 ,1,*, 黄秋兰1, 胡皓1, 田浩来2,3, 汪璐1, 王彦明1, 赵海峰1, 张红梅1, 曾珊11.
,1,*, 黄秋兰1, 胡皓1, 田浩来2,3, 汪璐1, 王彦明1, 赵海峰1, 张红梅1, 曾珊11. 2.
3.
The Design of Science Data Platform for High Energy Photon Source
Qi Fazhi,1,*, Huang Qiulan1, Hu Hao1, Tian Haolai2,3, Wang Lu1, Wang Yanming1, Zhao Haifeng1, Zhang Hongmei1, Zeng Shan11. 2.
3.
通讯作者: *齐法制(E-mail:qfz@ihep.ac.cn)
收稿日期:2020-01-10网络出版日期:2020-04-20
| 基金资助: |
Received:2020-01-10Online:2020-04-20
作者简介 About authors

齐法制,中国科学院高能物理研究所计算中心,博士,研究员,高能同步辐射光源计算与网络通讯系统负责人。主要研究方向为高性能网络、科学数据处理等。
本文中负责整体架构规划与设计。
QI Fazhi, Ph.D, Researcher of Computing Center, Institute of High Energy Physics, is the leader of the HEPS computing and networking group. The research field is high performance network and science data processing.
In this paper, he is responsible for the architecture design of the platform. E-mail:qfz@ihep.ac.cn

黄秋兰,中国科学院高能物理研究所计算中心,博士,副研究员,负责高能同步辐射光源计算系统。主要研究方向为高性能计算技术。
本文中负责科学数据分析系统设计。
Huang Qiulan, Ph.D., Associate Researcher of Computing Center, Institute of High Energy Physics, is in charge of the computing system for HEPS. The research field is high performance computing.
In this paper, she is responsible for the design of computing system.
E-mail: huangql@ihep.ac.cn

胡皓,中国科学院高能物理研究所计算中心,硕士,工程师,高能同步辐射光源科学数据管理系统负责人。主要研究方向为科学数据管理。
本文负责科学数据管理系统设计。
Hu Hao, master, Engineer of Computing Center, Institute of High Energy Physics, is in charge of the scientific data management system. The research field is science data management.
In this paper, she is responsible for the design of scientific data management.
E-mail: huhao@ihep.ac.cn

田浩来,中国科学院高能物理研究所东莞分部,博士,副研究员。主要研究方向为科学软件。
本文中负责科学软件设计。
Tian Haolai, Ph.D., is an Associate Researcher of Dongguan Branch, Institute of High Energy Physics. The research field is science software.
In this paper, He is responsible for the design of scientific software.
E-mail:tianhl@ihep.ac.cn

汪璐,中国科学院高能物理研究所计算中心,博士,副研究员,负责高能同步辐射光源存储系统设计与实施。主要研究方向为存储技术。
本文中负责网络系统设计。
Wang Lu, PH.D., Associate Researcher of Computing Center, Institute of High Energy Physics, is in charge of IHEPS data storage system design and deployment.The research field is storage technology.
In this paper, she is responsible for the design of data storage system.
E-mail: wanglu@ihep.ac.cn

王彦明,中国科学院高能物理研究所计算中心,高级工程师,负责高能同步辐射光源网络系统。主要研究方向为网络技术。
本文负责网络系统设计。
Wang Yanming, Senior Engineer of Computing Center, Institute of High Energy Physics, is in charge of the networking system for HEPS. The research field is network technology.
In this paper, she is responsible for the design of network system.
E-mail: wym@ihep.ac.cn

赵海峰,中国科学院高能物理研究所多学科中心,博士,副研究员,高能同步辐射光源计算与网络通讯系统副负责人。主要研究方向为科学软件。
本文中负责高能同步辐射光源需求分析。
Zhao Haifeng, Ph.D., Associate research fellow of Multi-disciplinary Research Division, Institute of High Energy Physics, is the vice leader of the HEPS computing and networking group. The research field is science software.
In this paper, he is responsible for the requirements of HEPS.
E-mail: zhaohf@ihep.ac.cn

张红梅,中国科学院高能物理研究所计算中心,硕士,副研究员,负责高能同步辐射光源信息及应用软件子系统。主要研究方向为数据库技术。
本文中负责公共服务系统设计。
Zhang Hongmei, master, Associate Researcher of Computing Center, Institute of High Energy Physics, is in charge of HEPS information and application software. The research field is database technology.
In this paper, she is responsible for the design of public service.

曾珊,中国科学院高能物理研究所计算中心,博士,副研究员,负责高能同步辐射光源网络子系统设计与实施。主要研究方向为网络技术。
本文中负责网络系统设计。
Zeng Shan, PH.D., Associate Researcher of Computing Center, Institute of High Energy Physics, is in charge of IHEPS network environment design and deployment. The research field is network technology.
In this paper, she is responsible for the design of network system.
E-mail: zengshan@ihep.ac.cn

摘要
【目的】高能同步辐射光源(HEPS)是我国“十三五”期间优先建设的、为国家的重大战略需求和前沿基础科学研究提供技术支撑平台的国家重大科技基础设施,开展超高空间分辨、时间分辨、能量分辨的高通量同步辐射实验。其一期建设的十五条光束线实验站,预计平均每天产生200TB的原始实验数据,峰值可达每天500TB。这些实验数据需要得到存储、共享,并能够进行准确实时的处理与分析。【方法】科学数据处理平台包括基础设施、科学软件、网络、计算、存储、公共信息服务等系统。【结果】该平台将为HEPS设施、科研人员、工程技术人员以及用户提供包括设数据传输、数据存储、数据分析、数据共享、科研协同等在内的网络、计算、存储等基础设施能力,以及提供科学软件、通用软件、通用信息系统和网络信息安全服务等。
关键词:
Abstract
[Objective] High Energy Photon Source (HEPS) is one of the key scientific and technological infrastructure projects in China. It supplies an important platform for original and innovative research in basic science and engineering to meet the demands of national significant strategy, on which high-throughput synchronous radiation experiments can be carried out, including ultra-high spatial resolution, time resolution and energy resolution X-ray diffraction experiments. It is estimated that over 200TB on average and even 500TB at maximum raw data will be produced every day from the 15 public beamlines and stations in the first construction phase. These experimental data will be permanently stored in a central storage, shared with research members, and can be near real-time processed and analyzed. [Methods] The science data platform consists of multiple systems, including IT infrastructure, scientific software, network, computing unit, storage device and public information service. [Results] It will provide scientific researchers, engineers and users with networks, computing units, storage devices, and other infrastructure capabilities for scientific research collaboration, data transmission, data storage, data analysis, data sharing and services for scientific software, general software, general information system, and information security, etc.
Keywords:
PDF (15707KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
齐法制, 黄秋兰, 胡皓, 田浩来, 汪璐, 王彦明, 赵海峰, 张红梅, 曾珊. 高能同步辐射光源科学数据处理平台规划与设计. 数据与计算发展前沿[J], 2020, 2(2): 40-58 doi:10.11871/jfdc.issn.2096-742X.2020.02.004
Qi Fazhi.
