 ,1,2,3,*1.
,1,2,3,*1. 2.
3.
Materials Science Database in Material Research and Development: Recent Applications and Prospects
Li Zixin1,2,3, Zhang Neng1,2,3, Xiong Bin1,2,3, Hu Yunfeng1,2,3, Zhao Xinpeng1,2,3, Huang Haiyou,1,2,3,*1. 2.
3.
通讯作者: * 黄海友(E-mail:huanghy@mater.ustb.edu.cn)
收稿日期:2020-02-16网络出版日期:2020-04-20
| 基金资助: |
Received:2020-02-16Online:2020-04-20
作者简介 About authors

李姿昕,北京科技大学新材料技术研究院,在读研究生,主要研究方向为机器学习。
本文承担工作为:数据库平台概述,以及论文的写作与修改。
Li Zixin is a master student at Institute for Advanced Materials and Technology, University of Science and Technology Beijing. Her main research interest is machine learning.
In this paper she undertakes the following tasks: organizing the review on the development of database, as well as the writing and revision of manuscript.
E-mail: s20191363@xs.ustb.edu.cn

张能,北京科技大学新材料技术研究院,在读研究生,主要研究方向为基于机器学习方法的Cu-Al合金断裂性能研究。
本文承担工作为:数据库应用的分析与讨论,以及论文的写作与修改。
Zhang Neng is a master student at Institute for Advanced Materials and Technology, University of Science and Technology Beijing. His main research interest is machine learning based research on fracture properties of Cu-Al alloys.
In this paper he undertakes the following takes: analysis and discussion of database applications, as well as the writing and revision of manuscript.
E-mail: s20191421@xs.ustb.edu.cn

熊斌,北京科技大学新材料技术研究院,在读研究生,主要研究方向为机器学习方法在形状记忆合金马氏体相变研究中的应用。
本文承担工作为:文献的整理、查阅。
Xiong Bin is a master student at Institute for Advanced Materials and Technology, University of Science and Technology Beijing. His main research interest is machine learning based research on martensite transformation of shape memory alloys.
In this paper he undertakes the following tasks: collecting and summarizing references.
E-mail: g20189313@xs.ustb.edu.cn

胡云凤,北京科技大学新材料技术研究院,在读研究生,主要研究方向为高弹热效应形状记忆合金以及机器学习。
本文承担工作为:文献的整理、查阅。
Hu Yunfeng is a master student at Institute for Advanced Materials and Technology, University of Science and Technology Beijing. Her main research interests are focusing on high elastocaloric effect shape memory alloys and machine learning.
In this paper she undertakes the following tasks: collecting and summarizing references.
E-mail: s20181326@xs.ustb.edu.cn

赵新鹏,北京科技大学新材料技术研究院,硕士,主要研究方向为第一性原理计算,机器学习以及高弹热效应形状记忆合金。
本文承担工作为:数据库在机器学习中的应用分析与讨论以及全文统筹。
Zhao Xinpeng, master, is studying at Institute for Advanced Materials and Technology, University of Science and Technology Beijing. His main research interests are First-principles calculations, machine learning and high elastocaloric effect shape memory alloys.
In this paper he undertakes the following tasks: conceptualizing and organizing the review on the application of database in machine learning.
E-mail: g20179183@ustb.cn

黄海友,北京科技大学新材料技术研究院,工学博士,副研究员。在Applied Physics Letters,APL Materials,Scripta Materials等期刊上发表学术论文61 篇。授权发明专利5项;参编著作3部;2017年获教育部自然科学奖二等奖。主要研究方向包括材料基因工程数据库与大数据技术,基于数据驱动的新材料研发和形状记忆合金等。
本文承担工作为:总体架构和主要思路。
Huang Haiyou, D.E, is an associate research fellow at Institute for Advanced Materials and Technology, University of Science and Technology Beijing. He has published more than 60 academic papers in Applied Physics Letters, APL Materials, Scripta Materials and other journals. He also has authorized 5 invention patents, edited 3 books and won the second prize of the Natural Science Award of the Ministry of Education in 2017. His main research interests are materials genome engineering database, big data technology, data-driven development method of new materials and shape memory alloys, etc.
