 ,1,3, 周园春,1, 宋秋成,1, 王建伟,2, 孟珍,1,*, 张艳玲,2,*
,1,3, 周园春,1, 宋秋成,1, 王建伟,2, 孟珍,1,*, 张艳玲,2,*Application of Data Dimension Reduction and Clustering Algorithm in Tobacco Leaf Similarity Analysis
ZHAI Qingchen,1,3, ZHOU Yuanchun,1, SONG Qiucheng,1, WANG Jianwei,2, MENG Zhen,1,*, ZHANG Yanling,2,*通讯作者: 孟珍(E-mail:zhenm99@cnic.cn);张艳玲(E-mail:zhangyanling@ztri.com.cn)
收稿日期:2020-11-24网络出版日期:2021-02-20
| 基金资助: |
Received:2020-11-24Online:2021-02-20
作者简介 About authors

翟擎辰,中国科学院计算机网络信息中心,中国科学院大学,硕士研究生,研究方向为机器学习、无监督学习、表征学习等。本文中负责数据处理、模型构建、实验、论文撰写。
ZHAI Qingchen is a graduate student of Computer Network Information Center of Chinese Academy of Sciences. His research directions are machine learning, unsupervised learning, representation learning, etc.In this paper, he is responsible for data processing, model construction, experiments, and paper writing.E-mail:

周园春,中国科学院计算机网络信息中心,副主任,博士,研究员,博士生导师,中国科学院特聘研究员,中心学位评定委员会主席,大数据应用与技术发展部主任,大数据分析与计算技术国家地方联合工程实验室秘书长,中科院信息化专项科学大数据工程负责人。发表SCI/EI收录论文90多篇。主要研究方向为大数据分析与处理。本文主要承担工作为数据挖掘算法研究框架设计。
ZHOU Yuanchun is the research fellow, Ph.D. supervisor and the assistant director in Computer Network Information Center, Chinese Academy of Sciences and the director of the Department of Big Data Technology and Application Development. He is also the chairman of the Degree Evaluation Committee in Computer Network Information Center, Chinese Academy of Sciences. His research interests include big data analysis and processing. He has published more than 90 SCI/EI papers.In this paper, he is responsible for the design of data mining algorithm research framework.E-mail:

宋秋成,中科创嘉公司,具有丰富的从事前端开发、数据可视化等工作的经验。本文中负责数据可视化。
SONG qiucheng, employee of Zhongke Chuangjia Company, has rich experience in front-end development, data visualization, etc.In this paper, he is responsible for data visualization.E-mail:

王建伟,中国烟草总公司郑州烟草研究院,硕士,高级农艺师,硕士研究生导师,主要研究方向为烟叶生产技术与烟叶质量大数据应用。本文中负责对烟叶相似性结果以烟草行业角度进行评估。
WANG Jianwei, master, is a senior agronomist and master tutor of Zhengzhou Tobacco Research Institute of China National Tobacco Corporation. His main research directions are the tobacco leaf production technology and big data applications of tobacco leaf quality.In this paper, he is responsible for evaluating the similarity results of tobacco leaves from the perspective of the tobacco industry.E-mail:

孟珍,中国科学院计算机网络信息中心,高级工程师,硕士研究生导师,大数据技术与应用发展部数据资源与应用实验室副主任,主要研究方向为多源异构数据的融合管理与关联技术、面向领域大数据分析模型与云服务技术。发表SCI/EI收录论文20多篇。本文中负责数据挖掘算法研究框架设计与指导。
MENG Zhen is a senior engineer and the master supervisor at the Department of Big Data Technology and Application Development at Computer Network Information Center, Chinese Academy of Sciences. She is the deputy director of the Resource and Application Lab at the Department of Big Data Technology and Application Development. Her research interests include big data management, processing, mining, analysis and other related technologies. And she has published over 20 papers included in SCI/EI.In this paper, she is mainly responsible for the overall design and guidance of data mining algorithm research frameworks.E-mail:

张艳玲,烟草行业生态环境与烟叶质量重点实验室,副主任,博士,硕士生导师,主要研究方向为烟叶质量评价、大数据技术在烟叶质量评价中的应用。本文中负责创新平台在烟叶质量评价中的典型应用。
ZHANG Yanling, Ph.D., is a researcher and deputy director of the key laboratory of environmental and tobacco leaf, CNTC. Her recent research interest areas are tobacco leaf quality assessment and implication of big data on tobacco leaf quality assessment.In this paper, she is responsible for the application of innovation platform on tobacco leaf quality assessment.E-mail:

摘要
[目的]为了对烟叶产地进行相似性度量和分类,并克服高维空间下距离度量失效的问题。[方法]文章通过方差权重法、主成分分析法及局部线性嵌入法三种方法对烟叶属性指标进行降维和筛选,使用经过特征降维后的数据相似性进行计算及K-means聚类分析。[结果]通过分析不同方法所得输入指标的聚类的轮廓系数发现,方差权重法所筛选出的总植物碱、还原糖、钾、含梗率四个指标的聚类效果较两种降维算法所得的指标的聚类效果更好,对烟叶质量评估有较强的参考价值。K-means聚类算法将烟叶产区分为四类并且得到各类中属性特点,通过相似性算法所得到的结果在以麒麟区、宣威县、罗平县为代表的县区的相似性产地上与业内现有研究相互验证。[结论]文章基于机器学习算法,通过数据挖掘得到烟叶感官数据中的特征性指标与产地之间的相似性特点,为烟叶工业生产提供了具有一定参考价值的指标与结论,也为机器学习在烟草工业中的应用提供了算法基础。
关键词:
Abstract
[Objective] In order to measure and classify the similarity of tobacco leaves and to overcome the problem of invalid distance measurement in high-dimensional space, [Methods] the article uses three methods: variance weighted method, principal component analysis method, and local linear embedding method to reduce the dimension and filter the attributes of tobacco leaves. The similarity is calculated using the selected indicators and K-means algorithm is carried out to cluster tobacco leaves. [Results] By analyzing the cluster silhouette coefficient of the input indicators obtained by different methods, it is found that the clustering effects of the four indicators of total alkaloids, reducing sugars, potassium, and stalk rate selected by the variance weighted method are better than those of other two dimension reduction algorithms. The clustering algorithm divides tobacco leaves into four categories and analyzes the characteristics of various input indicators. And the results obtained through the similarity algorithm are mutually verified with the existing research in the industry at three similar counties: Qilin district, Xuanwei county, and Luoping county. [Conclusions] Based on the machine learning algorithm, this article digs out the similarities between the characteristic indicators in the sensory data of tobacco leaf and the place of origin, providing indicators and conclusions with a certain reference value for the tobacco industry production. It also provides an algorithmic basis for the application of machine learning in the tobacco industry.
Keywords:
PDF (6372KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
翟擎辰, 周园春, 宋秋成, 王建伟, 孟珍, 张艳玲. 数据降维及聚类算法在烟叶相似性分析中的应用. 数据与计算发展前沿[J], 2021, 3(1): 112-121 doi:10.11871/jfdc.issn.2096-742X.2021.01.009
ZHAI Qingchen, ZHOU Yuanchun, SONG Qiucheng, WANG Jianwei, MENG Zhen, ZHANG Yanling.
