 ,1,*, 程凯1,2, 韩雪华1,2, 张敏1,21.
,1,*, 程凯1,2, 韩雪华1,2, 张敏1,21. 2.
Big Data Driven Data Technology Analysis Frontier and Application in Resource Discipline
Wang Juanle,1,*, Cheng Kai1,2, Han Xuehua1,2, Zhang Min1,21. 2.
通讯作者: * 王卷乐(E-mail:wangjl@igsnrr.ac.cn)
收稿日期:2020-01-15网络出版日期:2020-04-20
| 基金资助: |
Received:2020-01-15Online:2020-04-20
作者简介 About authors

王卷乐, 中国科学院地理科学与资源研究所,博士,博士生导师,地球数据科学与共享研究室副主任,世界数据中心可再生资源与环境数据中心主任。主要研究方向为资源环境数据集成与共享、一带一路空间信息系统、防灾减灾知识服务。
本文中负责总体统稿、资源学科领域创新应用平台与典型应用。
Wang Juanle, Ph.D., is a professor and doctoral supervisor of Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences. His recent research interest areas follow: scientific data sharing in resources and environmental field, the space information system of Belt and Road Initiatives, and knowledge service system of disaster risk reduction.
He is responsible for the final compilation, edition of the manuscript, implementation of the Resource Discipline Innovation Platform and design of the typical applications. E-mail:wangjl@igsnrr.ac.cn

程凯,中国科学院地理科学与资源研究所,博士研究生。研究方向为遥感地学分析、机器学习在遥感领域的应用等。
本文中负责资源遥感监测技术、资源调查技术、部分资源综合分析技术的撰写。
Cheng Kai is a doctor student of Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences. His research interests include Geo-analysis of Remote Sensing, Machine Learning Application in Remote Sensing.
He wrote the parts of the resource remote sensing technologies, resource surveying technologies and comprehensive analysis technologies.
E-mail: chengk@lreis.ac.cn

韩雪华,中国科学院地理科学与资源研究所,博士研究生。研究方向为灾害数据挖掘、社交媒体数据挖掘、公众行为分析等。
本文中负责资源网络挖掘技术、摘要、引言等内容的撰写。
Han Xuehua is a doctor student of Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences, majoring in cartography and geographic information systems. Her main research interests include natural disaster social media data mining and public behavior analysis during natural disasters.
She completed the parts of the resource net mining technologies, abstract and introduction.
E-mail: hanxh@lreis.ac.cn

张敏,中国科学院地理科学与资源研究所,博士研究生。目前主要从事灾害数据管理与共享、知识图谱构建的研究工作。
在本文中承担资源综合分析技术部分。
Zhang Min is currently an Ph.D student in National Key Laboratory of Resources and Environmental Information System, Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences (IGSNRR,CAS). Her research interests focus on disaster data management and sharing, and knowledge graph construction.
Her contribution to this paper is the part of comprehensive resource analysis technologies.
E-mail: zhangmin@lreis.ac.cn

摘要
【目的】在大数据驱动和信息技术支持下,使得资源科学综合研究这一学科灵魂问题的突破和解决成为可能,催生和促进资源科学的新发展,促进资源学科领域的创新应用。【方法】基于资源学科领域需求,阐述了资源学科领域数据分析技术前沿,包括资源遥感监测、资源调查、资源网络挖掘以及资源综合分析等技术。以中国科学院“十三五”信息化专项科学大数据工程项目“大数据驱动的资源学科创新示范平台”为例,展示其典型应用架构。【结果】基于应用案例,展现了中蒙俄经济走廊交通与管线生态风险防控、京津冀资源环境承载力评价、大数据驱动的美丽中国全景评价三个典型资源学科领域科研活动应用中的大数据驱动场景。【结论】大数据驱动的资源学科领域数据分析技术具有巨大潜力且已有部分应用展示,但仍需要更多适应资源学科领域发展的新方法和新模式,促进其向综合科学研究的范式转变。
关键词:
Abstract
[Objective] Driven by big data and supported by information technology, it makes it possible to break through and solve the soul problem of the comprehensive study of resource science, promoting the new development and innovative application of resource science, and the innovative application of resource science. [Methods] Based on the domain demand of the resource discipline, this paper expounds the frontier of data analysis technology in the resource discipline, including remote sensing monitoring, resource surveying, resource network mining and resource comprehensive analysis, and takes the “The Big Data Driven Resource Discipline Innovation Platform” supported by 13th Five-year Informatization Plan of Chinese Academy of Sciences as an example to demonstrate its typical application architecture. [Results] Based on application cases, three big data-driven scenarios in the typical application of scientific research activities in resource discipline are presented, including ecological risk prevention of transportation and pipeline control in China-Mongolia-Russia economic corridor, assessment of the carrying capacity of resources and environment in Beijing-Tianjin-Hebei region, and assessment of the beautiful China driven by big data. [Conclusions] The data analysis technologies driven by big data in the field of resource discipline have great potential and some of them have been applied in reality. However, more new methods and models adapted to the development of resource discipline are needed to promote its paradigm shift to comprehensive scientific research.
