 ,1,2, 焦文彬,1,*, 汪洋,1
,1,2, 焦文彬,1,*, 汪洋,1Automatic Summarization of e-Government Documents Based on Sentence Vector Representation and Fuzzy C-Means
QI Rongling,1,2, JIAO Wenbin,1,*, WANG Yang,1通讯作者: *焦文彬(E-mail:wbjiao@cnic.cn)
收稿日期:2020-10-23网络出版日期:2021-04-20
| 基金资助: |
Received:2020-10-23Online:2021-04-20
作者简介 About authors

祁荣苓,中国科学院计算机网络信息中心,中国科学院大学,硕士研究生,主要研究领域为自然语言处理和智能应用。
本文负责算法实现、论文写作。
QI Rongling is a master student of Com-puter Network Information Center, Chinese Academy of Sciences. Her research interests include natural language processing and intelligent applications.
In this paper she undertakes the following tasks: algorithmic implementation and paper writing.
E-mail:

焦文彬,中国科学院计算机网络信息中心,硕士,正高级工程师,主要研究领域为电子政务及数据智能应用。
本文负责论文组织、论文修改。
JIAO Wenbin, master, is a Senior Engineer of Computer Network Information Center, Chinese Academy of Sciences. His research interests include E-Government and Data Intelligence Application.
In this paper he undertakes the following tasks: organizing paper structure and paper revision.
E-mail:

汪洋,中国科学院计算机网络信息中心,博士,高级工程师,主要研究领域为大数据分析与信息化战略研究。
本文负责论文修改。
WANG Yang, Ph.D., is a Senior Engineer of Computer Network Information Center, Chinese Academy of Sciences. His research interests include Big Data Analysis and Information Technology Strategy.
In this paper he undertakes the following tasks: paper revision.
E-mail:

摘要
【目的】随着“互联网+电子政务”的发展,国家越来越重视我国电子信息化建设,对于政府相关决策者、管理者、信息化工作者及研究人员来说,迫切需要一种方式可以快速有效地获取众多的电子政务资讯来指导信息化评估和决策。本文旨在研究一种适合电子政务文档的自动摘要算法。【方法】本文针对电子政务资讯文本的特点提出了一种融合Doc2Vec句子向量表示方法和模糊均值聚类方法的算法并应用在电子政务资讯文档的自动摘要生成中,不仅考虑句子之间的相关度,而且针对文章的特点对于每个句子赋予一定的权重来表示他作为摘要句子的重要性。【结果】实验表明,相较于目前常用的k-means算法结果和复杂的深度学习算法结果,该算法在电子政务资讯文档的自动生成取得了比较好的结果。【结论】研究自动摘要技术并在电子政务领域应用是一项很有价值的工作。
关键词:
Abstract
[Objective] With the development of "Internet + E-Government", more and more attention has been paid to the construction of electronic information technology in China. For government decision-makers, managers, information workers and researchers, there is an urgent need to quickly and effectively obtain plenty of E-Government information to guide information evaluation and decision-making. This paper studies an automatic summarization algorithm for e-government documents. [Methods] According to the characteristics of e-government information text, this paper proposes an algorithm that uses Doc2Vec sentence vector representation and fuzzy c-means to automatically generate the summary of e-government information documents. It not only considers the correlation between sentences, but also gives weight to each sentence to express its importance as a summary sentence according to the characteristics of the article. [Results] Experiments show that, compared with the commonly used k-means algorithm and complex deep learning algorithms, this algorithm achieves better results in automatic generation of e-government information documents. [Conclusions] The proposed algorithm is effective for automatic document digest in the field of e-government.
Keywords:
PDF (6571KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
祁荣苓, 焦文彬, 汪洋. 基于句子向量表示和模糊C均值的电子政务文档自动摘要技术. 数据与计算发展前沿[J], 2021, 3(2): 103-111 doi:10.11871/jfdc.issn.2096-742X.2021.02.012
QI Rongling, JIAO Wenbin, WANG Yang.
