 ,1,2, 王学志,1,*, 赵江华,1,2, 周小华,1,2
,1,2, 王学志,1,*, 赵江华,1,2, 周小华,1,2A Lightweight Remote Sensing Data Distributed Scheduling Framework DataboxMR
MENG Xianghai,1,2, WANG Xuezhi,1,*, ZHAO Jianghua,1,2, ZHOU Xiaohua,1,2通讯作者: *王学志(E-mail:wxz@cnic.cn)
收稿日期:2021-01-4网络出版日期:2021-06-20
| 基金资助: |
Received:2021-01-4Online:2021-06-20
作者简介 About authors

孟祥海,中国科学院计算机网络信息中心,在读硕士研究生,主要研究领域为海量数据处理技术及应用、遥感数据分布式处理等。
本文中承担的任务是实验设计与文献撰写。
MENG Xianghai is a postgraduate student of Computer Network Information Center, Chinese Academy of Sciences. His main research areas are massive data processing technology and appli-cations, and distributed remote sensing data processing.
In this paper, he is responsible for experimental design and paper writing.
E-mail:

王学志,中国科学院计算机网络信息中心,研究员,硕士生导师。主要研究方向为科学大数据管理和应用技术、时空大数据分析处理、科学大数据挖掘分析等。主持参与了环境保护部和中国科学院联合重大项目、火炬计划项目、国家重点研发计划子课题、环保公益性行业科研专项、院十二五信息化项目子课题、院战略性先导科技专项子课题等多个项目。
本文中负责研究指导和总体统稿。
WANG Xuezhi is a senior researcher and master’s supervisor of Computer Network Information Center, Chinese Academy of Sciences. The main research directions are scientific big data management and application technology, spatio-temporal big data analysis and processing, scientific big data mining analysis, etc. He has Presided over and participated in the joint major projects of the Ministry of Environmental Protection and the Chinese Academy of Sciences, the Torch Program project, the sub-projects of the National Key R&D Program, the spe-cial scientific research projects of environmental protection public welfare industries, the sub-projects of the 12th Five-Year Informatization Project of the Academy, the special sub-projects of the Academy’s strategic leading technology projects, etc.
In this paper, he is responsible for research guidance and overall draft.
E-mail:

赵江华,中国科学院计算机网络信息中心,在读博士研究生,主要研究方向为遥感数据处理与分析。
本文中主要承担的任务是论文指导。
ZHAO Jianghua is a PhD candidate at the Computer Network Information Center, Chinese Academy of Sciences. Her main research direction is remote sensing data processing and analysis.
In this paper, she is responsible for thesis guidance.
E-mail:

周小华,中国科学院计算机网络信息中心,在读博士研究生,主要研究方向为遥感数据处理与分析。
本文中主要承担的任务是实验指导。
ZHOU Xiaohua is a PhD candidate at the Computer Network Information Center, Chinese Academy of Sciences. His main research direction is remote sensing data processing and analysis.
In this paper, he is responsible for experimental guidance.
E-mail:

摘要
【目的】 目前,基于通用平台处理遥感数据,在提升处理效率的同时,也带来了执行轻量级任务效率低、用户使用门槛高、迁移代价大的问题。为降低用户处理轻量级任务的复杂度,降低基于通用平台处理带来的迁移代价,提高用户对任务调度端的控制力。【方法】 本文提出了一个高效处理遥感数据的轻量级分布式调度框架(DataboxMR)。框架基于UDF(User-Defined Function)技术设计实现了遥感数据处理服务组件(Remote Sensing User-Defined Function, RS-UDF),RS-UDF支持用户已有程序封装、自定义函数封装和引用已有成熟处理技术,通过接口服务的形式实现同步调用和异步调用。此外,框架基于双层调度模式设计遥感数据调度引擎(DataboxMR-Engine),支持指定节点处理任务,支持任务划分和分发及故障恢复等功能。【结果】 与基于内存计算的遥感数据处理工具GeoTrellis进行实验对比,结果表明,执行轻量级遥感数据处理任务时,DataboxMR效率更高,系统开销更小。【结论】 DataboxMR是一个轻量高效的遥感数据分布式调度框架。
关键词:
Abstract
[Objective] At present, processing remote sensing data based on a common platform not only improves processing efficiency, but also introduces problems such as low efficiency in executing lightweight tasks, high threshold for end users, and high migration costs. This paper aims to reduce the complexity faced by users in handling lightweight tasks as well as the migration cost caused by common platform processing, and improve the user's control over the task scheduling. [Methods] A lightweight distributed scheduling framework DataboxMR is proposed for efficient processing of remote sensing data. The framework is based on UDF (User-Defined Function) technology to design and implement the remote sensing data processing service component (Remote Sensing User-Defined Function, RS-UDF). RS-UDF enables users to package existing programs, custom functions, and references to existing mature processing technologies. It realizes synchronous and asynchronous calls in the form of interface services transfer. In addition, the framework achieves a remote sensing data scheduling engine (DataboxMR-Engine) based on a two-tier scheduling model, supporting designated node processing tasks, task division and distribution, and fault recovery functions.[Results] Experimental comparison with GeoTrellis, a remote sensing data processing tool based on memory computing, shows that DataboxMR is more efficient and has less system overhead when performing lightweight remote sensing data processing tasks. [Conclusions] DataboxMR is a lightweight and efficient distributed scheduling framework for remote sensing data.
Keywords:
PDF (11069KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
孟祥海, 王学志, 赵江华, 周小华. 轻量级遥感数据分布式调度框架DataboxMR[J]. 数据与计算发展前沿, 2021, 3(3): 95-110 doi:10.11871/jfdc.issn.2096-742X.2021.03.009
MENG Xianghai, WANG Xuezhi, ZHAO Jianghua, ZHOU Xiaohua.