Keywords:
PDF (10366KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
王卷乐, 程凯, 韩雪华, 张敏. 大数据驱动的资源学科领域数据分析前沿与应用. 数据与计算发展前沿[J], 2020, 2(2): 20-30 doi:10.11871/jfdc.issn.2096-742X.2020.02.002
Wang Juanle.
引言
资源科学是研究资源的形成、演变、质量特征与时空分布及其与人类社会发展之相互关系的科学。其目的是为了更好地认识资源,合理开发、利用、保护和管理资源,协调资源与人口、资源和环境之间的关系[1],促使其向有利于人类社会生存与发展的方向转化[2]。资源学科涉及资源开发与利用、环境科学、区域可持续发展及资源环境观测技术科学等多个方面,包括水循环和水资源、土壤和土地资源、气候变化影响与适应、生态系统、环境科学与工程、区域可持续发展、遥感科学与地理信息科学等领域,是一个综合的现代学科群。由于资源环境领域需求各异以及相关行业标准及规范的更新变化,资源学科数据存在种类繁多、格式多样、标准难以统一的特点。随着资源环境全局性问题协调的需求不断增大,传统的单一资源学科的深化难以解决资源与环境可持续发展的综合性问题。大数据时代催生了围绕海量数据获取、存储、共享和分析的科学研究手段,即数据密集型研究范式[3,4],其显著特征是以数据作为科学发现的核心和科研活动的驱动力,从海量数据中发现科学规律[1,5]。资源科学的综合思想既强调作为研究对象的资源系统内部要素的关联与整体效应,也强调资源系统与其环境系统的耦合,还重视研究方法与技术手段的集成[1]。大数据技术可以解决资源学科数据存储和组织问题,能够在短时间过滤出有价值的内容,进而为资源数据服务集群化和产业化发展提供技术支撑。因此,资源学科领域的研究和应用迫切需要大数据应用环境和科研信息化技术分析方法的支持。本文结合资源学科领域发展需求,探讨大数据驱动的资源学科领域数据分析前沿,并以中国科学院“十三五”信息化专项科学大数据工程项目“大数据驱动的资源学科创新示范平台”为例,对典型应用进行探讨。
1 大数据驱动的资源数据分析技术前沿
1.1 资源遥感监测技术
遥感数据与土地资源具有高度一致的时空特点 [4,6],自遥感技术出现,就广泛的应用在土地资源在内的地表资源与环境方面。资源信息提取与监测是资源遥感大数据应用的普遍手段。提取的方法主要包括两类:一是基于专业人员对于遥感数据及其区域状况的了解,采用综合分析的方法来实现[6],但这种方法存在着人工投入大、对于解译经验要求较高且受个人主观因素影响大等问题[7];另一种是基于计算机技术,通过在遥感数据中提取有效的反映资源特点的特征,建立特征集实现资源信息的提取和分析,这种方法是当前资源遥感信息提取领域最常用的方法。特别是随着人工智能技术的发展,使得机器学习(Machine Learning, ML)等新技术在资源遥感领域的应用越来越普遍,如土地、海洋、大气等领域[8,9,10]。图1是机器学习在遥感及其他领域的一个通用的工作流程,包括:数据获取、数据清洗、模型构建与选择、结果评价、结果可视化五个步骤。图1
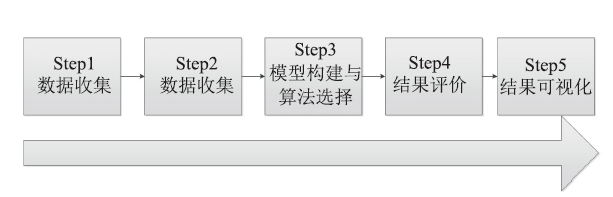 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1机器学习通用工作流程