引言
随着互联网的发展和国家对于信息化工作的高度重视,“互联网+”时代下电子政务迅速发展,迫切需要互联网技术和大数据技术加强对于海量电子政务资讯信息的管理与统筹[1]。电子政务资讯作为电子政务发展中的重要组成,主要包括国家、各省市、各地区的信息化系统建设中的一些信息化政策、战略方针、系统建设文档等,对于国家信息化系统的建设发挥着重要作用。但是随着信息网站的建设,增加了相关的电子政务信息获取的难度,同时也因为文本信息过长和冗余使得关键信息的获取变得更加困难。对于政府相关决策者、管理者、信息化工作者及研究人员来说,需要一种方式可以快速有效地获取这些电子政务资讯。如何及时、准确、有效地提供高质量的信息,这是所有党政办公部门非常关心并需要很好解决的问题。文本摘要作为获取关键信息的一种重要手段,自动摘要的研究也受到广大研究者的关注,但是目前自动摘要更多的应用在新闻等领域,对电子政务资讯文本并没有太多研究,将自动摘要系统应用到电子政务领域是我们一个崭新而又有实用价值的研究方向。文本自动摘要最早的起源要追溯到20世纪50年代,作为一个发展中的研究领域,这么多年以来,国内外的很多研究者都提出了不同的方法来解决自动摘要的问题。但是目前最主流的方法就是两类:抽取式摘要和抽象摘要。抽取式摘要生成的摘要句子都是直接从原始文档中直接提取的,并不对原始文本进行修改,句子按照原始文本排列可读性较强。而对于抽象摘要,可以通过对文档提取特征信息,可以通过对于句子的转述、替换开发新的句子,然后生成精确的信息摘要,但是相比起来实现难度比较大,技术还不成熟。目前自动摘要的生成主要有几种方法:基于简单统计的方法,通过统计一些文本特征,比如文本中词频、词位置、标题等[2,3,4];基于图模型的方法,常见的是lexrank和textrank方法,利用句子间的语义相似度构建图模型,然后抽取中重要句子[5,6,7];基于传统的机器学习的方法,就是把自动摘要问题抽象为一个二分类的问题,利用传统的机器学习的算法比如k-means等算法和一些优化算法进行解决[8,9];深度学习方法,目前最新的就是“序列到序列”思想[10],然后就是利用各种方法对于这些基本方法的改进和优化[11,12]。
针对目前的自动摘要的方法来看,自动摘要技术具有一定的领域性,针对不同领域,所需要选取的特征是有差异的。针对政务的文本,由于缺乏大量标注的语料库,导致深度学习的方法效果并不是很好,相反无监督的方法更加适用[13]。同时这类文本存在大的主题下面覆盖很多明确的小主题、文本叙述冗余等特点。采用现有的方法可能会存在生成很多冗余重复语义的句子,导致生成的有限的摘要并不能涵盖文章的所有内容,所以我们选择采用聚类算法来避免。而对于先前已有的k-means算法在自动摘要中的应用,虽然取得一定的效果,但是对于这种硬聚类算法来说,模糊聚类其实跟我们实际的研究是更契合,所以结合我们所研究的领域以及文章自身的一些特征,本文提出一种结合Doc2Vec与模糊C均值的方法。首先采用Doc2Vec对文章的句子进行向量化表示,然后根据文章特点,考虑句子与文章标题的相似度、句子位置和句子的特殊信息来对文章的句子进行加权,抽取中心句组成初始摘要,最后对初始摘要进行加工,得到流畅便于理解的摘要。最后采用从电子政务网站上爬取得到的电子政务类的文档对该算法进行测试和评价,并与k-means算法和目前研究的深度学习算法进行对比,得到比较好的结果。
1 结合Doc2Vec与模糊C均值的单文档自动摘要提取
