电声门图仪(Electroglottography,EGG)是测量说话人声门开启与闭合状态以及声门振动方式的仪器.客观地反应了发元音时声带开闭的状态,对情感语音识别研究有重要作用.目前大多数情感语音数据库都不含EGG信息,而本文的汉语双模情感语音数据库中采用了EGG信息.
1 情感语音数据库概况2003年在Ververidis和Kotropoulos总结的情感语音数据库中,和汉语相关的仅列出了微软公司从电视剧截取录音片段的数据库[4],表 1总结了语音情感识别研究中常用的一些情感语音数据库的基本情况.
表 1 部分情感语音数据库总结 Table 1 Summary of parts of emotional speech database
| 情感语音数据库 | 语言 | 说话人 | 容量/条 | 使用权 | EGG | 情感类型 |
| CASIA[12] | 汉语 | 4名非专业人员 | 9 600 | 非公开 | 否 | 高兴,悲伤,生气,惊吓,中性 |
| ACCorpus_SR[2, 13] | 汉语 | 50名非专业人员 | 50 000 | 非公开 | 否 | 高兴,生气,恐惧,悲伤,中性 |
| ESMBS[14] | 汉语和缅甸语 | 6名中国人和6名缅甸人 | 720 | 非公开 | 否 | 高兴,生气,伤心,嫌恶,恐惧,惊奇 |
| NATURAL[15] | 汉语 | 11名人员呼叫中心对话 | 388 | 非公开 | 否 | 生气,中性 |
| Beihang University[16] | 汉语 | 7名非专业人员 | 2 100 | 部分公开 | 否 | 生气,高兴,伤心,沮丧,惊奇 |
| CLDC[17] | 汉语 | 4名非专业人员 | 1 200 | 非公开 | 否 | 高兴,生气,惊奇,恐惧,中性,伤心 |
| Hu等[18] | 汉语 | 8名非专业人员 | 1 600 | 非公开 | 否 | 高兴,生气,伤心,恐惧,中性 |
| Berlin emotional database[19] | 德语 | 10名专业人员 | 800 | 公开 | 是 | 高兴,生气,伤心,恐惧,嫌恶,厌烦,中性 |
| FERMUS Ⅲ[20] | 德语和英语 | 13名人员;汽车噪音环境 | 2 829 | 公开 | 否 | 高兴,生气,伤心,嫌恶,惊奇,中性 |
| Danish emotional database[21] | 丹麦语 | 4名专业人员 | 500多 | 公开 | 否 | 高兴,生气,伤心,惊奇,中性 |
| SUSAS[22] | 英语 | 32名非专业人员 | 16 000 | 公开 | 否 | 生气,恐惧,沮丧,焦虑,害怕等情绪 |
| KISMET[23] | 英语和美语 | 3名非专业人员 | 1 002 | 非公开 | 否 | 赞成,关心,禁止,吮吸,中性 |
| BabyEars[24] | 英语 | 12名非专业人员 | 509 | 非公开 | 否 | 赞成,关心,禁止 |
表选项
从表 1中可以看出,目前的情感语音数据库存在的共同问题是:①包含EGG信息的情感语音数据库非常少,汉语中尚未有;②大多数库规模小,如NATURAL、ESMBS;③录制标准不统一,如情感类别多样;④一些库中记录的话语质量差,如KISMET,采样率为8 kHz;⑤一些库不提供音标等标注信息,如BabyEars,对提取语言内容等信息造成困难[5].
一个完整的情感语音数据库除了包括基本的语音文件外,还应该有相应的标注文件,详细的情感语音标注可以为情感语音合成和识别提供可靠的训练集和测试集,因此对情感语音数据库进行标注就显得极其重要.目前国内的情感语音数据库尚未有与情感有关的标注信息,国外有一些情感语音数据库进行了与情感有关的标注,如英语情感语音数据库[6],德语音视频自然语音库[7]和日语JST/CREST ESR库[8];马来西亚语音库[9]收集了对话语音,标注了不平滑以及填充间断等语言现象,但未标注情感信息;日本UU(Utsunomiya University)语音库[10]标注了副语言信息[11].
本文结合中国社会科学院(简称社科院)制定的标注符号和研究需要,主要做了以下工作:首先根据北京航空航天大学(简称北航)录制的双模情感语音数据库制定了详细的语音数据库标注规则,考虑到标注的规范化,采用了社科院设计的一部分标注符号;然后对5名标注者进行培训,培训之后标注者开始标注语音数据库中的语音;最后为了确保标注质量,根据标注规则设计了一致性检测算法,检验几名标注者标注结果的一致性好坏.本文的工作与其他语音数据库不同之处在于:①录制的情感语音数据库为双模的,包括语音波形图和EGG信息,信息更丰富;②除了标注基本的汉字转换和音节等信息外,还标注了与清音、静音、浊音、情感、副语言信息和重音等相关的信息,目前国内其他情感语音数据库中未有如此完整的标注信息;③设计了一致性检测算法并对标注过的语音进行了一致性测试,实验结果表明不同标注者标注的一致性较高,说明语音数据库的质量较高.