引言
数据与计算技术飞速发展,不仅在科学研究中起到辅助与支撑的作用,而且可以依靠其自身的逻辑方法,驱动甚至引领科学研究活动[1]。烟草行业内的工业需求的快速扩张,对传统的烟叶质量的认知模式也带来了很大的挑战。仅依靠经验主观判断的方法如人工抽吸法与化学分析法,来完成对烟叶质量的判别与评价已经无法满足产品质量稳定性的需求。机器学习时代的来临实现了很多技术上的应用[2]。通过对以往历史数据的挖掘模拟,建立智能替代模型和交互分析应用,采用客观数据作为辅助来配方评价和烟叶替代,对提高卷烟质量稳定性有重要意义。因此机器学习方法成为挖掘烟叶原料内在特征、发现烟叶产地外在关联、寻找烟叶分类特点的一种重要的科学手段。这也是目前辅助技术人员快速寻找缺失原料替代产地的一种重要方法[3]。标准化的数据集是人工智能算法开展大规模训练和提升准确率的重要要素[4]。烟叶质量数据中包括物理属性、化学属性、感官质量、叶身外观等多种指标[5],有的数据源可以到达几十维甚至上百维。这种情况下,属性指标的选择和降维以及距离度量的构建就成了影响相似性度量和烟叶分类结果的关键[6]。仅仅依靠人工经验筛选输入指标,结果会丧失客观性且不能体现数据之间的关联性;而在使用数据降维算法时,所降维的数据在高维空间中的分布状态将对降维算法的准确性产生影响。数据分布状态未知时,采用主成分分析法进行降维可能出现原始样本间距离结构、拓扑结构发生改变等诸多问题,导致相似性度量结果不准确[7]。
面对上述问题,文章在数据降维时采用方差权重法、主成分分析法及局部线性嵌入法三种方法进行特征筛选与降维。方差权重法可以对相似性度量及聚类指导性较高的属性进行筛选。主成分分析法与局部线性嵌入法进行降维针对数据在高维空间的分布结构,以线性与非线性两种方式进行降维。通过比较三种方法的筛选和降维后的数据的聚类效果,文章对特征筛选与降维方法进行分析,将优胜的筛选或降维后的数据通过加权欧氏距离进行相似性度量,以克服工业数据中不同属性的指导性不同的问题,并通过K-means算法对烟叶进行聚类及分析。
文章以数据挖掘技术为基础,为完善烟叶质量评价体系、提升烟叶感官品质提供理论基础,为研究烟叶质量智能评吸算法逐步替代人工抽吸评价提供算法基础,在烟草工业应用中有较高的参考价值。
1 烟叶感官质量数据
文章数据源采用中国烟草总公司郑州烟草研究院的2004年至2017年湖南、云南、湖北、安徽、福建等22个省208个县区5 314个烤烟烟叶样品数据,其品质属性指标包括:物理化学属性如总植物碱、还原糖、总糖、总氮、钾、挥发酸、淀粉等28项,感官指标包括香气质、香气量、杂气、刺激、劲头、浓度、余味等7项指标,以及叶身外观的长度、厚度、颜色、重量等7项指标。2 面向烟叶产地的数据挖掘算法
2.1 数据预处理
文章对源数据进行归一化预处理:$x^{*}=\frac{x-x_{\min }}{x_{\max }-x_{\min }}$
其中xmax为样本数据的最大值,xmin为样本数据的最小值,x*为原数据在[0,1]之间的线性映射。
2.2 特征筛选及降维
原始数据在高维空间中的结构特征尚未明确,采用单一的降维方法不利于特征的选择。文章采用方差权重法、主成分分析法、局部线性嵌入法三种核心思想不同的算法对烟叶原始数据进行降维。使线性与非线性结构分布的数据在实验中都尽可能保持在高维空间下的原有拓扑结构映射[8],并且方差权重法可以对烟叶质量具有指导性强的属性进行筛选。文章通过降维后数据的Kmeans聚类效果对三种特征选择与降维方法在烟叶数据集上的适用性进行比较。本文的方法有效避免了数据在高维空间中分布未知的情况下造成的“距离度量失效”的问题,并且保证了输入指标选择的客观性。