Fig.1General workflow of machine learning
算法选择是机器学习中的关键步骤之一,选择哪一种算法最优取决于研究的问题或对象。目前主要有三大类机器学习算法,分别是有监督的机器学习、无监督的机器学习与强化学习。监督算法在分类时使用的是包含输出列的数据集,而无监督算法使用的是全部未标记的样本,根据数据集在不同记录之间识别出的关系将数据集聚到不同的类别中。强化学习则是提供一个环境,并在这个环境中做出决策,根据决策得到的反馈,不断改进自己。
随机森林(Random forest,RF)、支持向量机(Support Vector Machine,SVM)与人工神经网络(Artificial Neural Networks,ANN)[11,12,13]是资源遥感中较为常用的关键方法。RF算法属于集成分类器,意味着它在做决策时,利用了多个决策树。在分类过程中,RF中的每棵决策树都会做出类别预测,而获得票数最多的类别将成为模型预测的类别。由于不同模型(决策树)之间的相关性较低,因此可以产生比单个预测更准确的总体预测。SVM是一种监督学习模型,可用于回归和分类问题。它是由一个分离超平面正式定义的判别分类器,在给定训练数据(监督学习)的情况下,该算法输出一个最优超平面,该超平面对未分类数据进行分类。ANN是神经网络的一种,是在计算机上进行的受生物学启发的模拟,以执行特定的任务,如模式识别、聚类、分类等。ANN是通过在最小输入中学习不同类别的模式进而对未分类数据进行分析与分类,这与传统的依赖统计假设的算法是不同的。
1.2 资源调查技术
传统的资源调查技术多以大规模的综合科学考察、庞大的基础设施与大量的人员队伍为主,如依托全国布置40余万个地面采集样点定时开展的森林调查,依托全国2万多个水文站点开展水文要素的观测等。地理信息系统(GIS)、全球定位系统(GPS)、遥感(RS)等3S技术的出现促进了国土资源基础数据获取、处理、建库等全流程的数字化。对地观测数据的开放与共享,以及云平台的推广与使用产生了海量的资源数据,为资源环境调查、监测与评估提供了新的技术手段[14,15]。众源地理信息技术基于众多非专业人员来志愿采集数据,并按照一定的标准将众源地理数据(Volunteered Geographic Information,VGI)汇交至服务器、分布式数据库或云平台[16]。随着智能手机的快速发展与普及,进一步促进了众源地理数据的发展。如Fritz 等人创建了Geo-Wiki.Org 网站并开发了“GEOwiki pictures”手机应用程序,使全球用户通过使用程序上传带有地理位置信息的照片,贡献包括森林、草地、农田、水体、湿地等生态系统位置和照片的“众源数据”。全球农情遥感速报团队建立了“GVG(GPS、VIDEO 和 GIS)农情采样系统”桌面端软件,使其可以在移动智能端进行使用,从而实现了农作物种植状况照片的随时随地采集[14]。