2 汉语双模情感语音数据库的设计为了获得高质量的情感语音数据库,本文建立了北航汉语双模情感语音数据库(Chinese Dual-mode Emotional Speech Database,CDESD),并对数据采集过程以及对被试者的诱导方式进行了设计.
2.1 实验条件双模是指语音录制过程中同时采集了语音信息和电声门图信息.说话人包括20名年龄在21~23岁的大学生(13男,7女),每位说话人根据预先设定好的20条语句进行发音,每句话表达7种不同的情感,分别是悲伤、高兴、害怕、惊奇、平静、生气、嫌恶,每条语句发音3到5遍不等,后期经过拆分和删选,每条保留3遍,共得到8 400条语句.表 2描述了北航情感语音数据库录音文本,要求文本无某一方面的情感倾向,有较高的情感自由度,能施加各种情感进行分析比较,并且是口语化的陈述句.录音时间选择在较安静的晚上,地点是在密闭空旷的实验室.录音设备采用笔记本电脑,外接创新Audigy 2 NX USB接口声卡,台式麦克风,录音软件采用GoldWave V5.14,采样率为44 100 Hz,16 b量化.
表 2 北航情感语音数据库录音文本Table 2 Recorded text of Beihang emotional speech database
| 语句编号 | 语句内容 |
| 1 | 啊,你可真伟大呀 |
| 2 | 快点干 |
| 3 | 这下完了 |
| 4 | 啊,下雨了 |
| 5 | 太棒了 |
| 6 | 我真的以为你是这个意思 |
| 7 | 我在论文上看到你的名字了 |
| 8 | AC米兰赢球了 |
| 9 | 我这次考试刚刚通过 |
| 10 | 今天是星期天 |
| 11 | 你这人 |
| 12 | 电话铃响了 |
| 13 | 他就快来了 |
| 14 | 路上人真多啊 |
| 15 | 明天我要搬家了 |
| 16 | 这件事是他干的 |
| 17 | 你这段时间变瘦了 |
| 18 | 过两天学校就要开学了 |
| 19 | 昨天晚上我做了一个梦 |
| 20 | 有一辆车向我们开过来了 |
表选项
2.2 数据采集过程的设计由工作人员为被试者带上电声门图仪的采集工具,面前放置麦克风.①采集前先进行信号的测试,尤其注意电声门图和语音信号是否有削顶现象,适当地调整电脑音量或者电声门图和语音采集的放大倍数,声音大小也可以通过调整麦克与人的距离实现.②同时保证测试环境的绝对安静,测试时告知被试者不能随便移动,周围不能发出声响.③被试者以尽量真实的情感表达出7种不同的、区分度较高的情感状态,不需要过分夸张的成分.④测试中,需要与被试者多进行沟通,引导其感情,舒缓其情绪,使其放松,当被试者表达不理想时,重复4~6次甚至更多.⑤实验中,应让被试者有足够的休息时间,期间也需要尽量多的沟通交流,调节被试者状态.
2.3 提示的设计为了获得被试者的7种情感数据,实验前对表 2中的每一条语音及相应的情感,都进行了情景设置,建立了一个完整的含有140场情景的表.例如对第4条语句“啊,下雨了”,当表达悲伤情感时,设置情景为:“一位诗人,想起怀才不遇,看见阴沉的天空,淅沥的小雨,有感而发:啊,下雨了!”;当表达高兴情感时,设置情景为:“入春以来,整个地区没有掉过一滴雨,以土地为生的农民们躲在家中感慨春雨贵如油.突然有一天,外边雷声大作,你马上跑入雨中,高兴地说:老天开眼,啊,下雨了!”.
3 情感语音数据库标注规则社科院语音研究室根据国际语音****团体制定的可机读的音段标注体系SAMPA(Speech Assessment Methods Phonetic Alphabet)和韵律标注体系ToBI(Tones and Break Indices)设计了适用于汉语标注的SAMPA-C和ToBI-C等标注符号体系,并根据指定的符号标注了很多语音数据库,例如DFEIC(Database of Functional and Emotional Intonation in Chinese)语音数据库[25],该库收集了电视节目和谈话节目的语音数据,主要用于情感中的声调识别,但是仅标注了两层信息,分别是音节层和韵律层;自然口语库[26]总共标注了7层信息,包括韵律和语言学标注,主要用于语音合成和韵律识别.本文的汉语双模情感语音数据库不但包含EGG信息,而且加入了情感信息的标注,为情感识别提供丰富的信息.
