 ,1,2, 黎建辉,1,*, 张丽丽,1
,1,2, 黎建辉,1,*, 张丽丽,1Data Classification of the Sustainable Development Goals Based on Unsupervised Learning
LEI Sheng,1,2, LI Jianhui,1,*, ZHANG Lili,1通讯作者: *黎建辉(lijh@cnic.cn)
收稿日期:2021-02-4
| 基金资助: |
Received:2021-02-4
作者简介 About authors

雷声,中国科学院计算机网络信息中心,中国科学院大学,硕士研究生,研究方向为自然语言处理、机器学习、无监督学习等。
本文中负责数据处理、模型设计与实验、论文撰写。
LEI Sheng is a graduate student of Com-puter Network Information Center of Chinese Academy of Sciences. Her research directions are Natural Language Process, Machine Learning, unsupervised learning, etc.
In this paper, she is responsible for data processing, model design and experimentation, and thesis writing.
E-mail:

黎建辉,中国科学院计算机网络信息中心,博士,研究员,博士生导师,发表论文80余篇,主要研究方向为数据密集型计算与应用、大数据资源开放共享、大数据挖掘与应用等。
本文负责分类算法框架指导和实验指导。
LI Jianhui, PhD, is a researcher and doctoral supervisor at Com-puter Network Information Center, Chinese Academy of Sciences. He has published more than 80 papers. His main research directions are data-intensive computing and applications, open sharing of big data resources, and big data mining and applications.
In this paper, he is responsible for algorithm framework design and experimental guidance.
E-mail:

张丽丽,中国科学院计算机网络信息中心,高级工程师,主要研究方向为开放科学、开放数据技术政策,信息经济学。
本文中负责模型指导和实验指导。
ZHANG Lili is a senior engineer at Computer Network Infor-mation Center, Chinese Academy of Sciences. Her main research directions are open science, open data technology policy, and information economics.
In this paper, she is responsible for model guidance and exper-imental guidance.
E-mail:

摘要
【目的】联合国可持续发展目标(SDGs)是联合国于2015年提出的指导全世界在2015-2030年间发展方向的目标,涵括了社会、经济、环境三个方向上的海量数据。针对SDGs标注数据少、数据量大、难以查找利用的特点,本文旨在无监督地对SDGs数据进行分类。【方法】本文首先利用结合textrank和相对词频的关键词提取算法从SDGs元数据集中提取类别描述信息,再利用基于词向量的无监督文本分类算法对SDGs数据进行了分类。【结果】在联合国官方提供的SDGs数据库上的分类实验表明,本文分类模型的F1-micro score达到了0.813,对比SeedBTM提高了33%,相较于不擅长短文本分类的STM及DescLDA上更是分别提升了39%和 52%,对比使用TFIDF和textrank所提取关键词的分类效果分别提升了7%和25%。【结论】本文所提基于textrank和相对词频的关键词提取方法具有较好地可用性,且相较于目前主流的主题模型算法,本文所提基于词向量的无监督分类方法能够取得更好的效果。
关键词:
Abstract
[Objective] The Sustainable Development Goals (SDGs) are the goals proposed by the United Nations in 2015 to guide the direction of world development from 2015 to 2030, which include massive amounts of data in three aspects of society, economy, and environment. Since a huge amount of SDGs data are rarely labeled and hard to use, this paper tries to classify them with unsupervised models. [Methods] In this paper, we firstly use a keyword extraction algorithm combining textrank and relative word frequency to extract category description information from SDGs metadata set and then develop an unsupervised text classification algorithm based on word vectors to classify SDGs data. [Results] The experiments on the official SDGs database provided by the United Nations show that the F1-micro score of the proposed method reaches 0.813, which is 33%, 39%, 52% higher than SeedBTM, STM, and DescLDA models, respectively. When compared with TFIDF and textrank, keywords extracted by our model also outperform TFIDF and textrank with 7% and 25% higher F1-micro scores respectively. [Conclusions] The keyword extraction method proposed in this paper based on textrank and relative word frequency is effective. Compared with the current mainstream topic model algorithms, the unsupervised classification method based on word vector achieves better results.
