 ,1,2, 陈远平,1,*
,1,2, 陈远平,1,*Research on Resource Recommendation Technology of Scientific Research Information Portal
LI Yan,1,2, CHEN Yuanping,1,*通讯作者: *陈远平(E-mail:ypchen@cnic.cn)
收稿日期:2020-11-15网络出版日期:2021-04-20
Received:2020-11-15Online:2021-04-20
作者简介 About authors

李言,中国科学L院计算机网络信息中心,中国科学院大学,硕士研究生,主要研究方向为软件开发、推荐技术、大数据分析。
本文承担工作为:模型设计,实验数据分析论文写作。
LI Yan is a master student in Computer Network Information Center of Chinese Academy of Sciences (University of Chinese Academy of Sciences). His main research interests are software development, recommended technology and big data analysis.
In this paper, he undertakes the following tasks: model design, experimental data analysis and paper writing.
E-mail:

陈远平,中国科学院计算机网络信息中心,高级工程师,主要研究方向为数据分析、决策分析模型研究、数据挖掘应用。
本文承担工作为:论文整体框架设计、研究指导。
CHEN Yuanping is a senior engineer from the Computer Network Information Center of the Chinese Academy of Sciences. His main research interests are data analysis, decision analysis model research, and data mining applications.
In this paper, he undertakes the following tasks: the overall framework design and research guidance of the thesis.
E-mail:

摘要
【应用背景】科研信息门户作为科研工作者获取资源服务的入口,已经成为了科研人员、管理决策者、学生等多种用户的工作台,在科研活动、科研管理、教育培训、科学传播等多个业务领域发挥着重要作用。【目的】针对科研信息门户中存在的信息资源配置不合理问题,设计出适用于科研信息门户的推荐算法来提高信息资源的推送效率,对于科研工作者是十分有意义的。【方法】本文提出了一个混合的推荐算法,对于首次使用系统的新用户,可以基于用户属性,通过K-means聚类后找到相邻用户来计算预测评分,对于存在行为数据的用户,先通过计算用户与资源的相似度来解决隐式反馈缺少负反馈的问题,再使用矩阵分解的方法计算预测评分。最后将两种算法的预测评分进行线性组合得到最终预测评分,该算法既利用了群体智慧也体现了个性化。【结果】通过在真实的科研信息门户网站上进行代码埋点来采集用户行为数据,完成对比试验,证明提出的推荐方法能在解决冷启动问题的同时保证较高的推荐准确率。
关键词:
Abstract
[Application Background] As the entrance for scientific researchers to obtain resource services, the scientific research information portal has become a workbench for scientific researchers, management decision makers, students and other users. It is used in scientific research activities, scientific research management, education and training, and scientific communication. Each business area plays an important role. [Objective] To address the issue of unreasonable information resources allocation in scientific research information portals, design of recommendation technology suitable for scientific research information portals to improve the push efficiency of information resources is of great significance to scientific researchers. [Methods] This paper proposes a hybrid recommendation algorithm. For new users who use the system for the first time, based on user attributes, neighbor users can be found through K-means clustering to calculate prediction scores. For old users, the problem of lacking negative feedback in implicit feedback is firstly solved by calculating the similarity between users and resources, and then matrix factorization is used to calculate the predicted score. Finally, the prediction scores of the two algorithms can be linearly combined to obtain the final prediction score. The algorithm not only employs the wisdom of the group but also embodies personalization. [Results] Based on user behavior data by embedding code on the real scientific research information portal website, the comparative experiment proves that the proposed recommendation method can solve the cold start problem while ensuring high recommendation accuracy.
Keywords:
PDF (5456KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
李言, 陈远平. 科研信息门户的资源推荐技术研究. 数据与计算发展前沿[J], 2021, 3(2): 112-119 doi:10.11871/jfdc.issn.2096-742X.2021.02.013
LI Yan, CHEN Yuanping.