随着网络和计算机技术的革新,云存储和云计算技术已经成为当前主流的技术手段。与传统的个人计算机、服务器等硬件设备相比,云平台具备计算效率高、性能强、可弹性扩展、存储容量大、价格低、数据安全等特点,适用于海量地理数据的处理、运算与分析。基于云计算技术出现的地理数据云平台也逐渐成为资源环境数据研究和生产的主要手段。得益于云平台高速计算设备,用户可直接在云端处理与分析数据,实现地表资源环境长时间序列、多空间尺度地处理与分析,解决了运算、存储能力限制等方面的问题[14]。如2011 年,Google 公司发布了“Google Earth Engine”云计算平台。澳大利亚地球科学院(Australian Geoscience)于 同年开发了云端地理数据处理方案“Data Cube”,并实现了对澳大利亚全境包括遥感、气象、地面站点数据等的一致性数据管理构架。“AWS 亚马逊云”开放了包括NASA Earth Exchange数据集、全球 Landsat 系列影像、Sentinel 系列卫星影像、气象雷达(NEXRAD)数据、美国农业影像计划(NAIP)和数字高程(DEM)等数据集。利用这些云端对地观测数据,科学家可以更加方便地开展大尺度资源环境调查、监测与分析。
1.3 资源网络挖掘技术
网络数据按数据类型可分为自媒体数据、日志数据和富媒体数据三类。其中,自媒体数据主要是指通过以Facebook、Twitter、微博等为代表的社交网络中产生的用户生成数据(User Generated Content,UGC),具有空前的规模性和群体性,数据总量巨大,数据变化非常快。譬如,截止2019年4月,全球社交媒体用户数量达到近 35 亿,其中98% 的社交媒体用户(超过 34 亿人)通过移动设备访问社交平台。Facebook月活跃用户总数为24.5亿,日活跃用户16.2亿;新浪微博月活跃用户4.86亿,日活跃用户2.11亿。日志数据主要指各种网上服务提供商积累的系统和用户操作的日志记录,比如Google、百度等搜索引擎提供商积累的用户搜索行为日志,中国移动等电信运营商积累的用户通话日志数据,亚马逊、淘宝等网络购物平台提供商积累的用户交易数据等,具有大量的历史性数据、同时数据增速极快、数据访问吞吐量巨大。富媒体数据指聚合多种媒体数据(包括文本、音视频、图片、文字、消息等)动态、交互的体现。富媒体并不单纯是互联网多媒体形式,还包括动画、声音、视频或交互性的信息传播方式,具有内容多源、异构的显著特性[17,18]。资源网络数据挖掘方面,依托网络爬虫、信息抽取、主题模型、情感分析等技术,根据典型应用的示范需求,展开资源网络大数据整合与挖掘。一方面以国家和地方自然资源管理的机构网站,以及新浪网、新华网、人民网、搜狐网、腾讯网以及百度等互联网媒体为数据源,对互联网中的资源环境数据进行收集、整理,如自然资源禀赋、资源储量、资源开发、资源利用、资源配置等。另一方面以设计媒体、新闻文本等为数据源,提取环境感知信息,获取具有地理分布特征的专题信息;进行资源环境舆情分析,挖掘相关的语义信息、探索分布规律、检测异常,提取网络文本的资源环境相关信息;并将其纳入传统上以调查数据为对象的空间计算模型中[19]。利用网络开放资源、百科协作平台或社会化媒体,丰富资源环境要素或事件的时空属性,自动生成结构化资源环境知识库[19]。相关技术介绍如下文。