引言
高能同步辐射光源(High Energy Physics Photon Source, HEPS)是我国“十三五”期间优先建设的、为国家的重大战略需求和前沿基础科学研究提供技术支撑平台的国家重大科技基础设施,位于怀柔科学城北部核心区域。建成之后,HEPS将是我国第一台高能量同步辐射光源,也将是世界上亮度最高的第四代同步辐射光源。HEPS建成之后将是一个开放的大型科学实验平台,年均面向全球用户提供实验机时将在5000小时以上,开展X射线衍射、散射、成像和谱学等同步辐射实验。作为第四代同步辐射装置,HEPS产生的X射线能够获得毫电子伏的能量分辨、纳米的空间分辨率和飞秒的时间分辨(来源自《高能同步辐射光源初步设计报告》),相对于现有光源有数量级的提升。同时,随着光学、电子学技术的发展,以及先进的光学仪器、探测器的使用,用户实验过程中的实验数据将呈现爆发性增加,海量的实验原始数据、实验元数据需要高效、安全地进行采集、传输、存储、分析和共享,以满足装置、光束线实验站、用户等各方面的需求,促进依托HEPS的科研实验产出。
HEPS作为我国面向多学科综合研究平台类重大科技基础设施,其运行和科学数据处理效率以及用户体验至关重要。HEPS科学数据处理平台作为设施的重要支撑,需要提供依托HEPS的科学实验过程、实验数据分析与共享、科学成果发布与管理等科研活动过程的自动化。从科学实验用户视角,保障用户实验全过程的信息化、自动化、便利化;而从HEPS设施运行视角,需要实验运行过程的数字化和智能化,保障设施运行高效、可靠和安全;从信息技术视角,支撑HEPS的计算平台需要支持硬件架构异构化、软件功能模块化、功能接口及数据管理标准化。
1 需求分析
HEPS科学数据处理平台需要以服务依托HEPS设施开展科学实验的用户和科学家需求,围绕科学实验数据全生命周期开展支撑服务。依托信息化基础设施,结合信息化业务系统软件,在整个科学实验的前期准备阶段、实验开展阶段以及试验后阶段均提供相应的融合的科研信息化综合服务(图1)。图1
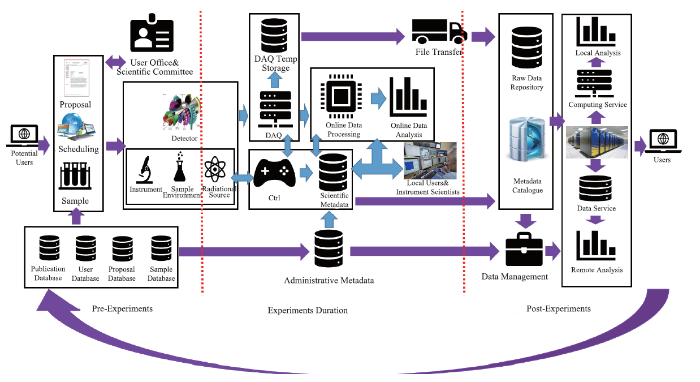 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1HEPS科学实验过程与科学数据处理系统
Fig.1HEPS structure experiment duration and the science data platform of HEPS
HEPS一期工程包括B1-BE共14个线站和1个测试线站,预计平均每天产生200TB的原始实验数据(峰值可达每天500TB)(表1)。但这些线站中不同线站数据产生速率差异较大。其中B7线站的原始数据产生速率约为10GB/s,后续有可能继续增加到30GB/s,预计每天产生的数据量为100TB-500TB。原始数据会通过对探测器像素的分块采集,由多流写入存储系统。B2、BA和BE线站的原始数据产生速率约为500 MB/s~1.5 GB/s,预计每天产生的数据量为在15~40TB之间。其余线站的数据产生速率均小于200MB/s,每天产生的数据量小于4TB。三种线站的数据写入吞吐率之间各相差了一个数量级,B7线站的存储空间需求和数据读写吞吐率需求超过其他线站的总和。
Table 1
表1
表1HEPS各实验站原始数据统计表
Table 1
| 线站编号 | 每天平均产生数据量(Byte/Day) | 每天峰值产生数据量(Byte/Day) |
|---|---|---|
| B1 | 820G | 4T |
| B2 | 14T | 20T |
| B3 | 112.5G | 1.4T |
| B4 | 2T | 2T |
| B5 | 6.8G | 10G |
| B6 | 20G | 50G |
| B7 | 95T | 520T |
| B8 | 10.32G | 30G |
| B9 | 5G | 10G |
| BA | 35T | 35T |
| BB | 91.08G | 165.6G |
| BC | 1T | 1T |
| BD | 275M | 500M |
| BE | 11.2T | 25T |
| 合计 | 159.27T | 608.67T |
新窗口打开|下载CSV
线站产生的科学实验数据均需要得到及时、快速的处理、分析、存储和共享,同时需要提供实验数据的实时分析和快速反馈,以便为实验站用户提供决策以指导和修正实验过程。
从光束线实验站科学家角度出发,为了线站的高效运行,需要足够的数据存储资源并提供满足不同计算需求(CPU,GPU,FPGA等)的在线分析环境。部分实验站产生的实验数据产生速率较大(如B7线站未来采用高分辨面探测器,数据产生速率可达50GB/s),需要具有融合数据、计算、网络、软件环境等多种功能并且优异性能的科学数据处理平台作为支撑,实现科学实验过程和科学成果获取所需实验数据的及时处理、反馈和利用。从实验用户角度来说,希望能在短时间内完成实验数据的分析、获得理想的实验成果并获取科研成果,因此需要HEPS能够提供快捷、便利、易用和友好的支撑环境,方便用户跟踪、访问、下载实验数据和成果,同时保证实验数据的长期保存、安全和完整。部分实验数据由于特别庞大(如衍射断层扫描实验,一次实验可能产生高达50TB的数据),一方面需要优质的网络性能实现实验数据的快速传输,另一方面希望HEPS能够提供强大的计算平台和软件环境进行实验数据分析。
从整个HEPS装置来说,对平均每天200TB、文件大小不一(KB~GB)、格式不一(ASCII、图像、HDF5)、来源不一(不同实验技术、光束线、前端等)的实验数据进行统一化管理是非常重要的工作。涉及科学数据库(实验数据库、元数据库、仪器设备数据库等)、数据管理规范、数据标准化、数据接口等一系列工作,为科学数据利用和共享提供支撑和保障。
此外,HEPS总体规划中,未来将有超过90个光束线站运行,届时每天产生实验数据将会有更大幅度的提升,这对科学数据存储、分析、管理和共享带来更大的压力,其科学数据处理平台在规划时需要考虑架构、技术上的扩展性。
2 平台总体规划与设计
