 ,1,2, 李俊,1,*, 岳兆娟,1, 赵泽方,1,2
,1,2, 李俊,1,*, 岳兆娟,1, 赵泽方,1,2Hybrid Recommendation Model Based on Autoencoder and Attribute Information
CHEN Zijian,1,2, LI Jun,1,*, YUE Zhaojuan,1, ZHAO Zefang,1,2通讯作者: *李俊(E-mail:jlee@cstnet.cn)
收稿日期:2021-02-2网络出版日期:2021-06-20
| 基金资助: |
Received:2021-02-2Online:2021-06-20
作者简介 About authors

陈子健,中国科学院计算机网络信息中心,在读硕士研究生,主要研究领域为推荐系统、机器学习等。
本文中负责模型设计、实验设计与文献撰写。
CHEN Zijian is a graduate student in Computer Network Information Center of Chinese Academy of Sciences. His main research areas are recommender system and machine learning.
In this paper, he is responsible for the model design, experi-ments design and paper writing.
E-mail:

李俊,中国科学院计算机网络信息中心,研究员,博士生导师,中国科学院特聘研究员,主要研究领域为人工智能和大数据应用、互联网体系结构等。
本文中负责研究指导,论文结构组织。
LI Jun is a research fellow and PhD supervisor at Computer Network Information Center of Chinese Academy of Sciences, specially appointed researcher of Chinese Academy of Sciences. His main research interests are artificial intelligence and big data technical applications and future Internet architecture.
In this paper, he is responsible for the research guidance and paper structure organization.
E-mail:

岳兆娟,中国科学院计算机网络信息中心,高级工程师,主要研究领域为空间信息处理、大数据处理等。
本文中负责研究指导。
YUE Zhaojuan is a senior engineer at Computer Network Information Center of Chinese Academy of Sciences. Her main research interests are spatial information processing and big data processing.
In this paper, she is responsible for the research guidance.
E-mail:

赵泽方,中国科学院计算机网络信息中心,在读硕士研究生,主要研究领域为自然语言处理、情感分析等。
本文中负责实验设计。
ZHAO Zefang is a graduate student in Computer Network Information Center of Chinese Academy of Sciences. His main research areas are natural language processing and deep learning.
In this paper, he is responsible for the experiments design.
E-mail:

摘要
【目的】 传统的协同过滤推荐模型无法提取到用户与项目之间复杂的交互关系,这对于最终的推荐结果会造成一定的不良影响。 【方法】 针对这一问题,本文提出了一种混合推荐模型DAAI(Denoising Autoencoder with Attribute Information),采用降噪自编码器提取评分矩阵中的深层次非线性特征,在此基础上,使用DNN、CNN等方式提取属性信息中隐藏的特征,最后通过多层感知机融合多种特征得到最终的预测评分。 【结论】 将该模型在电影数据集MovieLens上进行实验,与奇异矩阵分解(SVD)、概率矩阵分解(PMF)、AutoRec等传统推荐算法进行比较,实验结果表明DAAI模型具有更好的推荐效果。 【局限】 神经网络结构较为复杂,所以本文的模型相较于传统的推荐模型训练时间有所增加。
关键词:
Abstract
[Objective] The traditional collaborative filtering recommendation models cannot extract the complex interactive relationship between users and projects, which causes a certain adverse impact on the final recommendation results. [Methods] To solve this problem, a hybrid recommendation model DAAI (Denoising Autoencoder with Attribute Information) is proposed in this paper. The denoising autoencoder is used to extract the deep nonlinear features of the scoring matrix. On this basis, DNN, CNN, and other methods are used to extract the hidden features in the attribute information. Finally, a multi-layer perceptron is adopted to generate the final prediction score by aggregating various features.[Conclusions] The proposed model is tested on the MovieLens dataset and compared with the traditional recommendation algorithms such as SVD, PMF, and AutoRec. The experiment results show that the DAAI model can achieve better recommendation results. [Limitations] Due to the complex neural network structure, the training cost of our model increases slightly compared with traditional models.