Keywords:
PDF (9306KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
雷声, 黎建辉, 张丽丽. 基于无监督学习的可持续发展目标数据分类[J]. 数据与计算发展前沿, 2021, 3(4): 104-115 doi:10.11871/jfdc.issn.2096-742X.2021.04.009
LEI Sheng, LI Jianhui, ZHANG Lili.
引言
联合国可持续发展目标(Sustainable Develop-ment Goals,SDGs)是联合国在2015年9月制定的17个全球发展目标,旨在从2015年—2030年间以综合方式彻底解决社会、经济和环境三个维度的发展问题,从而转向可持续发展道路[1]。SDGs数据对可持续发展工作具有极为重要的指导意义,它对可持续发展给出了细致而全面的数据指标,涉及范围极广,值得研究的相关数据也极多。数据与计算技术飞速发展,在科学研究中能够起到辅助与支撑的作用,甚至能够驱动和引领科学研究活动[2]。截至目前,对SDGs数据及工作进行研究讨论的中英文文献数量已经达到了数十万篇。SDGs所涉及的庞大数据量在为相关科研工作提供信息的同时也提高了科研人员的使用难度,要想在如此海量的数据中获得与研究目标相关的数据,就必须将数据进行合理的分类。机器学习时代的来临实现了很多技术上的应用[3]。联合国为SDGs中的每项指标都提供了详细的描述文档,基于机器学习利用这些描述文档为数据进行分类可以更好地为从事SDGs相关研究的科研人员提供便利。现有的文本分类算法大多属于有监督模型,它需要大量人工标注的文档作为训练集,而联合国官方能够提供的标记数据极少,利用有监督甚至半监督模型都难以得到令人满意的效果。且联合国为每个SDGs指标都制定了详细的描述文档,人工地根据这些文档对数据进行标记会是一个复杂而耗时的工程。因此,使用无监督算法来进行实际分类是更为合适的选择。本文基于数据描述无监督地对科学数据进行了SDGs相关性分类,主要分为以下两个阶段:
(1)类别描述信息筛选。本文综合textrank和相对词频统计(Relative Frequency,RF)的方法,无监督地从联合国所提供指标描述文档中提取指标关键词集,以此作为类别描述信息。
(2)数据分类。本文将类别信息和数据描述信息投影到同一语义空间中,基于相似度匹配的自学习算法无监督地对数据进行了分类。
在联合国官方所提供的官方数据集上的测试表明,我们对SDGs科学数据的分类是有效的;且相对于目前主流的基于主题模型的无监督文本分类算法而言,我们所提模型能够取得更好的效果。
1 相关工作
1.1 无监督文本关键词提取
无监督的文本关键词提取方法种类繁多,但按其原理大致可以分为以下三类:基于统计的方法、基于图结构的方法以及基于语义的方法。(1)基于统计的方法通常综合统计TFIDF[4]、词共现[5]、词频[6]、词性[7]等一系列指标信息,再根据这些指标进行排序。例如罗燕等人[6]通过齐普夫定律推导出文本中同频词数的计算公式,并综合词频统计和TFIDF进行了关键词提取;Barker等人[7]通过词频及词长等特征选择性提取名词短语作为文本关键词;Song等人[4]综合单词词性的语法信息和TFIDF信息提出了一种新闻关键词提取方法。这种方法简单易用,但需要大量文本进行对比统计,在文本数量较少的情况下效果不佳。
(2)基于图结构的方法将词语视作图中的节点,按照特定的规则为节点之间进行关联,据此迭代计算词语的重要性。典型地,Mihalcea等人[8]提出的textrank模型基于google所提Pagerank的链接分析理论,通过迭代计算节点边缘权重来计算词语重要性;Bellaachia等人[9]提出的NERank模型在节点边缘权重的基础上,也考虑了单词权重;Saroj等人[10]综合考虑词语节点的中心程度、位置、词频、及邻居频数来考虑节点的重要性,从而提取关键词。这种方法比较灵活,既可以仅利用文档本身的信息来完成关键词抽取,也可以很容易地融合外界权重、相似度等信息来综合构建词图网络。
