 ,1,2, 杜义华,1,*
,1,2, 杜义华,1,*A Survey on Short-text Generation Technology
ZHANG Chenyang,1,2, DU Yihua,1,*通讯作者: *杜义华(E-mail:yhdu@cashq.ac.cn)
收稿日期:2021-01-6网络出版日期:2021-06-20
| 基金资助: |
Received:2021-01-6Online:2021-06-20
作者简介 About authors

张晨阳,中国科学院计算机网络信息中心,硕士研究生,主要研究方向为文本生成,网络传播引导技术。
本文中承担的工作为:方法调研,模型及应用对比分析,论文撰写。
ZhANG Chenyang is a postgraduate student in the Computer Network Information Center, Chinese Academy of Science. Her research interests include natural language generation and network communication broadcast and guidance technology.
In this paper, she is responsible for method reviews, comparative analysis of models and applications, and paper writing.
E-mail:

杜义华, 中国科学院计算机网络信息中心,副研究员,硕士生导师,主要研究方向为软件系统设计、网络传播引导技术。曾参加或负责中国科学院MIS系统、资源规划系统(ARP)、网络化信息发布平台(网站群)、科研管理数据集成及应用技术研究、信息化管理与决策支持工程等建设与运维项目。当前负责互联网信息传播引导技术的研究与示范、新媒体科学传播平台建设等项目。
本文中承担的工作为:论文思路解析及论文统稿。
DU Yihua is an associate Researcher and the master tutor of the Computer Network Information Center, Chinese Academy of Science. His research interests include software system design, and network communication broadcast and guidance technology. He has participated in the construction and opera-tion of the MIS system, resource planning system (ARP), network information publishing platform (website group), research mana-gement data integration and application technology research, information management and decision support engineering. He is currently responsible for the research and demonstration of Internet information dissemination guidance technology and the construction of new media science communication platform.
In this paper, he is responsible for idea analysis and finalization.
E-mail:

摘要
【背景】 短文本自动生成技术的研究对阅读与写作效率的提升、传播与引导影响力提升、智能人机交互满意度和机器语义理解能力的提升等都有重要意义。但生成技术的发展和实际应用需求难度的提升使得短文本自动生成技术面临着诸多困难与挑战。【方法】 基于神经网络的生成方法作为人工智能领域的关键技术,在短文本摘要、对话生成、评论文本生成、诗歌创作等任务中都取得了很多创新性成果。【结果】 本文对基于神经网络的短文本自动生成技术在生成模型、应用需求、评估指标等方面的研究进展进行了介绍和梳理,为短文本自动生成技术的进一步研究提供了参考。【结论】 本文总结了基于神经网络的短文本自动生成技术的发展现状并进一步提出了未来的发展趋势。
关键词:
Abstract
[Context] Research on short-text generation is of great importance in improving the efficiency of reading and writing, the impact of communication and guidance, the satisfaction of intelligent human-computer interaction and the capacity for machine semantic comprehension. However, short-text generation technology faces many difficulties and challenges due to the weakness of generation technology and the increasing complexity of realistic implementation requirements.[Methods] The neural network based generation method is a key artificial intelligence technology that has accomplished several pioneering achievements in short-text summary, dialogue generation, text generation of comments, poetry creation, and other linguistic tasks. [Results] This paper presents the research status and development of neural network based short-text generation technology in the aspects of the generation model, goal, and evaluation metric, providing a guide for further research into short-text generation technology. [Conclusions] we summarized the difficulties, challenges and trends of neural network based short-text generation technology.
Keywords:
PDF (11657KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
张晨阳, 杜义华. 短文本自动生成技术研究进展[J]. 数据与计算发展前沿, 2021, 3(3): 111-125 doi:10.11871/jfdc.issn.2096-742X.2021.03.010
ZHANG Chenyang, DU Yihua.