2.2.1方差权重法
方差权重法是通过特征本身的方差来筛选特征的算法。当一个特征本身的方差很小,表明样本在此特征上基本没有差异。这种情况下该特征对于样本区分作用较小。当一个特征分布发散,则代表特征的方差大,能够根据取值的差异化度量目标信息[9]。故文章通过对于每个特征进行方差计算,设定阈值或者待选择阈值的个数选择特征,优先选取与目标高度相关性的指标。
在烟叶的特征对其聚类与相似性度量未知的情况下,文章通过方差权重法对特征进行筛选会有更强的可解释性。
2.2.2 主成分分析法
主成分分析法(PCA)将输入数据构成协方差矩阵,并以特征分解的方式对数据进行优化,得到数据的特征向量与特征值。其中特征向量为数据的主成分,特征值为这些数据的权重值[10]。
2.2.3 局部线性嵌入法
局部线性嵌入算法(LLE)基于数据在高维空间满足流形分布为假设,将其映射至低维空间时也将保持其流形结构不变化[11]。其步骤主要分为三步:(1)得到样本的k邻近点;(2)通过样本点的邻近点计算出该样本点的局部重建权值矩阵;(3)由样本点的局部重建权值矩阵与其相应的邻近点可计算出输出值[12]。
上述三种方法得到的输入值分别是特征选择后的四种属性、PCA降维后的属性因子及LLE降维后的属性因子。将这三种方法得到的因子与属性分别作为输入对样本进行K-means聚类,通过比较聚类轮廓系数,对三种方法在文章数据集上的适用性进行判断,从而确定分类输入指标或属性。
2.3 产地相似性构建
文章烟叶产地以县区为基本单位对烟叶质量的相似性进行分析。基于加权的欧式距离公式对产地间的相似性进行度量。定义样本矩阵X:
$X=\begin{array}{cccc}x_{11} & x_{12} & \cdots & x_{1 k} \\x_{21} & x_{22} & \cdots & x_{2 k} \\\cdots & \cdots & \cdots & \cdots \\x_{i 1} & x_{i 2} & \cdots & x_{i k}\end{array}$
其中xik表示第i个样本的第k个指标数据,原料样本质量数据可包括理化属性、感官质量及外观指标等。
定义Dij为两个样本间的相似度:
$D_{i j}=\sqrt{\sum_{k=1}^{n} w\left(x_{i k}-x_{j k}\right)^{2}}$
其中n为所输入特征的维度,w为权重。
定义距离矩阵M,其中m为县区总数量,该矩阵中每一个D值由上文中距离公式所求得:
$M=\left(\begin{array}{ccc}D_{11} & \cdots & D_{1 m} \\\vdots & \ddots & \vdots \\D_{m 1} & \cdots & D_{m m}\end{array}\right)$
该矩阵即含括了所有县区之间的距离,且该矩阵每一行最小的距离即为该行所对应的县区与其最相近的产地。当样本集中某个样本xi需要用另一个样本作为替代时,可以从距离矩阵M中寻找与样本xi最短距离的点即最邻近样本点集合B。
2.4 烟叶产地聚类及指标
文章采用K-Means聚类对烟叶质量进行聚类并对聚类结果进行分析。对于聚类簇数即k值的选取,将通过轮廓系数作为评价指标。轮廓系数表达式如下:
$S(i)=\frac{b(i)-a(i)}{\max \{a(i), b(i)\}}$
其中b(i)与a(i)分别是簇间与簇内样本点间距离。当轮廓系数S越接近1时,则聚类轮廓的表达越优异。