(3)基于语义的方法通常使用PLSA[11]、LDA[12]等主题模型或者word2vec[13]等语言模型对文本和词汇进行语义建模,进而抽取关键词。例如石晶等人[14]基于LDA得到文本和词汇的主题分布,通过比对词与文档的主题分布情况来获取关键词;刘啸剑等人[15]利用文档和词语的主题信息并结合词语的统计特征来为候选词打分。这种方法能够获取语义相似性的关系,因此常常能够获得不错的效果。
本文综合了相对词频和textrank的方法从联合国提供的SDGs描述文档中抽取关键词,以得到SDGs类别描述词集。
1.2 无监督文本分类
现有的无监督文本分类研究按照其思想可被大致分为以下两类:基于相似度匹配的方法和基于主题模型的方法。(1) 基于相似度匹配的方法通常通过计算、对比类别描述和文本之间的相似度来实现分类,它并不关注样本本身,而是将文本和类别投影到同一语义空间中并直接对二者进行比较,广泛适用于各种数据集。例如Druck等人[16]首先预定义一批类别关键词,利用最大熵算法,最大化文档的预期类别分布与类别中相应关键词的类别分布之间的相似度来优化分类器参数;Chang等人[17]通过基于英文维基百科的显示语义分析(Explicit Semantic Analysis, ESA)来计算文档与类别描述之间的相似度,但这种方法需要准确地用词条描述来替换对应词条,难以推广到概念描述不够多的其他领域及数据集中;Song等人[18]同样利用ESA来评估文档-类别相似度,并通过对类别进行分层来解决类别重合,获得了良好的效果。
(2)基于主题模型的方法通常先学习文档集得到联合概率分布,再通过联合概率分布得到条件概率分布实现分类,它基于数据集中的共现分布进行推理,能够很好地分析文本本身的特点且不依赖于外界知识库,是目前主流的无监督文本分类方法。但由于主题模型的分布推理通常基于共现统计,当面对小规模数据集或短文本数据集时,词共现矩阵往往过于稀疏,因此在这些数据集上的应用效果并不理想。Xia等人[19]首先利用类别描述种子词产生少量文本,通过LDA推理得到类别的狄利克雷先验(主题-词矩阵),再通过词分布推断具体文本的类别分布; Li等人[20]直接利用类别描述种子词集和主题模型进行主题推断,从而完成对文本种类标签的预测;Yang等人[21]为了解决短文本数据集共现矩阵稀疏的问题,将文本中的词排列组合成二元词组来构建共现矩阵,但这种重复统计所带来的提升非常有限,效果依然不够理想。
由于基于主题模型的方法在短文本上应用效果不佳,而SDGs数据描述文本的长度通常在10~100词之间,属于短文本。因此,本文主要采用了基于相似度匹配的方法,一方面,本文利用词向量构建通用语义空间,直接通过文本-类别间的距离度量来对文本进行分类,以适应不同类型的文本数据;另一方面,也利用同类文本中词汇的相似分布,通过自训练算法对分类器进行迭代更新。
2 SDGs数据分类方法设计
本文对SDGs科学数据进行分类的流程框架如图1所示,主要包括数据提取和文本分类两个部分。图1
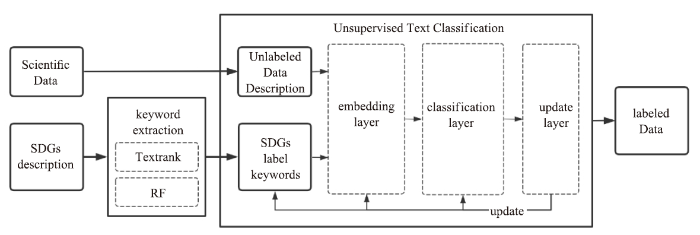 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1基于无监督的SDGs数据分类
Fig.1Unsupervised SDGs data classification
(1)数据提取。根据联合国提供的指标类别描述文档,利用综合textrank和相对词频统计的关键词抽取算法提取出SDGs类别关键词作为类别描述,提取待分类的科学数据中的标题及描述信息得到数据描述文本。
(2)文本分类。通过一个基于无监督的文本分类算法根据(1)中提取出的数据描述文本对科学数据进行归类。
2.1 SDGs类别关键词提取
由于本文提取类别关键词来表征类别信息,这些关键词应当具有两个特点:(1)能够概括类别;(2)能够与其他类别进行区分。前者需要利用常规的关键词抽取算法如TFIDF、textrank等对官方所给描述文档进行精炼提取,后者需要关键词为类别专属词或具有足够的类别区分度。在本文中,我们首先采用textrank初筛出类别关键词,再根据词频计算词语的相对词频,再次筛选得到具有区分度的词语集合作为最终的类别描述。首先,我们根据文本内部之间的共现关系构建词图,首先利用textrank公式迭代计算各个词语节点的重要度得分,初步筛选出较多的类别描述词;然后,我们通过公式(1)来统计获取类别i中候选词w的相对词频RF(w, i),为每个类进行再次筛选,得到少量具有类别区分度的最终类别关键词。