引言
短文本自动生成技术属于自然语言生成(NLG)的研究范畴,是指计算机能够根据知识库或逻辑形式的机器表述自动生成一段符合语法和逻辑的自然语言文本[1]。短文本是指长度较短,通常在200字符左右的文本形式[2]。相对于长文本,短文本内容特征稀疏、噪声大、上下文依赖性强,同时受网络传播的影响,短文本还具有海量性、实时性、内容多样性等特点,在预处理、文本语义表示及生成方法复杂度等方面都给短文本自动生成技术提出了挑战[3]。短文本自动生成技术的研究意义主要体现在四方面:(1)阅读和写作效率提升的现实需要。在当前数据呈现爆炸性增长的背景下[4],短文本自动生成技术可以从海量的文本信息中快速总结出内容主旨、要义,或按需自动生成提纲、文章,节省用户阅读写作时间。(2)人机交互满意度提升的需要。短文本自动生成技术在问答机器人、闲聊机器人等人机交互任务中可以获得更多优质的回复文本,提高机器有效应答能力,提升用户满意度[5]。(3)传播与引导效果提升的需要。短文本自动生成技术在信息传播与引导中可用于生成优质评论,降低负面信息的传播影响力[6]。(4)机器语义理解能力提升的需要。受短文本自身特性和网络传播的影响,在生成内容时计算机不仅要考虑短文本本身的特点,还要分析理解文本的上下文关系及用户个性,对机器语义理解能力的提升提出了更高的要求[7]。
短文本自动生成技术具有广泛的应用前景,可应用在短文本摘要、智能对话生成、诗歌创作、评论文本生成等多种场景中。相关模型优化和针对具体任务的创新成果也多次在发布ACL、EMNLP、ICLR、AAAI等自然语言顶级会议和期刊中,短文本自动生成技术的研究对人们的生活和工作产生着巨大的影响。
本文将从短文本生成方法和生成模型、短文本生成需求演化方向以及生成评价方法三方面对短文本自动生成技术进行梳理介绍,并对未来发展趋势提出展望。
1 短文本生成方法
传统的短文本生成方法多是采用基于模板或规则、基于统计语言模型的方法。随着人工智能技术和神经网络的变革与发展,现基于神经网络模型的生成方法成为短文本生成领域的主流方法。1.1 传统文本生成方法
基于模板或规则的方法是文本生成任务中早期的使用方法[8]。方法的本质相当于同义词替换的“填空”过程,其原理是通过抽取语义相似句子的共同特征,形成由变量和固定词组成的系列模板,再通过检索语义相似的模板,在具体生成任务中将其变量替换。基于模板或规则的生成思路简单,在短文本生成任务的对话生成[9]、描述文本生成[10]中都有相关应用实现。但该方法存在模板不够灵活,文本生成质量较低的问题。统计语言模型是用来计算一个词语、句子甚至是文档概率分布的模型,能够使计算机从概率角度预测下一个词语或句子出现的可能性及语义合法性[11]。常见的统计语言模型包括:N元文法模型、马尔可夫模型、最大熵模型、决策树模型等。基于统计语言模型的生成方法最初多应用在机器翻译中,其后基于统计翻译的思想也被广泛应用在诗歌创作等短文本生成任务[12]。基于统计语言模型方法的生成质量很大程度受相应领域数据丰富程度的影响,通用性较差,生成句子时更多的只考虑当前词语,缺少对上下文的语义估计。
1.2 基于神经网络的生成模型
短文本生成领域常用的神经网络模型主要包括Seq2Seq模型、VAE模型、GAN模型、Transformer模型等四类,模型的优缺点对比见表1。Table 1
表1
表1四类模型优势及不足对比
Table 1
| 模型 | 优势与不足 |
|---|---|
| Seq2Seq | 优势:能够处理输入输出序列不等长问题。 |
| 不足:存在暴露偏差,训练和测试量度存在不一致问题。 | |
| VAE | 优势:有天然的能解决文本生成单一问题的能力。 |
| 不足:存在固有的KL散度消失的问题。 | |
| GAN | 优势:生成判别模式能通过多次迭代生成以假乱真的数据。 |
| 不足:判别器难训练。 | |
| Transformer | 优势:基于注意力机制,能更好的捕捉数据间的关系,生成质量高。 |
| 不足:模型复杂度高,尤其在处理长序列数据时。 |
新窗口打开|下载CSV
Seq2Seq模型:Seq2Seq采用基础的编码器-解码器(Encoder-Decoder)结构。编码器可以将句子编码成一个能映射其大致内容的固定长度的潜在向量,然后通过解码器将其还原为目标序列。
图1
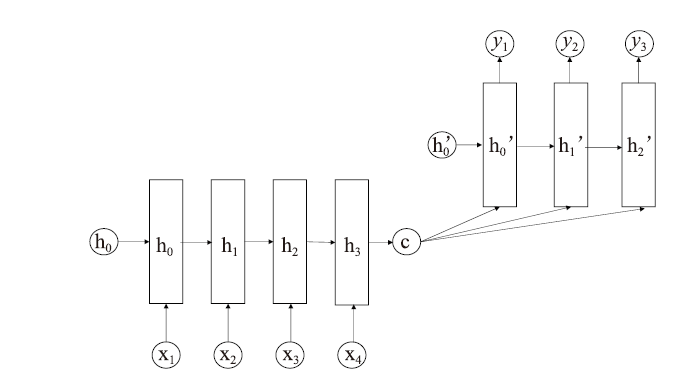 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1Seq2Seq基础模型架构
Fig.1The base model architecture of Seq2Seq