Keywords:
PDF (5753KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
陈子健, 李俊, 岳兆娟, 赵泽方. 基于自编码器与属性信息的混合推荐模型[J]. 数据与计算发展前沿, 2021, 3(3): 148-155 doi:10.11871/jfdc.issn.2096-742X.2021.03.013
CHEN Zijian, LI Jun, YUE Zhaojuan, ZHAO Zefang.
引言
随着互联网的普及与发展,各类数据信息在网络空间内呈爆炸式的增长,如何让用户在海量的信息中寻找到自己感兴趣的信息成为了一个亟待解决的问题。为了解决这一问题,推荐系统应运而生,它通过用户的交互历史为用户提供个性化的信息推荐,满足用户对信息的需要。近年来,推荐系统在电影、音乐、新闻、电商、短视频等领域都发挥着巨大的作用,在为用户带来便利的同时也具有相当大的商业价值。传统的推荐方法可以分为三大类:基于内容的推荐、协同过滤推荐以及混合推荐。基于内容的推荐是最简单有效的推荐算法,基本思想是从项目内容相似性方面进行推荐,为用户推荐与其交互过的项目内容相似的项目。基于协同过滤的推荐算法利用群体智慧的思想,推荐结果更具新颖性。混合推荐算法则是将多种不同的推荐算法融合起来,发挥各自的优势。
目前使用最为广泛的推荐模型当属协同过滤推荐模型。具体可分为基于邻域的协同过滤与基于模型的协同过滤。其中基于邻域的协同过滤根据用户与项目的交互历史信息,如评分矩阵,通过相似度的计算,计算出用户之间的相似度或项目之间的相似度,从而进行基于用户或基于项目的推荐。基于模型的协同过滤则是通过构建偏好模型,提取用户和项目的隐式空间表示,预测用户对项目的潜在偏好从而进行推荐。这其中最为著名的模型为矩阵分解推荐模型,将用户的评分矩阵分解成为两个规模较小的矩阵,用两个矩阵相乘得到的结果对原始的评分矩阵进行补全从而得到用户未评分区域的预测的评分。协同过滤的优势在于仅使用交互矩阵就可以进行推荐,不依赖于其他信息,而且相比较于基于内容的推荐可以提供更加多样化的推荐结果,因此受到了广泛的关注。然而协同过滤方法也存在着一些问题,以矩阵分解推荐模型为例,它只能提取用户和项目的浅层次特征,无法提取到深层次的非线性特征;此外,交互矩阵的数据稀疏性也使得矩阵分解模型容易出现过拟合等问题,对推荐的效果造成了不良的影响。
近年来,深度学习在图像处理、自然语言处理、语音识别等许多领域都展现出了强大的能力。得益于其在特征提取与特征融合方面的优势,推荐系统领域的研究人员可以通过深度学习的方式将更多有效信息引入到推荐过程中来,提升推荐准确率的同时,缓解传统协同过滤推荐算法的数据稀疏性与冷启动问题。
针对协同过滤存在的上述问题,本文使用深度学习技术,提出了一种混合推荐模型以提升推荐效果,本文的工作如下:
(1)使用降噪自编码器代替传统矩阵分解方法,从评分矩阵中获取到用户和项目鲁棒性的非线性特征表示。
(2)将属性信息融合到特征表示中去,构建一种混合推荐模型,通过训练确定模型参数,得到用户对项目的预测评分。
(3)通过实验进行对比验证,证明本文提出的模型相较于传统的推荐模型可以取得更好的评分预测效果。
1 相关工作
1.1 自编码器在推荐系统中的应用
自编码器是一种经典的自监督机器学习模型,一个最基本的自编码器由输入层、隐藏层和输出层三部分组成,其中输入层和输出层的维度相同,隐藏层的维度较小。输入层到隐藏层的计算过程被称为编码过程,隐藏层到输出层的计算过程则被称为解码过程。通过最小化输出层与输入层的重构误差训练网络使得解码后的数据尽可能地接近输入层的原始数据。近年来许多研究将自编码器应用到推荐领域。Sedhain等[1]将自编码器与协同过滤推荐结合起来,提出了AutoRec模型,使用一个单隐藏层的自编码器对评分矩阵进行编码与解码,在输出层获得重构后的评分向量,以此得到用户对项目的预测评分,这是自编码器与推荐系统的第一次结合。