3 面向应用的烟叶数据挖掘
3.1 烟叶特征筛选及降维
3.1.1方差权重特征选择烟叶作为一种农产品,其质量特征可以看作内在理化属性的外在表现。故本文采用理化属性作为衡量烟叶分类与相似性的输入指标。输入指标通过方差权重法进行筛选得到本次实验中相近烟叶查找的关键指标为:总植物碱、还原糖、含梗率、钾。其归一化后权重系数取值分别近似取值 1.0、0.5、1.0、0.8。
3.1.2 PCA及LLE降维
使用主成分分析法将总植物碱、还原糖、总糖、总氮、钾、淀粉、含梗率、单叶重、叶面密度多个属性降至四维。其降维筛选过程如下表。
Table 1
表1
表1PCA筛选过程
Table 1
| 成份 | 初始特征值 | ||
|---|---|---|---|
| 合计 | 方差的 % | 累积 % | |
| 1 | 4.368 | 33.598 | 33.598 |
| 2 | 2.518 | 19.368 | 52.967 |
| 3 | 1.071 | 8.235 | 61.201 |
| 4 | 0.969 | 7.454 | 68.655 |
| 5 | 0.794 | 6.104 | 74.759 |
| 6 | 0.680 | 5.230 | 79.989 |
| 7 | 0.577 | 4.439 | 84.428 |
| 8 | 0.568 | 4.371 | 88.799 |
| 9 | 0.484 | 3.724 | 92.523 |
| 10 | 0.382 | 2.940 | 95.463 |
| 11 | 0.250 | 1.926 | 97.389 |
| 12 | 0.226 | 1.739 | 99.128 |
| 13 | 0.113 | 0.872 | 100.000 |
新窗口打开|下载CSV
由上表可以发现,主成分分析法分解所得到的前6个特征根所代表的主成分累计方差贡献率达到79.989 %,可以涵盖数据源中大部分的信息。若要保留更多信息,则会保留9维以上的维度,丧失了降维的初衷,故文章采用PCA将数据降至6维。
由于LLE降维的维数选取基于高维空间的本征维数,维数过高会导致数据中含有过多噪声,维数过低会导致数据集在低维空间映射会彼此交叠。文章基于已有的特征筛选结果对维度数做出判断,通过LLE算法将原数据集降至与特征筛选相同的维度数目(4维)。
3.1.3 特征筛选及降维方法比较
为对比降维的效果,文章对未降维的数据进行K-means聚类的轮廓系数如图1所示。
图1
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1轮廓系数(未降维)
Fig.1Silhouette coefficient(unreduced)
图1表明数据未降维时聚类在簇数为2时轮廓系数最佳,但数值仍未超过0.5,故文章存在对数据进行特征选择和降维的必要。
文章将方差权重数据集(4维)、PCA变换数据集(6维)及LLE变换数据集(4维)在K-means聚类后计算其轮廓系数。结果如图2所示。
图2
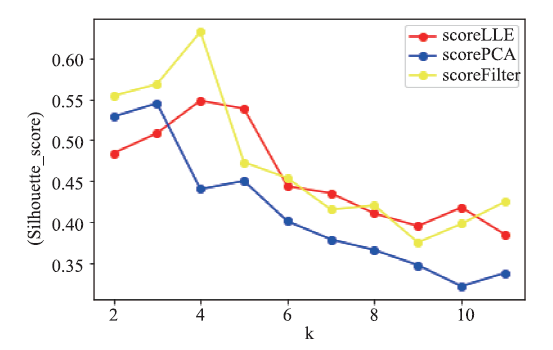 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2轮廓系数(降维后)
Fig.2Silhouette coefficient (reduced)
由图2可知,PCA及LLE两种方法所得到的数据在簇数目分别为3和4时有最高的轮廓系数值0.544和0.548。方差权重法筛选所得的数据在簇数目为4时有最高的轮廓系数值0.632。