根据CDESD,制定了详细的标注规则.标注规则包括标注的一致性、连贯性,标注符号的易记性,但同时还需要遵循的一条原则是允许标注的不确定性和差异性存在,即允许不同的标注者对同一条语音中的情感、重音、声调等有不同的理解,避免向用户提供错误信息.标注软件使用Praat 5.3.59 ,标注内容一共包括8层:第1层是文字转换层(HZ),第2层是音节层(PY),第3层是声韵母层(SY),第4层是清音静音浊音层(SUV),第5层是副语言信息层(PARAL),第6层是情感层(EMO),第7层是重音指数层(ST),第8层是语句功能层(FU).下面详细介绍每一层的标注内容和标注规则.
3.1 文字转换层(HZ)文字转换层的主要工作就是将语音转化为文字,也是语音标注中最基本的标注内容,文字标注必须包括文字信息和基本的副语言信息,文字标注的要点是汉字和副语言信息的准确标注,其中副语言信息采用通用的副语言符号表示.本文的副语言符号参考社科院语言研究所语音研究室制定的一些基本的副语言符号[27].
3.2 音节层(PY)音节层主要标注正则的拼音和声调,声调标注在音节之后,汉语中的声调包括轻声、一声、二声、三声和四声,分别用0、1、2、3、4表示,声调标在音节之后.例如:a0、tian1、ren2、guo3、fang4.标注时标注者通过听语音将原始语音划分为音节,音节的划分也是标注中的难点,为了保证不同标注者的标注误差在5 ms内,同时也规定了更加详细的标注细则.
3.3 声母/韵母层(SY)汉语中,一个完整的音节一般由声母和韵母组成.声母是在韵母之前的辅音,韵母是除去声母和音调之外的部分.声母、韵母标注时,对应于拼音层,将每个音节的声母、韵母、声母和韵母中间的过渡发音进行标注,声调标注在韵母之后.为了区分普通话中正则的声调,声韵母层的声调标注为实际发音的声调,分别用_1、_2、_3、_4表示,轻声用“_0”表示.例如:shuo标注为:声母段为sh+u,韵母段为uo_1.
3.4 清音静音浊音层(SUV)清音、静音和浊音层的标注目的在于划分语音中的清音S(Silence)、静音U(Unvoiced)、浊音V(Voiced).如图 1所示,图中包含3个子图,从上至下依次代表:语音波形图(channel 1)、电声门图(channel 2)、语谱图.判断静音、清音和浊音的一般简易方法是:观察电声门图波形,电声门图中有波形的部分代表浊音,电声门图中无波形而语音波形图中有波形的部分则代表清音,语音波形图和电声门图中均无波形的部分代表静音.一般地,电声门图中有波形的部分,对应的语谱图中也会对应地显示基频曲线(不包括基频错误点),即浊音,否则为清音或静音,进一步判断清音和静音主要通过观察语音波形图,清音有语音波形,而静音无语音波形.当然标注者还要结合语音知识进行仔细划分.
 |
| 图 1 语音波形图和电声门图 Fig. 1 Speech waveforms and EGG |
| 图选项 |
3.5 副语言信息层(PARAL)副语言信息(Paralinguinstic Information)指语言中非音段特征的信息,如拉长音、喘气声、语气词和咳嗽声等.副语言信息是以情感为导向的情感标签,描述了听话人对语音中情感的理解,在情感语音合成以及情感语音交互研究中至关重要[23],同时副语言信息可以为语音情感识别提供丰富的特征,Divillers和Vidrascu[28]、Truong等[29]、Arimoto等[30]都进行了副语言信息的研究.表 3为一部分基本的副语言标注符号[31].
表 3 副语言信息标注符号 Table 3 Annotation symbols of paralinguistic information
| No. | 副语言学现象 | 符号 | |
| 开始 | 结束 | ||
| 1 | 拉长(拖音)lengthening | LE< | LE> |
| 2 | 喘气breathing | BR< | BR> |
| 3 | 笑声laughing | LA< | LA> |
| 4 | 哭声crying | CR< | CR> |
| 5 | 咳嗽coughing | CO< | CO> |
| 6 | 犹豫(间断) disfluency | DS< | DS> |
| 7 | 口误error | ER< | ER> |
| 8 | 静音(沉默) silence | SI< | SI> |
| 9 | 含混音murmur/uncertain segment | UC< | UC> |
| 10 | 语气词modal/exclamation | MO< | MO> |
| 11 | 咂嘴音smack | SM< | SM> |
| 12 | 非汉语词汇non-Chinese | NC< | NC> |
| 13 | 吸气(吸鼻音) sniffle | SN< | SN> |
| 14 | 打哈欠yawn | YA< | YA> |
| 15 | 叠接(重叠发音) overlap | OV< | OV> |
| 16 | 吞咽声deglutition | DE< | DE> |
| 17 | 消嗓(清嗓子) hawk | HA< | HA> |
| 18 | 打喷嚏sneezes | SE< | SE> |
| 19 | 填充停顿filled pause | FP< | FP> |
| 20 | 颤音trill | TR< | TR> |
表选项
3.6 情感层(EMO)情感层是标注该条语句表达的情感类型及情感的强烈程度.语音数据库中包括的7种情感类型,分别为:b:悲伤;s:生气;j:惊奇;h:害怕;g:高兴;x:嫌恶;p:平静.标注者根据7种情感标注出实际表达的情感,同时,将说话人表达的情感强烈程度划分为3级,以打分的形式进行,满分5分,分数越高,代表情感表达越充分.具体的对应关系是:情感难以辨别:1、2分;有情感但情感表达不明显:3分;情感表达良好:4、5分.为了能更准确地反应语音中的情感,标注时采用对每一种情感都打分的形式进行,情感所得的分数越高,代表该种情感越明显,例如一条语句标注为:b4 g1 h1 j1 p1 s1 x1,说明该条语句表达的是悲伤的情感,并且情感表达比较强烈.
