 ,1, 张辉,1, 宋文燕,2,*, 王轩,1
,1, 张辉,1, 宋文燕,2,*, 王轩,1Scientific and Technology Resource Clustering Based on Domain Ontology
Ge Yinchi,1, Zhang Hui,1, Song Wenyan,2,*, Wang Xuan,1通讯作者: * 宋文燕 (songwenyan@buaa.edu.cn)
收稿日期:2020-07-17网络出版日期:2020-10-20
| 基金资助: |
Received:2020-07-17Online:2020-10-20
作者简介 About authors

葛胤池,北京航空航天大学计算机学院,博士研究生,主要研究方向为数据挖掘、知识图谱、自然语言处理。
本文中负责方法设计、实验和主要论文撰写。
Ge Yinchi is a PhD student in School of computer Science and Engineering, Beihang University. His research areas are data mining, knowledge graph and NLP.
In this paper, he is responsible for the method design, experiment conduction and main paper writing.
E-mail:

张辉,北京航空航天大学计算机学院,博士,教授,博士生导师,国家科技资源共享服务工程技术研究中心副主任,负责科技资源的整合、管理与共享服务的技术研发工作,发表相关学术论文70余篇,获得专利6项。目前主要研究领域为互联网信息检索、大数据管理与挖掘、知识发现与管理。
本文中对文章总体框架进行指导。
Zhang Hui is a professor and the doctoral tutor at the School of Computer Science and Engineering of Beihang University. He also serves as the deputy director of the National Science and Technology Resource Sharing Service Engineering Research Center. His main research areas are Internet information retrieval, big data management and mining, knowledge discovery and management.
In this paper, he is responsible for the overall framework guidance of the article.
E-mail:

宋文燕,北航长聘副教授、博士生导师,上海交通大学工学博士,德国慕尼黑工业大学(Technische Universit?t München)博士后。长期从事复杂产品/服务系统、大规模个性化定制、模块化协同开发、可持续运营等理论及应用研究。已发表学术论文近60篇,其中50多篇发表在IEEE T. Reliab., Int. J. Prod. Res., CIRP Ann.- Manuf. Techn.等国际SCI/SSCI期刊上,在国际知名出版社Springer独立出版英文学术专著1部,在机械工业出版社等出版著作、教材2部,授权/公开国家发明专利多项,入选“北航青年拔尖人才支持计划”。
本文中对文章整体框架进行指导。
Song Wenyan, Ph.D., is an associate professor and doctoral tutor of Beihang University. His research areas are engaged in theoretical and applied research on complex products/service systems, large-scale personalized customization, modular collaborative development, sustainable operation, and etc.
In this paper, he is responsible for the overall framework guidance of the article.
E-mail:

王轩,北京航空航天大学计算机学院,硕士研究生,主要研究方向为知识图谱,自然语言处理,大数据分析。
本文中完成研究背景部分论文撰写。
Wang Xuan is a graduate student in School of computer Science and Engineering, Beihang University. His research areas are knowledge graph, natural language processing, and big data analysis.
In this paper, he is responsible for the background research of the paper.
E-mail:

摘要
【目的】 针对科技资源分散、异构的特点,采用聚类的方法将分散、相关、相似的科技资源集成为多类型组合的资源池,以提高发现资源和利用资源的效率。本文提出一种基于领域本体的高维科技资源聚类方法。 【方法】 本方法构建了科技资源领域本体树和概念语义关系矩阵,并对其使用主成分分析(PCA)方法进行降维处理以构建科技资源向量空间,最终对科技资源向量空间应用K均值聚类算法得到聚类结果。与传统方法相比,本方法更适合于处理多源异构的科技资源数据。 【结果】 选取某国家生物种质资源库的资源数据作为科技资源集合,利用本方法得到了合理的聚类结果。 【结论】 本文提出的科技资源聚类方法具有三个特点:一是利用本体概念语义关系降维处理,有效降低了计算复杂度;二是较好地保留了重要的科技资源特征信息;三是生成的科技资源向量空间与聚类簇比较准确。本方法在一定程度上解决了多源异构科技资源数据的特征表示难、聚类效果差等问题。
关键词:
Abstract
[Objective] Clustering can gather scattered, heterogeneous but related, similar scientific and technology resources into a multi-type resource pool, which makes resource discovery and utilization more efficient. This paper proposes a clustering method for massive high-dimensional scientific and technology resources based on domain ontology. [Methods] This method constructs the ontology tree and concept semantic relationship matrix in the field of science and technology resources, and uses the Principal Component Analysis (PCA) method to reduce the dimensions to construct the vector space, to which the K-means clustering method is applied eventually to obtain the clustering result. Compared with the traditional methods, this method has a stronger processing capacity for multi-source heterogeneous scientific and technology resource data. [Results] In this paper, the rational clustering results can be obtained by the proposed method on a certain biological germplasm resource library test. [Conclusions] In general, the clustering method of scientific and technology resources proposed in this paper has three characteristics: first, the use of ontology concept semantic relations to reduce the dimensionality, which effectively reduces the computational complexity; second, better maintenance of important scientific and technology resource feature information; and third, more accurate resource vector space and clustering results. The proposed clustering method solves the difficult problems in feature representation and poor clustering effect of multi-source heterogeneous scientific and technology resource data to a certain extent.