In this paper he undertakes the following tasks: constructing manuscript structure and making up main ideas. E-mail:huanghy@mater.ustb.edu.cn

摘要
[目的]随着“大数据”时代的来临,大数据技术由于可显著加速材料研发,已经成为材料科学研究者关注的热点技术之一。基于材料数据库平台的材料大数据技术更是成为“材料基因工程”的三大核心技术之一。因此,材料数据库建设对于加速新材料的研发至关重要。[方法]本文通过对国内外材料科学数据库的建设及应用的概括和总结,并结合材料科学数据库的发展趋势,提出了未来的研究方向。[结果]材料基因组(工程)理念的提出和大数据技术的快速发展,促进了国内外大量材料科学数据库的建立。相较国外而言,国内的材料科学数据库建设相对较晚。但在“十三五”国家重点研发计划专项的支持下,我国材料科学数据库平台建设有望在未来几年内取得初步成效。[结论]材料科学数据库的建设已经成为材料基因工程技术发展进程当中一种不可或缺的要素,但在数据库建设和应用过程中还存在很多困难亟待解决,材料科学数据库的发展仍任重道远。
关键词:
Abstract
[Objective] With the advent of the "Big Data" era, big data technology has become one of the hottest technologies attracting material science researchers because it can significantly accelerate the development of materials. The material big data technology based on the material database platform is one of the three core technologies of "Materials Genome Engineering". Therefore, the construction of a material database is very important to acceleration of the development of new materials. [Methods] This article summarizes the constructions and applications of material science databases at home and abroad, and puts forward future research directions based on the development trend of material science databases. [Results] The advancement of the material genome (engineering) concept and the rapid development of big data technologies have promoted the establishment of a large number of material science databases at home and abroad. Compared with developed countries, the material science database construction in China is relatively late. However, with the support of the ‘Thirteenth Five-Year Plan’ national key research and development program of China, the construction of China's material