其中│Di│代表类别i中包含的文档数量,nw,i则为词语w在类别i中出现的次数,TF(w, i)代表词w在类别i中出现的频率。SDGs中每个类别中包含的文档数量可能有较大差别,因此在计算类间相对性时需要排除这个因素影响。
2.2 基于无监督的文本分类
本文所设计的基于词向量的无监督文本分类模型(Seedword and Embedding based Text Classification, SeedETC)以类别描述词集和待分类数据描述文本集及对应的初始化权重为输入,利用词向量将这些文本投影到同一语义空间,通过类EM算法的自训练迭代算法[21]更新分类器模型的相关参数,并输出文本对应的类别标签,主要包括以下四个步骤:(1)词向量编码:利用已有词向量模型对类别描述词集及待分类文本进行编码,得到词向量集;
(2)文本分类:根据词向量及文本权重对待分类文档进行分类;
(3)模型更新:对分类结果进行评估,更新部分样本的类别标记,更新类别描述词、类别词权重及文本权重。
(4)重复(1)、(2)、(3)步直到模型收敛。
2.2.1 词向量编码
词向量使得词之间存在“距离”概念,从而能够表征词之间的相似关系。使用词向量进行词的向量化表示时,能够充分考虑到文本的局部和整体信息[22]。本层将文档以及类别描述中的所有词表征为向量的形式。目前,主流词向量的表示方法有三种:一是基于词频统计的方式,比如使用全局矩阵分解的LSA[24]等,这种方式需要大量数据提供足够的共现统计信息,不适用于本文任务;第二种是基于局部上下文窗口的方式,如word2vec[25]、glove[26]等,能够用于多种场景,计算代价低,效果也很好,是目前主流的词向量表示方式;第三种则是基于预训练任务得到附属词向量产物的方式,如bert[27]等,这类模型相较于第二种效果更好,但其模型复杂,计算代价高,单纯作为词向量使用不够灵活。因此,本文采用了拼接大规模语料和新领域语料的glove词向量来完成单词的向量化编码。
由于glove是基于全局共现统计的算法,难以实现增量训练,而为了拟合数据集的分布,本文最终在经过大规模语料D0预训练得到的glove模型基础上,额外使用待分类数据SDGs元数据描述语料D1训练得到新数据分布的词向量,将这两种向量归一化后进行加权拼接,得到最终的词向量,如公式(2)所示:
其中,$ g_{D_{0_{ (w_{li})}} }$代表语料D0中词wli的glove向量,W(wl)则代表类别描述词w在类别l上的权重。
2.2.2 文本分类
在文本分类层,我们依据文档词与类别描述词间的距离对文本进行分类。与常见的先对词向量进行拼接或加权平均构造文本向量,通过计算待分类文本与类别描述文本的向量间距来衡量文本与类别相似度的方法不同,本文使用词作为一个独立的单位,并不根据文档对词进行整合。在分类时,本层通过词-词、词-类别、文本-类别3个阶段来计算文本与类别间的相似度,如算法1所示。

其中,由于一篇文本中具有很多通用词,在各个类别中分布都较为均匀,我们通过窗口Cd筛除掉这些对分类无意义的词,只保留与分类有关词的信息。
2.2.3 模型更新
本层的作用主要有以下两个方面:一方面是更新文本标记,利用改进的轮廓系数指标来评估分类结果,为被认为正确分类的文本更新类别标记;另一方面对分类器参数进行更新,利用分类结果、文本与类别及数据集中其他文本的相似度,更新分类器中的类别描述词及其权重、文本权重等参数。
(1)文本标签更新
本文通过改进原用于评估聚类效果的轮廓系数(silhouettes)算法[28]来评估每个节点与类别的相对相关性。假定在分类层我们认为文档d属于类别Li(d与类别Li的相似度最高),那么轮廓系数公式如式(3)所示。
很容易发现silhouettes公式的分母是为了除去相似度大小因素的影响而只关注距离的相对比例。但在实验中我们发现,相似度本身数值大小也非常重要,因此我们去掉了式(3)中的分母,据此得到改进的分类评估公式:
在每轮迭代时,根据剩余待分类样本数设定一个评估阈值,对所有分类评估分数高于阈值的样本更新其类别标签,剩余样本则投入下一轮训练。
(2)分类器参数更新
对于分类器,主要需要更新以下3种参数:类别描述词、类别描述词权重和文本权重。
由于我们需要的类别描述词需要满足对类别的高区分度条件,因此本文通过相对词频统计来更新每个类别的描述词。首先,从已更新标签的文本集中选出类别c中的高频词作为该类别候选词,并计算这些词在当前类与其他类别中的相对词频比例:
我们认为高频词可以有效表征类别,而相对词频比越高,说明这个词的类别区分度越高,最终筛选出相对词频比排名更高且满足最低阈值的少量词作为本轮分类器中更新的类别描述词。
由于我们利用了相对词频比来获取具有高区分度的关键词,单纯利用已更新标签的文本来更新其权重,将会导致权重偏高。为了获取更真实的词分布信息,我们借鉴了姜震等人[29]利用不精确的伪标签(Pseudo label)扩充训练集的思想,利用了全体样本来更新类别描述词的权重。将所有样本在当前轮次中的预测结果作为伪标签,通过词频统计来更新词权重。综合以上考虑,最终确定类别描述词权重W(w,c)更新公式如式(6)所示:
其中,α, β为比例参数,iternum表示词w加入类别描述词集时的当前迭代轮次。这是由于随着迭代的进行,被错误分类的噪声样本也越来越多,为了降低这些噪声的影响,我们也希望降低后更新的描述词权重。
在本文中,文本与文本间的相似度完全由单词计算得到,没有利用到任何词序信息,无法识别到长词组。因此,本文对待分类文本进行了二元词组统计,并基于统计结果计算待分类文本间的相似度,通过相似度阈值筛选得到文档d的近邻文本集neighbord,并依据属于类别Li的已标记近邻样本提高该文档对于类别Li的权重:
3 SDGs数据分类实验
3.1 实验数据
本文在联合国官方所提供的SDGs指标元数据集[30]上进行了类别描述关键词集的构建,并以联合国官方SDGs数据库[31]为实验数据集,验证了本文所提框架的有效性。在数据集处理方面,对于联合国所提供的257个SDGs元数据,我们仅仅保留每个文档中的goal、target、indicator,computation method和definition,concepts字段,其他诸如Disaggregation、Collection process等字段被过滤掉。对2个数据集我们均采用了传统的文本预处理流程来对这些数据集进行简单预处理,利用nltk[32]来对文本进行分词、去掉停用词、词形还原并剔除词向量模型中不包含的词汇得到我们所使用的数据集,其基本信息如表1所示。由于SDGs数据库所包含的词数较少,不作词频的限制,对于SDGs指标元数据集,我们额外筛除了词频低于5的词,以减少噪音的产生。在实验类别选择方面,联合国官方将SDGs指标统分为17个可持续发展目标,并在这17个一级目标(goal)下逐级细分,得到169个二级目标(target)乃至257个三级指标(indicator)。本文按照17个一级目标划分类别,并在此基础上进行分类实验。
Table 1
表1
表1SDGs数据集信息
Table 1
| 类别 | SDGs指标元数据集 | SDGs数据库 | ||
|---|---|---|---|---|
| 文档 数量 | 平均长度 (/词) | 数据 数量 | 数据描述平均 长度(/词) | |
| 1 | 15 | 295 | 61 | 10 |
| 2 | 15 | 258 | 53 | 8 |
| 3 | 28 | 367 | 58 | 9 |
| 4 | 13 | 383 | 110 | 14 |
| 5 | 15 | 235 | 45 | 21 |
| 6 | 12 | 539 | 90 | 13 |
| 7 | 6 | 334 | 6 | 10 |
| 8 | 16 | 295 | 58 | 8 |
| 9 | 12 | 260 | 30 | 7 |
| 10 | 14 | 364 | 46 | 10 |
| 11 | 14 | 440 | 50 | 10 |
| 12 | 14 | 473 | 37 | 9 |