引言
随着遥感数据处理技术的不断丰富和发展,遥感数据处理能力不断增强,处理手段更加丰富,发展出较多成熟的遥感数据处理技术,例如,利用人工智能技术进行云雪检测、利用rasterio访问栅格数据等,充分发挥不同遥感数据处理技术的优势,提升遥感数据处理的效率和水平是研究遥感数据处理的关键。遥感数据处理涉及数据解译、处理和专业应用等,目标为形成多源遥感基础数据产品和专业数据产品。基于遥感数据(特别是高分辨率遥感影像数据)的信息提取技术获取有效信息,可为专业应用提供数据支撑,可应用于土地遥感分析、植物遥感分析、水体和海洋遥感分析等领域。信息提取的前提是对遥感数据进行有效地组织、处理、计算和分析等操作。作为连接遥感数据和专业应用之间的媒介,遥感数据处理系统建设正临着数据密集、计算密集、并发访问密集、时空密集等实际应用带来的挑战[1]。传统单机处理的服务模式已不能满足遥感大数据的处理需求,为此需要引入分布式系统对空间数据进行处理[2,3,4],依托分布式处理技术提高处理遥感数据的规模和效率。
目前主流分布式计算框架Hadoop、Storm、Spark等在遥感数据处理方面均取得了较好的效果,根据数据的格式及内容提供实时处理和离线批处理[5]。张嘉等基于HBase预分区优化策略,结合MapReduce计算框架,构建了空间数据分布式计算与分析的优化流程[6]。宋峣等应用Storm对现有系统进行并行优化,设计了遥感数据流处理任务拓扑结构[7]。刘欢等基于Spark并行框架进行MODIS遥感影像的海表温度反演,影像处理效率大大提升[8]。然而,利用上述主流分布式计算框架对遥感数据进行分析处理需要用户自己设计遥感数据处理算子,其影像数据切割、分析等操作需借助额外的专有框架实现,用户操作复杂度较高。
针对上述问题,研究人员提出了众多专门应用于遥感数据处理的分布式系统架构,如SpatialHadoop[9]、Hadoop-GIS[10]、GeoSpark[11]、LocationSpark[12]、Simaba[13]、pipsCloud[14]等。这些系统基于MapReduce和Spark分布式计算框架实现,无需借助额外的专有框架,提高了遥感数据处理的效率。然而,基于MapReduce和Spark计算框架进行遥感数据处理带来性能提升的同时,也带来了一定的局限性。
上述框架集成在通用平台上,只能在特定开发环境,利用通用平台API和存储系统处理遥感数据,需要用户学习使用通用平台的API和技术,用户使用复杂度高,对于轻量级的遥感处理任务(数据的简单计算)来说迁移和使用代价较高。目前,用户大多拥有处理遥感数据的程序或算法,待处理遥感数据存储在特定存储系统中,借助一个轻量级框架,在尽量不改变既有程序和存储位置的基础上实现遥感数据的高效处理成为用户的需求。若基于MapReduce或Spark等通用计算框架进行遥感数据处理,其程序和算法需要根据通用平台的API进行重构,数据需要导入框架对应的存储系统,迁移代价较高。更换技术框架和存储系统给简单的处理任务带了较大压力。
实践中针对既有成熟遥感数据处理技术只能单独使用或在特定领域使用的问题,设计了一个新的交互环境。该环境支持既有成熟技术的综合使用,提升了系统处理能力。此外,不同用户需求不同,只提供特定的API接口或算法,难以满足用户个性化的处理需求。因此,设计一种迁移方便、操作简单的开放交互方式,也是目前亟待解决的问题。
目前,依托通用平台进行遥感数据处理的计算框架除迁移能力和操作复杂度受限制外,其调度端的可控性也是用户关心的问题。通常,分布式计算框架执行任务时,其他任务无法提交,需等待任务执行完毕才可提交新的任务执行,为用户执行紧急任务带来了一定的困扰。现有遥感数据处理系统一般将任务提交至集群,集群自动分配节点执行任务,紧急处理任务仍需按其调度策略分配执行,用户对任务分配调度过程的控制力较低。因此,设计一个用户可控的调度系统,保证紧急任务及时处理和负载均衡也是急需解决的问题。此外,遥感数据处理过程偶尔涉及处理全局数据的操作,通用平台的遥感数据处理一般基于内存执行分布式处理,若单景数据量较大,将全局数据加载至内存处理可能会造成内存资源负载过重,从而降低系统的处理性能。
针对上述问题,本文提出了基于RS-UDF的轻量级遥感数据分布式调度框架DataboxMR。针对处理轻量级遥感任务时迁移能力低、用户操作复杂度高等问题,本文提出了RS-UDF。RS-UDF是可封装既有成熟遥感数据处理技术并将封装单元提交至调度引擎执行的交互环境,可在不改变用户既有程序或数据存储位置的情况下提交分布式任务。针对调度过程可控性低和遥感数据全局处理性能差等问题,系统设计了双层调度引擎。双层调度引擎支持遥感数据的高效调度,支持用户指定节点执行任务,支持故障恢复,可实现轻量化任务处理,相同条件下,消耗更少的系统资源。