Kyunghyun Cho等[13]最早于2014年提出了基于RNN的编码器解码器模型。同年,Ilya Sutskever等[14]首次提出了Seq2Seq概念。随后注意力机制的提出[15],使得Seq2seq模型在各类文本生成任务中都有了突破性的进展。针对Seq2Seq模型在生成时的未登陆词的问题,结合注意力机制,****们提出了指针网络模型Pointer Network(Ptr-Net)[16]和CopyNet [17]模型,并在文本摘要任务中取得显著成效。为了解决Seq2Seq的曝光误差问题,也有****将结合强化学习的思想用于Seq2Seq的模型优化[18]。
VAE模型:VAE生成模型也是编码器-解码器的框架,VAE变分自编码器,是在自编码器(Auto-encoder)的基础上添加了隐变量,并将训练数据指定为一个联合概率分布,即编码器端将输入的高维数据先映射成符合某种概率分布的低维隐变量,解码器端按照条件概率由隐变量还原为目标数据。
图2
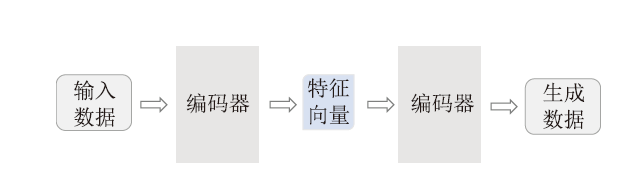 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2VAE模型架构
Fig.2Model architecture of VAE
VAE模型最早在2013年提出[19],模型通过重构得到输入的分布状态,再从分布中采样获得目标数据。
与Seq2seq模型相比,VAE具有生成非单一数据的优势。但VAE模型对目标函数的优化容易造成KL散度消失的问题。对此,一些****[20-21]通过减小KL loss来解决,也有****[22,23]通过加强编码器提取或减弱解码器强度的方式来增大VAE重构损失以减小KL散度消失。哈佛大学的研究人员提出了将注意力建模成隐变量[24],应用变分自编码器和梯度策略来训练模型,在不使用 KL 退火算法下进行模型训练。
GAN模型:GAN(生成对抗网络)由生成器和判别器构成,其基本原理是将生成器生成的样本和真实数据输入到判别器中进行真假判断,通过迭代训练,直至生成器的生成样本不能被判别器识别,即可达到理想的生成效果。
GAN最早于2014年针对离散问题提出[25]。2016年提出的TextGAN[26]是GAN在文本生成中最早的应用。同年为了解决生成器到判别器梯度更新困难的问题,有****提出了SeqGAN[27],将GAN与强化学习融合,用策略梯度算法更新生成器参数。
图3
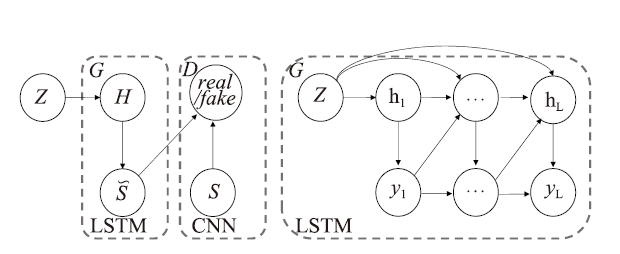 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3TextGan模型
Fig.3The model architecture of TextGAN
其后针对GAN在文本生成中有大量的研究成果。MaskGAN[28]为解决曝光误差问题,提出了利用强化学习中的 actor-critic 算法训练生成器,利用最大似然和随机梯度下降训练判别器的模型结构。针对GAN引入强化学习造成训练不稳定的问题,论文[29]提出了增强对抗奖励的最大似然框架(ARAML),融合了强化学习和最大似然方法,训练时通过分层采样方式从指数回报分布获得采样数据,判别器可实现对不同分布的样本分配稳定的奖励,实现较好的生成效果。
图4
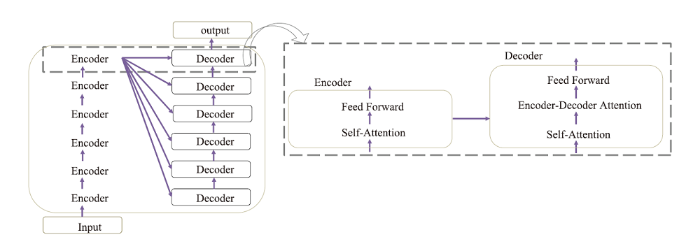 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4Transformer基本模型架构
Fig.4The model architecture of Transformer
Transformer模型:Transformer[30] 由Google团队在2017年提出,模型也是采用Encoder-Decoder架构,是完全采用注意力机制来实现加速深度学习算法的生成模型。Transformer模型能并行化处理,模型生成效率高,但相对时间复杂度也较大,同时Transformer 需要事先设定输入长度,对长序列关系的捕捉也有一定限制。
在扩展Transformer 处理序列长度上,Dai等提出了Transformer-XL[31],模型由片段级的循环机制和相对位置编码策略构成,能够在不破坏时间一致性的情况下,学习到超越固定长度的依赖性。在降低模型复杂度方面, Google提出了Reformer模型[32],模型使用可逆残差层和全连接层分段计算来降低内存占用,用局部敏感哈希的注意力机制代替点积注意力机制来降低模型的复杂度。
2 短文本生成需求演化方向