HEPS科学数据处理平台将为HEPS装置、束线科学家、工程技术人员以及用户提供包括数据传输、数据存储、数据分析、数据共享、科研协同等在内的网络、计算、存储等基础设施能力,以及提供科学软件、通用软件、通用信息系统和网络信息安全服务等。同时,在平台整体规划和建设时,统筹和设计同数据相关的多个系统之间的标准化和规划化接口。根据科学数据处理平台系统功能,具体系统包括支撑平台运行的基础设施、网络系统、存储系统、计算系统、公共信息系统、网络安全系统、智能化运维保障系统以及服务于科学数据全生命周期的的软件系统、数据管理系统(图2)。
图2
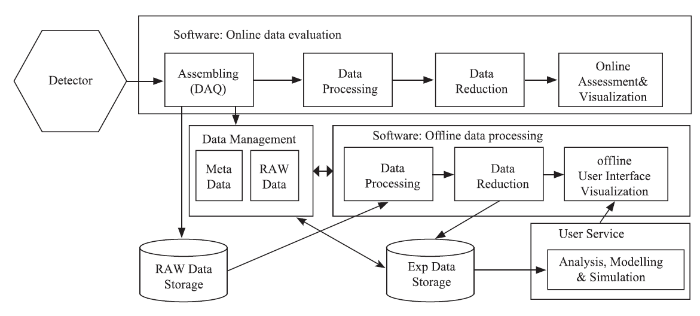 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2科学数据流程
Fig.2Scientific dataflow
2.1 科学软件系统
科学数据处理软件系统是HEPS科学数据处理平台的重要组成部分,其任务是利用平台提供的数据存储和访问服务、计算资源管理和网络环境等服务,把实验采集的测量数据处理成为具有明确物理意义的科学数据,并通过对科学数据的分析获得对实验对象的科学认识。由于光源用户的多样性,设备仪器和方法学的丰富性,导致HEPS科学数据处理软件是以解决和支持特定科学应用为驱动的开发。在这种领域驱动设计模式(Domain Driven Design, DDD)的要求下,开发首先需要对特定业务知识进行梳理,形成领域模型(Domain Model),并进一步驱动科学数据处理软件的设计和实现。HEPS数据处理软件的设计目标就是开发能支持多种领域模型的软件平台,并保证各领域模型、科学数据处理软件架构以及HEPS科学数据处理平台的迭代升级互不影响。2.1.1 科学数据处理软件框架
HEPS数据处理软件有两个典型的运行环境:(1)在线实时数据处理环境,既在实验执行的同时,利用有限的在线计算资源,对采集数据进行实时处理,其结果作为线站科学家和用户判断实验进展情况,并对随后的实验做出动态调整的依据;(2)离线数据处理环境,即在实验结束后,利用用户或计算中心的计算资源,对采集的数据进行细致、全面和深入的处理分析,其结果作为用户科学发现的实验证据。由于计算技术和实验方法学的发展,原来很多需要离线处理的数据现在已经可以实时处理。同时现代实验技术和方法,如材料基因组等研究计划提出了高通量实验方法,成像线站的计算机断层扫描方法,都能在短时间内获得大量的测量数据,导致离线数据处理也需要借鉴在线数据处理系统在自动化和集成计算方面的经验。因此我们在设计HEPS科学数据处理软件系统时,希望在线和离线数据处理系统能最大程度的共享计算组件。这种在线离线软件融合的设计,不但能降低开发和维护的工作量,也有利于向用户提供统一的操作体验,降低学习曲线。
为了实现这一目标,科学数据处理软件系统划分为四个部分:(1)软件框架;(2)可视化和数据分析平台;(3)基于微服务的分布式中间件;(4)第三方软件库和外部程序集成。由于光源的运行长达数十年,期间仪器技术、实验方法和计算硬件都会发生巨大的变化,因此软件系统整体的设计必须考虑计算组件之间的低耦和,以及计算平台的可拓展性,故在设计中我们遵循如下原则:(1)面向接口的系统设计,接口是计算组件之间交互的协议,通过定义接口而不是绑定实现来保证计算系统的灵活性;(2)插件式的开发模式,插件是遵循接口定义完成特定功能的计算组件,光源软件平台通过插件开发来拓展系统的功能。
科学数据处理软件框架基于SNiPER[1](图3)开发,并提供HEPS科学计算所需的通用功能组件。SNiPER实现了以数据为中心面向接口的软件架构,由C++开发并提供Python接口,兼顾计算的高效性和软件架构的灵活性,已经应用在江门中微子实验、中国散裂中子源[2]和高海拔宇宙线观测站的数据处理系统中。该框架最重要的两个组件是瞬态数据对象和算法对象。瞬态数据对象,是软件运行过程中内存中保存的数据对象,呈树型结构,能通过路径名被框架其他组件直接访问。由于现在大量科学计算程序都是基于Python科学计算库NumPy开发,且NumPy的基础数据对象ndarray由C实现并能方便的被C++调用,HEPS的基本瞬态数据对象也采用ndarray数据对象,用户可以在此基础上拓展定义自己的数据对象。算法对象是执行数据处理的具体计算组件,领域模型被包装在具体算法中,由Python或者C++实现,其输入输出一般为特定瞬态数据对象,并且实现框架定义的算法接口,这样框架就能通过接口调用算法,实现算法和框架之间调用的解耦合。HEPS科学数据处理软件接受两种输入输出数据:一种是文件,软件通过指定路径读取或写入文件,文件有明确的大小和边界(即文件头和文件结束标记);另一种是数据流(Data Stream),软件通过指定端口获取数据,数据流没有明确的边界。软件需要支持HDF5格式的文件读写,以及线站要求的其他格式数据,因此软件的输入输出模块应该具有插件架构,可以灵活的更换数据源并转换为指定瞬态数据对象,实现外部数据源和瞬态数据对象的解耦合。软件框架对外提供C++和Python的应用程序接口(Application Programming Interface, API),其他应用程序可以通过API访问软件的所有功能。
图3
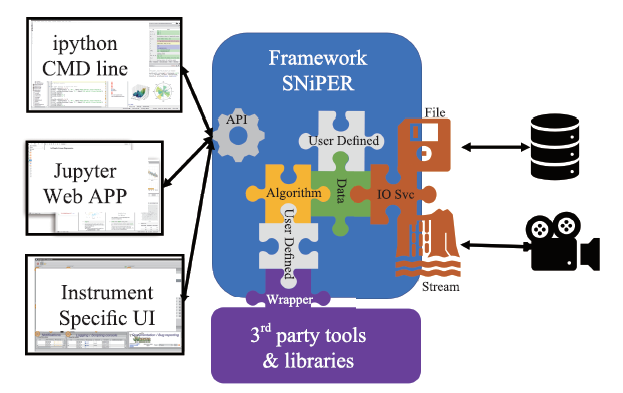 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3SNiPER软件框架
Fig.3SNiPER frame
2.1.2 可视化与数据分析
可视化和数据分析软件是搭建在软件框架上的一个重要应用(图4)。由于Python在数据处理领域的广泛应用,可视化和数据分析软件由Python实现,并通过框架提供的Python API访问其功能。可视化和数据分析软件提供三种用户界面,分别为基于ipython的脚本窗口,基于matplotlib和PyQt的图形化用户界面(Graphical User Interfaces, GUI),以及基于Jupyter的Web界面。对于通用GUI界面,我们将开发多种常用图形化组件(Widget),包括项目导航(The Project Explorer)、文件导航(File Browsing)、 瞬态数据浏览(Data Browsing)、数据视图(Data View)、绘图界面(Dataset Plot)、算法导航(Algorithm Browsing)、运行日志(Log)和终端(Console)等,并通过Qt提供通过的QML(Qt Modeling Language)用户界面标记语言定义这些Widgets的组合和排列,为每条线站和应用提供自己独特的用户界面。传统交互式数据处理软件遵从REPL(Read-Evaluate-Print Loop, 读入-求值-输出循环)编程模型,在此模型中,所有操作都在同一单进程/单线程中循环执行,由于光源数据量往往较大,同时数据分析算法的运行时间往往较长,采用这种编程模型会导致程序暂时失去响应,因此可视化和数据分析软件的前端用户界面和执行模块分属不同进程,并通过ZeroMQ消息队列和Jupyter Message消息标准进行通讯。这种编程模式也有很好的拓展性,适应从单机程序到分布式并行程序的迁移。