science database platform is expected to achieve initial results in the next few years. [Conclusions] The construction of material science database has become an indispensable element in the development process of material genome engineering technology. But there are still many difficulties to be resolved in the process of database construction and application. The development of a material science database remains a challenging task.
Keywords:
PDF (10346KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
李姿昕, 张能, 熊斌, 胡云凤, 赵新鹏, 黄海友. 材料科学数据库在材料研发中的应用与展望. 数据与计算发展前沿[J], 2020, 2(2): 78-90 doi:10.11871/jfdc.issn.2096-742X.2020.02.006
Li Zixin.
引言
材料是科技发展的基础和先导,随着全球新一轮工业革命浪潮的掀起,加速材料的研发进程成为世界各国共同的追求。如何基于低成本、高可靠性的预测方法理性指导实验来快速获得定制性能的新材料成为与之相关的关键问题。随着“大数据”时代的到来,以机器学习等人工智能技术为代表的材料信息学领域快速发展,并迅速成为材料设计与开发的有力工具。机器学习技术已经在很多材料研究中得到了应用。例如,Xue等通过机器学习自适应设计,仅实验合成36种预测成分的合金试样,就可以从包含约800,000种不同成分的搜索空间中找到具有极小热滞的新型多组元Ni-Ti基形状记忆合金[1]。Kiyohara等通过采用机器学习方法,仅计算不超过0.18%的晶体结构的偏析能即可准确得到合金元素在晶界偏析的稳定构型[2]。Wen等采用机器学习引导实验的策略,在机器学习反馈回路的辅助下仅通过7次实验便得到了高硬度高熵合金[3]。机器学习技术已经被证明可以有效地加速材料的研发进程。人类社会已经进入了“大数据”时代,数据资源已经得到了广大科学研究者的重视,即使是“失败”的数据,也可以用来辅助训练机器学习模型来预测成功条件[4]。机器学习不仅能够对材料性能进行预测,同时,借助机器学习挖掘的边界条件等信息,也有助于推进对相关机理的认识。Stanev等就是通过机器学习研究了每个超导体系中预测因子的重要性,获得了关于不同体系驱动超导性的物理机制[5]。
然而,这种方法取决于是否有足够多的高质量的数据。但是在材料科学研究中,建立准确的机器学习模型往往需要“海量”数据进行训练。Rahaman等建立的可对未知化学成分的钢铁材料Ms准确预测的机器学模型,使用了包含2 277条化学成分和Ms数据的数据库[6];Schmidt等人为了通过机器学习预测立方钙钛矿体系的热力学稳定性,更是构建一个包含约250,000条DFT计算数据集[7]。但材料科学研究面临更普遍的情况是小数据困境,即所研究的材料对象缺乏足够的高质量数据。其中一个主要原因是由于数据分散造成的,Zhou等在采用机器学习对高熵合金进行相分类研究的过程当中,从134篇文献当中收集了601条数据来作为数据集[8],这大大增加了研究人员的工作量。
因此,数据库的建设成为了信息学技术在材料科学应用中的重要组成部分。美国在2011年奥巴马总统提出材料基因组计划时,将材料数据库作为三大基础平台之一,其建设得到了高速发展。本文首先介绍了国内外较为知名的材料数据库及其使用情况;然后,分析了数据库如何帮助机器学习技术在材料科学研究中得到广泛应用;最后,讨论了数据库建设和应用中所面临的困难及其发展趋势。