Keywords:
PDF (7019KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
葛胤池, 张辉, 宋文燕, 王轩. 基于领域本体的科技资源聚类方法研究. 数据与计算发展前沿[J], 2020, 2(5): 13-22 doi:10.11871/jfdc.issn.2096-742X.2020.05.002
Ge Yinchi, Zhang Hui, Song Wenyan, Wang Xuan.
开放科学标识码(OSID)

引言
科学技术是第一生产力,而科技资源是推动科学研究和技术创新的重要组成部分。随着科技服务等新型服务业的兴起,对科技资源进行科学有效的管理提出了更高的要求[1]。科技资源有多种分类方法,从资源形态上包含人力资源、生物种质资源、科研仪器设备、科学数据等几大类,而按教育部学科门类划分,可分为13个学科门类110个一级学科。科技资源具有地理分布、结构复杂、特征众多、数量巨大且变化频繁的特点,并根据科技资源全生命周期管理的需要随时会有新增、变化、消耗及销除等情况。科技资源集成是将分散的、相关的、相似的科技资源整合为有信息组织形态的一体,提高科技资源共享效率,促进协同创新和提高企业竞争力的方法。[2]科技资源集成围绕完成某一项目或任务集成所需要的科技资源成套组合,形成科技资源池,提供整体解决方案。科技资源的分散性、异构性会阻碍其有效的集成与共享,因此我们需要对科技资源进行聚类以提高集成效率。物以类聚,聚类就是指将数据划分成有意义或有用的组(簇)的方法,组内元素尽量相似,不同组的元素尽量不相似。在科技资源集成中,对科技资源进行聚类形成资源包后,后续可以通过一定的规则进行集成组合,为不同用户提供个性化的科技服务。在聚类时,需要对科技资源集合进行数据预处理,选取数据的属性和维度。由于科技资源的分散性和异构性,其维度即属性数目将会非常高,容易陷入维度灾难。传统的聚类算法应对高维数据时往往表现较差。为此先对高维数据进行降维处理再进行聚类[3]。目前常见的降维方法有:主成分分析(PCA)[4,5]、Kohonen自组织特征映射(SOFM)[6]以及多维缩放(MDS)等算法。此类算法一般需要预先确定数据的维数以及属性信息,无法适用于科技资源多源异构、变化频繁的情况。同时对于高维度、海量的数据使用此类算法时需要大量的计算资源。
为此本文设计了一种基于领域本体的科技资源信息降维和聚类方法。该算法相比传统聚类分析的方法有以下优点:(1)利用领域本体语义关系以适应多源异构的科技资源数据;(2)适用于海量高维科技资源数据。
1 背景
1.1 科技资源整合与共享的意义
在信息时代,科技资源作为一种重要的信息资源和战略资源,对一个国家的科技发展和进步具有非常重要的意义。我国经过长时间的科技创新发展,已经产生了大量的科技资源,而这些科技资源既是我国科技创新的重要成果也是支撑我国新一轮科技创新活动的重要保证。能否充分有效地利用这些科技资源,对于我国的科技创新与发展而言至关重要[7]。世界各国特别是欧美等发达国家都在积极推动科技资源整合与共享工作,来促进科技创新与经济发展。如美国通过立法与专项资金支持的方式来积极推动科技资源共享,建设数据共享平台;欧盟也通过建设覆盖整个欧洲地区的科技资源共享平台的方式推动科技资源共享[8]。
近年来,随着国家对科技资源的重视以及投入的增加,我国已经在科技资源整合与共享方面取得了明显的成效。但从总体上看,我国科技资源的整合及共享服务体系依然处于初级阶段,与发达国家相比仍然存在较大差距。为此,我们必须不断加大科技资源共享力度,解决当前科技资源遇到的问题,从而推动创新型国家建设[9]。