短文本自动生成技术的应用主要可分为创作型生成和辅助型生成两大类。创作型生成包括诗歌生成、评论文本生成和对话生成等。辅助型生成任务包括标题生成、注释(描述)生成和短文本摘要等。通过对短文本生成应用的论文调研与分析,当前的短文本生成需求可概括为由生成文本连贯性向生成文本个性化的递进演化过程。包括语句连贯表达、语句多样表达、语境关联表达和个性化生成四个方面,其最新(2020年)的研究文献见表2。
Table 2
表2
表2四类生成需求最新研究文献
Table 2
| 类别 | 文献作者 | 生成模型/方法 | 描述 |
|---|---|---|---|
| 语句连贯表达 | Li等(2020) | Transformer | 论文采用预训练模型和微调的方法提出了硬格式诗歌生成模型SongNet,结合模板方法能够生成流畅连贯的诗句[61]。 |
| Zhang等(2020) | Transformer | 论文提出了基于预训练和微调方式的天马模型(PEGASUS),在文本摘要生成中取得了显著成效[62]。 | |
| Peng等(2020) | Transformer | 论文针对少样本场景下的任务导向型对话,采用预训练的方法提高了生成回复的流畅度[63]。 | |
| 语句多样表达 | Su等(2020) | Seq2Seq | 论文提出了基于统计风格信息指导的强化学习策略,在保证生成质量的同时提升生成对话的多样性[64]。 |
| Su等(2020) | Seq2Seq | 论文将贴吧评论、俗语和书籍内容等非对话文本引入到对话生成中,用以提升对话生成的多样性[65]。 | |
| Duan等(2020) | Transformer | 论文针对查询式广告生成任务,在给定关键词的前提下通过引入外部知识来生成多样性的广告文案[66]。 | |
| 语境关联表达 | 倪海清等(2020) | Seq2Seq | 论文针对短文本摘要任务,将短文本的整体语义信息引入生成模型,以确保生成摘要的语义完整性和关联性[67]。 |
| Wang等(2020) | Seq2seq | 论文中引入了外部知识用于捕获对话间的关联,同时提出了回复指导注意力机制,引导模型生成一致性回复[68]。 | |
| Byeongchang Kim等(2020) | Transformer | 论文针对基于知识的对话生成任务提出了序列知识转换模型,能在生成时选择更适合的知识以提升对话的语境关联[69]。 | |
| 个性化生成 | Zheng等(2020) | Transformer | 论文中基于预训练设计了个性化对话模型,通过用户角色和对话历史构建丰富的对话回复文本[70]。 |
| Yang等(2020) | Seq2Seq | 论文通过多任务学习和强化学习策略,设计了从输入句子中识别用户特征的作者分析模块用于生成个性化对话[71]。 | |
| Chen等(2020) | Seq2Seq | 论文中为了提升广告邮件的关注度,通过软模板方法结合用户偏好和产品描述来获得个性化主题[72]。 |
新窗口打开|下载CSV
2.1 语句连贯表达
语句连贯表达是指在生成语句时句子是准确、流畅且符合逻辑的。语句连贯表达是短文本生成任务的基础目标。当前多是采用融合模型或检索的方式、加强输入数据约束、增加预处理模型等三个方面进行。2.1.1 融合模板或检索
在生成应用中若从源文本直接生成可能会造成生成效果不稳定的情况,针对此类问题,有****将生成模型与传统的模板和检索的方式进行了融合。Cao等[33]利用检索式的方法先生成摘要的软模板,模板由高总结性不完整的句子构成,再基于模板和生成模型获得准确率更高的摘要内容。Yang等[34]在对话生成任务中,提出了融合生成式、检索式的混合神经网络模型,模型先分别通过生成模块和检索模块获得匹配的响应,再基于混合排序获得最佳的生成结果。Cai等[35]设计了匹配模型,将检索响应通过匹配模型获对话回应纲要,然后将检索响应和匹配纲要一起输入生成模型中,采用直接训练和强化学习两种思路来获得流畅连贯的对话文本。
2.1.2 输入数据约束
增强输入数据是提升语句连贯的重要手段之一。针对短文本摘要,Wang[36]提出了一种迭代修改的生成模型,模型先利用标题生成摘要初稿,再将初稿和标题作为模型输入,利用注意力机制再次生成摘要。论文中证明多次迭代会得到更高质量的摘要,但同时也降低了标题的影响,经作者验证,两次迭代能获得最好的生成效果。类似的,Hancock等[37]基于Transformer模型设计了自馈式聊天机器人,对话顺利时会将用户的回答作为训练的新范例进行模仿,对话不顺利时将反馈矫正建立新的范例,以此提高生成对话的流畅和逻辑性。Rik Koncel-Kedziorski等[38]通过知识图谱来约束模型输入,利用Transformer模型提取图特征,利用实体-属性-实体的指导来生成高质量的摘要内容。