1 数据库概述
想要实现材料基因组工程这一颠覆性研发新模式,数据共享与计算工具开发显得至关重要。数据库作为材料基因工程不可或缺的一部分,已经得到了材料科学研究者们的重视,目前,国外较为著名的材料信息数据库有加州大学伯克利分校的劳伦斯伯克利国家实验室和麻省理工学院等单位联合组建的Materials Project[9]、杜克大学组建的AFLOW[10]以及美国西北大学组建的OQMD[11,12]等。我国在科技部、工业和信息化部等部门的大力支持下,以中国材料基因工程专用数据库为代表的材料科学数据库在快速建设当中,并且在机器学习应用领域已经取得了初步成果。1.1 国外材料数据库建设情况
Materials Project(MP)计算材料数据库平台(图 1
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 1Materials Project数据库数据量统计
Fig.1Materials Project database statistics
AFLOW计算材料数据库(
图 2
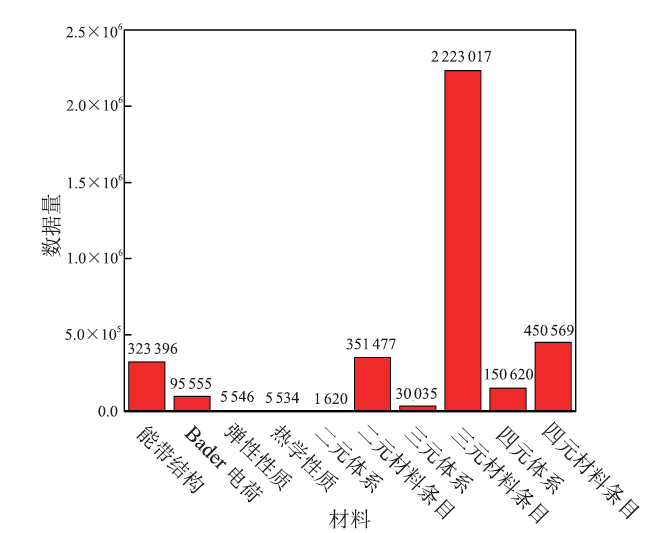 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 2AFLOW数据库数据量统计
Fig.2AFLOW database statistics
Open Quantum Materials Database (OQMD)开放量子材料数据库(
Materials Project,AFLOW和OQMD都是基于量子力学计算建设的数据库,这三个数据库计算数据所基于的晶体结构大多来自于ICSD数据库[17]。ICSD无机晶体结构数据库(
图 3
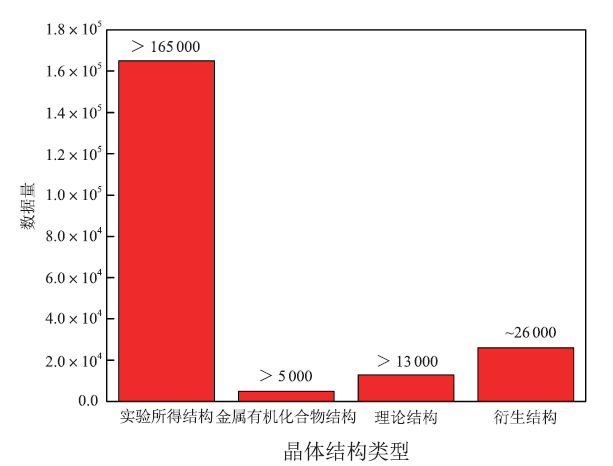 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 3ICSD数据库统计
Fig.3ICSD database statistics
除了以上几个著名的材料信息数据库以外,还有一些影响力较大的数据库。由美国国家标准与技术研究所NIST开发的标准参考数据库系列有百余个数据库(
Table 1
表 1
表 1主要材料科学数据库对比
Table 1
| 数据库 | 材料类型 | 特点 | 网址链接 |
|---|---|---|---|
| Materials Project | 包括锂电池、沸石、金属有机框架等材料 | 数据具有较高的准确性 | |
| AFLOW | 主要为金属材料 | 最大的数据库 | |
| OQMD | 主要为钙钛矿材料 | 用户可以下载完整的数据库 | |
| ICSD | 自1913年以来出版的已知的无机晶体结构 | 世界最大的无机晶体结构数据库 | |
| NIST | 几乎涵盖所有材料体系 | 由百余个子库构成,具有严格评估标准 | |
| MatNavi | 包括聚合物、陶瓷、合金、超导材料等材料 | 综合性数据库 | |
| PAULING FILE | 主要为非有机固态材料 | 包括相图、晶体学数据、衍射模式和物理特性 | |
| NOMAD | 几乎涵盖所有材料体系 | 可暂存研究人员的代码和数据,用户可以对比世界各地研究人员的计算结果,从而可以更好地研究材料的结构性能 | |
| Material Connexion | 包含了碳基材料、水泥基材料、陶瓷材料、玻璃材料、金属材料、天然材料、高分子材料、材料工艺等 | 将材料学家与设计师直接联系起来的创新材料咨询服务机构 | |
| Materials Web | 包括二维材料和层状体材料 | 在线存储二维材料电子结构为主的数据库 | |
| Matdat | 包括铝合金、钛合金等600多种材料 | 独特的综合在线平台,提供材料数据库和材料相关服务 | |
| 材料学科领域基础科学数据库 | 主要包括金属材料、无机非金属材料、闪烁材料、碳化硅材料、纳米材料和有机高分子材料 | 国内最全面的材料科学数据库之一 | |