主题模型(topic model)是以非监督学习的方式对文集的隐含语义结构(latent semantic structure)进行聚类的统计模型[20]。主题模型主要被用于自然语言处理中的语义分析和文本挖掘问题[21],能够处理和分析大规模文本并从中获取文本主要内容和主题,生成各文本的主题概率分布以及各主题的单词概率分布。目前应用比较广泛的主题模型有LDA模型、BTM模型、DMM模型等。潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)是Blei 等在2003 年提出的经典的主题模型,在基于位置的推荐、事件探索、话题发现方面得到了广泛应用[22,23,24]。LDA模型是三层贝叶斯模型,包括文本、主题和单词,是利用词语在文档中共现信息来发现文档集包含的主题信息。基本思想是每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布[25,26]。
资源的开发利用是人与自然资源之间的相互作用和相互协调。人类在参与的过程中也会产生相应的情感。情感分析(sentiment analysis)是指对带有情感色彩的主观性文本进行采集、处理、分析、归纳和推理的过程,涉及到人工智能、机器学习、数据挖掘、自然语言处理等多个研究领域[27,28,29]。分析资源学科研究和应用中的情感,能够探测到不同区域面临的资源环境开发、利用、保护、破坏等方面的公众舆情和情绪。美国心理学家Ekman发现人类有6种基本情绪:快乐、悲伤、恐惧、惊讶、愤怒、嫉妒[30]。这六种情绪之间可相互组合,或派生出其他复合情绪。情感分析的实现方法主要包括基于情感词典与规则的方法和基于机器学习的方法[31]。
1.4 资源综合分析技术
资源综合分析技术在提高数据检索效率、充分挖掘资源科学数据价值、提供各类知识服务等方面发挥了重要作用。1998年,澳大利亚提出了“玻璃地球”计划,目的是研制三维可视化和地质模拟等技术, 使澳大利亚大陆表层一千米及其发生的地质过程变得“像玻璃一样透明”,以便可以发现澳大利亚下一代巨型矿床。“玻璃地球”建设涉及地球探测、地质信息和资源环境评价三大综合分析技术领域,核心技术是地质信息技术[32,33,34]。为实现“玻璃地球”而进行的技术综合包括设备层的重力梯度测量、张力梯度和地磁测量,以及同位素地球化学等学科知识和技术;知识产生层的表土作用过程、地球化学、水文地质、力学化学耦合模拟等学科知识和技术;数据处理层的可视化、转化融合等技术。2005年启动的由美国NSF资助、美国威斯康星大学主导的Macrostrat是收集地层、古生物数据的平台,是世界上最大的同质化地质图数据库,目前覆盖北美、南美局部、新西兰等地区。此外,还有Earth Byte, DCO (About the Deep Carbon Observatory), 4D (Deep-time Data Driven Discovery) 等驱动地球科学综合研究的平台。2011年,美国NSF的计算机与信息科学工程和地球科学学部联合发起了地球科学领域的Earth Cube计划,其目标是以一种公开、透明和综合性的方式整合所有地球科学数据、信息、知识以及实践来创建地球科学知识管理系统和基础设施,从而极大地提升研究及教育者的知识创造和传播能力[35]。2018年中国科学院启动了A类战略性先导科技专项“地球大数据科学工程(CAS Earth)”,旨在突破技术瓶颈问题,形成资源、环境、生物、生态等领域多学科融合的地球大数据云服务平台,成为支撑国家宏观决策与重大科学发现的大数据重大科技基础设施[36,37]。CAS Earth的核心是突出地球大数据关键技术,拟利用地球大数据技术解决资源、环境、生物、生态等领域多学科的问题,如在2019年向联合国提交的《地球大数据支撑可持续发展目标报告》。