1.2 科技资源的特征
科技资源作为国家战略资源,具有稀缺性和增值性资源普遍共有的特性,同时科技资源还具有地域分布、差异性、异构型等特点。科技资源的特征主要包括:(1)稀缺性
科技资源作为国家科技创新发展与进步的重要资源,相对于科技资源日益增长的需求而言总是稀缺的。科技资源的稀缺性主要体现在两方面:科技资源总产出相对不足;科技资源利用率较低。
(2)分布的差异性
科技资源的分布受到区域的经济与科技发展状况的影响,不同地区的性质各异、层次不同、各具特色的经济发展模式与科技发展政策会导致区域科技资源分布的差异性[10]。另外,各种差异性受到地域差别的影响,不同的地域具有不同的特色资源。
(3)增值性
科技资源能为科技活动提供支持,同时科技活动对科技资源进行深层次的挖掘与使用,可以实现价值的转换与增加。通过科技资源开发,既可以转化为新的科技价值,还可以转化为社会价值、经济价值等。
(4)异构性
科技资源包含范围比较广,包括了人力资源、生物种质资源、科研仪器设备、科学数据等。其中人才、仪器、信息等资源结构性质各异,使用方式和评价指标等也有极大的区别。如何将这些分散的、多样的、异构的科技资源与海量个性化的需求相匹配,是提高科技资源服务质量的关键问题。
1.3 科技资源共享面临的挑战
在不断推动科技创新发展过程中,通过政府财政专项资助和科研计划等方式的支持,我国的科技资源越来越丰富,科技资源建设取得了较大的发展。但是我国的科技服务与共享体系依然不够完善,导致科技资源并没有得到充分的利用[11,12]。我国在科技资源共享过程中存在科技资源建设重复多但同时利用率低,科技文献资源质量不高,科技资源管理人才队伍建设不足等问题[13]。同时在科技资源服务建设过程中,因为科技资源的异构型和分布上的差异性等,科技资源及其信息往往具有分散、封闭、异构和孤立等特点。如何将分散在不同地理位置、不同部门的,具有不同属性的异构异质异种科技资源匹配多用户的个性化需求,成为推动科技资源共享与服务的一个关键问题。例如,科研工作者想要完成某项科研课题,为此需要获取特定种类的资源,则可以通过检索科技资源集成产生的多源资源服务包来确定可用的资源范围,并结合具体业务需求、预算、地理位置等进行组合和筛选实现效益最优的个性化科技服务。
许多****对多源异构资源的集成进行了研究。在科技资源领域中,于阳对江苏省科技资源信息使用Hadoop大数据平台实现了不同来源的科技数据合并与存储[14];李宗俊等提出了利用科技资源池作为虚拟化容器进行资源集成的方法[15];宫萍等提出通过建立统一的适用于多源异构科技资源的元数据格式规范来构建基于语义本体的科技资源集成建模框架[2]。此外,针对类似应用情景的其他领域资源集成的研究中,汤华茂通过构建制造资源的分布式语义描述模型实现了异构制造资源的虚拟化描述[16];程臻利用本体建模的方式用统一描述框架描述了异构云制造资源并建立起虚拟资源本体层次模型[17]。
以上研究虽然大都能够实现异构资源的整合,但并未提出实现个性化资源服务的完整方法。为此本文提出了一个适用于多源异构科技资源聚类的方法,通过聚类的方式将海量的、异构异质的科技资源有效地集成起来,以形成科技资源(服务池)供后续的检索和优化配置。
2 基于领域本体的科技资源聚类方法