图4
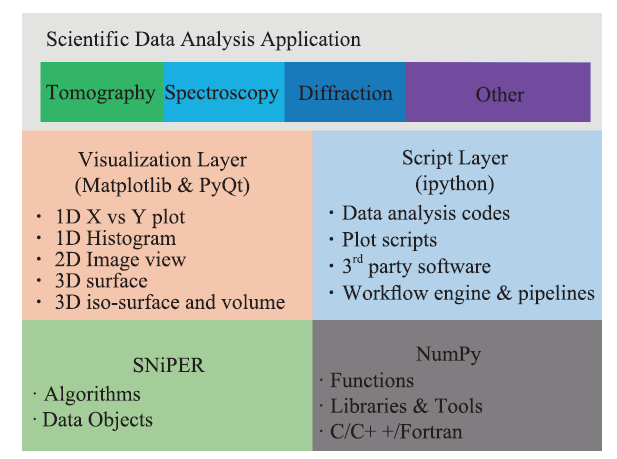 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4可视化和数据分析软件
Fig.4Software for visualization and analysis
2.1.3 分布式中间件
如上所述,HEPS数据处理软件需要运行在不同的计算环境中,包括在线实时处理环境、离线高性能计算环境和用户计算机系统,然而我们不希望线站科学家的注意力放在配置和管理计算资源,同时实验所需计算资源能根据需求实现自动的伸缩。微服务架构(图5)是解决这一问题的较好方案,其中微服务是一个有独立功能的可访问应用,通常以容器的形式部署在科学数据分析系统提供的异构分布式计算环境中;微服务网关(micro service gateway)是所有微服务的入口和反向代理,调用申请首先到达网关,网关根据服务路由将请求重定向到特定的微服务;工作流引擎(workflow engine)根据用户提交的业务申请和初始参数,生成微服务调用序列,即工作流(work flow)或管道(pipeline),数据从数据源输入工作流,经过一系列微服务的调用,最终获得结果输出。一个基于微服务的分布式中间件,可以通过微服务网关屏蔽分布式环境的实现细节,在不修改程序代码的同时,能满足从用户单台计算机到计算集群等不同计算环境的适配。同时领域模型被控制在微服务的边界内部,不同微服务通过轻量级的通讯协议交互,可以较好地实现计算组件的高内聚和低耦合。我们采用消息队列(Message Queue, MQ)实现微服务之间的通讯,由于科学数据处理软件需要传递大量数据,我们区别两种类型的消息,一种是含控制指令的远程过程调用(RPC)消息,另外一种是数据对象序列化后生成的数据流。前者数据量较小但是要求响应及时,采用符合Jupyter Message消息标准的JSON数据对象表达;后者着重吞吐量,由数据发送方和接收方共同定义数据格式,并自行实现瞬态数据对象的序列化与反序列化。
图5
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5基于微服务的工作流实现
Fig.5Workflow based on microservice
2.1.4 面向用户的软件集成
利用X射线研究物质结构的科学探索过程已经持续了一个多世纪,在此期间众多科研团体开发了大量的数据处理代码,形成了功能繁多的第三方软件和外部程序。HEPS的软件系统虽然准备在最新的计算体系上开发先进的软件架构,但是继承前人积累的遗留代码依然是一项重要的工作。由前面的论述可知,第三方软件和外部程序可以通过两种方式集成进入HEPS数据处理软件系统:一种是通过算法包装外部程序,实现框架定义的算法接口,并在算法内部实现框架标准数据对象和外部程序数据对象的转换;另外一种方式是通过微服务包装外部程序。前一种方法,外部程序能通过算法直接调用框架的所有功能,集成度较好,数据对象直接通过框架的瞬态数据对象机制访问和管理,效率较高,但是这种集成方式要求深入理解框架和外部程序的内部实现,工作量较大,因此是科学计算组件集成较好的选择;第二种方式,外部程序包装成微服务,独立部署运行,通过消息队列与其他组件交互,虽然集成度不及前者,而且需要分布式环境的支持,但是实现相对容易,是其他系统接入科学数据处理软件系统较好的选择。
基于面向科学用户提供便捷化、易用性服务的需求,将使用软件框架、设备控制系统、数据获取系统以及数据处理软件系统的功能和用户交互功能运行于在线数据处理环境中,使得HEPS数据处理软件通过数据获取系统访问实时采集的测量数据,经过快速数据处理后,获得快视结果,并返回给控制系统,作为下一步实验计划的依据,构成数据获取-数据分析-控制反馈的闭环过程。因此有必要开发一个集成环境,作为实验用户访问数据获取系统、在线数据处理系统和控制系统的统一界面。
集成环境和软件系统的交互可以分为两种层次。第一层次是可视化和数据分析软件作为集成环境的子系统,提供通用分析界面和功能,如文件导航、瞬态数据浏览、数据视图、绘图界面、算法导航和ipython终端。由于可视化和数据分析软件采用的前端用户接口和执行模块分属不同进程,集成环境可以利用Qt运行环境并通过QML加载所需Widget的方式配置分析界面组件,实现各线站定制的在线快视分析界面,执行模块在后台运行数据分析算法,并通过消息队列进行交互。第二层次是集成环境作为客户端,通过调用HEPS数据处理软件系统开放的API,向在线数据处理系统发出访问请求,以获得特定微服务响应,或者向工作流引擎发出业务申请,以启动所需数据处理的工作流。
2.2 科学数据管理
科学数据管理系统需要实现对HEPS实验产生的所有科学数据在数据获取、传输、存储、分析和数据成果发布各个阶段进行全生命周期的管理和跟踪。需要实现的目标包括:制定科学数据管理标准与规范;研究和设计科学元数据目录管理架构,实现对科学数据全生命周期的管理,保证科学数据的完整性和可追溯性;实现在实验不同阶段从控制系统、用户服务系统、数据分析系统获取数据和元数据;提供标准接口,满足其他各系统之间的协作与通讯;提供高效便捷的用户数据服务,实现数据管理制度和规范下对数据的可查看、可下载、可共享和可利用。2.2.1 科学数据管理总体架构