| 13 | 8 | 398 | 23 | 10 |
| 14 | 10 | 388 | 14 | 9 |
| 15 | 14 | 361 | 33 | 10 |
| 16 | 26 | 410 | 67 | 12 |
| 17 | 25 | 235 | 70 | 11 |
| 总 | 257 | 355 | 851 | 11 |
新窗口打开|下载CSV
3.2 实验相关参数
(1)关键词提取:在textrank算法中,我们设置其阻尼系数为0.85,窗口大小为5,边和节点的权重都初始化为1。在抽取过程中,首先通过textrank获取评分靠前的200个候选词,再筛出相对词频系数大于2的少量关键词作为当前类别的描述词集。(2)文本分类层:由于数据描述通常较短(SDGs数据库中的数据描述平均长度仅为11个单词),本文将窗口Cn固定为5。
(3)模型更新层:标签更新的阈值由每轮的更新样本数量决定,按照实验数据集的具体规模,本文在实验中每轮更新200个数据的标签;而对于类别描述词的更新阈值,本文实验设置每轮每类关键词更新数量不超过2个,且其词频比需满足最低阈值0.8;对于类别描述权重,实验将公式(7)中的值设为0.5,值设为0.05,k值设为1/17;对于近邻样本,规定相似度大于0.2的样本为近邻样本。
3.3 实验结果分析
3.3.1 对比实验(1)类别关键词提取实验
为了验证我们所使用的关键词提取算法的有效性,我们将以下两种常规的文档关键词提取算法在SDGs元数据集的提取结果也应用于数据分类中,并根据最终的分类结果进行对比。
①TFIDF[4]:首先将同类别的文档拼接成一整篇类别描述文档,再利用TFIDF公式从类别描述文档集中抽取得到类别关键词集。
②textrank[8]:与TFIDF实验类似,首先将同类别文档进行拼接,再对不同类别的描述文档分别构建图网络,通过textrank算法提取文档关键词,筛除类别重复词,得到最终的关键词集。
(2)数据分类实验
为了验证所提方法在无监督文本分类任务上的有效性,我们选取了以下基准模型,在textrank+RF方法提取得到的关键词基础上进行了对比实验。
①DescLDA[19]:在描述数据集上构建LDA模型并推理描述文档与主题的分布关系,并基于这个主题分布扩展到全体语料(包括待分类语料和类别描述语料),计算所有文档的主题分布。
②STM[20]:使用人工设定的少量类别描述种子词,利用主题模型对文本进行分类,该方法在长文本上获得了很好的效果。
③SeedBTM[21]:使用词向量扩展得到更大的类别描述词集合,对文本中的单词进行排列组合得到二元词组,在这些词组基础上构建二元主题模型,在短文本上获得了比STM更好的效果。
(3)词向量模型对比实验
为了探讨不同词向量模型对实验结果的影响,我们在常用的glove、Bert预训练模型所产生的词向量上进行了对比实验。
①glove[26]:由于glove词向量利用到了统计信息,难以进行增量训练。我们采用了stanford开源提供的100维词向量[33]作为外界语料词向量,同时在SDGs元数据集综合SDGs待分类数据集上进行glove训练得到的词向量作为语料向量,并以1:2进行加权组合。
②Bert[27]:本文以google开源提供的预训练语言模型[34]作为基础,在SDGs元数据集和待分类数据集上进行增量训练,以最后一层的输出作为最终使用的词向量。
3.3.2 实验结果及分析
本文所采用的综合textrank和相对词频方法的关键词提取结果如表2所示。
Table 2
表2
表2SDGs中goal层面的类别关键词提取结果
Table 2
| 类别 | 关键词集 |
|---|---|
| 1 | poverty,labor,poor,service,disaster |
| 2 | food,agriculture,breed,moderate,hunger |
| 3 | healthy,vaccine,mortality,disease,infection,alcohol |
| 4 | Education, teacher,numeracy,school,parity,child,skill |