在本文中,提出一种采用Doc2Vec句子向量表示和模糊C均值聚类融合的方法,然后加上一些文本特征权重来生成摘要。假设我们要提取k个句子作为文章的摘要,我们先用对文章的句子采用Doc2Vec的方法进行向量化,之后我们采用模糊C均值聚类的方法生成摘要。对于聚类的方法生成摘要,分为以下几个步骤:首先要根据文章的长度确定提取的摘要的句子的个数,也就是确定聚类k的大小;然后对于聚类中心进行初始化,根据句子的相似度进行迭代更新聚类中心,直到收敛,我们再进行聚类中心句的提取,对于每一类提取中心句的时候,一方面要找与聚类中心距离最近的,同时要抽取句子的权重最大的;最后生成文章的摘要。本文的方法流程图如图1所示,具体的算法步骤如表1所示。图1
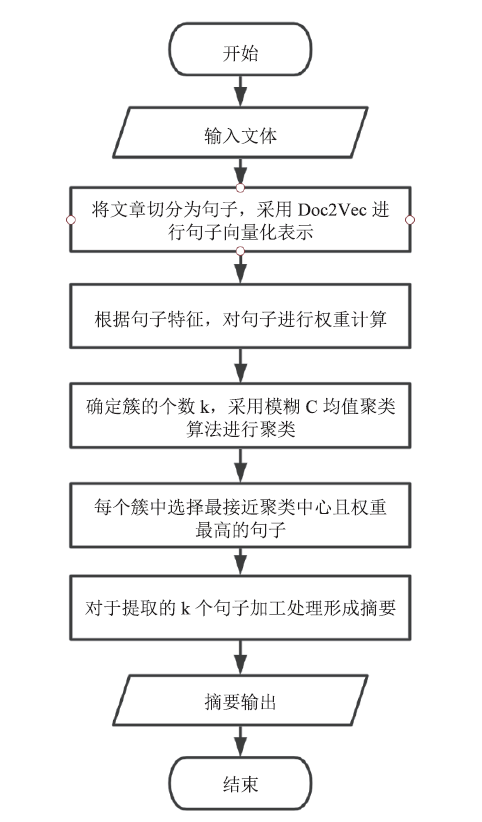 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1本文方法流程图
Fig.1Flow chart of this method
Table 1
表1
表1结合Doc2Vec与模糊C均值算法流程
Table 1
| 输入:要生成摘要的文章 输出:文章摘要 |
|---|
| Step l:将文档分解为句子,采用 Doc2Vec 模型对文档进行句子的向量化训练得到句子的向量化表示 Step 2:根据句子的相关特征对句子进行加权,得到每个句子的权重 Step 3:将句子向量采用模糊 C 均值聚类算法进行聚类,确定 k 个簇,对于句子随机初始化权重(隶属度)U = [uij],U(0) Step 4:根据隶属度矩阵,确定质心。通过 U(k) 计算类中心向量 C(k) = [cj] $c_{j}=\frac{\sum_{i=1}^{N} u_{i j}^{m} \cdot x_{i}}{\sum_{i=1}^{N} u_{i j}^{m}}$ Step 5:根据权重和质心,计算隶属度矩阵U(k),U(k+1) $u_{i j}=\frac{1}{\sum_{k=1}^{c}\left(\frac{\left\|x_{i}-c_{j}\right\|}{\left\|x_{i}-c_{k}\right\|}\right)^{\frac{2}{m-1}}}$ Step 6:重复步骤 4,5 不断迭代隶属度矩阵和簇中心,直到他们达到最优。目标函数为: Step 7:根据得到的隶属度矩阵,确定每个句子属于哪一类 Step 8:对于 k 个类,根据聚类中心抽取每个类的中心句,中心句选取与聚类中心的距离要小且权重大的句子。最终得到k个句子作为文章摘要 |
新窗口打开|下载CSV
1.1 基于Doc2Vec的句子向量的表示和句子权重的获取
对于文本摘要来说,句子向量化是文本摘要的一个首要环节也是一个重要的环节,他是每个文本摘要算法的基础。如果只是单纯的使用word2vec的词向量表示方法[14]对句子用词向量的和或者每个词的加权和表示,会忽略了句子上下文的语境等信息对句子的影响。所以国内外的研究者们也针对这一问题进行研究来提高自然语言处理的整体技术水平,国内一些研究者有采用概率潜在语义分析表示文本,也有采用潜在狄利克雷分布(LDA)对于句子进行向量表示,但是目前比较主流的方法还是Doc2Vec的向量表示[15,16,17]。所以在此算法中,我们采用这种方法来对句子进行向量化的表示。我们使用已有的gensim库中的Doc2Vec来进行句子向量的训练。对于每一个文档,先获取文档中的每一个句子,然后用jieba进行分词,用词来进行调用gensim来进行句子向量的训练,得到模型之后,对于每一个句子获取句子向量。很多****在研究的时候就提出,除了采用传统的统计特征,包括比如:句子的位置、句子相对长度、句子与标题的相似程度、关键词频率、TF-IDF、一些特定的专有词、信息熵、互信息等之外,可以寻找其他的特点作为句子的特征[18]。根据我们对于电子政务资讯文本的整体分析,发现获取的电子资讯的文本主要有以下特点:
(1)文章通常会有一些标题,可以充分地利用标题的作用。
(2)文章的层次划分比较明显,通常每一部分表示一个内容,会有一些单独成段的一个句子或者标题表示这一部分的核心内容。
针对这些特点,我们将句子的权重主要分为两个部分:一个是与文本标题的相似度Wtitle,另外一个就是单独成段的句子的权重Wpara,也可以称作是小标题。我们将句子进行向量化的表示之后,对于每一个句子,计算句子的权重
计算句子与标题的相似度获取相似度权重Wtitle,通过将句子向量化表示之后利用余弦定理获取。然后判断该句子是否自成一段,如果是则句子的权重为相似度权重的2倍,否则不变。
即:
1.2 模糊c均值算法生成文本摘要
对于摘要的生成,我们使用模糊C均值算法。模糊C均值算法的基本思想是定义一个隶属度矩阵,这个隶属度矩阵可以用来判断一个样本属于哪一类。算法通过优化目标函数得到每个样本点对所有类中心的隶属度来确定隶属度矩阵。简单来说:对于模糊聚类的方法生成摘要,就是给每个样本赋予属于每个簇的隶属度函数。通过隶属度值大小来将样本归类。分为以下几个步骤:首先要将文章中的每一个句子进行向量化的表示,然后确定聚类k的大小,对于聚类权值进行随机初始化,然后计算质心,以隶属度为权重做一个加权平均,最后更新模糊划分,就是更新每个句子对于聚类中心的隶属度,如果句子x越靠近质心,隶属度越高,反之越低。这样可以得到一个隶属度矩阵,我们可以根据这个矩阵来判断句子属于哪一类,然后对每一类提取一个句子作为摘要,最后生成文章的摘要。在L.A. Zadeh 1965发表的文章《模糊集》中,第一次提出了“模糊集合论”和“模糊逻辑”的概念,用属于程度代替属于或不属于[19]。模糊集合论,就是当我们不能确定的时候,用[0,1]区间来取代原始的0与1两个值,把经典的隶属关系更加模糊化。模糊C均值聚类融合了模糊理论的思想和聚类的方法,用隶属度确定每个样本属于某个聚类的程度的一种聚类算法。由Bezdek在1973年提出,是对硬聚类k-means方法的一种改进,在大部分情况下,数据集中的对象不能划分成为明显分离的簇,按照k-means的硬聚类算法可能会出错。而模糊聚类表示样本不再是硬性的属于某一类,而是计算出其属于各个类别的概率,使聚类的结果更加灵活。所以,模糊C均值聚类思想是一个比较符合实际应用的方法[20]。
FCM把n个向量分成k个组,初始化隶属度矩阵,计算每个组的聚类中心,通过模糊划分,计算每个向量在每个组的隶属度,也就是属于每一类的概率,隶属度由隶属矩阵U来确定,最后使得目标函数最小。
a.类中心向量:
b.隶属度矩阵:
$u_{i j} \in[0,1]$
$\sum_{i=1}^{c} u_{i j}=1, \forall j=1 \ldots n$
其中m表示聚类的簇数;i和j表示样本i相对于类簇j的隶属度。x是具有d维特征的一个样本。C是j这一类的通过d维度表示的中心。||*||可以用于表示两个点的距离。
c.目标函数Jm:
$c_{j}$表示类簇j的中心,$\left\|x_{i}-c_{j}\right\|^{2}$为第j个聚类中心与第i个样本点的距离,这个距离可以用欧几里德距离表示。模糊c均值通过不断迭代计算隶属度和类中心的过程,直到他们达到最优。
d.迭代的终止条件:
其中k是迭代步数,$\delta$表示误差阈值,当迭代过程中发现隶属程度不会发生较大的变化时,可以认为之后也不会发生变化,已经达到最优的状态,即这个过程收敛。
1.3 摘要句子的抽取和摘要加工