| 国家材料科学数据共享网 | 以钢铁材料、先进合金材料为主,也包含无机非金属材料和高分子材料 | 国内30余家科研单位参与建设,以整合、重构现有的、较为成熟的材料科学数据资源为基础。 | |
| MGED | 以核材料、特种合金、生物医用材料、催化材料和能源材料为主,涉及几乎所有材料体系 | 我国最大的材料基因工程数据库平台,除数据库外,平台还拥有第一原理在线计算引擎、原子势函数库、在线数据挖掘系统等众多功能 |
新窗口打开|下载CSV
1.2 国内材料数据库建设情况
相较于国外一些著名的材料数据库而言,我国在这方面起步较晚。为了更有效地应用和积累科学数据,在1987年,中国科学院牵头正式启动科学数据资源建设。经过多年发展,2019年全面改版的中国科学院数据云门户网站(我国从2001年开始逐步启动了科学数据共享工程。以国家科技部“十一五”基础条件平台项目“材料科学数据共享与服务平台建设”为依托的“国家材料科学数据共享网”(
2016年,由北京科技大学牵头建立的“材料基因工程专用数据库(MGED)”(
除此之外,国内还建成了很多专项数据库,包括国家纳米科学中心建立的纳米研究专业数据库、北京科技大学牵头建立的国家材料环境腐蚀科学数据中心、中国科学院化学研究所承担建设的高分子材料科学数据资源节点等。这些数据库虽然使用范围相对较小,但是在特定的研究领域具有很强的针对性。
2 数据库在材料信息学领域中的应用
2.1 基于材料数据库的机器学习应用案例
如今,在“大数据”时代中,数据是进行材料科学研究的基础,而采用机器学习进行材料研究的时候,更是需要庞大数据量的支持,材料信息数据库可以非常便捷地储存和利用现有的严重碎片化的材料数据[23]。材料数据库作为材料基因工程的核心技术之一,在材料基因工程领域研究中具有不可忽视的作用,同时也为研究中数据的获取提供了便捷。数据库在机器学习研究过程当中具有不同的应用方式。采用数据库中的数据作为训练集来训练机器学习模型,这是数据库在机器学习研究当中最广泛的应用方式。机器学习往往需要大量数据来训练模型,而数据库可以提供大量的数据支持。Tehrani等以Materials Project数据库中的3 246个弹性模量作为训练集训练的模型,通过对晶体结构数据库中118 287个化合物进行预测,得到了由支持向量机回归确定的最大体模量和最大剪切模量的材料,选择典型化合物进行合成测量后发现误差小于10%[24]。不只是理论计算类数据库在机器学习中有着重大应用,实验类的数据库也具有不可忽视的作用。Agrawal等利用NIMS的数据库中的实验数据,通过对特征选择和预测建模在内的不同数据科学技术在钢材疲劳性能中的应用进行探讨,发现一些先进的数据分析技术可以在预测精度上取得显著提高,成功地证明了这种数据挖掘工具可用于按预测钢铁疲劳强度的潜力顺序对成分和工艺参数进行排名,并实际开发了相应的预测模型[25]。Stanev等在超导临界温度的机器学习建模研究中,其数据集来自于NIMS创建和维护的SuperCon数据库,所建立的模型具有较强的预测能力,样本外推准确率约为92%[5]。
除了作为训练集,还可以将数据库中的数据作为测试集来检验训练完成的机器学习模型的性能,采用第一性原理计算的数据训练的机器学习模型可以有效地预测晶体化合物的振动性质[26]。在这个研究中,将振动性质的预测值和NIST数据库中的实验值进行了对比,发现预测结果与实验结果之间的一致性是显著的。这表明该模型可以有效并且快速地预测晶体化合物的振动性质。
机器学习模型也可以对数据库中的材料进行性能预测。Cheon等将通过三维晶体结构的原子位置训练好的机器学习模型应用于Materials Project数据库中的5万余个无机晶体材料后,可以识别出1 173个二维层状材料和487个由弱键一维分子链组成的材料。对于大多数不清楚是二维或一维材料的材料,这个模型识别材料的数量增加了一个数量级[27]。