虽然方差权重计算性上相对简单,但PCA与LLE也存在一定的不足,可能是导致降维效果较差的原因之一。PCA可能会将特征向量集合作为整体进行处理,以寻找均方误差最小意义下的最优线性映射投影,但这种情况下忽视所投影方向可能刚好包含重要可分性信息。而LLE降维对数据分布要求较高,对非流行分布的数据可能效果相对较差,可能对文章所用数据集也不够契合,并且文章所使用的数据集维度及样本量相对较小。这种情况下,采用特征的方差对重要特征进行筛选,反而存在所得到的特征更有代表性且特征间的分离度会更好的可能性。
综上多种原因,方差权重法在此烟叶数据集上降维的效果更为优异,且筛选所得的总植物碱、还原糖、含梗率、钾四个指标对于烟叶聚类有一定的指导作用。
而对比PCA及LLE两种降维方法所得到的结果可以发现,LLE降维所得到的结果相较于PCA降维所得到的结果随着簇数目增加,普遍有更好的表现。一定程度上可以反应,对于烟叶数据集,非线性降维相较于线性降维可能更能保持烟叶数据在高维空间的原始拓扑结构。局部线性嵌入法对烟叶领域数据适应性更强。
3.2 烟叶产地聚类分析
图2表明,以特征选择所筛选的四个属性作为输入的情况下,簇数目为4聚类效果最好。在簇数目为4时K-means聚类结果如表2所示。类别1含123个县区,烟叶质量主要特征是还原糖、含梗率、钾均相对较高,代表性产区有安龙县、宾川县等;类别3含51个县区,烟叶质量主要特征是含梗率、总植物碱和钾含量均明显较高,代表性产区有保康县、昌宁县、楚雄市等;类别4烟叶质量主要特征为含梗率和钾含量相对较低,代表性产区有宝丰、郏县等;类别2烟叶总植物碱、钾含量和含梗率均明显较低,还原糖含量明显较高,代表性产区有宾县、大安市、富锦等。
Table 2
表2
表2四类烟叶的代表指标的平均值
Table 2
| 属性 | 类1 | 类2 | 类3 | 类4 |
|---|---|---|---|---|
| 产地数 | 123 | 10 | 51 | 24 |
| 还原糖 % | 27.92 | 29.87 | 23.63 | 24.83 |
| 含梗率 % | 30.84 | 23.63 | 32.37 | 27.45 |
| 钾 % | 2.02 | 1.48 | 2.04 | 1.66 |
| 总植物碱 % | 2.22 | 1.60 | 2.53 | 2.33 |
新窗口打开|下载CSV
3.3 烟叶相似产地可视化
选取总植物碱、还原糖、含梗率、钾作为加权欧氏距离的输入指标,得到最邻近距离矩阵并将其以网络图的形式进行可视化结果如图3。图3
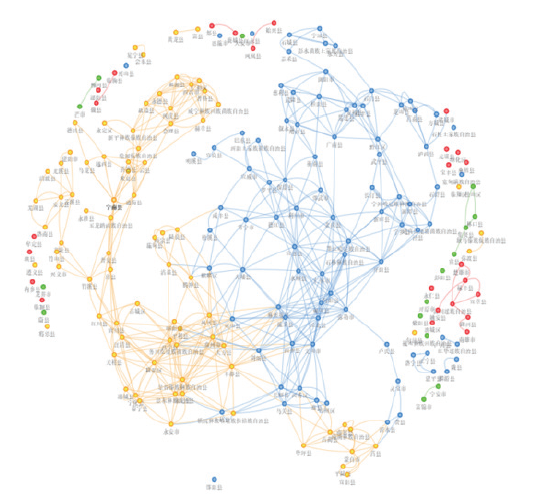 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3县区相似性关联图
Fig.3County similarity association graph
文章以浓香型典型产区襄城县为例对相似性度量结果的准确性进行验证。文章将与襄城县最相似的五个烟叶产地(谯城区、郏县、徽县、临朐县、泌阳县)分别从香气质、香气量、浓度、总植物碱、还原糖、钾六个维度进行比较。各产地属性的雷达图见图4所示。通过比较六个产地的雷达图发现,文章所得结果的产地间属性轮廓较为相似。
图4
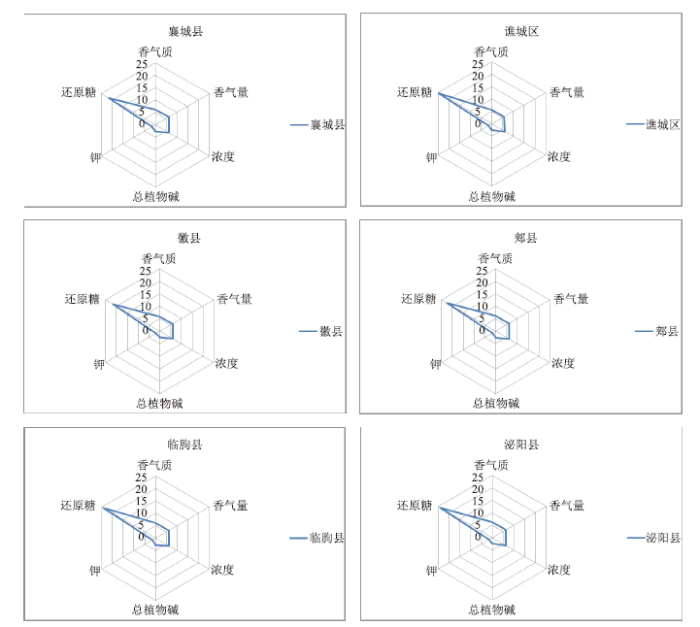 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4襄城县与最相近的五个县区雷达图
