应布局温度降低情况,从中可以看出,考虑温度分布布局与不考虑温度分布布局,芯片最高温度能降低5%~18%.图 11给出由于考虑温度效应,造成布线长度变化情况,从中可以看出线长增加最多不到16%.
表 1 互连线和缓冲器电气参数Table 1 Electrical parameters on interconnect and buffer
| 参数 | 参数值 |
| 单位长度电容/(fF·μm-1) | 0.118 |
| 单位长度电阻/(Ω·μm-1) | 0.074 |
| 缓冲器输出电阻/Ω | 363 |
| 缓冲器输入电容/fF | 23.4 |
| 缓冲器固有延时/ps | 36.4 |
表选项
 |
| 图 9 不同布局的比较Fig. 9 Comparison of different placements |
| 图选项 |
 |
| 图 10 考虑热效应布局温度降低情况Fig. 10 Temperature reduction based on thermal effect placement |
| 图选项 |
 |
| 图 11 考虑热效应布局线长增加情况Fig. 11 Wire length increasing based on thermal effect placement |
| 图选项 |
表 2给出温度分布范围及相应温度下所有基准电路的线电阻变化情况.在优化布局后,热条件下的RC延时模型和快速缓冲器插入算法被加到FBI程序中,优化整个电路的时序,给出优化结果.为了本文的简洁性,本文只考虑2种情况的测试:①关键路径插入缓冲器个数;②最坏路径延时.
表 2 不同温度下的互连线电阻参数Table 2 Interconnect resistor parameter in different temperature
| T/K | 线电阻/(Ω·μm-1) |
| 396.17~871.01 | 0.104~0.24 |
| 310.15~375.63 | 0.079~0.098 |
| 303.61~335.13 | 0.077~0.086 |
| 306.63~479.14 | 0.078~0.128 |
| 305.56~396.15 | 0.078~0.104 |
| 注:T初值为293.15 K;线电阻初值为0.074 Ω/μm. | |
表选项
关键路径插入缓冲器插入个数情况,为了和参考文献比较,本文也采用每个测试电路保留10%路径做为关键路径.表 3列出和不考虑温度效应及文献[7]的比较结果,从中可以看出相比参考文献,本文提出的考虑温度效应布局下缓冲器插入方法需要缓冲器数比文献[7]的少,这主要由于考虑温度布局降低芯片温度.
表 3 关键路径插入缓冲器数对比Table 3 Buffer insertion number comparison in critical path
| 缓冲器插入方法 | 插入缓冲器数 | ||||
| apte | hp | n10 | n30 | n200 | |
| 本文方法 | 145 | 122 | 18 | 39 | 370 |
| 不考虑温度效应 | 80 | 73 | 10 | 24 | 210 |
| 文献[7]方法 | 165 | 132 | - | - | - |
| 注:“-”—文献中未有此数据. | |||||
表选项
对于最坏路径延时情况,每个标准测试电路延时降低情况如表 4所示.这些电路中包括单驱动多负载和单驱动单负载情况,基于考虑温度效应布局优化缓冲器插入时序优化方法,最坏延时降低9%~18%相比传统方法,相对于文献[7]的方法最坏延时降低5%~7%,这是由于基于本文方法虽然线长增加,但温度降低了.以上结果表明,温度效应对于集成电路时序优化有重要影响,必须进行优化布局.
表 4 支持向量机与RBF网络分类性能比较Table 4 Comparison between SVM and RBF network
| 基准电路 | 延时/ps | 延时降低/% | |||
| 不考虑温度效应 | 文献[7]方法 | 本文方法 | 不考虑温度效应 | 文献[7]方法 | |
| apte | 1 078.67 | 1 014.78 | 941.54 | 12.71 | 7.22 |
| hp | 605.16 | 569.83 | 541.43 | 10.53 | 4.98 |
| n10 | 842.35 | - | 760.21 | 9.75 | - |
| n30 | 790.45 | - | 650.78 | 17.67 | - |
| n200 | 1 405.79 | - | 1 168.36 | 16.89 | - |
表选项
4 结 论 1) 根据集成电路时序要求,提出基于热条件布局的缓冲器插入方法.首先在热条件下基于模拟退火算法进行优化布局(相对传统布局温度能降低5%~20%);接着进行热条件下缓冲器插入.