3.7 重音指数层(ST)重音指数是指根据每一个音节发音的轻重程度赋予其一个数值.本文将重音指数划分为4级,分别用1、2、3、4表示,从1到4代表重音越来越强.
3.8 语句功能层(FU)根据语音数据库中的情感类型,目前语句功能层主要标注4种语句类型,分别是:陈述句declarative、疑问句interrogative、感叹句exclamatory、祈使句imperative.图 2为一条完整的语音标注示例,包含4层主要信息,从上往下依次为:语音波形图、电声门图、语谱图、1~8层标注信息.在标注信息中,最左侧竖列的数字代表标注的层数,最右侧代表标注层的名字,中间代表标注内容.例如:第1层为HZ层,标注内容为“哎[MO][LE],你可真伟大呀[MO][LE]!”.
 |
| 图 2 语音标注示例 Fig. 2 Speech annotation example |
| 图选项 |
4 一致性检测算法一致性检测[31]是指不同的语音标注者标注相同的语音,然后对标注的结果进行对比,观察和分析标注结果的相同性和差异性.语音手工标注的一致性是评价语音质量好坏和标注系统是否完备的重要指标.为了保证情感语音数据库的标注质量,同时检验标注规则的完整性,通过做一致性检测,可以更好地发现标注中存在的问题,从而及时完善标注规则,也可以更好地理解语音的特点和语音数据库的质量.
针对标注规则,设计了相应地一致性检测算法.对于汉字转换层,由于语音文本是预先设定好的,所以HZ层没有必要进行一致性检测.另外,语句功能层受标注者主观情绪影响较大,暂定不做一致性检测.通过对文献[31]中一致性检测的理解,结合本文制定的标注规则,对其他6层分别设计了对比算法.
1) PY层、SY层.PY层的标注内容是正则的音节和声调,SY层标注的是声母、韵母和实际的声调.所以在这2层的对比中涉及到是否考虑声调一致的问题,因为不同标注者对语句中表达的情感理解有差异,对声调的理解也有差异,所以无论声调相同与否,只要音节相同时,即判断为标注内容相同.设两个标注者为A和B,则具体对比过程是:将待对比的当前层中标注信息理解为由多段组成,每一段的信息包括该音节的起始时间、截止时间和标注内容.则两人标注的一致性可以通过式(1)进行计算:
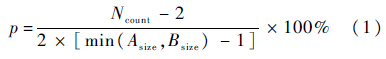
式中:p代表一致性结果;Ncount代表标注者A、B标注结果一致的分割点数;Asize和Bsize分别代表标注者A、B在该层标注的音节段数.
图 3为一致性检测的算法流程图.具体的对比过程为
 |
| 图 3 一致性检测算法流程图 Fig. 3 Algorithm flowchart of consistency detection |
| 图选项 |
令
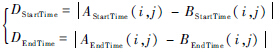
则对于同一条语音,AStartTime(i,j)代表标注者A标注的语音中第i层第j段的起始时间;AEndTime(i,j)代表标注者A标注的语音中第i层第j段的结束时间;BStartTime(i,j)代表标注者B标注的语音中第i层第j段的起始时间;BEndTime(i,j)代表标注者B标注的语音中第i层第j段的结束时间.将标注者A和标注者B在该层的每一段进行遍历对比,包括音节和声调的对比,然后进行下面的判断:
① 若
 , 则A和B有2个相同的分割点,即相同的音节有两个一致点.
, 则A和B有2个相同的分割点,即相同的音节有两个一致点.② 若
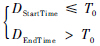 , 则A和B有一个相同的分割点.
, 则A和B有一个相同的分割点.③ 若
 , 则A和B有一个相同的分割点.
, 则A和B有一个相同的分割点.④ 若
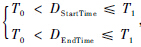 , 则A和B无相同的分割点.
, 则A和B无相同的分割点.其中T0代表两人标注的误差大小,标注过程中,规定2名标注者的时间误差限制在5 ms内;T1用来区分两个不同音节,此处限制在20 ms内,避免一句话中有同音字时,一个同音字与另一个同音字判断为一致.
2) SUV层.SUV层的内容不包括声调,所以无需判断音调是否一致,其余判断流程和计算公式与PY层一样.