Strub等[2]在此基础上,使用栈式降噪自编码器学习用户和项目的特征表示,对缺失的评分进行预测,增强了模型的表示能力和鲁棒性。Zhou等[3]使用栈式降噪自编码器处理电影评分矩阵,得到电影的潜在特征表示,利用基于项目的协同过滤计算电影之间的相似度进行电影推荐。自编码器中隐层的输出向量可以看作是原始输入向量的降维压缩表示,其在最大程度地保留了输入向量中的关键特征信息的同时,也可以提取到交互矩阵中的非线性特征。由于用户和项目之间存在着复杂的交互关系,相较于单纯地使用自编码器的重构输出作为预测结果,将用户与项目的隐式空间中的基于交互过程的特征表示提取出来,更有利于下游任务对用户和项目之间复杂交互关系进行建模。
1.2 利用属性信息进行推荐
由于评分矩阵的稀疏性,仅使用评分矩阵的推荐已经很难取得令人满意的效果,随着大数据时代的到来,各类属性信息的获取变得越来越容易,但是由于属性信息具有多模态、异构性、分布不均匀等问题,如何有效地构建模型,提取和利用属性信息提高推荐的准确性也成为了推荐领域的热门研究问题[4]。Shan等[5]提出了Deep-Crossing推荐模型用于广告领域,从搜索词、广告标题、点击率、落地页等属性信息中提取特征,使用多层神经网络进行特征融合完成点击率预测任务实现广告推荐。Cheng等[6]提出了Wide&Deep模型,对提取到的属性信息采用不同的融合方式,使用多层神经网络构建Deep部分让模型具有“泛化能力”,使用单输入层构建Wide部分让模型具有“记忆能力”,通过这样的结构兼顾了用户兴趣的专一性与发散性,完成推荐任务。Zhang等[7]使用知识图谱、电影摘要、电影海报等作为属性信息,分别提取知识图谱中实体的结构化表示、电影摘要中的文本表示以及海报中的视觉表示,对多模态的特征进行整合,从而提升推荐的效果。2 基于自编码器与属性信息的混合推荐模型
2.1 模型整体介绍
基于以上的研究分析,本文提出一种基于自编码器与属性信息的混合推荐模型DAAI,使用两个降噪自编码器处理评分矩阵,分别提取出评分矩阵中蕴含的用户特征与项目特征;同时将用户和项目的各类属性信息通过DNN、CNN等方式处理得到基于属性信息的用户特征与项目特征。将两种特征融合之后,通过MLP层进行特征融合并输出预测评分。最后使用真实评分与预测评分的误差训练整个网络的参数。推荐模型结构如图1所示。图1
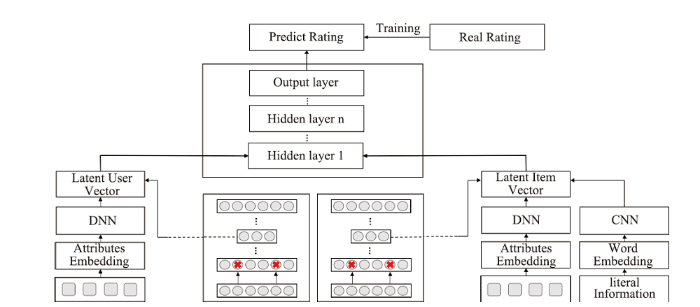 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1DAAI推荐模型结构图
Fig.1Structure of DAAI recommendation system
不同于现有的基于深度学习的推荐模型,DAAI使用评分矩阵的目的是提取矩阵中的非线性特征,而不是单纯地将评分作为模型训练的监督信号或直接重构矩阵。而相较于协同过滤推荐模型,DAAI加入了属性信息以提高推荐效果。DAAI与现有的一些推荐模型的对比如表1所示。
Table 1
表1
表1DAAI与其他模型的对比
Table 1
| 具体模型 | 评分矩阵的作用 | 属性信息 |
|---|---|---|
| User-CF | 计算用户相似度 | 不使用 |
| Item-CF | 计算项目相似度 | 不使用 |
| SVD | 进行奇异值矩阵分解 | 不使用 |
| PMF | 进行概率矩阵分解 | 不使用 |
| AutoRec | 使用自编码器重构评分矩阵 | 不使用 |
| Deep-Crossing | 将评分作为监督信号 | 使用属性信息进行推荐 |
| DAAI | 使用降噪自编码器获取非线性特征 | 使用属性信息提高推荐效果 |
新窗口打开|下载CSV
2.2 交互特征的获取