科学数据管理系统数据流图(图6)描述了整个实验过程中所有数据流向过程。具体包括:从线站接收的原始数据和科学元数据以文件的形式保存到数据中心存储。另一方面,原始数据流经过在线分析系统得到的分析结果数据同样也保存到数据中心存储。同时,元数据提取器从用户服务系统获取提案、用户、样本相关信息,从实验参数文件获取部分关键实验元数据,并存储到元数据目录数据库,用于实验数据的查找、搜索和共享。如果从探测器获取的原始数据文件不是标准HDF5格式,需要对数据进行格式转换和数据封装(包括原始数据和所有元数据),形成标准HDF5文件,注册元数据并长期保存。用户通过数据服务portal可以对数据进行搜索、查看、下载和离线分析,同时,被经过离线计算分析得到的结果数据同样会被存放到中心存储文件系统中长期保存。
图6
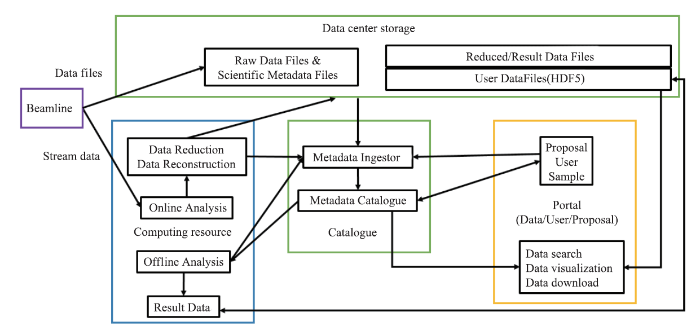 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6科学数据管理系统数据流图
Fig.6The data flow for HEPS data management system
2.2.2 科学数据管理策略[3]
为进一步加强和规范科学数据管理,保障科学数据安全,提高开放共享水平,国务院办公厅已发布《科学数据管理办法》[4]。科学数据开放共享已经成为国际科研领域的必然发展趋势。但是,目前仍然缺乏相关国家法律法规对用户类设施科学数据的所有权和使用权做清晰的解释和说明。因此,制定数据策略对HEPS科学数据管理执行以及未来科学数据开放共享具有重大意义。该科学数据策略是整个数据管理过程的制度和规范,对HEPS的科学数据管理必须遵从该数据策略的各项规定。
HEPS科学数据策略包括对设施获取的所有数据以及元数据的所有权、管理、存储、访问四个方面作出的约束和说明。HEPS会对产生的数据进行长期保存,其中包括提供至少三个月磁盘存储和永久磁带存储;对原始数据、结果数据、刻度数据、用户数据长期存储,对缩减数据、过程数据短期保存;每个数据集都分配唯一永久标识(PID),任何与该数据集相关的发表文章必须引用数据集的PID;制定数据封闭期,例如三年,封闭期之内,只有授权用户拥有数据所有权,封闭期过后,数据可以提供给其他合法用户访问和下载。
2.2.3元数据分类
2.2.3.1元数据定义和分类
管理元数据(administrative metadata):管理元数据包括与数据相关的提案信息、用户信息、实验类型、线站信息等,来自提案系统和用户系统。
科学元数据(scientific metadata):包括与数据相关的样本信息和实验环境参数等相关信息,从控制系统获取。由于科学元数据会被用于数据分析和数据目录索引,它需要进行两部分存储:与原始文件一起进行数据封装标准化,生成HDF5文件,同时需要被存储到元数据库。
其他元数据(other metadata):其他元数据主要来自传输或者分析应用,包括该数据传输中完整性校验信息(checksum)、分析软件名称版本信息、数据更新时间等。
2.2.3.2元数据管理框架
SciCat[5,6]是由PSI、ESS和MaxIV合作研发的开源的元数据目录管理框架,通过微服务的架构对科学数据进行全生命周期的管理。SciCat架构(图7)采用了弹性框架,具有可扩展性,不受数据类型和数据量变化的限制;使用json文件定义元数据模型,并且可由元数据模型直接生成RESTful API,供其他系统调用;后端采用非关系型文档数据库MongoDB,支持高并发元数据读写,同时数据结构灵活,能符合各线站元数据不一致的需求;支持可视化编程的数据流处理,高效地匹配每个线站前期元数据处理和整理的流程;同时该架构集成基于Web的可视化界面,支持元数据检索功能,简化后期Web界面开发过程。
图7
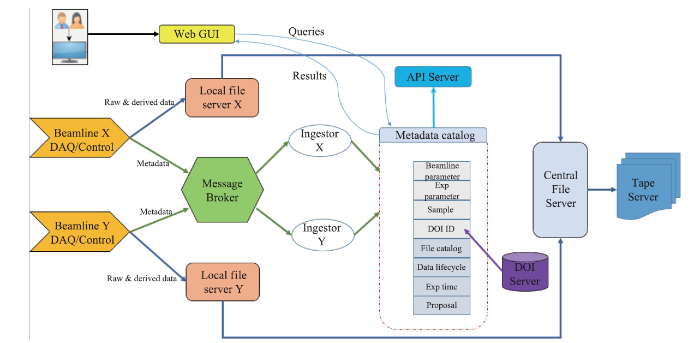 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7SciCat元数据管理架构
Fig.7SciCat meta data management structure
该架构采用消息队列的方式接收从线站收集数据集的相关元数据,元数据提取器从消息队列消费元数据,并将元数据通过元数据管理API存放至元数据目录数据库中。用户通过提供的数据web服务界面在元数据目录数据库中搜索查找数据集。同时,用户可以将数据发送至现有计算资源或超算平台进行分析和处理,数据相关分析和处理作业信息被保存到元数据库,实现对数据处理过程的跟踪。数据分析的结果被保存到数据中心存储,相关分析结果元数据和数据发布信息最终被保存至元数据库。该架构可实现对数据集从提案、数据获取、数据存储、数据分析到数据发布整个过程进行全生命周期的记录和跟踪。
2.2.4 关键技术
2.2.4.1 消息队列
消息队列是一种应用间的异步协作机制,消息发送后可以立即返回,由消息系统来确保消息的可靠传递,具有以下特性。
(1) 可靠性:使用持久化、传输确认、发布确认等机制来保证可靠性;
(2) 消息集群:提供消息集群服务,形成一个逻辑 Broker;
(3) 高可用:队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用;
(4) 多种协议:支持多种消息队列协议,比如 STOMP、MQTT 等;
(5) 易用性:提供易用的用户界面,使得用户可以监控和管理消息 Broker ;
(6) 跟踪机制:提供消息跟踪机制,使用者可以跟踪消息异常情况。
拟采用消息队列技术来实现高并发元数据接收和存储,解决高速元数据产生时本地IO与数据库写入速度不匹配的问题,同时也可以使用传输确认、发布确认等机制来保证传输的可靠性。
2.2.4.2 非关系型数据库
非关系型数据库MongoDB是一个基于分布式文件存储的数据库。旨在为Web应用提供可扩展的高性能数据存储解决方案。MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富、最像关系数据库的。它支持的数据结构是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。其特点是高性能、易部署、易使用。
(1) 面向集合存储、易存储对象类型数据;
(2) 使用高效的二进制数据存储,包括大型对象(如图片、视频等);
(3) 支持完全索引,包含内部对象;
(4) 支持RUBY、PYTHON、JAVA、C++、PHP等多种语言;
(5) 文件存储格式为BSON;
(6) 支持复制和故障恢复。