1 遥感数据调度框架DataboxMR
1.1 系统概述
DataboxMR以稳定高效地处理遥感数据为目标,提供了一个支持已有成熟遥感处理技术、迁移方便、用户使用复杂度低、调度过程可控的轻量级调度框架。如图1所示,DataboxMR主要由RS-UDF、主调度器(Jobman)、分调度器(Taskman)和工作节点(Worker)四部分组成。其中,RS-UDF以函数为调度单元,实现分布式任务的封装与提交,主调度器接收RS-UDF提交的任务并进行任务划分和分发,分调度接收主调度器分配的子任务并分发给工作节点,工作节点负责实际的任务执行。图1
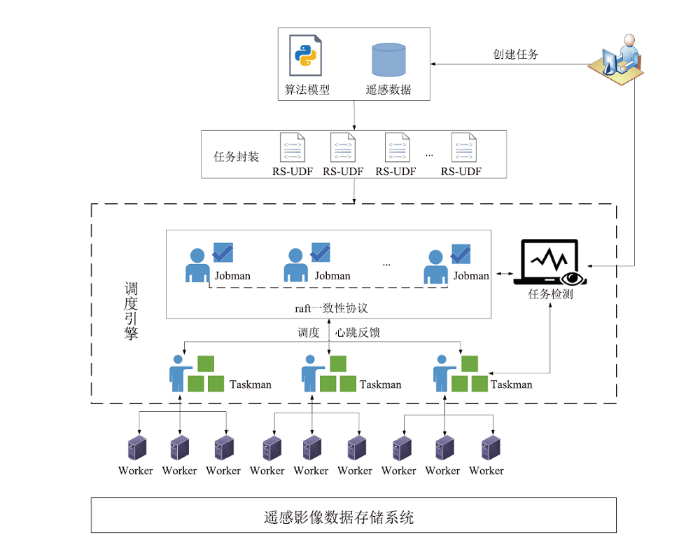 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1DataboxMR框架
Fig.1DataboxMR framework
在这四部分中,RS-UDF和调度引擎(主调度器和分调度器)是支撑DataboxMR框架的核心模块,RS-UDF实现对遥感处理逻辑的封装,提供对外交互的环境和接口。调度引擎实现遥感处理任务的高效划分、分配与处理,支持指定节点处理紧急任务,具备故障恢复能力。
1.2 遥感数据处理服务组件RS-UDF
UDF技术是用户自定义函数的简称,一般表示自定义标量函数、自定义聚合函数及自定义表函数三种自定义函数的集合,通常所说的UDF指用户自定义标量函数。RS-UDF受UDF启发,将遥感数据处理技术融入UDF技术中,用以支持对现有遥感数据处理技术的扩展,实现灵活高效的二次开发。RS-UDF是DataboxMR中面向遥感数据的用户自定义服务组件,基于Python提供迁移方便、操作简单的开发交互环境,侧重与既有成熟技术(如numpy、rasterio、gdal等)结合,利用既有成熟技术设计业务逻辑。用户已有程序或算法经过简单封装,即可提交任务请求。当用户实现数据可视化、数据计算等简单的处理任务时,无需根据通用平台的API进行重构,只需简单修改已有程序,将其封装成满足RS-UDF要求的函数算子形式,通过服务接口提交调度引擎处理即可,用户操作复杂度低,迁移代价小。此外,用户可根据需求灵活设计遥感数据处理逻辑,直接引入已有成熟软件包,充分保留UDF灵活开发的优势,从而保证用户操作的灵活性。
1.2.1 基于RS-UDF处理遥感数据的内部任务封装过程
RS-UDF接收用户任务后,内部对任务进行进一步封装处理。如图2所示,用户以函数为单元封装好处理逻辑,将函数单元以参数形式提交至RS-UDF接口,接收任务参数后,RS-UDF将任务调度服务器地址、客户端地址注册至etcd。检测集群状态、节点状态等信息,验证集群是否有空闲资源可以分布式处理遥感数据。若集群资源满足处理遥感数据的要求,则将函数单元序列化为统一的JSON格式,将接口中其他参数转码为字节码形式。将序列化和转码后的参数提交至DataboxMR-Engine进行分布式处理。RS-UDF根据用户不同需求可提供不同的接口服务,同步任务若存在Reduce算子,则选用MapReduce接口,若只存在Map算子,则选择map接口。异步任务调用过程同理,在实际应用中,用户可根据不同需求选择不同接口服务。
图2
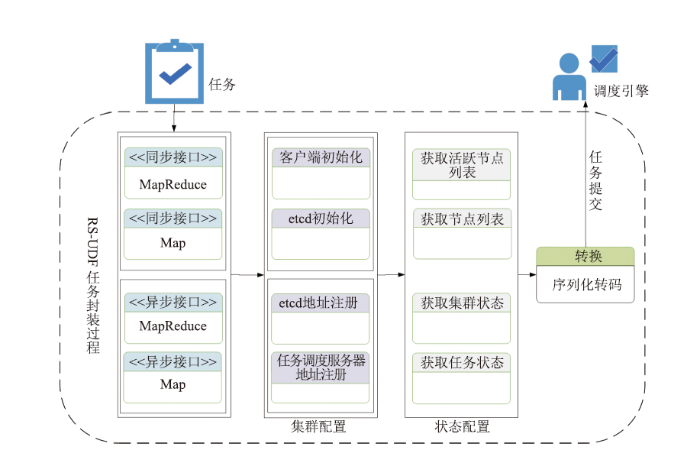 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2RS-UDF任务封装
Fig.2RS-UDF task package
上述客户端地址、集群主调度器地址等注册过程通过etcd服务器保障实现。etcd通过raft一致性协议保证集群的高可靠性,当一个节点出现故障时,集群中其他节点的备份数据可保障任务的正常执行。
1.2.2 RS-UDF用户任务封装实例
针对通用平台迁移代价大、用户使用复杂度高等问题,RS-UDF结合既有成熟遥感数据处理技术,在原有程序和算法的基础上只需简单封装,即可提交调度引擎执行分布式处理。此外,基于RS-UDF提交分布式任务时,对数据的存储系统没有特殊要求,可在不改变原有存储系统的情况下处理数据。为了解RS-UDF用户任务封装过程,设计了图3所示NDVI计算实例。
图3
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3RS-UDF封装实例
Fig.3RS-UDF package example
举例:
如图3所示,用户在已有处理逻辑的基础上,利用DataboxMR的分布式计算能力完成数据分析任务时,只需简单修改既有程序(其中“+”表示增加的代码,“-”表示删除的代码),修改为满足RS-UDF要求的函数形式。基于RS-UDF封装函数调度单元时,基本未改变用户原有处理逻辑,有效避免了为实现轻量级任务而学习通用平台API、进行大规模代码修改、迁移等问题,用户操作简便,使用代价低。
1.3 调度引擎DataboxMR-Engine
调度引擎主要为遥感数据提供作业和计算任务的分层调度、任务处理等服务。分别从高效处理轻量级任务、用户可控性及性能稳定性方面入手,保证调度引擎的功能。作为调度系统的核心,DataboxMR-Engine除实现任务划分及调度基本功能外,保证系统的高可靠性,实现对任务状态的监测、保障有效的容错及恢复机制也是其必不可少的功能。基于双层调度模式实现遥感数据的切分和分配,其处理过程可支持用户指定节点处理遥感数据,保证灵活性的同时,可增加用户对调度引擎的控制能力,可提升用户处理紧急任务的能力和效率。同时,调度引擎支持故障恢复功能,基于核心数据结构(双端队列和索引树)和状态机制实现,保证系统高可用和稳定性的同时,可快速回收系统资源,保证系统可用资源充足,从而保证系统轻量化的特点。1.3.1 遥感处理任务调度过程
双层调度引擎由一个主调度器和多个分调度器组成。主调度器负责任务的划分和分发,分调度器负责接收子任务并分发给工作节点。双层调度模块侧重对遥感数据的高效调度和处理,通过双端队列和索引树等数据结构实现,具有指定节点优先执行、故障恢复的能力。其调度过程如图4所示。
图4
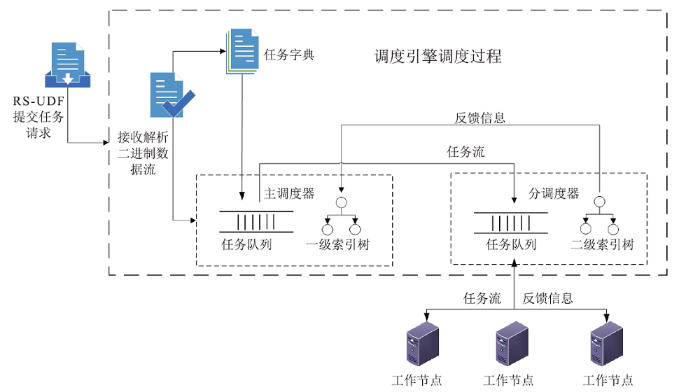 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4调度过程
Fig.4Scheduling process
任务接收和划分:主调度器接收来自RS-UDF的任务二进制流,解析二进制流,将解析后任务加入任务字典,从字典中取出任务划分并加入任务队列。入队顺序根据优先级参数确定,若优先级参数为True,则将子任务分配至队列首部,若未指定优先级,则按顺序加入至队列尾部。
主调度器子任务分配:从任务队列首部取出任务分配。当任务指定优先级时,高优先级任务的任务信息被放入至数据库,子任务信息不放入数据库,放入内存等待分配执行。若任务未指定优先级,任务和子任务信息均放入数据库,不放于内存,等高优先级任务执行完毕再执行。
分调度器子任务分配:分调度器向主调度器请求批量子任务,主调度器根据分调度器的请求信息从任务队列取出子任务分配给分调度器,分调度器将接收到的子任务加入至其自身维护的双端队列中,等待工作节点来主动拉取任务执行。
任务执行:工作节点从与其位于相同节点的分调度器队列中主动拉取子任务到本地执行。
1.3.2 基于队列和索引树的双层调度结构
如图5所示,双层调度引擎的核心数据结构为任务队列和索引树。任务队列负责维护待分配子任务。索引树用于记录子任务与分调度器或子任务与工作节点之间的映射关系。
图5
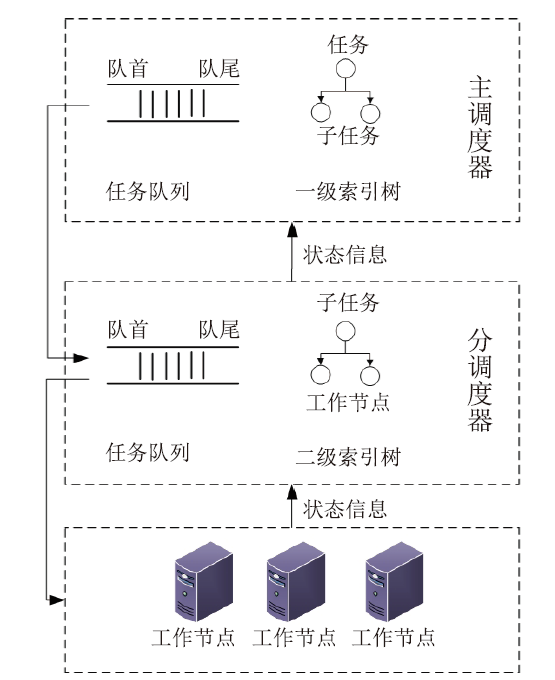 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5队列和索引执行原理
Fig.5Queue and index execution principle
任务队列基于双端队列实现,入队时,当未指定任务优先级时,按顺序将划分后子任务加入至队列尾部,当指定任务优先级或重新执行任务时,将子任务加入至队列首部。分配时,从队列首部取出任务分配执行。
索引树用于存储任务、子任务和节点之间的分配关系,基于任务id、子任务id及节点地址实现映射。一级索引树用于记录任务、子任务和分调度器之间的映射关系,二级索引树用于记录子任务和工作节点地址之间的映射。
1.3.3 基于状态机制的故障恢复
受限于网络、硬件资源等情况,任务执行过程中出现任务超时、任务执行出错等情况不可避免,如何实现高效的故障恢复是必须解决的一个问题。为保证任务执行过程中的故障恢复能力,提升系统的可靠性,调度引擎提出了状态机制。
状态机制是指在调度过程中为每个阶段的任务赋予相应状态,例如,任务分发后赋予已分配状态,任务执行成功赋予成功状态。调度过程根据任务的状态信息,执行相应的分配、抛弃等操作。
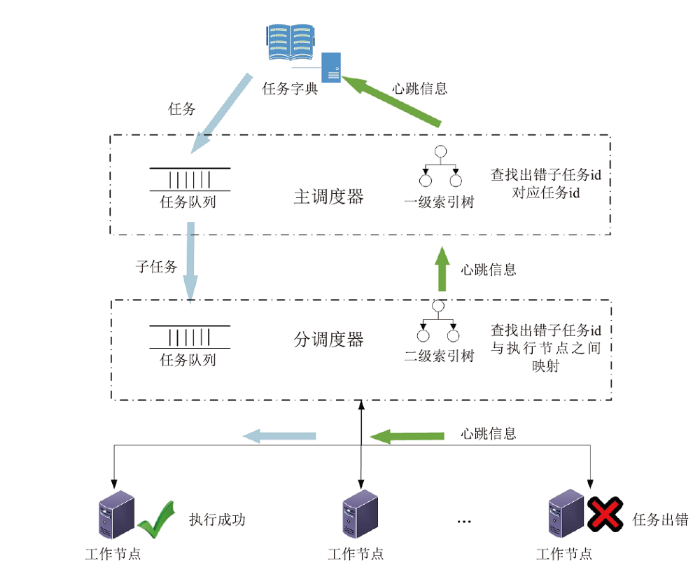
如图6所示,任务在工作节点执行时,分调度器通过心跳信息定时的获取任务的执行状态,若任务出现超时或出错,工作节点通过心跳信息将失败任务信息反馈给上层分调度器。分调度器通过索引树快速定位出错子任务相应信息、子任务id及与工作节点间的映射关系,将获取到的错误子任务相关信息通过心跳信息反馈给主调度器。主调度器根据状态信息首先从索引树中获取出错的子任务id及任务id的映射信息,停止出错任务相关的所有子任务的执行,回收分配至这些任务中的资源,然后从任务字典重新取出任务并划分为子任务,将子任务分配至双端队列的首部,等待重新分配,最终任务被重新分配至新的节点执行成功,结束故障恢复过程。