由于需要抽取k个句子作为文章的摘要,所以我们采用模糊c均值聚类的方法将文档的句子分为k个类,然后根据聚类的结果提取每一类的中心句,通过我们之前对于句子的加权处理,找到与聚类中心距离最近而且权重最高的k个句子,最后生成文章的初始摘要。按照聚类权重抽取出来的句子往往是按照权重大小排序的,前后句子顺序会影响读者对于文章的理解,所以对于抽取出来的句子按照原文中的句子的顺序进行排序,符合文章的逻辑思路,更加便于读者理解。2 自动摘要评价指标
对于生成自动摘要的评价方法,我们一般采用和人工撰写的摘要进行比较来评价生成的摘要的质量,但是对于电子政务资讯的摘要来说,对于大规模的文章,采用人工的方式一般费时费力,鉴于每一篇文章都有文章标题,所以我们采用与文章标题比较的方法来判断,然后对于少量的文章用人工来评价,这样效果更好。目前自动文摘评价技术的标准之一的ROUGE评价方法,就是与标准文摘进行比较时采用n-gram进行细粒度的划分,同时采用最长公共子串来计算准确率和召回率。对于我们采用的与标题比较的方式来看,用召回率的检测的效果更加明显,召回率越高,说明聚类的效果越好[21],具体的公式如下:其中:
n表示n-gram的长度;
$\text { \{ReferenceSummaries\} }$ 是参考摘要,即人工标注好的标准摘要;
$\text { Count }_{\text {match }}\left(\text { gram }_{n}\right)$ 表示生成的摘要和标准摘要中同时出现的n-gram的个数;
$\text { Count }\left(\text { gram }_{n}\right)$ 表示的是标准摘要中出现的n-gram的个数。
Rounge_L :采用了最长公共子序列比较,其中L表示LCS就是最长公共子序列的首字母。
n为生成的自动摘要的长度。
m为标准的自动摘要的长度。
3 实验应用和结果分析
随着互联网的发展,我们国家加强电子政务建设,一些电子政务工作也采用了线上网站公布的方式,便于对目前电子政务的发展进行公开化和透明化,同时可以便于信息化工作者的评估和决策。对于这种电子政务资讯的文档一般蕴含了很多重要的内容,但是大篇幅的文档看起来很不方便,不能短时间内掌握文章的整体内容,所以我们研究对电子政务类文档自动生成摘要就很有必要。3.1 数据的收集和分析
我们利用爬虫技术从电子政务网站上爬取出3500多篇文章,文本包含文章的内容和文章的标题,并且进行整理和分析。根据电子政务的文章进行分析,以一篇文章为例,如表2所示,得到以下相关信息。Table 2
表2
表2原始的电子政务文章示例
Table 2
| 原始文章 |
|---|
| 文章标题:政府云应用效果显现 在云计算技术逐渐成熟和“十二五”规划的共同促进下,各地方政府的云计算发展如火如荼。近两年,政府用户对云计算解和认可程度不断提高,云计算厂商的解决方案也在逐步完善,成功案例不断涌现。截止到2012年初,已有北京、上深圳、成都、杭州、青岛、西安和佛山等城市在政府云应用领域进行了积极探索,并取得丰硕成果,政府云计算应用效果逐渐显现。对政府而言,云计算不仅能够提高降低信息化建设成本、加强信息资源整合、促进政务资源共享,还能够推动服务和管理创新,帮助政府部门向服务型政府转型。 首先,政府云应用顺应了电子政务发展的新要求。 政府云是一种基于云计算的,可以优化政府管理和服务职能,提高政府工作效率和服务水平的平台技术框架,本质上是在层面“构建了统一的政府底层IT基础结构”。具体而言,政府云可以把政府的IT资源整合为服务,以供居民、企业和所关部门共享使用,从而提高了政务IT资源的利用率。另外,政府云可以满足IT资源对安全性、可靠性、可管理性方面的,顺应了电子政务发展的新要求。