来自不同领域的科技资源往往具有不同的描述方法及元数据标准,这便是其异构性所在。为了尽可能多和完整地保留各个领域科技资源信息的完整性,本方法对相关科技资源领域构建概念领域本体树,并将每一个科技资源的元数据信息根据概念集合进行向量化表示。据此得到的科技资源向量虽保有足够的信息,但向量的维数随着领域范围的扩大、异构性的增强而逐渐增多,容易陷入维度灾难。因此本文在进行聚类前,使用PCA方法对稀疏语义关系矩阵进行降维处理以得到属性较少的科技资源向量,以避免聚类出现效率低、效果差的问题。本方法主要分为三部分,如图1所示:构建领域本体树及语义关系,以计算不同概念之间语义距离;根据语义距离构建科技资源向量空间;对科技资源向量进行聚类。
图1
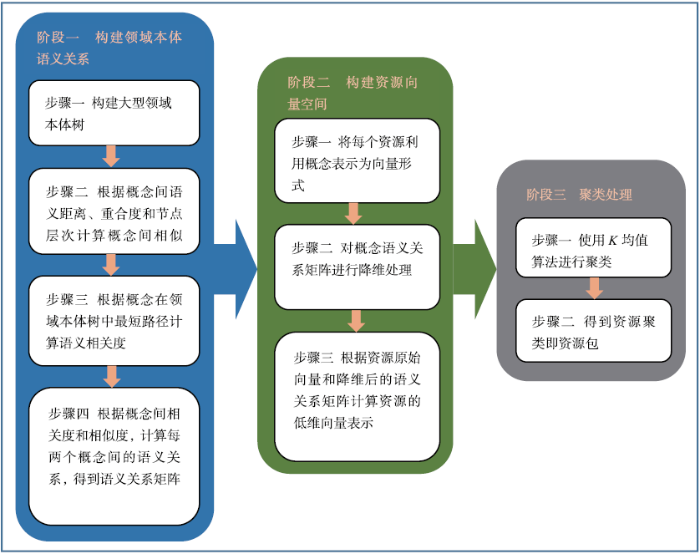 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1方法流程
Fig.1Method flow
2.1 领域本体语义关系定义与构建
领域本体是对特定领域之中概念及其相互之间关系进行形式化表达的领域知识库,可以在宏观上反映出领域知识的梗概全貌,并可以为特定领域信息的检索、分类提供有力的支持[18]。在本文中,定义本体结构G = (V,E),其中为概念集合,每个概念作为树中的一个节点;为概念间的语义关系,作为边集。本体中的概念间关系可分为上下位关系和相关概念的其他关系,其中上下位关系构成了本体的树形结构,称为本体的层次树,相关概念的其他关系构成本体结构中的非上下位关系[19]。如图2。
本体结构中,概念间的语义关系包含概念间语义相似度和概念间语义相关度。概念间语义相似度主要度量了本体中的上下位关系,概念间的相关度主要度量本体中概念间特有的关系[20]。
图2
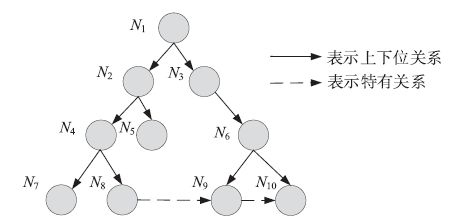 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2本体领域树示意图
Fig.2An ontology domain tree
2.1.1领域本体语义关系定义
本小节对领域本体结构中语义关系的相关概念进行定义。
定义一:语义距离。设Ni、Nj为本体领域树中任意两个概念节点,语义距离d(Ni,Nj)表示从Ni到Nj所经过的路径长度。
定义二:语义重合度。设R为本体层次树的根。NS(Ni)是从Ni出发,向上直到根R所经过的概念节点集合。Ni、Nj语义重合度表示为:
定义三:节点层次。Level(Ni)表示节点Ni在本体领域树中所处的层次。
定义四:概念节点Ni、Nj的相似度。定义为:
定义五:概念节点Ni、Nj的语义相关度。定义
为:
其中ShortestP(Ni,Nj)为Ni、Nj间的最短距离。语义相关度主要用于表示领域本体树中具有非上下关系的节点间的相关程度。
2.1.2领域本体语义关系构建
领域本体结构中概念间的语义关系应包含两种关系:本体中的上下位关系和本体中定义的其他关系。因此定义概念间语义关系R(Ni,Nj)为:
由式(4)可以得到本体概念集合中的所有概念间语义关系,并可以表示出本体的语义关系矩阵Sm×m:
其中sij(0≤i, j≤m)表示概念Ni与Nj之间的语义关系,即sij = R(Ni, Nj)。易知S为对称矩阵,即sij = sji。
2.2 科技资源向量空间表示
每一个科技资源都可以根据领域本体树中的概念集合唯一表示为词袋(Bag of words, BOW)向量形式,即:其中,0≤i≤k,k为科技资源集合中的资源总数。
对于异构异质异种的科技资源集合,由于概念领域的较大差异,其向量表示会呈现出极其稀疏的特性。且构建的领域本体树概念数目越大、覆盖领域越广,这种现象也越严重,将会增加分析和计算的难度和成本[21]。