引言
科研信息门户作为各类信息、应用和资源整合利用的平台,为用户提供了统一的终端使用者接入环境。科研信息门户的存在可以帮助科研人员了解学科态势、确定研究目标的必要性,可以为管理决策者提供综合信息的分析以及辅助决策的支持,可以帮助学生获取日常学习研究等信息。但在实际应用中,现阶段的科研信息门户尚存在一些需要解决的问题,如主页承载的信息量有限、资源配置不合理、提供的信息服务不能满足用户的个性化科研需求等,无法达成“以用户为中心”的目标。因此,设计出适用于科研信息门户的推荐技术,提高资源推送的效率,向用户提供个性化的服务,有利于帮助用户从大量、无序的信息资源中解放出来,减少用户检索信息花费的时间,提高工作效率,使科研信息门户对资源的组织、管理和服务提供方面获得改善和提升。随着互联网行业的快速发展和大数据概念与技术的普及,信息爆炸是互联网用户目前最直观的感受。当前时代下,信息增长的速度已经远远超过我们的接受速度[1,2,3],这促进了推荐技术的快速发展。推荐系统可以帮助用户从较大的搜索空间中找到感兴趣的对象,在新闻、电商、短视频等多个应用领域,推荐系统都提高了信息投放的效率并创造了可观的增量收入,成为许多行业都不可或缺的重要技术[4]。在众多的推荐算法中,比较常见的有基于协同过滤的推荐算法、基于矩阵分解的推荐算法、基于稀疏自编码的推荐算法、基于社交网络的推荐算法等等[5],每种方法各有利弊,但没有一种方法利用了数据的所有信息。为此,本文从科研信息门户领域出发,在现有研究的基础上构建了一种混合推荐算法,可以结合不同算法的优点,克服单一推荐算法的局限性。
1 基于用户属性聚类的推荐算法
用户聚类分析(Cluster analysis)也称群体分析,是一种数据点分组的机器学习技术,给定一组数据点,可以用聚类算法将每个数据点分到特定的组中[6,7]。由于本系统已经有过几代版本的迭代,存在了一些老用户,这些老用户在使用了一段时间后产生了一些有参考价值的浏览和点击信息,借助这些数据可以解决新用户进入系统产生的“冷启动”问题。具体的思路是根据用户属性信息将用户进行聚类,找到与目标用户具有相似属性的邻居用户,再来进行预测评分和产生推荐。本文以科研信息门户系统中较有参考意义的六种属性信息作为用户的特征数据,这六种属性信息分别是年龄、学历、所在单位、研究领域、职称和角色类型。在使用这些属性信息进行聚类运算前需要进行数据预处理,主要是通过one-hot编码将非连续型数值特征映射成离散值,经过处理会让后续的特征之间的距离计算更加合理。本文采用皮尔逊相关系数来计算用户间的相似度,如式(1)所示。
其中,sim(m, n) 表示用户m和用户n的评分相似度,Rmi和Rni分别表示用户m和用户n对资源i的评分,R m和R n分别表示用户m和用户n对资源i的平均评分,Imn表示用户m和用户n对共同评分的项目组成的集合。
本文选取K-means算法作为聚类手段。K-means算法可以在初始指定k个簇后,反复计算更新每个簇的中心,当每个簇的中心都不发生改变时,算法结束,输出更新后的k个簇。不考虑个性化时,可以认为同一个簇中的用户有相同的偏好。基于这个思路可以得到推荐算法的实现流程,如图1所示。
图1
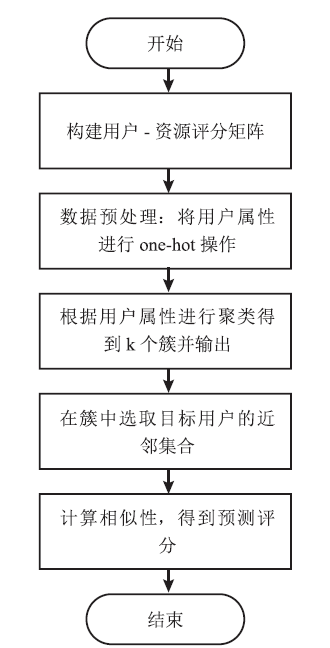 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1基于用户属性的推荐算法流程图
Fig.1Flowchart of recommendation algorithm based on user attributes
最终的预测评分基于sim(m, n) 来得到:
其中,$P_{(m i) \text { Cluster }}^{\prime}$ 表示在用户属性聚类后,目标用户 m 在其簇中对资源 i 的预测评分,$S_{nearest}$ 表示目标用户在其簇中的邻居用户集合,$\overline{R_{m}}$ 和 $\overline{R_{n}}$ 分别表示目标用户 m 与其簇中邻居用户 n 对资源 i 的平均评分。
2 基于隐式反馈的推荐算法
在科研信息门户网站上,通常利用网站运行产生的日志数据或者在网站上布设埋点来获取用户行为数据,这些数据描述了一个用户在某个时间点、某个地方,以某种方式完成了某个具体的事情,可以利用这些数据还原用户的点击、浏览等行为信息,在一些文献中[8,9],把这些数据信息定义为隐式反馈数据,因为这些数据不能直接表达用户的喜好;与之相对应的是显示反馈数据,如用户评分、评论,可以明确地表达用户喜好。本文研究的推荐技术是基于隐式反馈数据的。隐式反馈并没有具体的数值,往往是用户的一次行为,比如用户的一次点击、一次浏览等等,相比之下,显式反馈往往是一个具体的数值,比如用户的评分,通过这些细致的评分我们可以清晰地了解到用户的偏好。在目前的学术界,有许多的推荐算法研究都是针对显式反馈的数据的,许多著名的开源数据集如MoiveLens也是属于显式反馈数据,但在实际应用中,显式反馈的数据需要用户的额外操作,容易引起用户的反感,所以有大量的用户并不会进行内容评分,这就造成了显式反馈的数据收集起来十分困难。隐式反馈的数据相比起来收集十分容易,潜在的数据规模也很巨大,在以后很有可能替代显式数据成为推荐系统的主要输入,所以研究基于隐式反馈的推荐技术是非常有意义的。
虽然隐式数据获取方便,但由于其自身的特征性,也导致基于隐式反馈的推荐技术存在一些挑战:如图2所示,两个表格代表用户对资源的打分,在显式反馈中评分从低到高反映了用户对物品的喜好程度,而隐式反馈可以定义成0和1,0表示用户没有点击或使用过,1表示用户点击或使用过,不同于显式反馈同时包含了正负反馈,隐式反馈的数据只有正反馈,即通过隐式反馈我们只能推测出用户可能喜欢某资源,但无法得知用户是否不喜欢某资源,所以如何解决隐式反馈缺少负反馈问题同时保证较高的推荐准确率是本文面临的主要挑战。
图2
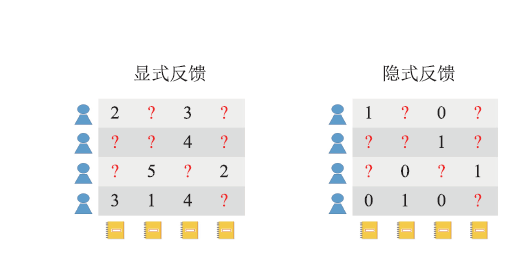 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2显式反馈和隐式反馈的区别
Fig.2The difference between explicit feedback and implicit feedback
考虑到缺少负反馈的问题,直接套用一些现有的推荐模型准确率不是很理想,有些****提出了适用的推荐模型,比如Hu[10]和俞东进[11]等人提出了置信度模型,用户和物品的交互次数越多,对应的置信度越大。Loni[12]等人将用户的交互行为分层,将高层次的反馈视为更强烈的偏好信息。Pan[13] 等人将只存在正样本的协同过滤问题称为单类协同过滤问题(One-Class Collaborative Filtering),通过人工采集负样本来解决缺少负反馈的问题,并提出了三种负样本的选择策略:
(1)根据正样本数量,随机选取等量负样本。
(2)选择活跃用户未选择的样本作为负样本,因为活跃用户的置信度更高。
(3)选择无人问津的样本作为负样本,因为一个较为流行的项目不太可能是负样本。
还有一些****[14,15,16]在单类协同过滤模型的基础上引入辅助信息进行推荐,使推荐的准确率获得了一定提高。考虑到在科研门户信息系统中,用户与资源的关联性较强,所以在本文中,利用了用户与资源的相似度来计算预测评分,设置 $C_{ui}$ 作为用户倾向权重,$C_{ui}$∈[0,1]。对于正样本,权重固定为1,表示用户和资源之间存在交互,对于负样本,权重负相关于用户和资源的相似度。其中用户和资源的相似度可以通过公式(3)计算:
其中,$S(i)=\left(\left(w_{i 1}, c_{i 1}\right),\left(w_{i 2}, c_{i 2}\right), \ldots,\left(w_{i k}, c_{i k}\right), \ldots\right)$, $w_{ik}$代表资源描述切分出来的分词, $C_{ik}$代表该分词出现的次数,$S_{u}$ 代表用户 $u$ 近期浏览的资源集合,$S_{t}$ 代表目标资源。
由于在推荐系统中的矩阵通常是非常稀疏的,为了降低存储空间并提高运算效率需要将原矩阵进行分解,本文选择ALS(Alternating Least Square)作为分解矩阵的方法,与常规的SVD(Singular Value Decomposition)分解方法相比,ALS方法可以有效地解决过拟合问题,而且扩展性更好[17,18]。
下面基于ALS方法,用两个低维矩阵来逼近原矩阵,同时引入代表用户倾向的权重 $C_{ui}$,可以得到如下损失函数:
其中 $u \in\{1,2, \ldots, m\}$,$i \in\{1,2, \ldots, n\}$,$X \in \mathbb{R}^{m \times k}$ ,$ Y \in \mathbb{R}^{n \times k}$。$m$ 代表用户的数量,$n$ 代表资源的数量,$k$ 代表矩阵降维后的维度,$k \ll \min (m, n)$ 。矩阵 $X$ 代表用户对隐含特征的偏好矩阵,矩阵 $Y$ 代表资源所包含隐含特征的矩阵。具体表示如下所示:
$\begin{array}{l}X=\left[\begin{array}{ccc}x_{11} & \cdots & x_{1 k} \\\vdots & \ddots & \vdots \\x_{m 1} & \cdots & x_{m k}\end{array}\right]=\left[\begin{array}{c}X_{1} \\\vdots \\X_{m}\end{array}\right] \\Y=\left[\begin{array}{ccc}y_{11} & \cdots & y_{1 k} \\\vdots & \ddots & \vdots \\y_{n 1} & \cdots & y_{n k}\end{array}\right]=\left[\begin{array}{c}Y_{1} \\\vdots \\Y_{n}\end{array}\right]\end{array}$
在式(4)中对 $X_{u}$ 求导,可以得到式(5):
其中,$I$是单位矩阵,$C^{u}$ 是一个 $n$×$n$ 的对角矩阵,$R_{u}$ 是 $n$×1 的列向量。具体表示如下所示:
$C^{u}=\left[\begin{array}{cccc}C_{u 1} & 0 & \cdots & 0 \\0 & C_{u 2} & \cdots & 0 \\\vdots & \vdots & \ddots & \vdots \\0 & 0 & \cdots & C_{u n}\end{array}\right]$
$R_{u}=\left[\begin{array}{c}R_{u 1} \\R_{u 2} \\\vdots \\R_{u n}\end{array}\right]$
在式(5)中令导数 $\frac{\partial \operatorname{Loss}(X, Y)}{\partial X_{u}}=0$,可以得到式(6):
同理可得式(7):
算法的具体步骤如下:

利用降维后的用户矩阵 $X$ 和资源矩阵 $Y$,可以得到基于隐式反馈模型的预测评分(8):