| 5 | woman,proxy,gender,ownership,care |
| 6 | water,sanitation,wastewater,basin,procedure |
| 7 | energy,technology,electricity,fuel |
| 8 | employment,earn,engage,gdp,violation,labour |
| 9 | industry,manufacture,establishment,transport,mobile |
| 10 | migration,cost,income,flow,transfer |
| 11 | city,disaster,pixel,urban,space |
| 12 | policy,material,convention,fossil,waste |
| 13 | reduction,risk,climate |
| 14 | fish,marine,fishery,ocean,sustainable,ph |
| 15 | specie,wildlife,forest,biodiversity |
| 16 | right,develop,victim,traffic,chamber |
| 17 | development,least,worldwide,broadband,statistical, partnership |
新窗口打开|下载CSV
在将类别描述词集应用于分类算法时,我们发现,一方面类别描述并非越详细越好,而应该在能够描述类别的基础上尽量保证类别之间的差距足够大,以得到一个尽量准确的初始分类界面。当类别关键词集过大时,词集中往往拥有很多噪声信息,初始分类界面不够准确,导致分类效果不佳;当类别关键词集过小时,类别描述不够充分,部分文档无法分类,分类效果也不理想。
如图2所示,在分类器第一轮迭代上的对比实验表明,当相对词频筛选阈值不超过某个值时(阈值过高会使得描述词集过小,只有2-3个词),相对词频分数越低,分类的准确度也会随之降低。因此,我们最终所选相对词频分数的阈值大小为2,以保证最终每个类别的描述词集大小在5左右。
图2
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2在不同相对词频阈值下的分类准确度
Fig. 2Classification accuracy of different relative word frequency thresholds
表3展示了不同方法在SDGs数据库上实验得到的结果。可以看出,与当前主流的基于主题模型的分类方法相比,我们的分类方法取得了更好的效果;而与基础的TFIDF等关键词提取算法相比,我们所使用的关键词提取方法得到的词汇更适用于本文模型。
Table 3
表3
表3文本分类实验结果比较
Table 3
| model | Result | |||
|---|---|---|---|---|
| F1-micro | F1-macro | Rec | prec | |
| SeedBTM | 0.612 | 0.576 | 0.552 | 0.603 |
| STM | 0.583 | 0.558 | 0.531 | 0.589 |
| DescLDA | 0.535 | 0.495 | 0.486 | 0.505 |
| SeedETC-glove (TFIDF) | 0.757 | 0.729 | 0.721 | 0.740 |
| SeedETC-glove (textrank) | 0.651 | 0.613 | 0.598 | 0.625 |
| SeedETC-glove (textrank+RF) | 0.813 | 0.772 | 0.768 | 0.782 |
| SeedETC-bert (textrank+RF) | 0.770 | 0.736 | 0.719 | 0.753 |
新窗口打开|下载CSV