图6
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6故障恢复过程
Fig.6Failure recovery process
状态机制结合调度引擎的队列和索引树数据结构保障任务执行的可靠性和稳定性。调度引擎基于每秒一次的心跳信息获取任务状态,保证及时发现任务执行故障并激活故障恢复机制,整个状态恢复过程调度引擎自主完成,无需人工干预,对用户透明。
1.3.4 可控、轻量化的调度引擎
通常,用户希望通过管理调度引擎来提升任务处理过程的可控性。为满足这一需求,系统内部设计任务处理监测模块,通过状态反馈机制、接受用户指定节点执行任务的方式实现。状态反馈机制负责监测并反馈任务执行状态。接受用户指定执行节点的服务可保证调度引擎可控的特性,指定节点执行任务时,若指定节点未在执行任务,可直接执行用户指定任务,若指定节点有任务执行中,则需要等待当前任务执行完毕后执行用户任务。
此外,处理全局遥感数据时,可结合Zonal Operation运算的特点及其状态机制提升资源的利用率和任务处理的效率。遥感数据的Zonal Operation运算,处理范围通常为不规则但具有明确物理意义的单元,其输入需包含指定区域的矢量范围,调度引擎在计算时将矢量范围掩膜包含的多个Tiles按数据量大小均衡的加载至各个节点执行分布式处理。同时,基于状态机制及时将分配至出错任务的系统资源收回,保证系统资源的高效利用,从而保证系统轻量化处理的特点。
2 实验
2.1 实验设计
为验证系统性能,基于Landsat8[15]数据集计算归一化植被指数(Normalized Difference Vegetation Index, NDVI)。NDVI是一种利用绿色植物对红光的低反射率和对近红光的高反射率的光谱特征值计算的植被指数,可应用于检测植被生长状态、植被覆盖度等。NDVI值在-1至1之间,负值表示地面覆盖为云、水、雪等,对可见光高反射;0表示有岩石或裸土等,近红外光谱特征(NIR)和红外光谱特征(Red)近似相等;正值表示有植被覆盖,且随覆盖度增大而增大。其数学表达式为:$NDVI=\frac{NIR-Red}{NIR+Red}$
实验过程中对比DataboxMR和GeoTrellis计算NDVI时处理时间、CPU占用、内存占用和网络占用的性能差异。
基于DataboxMR处理遥感数据时,将Map函数、Reduce函数及数据提交至RS-UDF的服务接口。实验中,DataboxMR引入gdal库,基于gdal库将影像数据读取为矩阵,基于矩阵可分解的性质,对矩阵进行切分,切分后数据块作为DataboxMR分布式处理的基本单元,以List或者Tuple形式提交至服务接口,接收参数后接口将任务封装并提交至调度引擎,调度引擎对任务执行划分和分配,将子任务下发至集群中各节点分别执行遥感数据的NDVI计算,最后将各部分数据计算结果汇总返回并写入磁盘。
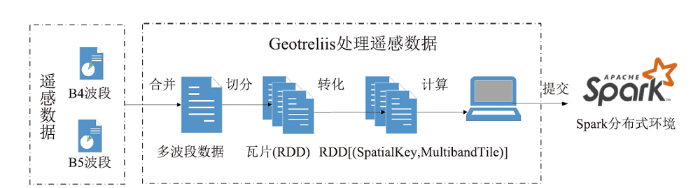
为使用内存计算平台Spark的分布式调度和计算能力执行遥感数据处理任务,需引入开源框架GeoTrellis[16]进行分布式栅格数据处理。GeoTrellis是基于Spark环境处理遥感空间数据的框架,旨在支持网络规模和集群规模的地理空间处理,可读取、转换、操作和写入遥感数据,此外,GeoTrellis可对矢量数据进行地图代数操作,可进行矢量数据和栅格数据的相互转换操作。其主要实现了创建低延迟、可扩展的地理处理Web服务、在分布式体系结构中运行,对大型遥感数据集进行快速批处理、采用多核架构对遥感数据进行并行化处理等功能。综上所述,GeoTrellis为Spark提供了功能丰富、处理高效的遥感数据处理库,通过GeoTrellis与Spark共同组成的处理引擎执行遥感数据处理操作,在提升处理效率的同时,也扩展了Spark的处理能力和范围。因此,为了利用Spark基于内存的分布式计算能力,对遥感数据进行高效处理。同时,也为了利用GeoTrellis强大的遥感数据处理能力,提出了开源框架GeoTrellis与Spark组成调度引擎进行遥感数据处理的方法。基于GeoTrellis处理遥感数据时将栅格数据分割为使用空间填充曲线索引的统一瓦片[17]。受GeoTrellis-Landsat-Tutorial[18]启发,本实验基于GeoTrellis对数据进行栅格化。