3 混合推荐算法
将前两种方法得到预测评分进行进一步的加权组合,可以得到最终的预测评分(9):其中,$P_{ui}$ 是最后目标用户 $u$ 对资源 $i$ 的评分;$\text P^{\prime}_{ (ui) Cluster }$ 代表的是在用户属性聚类后,基于用户属性的预测评分;$\text P^{\prime}_{ (ui) Implicit }$ 代表的是基于隐式反馈推荐模型的预测评分。同时为了结合两者的预测评分,对其加入了参数 $\lambda$,其中 $\lambda \in(0,1]$。对于首次进入系统的新用户,并无历史浏览数据,无法计算出用户偏好预测评分,从用户表中可以取到用户的属性特征,即 $\lambda=1$,完全利用用户属性来进行评分的预测;对于能够获取有价值的用户-资源评分的情况,可以结合用户属性和用户偏好的预测评分,根据具体情况或依据训练值来获得最佳参数值 $\lambda$,使其能够对系统产生更好的推荐效果。最后根据评分进行Top-N推荐,即在用户对资源的推荐列表中,将预测评分由高到低进行排序,把预测评分前N的资源推荐给目标用户。
4 实验
4.1 数据来源
本文的数据主要通过在科研门户客户端进行代码埋点的方式来获得,其原理是向客户端嵌入一段JavaScript代码,在监听到用户与网页元素控件发生交互时将用户行为的过程及结果记录上报至后端数据采集平台,这种方式可以将客户端的用户行为尽可能全面地采集。实验统计了科研信息门户后端数据采集平台三个月内2,169个用户在405个资源上产生的共783,009条事件信息。为了方便计算,本实验将资源的加载、访问和点击事件定义为正样本。为了评估算法性能,本实验将采集到的数据的2/3作为训练集,其余1/3作为测试集。4.2 推荐算法的评价指标
实验采用精确率(precision)和召回率(recall)作为评价推荐算法效果的标准。精确率描述了推荐样本的正确率,召回率又称查全率,描述了推荐样本占所有实际正样本的比例。对于某个给定资源的推荐,结果有4种:(1)True Positive(TP),预测为正样本且实际为正样本。
(2)False Positive(FP),预测为正样本但实际为负样本。
(3)True Negative(TN),预测为负样本且实际为负样本。
(4)False Negative(FN),预测为负样本但实际为正样本。
进一步的,根据精确率和召回率的定义可以得到计算公式如式(10)和(11)所示。其中,$U$是测试集中用户的集合,$R(U)$ 是根据用户在测试集上的行为数据做出的推荐集合,$T(U)$ 是测试集中正样本的集合。
4.3 实验结果及分析
首先是关于基于用户属性聚类的推荐算法实验。将科研门户系统中的2,169个用户输入到聚类算法中,设置9个初始的簇中心,输出后的结果如表1所示。Table 1
表1
表1每个簇中的用户数量
Table 1
| 簇1 | 簇2 | 簇3 | 簇4 | 簇5 | 簇6 | 簇7 | 簇8 | 簇9 | |
|---|---|---|---|---|---|---|---|---|---|
| 数量 | 391 | 365 | 274 | 253 | 241 | 263 | 175 | 132 | 102 |
新窗口打开|下载CSV
为了验证选取的邻居个数对基于用户属性聚类的推荐算法的影响,我们可以根据表1设置邻居个数从5增长到50的对比实验。实验的结果如图3所示,可以看出,在一定范围内推荐的效果会随着邻居用户数的增加而越来越好,但达到临界值后算法的精确率会下降,这是因为邻居用户集合是按照相似度的大小由高到低进行排序的,当超过临界值后,算法会把相似度并不高的邻居用户也加入进行计算而使推荐的精确率降低。从图中可以看出邻居用户个数取35时推荐效果最佳。