3) PARAL层.标注副语言信息时,符号是标在某个时间点上,而非一个时间间隔内,所以该层判断时只需要判断某一个时间点以及该点上的标注内容即可.具体的判断方法如下:
若|ATime(i,j)-BTime(i,j)|≤T0,且标注内容相同时,则A和B标注一致,否则认为A和B标注不一致,其一致性计算公式为
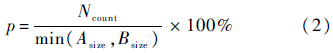
4) EMO层.由于每一句话的情感层标注内容包括7种情感类型和其对应的程度,所以应用欧氏距离公式比较其一致性,为了表示高的分数代表一致性高,低的分数代表一致性低,将欧氏距离公式表示为
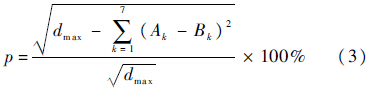
式中:dmax=(a-b)2×c,代表两人标注的结果完全相反时的分数,a代表最高分,b代表最低分,c代表情感种类总数,在本次标注中,a=5,b=1,c=7;Ak和Bk分别代表相应的情感所得分数,即情感程度,其中k=1,2,…,7,代表 7种情感类型.
5) ST层.ST层标注的是重音的程度,当说话人根据录音文本准确表达并且发音清晰时,则该层的重音段数应该是固定的,但是实际上说话人表达感情时会自发地增加、减少或者改变一些语气词,导致该层的重音段数不一致.因此该层采用与PY层相同的对比和计算方法,不同的是标注内容是否相同的判断,认为1和2的重音轻重程度相同,3和4的重音轻重程度相同.
5 一致性检测结果为了保证情感语音数据库标注的质量,在正式标注之前进行了标注测试,标注结果的优劣采用第3节中的一致性算法进行检测,测试语音由一名男生的语音和一名女生的语音组成,每人的语音均包括7种情感,每种情感20句话,一共是280条语句.表 4~表 9所示为一致性检测结果,A、B、C、D和E代表 5名不同的标注者.A、B、C3名标注者分别对同一男生语音标注,标注误差T0取5、8、10 ms时,分别对标注结果进行一致性检测,对比结果如表 4、表 5和表 6所示.C、D、E 3名标注者分别对同一女生语音标注,标注误差T0取5、8、10 ms时,分别对标注结果进行一致性检测,对比结果如表 7、表 8和表 9所示.
表 4 T0=5 ms的男生语音一致性对比结果 Table 4 Comparison results of consistency for male speech when T0=5 ms
| 标注者 | p/% | ||||
| PY | SY | SUV | PARAL | ST | |
| A-B | 61.72 | 63.01 | 73.01 | 66.32 | 63.55 |
| A-C | 60.49 | 61.42 | 72.84 | 69.86 | 63.11 |
| B-C | 61.41 | 62.86 | 74.06 | 69.92 | 64.52 |
| 平均 | 61.21 | 62.43 | 73.30 | 68.70 | 63.73 |
表选项
表 5 T0=8 ms的男生语音一致性对比结果 Table 5 Comparison results of consistency for male speech when T0=8 ms
| 标注者 | p/% | ||||
| PY | SY | SUV | PARAL | ST | |
| A-B | 67.41 | 69.22 | 77.54 | 69.40 | 70.23 |
| A-C | 66.00 | 65.40 | 75.71 | 73.06 | 69.21 |
| B-C | 68.85 | 69.54 | 78.97 | 74.17 | 72.36 |
| 平均 | 67.42 | 68.05 | 77.41 | 72.21 | 70.60 |
表选项
表 6 T0=10 ms的男生语音一致性对比结果 Table 6 Comparison results of consistency for male speech when T0=10 ms
| 标注者 | p/% | ||||
| PY | SY | SUV | PARAL | ST | |
| A-B | 70.46 | 72.10 | 78.88 | 71.37 | 73.83 |
| A-C | 69.70 | 69.01 | 78.04 | 74.65 | 73.01 |
| B-C | 72.29 | 72.96 | 81.17 | 75.93 | 76.32 |
| 平均 | 70.82 | 71.36 | 79.36 | 73.98 | 74.39 |
表选项
表 7 T0=5 ms的女生语音一致性对比结果 Table 7 Comparison results of consistency for female speech when T0=5 ms
| 标注者 | p/% | ||||
| PY | SY | SUV | PARAL | ST | |
| C-D | 57.01 | 59.92 | 72.21 | 65.98 | 61.49 |
| C-E | 50.69 | 55.41 | 65.41 | 63.08 | 52.47 |
| D-E | 50.40 | 55.12 | 66.46 | 63.62 | 55.96 |
| 平均 | 52.70 | 56.82 | 68.03 | 64.23 | 56.64 |
表选项
表 8 T0=8 ms的女生语音一致性对比结果 Table 8 Comparison results of consistency for female speech when T0=8 ms
| 标注者 | p/% | ||||
| PY | SY | SUV | PARAL | ST | |
| C-D | 63.27 | 65.31 | 76.45 | 69.23 | 68.34 |
| C-E | 58.70 | 61.85 | 72.87 | 69.17 | 64.69 |
| D-E | 58.70 | 61.85 | 72.87 | 69.17 | 64.69 |
| 平均 | 60.22 | 63.01 | 74.06 | 69.19 | 65.91 |
表选项
表 9 T0=10 ms的女生语音一致性对比结果 Table 9 Comparison results of consistency for female speech when T0=10 ms
| 标注者 | p/% | ||||
| PY | SY | SUV | PARAL | ST | |
| C-D | 66.50 | 68.16 | 78.52 | 70.27 | 71.70 |
| C-E | 61.17 | 64.11 | 72.07 | 66.50 | 63.74 |
| D-E | 62.05 | 64.36 | 75.36 | 71.37 | 68.14 |
| 平均 | 63.24 | 65.54 | 75.32 | 69.38 | 67.86 |
表选项
观察对比结果,可以得出以下结论:
1) 对于男生语音,T0=5 ms时,各层的一致性综合平均为65.87%,T0=8 ms时,一致性平均为71.19%,T0=10 ms时,一致性平均为73.98%.对于女生语音,T0=5 ms时,一致性平均为59.68%,T0=8 ms时,一致性平均为66.48%,T0=10 ms时,一致性平均为68.27%.