在电子政务建设领域,政府云的建设可以提高设备资源利用率,推动信息资源整合,优务效率,提高信息平台的安全性。第一,提高设备资源利用率,避免重复建设,减少专业维护人员的需求。第二,推动信源整合,促进政务资源共享的需求。第三,提高服务灵活性,改善服务可扩展性,推动创新提升服务效率的需求。第四,平台提高安全性的需求。 其次,政府云应用项目建设在全国各大城市遍地开花。 为推动政务服务创新、加强信息资源整合、促进政务资源共享、降低信息化建设成本,各地方政府积极开展政府云应用项设,以政府应用带动云计算产业发展,北京、上海、成都、深圳、杭州、青岛、无锡等城市纷纷启动政府云项目建设,政应用项目建设正以星火燎原之势席卷全国。第三,民生服务和企业服务是政府云计算的重点应用领域。政府云计算应用的应用领域是公共服务,主要包括民生服务和企业服务。公共服务与云计算的契合,不仅为公共服务开辟了不受时空限制的可能,而且使公共管理创新的动力互动化。构建面向公共服务的云计算体系,不仅可以丰富行政管理体制改革的实验模而且能为行政管理体制改革提供外部动力,奠定服务型政府建设的技术基础和社会基础。在民生服务方面,政府云可以将分散独立的各类民生业务系统打通、整合,提供单一服务节点上的不同业务办理,提高为民服务效率,降低社会服务成本间成本,并成为公平、均等的民生服务窗口。在公共服务方面,政府云可以增强公用事业单位的处理能力、扩展性和灵活提供完善的数据分析能力以及协作能力。在文化服务领域,政府云可以实现文化资源的社会化、服务化、专业化的发展,服务对图书馆提供存储、平台和计算能力,而图书馆利用云服务来处理业务,大大降低图书馆信息技术的投入成本。在企务方面,政府可以建立面向中小企业的公共云服务平台来帮助中小企业解决信息化建设问题。第四,技术与应用双重因素政府云建设飞速发展。政府云的成功实施,离不开云计算相关技术的快速成熟和目前政务领域迫切的应用整合需求。云计术作为新一代科技信息技术的变革力量,已成国内外软件和信息行业普遍关注的焦点技术之一,使全球迎来第三次I浪虚拟化技术、海量分布式存储技术、高效可靠的后台系统、自动管理监控技术、信息安全技术等云计算核心技术的快速发为政府云建设提供了技术基础,加快了政府云应用的落地速度。 |
新窗口打开|下载CSV
3.2 实验结果与分析
3.2.1 对于文章生成的摘要对于文本使用向量表示,经过本文中提到的算法进行处理,可以生成一篇文章的摘要结果,表3为采用本论文方法提取的文章的摘要结果与人工摘要和k-means方法提取摘要的结果的对比。
Table 3
表3
表3文章自动摘要生成结果对比
Table 3
| 人工摘要 | 模糊C均值摘要结果 | k-means摘要结果 |
|---|---|---|
| 在云计算技术逐渐成熟和“十二五”规划的共同促进下,各地方政府的云计算发展如火如荼。 首先,政府云应用顺应了电子政务发展的新要求。 其次,政府云应用项目建设在全国各大城市遍地开花。 | 在云计算技术逐渐成熟和“十二五”规划的共同促进下,各地方政府的云计算发展如火如荼。 对政府而言,云计算不仅能够提高降低信息化建设成本、加强信息资源整合、促进政务资源共享,还能够推动政务服务和管理创新,帮助政府部门向服务型政府转型。 其次,政府云应用项目建设在全国各大城市遍地开花。 | 首先,政府云应用顺应了电子政务发展的新要求。 另外,政府云可以满足IT资源对安全性、可靠性、可管理性方面的要求,顺应了电子政务发展的新要求。 公共服务与云计算的契合,不仅为公共服务开辟了不受时空限制的无限可能,而且使公共管理创新的动力互动化。 |
新窗口打开|下载CSV
3.2.2 ROUGE指标评价