为了降低高维数据的计算分析难度,本文采用主成分分析的方法对语义关系矩阵进行降维。主成分分析方法是将多个具有相关性的要素转化成几个不相关的综合指标的分析与统计方法,可以在保证主要信息少量丢失的前提下,对高维数据进行降维处理,把一些作用较低或不相关的指标省去,起到简化研究和提高计算效率的作用。
经过主成分分析后,本体概念集合将保留n个主要概念,且n<<m。经过降维后的语义关系矩阵S'可以表示为:
每个科技资源在降维后的语义关系矩阵S'下对应的向量形式表示为:
2.3 科技资源聚类
聚类分析用于将数据划分成有意义或有用的组(簇)。在本文中,对科技资源进行聚类形成许多资源包,以供后续通过一定的规则进行集成组合,为不同用户提供个性化的科技服务,提高检索查询效率。本文采用经典的K均值聚类算法。K均值聚类算法可以描述为:首先选择K个初始质心,每个点被指派到最近的质心,而指派到一个质心的点集为一个簇。然后以每个簇的均值替换更新每个簇的质心,重复这个过程,直到簇不发生变化或质心不发生变化即收敛[22]。其时间复杂度为O(I×K×k×n),其中I为收敛所需迭代次数,K为聚类簇数,k为点数,n为属性数量。当K显著小于k时,K均值算法的计算时间可视为与线性相关。算法流程如表1所示。
Table 1
表1
表1聚类算法
Table 1
| Algorithm K-均值聚类算法************************* |
|---|
| Input: 科技资源向量空间,K个初始质心 |
| Output: 聚类结果 |
| 1. repeat |
| 2. 将每个点指派到最近的质心,形成K个簇 |
| 3. 重新计算每个簇的质心 |
| 4. until 质心不发生变化 |
新窗口打开|下载CSV
本文使用科技资源向量间的欧式距离度量点间距离,基于肘部法则(Elbow Method)来选择合适的K值。肘部法则是一种K均值聚类簇数的选择方法,它通过寻找畸变程度得到大幅改善的K值来确定聚类簇数。
3 实验分析
为了验证本文设计的聚类方法,使用“中国科技资源共享网”(https://www.escience.org.cn)中的部分水生生物种质数据作为科技资源数据集进行实验。该数据集包含国家水生生物种质资源库提供的3 606个与水生生物相关的资源的名称、描述等资源元数据信息。3.1 水生生物种质资源本体树构建
为了应用本文的方法,首先需要建立水生资源数据的领域本体树。本文设计的领域本体树主要针对水生资源数据标题、描述以及关键词中出现的词汇用手动建立。本体树含有27个概念及个体,如图3所示。图3
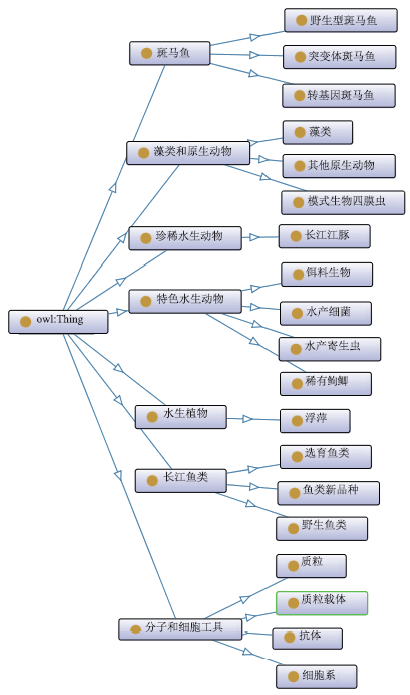 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3领域本体树
Fig.3Domain ontology tree
将此领域树通过2.1节描述的方法建立降维矩阵,将27个概念组成的高维向量转换为3个主要概念组成的向量。通过分析降维矩阵可知,对每个主要概念贡献最大的前5个主要概念如表2所示。
Table 2
表2
表2贡献前5的主要概念
Table 2
| 概念 | 主要概念1 | 主要概念2 | 主要概念3 |
|---|---|---|---|
| #0 | 抗体 | 突变体斑马鱼 | 特色水生动物 |
| #1 | 质粒 | 野生型斑马鱼 | 藻类和原生动物 |
| #2 | 细胞系 | 转基因斑马鱼 | 长江鱼类 |
| #3 | 分子和细胞工具 | 斑马鱼 | 珍稀水生动物 |
| #4 | 突变体斑马鱼 | 水产细菌 | 水生植物 |