2) 对比表 4、表 5和表 6,可以看出,当T0从5 ms增大至8 ms时,各层的一致性都有提高,最低可提高4%,最高可提高7%,平均提高了5.5%;当T0从5 ms增大至10 ms时,对比各层的一致性,最低可提高5%,最高可提高11%,平均提高了8%.从表 7、表 8和表 9中可以看出,当T0从5ms增大至8 ms时,各层的一致性最低可提高4%,最高可提高9%,平均提高了6.5%;当T0从5 ms增大至10 ms时,各层的一致性最低可提高5%,最高可提高11%,平均提高了8%.说明2名标注者之间的标注误差增大时,标注的一致性提高,限制的时间误差大小直接影响着一致性对比结果.
3) 观察表 4~表 9,可以发现SUV层的一致性最高,PY层和SY层的一致性较低.因为SUV层存在的差异性最小,容易区分,PY层和SY层的标注需要的语音知识较多,造成音节和声韵母的划分难度比较大.ST层重音程度的判断受标注者主观因素的影响比较大,例如标注时间、标注者心情、个人情感理解等.C-E、D-E的一致性结果较低,因为标注者E的语音基础知识较薄弱,直接影响其对语音的理解.另外,当长时间进行标注工作时,难免出现烦躁和难以判断的情形,这些都会影响标注的一致性.
4) 表 4~表 9整体的一致性比文献[31]中的低,分析造成整体一致性较低的原因有3点:①一致性检测的具体算法不同,虽然基本的检测标准都是标注符号和时间点误差,但是标注层数及每层具体的一致性算法不同,本文的一致性检测算法还考虑了分割段数,这可能造成一致性偏低.因为本文的一致性检测算法原理是一致点的个数占总个数的比重,所以当语句较短、音节较少时,每个一致点占的比重就会较大,每个点的错误都会导致一致性百分比大大降低.②一致性检测算法中规定的时间误差较短,这对标注者的专业要求非常高,实验结果中可以看出,将对比误差从5 ms扩大到10 ms时,一致性会大大提高.③一致性对比算法设计中,对标注准确性的要求严格程度不同.
设计的一致性检测算法除了可以反映出2个人标注的一致性结果,同时还可以将2个人标注不一致的时间点以及内容准确地显示出来,返回的内容以txt文件存储,方便标注人员检查标注错误的原因.txt文件中显示的信息包括标注人员、文件序号、文件名、标注层、一致性检测结果、不一致的时间点及对应的不一致内容.表 10为标注者A和B标注结果对比的详细信息示例,文件名为bM0C03011.TextGrid,引号内无内容时代表标注内容为空,从表 10中可以看出,在SY层的0.218 9 s时刻,一个人标记为“ai_0”,另一个人标记为“ai_4”,后面的_0和_4代表实际发音中的声调,属于主观判断,标注者的判断受外界环境等因素影响比较严重,所以在检测的时候认定音节相同而仅仅声调不同的情况为一致,不影响检测的分数,而1.642 2 s时刻和1.647 55 s时刻相差5.35 ms,仅比5 ms大0.35 ms,检测结果为不一致,由此也可以发现一致性检测中对时间的要求十分苛刻.
表 10 标注中不一致点详情示例 Table 10 Example of inconsistency details in annotation
| 标注层 | 不一致时间点/s | 不一致内容 | 一致性结果/% |
| PY | xminA:1.642 2xmaxA:1.456 3… | A:“”B:“sil”… | 94.44 |
| SY | xminA:0.218 9… | A:“ai_0”B:“ai_4”… | 96.15 |
| SUV | xminA:1.642 2xminB:1.647 5… | A:“”B:“S”… | 95.83 |
| PARAL | numberA:0.218 9… | markA:“MO<”markB:“MO| 71.43 | |
| ST | xminA:0.680 44… | A:“1”B:“4”… | 83.303 |
表选项
6 结 论本文总结了国内外情感语音数据库的发展现状,据此做了以下工作:
1) 建立了一个汉语双模情感语音数据库,与其他情感语音数据库主要不同在于包含EGG信息.