基于Spark环境实现遥感影像的分布式处理,首先需利用GeoTrellis将遥感影像切分为多个瓦片数据(实验中为弹性分布式数据集(Resilient Distributed Dataset,RDD),然后对瓦片数据进行一系列处理。其处理流程为读取影像数据并将其转化为RDD[(SpatialKey, MultibandTile)],然后基于转化后RDD[(SpatialKey, MultibandTile)]执行分布式计算,除计算NDVI外,基于RDD还可对遥感影像执行多种分布式处理操作。实验中,GeoTrellis涉及处理技术有:基于HadoopGeoTiffRDD方法将单波段影像读取为RDD[(SpatilKey,Tile)],基于combine等方法将单波段影像合并为多波段形式,然后基于map算子设计处理逻辑,将合并成的多波段影像切分为瓦片并执行计算,最后在Spark环境中以RDD为执行单位进行分布式处理。Spark分布式环境下GeoTrellis执行分布式处理的流程如图7所示。
图7
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7GeoTrellis计算NDVI过程
Fig.7GeoTrellis calculation process of NDVI
2.2 实验环境与数据
实验在由3个计算节点组成的集群上进行,每个计算节点中配置有4核CPU、8GB RAM和30GB 7200RPM的HDD,实验环境如表1所示。Table 1
表1
表1实验环境系统信息
Table 1
| 系统/硬件 | 版本/容量 |
|---|---|
| 系统版本 处理器 内存 网卡速度 磁盘容量 磁盘速度 | Linux fedora31 5.3.7-301.fc31.x86_6 4核2GHz 8192MB 1000Mbps HDD 30GB 133MB/s |
新窗口打开|下载CSV
实验数据基于Landsat8数据集,本实验采用十景Landsat8数据集作为实验数据,数据集及数据量如表2所示。
Table 2
表2
表2数据集
Table 2
| 数据名称 | 数据量 |
|---|---|
| LC08_L1GT_123032_20200819_20200823_01_T2 | 999MB |
| LC08_L1TP_121032_20200821_20200905_01_T1 | 862MB |
| LC08_L1TP_121032_20200906_20200906_01_RT | 950MB |
| LC08_L1TP_122032_20200812_20200822_01_T1 | 990MB |
| LC08_L1TP_122032_20200828_20200905_01_T1 | 920MB |
| LC08_L1TP_122033_20200828_20200905_01_T1 | 871MB |
| LC08_L1TP_123032_20200803_20200807_01_T1 | 913MB |
| LC08_L1TP_123032_20200904_20200904_01_RT | 980MB |
| LC08_L1TP_123033_20200803_20200807_01_T1 | 980MB |
| LC08_L1TP_123033_20200904_20200904_01_RT | 913MB |
新窗口打开|下载CSV
2.3 实验结果监测
DataboxMR与GeoTrellis分别读取并处理十景遥感影像,并将计算后的遥感数据写入相应的存储系统。在该过程中,分别记录分布式处理任务的消耗时间、CPU占用率、内存占用率和网络传输占用等性能指标。时间消耗通过监测Linux系统时间实现,后三者通过Ganglia监测记录。Ganglia是UC Berkely发起的开源项目,可对分布式集群的所有计算资源进行监测,通过Web页面显示监测结果。实验过程中,通过为集群部署Ganglia的方式实时监测集群处理任务时间段内的系统资源(CPU占用率、内存占用率、网络负载)变化,并记录反馈监测结果。2.3.1 计算时间
为验证DataboxMR处理遥感影像数据的速度,相同实验条件下,对相同数据集执行NDVI计算,基于Linux的系统时间,对读取遥感数据、分析遥感数据和写遥感数据处理结果三个阶段时间分别监测记录,各阶段时间消耗情况如表3所示。
Table 3
表3
表3GeoTrellis与DataboxMR时间消耗
Table 3
| 框架 | 读数据(秒) | 处理数据(秒) | 写数据(秒) |
|---|---|---|---|
| GeoTrellis | 276.276 | 0.309 | 261.011 |