采用MongoDB作为科学元数据存储数据库,面向集合的存储特性能满足元数据模型中分层数据关系的存储;对完全索引的支持,有利于对数据进行快速高效地检索;提供REST API接口,为各个应用提供标准的无状态接口,使用http方式对数据库进行CRUD操作。
2.2.4.3 数据格式标准化
HDF5[7](Hierarchical Data Format 5)是一种分层数据格式,由数据格式规范和支持库实现组成,是用于存储和分发科学数据的一种自我描述、多对象文件格式。HDF5可以表示出科学数据存储和分布的许多必要条件。
HDF5数据格式具有以下特性:通用性,许多数据类型都可以被嵌入在一个HDF5文件里;灵活性,允许相关数据对象组合在一起,放到一个分层结构中,向数据对象添加描述和标签;跨平台性,它是一个与平台无关的文件格式,无需任何转换就可以在不同平台上使用。HDF5文件以分层结构组织,其中包含两个主要结构:组和数据集。分组结构包含零个或多个组或数据集的实例;数据集是数据元素的多维数组。
采用HDF5作为HEPS数据统一的格式标准,组合相应数据对象放到分层结构中,并为数据对象添加描述和标签,实现对元数据模型中多层数据关联结构描述。
2.3 科学数据存储系统
存储系统为各线站提供快速存储和长期保存服务,为用户和离线分析作业提供数据共享和文件系统访问接口,为远程用户提供跨域数据共享服务。主要的应用场景包括:线站数据流写入、在线快视、离线数据分析、长期保存以及跨域数据共享等。系统包括线站存储和中心存储两个部分,除数据接口、访问性能、可靠性和性价比等与其它科学计算设施共性需求外,光源存储还需要考虑到不同线站对存储需求的多样性。2.3.1 总体架构设计
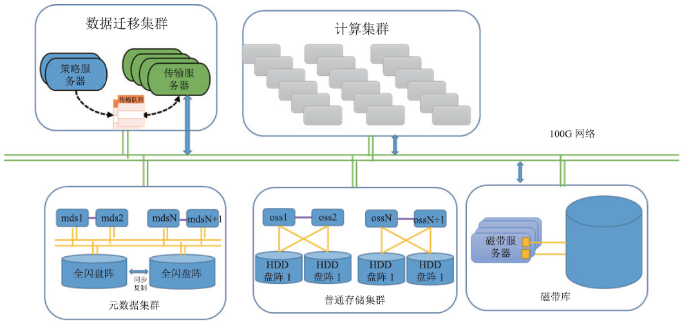
光源存储系统(图8)包括线站存储、中心磁盘存储和磁带存储三个层级。每个线站有独立的线站存储,一般只存储一次实验(持续时间1-3天)的数据。实验进行过程中,用户通过快视服务器检查采集到线站存储的数据。快视服务器可以读在线存储,可以读采集服务器转发的数据流。如果数据有问题,则需要调整探测器和样本,重新采集。快视服务器产生的数据的写入吞吐率,远小于探测器。如果数据没有问题,则通过在线数据处理服务器将数据异步拷贝到中心存储并注册到数据管理系统。中心磁盘存储系统是各实验共享的分布式文件系统,用户只能对中心磁盘存储上的数据进行大规模重建、分析、拷贝和远程访问。原始数据在中心磁盘存储中存放的期限是从实验结束开始计算的2-6个月,超过期限的数据会被保存到磁带存储中。中心磁盘存储中产生的衍生数据,会被定期删除,不会拷贝到磁带存储中。
图8
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8存储系统架构
Fig.8Structure of the storage system
2.3.2 详细设计
2.3.2.1线站存储
计划通过入门级NAS(Network Attached Storage, 网络附加存储)、企业级NAS和高性能NAS存储设备来满足各线站的数据访问需求。NAS设备集成了多种数据访问协议,Windows客户端可以通过SMB协议,Linux客户端可以通过NFS协议来访问数据。访问接口与本地文件系统没有区别,多个客户端可以共享线站存储的名字空间,实现一定级别的数据同步功能。对于B7线站,基于全闪盘阵的高性能NAS能够实现从10GB/s到TB/s。每秒的访问吞吐率线性扩展和从数百TB到数十PB的容量扩展,可以满足其存储性能挑战。以上三种NAS产品均可配置图形化的性能监控、存储管理界面以及故障告警,保证了系统的可靠性和易维护性。
2.3.2.2中心磁盘存储
中心磁盘存储主要基于Lustre分布式文件系统搭建,通过元数据和数据分离的架构实现读写吞吐率的线性可扩展性。 Lustre是高性能计算领域使用最广泛的分布式文件系统,在全球Top 100超级计算机中,已经存在若干超过HEPS需求的部署实例。如图8,所示元数据服务器集群包括多台Lustre元数据服务器,通过SAN存储交换网络连接一个高性能全闪存存储阵列,每个服务器连接的元数据设备是该阵列的一个LUN。同时,系统还设计了一个低速盘阵来异步地拷贝全闪盘阵中的数据,进一步保证元数据的可靠性。数据服务器通过FC通路主连一个磁盘阵列作为数据存储设备。每个磁盘阵列配置两个以上的控制器以及RAID 6以上的数据冗余和快速数据重建能力。所有服务器均通过两两之间的Active-Active热备实现服务高可用性,通过双端口绑定、双链路冗余等技术避免单点失效。所有服务器通过高带宽、低延时的百Gb高速网络向计算集群提供服务。
2.3.2.3 中心磁带存储
中心磁带存储将采用CERN CASTOR 磁带管理系统,该系统已经有数百PB的部署实例,可以驱动市场上主流的磁带格式和磁带库硬件。系统包括请求队列、磁带驱动器、磁带服务器和名字服务器等组件。磁带服务器可以通过FC通道驱动磁带库的机械手,并且通过HBA卡连接磁带驱动器读写数据。通过CASTOR提供的数据访问接口和API,用户可以顺序的读写磁带中的数据文件。如图8所示,数据在磁盘和磁带之间的透明移动由专门的数据拷贝节点实现,这些节点同时安装了Lustre和CASTOR的客户端。用户在Lustre客户端发起了归档和读出请求后,Lustre会将这些请求放在自己的分级存储队列中,数据拷贝节点从分级存储队列中主动拉取请求进行数据读写。用户在Lustre客户端发出的分级存储请求会一直阻塞到CASTOR中的读写顺利完成。
2.3.3 关键技术
2.3.3.1 分布式文件系统
考虑到线站存储将采用软硬一体化的商业NAS产品,存储系统的核心技术主要体现在中心存储的设计上。中心存储计划采用在高性能计算领域应用最广泛的分布式文件系统作为技术方案。其中仍需要解决的问题包括智能运维、分级存储以及性价比等。根据高能所计算中心长达10余年的Lustre建设和运维经验,实现智能运维首先需要解决细粒度的性能监控问题,有了监控数据以后可以用基于机器学习的算法和模型实现故障检测、异常作业发现、访问热度预测以及参数调优等自动化运维任务。为了实现对磁盘数据和磁带数据的透明访问,还需开发针对CASTOR磁带存储系统的Lustre插件。Lustre是还在发展中的文件系统,目前还在开发中的文件副本、纠删码数据冗余和元数据访问性能优化等功能,有望在HEPS存储系统实施时完成开发,使用这些功能和更为廉价的存储盘阵,可以在保证数据可靠性的同时,进一步提高存储系统的性价比。