2) 制定了一套详细的情感语音数据库标注规则,并对汉语双模情感语音数据库进行标注.
3) 根据规则设计了相应的一致性检测算法,综合对男生和女生语音检测结果表明:
① T0=5 ms时,各层的一致性平均为62.77%,T0=8 ms时,一致性平均为68.84%,提高了5%;T0=10 ms时,一致性平均为71.13%;提高了8%.
② 算法可以反映出标注错误的位置和内容,便于标注者修改错误之处.
③ 算法可以有效地对标注结果进行对比,5名标注者对语音的理解较一致,证明了语音数据库的质量较好,为后续标注工作提供了保障,也为其他语音数据库的标注提供了有效的标注和检验方法.
本文还有需要进一步改善的内容:
1) 在保证标注时间误差相同的条件下,通过改进一致性检测算法,使新的一致性检测算法能更合理、更好地反映出真实的一致性;通过加强标注者的专业培训,保证不同标注者对相同语音有更一致的理解,使标注符号更一致,提高一致性.
2) 由于标注过程中对EMO层的标注规则进行了修改,部分标注内容尚未修改完,所以尚未标出EMO层的一致性,作为下一步的工作重点.
全部语音标注完成后,可以建立一个完整的情感语音数据库,为语音情感识别的模型建立提供了可靠的汉语双模情感语音数据库,对国内外情感语音数据库进行了有益补充.
参考文献
| [1] | 韩文静,李海峰.情感语音数据库综述[J].智能计算机与应用,2013,3(1):5-7.Han W J,Li H F.A brief review on emotional speech databases[J].Intelligent Computer and Applications,2013,3(1):5-7(in Chinese). |
| Cited By in Cnki (1) | |
| [2] | 徐露,徐明星,杨大利.面向情感变化检测的汉语情感语音数据库[J].清华大学学报:自然科学版,2009,49(S1):1413-1418.Xu L,Xu M X,Yang D L.Chinese emotional speech database for the detection of emotion variations[J].Journal of Tsinghua University:Natural Science,2009,49(S1):1413-1418(in Chinese). |
| Cited By in Cnki (6) | |
| [3] | 薛雨丽,毛峡,张帆.BHU人脸表情数据库的设计与实现[J].北京航空航天大学学报,2007,33(2):224-228.Xue Y L,Mao X,Zhang F.Design and realization of BHU facial expression database[J].Beijing University of Aeronautics and Astronautics,2007,33(2):224-228(in Chinese). |
| Cited By in Cnki (28) | |
| [4] | Ververidis D,Kotropoulos C.A state of the art review on emotional speech databases[C]∥Proceedings of 1st Richmedia Conference.Lausanne:The European Association for Signal Processing,2003:109-119. |
| Click to display the text | |
| [5] | El Ayadi M,Kamel M S,Karray F.Survey on speech emotion recognition:Features,classification schemes,and databases[J].Pattern Recognition,2011,44(3):572-587. |
| Click to display the text | |
| [6] | Greasley P,Setter J,Waterman M,et al.Representation of prosodic and emotional features in a spoken language database[C]∥Proceedings of the 13th International Congress of Phonetic Sciences.Paris:IPA,1995:242-245. |
| [7] | Grimm M,Kroschel K,Narayanan S.The Vera am Mittag German audio-visual emotional speech database[C]∥IEEE International Conference on Multimedia and Expo.Piscataway,NJ:IEEE Press,2008:865-868. |
| Click to display the text | |
| [8] | Campbell N.The JST/CREST ESP project-a mid-term progress report[C]∥1st JST/CREST Intl.Workshop Expressive Speech Processing.Baixas:ISCA,2003:61-70. |
| [9] | Chong T Y,Xiao X,Tan T P,et al.Collection and annotation of malay conversational speech corpus[C]∥International Conference on Speech Database and Assessments (Oriental COCOSDA 2012).Piscataway,NJ:IEEE Press,2012:30-35. |
| Click to display the text | |
| [10] | Mori H,Satake T,Nakamura M,et al.Constructing a spoken dialogue corpus for studying paralinguistic information in expressive conversation and analyzing its statistical/acoustic characteristics[J].Speech Communication,2011,53(1):36-50. |
| Click to display the text | |
| [11] | Mori H,Hitomi T.Annotating conversational speech for corpus-based dialogue speech synthesizer-a first step[C]∥International Conference on Speech Database and Assessments (Oriental COCOSDA 2012).Piscataway,NJ:IEEE Press,2012:135-140. |
| Click to display the text | |
| [12] | CASIA.Database of Chinese emotional sppech[EB/OL].Beijing:Chinese Linguistic Data Consortium,2008(2010-10-09)[2014-12-8].http:∥www.chineseldc.org/resource_info.php?rid=76. |
| [13] | Pan Y C,Xu M X,Liu L Q,et al.Emotion-detecting based model selection for emotional speech recognition[C]∥IMACS Multiconference on Computational Engineering in Systems Applications.Piscataway,NJ:IEEE Press,2006,2:2169-2172. |
| Click to display the text | |
| [14] | Nwe T L,Foo S W,de Silva L C.Speech emotion recognition using hidden markov models[J].Speech Communication,2003,41(4):603-623. |