很多数据库都内置了高通量计算框架或势库,可以间接为机器学习研究提供数据支持。在AFLOW数据库的高通量计算框架下,结合机器学习方法评估了大约400个半导体氧化物和氟化物与立方钙钛矿结构在0、300和1000K下的力学稳定性。找到了92种在高温下力学稳定的化合物,其中36种未在以往的文献中提及[28]。采用MGED数据库中的晶格反演势库结合机器学习,可以在大约50万个候选合金中快速找到具有最高相变熵变的Cu-Al基形状记忆合金,同时得到了部分合金元素对合金相变熵变的影响规律[29]。
数据库可以将碎片化数据整合,并不断积累,为材料研究提供数据支持。在机器学习辅助镍基单晶高温合金晶格错配度预测的研究中[30],其数据集来源于文献摘录。而在利用机器学习算法训练实验数据预测粉末冶金材料烧结密度的研究中[31],数据则来源于实验室积累以及文献收集。这些研究的数据虽然来源于文献以及实验室的收集,但是为了指导未来的合金设计,都被收集在了国家材料科学数据共享网中。该数据库中的所有数据均经过所属单位和文献出处信息的验证,保证了质量的可靠性。
2.2 发展中的高通量计算软件
对于材料数据库来说,通过第一性原理等高性能、高通量的材料计算进行材料理论数据获取, 并结合实验数据和经验数据, 再利用信息化技术对大规模、多源异构的材料数据进行处理分析,由此才能对材料数据库所存储的数据进行充分的挖掘和利用[32]。目前,常用的高通量计算框架包括Materials Project和AFLOW等都具有较高的入门门槛。因此,高通量计算软件的发展也变得刻不容缓。上海鞍面智能科技有限公司的LASP软件利用最新的高效神经网络势能面方法来进行势能面模拟计算,解决了诸如晶体结构预测、相变动力学、反应路径预测等许多复杂的反应路径及材料体系中的问题。高岩涛等人[33]基于第一性原理,利用平面波基组、赝势方法进行电子结构计算、分子动力学模拟,研发了GPU加速计算平台PWMat,其比相同的CPU软件(例如PEtot)的计算速度要快20倍左右,能够在平台上面实现4 000电子以上体系的模拟计算。中国科学院计算机网络信息中心的杨小渝等人研发了高通量材料计算平台MatCloud,以及高通量材料计算数据库MatCloudLib[34]。具有晶体结构建模、图形化界面的流程设计、性质预测、结果分析、数据提取与查询、与计算资源的集成等特色,并且可以完成对计算结果的可视化分析及展示。王宗国等人[35]以Fe-Al和Al-Ti体系为例,采用MatCloud的特色工作流技术快速筛选出了掺杂的稳定结构,相较于遍历筛选,计算量分别减少了66%和84%。而由北京航空航天大学的孙志梅等人开发的计算平台ALKEMIE同样包含计算平台MATTER STUDIO (MS)以及数据库DATAVAULT (DV)两个部分,并且可以全自动地进行建模、运行以及数据分析。其中MS计算平台集成了第一性原理、热力学、经典分子动力学及动态蒙特卡洛模拟等计算引擎,DV数据库当中的材料结构数据超过了18 万条,计算完成的材料性能数据超过1万条。
3 存在的问题与展望
材料数据是材料科学研究的基础,随着“材料基因工程”的提出与实施,材料科学数据呈现出爆炸式增长的态势。对于材料数据库来说,其最主要的作用之一就是积累材料数据,为材料计算和实验提供数据支撑。所以已有研究数据的积累对于材料数据库的建立是十分必要的。但是国内在数据库方面的资源储备量远远不如美国、欧洲、日本等发达国家,我国的材料科学数据库处于建设初期,还无法很好地为材料科学研究者们服务,还无法满足应用的需求。3.1 存在的问题
目前,中国材料信息数据库的建设与应用面临着很大的挑战,主要表现在以下几个方面。(1)数据库的数据量远远不够。相较于一些发达国家而言,中国的材料科学数据库在建设方面起步较晚,数据积累量远远不足,已有的几个国家级数据库中的数据不够丰富,还处于建设初期。在“大数据”时代背景下,相比于其他领域数据量的积累速度,材料领域的数据量积累速度也较慢。
(2)数据质量评价方法与机制亟需完善。失败实验的数据依旧可以为研究工作提供其应有的价值,但是,错误的数据只会阻碍研究的进展。无论国内国外,在数据库建立之初都会将数据的质量列为重中之重。但是,错误的数据难免会存在,这就需要材料科学工作者们严格把关,将错误的数据拒之门外,为机器学习研究减少“噪音”的影响。