| DataboxMR | 154.133 | 0.223 | 12.6814 |
新窗口打开|下载CSV
表3表明,相同实验条件下,对相同遥感数据执行NDVI计算,DataboxMR读写磁盘数据的时间相较于GeoTrellis读写HDFS数据更快。由于最终处理数据为矩阵形式,因此处理过程消耗时间相近,差异较小。因此,由实验结果可知DataboxMR的I/O速度较快。若将数据存于主流空间数据库或对象存储系统,其读写性能可进一步提升。
2.3.2 CPU占用
为观察DataboxMR执行分布式计算时CPU占用变化,分别监测集群整体和各节点的CPU占用变化。
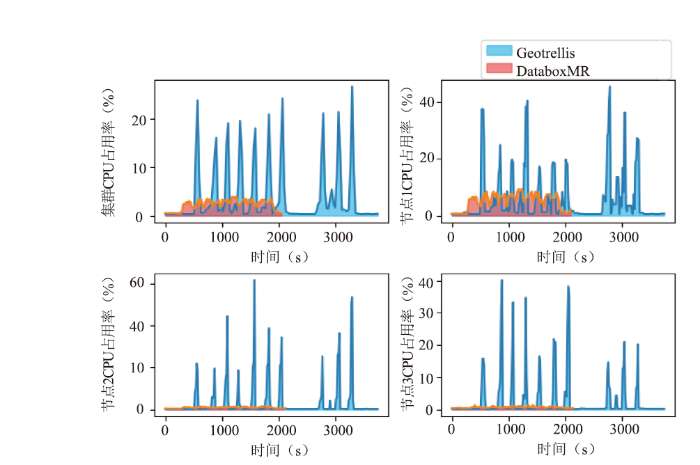
图8(左上)表明,GeoTrellis在Spark环境下执行遥感影像分布式处理时,任务提交后,集群整体CPU占用率最高超过25%,普遍维持在15%~20%之间。DataboxMR的CPU占用率峰值在4%以下,普遍稳定在3%~3.5%之间,GeoTrellis的占用面积(曲线与坐标轴的积分)大于DataboxMR的面积。因此,分布式处理遥感数据时,DataboxMR比GeoTrellis占用更少的CPU资源。图8(右上、左下、右下)表明,集群各节点CPU占用率均出现明显变化,未出现明显负载不均衡,未产生明显数据倾斜,分布式任务执行状态正常。对比各节点CPU占用率变化可知,DataboxMR的CPU占用率明显低于GeoTrellis的CPU占用率。综上所述,DataboxMR进行遥感数据分布式处理时比GeoTrellis占用更少CPU资源。
图8
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8CPU占用变化
Fig.8CPU usage changes
2.3.3 内存占用
为验证分布式处理过程中内存占用变化情况,分别监测处理过程中集群内存变化和各节点内存变化。图9表示内存使用时的占用变化,图10表示剩余空闲内存变化。
图9
 新窗口打开|下载原图ZIP|生成PPT
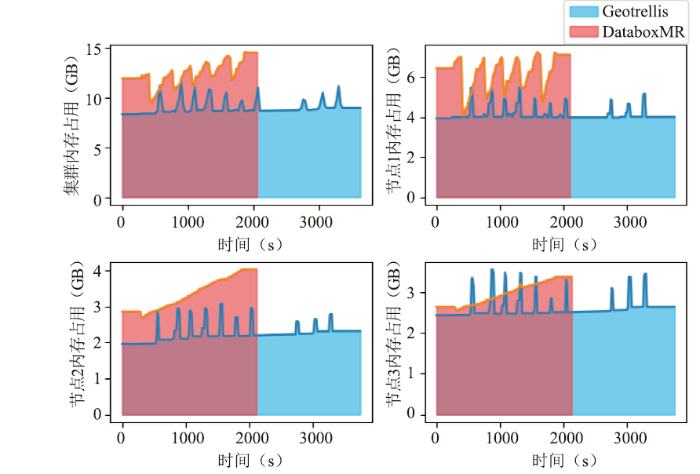
新窗口打开|下载原图ZIP|生成PPT图9内存占用变化
Fig.9Memory usage changes
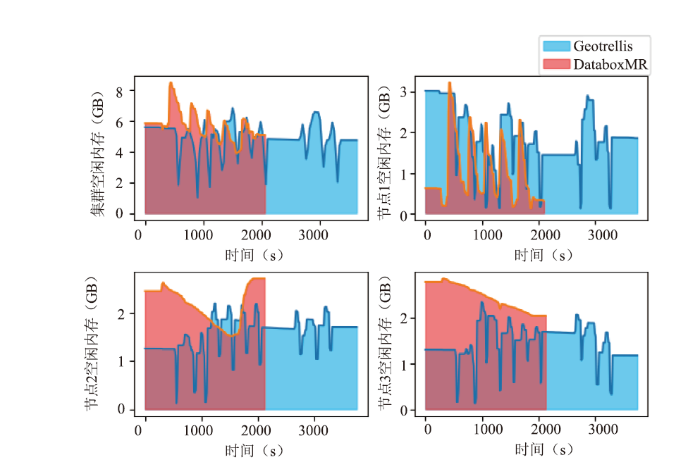
图 10
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 10空闲内存变化
Fig.10Free memory changes
图9(左上)表示GeoTrellis和DataboxMR处理相同任务时集群内存使用变化。结果表明,前者处理时内存占用面积(占用曲线与坐标轴之间的积分)大于后者的面积。因此,可知前者处理任务时内存占用更大。图9(右上、左下、右下)表示集群各节点处理相同任务时内存占用变化。结果表明,各节点前者面积均大于后者面积,说明处理任务时GeoTrellis各节点的内存占用率大于DataboxMR。图10(左上)表明,GeoTrellis提交分布式任务至Spark运行环境时,空闲内存出现明显减少,维持在2GB~4GB之间。提交分布式计算任务至DataboxMR时,空闲内存资源变化较平缓,维持在5GB~6GB之间,前者平均空闲值小于后者。图10(右上、左下、右下)表明,各节点执行计算任务时空闲内存均出现了明显减少,但DataboxMR各节点的空闲内存相较于GeoTrellis平均值更大,即相对空闲内存更多。综上所述,执行遥感数据处理任务时,GeoTrellis消耗的内存资源比DataboxMR更多。
2.3.4 网络传输
为验证网络传输和通信效率,监测网络负载。图11表示网络输入变化,图12表示网络输出变化。
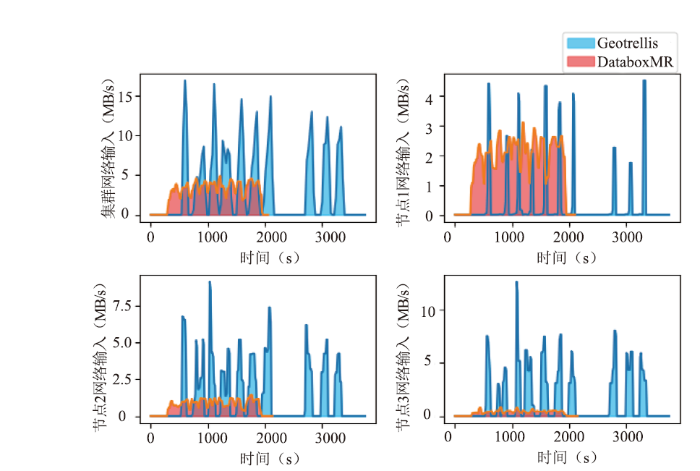
图11
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图11网络输入变化
Fig.11Network input changes
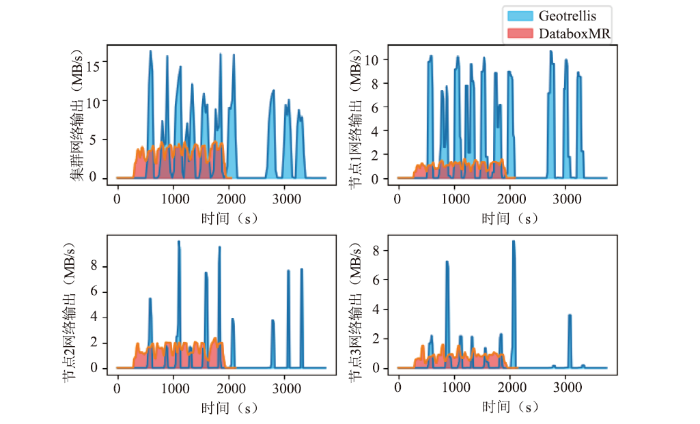
图12
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图12网络输出变化
Fig.12Network output changes