由于传统的自编码器存在过拟合,泛化能力差等缺点,所以本文使用降噪自编码器进行特征提取。区别于普通的自编码器,降噪自编码器在输入层随机地将一部分原始数据替换为噪声数据,而在输出层使用原始数据进行误差计算训练模型,通过这种方式提高了自编码器的泛化能力,缓解了交互矩阵的数据噪音问题[8]。本文使用两个降噪自编码器在用户项目交互矩阵上进行特征提取,分别是提取用户特征的模块与提取项目特征的模块,以为例,自编码器的训练过程如图2所示。
图2
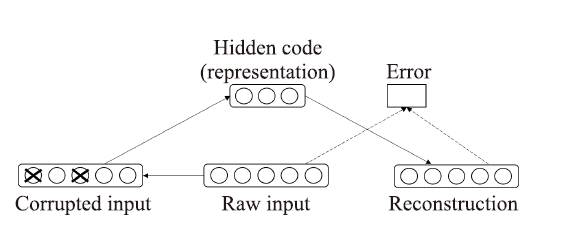 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2降噪自编码器的训练过程
Fig.2Training process of denoising autoencoder
设输入的评分矩阵$R=[r_{1},r_{1},\dots,r_{n}]$,其中r代表用户对项目的评分向量,用户的总体数量为n。首先在输入层部分,在输入的数据中按照一定的比例加入噪声,得到受损后的数据$\widetilde{R}$;将$\widetilde{R}$输入到隐藏层中,隐藏层的计算过程如下:
$\begin{aligned} H_{1} &=\sigma\left(W_{1} \widetilde{R}+b_{1}\right) \\ H_{l} &=\sigma\left(W_{l} H_{l-1}+b_{l}\right) \end{aligned}$
l是具体所在的隐藏层,W代表权重矩阵,b代表偏置项,设隐藏层的总数为L,将L/2层之前看作是编码部分,L/2层之后看作是解码部分,$\sigma $是隐藏层神经元的非线性激活函数;模型的最后一层为输出层,输出层的表示为$\widehat{R}$,最小化均方误差作为训练目标:$min|| \widehat{R}-R||_{2}^{2}$,使用反向传播将输出层的误差反向传播至各层,调整各权重和偏置的值。训练UserDAE的目的是从用户矩阵中提取用户的特征表示,即第L/2层的隐层输出。将用户的评分向量通过网络的正向传播可以获取到L/2层的输出即用户基于评分的特征向量u*。
同理,将评分矩阵转置后,将项目的评分向量输入到ItemDAE模块获得ItemDAE的L/2层的输出即项目基于评分的特征向量i*。
2.3 属性信息的利用
为了进一步提升推荐效果,本文将用户与项目的属性信息加以利用,在上一节通过评分矩阵得到的特征表示的基础上,结合基于属性信息的特征表示。一般来说,用户的属性包括用户ID、性别、年龄、职业、地区等,而项目的属性包括项目ID、类型、标题、摘要等。为了在推荐模型中使用这些信息,首先需要将各类属性信息经过一定的预处理。在本文中,将用户性别、职业、项目类型等信息通过构建字典的方式映射为数字信息。设用户的属性信息向量为$u={u_{1},u_{2},u_{3},\cdots,u_{n}}$,项目的非文本属性信息向量为$i={i_{1},i_{2},i_{3},\cdots,i_{m}}$,在输入层之后通过嵌入层将属性信息中高维稀疏的编码表示映射为低维稠密的编码表示。将得到的嵌入表示$u^{emb}$,$i^{emb}$输入到隐藏层中对网络进行训练,隐藏层的输出即为用户基于属性信息的特征表示$\bar{u}$和项目的基于非文本属性的特征表示$\widetilde{i}$,计算过程如下:$\bar{u}=f\left(w_{u 2} f\left(w_{u 1} u^{e m b}+b_{u 1}\right)+b_{u 2}\right)$
$\tilde{\imath}=f\left(w_{i 1} i^{e m b}+b_{i 1}\right)$
其中f为激活函数,这里采用ReLu激活函数,w为神经网络的权值矩阵,b代表偏置值。