2.1.3 融合预训练模型
预训练模型思想自提出后,在情感分类[39]、多轮对话[40]等各类NLP应用中都被验证了其优异的提升效果,也为短文本生成质量提升提供了新方向。Bao [41]在论文中提出结合预训练模型和离散潜变量的方法,通过改进的注意力机制来考虑语言生成的双向语境和单向特征,以提升对话生成连贯性。Chen Qu[42]和Wang等[43]对预训练模型Bert进行改进,并分别用于提升在问答和开放域对话生成任务中的对话生成质量。
2.2 语句多样表达
语句的多样表达在短文本任务中,是解决生成回复较单一或者存在较多“安全性”回复(如“我不知道” 、“我明白了” 等意义低且简单的通用性回复)问题。语句多样性的实现主要通过改变目标函数、搜索算法或增加生成内容控制单元。2.2.1 目标函数优化
为了提成对话的生成多样性,Li等 [44]将最大互信息作为神经网络模型的目标函数,Li[45],Shao[46]等通过增加多样性惩罚或随机定向搜索策略等方式优化编码器的波束搜索算法,以提升生成句子的内容信息量,解决生成文本单一问题。Wang[47]等人提出了基于惩罚的目标函数,不同与其他最大化奖励的方法,该方法是以最小化总体惩罚的目的迫使每个生成器生成多个特定情感标签的文本。
2.2.2 内容控制
很多****们利用增加控制模块或指定内容选择策略的方式来实现语句的多样性表达。如:Liu等提出了一种用于现代汉语诗歌生成的修辞控制编码器[48],模型可以利用人工输入的修辞标签或通过上下文信息自动生成的修辞标签指导生成,以获得具有丰富修辞的诗歌文本。Gao等[49]引入一个具有显式语义的离散潜变量的变分自编码模型,通过两阶段采样的方法选择具有不同的语义距离的隐变量,实现在短文本会话中生成语义多样的文本。
2.3 语境关联表达
语境关联表达主要针对短文本摘要、对话生成、评论生成等短文本生成应用中输入与响应不一致或关联性不强的情况。为解决这类问题,近年的研究多是基于主题词(话题词)约束、情感约束、引入外部知识约束的方法。2.3.1 主题词约束
无论是对话内容还是评论内容往往都是基于同一主题或同一话题产生的,利用主题词的约束限制能在生成时实现较理想的语境关联。Yao[50]在对话生成任务中,将关键词融合到解码时每一步的状态更新中,使产生的回应更贴合语境。Dziri[51]设计了端对端的对话系统THRED,模型融合主题信息,采用层次化的注意力机制在句子级别和单词级别分别对输入的数据进行建模,充分考虑了主题和对话历史信息的上下文语境关联。Zheng[52]设计了引入门控注意机制的神经网络模型,以控制新闻评论生成时语境的选择和自适应性,同时为了保证评论的关联性,使用随机样本和关联控制来生成不同主题和相关度的评价。
2.3.2 情感约束
结合短文本的情感特性,有****采用情感词典的方式来考虑生成时的上下文关联。如:Asghar[53]基于seq2seq模型,通过引入外部的情感词典将输入词建模成带情绪的词向量,同时设置了最小化情感失调、最大化情感失调、最大化情感内容三类情感目标函数,对解码器搜索算法进行优化,使得生成文本时既能考虑单词情感也能考虑句子情感。Zhong[54]设计了基于情感的注意力机制来考虑对话生成时否定词和加强词的作用,同时用融入情感的目标函数优化模型,确保生成对话的情感一致性。
2.3.3 外部知识约束
外部知识约束也是解决语境关联表达的有效方式之一。Zhou[55]提出了把知识图谱看作一个整体用于对话生成任务中,模型通过静态图注意力机制来增强输入句子的语义信息,通过动态图注意力机制和知识来生成更一致的回答。Lian[56]提出了融合了外部知识指导对话生成的模型,模型由表达编码器,知识编码器,知识管理模块,解码器四部分构成,模型的主要思想是由表达编码器获得原数据的词向量,知识编码器获得外部知识的编码向量,然后将二者输入到知识管理模块采样获得最优知识和内容隐变量,最后再通过注意力机制将知识和内容隐变量生成更一致的对话响应。
2.4 个性化生成
个性化表达是指在评论、对话短文本生成任务中,模型可以模仿和生成更贴近人类表达和行为特性的内容。个性化表达常用的方法可概况为增加风格和人格特性、基于用户个性化信息两方面。2.4.1 基于风格或人格特性
为了能够生成不同风格的评论,Tai 等[6]建立了一种针对特定社交网络领域的评论内容生成方法,该方法针对政治、娱乐等不同领域内的评论特点设计了句子级分类器,将不同句式结构和情感的句子分别使用递归神经网络模型训练,提升生成评论的个性化。Wang团队提出了一个融合心理学中大五人格的个性化的短文本生成模型[57],将大五人格编码成特征向量用于条件语言生成模型中指导输入数据的生成,该模型在基于微博的中文评论验证时能够生成不同的emoji表情来增加评论的个性化。