新窗口打开|下载CSV
通过这些信息可知:主要概念1侧重于分子和细胞工具相关资源;主要概念2侧重于斑马鱼资源;主要概念3侧重于水生生物。
3.2 水生生物种质资源向量表示
科技资源相关描述主要由标题与详细描述两部分文本组成。为了将描述转换为向量,首先分别把标题和详细描述分别转换为与概念同维度的27维向量。具体方法为:如概念出现在文本中则设置为1,否则设置为0。之后将标题向量、详细描述向量和关键词向量叠加形成科技资源数据描述向量。以水生生物资源数据的一个资源为例,其标题为“工具质粒 (pT2(kop:Cre-UTRnos3, CMV:EGFP))”,描述为“由国家斑马鱼资源库收集、保藏,用于科学研究目的的工具质粒。DNA资源,经由每年不少于一次转化、质粒提取、验证工作维护。资源常年以DNA样品方式保藏和分享。资源类型为工具质粒。”关键词为“斑马鱼;工具质粒;DNA”。转换后向量中非0值以及对应概念如表3所示。
Table 3
表3
表3科技资源向量实例
Table 3
| 向量下标 | 概念 | 向量值 |
|---|---|---|
| 9 | 质粒 | 3.0 |
| 17 | 斑马鱼 | 2.0 |
新窗口打开|下载CSV
其中向量下标为9的“质粒”取值为3,因为概念出现在标题、描述和关键词中;下标为17的斑马鱼取值为2,因为概念同时出现在描述和关键词中。
通过以上方法对水生生物种质资源数据中3 606个样例进行向量化,并通过2.2节描述的方法进行降维得到3维空间中的点集。
3.3 水生生物种质资源聚类
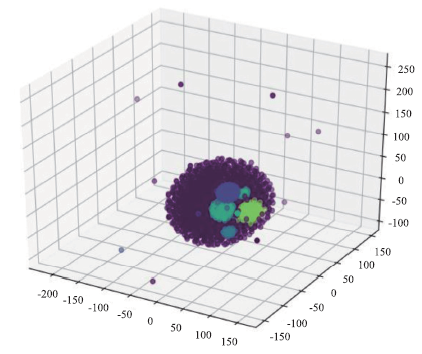
对3.2节降维后的结果使用K均值算法对科技资源进行聚类。根据肘部法则进行K值的选取,根据图4聚类簇数量与误差平方和(Sum of the Squared Error, SSE)关系图,本例中K值选取为6,即聚类簇数为6。聚类结果如图5和表4所示。图4
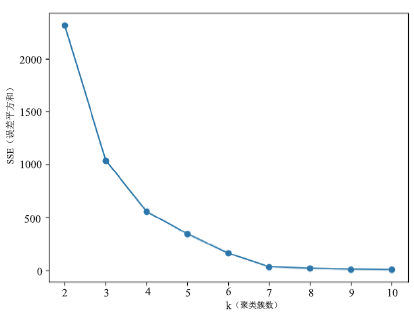 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4聚类簇数量误差平方和(SSE)关系图
Fig.4Relationship between the number of clusters and SSE
图5
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5科技资源聚类向量空间
Fig.5Technology resource clustering vector space
Table 4
表4
表4科技资源聚类结果
Table 4
| 类别 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 数量 | 1772 | 1260 | 424 | 102 | 26 | 22 |
| 解释 | 藻类和原生动物 | 斑马鱼 | 模式生物四膜虫 | 水产细菌 | 长江鱼类 | 质粒载体、鱼类细胞系 |
| 错误 | 8 | 1 | 1 | 1 | 1 | 2 |
新窗口打开|下载CSV
由聚类结果可知,本文提出的聚类方法将2 606条水生资源数据聚成了6类,且聚类结果具有明显的语义意义,与数据提供机构给出的主题分类(图6,来自“中国科技资源共享网”)能够较好地吻合,其准确率为99.6%。相关科研工作者提出科技资源需求时,可以通过检索条件检索到相关的资源包并进行优化配置实现个性化服务。
图6