2) 构建基于热效应的温度模型,并且采用快速缓冲器插入算法进行互连时序优化.采用C++语言实现对MCNC和GSRC标准测试电路的仿真模拟,模拟结果表明算法的有效性.
3) 根据电路规模不同,选择不同的测试电路进行仿真对比测试,仿真结果表明本文提出的方法的有效性包括:①需要缓冲器数少;②最坏延时降的更低,比传统方法降低9%~18%,比Kim等[7]提出的方法降低5%~7%.
参考文献
| [1] | Tsai C H,Kang S M.Cell-level placement for improving substrate thermal distribution[J].IEEE Transactions on Computer-Aided Design for Integrated Circuits and Systems,2000,19(2):253-266. |
| Click to display the text | |
| [2] | Ajami A H,Banerjee K,Pedram M.Modeling and analysis of non-uniform substrate temperature effects on global ULSI interconnects[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2005,24(6):849-861. |
| Click to display the text | |
| [3] | Ajami A H,Banerjee K,Pedram M.Analysis of substrate thermal gradient effects on optimal buffer insertion[C]∥IEEE ACM International Conference on ICCAD.Piscataway,NJ:IEEE Press,2001:44-48. |
| Click to display the text | |
| [4] | Huang W,Ghosh S,Velusamy S,et al.HotSpot:A compact thermal modeling methodology for early-stage VLSI design[J].IEEE Transactions on Very Large Scale Integration Systems,2006,14(5):501-513. |
| Click to display the text | |
| [5] | Sankaranarayanan K,Velusamy S,Stan M R,et al.A case for thermal-aware floorplanning at the microarchitectural level[J].Journal of Instruction-Level Parallelism,2005(8):1-16. |
| Click to display the text | |
| [6] | Saxena P,Menezes N,Cocchini P,et al.Repeater scaling and its impact on CAD[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2004,23(4):451-463. |
| Click to display the text | |
| [7] | Kim M,Ahn B G,Kim J,et al.Thermal aware timing budget for buffer insertion in early stage of physical design[C]∥IEEE International Symposium on Circuit and Systems.Piscataway,NJ:IEEE Press,2012:357-360. |
| Click to display the text | |
| [8] | Kirkpatrick S.Optimization by simulated annealing:Quantitative studies[J].Journal of Statistical Physics,1983,34(5-6):975-986. |
| Click to display the text | |
| [9] | Kevin S.HotSpot[EB/OL].2014[2015-03-22].http:∥lava.cs.virginia.edu/hotspot. |
| Click to display the text | |
| [10] | Kevin S.HotSpot[EB/OL].2014[2015-03-22].http:∥lava.cs.virginia.edu/HotSpot/HotSpotHowTo.htm. |
| Click to display the text | |
| [11] | van Ginneken L P P P.Buffer placement in distributed RC-tree networks for minmal elmore delay[C]∥IEEE International Symposium on Circuits and Systems.Piscataway,NJ:IEEE Press,1990:865-868. |
| Click to display the text | |
| [12] | Gupta R,Tutuianu B,Pileggi L T.The Elmore delay as a bound for RC trees with generalized input signals[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,1997,16(1):95-104. |
| Click to display the text | |
| [13] | Abou A I,Nowak B,Chu C.Fitted Elmore delay:A simple and accurate interconnect delay model[J].IEEE Transactions on Very Large Scale Integration System.Piscataway,NJ:IEEE Press,2004,12(7):691-696. |
| Click to display the text | |
| [14] | Athikulwongse K,Zhao X,Lim S K.Buffered clock tree sizing for skew minimization under power and thermal budgets[C]∥Proceedings of the 2010 Asia and South Pacific Design Automation Conference.Piscataway,NJ:IEEE Press,2010:474-479. |
| Click to display the text | |
| [15] | Skadron K,Stan M,Velusamy S,et al.A case for thermal aware floor planning at the microarchitectural level[J].Journal of Instruction-level Parallelism,2005,7:1-16. |
| Click to display the text | |
| [16] | Patrick H M,Ameya R A.GSRC bookshelf benchmarks[EB/OL].2001(2007-06-01)[2015-03-22].http:∥vlsicad.cs.binghamton.edu/benchgsrc.html. |
| Click to display the text | |
| [17] | Yu C.Predictive technology model[EB/OL].Arizona:[s.n.],2005(2012-06-01)[2015-03-22].http:∥ptm.asu.edu/. |
| Click to display the text |