2.4.2 基于用户个性化信息
在个性化实现方面,也有很多****从用户本身信息考虑。如:Liu[58]提出了从对话内容中学习用户潜在内容的用户个性化表示方法,论文中利用双分支神经网络从用户对话中自动学习用户查询、用户回复和用户配置文件的融合表示,实现了从用户角度的个性化对话生成。Ni[59]对电商评论的自动生成任务设计了基于用户和商品信息以及辅助的感知知识的生成模型,通过用户方向偏好与项目方向的关联关系获得个性化评论。Luo设计了基于用户概要模型和用户偏好模型的个性化对话生成模型MEMN2N[60],概要模型使用分布式概要文件表示用户的个性化信息,并获取类似概要文件的其他用户历史对话,以指导语言风格和对话推荐策略的选择;偏好模型是通过用户概要和知识库间的关联获得用户偏好。
本小节关于短文本的应用研究多是基于文本到文本的生成,现今随着计算机视觉技术的发展,结合NLP技术中图卷积神经网络技术的应用,也有****致力于研究多模态的文本生成,如:Sanabria等提供了针对教学视频的多模态摘要数据集,用于教学式视频摘要的生成[73]。Zhu等提出了多模态基准指导的图文式摘要生成[74]。Chen等设计了基于用户注意力指导的多模态对话生成系统[75]。多模态文本生成的研究历史在国内还较短,但具有巨大的研究和应用价值,也为短文本生成的多样性和个性化提供了新思路。
3 短文本生成评价方法
为了评价生成文本质量的好坏,短文本生成领域目前常用的评价方式主要包括自动评价指标、人工评估指标和利用训练神经网络来模拟人打分流程的模拟人工评估方式。3.1 常用评价指标
短文本生成任务中的常用指标可概括为三类:基于词重叠率的评价指标、基于语言模型优劣的评价指标、基于场景需求的多样性评价指标。短文本任务中常用的基于词重叠率的指标主要为BLEU和ROUGE。
BLEU[76]的本质是对两个句子中重复词频率的计算,在短文本生成任务中,通过BLEU可获得参考文本和生成文本的重合程度,重合程度越高代表生成文本的质量越高,句子流畅性和一致性越好。公式如下:
其中,BP为长度惩罚因子,c为参考句子长度。
BLEU包括BLEU-1、BLEU-2、BLEU-3、BLEU-4,分别表示一元组至四元组的重合程度。但BLEU只从词的角度评估内容,缺乏对语义和句子结构的评估,在短文本生成任务中,通常和其他评价指标共同衡量生成效果。
与BLEU类似,ROUGE[77]也是基于n元词组、序列和词对的重复率的评估方式。ROUGE分为四种:ROUGE-N(N通常取1-4),ROUGE-L,ROUGE-W,ROUGE-S。短文本常用的是基于召回率n元词组重合度的Rouge-N和基于F1值序列重合度的ROUGE-L,计算公式如下:
其中,分母表示在生成文本中的N-gram个数,分子表示生成文本和参考文本中共同的N-gram个数。
其中,L指最长公共子序列,X、Y分别代表生成文本和参考答案的最长公共子序列,Rlcs表示召回率,Plcs表示精确率,Flcs即为ROUGE-L的得分。
ROUGE常用在摘要生成任务中,ROUGE虽然也没有考虑语义信息,但联合ROUGE-N和ROUGE-L和句子数量能够缓解语义信息的缺失,比BLEU评估更全面。
基于语言模型优劣的评价指标包括困惑度Preplexity和熵,用于评估语言模型的好坏,短文本生成中最常使用的为困惑度。
困惑度Perplexity[78]是将词重复出现概率用句子长度归一化表示的指标。困惑度在短文本任务中可以衡量生成评论或对话的质量,是对句子通顺,没有词序颠倒的衡量。计算公式如(5)所示。
其中S表示句子,$\omega_{N}$表示单词。困惑度实际是计算每一个单词概率导数的几何平均。
困惑度越低,说明文本生成的质量越好。但具体生成任务中数据集数量、标点符号和未登陆词等因素会对PPL评估结果造成干扰。
基于场景需求的多样性指标主要是判断生成时是否有大量无关、重复或通用性的文本。短文本中常用的指标包括Distinct和Self-BLEU。
Distinct[79]指标公式如(6)所示。
其中,Count(unique ngram)表示回复中不重复的元组的数量,Count(word)表示生成的回复中元组的总数量。Distinct一般多用于对话生成中,Distinct(n)越大表示生成的回复多样性越高。
Self-BLEU[80]指标公式如(7)所示。
其中,Y为生成的文本列表,$\Delta(y, y^{\prime})$表示两个生成文本间的BLEU得分,表示二者差异。Self-BLEU计算生成文本的BLEU的平均值,Self-BLEU得分越低,表示生成文本的多样性程度越高。