报告案例中,研究者基于SAR和光学影像融合生产了2015年全球10米分辨率不透水面遥感产品,其精度优于85%,解决了土地消耗率与人口增长率比率指标监测数据缺失问题;选取土地覆盖、土地生产力与土壤碳3个子指标,利用全球尺度地球大数据与产品,采用联合国防治荒漠化公约(UNCCD)发布的GPG(Good Practice Guidance on SDG 15.3)报告及Trend.Earth推荐方法,完成了全球尺度2000-2015年土地退化/恢复评估等。
人工智能、知识图谱、关联分析等新技术已逐步成为资源学科各个领域的重要数据分析计算工具。深时数字地球大科学计划(Deep-time Digital Earth, DDE)将基础学科研究与人工智能相融合,旨在整合地球演化全球数据、共享全球地学知识。关联开放云(The Linked Open Data Cloud, LOD,
2 资源学科领域创新应用平台与典型应用
2.1 资源学科领域创新应用平台
基于以上资源学科领域的数据分析需求,在中国科学院信息化专项支持下,设计和构建了大数据驱动的资源学科创新示范平台。该平台包括基础设施、数据存储管理、数据处理计算与模型集成、协同科研活动环境、数据分析与可视化应用服务五部分,平台架构如图2所示。图2
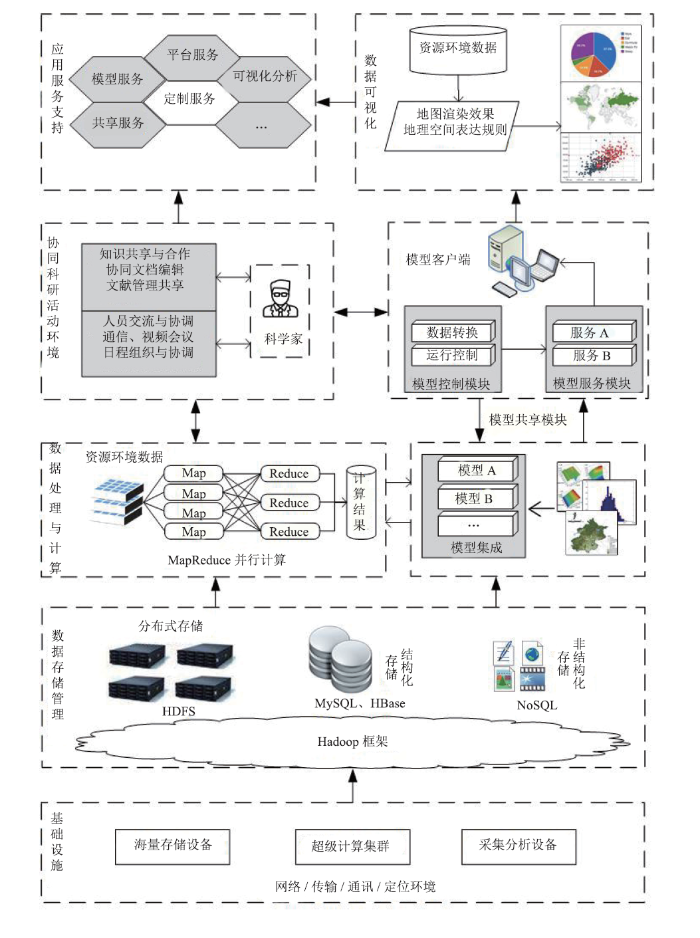 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2资源学科领域大数据创新应用平台框架
Fig.2Framework of big data innovation application platform in resource discipline field
基础设施基于中国科技云基础设施,以及资源学科领域的私有云设施,建立基础的云环境,是创新示范平台正常实施与运作的基础。数据存储管理基于Hadoop/Spark框架的分布式存储文件系统HDFS、NoSQL数据库,实现多源、非结构化数据存储管理。数据处理计算与模型集成采用MapReduce并行计算处理技术,结合资源环境领域相关理论,将现有模型与大数据技术相结合,集成超过200个资源环境数据处理与分析模型,涉及土地资源、水资源、生物资源、矿产资源、城市承载力、旅游资源等多个方向。协同科研活动环境在互联网络环境、超级计算环境、数据应用环境等信息化基础上,实现跨组织、跨区域、跨学科的资源环境领域科研合作研究虚拟环境,为资源环境科研工作者和国家重大科研项目提供基于网络的合作研究。数据分析与可视化应用服务提供数据时空分析计算等所需模型和工具软件,对多源异质数据进行数据级、特征级、决策级融合,形成区域高精度、高频率、高时空分辨率集成数据产品,实现重点区域评估可视化等应用环境。
基于以上框架,基于Web+WebGIS模式开发构建大数据驱动的资源学科领域创新应用平台(
在资源学科科学计算模型算法方面,平台设计构建了资源学科创新平台模型共享子系统。构建了资源领域科学计算模型分类体系,集成超过200个资源环境数据处理与分析模型,促进资源学科的模型集成共享,将模型共享服务推向大众。平台实现了模型元数据目录服务的功能;制定了资源学科科学计算模型的元数据标准规范;定义了资源学科模型互操作接口规范。模型共享包括六个步骤:一是模型开发与共享转换,二是模型注册,三是模型审核,四是模型发现,五是模型应用,六是复杂应用集成[38]。