除了对生成的摘要人工分析之外,我们对于3500多篇文章采用ROUGE指标评价,同时由于文章都有标题,所以我们采用对于标题的召回率的结果来进行评测,抽取文章中的3个句子作为最终生成的自动摘要。然后分别采用目前已有研究的k-means聚类的方法、深度学习中的指针生成网络同本文提到的基于句子向量表示和模糊C均值的方法进行测试和评估。表4为本文结合句子向量表示和模糊C均值的方法同其他算法的结果对比。
Table 4
表4
表4本文的方法和其他算法的结果对比
Table 4
| 召回率 | k-means | Fuzzy c-means | 指针生成网络 |
|---|---|---|---|
| Rouge_1 | 0.44 | 0.49 | 0.22 |
| Rouge_2 | 0.23 | 0.29 | 0.04 |
| Rouge_3 | 0.31 | 0.34 | 0.21 |
新窗口打开|下载CSV
从表4中的结果我们可以看出,在同样的采用句子向量表示方式下,采用基于句子向量表示和模糊C均值方法比深度学习的指针生成网络算法有显著优势,比同属于机器学习的k-means的方法效果也有一定的提高。对于和人工摘要的比较来看,算法抽取的主题句还是有一定的代表性,可以基本满足要求,之后可以随着人工标注数据的增加再对算法进行改进。
4 总结与展望
自动摘要是目前自然语言处理和文本数据挖掘的一个热点研究领域,本文主要针对电子政务目前对于自动摘要的需求,结合电子政务文章的特点提出了新的自动摘要的方案。对于句子增加了权重来提高主题句提取的效率,同时又采用Doc2Vec的句子向量表示方法和模糊C均值聚类的无监督学习的方法的融合,在电子政务领域取得了较好的效果。对于电子政务文本的自动摘这是一次全新的尝试,如果能够很好的实现文章的自动摘要的提取,对于之后文章模板的生成,文章的自动编写都能起到促进作用。同时不仅针对电子政务文本,对于其他一些全新的领域文本,针对其没有完善高质量的特点也可以借鉴该方法进行摘要生成。但是目前的方案仅能满足一定程度的要求,对于一些结构比较复杂的文章识别结果还有进一步提升空间。而对于大数据时代的到来,人工智能技术也在逐步攀升,大数据融合建设也是人工智能发展的一个方向[22,23,24]。所以,下一步计划结合复杂结构和主题思想及先进的人工智能手段进一步提高摘要提取的准确率。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
DOI:10.1145/321510.321519URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1145/951787.951766URL [本文引用: 1]
[J].
DOI:10.1613/jair.1523URL [本文引用: 1]
[C]//
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 1]
[J].
[本文引用: 1]
[C]//
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C]//
[本文引用: 1]
[J].
DOI:10.1016/j.ipm.2003.10.006URL [本文引用: 1]
[J].
DOI:10.1016/S0019-9958(65)90241-XURL [本文引用: 1]
[M].
[本文引用: 1]
[A].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]

{kind=link}
{kind=link}