3.2 人工评价指标
当前短文本生成研究中,由于常用的评价指标在语义层面评估的不足,很多研究采用人为打分的方式测量生成的内容质量。人工评价指标通常可划分为基于生成内容本身评估和针对任务完成情况评估。基于生成内容本身的人工评价指标可概括为真假判定、流畅性得分、逻辑性得分,多样性得分等,可根据具体的生成需要进行人为限定。如论文[48]对自动生成诗歌的流畅度、意义、美感等指标进行人工打分。论文[57]对将生成的评论和真实的评论混合,让50名志愿者评判是人工写作还是机器生成,并根据句子流畅性和逻辑性给出1-5评分。
基于内容完成情况的指标多是对任务成功度,系统表现等方面评估。在对话生成中多是评估对话的表现,如角色一致性、语境关联性、外部知识引用情况等。如:论文[56]将人工评价指标定义为:内容级别的适宜性(回应在语法、主题和逻辑上是否合适),知识层面的信息性(回复是否提供了新信息和知识)。论文[68]针对对话的生成效果将人工评分按照生成回复的相关性划定从0到2的评分范围。论文[81]提出从对话语流畅性、角色一致性、语境连贯三项指标判别对话表现。
3.3 基于神经网络的评价方法
鉴于人工评价工作量大、成本高、标注困难且存在主观因素,而且人工很难合理的评估生成的多样性,因此一些研究****们致力于使用神经网络模型的评价方式来改进相关问题。Kannan[82]提出了基于GAN的生成对抗思想来评价对话生成质量,将生成器生成的文本和人真实的对话回复都送入鉴别器中,以鉴别器的对抗损失作为对生成质量的评估。但作者只是提出了这种思想,论文中的生成器和判别器均是独立训练的,生成器效果好和判别效果差都会对结果产生影响,不够客观。相似的,Ryan等人提出了对话生成质量评价的ADEM模型[83],作者主要通过人工标注的形式对对话数据进行打分,然后通过这些标注的数据训练ADEM模型,模型采用分层的循环神经网络预测人工评分,通过预测效果说明模型的评分可以贴合人工评分,虽然该方法说明可以利用神经网络模型来模拟人工打分,但存在对数据集的依赖较大的问题。
由于Bert等预训练模型在文本生成任务中的突出表现,也有很多****们将预训练模型微调用于文本评价任务中。Hassan Kane提出了基于Bert的评价方法ROBERTA-STS[84],与BLEU和ROUGE相比,ROBERTA-STS不仅与人工评价结果相关,而且能够评价句子逻辑是否一致。Zhang提出的BERTSCORE[85]不仅能够计算句子相似度评分,同时给出了准确率、召回率、F1值等评价指标,能够适应更多的NLG任务。BLEURT[86]在生成时使用了两步微调,在预训练过程中使用BLEU和ROUGE等常见的自动评价指标对生成的句子微调,然后再融合人工与自动评价指标进一步微调,评价结果与人工评价更相似。
4 总结与展望
从模型和应用实现发展来看,短文本自动生成技术已经取得了巨大突破。Attention和 Transformer 的提出是文本生成向真正的机器创作道路的重要一步。文本预处理模型的研究也使得文本生成任务取得了突飞猛进的进展,但由于人工智能技术研究还处在“感知”阶段,距离“认知”还存在很大的距离,仍需要在工具、数据、模型计算能力及应用效果的提升方面有所突破[87]。(1)从自然语言处理技术角度, 由于中英文在分词、词性标注、词汇粒度、句法结构等方面都存在着差异,致力于中文或多语种通用的短文本分析及生成方法的研究有很大的应用价值。
(2)在数据集方面,目前短文本领域,高质量通用的数据集构建仍是一大挑战,未来可从生成模型训练或公开搜集的方式进行数据集的构建,结合模型计算力的提升进一步提升生成质量。
(3)在评估方法方面,尽管预训练微调在文本评估任务中取得了不错的成效,但仍不够完善,现在的评估方法仍是以人工和自动评估指标结合应用,未来通用的自动评估体系的建立仍是领域的重点研究方向。
(4)在应用方面,现在的研究对个性化生成越来越关注,个性化生成也是领域的热点研究问题,未来可通过研究用户个性化和生成文本的关联关系,结合多模态文本的生成,进一步探索个性化信息对于生成技术的影响。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
DOI:10.4149/cai_2017_1_1URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
URL [本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 2]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
URL [本文引用: 1]
[C].
URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[DB/OL]. arXiv preprint arXiv:1406.1078,2014(2014-9-3) [2020-12-15]. https://arxiv.org/abs/1406.1078.
URL [本文引用: 1]
[C].
[本文引用: 1]
e[DB/OL]. arXiv preprint arXiv; 1409.0473,2014(2016-5-19)[2020-12-15]. https://arxiv.org/abs/1409.0473.
URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
URL [本文引用: 1]
[DB/OL]. arXiv preprint arXiv: 1511.06732, 2015(2016-5-6)[2020-12-15]. https://arxiv.org/ abs/1511.06732
URL [本文引用: 1]
[DB/OL]. arXiv preprint arXiv: 1312.6114,2013(2014-5-1)[2020-12-15].https://arxiv.org/abs/1312.6114.
URL [本文引用: 1]
[C].
[本文引用: 1]
[DB/OL]. arXiv preprint arXiv:1611. 02731,2016(2017-3-4)[2020-12-15]. https://arxiv.org/abs/1611.02731.
URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[DB/OL]. arXiv preprint arXiv: 1801.07736,2018(2018-3-1)[2020-12-15]. https://arxiv.org/abs/1801.07736.
URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[DB/OL]. arXiv preprint arXiv:2001.04451,2020(2020-2-18)[2020-12-15]. https://arxiv.org/abs/2001.04451.
URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[DB/OL].arXiv preprint arXiv:1611.08562,2016(2016-12-22) [2020-12-15]. https://arxiv.org/abs/1611.08562.
URL [本文引用: 1]
URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 2]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 2]
[C].
[本文引用: 2]
[J].
DOI:10.1109/TASLP.2017.2763243URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[DB/OL]. arXiv preprint arXiv:2004.02202, 2020(2020-4-5)[2020-12-15]. https://arxiv.org/abs/2004.02202.
URL [本文引用: 1]
[C].
[本文引用: 1]
[DB/OL].arXiv preprint arXiv: 2004. 06438. 2020(2020-4-14)[2020-12-15].https://arxiv.org/abs/2004.06438.
URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1609/aaai.v34i05.6453URL [本文引用: 2]
[DB/OL]. arXiv preprint arXiv: 2002.07510. 2020(2020-6-16)[2020-12-15].https://arxiv.org/abs/2002.07510.
URL [本文引用: 1]
[J].
DOI:10.1609/aaai.v34i05.6518URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1609/aaai.v34i05.6252URL [本文引用: 1]
[DB/OL].arXiv preprint arXiv: 1811.00347, 2018(2018-12-7)[2020-12-15].https://arxiv.org/abs/1811.00347.
URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[DB/OL].arXiv preprint arXiv: 2006.14799,2020(2020-6-26)[2020-12-15].https://arxiv.org/abs/2006.14799.
URL [本文引用: 1]
[DB/OL].arXiv preprint arXiv: 1701.08198,2017 (2017-1-27)[2020-12-15].https://arxiv.org/abs/1701.08198.
URL [本文引用: 1]
[C].
[本文引用: 1]
[DB/OL]. arXiv preprint arXiv: 1909.09268,2019(2019-10-30) [2020-12-15]. https://arxiv.org/abs/1909.09268.
URL [本文引用: 1]
[DB/OL]. arXiv preprint arXiv: 1904.09675,2020(2020-2-24) [2020-12-15]. https://arxiv.org/abs/1904.09675.
URL [本文引用: 1]
[C].
[本文引用: 1]
[J].
URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}