(3)明确数据分类。材料根据不同的分类方式有很多类别,材料数据的分类应该根据权威的材料分类体系进行划分。同时,还应该加强年轻学生和科研工作者对材料分类的学习,在进行数据收集的时候就可以避免分类混乱,减少日后数据库的维护成本。
(4)材料数据的获取过程较为复杂。无论是材料计算数据还是实验数据,对工艺参数都显得十分敏感,往往一些工艺参数的微小变化,就可以使得同种材料的数据产生巨大差异。在进行数据收集的时候,还需要严格数据格式,明确数据来源以及数据的生产条件。
(5)数据的共享程度仍有待提高。在现在这个“大数据”时代,已经有很多科研机构和生产单位意识到了数据的重要性。不同的研究单位往往都拥有自己的数据库,但是,这些数据库的共享程度非常低,并且很多都是单一性能或者单一材料体系,无法形成一个系统的综合类材料信息数据库。而且数据格式也具有其自身的特色,这也影响了其共享程度。
(6)数据知识产权问题依旧严峻。这也是造成数据共享程度较低的一个主要原因。“大数据”时代,数据是一笔很大的“财富”,而对这笔“财富”的知识产权属性和保护还没有一个明确的法律界定,很多研究工作者也不愿意无偿贡献数据,尤其是一些生产单位的数据,更是涉及到了其商业机密。
(7)生产数据的收集有很大的困难。一些生产数据会涉及到生产单位的核心技术或者商业机密。但是部分不涉密数据的收集力度依旧不大,很多数据库在这方面存在很大空白。
(8)数据的收集、更新,与数据库的维护需要专业人员监管。现在一些数据库的数据收集、更新与数据库的维护是由青年学生和研究工作者完成的,但是部分学生和研究工作者对材料科学领域的知识理解得不够深刻和系统,在进行数据库建设的时候往往会造成很多失误,影响了数据库中的数据质量和数据库的建设进度,所以需要专业人员进行监管。
3.2 未来的发展方向
材料信息数据库的建设刻不容缓,由于近年来“材料基因工程”的提出与发展,数据库的建设与发展也受到了极大的关注。中国在材料科学研究领域已经积累了大量的数据,但是,这些数据还没有很好地被收集起来,加大材料数据收集和共享力度显得十分重要。而在收集数据的过程当中应该对数据质量严格把关,对数据格式严格要求,对数据知识产权问题加强管理,提高数据库中数据的质量和共享程度。高通量材料计算和高通量制备与表征是“大数据”时代补充材料信息数据库数据量的有效手段,发展高通量计算平台、高通量制备技术和高通量表征技术可以有效缓解数据收集困难的情况,同时也可以降低材料数据收集过程的复杂程度,增加相同工艺参数下材料的数据量。中国现在材料信息数据库的建设属于“边建设边使用”,数据库的建设是一项长期的工作,应该优先建立一些热门材料体系的专题材料数据库,优先解决国家科技重大专项和国防建设急需数据研究的情况。由于数据库建设是材料基因工程领域中重要的一环,同时中国数据库的发展与发达国家相比还有较大差距,因此,中国的材料数据库建设还具有很大的发展空间。4 结束语
本文对国内外材料信息数据库的建设情况和使用情况进行了简单的介绍。总的来说,材料基因组工程领域作为一个新兴的科学研究领域,已经取得了初步成效。材料基因工程作为颠覆性技术,想要实现新材料研发周期缩短一半、研发成本降低一半的目标就离不开数据库的支撑。在过去约10年间的发展中,材料科学数据库的发展情况呈现出“百家争鸣”的态势,众多材料学研究者都认识到了数据的重要性。因此,未来几年中国材料科学数据库在建设和应用上将迎来一个快速发展时期。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1016/j.actamat.2019.03.010URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1038/s41524-018-0138-zURL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1021/jacs.8b02717URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}