图3
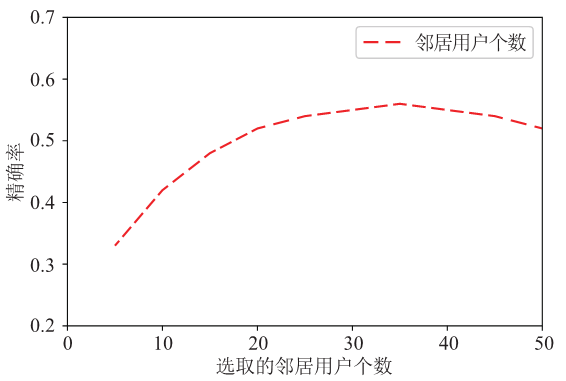 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3选取邻居用户个数对用户属性聚类算法的影响
Fig.3The influence of selecting the number of neighbor users on the user attribute clustering algorithm
然后是关于混合推荐算法的实验。为了对比不同权重λ下混合算法的推荐性能,同时找到最优的λ取值,本文进行了步长为0.1,λ从0开始增长到1的参数评估实验。图4展示了实验的最终结果,可以看出,在λ取0的时候,代表最终的预测评分仅依赖于用户的行为记录,此时算法的精确率在63%左右,由于只利用了部分数据,算法并没有达到最佳效果。在λ取1的时候,代表最终的预测评分仅依赖于用户属性,算法将相似群体偏好的资源推荐给用户,虽然此时算法的精度最低,但可以解决新用户冷启动问题。在λ取0.5时,推荐算法效果较好,达到了73%的准确率,此时的算法同时将群体的一般评价和用户的个人偏好结合,推荐的角度更加多元,较高的准确率说明混合推荐算法的结果符合预期。
图4
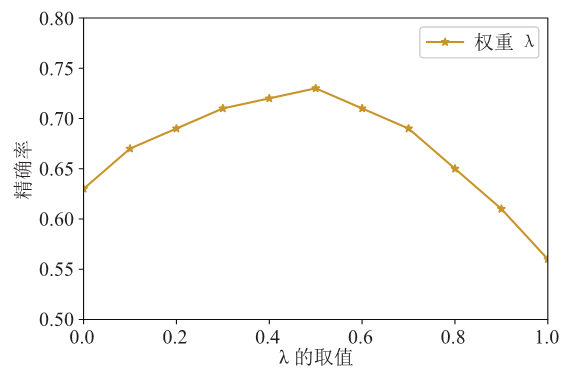 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4混合推荐的权重λ对算法的影响
Fig.4The influence of the weight λ of mixed recommendation on the algorithm
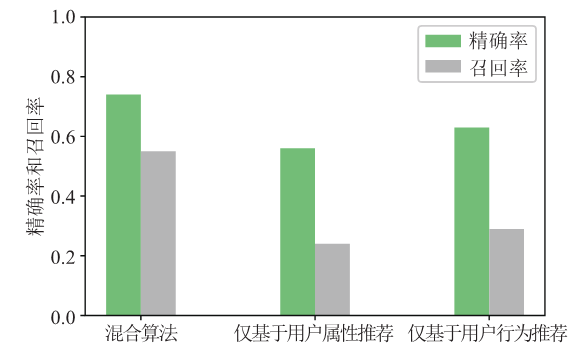
图5为邻居用户的个数取35,λ取0.5时三种算法的对比实验,从对比结果可知,经过混合后的推荐算法在精确率和召回率上明显优于两种单一评价模型的算法,证明了混合推荐策略的可行性。
图5
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5混合算法与单一推荐算法的对比实验
Fig.5Comparison experiment of hybrid algorithm and single recommendation algorithm
5 结束语
本文主要解决了两个问题:(1)利用用户属性解决了新用户冷启动问题。(2)通过计算用户与资源相似度的方式解决了隐式反馈模型不适用于传统的基于显式评分的ALS算法的问题。在计算最终的预测评分时,将两种推荐技术进行混合,相互弥补缺点,获得了更好的推荐效果。改进后的科研门户系统既可以帮助新用户快速适应系统,也可以帮助老用户获得更好的用户体验。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[J].
DOI:10.1109/TKDE.2005.99URL [本文引用: 1]
[D].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1145/3130332.3130334URL [本文引用: 1]
[C]//
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1145/959258.959260URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1016/j.knosys.2018.05.040URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}