更具体地,我们通过F1-micro来对比评估SeedETC的分类性能。由图3可以看出,我们所提SeedETC方法对比SeedBTM在F1-micro指标上提高了33%,而在不擅长短文本分类的STM及DescLDA上分别提升了39%和 52%。这主要是由于主题模型往往需要足够大的数据集以支撑其基于词共现统计的主题分布建模,而SDGs数据集数据量较少,难以提供足够的信息,导致共现矩阵过于稀疏,而我们的方法利用了外界训练得到的词向量,除了数据集内部分布外也能捕捉外界信息,因此能够获得更好的效果。此外,由实验结果可以发现,glove词向量比经过大规模预训练的bert模型所得词向量效果也要更好,初步推测这是由于数据集过小,bert词向量受到外界噪声信息影响较大,难以很好的表征SDGs相关语料的分布造成的。Glove词向量直接对外界和SDGs语料训练得到的词向量进行加权拼接,更能够表征SDGs数据集内部的词汇分布。
图3
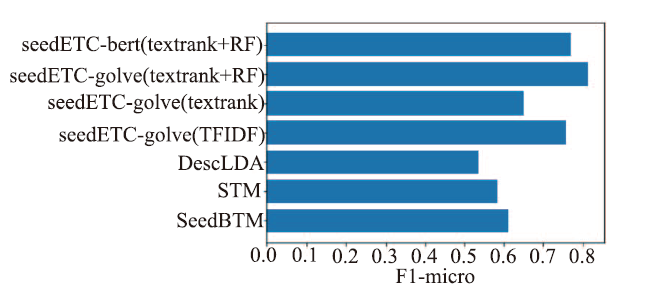 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3不同方法实验得到的F1-micro分数
Fig. 3F1-micro scores obtained from experiments with different methods
而在关键词提取算法中,相较于常规TFIDF及textrank关键词提取方法得到的类别描述词集而言,我们利用textrank+RF得到的关键词也具有明显优势。
由表3可以看出,textrank+RF方法所得关键词在与TFIDF的对比实验中,其F1-micro指标上提升了7%,而在与textrank的对比实验中提升了25%。这主要是由于TFIDF方法通过逆文档频率IDF,与其他类别文档进行了一定的区分;textrank方法只考虑了文档内部的高频词,缺少与其他类别之间关键词的区分;我们的方法主要关注的就是词语在不同类别间的相对词频,能够得到具有极高类别区分度的单词作为类别描述词。这也在一定程度上印证了我们在前文中提出的类别描述不一定要足够详细但一定要有足够的类别区分度的观点。
4 结束语
本文以联合国官网所提供的联合国可持续发展目标(SDGs)指标数据集为例,设计了一种基于词向量的无监督文本分类方法(SeedETC)进行数据分类。其中,无监督文本分类方法往往需要一些关键词来提供类别信息,本文又提出了基于textrank和相对词频的关键词提取方法,从SDGs元数据描述文档中提取得到了类别描述关键词集用于文本分类模型。实验结果表明,我们的方法取得了较好的分类效果,取得了0.813的micro-F1 score,且与其他无监督文本分类方法对比,本文所提SeedETC算法具有更好的性能。由于本文所使用算法高度依赖于词向量,当词向量不能够准确表征数据分布时分类效果将会大幅下降,下一步工作中将会继续探讨更稳定的词向量改进方式,并探索将本文所使用方法应用于其他领域。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 3]
[J].
DOI:10.1142/S0218213004001466URL [本文引用: 1]
[J].
[本文引用: 2]
[C].
[本文引用: 2]
[C].
[本文引用: 2]
[C].
[本文引用: 1]
[J].
DOI:10.1016/j.eswa.2017.12.025URL [本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 2]
[C].
[本文引用: 2]
[C].
[本文引用: 3]
[J].
[本文引用: 1]
[J].
[J].
DOI:10.1002/(ISSN)1097-4571URL [本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 2]
[J/OL].
URL [本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]
[J].
DOI:10.1007/s10579-010-9124-xURL [本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}