| Click to display the text | |
| [15] | Morrison D,Wang R,de Silva L C.Ensemble methods for spoken emotion recognition in call-centres[J].Speech Communication,2007,49(2):98-112. |
| Click to display the text | |
| [16] | Fu L,mao X,Chen L.Speaker independent emotion recognition based on SVM/HMMS fusion system[C]∥International Conference on Audio,Language and Image Processing,2008.Piscataway,NJ:IEEE Press:61-65. |
| Click to display the text | |
| [17] | Zhou J,Wang G,Yang Y,et al.Speech emotion recognition based on rough set and SVM[C]∥IEEE International Conference on Cognitive Informatics.Piscataway,NJ:IEEE Press,2006,1:53-61. |
| Click to display the text | |
| [18] | Hu H,Xu M X,Wu W.GMM Supervector based SVM with spectral features for speech emotion recognition[C]∥2007 IEEE International Conference on Acoustics,Speech and Signal Processing.Piscataway,NJ:IEEE Press,2007:413-416. |
| Click to display the text | |
| [19] | Burkhardt F,Paeschke A,Rolfes M,et al.A database of German emotional speech[C]∥Interspeech 2005.Baixas:ISCA,2005,5:1517-1520. |
| Click to display the text | |
| [20] | Schuller B.Towards intuitive speech interaction by the integration of emotional aspects[C]∥IEEE International Conference on Systems,Man and Cybernetics.Piscataway,NJ:IEEE Press,2002,6:6-12. |
| Click to display the text | |
| [21] | Engberg I S,Hansen A V.Documentation of the danish emotional speech database[R].Denmark:Aalborg University,1996. |
| [22] | Hansen J H L,Bou-Ghazale S E,Sarikaya R,et al.Getting started with SUSAS:A speech under simulated and actual stress database[C]∥EUROSPEECH 1997.Baixas:ISCA,1997,97(4):1743-1746. |
| Click to display the text | |
| [23] | Breazeal C,Aryananda L.Recognition of affective communicative intent in robot-directed speech[J].Autonomous Robots,2002,12(1):83-104. |
| Click to display the text | |
| [24] | Slaney M,Mcroberts G.BabyEars:A recognition system for affective vocalizations[J].Speech Communication,2003,39(3):367-384. |
| Click to display the text | |
| [25] | Wang M,Li Y,Lin M,et al.The development of a database of functional and emotional intonation in Chinese[C]∥International Conference on Speech Database and Assessments (Oriental COCOSDA 2011).Piscataway,NJ:IEEE Press,2011:136-141. |
| Click to display the text | |
| [26] | Li A J.Chinese prosody and prosodic labeling of spontaneous speech[C]∥International Conference on Speech Prosody 2002.Baixas:ISCA,2002. |
| Click to display the text | |
| [27] | 刘亚斌.汉语自然口语的韵律分析和自动标注研究[D].北京:中国社会科学院研究生院,2003.Liu Y B.Prosodic analysis and automatic prosodic-labeling for Chinese spontaneous speech[D].Beijing:Graduate School of Chinese Academy of Social Sciences,2003(in Chinese). |
| Cited By in Cnki (6) | |
| [28] | Devillers L,Vidrascu L.Real-life emotions detection with lexical and paralinguistic cues on human-human call center dialogs[C]∥Interspeech 2006.Baixas:ISCA 2006:801-804. |
| Click to display the text | |
| [29] | Truong K P,Neerincx M A,van Leeuwen D A.Assessing agreement of observer-and self-annotations in spontaneous multimodal emotion data[C]∥Interspeech 2008.Baixas:ISCA,2008:318-321. |
| Click to display the text | |
| [30] | Arimoto Y,Kawatsu H,Ohno S,et al.Emotion recognition in spontaneous emotional speech for anonymity-protected voice chat systems[C]∥Ninth Annual Conference of the International Speech Communication Association.Baixas:ISCA,2008:322-325. |
| Click to display the text | |
| [31] | 李爱军,陈肖霞,孙国华,等.CASS:一个具有语音学标注的汉语口语语音库[J].当代语言学,2002,4(2):81-89.Li A J,Chen X X,Sun G H,etal. CASS:A Chinese annotated spontaneous speech corpus[J].Contemporary Linguistics,2002,4(2):81-89(in Chinese). |
| Cited By in Cnki (14) |