2.4 使用卷积神经网络提取文本信息
卷积神经网络是一种前馈神经网络,被广泛应用于图像音频等领域的特征提取,通过多个卷积核在特征矩阵上的移动来提取多重局部特征,聚合局部特征来得到原始数据的特征表示[9]。最近的研究证明,卷积神经网络在文本处理方面也可以取得良好的效果。在本文的工作中,采用CNN-Rand的方式对项目的文本信息进行特征抽取[10,11],文本的词汇部分被随机初始化,并在训练的过程中进行调整,得到每个词的嵌入向量。在整体模型训练的过程中,从嵌入层中得到电影标题的向量集合T=[t1, t2, t3,…, tn],其中t表示每个词的嵌入向量,n表示标题中词的个数。在卷积层,将矩阵T作为卷积神经网络的输入进行卷积操作。使用大小为k×d的卷积核Fi对矩阵从上至下进行卷积操作,k为卷积核的宽度,即每次卷积覆盖的单词数量,d为每个单词的维度。第i个卷积核在矩阵T上得到的第j个特征为eji,可以通过下面的公式得到:$e_{i}^{j}=f(T * F_{i}+b_{i})$
其中$j=(1,2,\cdots,n-k+1)$,*代表卷积运算,bi代表偏置项,f代表激活函数,本文采用Relu。则第i个卷积核得到的文本特征向量为
$E_{i}=[e_{1},e_{2},\cdots,e_{n-k+1}]$
每个卷积核对应着不同的特征信息,且由于卷积核大小不同,得到的特征向量的长度也是不同的,为了从每个卷积核中得到最有价值的信息,卷积层之后在池化层采用最大池化max-pooling操作提取每个向量中特征值最大的特征,去除冗余信息,组成该文本的完整文本语义向量z。
Z=[max(E1),max(E2),…, max(Ek)]
将池化后的向量输入到全连接层,得到项目的文本特征表示it:
$i_{t}=f(wz+b)$
将项目的基于非文本属性的特征表示$\widetilde{l}$与文本属性的特征表示it拼接起来,得到项目的基于属性信息的特征表示$\bar{l}$:
$\bar{\imath}=\operatorname{concat}\left(\tilde{\imath}, i_{t}\right)$2.5 评分预测与模型训练
通过以上的工作,我们得到了用户和项目基于评分矩阵的特征表示u*,i*,基于属性信息的特征表示$\bar{u}$,$\bar{l}$将这两种特征拼接在一起,得到用户特征向量$\widehat{u}$和项目特征向量$\widehat{l}$,同样使用concat操作。通过多层感知机对特征进行交叉融合,输出最后的预测评分$\widehat{R}_{u,i}$。
$\widehat{R}_{u i}=M L P(\widehat{u}, \hat{\imath})$,
推荐任务的最终目标是尽可能准确预测用户对项目的评分,即使得$\widehat{R}_{u,i}$逼近于Ru,i,所以将模型的损失函数定义为:
$\operatorname{Loss}=\sum_{u, i}\left(R_{u, i}-\widehat{R}_{u, i}\right)^{2}$
3 实验分析
3.1 实验环境、数据集及评价指标
实验编程环境为Python 3.6,深度学习计算框架为TensorFlow 1.4,实验平台为Google Colaboratory。本实验采用在推荐系统实验中被广泛使用的MovieLens数据集,该数据集由美国明尼苏达大学的GroupLens研究小组收集提供。选用MovieLens-100K和MovieLens-1M两个版本,数据集具体情况如表2所示。
Table 2
表2
表2数据集信息统计
Table 2
| 数据集 | 用户 | 电影 | 评分数 | 稀疏度 |
|---|---|---|---|---|
| ML-100K | 943 | 1682 | 100000 | 93.70% |