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6国家水生生物种质资源库主题分类
Fig.6Theme classification of NABRC
综上,本文使用“中国科技资源共享网”(https://www.escience.org.cn)中水生生物种质资源验证了本文讨论的科技资源聚类方法,可以看到通过领域本体树对科技资源向量进行降维后依然保持了良好的原始数据特征,并取得了良好的聚类结果。这验证了本方法在高维数据集上应用的有效性。
4 结论与展望
本文提出了一种基于领域本体概念树的科技资源向量化方法,给出了本体概念语义关系矩阵的构造方法和向量空间的构造方法,并利用该向量空间进行了聚类处理分析,目前在一般规模的真实数据集上得到了较好的聚类结果。证明通过本体概念语义关系降维后的向量在简化计算的同时,依然可以保留足够的科技资源特征信息。本方法具有针对多源异构的高维科技资源数据的处理能力,为领域广、数量大的异构科技资源集合进行聚类分析和个性化服务共享提供了技术支持。通过本方法产生合适的科技资源聚类后,可以在由每个聚类中心组成的新向量集合中进行查询条件最近邻检索,并对检索结果对应的聚类包通过一定的规则进行选择集成组合,可以达到为不同用户提供个性化资源服务的目的。如何对资源包进行选择和最优化组合配置将是科技资源集成的另一个研究重点。
本文提出的异构数据聚类方法依赖于基于领域本体的数据预处理过程,目前对大规模构建领域本体仍然是一个困难的工作。本文未来将研究利用深度学习和知识图谱的技术自动构建大规模的本体领域网络以适应海量的、覆盖众多领域的科技资源数据集。
本文的另一个未来工作方向是改进聚类方法的灵活性和计算效率,以具备较强的领域适应性和规模适应性。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
[本文引用: 2]
[C].
[本文引用: 1]
[M].
[本文引用: 1]
[J].
DOI:10.1198/106186006X113430URL [本文引用: 1]
[J].
DOI:10.1007/BF00337288URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
URL [本文引用: 1]

针对云制造资源服务模型及其特点,形式化定义了云制造资源及其粒度模型。通过构建制造资源的分布式语义描述模型,屏蔽了各类制造资源粒子在底层数据结构方面的差异,在信息表示的更高层次上实现了制造资源粒子的虚拟化描述。通过构建云制造资源本体对散布在各类网络环境中的制造资源在逻辑上进行统一管理、语义查询和智能推理。同时构建了云制造资源的集成化智能服务模型,使制造企业联盟在资源查询、资源匹配、资源利用以及资源协同等方面更加高效和便捷。
[D].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
URL [本文引用: 1]
在应用SVM对文本进行分类时,用传统的TFIDF算法对文本特征进行选择会产生高维特征向量问题,这个问题干扰了SVM的效率和准确性,使SVM的性能下降.为了解决SVM文本分类过程中产生的这个问题,提出一种基于本体的特征项约简方法.该方法通过本体找出特征向量中具有同义关系、组成关系和上下位关系的冗余特征项,然后对它们进行合并降低特征向量的维数.试验结果表明,采用本体约简特征向量的方法改进了SVM分类器的性能.
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}