Fig.4Radar map of Xiangcheng County and the five closest counties
为从烟草业内角度对结果进行验证,文章采用指纹图谱技术取得的研究成果与本文进行比对(唐徐红等应用烟叶指纹图谱聚类对云南省的十五个不同的烟叶产区进行的研究[13])。
文章与唐徐红等研究结果中所共同涉及的产地为麒麟区、宣威县、罗平县。唐徐红等的研究结果表明,基于烟叶指纹图谱聚类时,宣威市与罗平县处于同一簇;基于产区特点分类时,罗平县与麒麟区处在同一产区类别;结合上述两点,宣威市、罗平县、麒麟区在指纹图谱技术下表现为质量相近的烟叶产地。与本文表3中的结果趋于一致。
Table 3
表3
表3最邻近产地
Table 3
| 产地 | 相近产地 |
|---|---|
| 麒麟区 | 宜良县、宣威县、江华瑶族自治县、宁远县、罗平县 |
| 宣威县 | 保康县、罗平县、陆良县、麒麟区、腾冲县 |
| 罗平县 | 宣威市、利川市、永兴县、保康县、腾冲县 |
新窗口打开|下载CSV
故实验结果表明,文章的相似性度量结果与行业内专家对特定产区相似性分析的判定相互验证。文章相似性度量的结论及算法对烟草企业进行产地替代、配方维护、烟叶种植区规划有一定的指导作用。
4 结论与展望
针对实验结果及分析,文章从三个方面进行总结。对降维算法研究而言。在烟叶数据集上,局部线性嵌入法降维后的结果相较于主成分分析法更能体现烟叶数据集在高维空间中的非线性特征,使其在低维空间映射后能更大程度地保持其分布的拓扑结构,故局部线性嵌入法更为适合于应用在烟叶数据集上。而文章采用方差权重法所筛选出的四个特征相较于两种降维算法也更为优异。基于实验分析可以发现总植物碱、还原糖、钾、含梗率四个指标对于烟叶聚类与相似度分析有一定指导作用。
对烟叶聚类而言。文章基于K-means聚类算法,使用总植物碱、还原糖、钾、含梗率作为输入特征进行聚类。通过聚类结果分析发现,烟叶产地分为四类时是最理想的结果并得到四类烟叶产地所产烟叶的理化指标特点及代表性县区。
对样本集相似性度量而言。本文以总植物碱、还原糖、钾、含梗率作为输入指标,通过加权欧氏距离进行相似性度量,所得结果与业内专家通过指纹图谱技术所得结果间相互验证。表明文章所构建的烟叶相似度计算算法对卷烟配方替代工作有重要意义。
总体而言,本文构建针对烟叶分类与相似度计算的组合算法库能够通过对以往历史数据的挖掘模拟,建立智能替代模型来作为辅助烟叶配方评价和烟叶替代的方法,对提高卷烟质量稳定性有重要意义。
当然,数据挖掘技术在烟叶聚类与相似性度量领域的应用尚处于起步阶段,对烟叶质量的评价指标还缺乏统一和规范的计算方法,这对于数据挖掘技术在烟草业内的实际应用构成了一定的障碍。保留原始特征信息、过滤无用信息、构建距离度量都是数据挖掘在烟叶应用领域的难点。目前在未对烟叶按风格及年份进行标签的情况下所得到的结果精确度依然有待提高,通过基于区分典型区域或典型风格的条件下,将样本数据集带上年份标签进行研究可能使精确度有一定程度上的提高,这也为后续卷烟配方替代的研究工作提供了一个新的研究方向及目标。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[R/OL]. [
[本文引用: 1]
[J].
[本文引用: 1]
[D].
[本文引用: 1]
[J].
[本文引用: 1]
[M].
[本文引用: 1]
[J].
URLPMID:32406416 [本文引用: 1]
[D].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}