| ML-1M | 6040 | 3905 | 1000209 | 95.81% |
新窗口打开|下载CSV
统一数据集的数据格式,去掉数据集中电影链接、电影题目中的发行年份等信息,将数据集按照80%、20%的比例划分为训练集和测试集。由于本文将推荐问题转换为了评分预测问题,所以采用均方根误差RMSE作为实验的评价指标,RMSE的计算公式如下:
$R M S E=\sqrt{\frac{1}{|D|} \sum_{(i, j) \in D}\left(Y_{i j}-\widehat{Y}_{i j}\right)^{2}}$
|D|为测试数据的个数,Yij为用户i对项目j的评分,$\widehat{Y}_{ij}$为用户i对项目j的预测评分,误差值越低则代表模型的预测效果越好。
3.2 模型参数设置
模型的结构包括三部分,在降噪自编码器部分,隐藏层的层数设置为3,中间隐层维度为200,采用sigmoid激活函数,噪声率设置为0.2;在属性特征提取部分,文本卷积核的规模分别为{2,3,4,5},卷积核数目为8,用户与项目的属性信息表示维度均设置为200;评分拟合部分全连接层数设置为3,激活函数为Relu,dropout为0.5,batch_size为128。整体采用Adam优化器进行训练。模型训练的过程中,学习率的选择会对最终的实验效果造成较大的影响,实验表明学习率为0.0001时模型效果最好,在ML-100K数据集上误差值随学习率的变化趋势如图3所示。图3
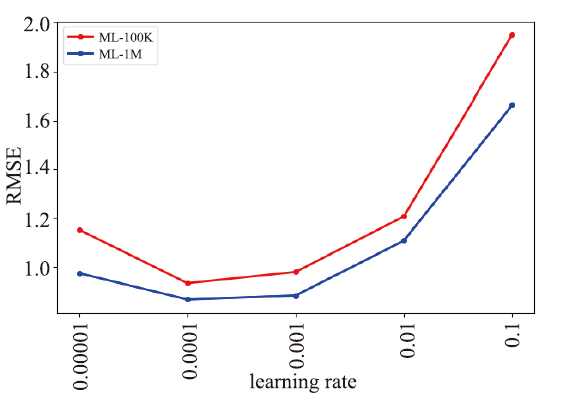 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3不同学习率下RMSE的比较
Fig.3RMSE comparison with different learning rates
3.3 对比实验
实验选用的对比模型包括:(1)SVD[12]:经典的基于用户和项目的奇异值矩阵分解模型,将评分矩阵分解为奇异矩阵和奇异值。
(2)PMF[13]:概率矩阵分解模型,假设用户隐向量、项目隐向量以及评分的分布都服从高斯分布。
(3)NMF[14]:非负矩阵分解模型,分解后的矩阵元素均为正值,符合实际打分的情况。
(4)U-AutoRec:基于用户角度的自编码器推荐模型,输入用户对项目的评分矩阵,通过编码解码预测缺失的评分值,对评分数据进行补全。
3.4 结果分析
通过实验我们发现,在ML-100K数据集上NMF模型的准确率最高,DAAI模型的准确率相较于其他三种模型均有提高,略低于NMF模型;而在数据更加稀疏的ML-1M数据集上面,DAAI模型可以取得最好的预测准确率,相较于对比模型最多提升了2.9%。这意味着我们的模型在稀疏数据集上依然能取得良好的效果。实验结果如表3所示。Table 3
表3
表3不同推荐模型的RMSE对比
Table 3
| 模型 | ML-100K | ML-1M |
|---|---|---|
| PMF | 0.951 | 0.868 |
| U-AutoRec | 0.936 | 0.891 |
| NMF | 0.925 | 0.876 |
| SVD | 0.938 | 0.870 |
| DAAI | 0.932 | 0.865 |
新窗口打开|下载CSV
4 结论与下一步工作
本文使用降噪自编码器对评分矩阵进行特征提取,使用DNN、CNN等方式结合属性信息构建推荐模型,通过实验证明相比较于传统的基于评分矩阵的推荐模型可以取得更好的推荐效果。属性信息的加入意味着在数据稀疏的情况下可以依靠属性信息进行推荐,在缓解数据稀疏性问题方面起到了一定的作用。下一步可以将注意力机制和更多的属性信息等加入推荐模型中,进一步提升推荐的准确度。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}