图3
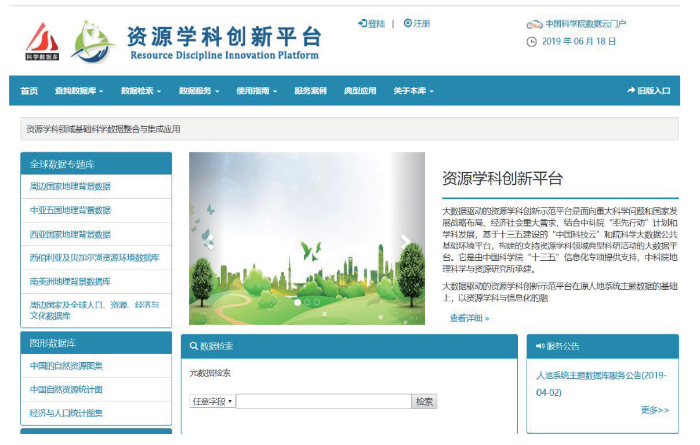 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3资源学科创新应用平台门户
Fig.3Resource discipline innovation platform portal
2.2 资源学科大数据驱动典型应用场景
(1)中蒙俄经济走廊交通与管线生态风险防控典型应用结合联合国可持续发展目标(Sustainable Deve-lopment Goals,SDGs)15.3中的土地退化问题,以中蒙铁路沿线(蒙古段)两侧200公里范围内的区域作为研究区,以Landsat8数据为基础数据源,基于Albedo-NDVI、Albedo-MSAVI、Albedo-TGSI三种特征空间模型的适用性,结合平台的遥感大数据处理与信息提取系统,得到中蒙铁路沿线(蒙古段)荒漠化分布数据(图4),结合土地利用矩阵变化,分析了1990-2015年的中蒙铁路(蒙古段)的土地退化格局与变化特征,发现中蒙铁路沿线(蒙古段)不同区域荒漠化的分布规律,为本区域荒漠化防控提供精细的数据和方法支持[39,40,41,42]。
图4
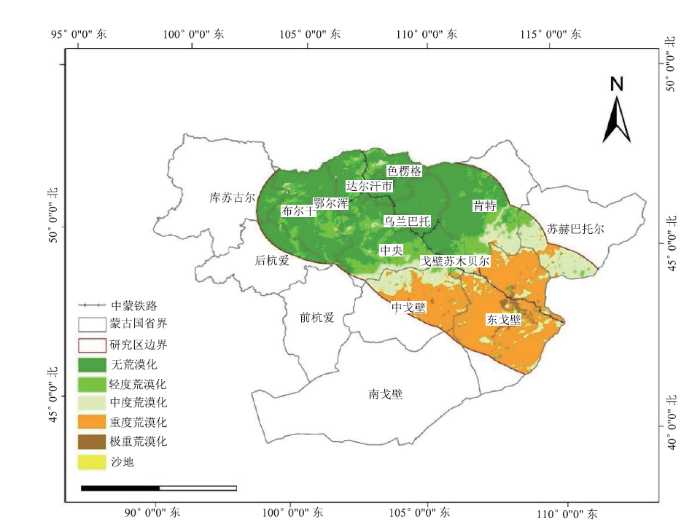 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4中蒙铁路沿线(蒙古段)2015年荒漠化分布图
Fig.4Desertification distribution map along the China-Mongolia railway (Mongolian section) in 2015
(2)京津冀资源环境承载力评价典型应用
结合SDG11与中国城市化发展的需求,利用资源大数据进行京津冀资源环境区域承载力评价,为区域可持续发展提供科学有效的建议。①构建资源网络大数据分析与挖掘方法体系,依托新型互联网大数据,研发面向高时空分辨率的资源网络大数据分析与挖掘评价指标。②融合京津冀资源与环境承载力评价指标体系与数据,建立适用于京津冀资源环境可持续发展评价指标体系,具体包括生态环境、经济增长、社会进步、城市发展类要素。③搭建京津冀资源环境承载力评价模型方法与平台(图5),筛选影响京津冀资源环境承载力与可持续发展的关键因素,构建区域可持续发展过程模拟的系列数学模型,进行资源环境承载力综合评价,搭建京津冀资源环境承载力评价平台原型。④面向京津冀协同可持续发展的客观需求,为制定国家新型城镇化战略、城镇群规划等提供技术方法和理论支撑,提高政府决策的科学性。
图5
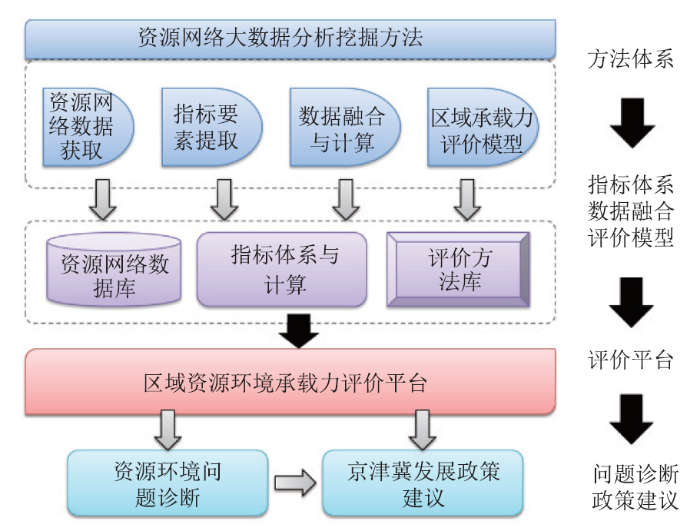 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5京津冀资源环境承载力评价平台系统
Fig.5Website of the resource and environmental carrying capacity assessment in Beijing-Tianjin-Hebei region
(3)大数据驱动的美丽中国全景评价典型应用