2.3.3.2 数据压缩技术
对存储空间和访问带宽需求最多的线站是成像实验线站。成像实验通过对样品进行不同角度的投影成像和对成像数据的断层扫描,实现对样本内部构造的详细分析。一组成像数据可以看成是一套连续的图片帧,每帧图片为16比特位的灰度图片。如果能够利用相邻两帧数据的相似性以及样本运动轨迹的先验知识,有望通过图片帧的预测、残差计算和数据压缩等方法,实现对数据容量大幅度的无损压缩。数据压缩的比例,将决定存储系统的造价和访问带宽开销。同时,还需要可以通过GPU、FPGA等硬件加速数据压缩和解压过程,保证算法的可实时性。
2.4 科学数据分析系统
科学数据分析系统旨在满足高能光源实验的科学研究需求,通过建造HEPS实验快速在线数据处理集群和离线计算集群,用来支持HEPS在线计算和大规模离线数据处理。图9显示了HEPS实验数据产生、处理、存储、传输等过程中的数据流,科学数据分析系统的功能主要体现在图9中的红色圆圈部分,包括在线数据处理服务和离线数据集群两部分。该系统将提供一个混合CPU、GPU等多类型计算资源的大规模异构计算系统。根据HEPS不同光束线站实验及不同用户的使用模式,设计相应的计算服务解决方案,保证科学计算任务的高效执行。图9
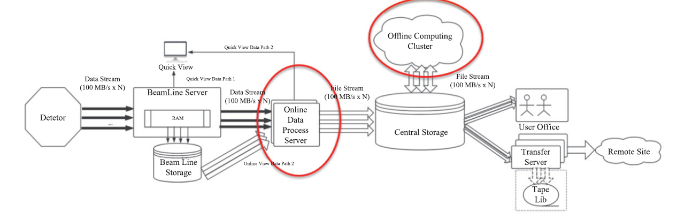 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图9HEPS实验数据流
Fig.9Data flow for HEPS experiments
2.4.1 系统设计及关键技术
高能光源的实验机时非常宝贵,用户希望能在给定的实验时间内尽可能快地完成多个实验,取得准确、满意的实验结果,这就要求HEPS能够提供高性能的在线快速数据处理,让用户能够判断已完成的实验是否符合预期,为下一个实验的参数调整提供判断依据。这对提高实验的效率至关重要。实时快速的在线数据分析系统由CPU,GPU等异构资源组成,根据实验的数据量和计算复杂度合理分配计算资源,满足不同实验站的需求。需要提供面向用户定制的个人高性能数据分析服务,实时反馈数据处理结果,让用户能够方便、快捷地获得初步的实验结果。实验结束后,部分光束线站还需要大规模的计算资源用于离线数据分析,进一步对实验数据进行分析以获得更好的成果。因此,科学数据分析系统包括在线计算服务和离线计算服务。系统架构如图10所示。
图10
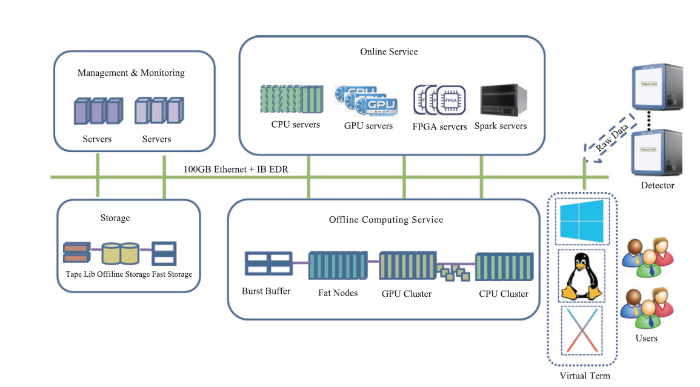 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图10HEPS科学数据分析系统架构
Fig.10The struct of data analysis system
为满足在线计算服务和离线计算服务,提供四种计算服务模式,包括基于CPU的流式计算、基于Web的数据处理、云主机分析和批作业处理。
(1)基于CPU的流式计算
从探测器出来的数据流直接进入在线计算系统提供的基于CPU的流式计算集群(图11),数据处理后进行快速展示。涉及的关键技术是基于内存计算的Spark streaming计算和消息队列的接收和分发。这种计算模式适用于数据量大且数据处理实时性要求较高的光束线站。
图11
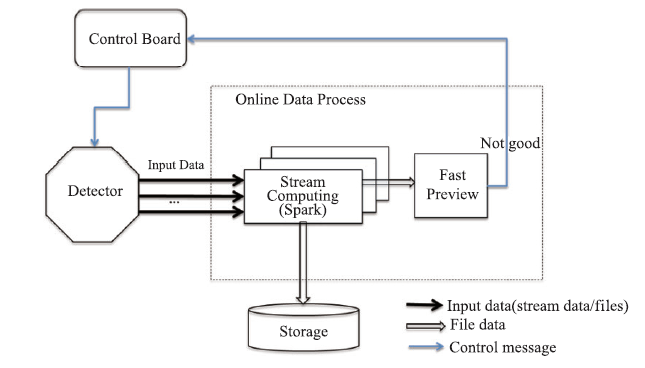 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图11流式计算模式
Fig.11Streaming computing mode
(2)基于Web的数据处理
这种计算模式前端为用户提供基于Web的数据处理接口,底层计算资源由GPU、CPU、FPGA等异构资源组成的高性能在线数据处理服务。该计算模式由用户前端层、中间软件层和底层资源管理层构成。用户前端层基于Jupyter Notebook,实现多用户访问,为不同光束线站开发数据分析Jupyter notebook,提供固定的数据分析流程。中间件软件基于Jupyter Hub,提供用户的认证和授权、计算资源的申请,以及Jupyter Notebook的管理。底层资源管理层基于Kubernetes,并根据中间件软件的需求,提供动态的计算资源创建、管理和调度。该系统支持一键式数据分析并可视化,用户可灵活定制分析步骤,适用于中小型线站、轻量级的数据处理。
(3)云主机分析
利用云软件管理和调度物理计算资源。针对不同光束线站的不同数据分析需求创建不同的数据处理环境,并集成HEPS实验数据访问。利用CVMFS仓库管理分析环境和云分析软件更新和维护。该系统支持按需请求计算资源、高安全性隔离、计算密集型分析和较复杂的数据可视化分析。底层计算资源由CPU和GPU等异构资源组成,并对用户透明。
图12
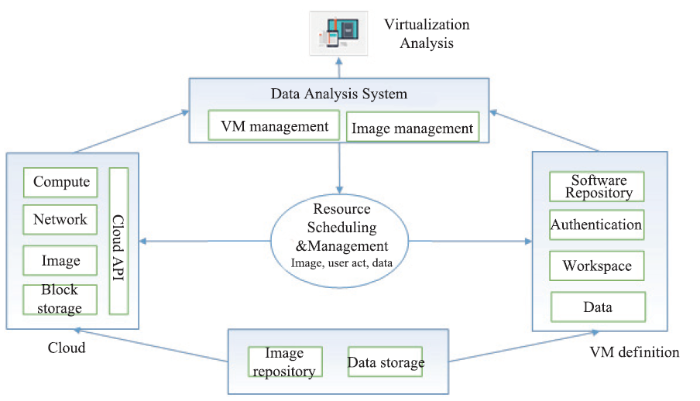 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图12云主机分析模式
Fig.12Cloud computing mode
(4)批作业处理
提供提交批作业处理的接口,方便用户进行大规模的离线数据处理分析。计算资源有CPU和GPU组成的高性能集群,由SLURM管理和调度。
2.4.2 计算资源统一管理
科学数据分析系统将整合所有可用计算资源,并对资源统一管理和分配(图13),快速调度和分配在线和离线计算的资源。根据HEPS用户的提案信息,得知实验所需的计算资源情况、数据处理环境(包括操作系统、软件、数据等)生成相应的计算集群/云主机,并匹配CPU/GPU/FPGA等硬件资源。整个资源的调度和分配及底层硬件细节对用户透明,用户无需花时间部署数据处理环境,从而大大提高了科学家们的工作效率。
图13
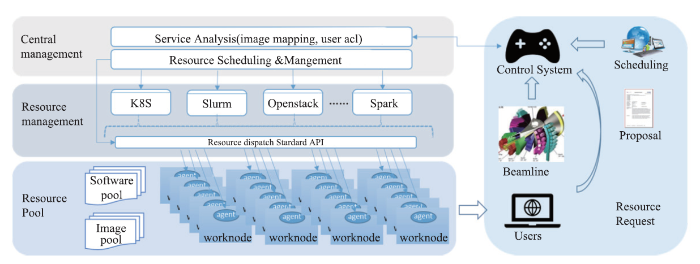 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图13资源的统一管理和调度
Fig.13Scheduler for computing resources
系统将基于虚拟化技术开发上层调度管理软件,通过虚拟机和容器技术,降低应用与基础设施的耦合程度,提供可以弹性伸缩的计算服务,满足不同实验和应用需求,并使资源利用率最大化。