图11-12(左上)表明,GeoTrellis处理遥感影像时,从HDFS读写数据将产生大量网络传输开销,最大输入、输出传输达到17.5MB/s左右。DataboxMR计算NDVI时,最大输入、输出传输峰值在5MB/s以下,后者的面积(输入、输出曲线与坐标轴之间的积分)明显小于前者,为前者的1/3左右,说明后者占用了更少的网络资源。图11-12(右上、左下、右下)表明,Spark集群中各节点从HDFS读写数据时输入、输出的网络传输负载在6MB/s~10MB/s之间,网络负载重,系统传输效率低。DataboxMR集群中各节点的输入、输出的网络负载在3MB/s以下,数据传输的网络开销明显低于GeoTrellis,网络占用低,对系统的网络性能影响小,网络通信效率高。综上所述,执行遥感数据处理时,DataboxMR网络传输开销比GeoTrellis更低,通信代价更小,网络传输效率和通信效率更高。
3 实验结果分析
实验从处理时间、CPU占用率、内存占用率、网络负载角度验证了DataboxMR处理遥感数据的性能。对比DataboxMR与基于Spark计算框架的GeoTrellis的处理性能,实验结果表明,前者的I/O时间、处理时间均比GeoTrellis少,处理轻量级任务的效率较高。前者处理任务时CPU占用率比后者低,前者平均剩余空闲内存比后者高,即DataboxMR比GeoTrellis消耗更少的内存资源。网络传输从输入占用和输出占用两方面进行分析,前者输入、输出均约为后者的1/3,因此,DataboxMR相比于GeoTrellis的网络负载更低。综上所述,DataboxMR处理轻量级遥感数据分析任务时,具有稳定高效的特点,相同实验条件下,占用更少的系统资源。4 结论
将大数据技术与遥感数据处理技术深度融合是一个值得继续探讨的问题[19]。数据密集型科学需要高效的计算框架提高数据分析效率[20],本文对目前遥感数据分布式处理面临的一些挑战做了详细阐述并设法予以克服,设计并实现了一个轻量级的分布式调度框架(DataboxMR),从处理轻量级任务、方便迁移、支持已有技术扩展、提高用户对调度系统的控制力等角度出发,设计实现了RS-UDF以及双层调度引擎。最后,与开源框架GeoTrellis作对比实验,分别计算遥感数据的NDVI,收集集群内资源消耗情况,从不同角度对结果进行了分析。结果表明,DataboxMR不仅具有高效处理轻量级任务的能力,而且相同实验条件下,比GeoTrellis消耗更少的时间和更少的CPU、内存、网络等系统资源,具有轻量高效的特点。随着云计算技术的发展,在线计算平台得到了空前的发展,在线计算可根据用户个性化需求高效处理任务。RS-UDF自定义函数算子的特点可满足用户个性化的开发需求,简单封装已有算法和程序执行轻量级分布式任务的特性,为用户提供了一个高效易用的开发环境。DataboxMR是在遥感影像数据处理领域的新技术,可应对遥感大数据带来的挑战,可为遥感数据处理提供灵活、高效的服务,可应用于在线计算领域,提供科学数据端的在线交互分析[21]。该框架除分布式处理遥感数据外,还可支持传统数据的批处理以及人工智能算法的分布式训练等,为多种数据处理任务及应用场景提供分布式算力支撑。目前该调度框架已开源,可通过
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
DOI:http://www.jfdc.cnic.cn/article/2021/1674-9480/10.1016/j.ins.2014.01.015URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1080/17538947.2011.587547URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
URL [本文引用: 1]
[J].
URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
URL [本文引用: 1]
[C].
[本文引用: 1]
[J].
DOI:10.14778/2536222.2536227URL [本文引用: 1]
[C].
[本文引用: 1]
[J].
DOI:10.14778/3007263.3007310URL [本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1016/j.rse.2015.11.032URL [本文引用: 1]
URL [本文引用: 1]
[J].
URL [本文引用: 1]
URL [本文引用: 1]
[J].
URL [本文引用: 1]
[C].
URL [本文引用: 1]
[J].
URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}