结合中国科学院地球大数据科学工程,以地球大数据和云服务平台为基础,综合集成网络大数据、遥感大数据、社会经济统计数据等多源数据,构建地球大数据集成平台,根据美丽中国评价指标的需求提供相关数据、方法与模型产品[43]。①数据生产与汇集。汇集基础地理数据、网络挖掘数据、社会经济数据、遥感数据产品等数据产品,如2000年乡镇级人口数据、中国地表高程数据、中国地表坡度数据、中国地表坡向数据、全国道路数据、耕地保护数据、经济总量数据等,为美丽中国评价提供了支撑。②遥感技术支撑森林类型提取与服务SDG森林资源可持续评价。利用Sentinel-2影像、Sentinel-1SAR数据、SRTMDEM数据、森林类型清查数据、森林类型野外调查数据、环球地理参场图片库等数据,依托Google Earth Engine(GEE)大数据处理云平台和机器学习技术,综合时空谱特征得到空间分辨率为10米的中国秦岭地区森林类型产品。③为服务美丽中国评价,研发了面向美丽中国的数据集成与共享原型系统。系统内集成了面向“美丽中国生态文明建设科技工程”(以下简称“美丽中国”专项)评价的基础地理数据、社会经济数据、遥感数据产品等,覆盖中国、区域等不同尺度(图6)。
图6
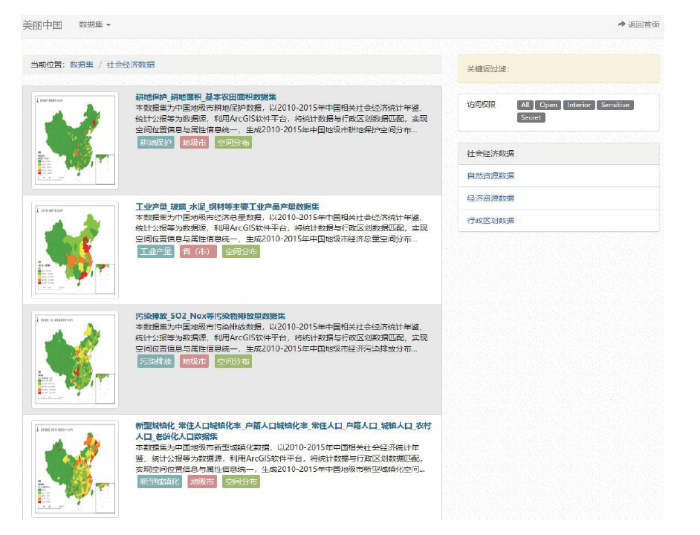 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6面向美丽中国的数据集成与共享平台系统
Fig.6Data integration and sharing platform system for Beautiful China
3 结论与展望
本文结合资源学科领域数据分析和计算的需求,阐述了资源学科领域数据分析技术前沿,包括资源遥感分析、资源调查分析、资源网络挖掘以及资源综合分析等技术。依托大数据驱动的资源学科创新示范平台,介绍了平台的框架、技术、算法、应用等架构。实现了中蒙俄经济走廊交通与管线生态风险防控、京津冀资源环境承载力评价、大数据驱动的美丽中国全景评价等资源学科领域典型场景应用。大数据驱动的资源学科领域数据分析技术具有巨大潜力且已有部分应用展示,但仍需要更多适应资源学科领域发展的新方法和新模式,促进其向综合科学研究的范式转变。未来将进一步探索大数据驱动下的资源学科综合研究信息链、跨国科学考察协同科研模式等新型研究模式。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 3]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[D].
[本文引用: 1]
[D].
[本文引用: 1]
[D].
[本文引用: 1]
[J].
[本文引用: 3]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 2]
[J].
[本文引用: 1]
[D].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[D].
[本文引用: 1]
[D].
[本文引用: 1]
[J].
[本文引用: 1]
[M].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.3390/rs10030446URL [本文引用: 1]
[J].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}