2.5 网络系统
网络系统提供支撑光源实验数据存储和分析、科研协同等需要的网络通讯服务,为实验数据的国际、国内共享提供高效的国际国内互联网环境,同时为实验数据获取、光源线站实验控制、加速器控制网络提供技术支撑。HEPS网络系统按照功能划分为通用网络、数据中心网络、业务系统网络(包括数据获取网络、加速器控制网络、线站控制网络)、管理网络和用于支持与国际、国内合作单位实现高效多流数据传输的广域网络(图14)。
图14
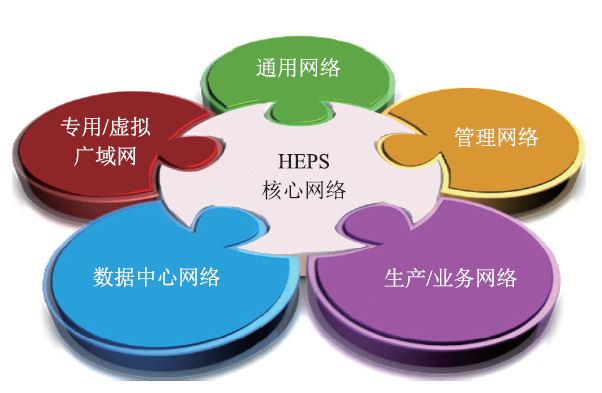 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图14网络总体逻辑架构图
Fig.14Overview of HEPS network
通用网络主要提供HEPS办公区有线和无线网络连接,并进行相关的网络管理系统建设:接入控制系统、计费系统、监控系统等。
数据中心网络用于支撑HEPS计算资源和存储系统之间、计算资源之间以及存储系统内部的网络连接。
生产网络也称为业务网络,支撑HEPS各实验线站和数据中心之间的高速数据传输网络、加速器控制网络和线站控制网络。
广域网用于支持HEPS实验数据与国际、国内合作单位之间的高效多流数据传输的网络环境。
管理网络用于对HEPS整网中服务器的远程控制管理,下接服务器的管理网口,通过将管理网络和数据网络分离,使两种流量互不干扰,数据网络中断时依然可管理,管理网络中断时,可通过数据网络临时管理,保障服务器可以长期在线接入到网络。
通用网络、生产/业务网络、数据中心网络和管理网络之间通过HEPS核心交换机实现互联互通,考虑到数据中心网络和生产/业务网络的安全性以及未来实际业务的需求,将在数据中心网络和HEPS核心交换机之间、生产/业务网络和HEPS核心交换机之间架设防火墙,既实现网络通信的安全性要求,同时也满足特殊通讯需求。如图15所示。
图15
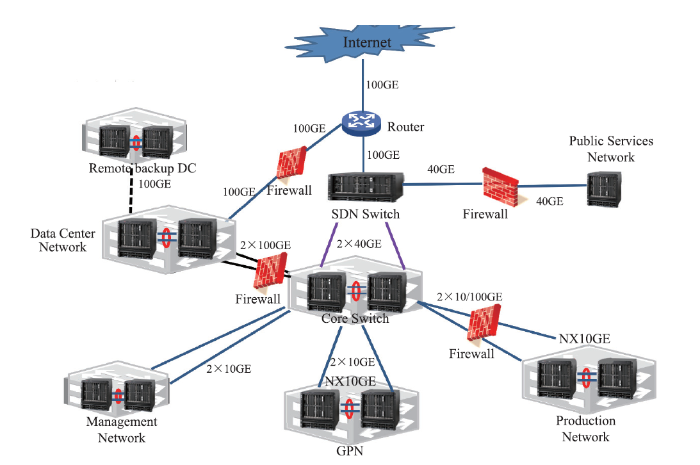 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图15网络总体连接图
Fig.15Overview of HEPS network connections
2.6 用户综合服务系统
HPES公共服务系统是一个开放的综合信息服务平台,面向全球用户提供简洁快速的服务,满足用户注册、提案提交、机时申请等,经过专家评审后使用高能同步辐射光源装置来完成各自实验,同时系统会对用户安全培训、行程安排、用户实验数据及实验结果进行一系列的管理过程,为用户提供一个清晰、流程化的高能同步辐射光源装置使用体验,接受用户的反馈,提高用户实验申请及使用效率,同时提高装置运行效率,加速科学成果的产出。公共服务系统主要实现四个方面的管理流程,分别是用户服务流程、实验过程管理流程、装置运行状态管理流程和数据共享管理流程。其中用户服务流程是面向装置用户提供从提案申请、机时分配、实验过程、数据服务到成果反馈的用户全生命周期服务流程(图16);实验过程管理是面向束线站管理员提供用户管理、样品管理、实验过程管理和实验结果分析的过程管理流程;装置运行状态管理流程是面向束线站运行管理人员和实验用户提供装置运行状态和运行分析的运行管理流程;数据共享管理流程面向数据管理员提供遵照数据共享策略进行数据共享分配,并对数据使用情况进行分析的数据管理流程。
图16
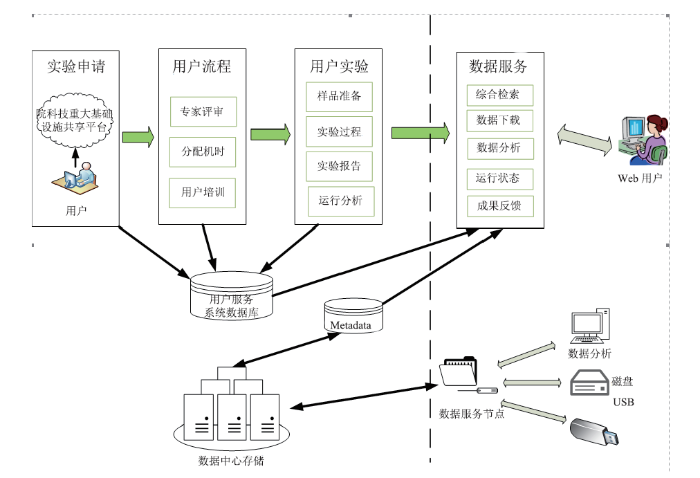 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图16HEPS公共服务系统用户服务流程
Fig.16Data flow for HEPS public services
HEPS公共服务系统是一个Web服务系统,以统一认证为核心,通过OAUTH和LDAP的形式认证和授权用户访问系统。系统实现采用SpringBoot + JPA + Thymeleaf的技术架构,共分为六层:最底层是数据,放置关系数据库和文件;实体层使用JPA框架,将数据库中的表和表关系影射成实体类和配置文件,所有针对数据库的操作都针对这些实体类进行;再上一层是数据访问层,所有对实体类的操作都位于该层的文件内;服务层调用数据访问层完成系统的业务逻辑,在该层使用SpringBoot框架的事务管理保证数据的完整性、一致性;控制层处理页面逻辑并判定用户请求的跳转关系,在该层记录用户的操作日志;视图层面向用户,是控制层输入输出的接口,使用JQuery、Thymeleaf、AJAX技术动态形成页面向用户提供服务。
3 未来计划与合作
作为服务于依托国家重大科技基础设施开展科学研究和科学实验的重要支撑系统,HEPS科学计算平台在功能、性能等各方面均面临巨大的压力。特别是随着技术的发展,尤其是光学仪器、探测器技术的快速进步,HEPS在科学数据产生速度以及对科学数据和计算系统的需求上将不断增加。设计方案在满足功能性需求的基础上,采用模块化、可扩展的技术架构,未来将根据数据规模、科研活动模式变化的需求,不断提升系统性能指标。当前相关设计方案已经完成,具体建设、开发工作正在稳定推进。随着包括GPU、ARM、FPGA在内的新的计算体系架构及技术的发展,将开展人工智能技术在光源数据获取、数据触发判选、数据准实时在线处理和离线处理方面的应用和探索研究。加强同信息技术企业界在关键技术、前沿技术等方面开展相关交流与合作,提升科学数据处理效率。
当前我国已经运行和正在规划和建设的有多个光源类(包括散裂中子源和自由电子激光)重大科技基础设施:如北京同步辐射装置、合肥光源、大连自由电子激光装置、上海光源、中国散裂中子源、高能同步辐射光源、上海自由电子激光、合肥先进光源、南方光源(预研)等,这些设施在科学数据处理方面均面临类似的需求和挑战。在此领域的科学数据处理平台、软件等各方面具有广泛的合作潜力。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[C].
URL [本文引用: 1]
[J].
URL [本文引用: 1]
URL [本文引用: 1]
.
[本文引用: 1]
URL [本文引用: 1]
[本文引用: 1]
URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}