 ,1,2, 张宏海,1,*, 仲波,3
,1,2, 张宏海,1,*, 仲波,3A Deep Learning Based Method for Remote Sensing Image Parcel Segmentation
ZHAO Weiyu,1,2, ZHANG Honghai,1,*, ZHONG Bo,3通讯作者: *张宏海(E-mail:zhh@cnic.cn)
收稿日期:2020-12-31网络出版日期:2021-04-20
Received:2020-12-31Online:2021-04-20
作者简介 About authors

赵伟昱,中国科学院计算机网络信息中心,中国科学院大学,硕士研究生,研究方向为云计算与分布式系统、深度学习。
本文主要承担工作为:模型设计、实验数据分析、文章撰写。
ZHAO Weiyu is a master student in Computer Network Infor-mation Center, Chinese Academy of Sciences (University of Chinese Academy of Sciences). His research interests include cloud computing and distributed system, and deep learning.
In this paper, he is mainly responsible for model design, experi-mental data analysis and article writing.
E-mail:

张宏海,中国科学院计算机网络信息中心,副研究员,研究方向为云计算与分布式系统、嵌入式操作系统与物联网、高性能计算环境软件与技术。
本文主要承担工作为:文章框架的整体设计。
ZHANG Honghai is an associate research fellow in Computer Network Information Center, Chinese Academy of Sciences. His research interests include cloud computing and distributed system, embedded operating system and Internet of things, high performance computing environment software and technology.
In this paper, he is mainly responsible for the organization of the paper.
E-mail:

仲波,中国科学院空天信息创新研究院,副研究员,研究方向为遥感大数据与产品生产系统。
本文主要承担工作为:遥感图像分割介绍与研究指导。
ZHONG Bo is an associate research fellow in Aerospace Information Research Institute, Chinese Academy of Sciences. His research interests include remote sensing big data and product production system.
In this paper, he is mainly responsible for the introduction of Remote sensing image segmentation and supervising the research.
E-mail:

摘要
【目的】遥感影像地块分割是遥感影像解译的一项具体任务。良好的遥感影像地块分割结果可以为环境保护、农业生产、城镇建设提供指导意见。【方法】本文使用Pytorch框架搭建了DeepLabV3+网络,编码器使用ResNet101和空洞空间金字塔池化模块进行特征提取,解码器使用双线性插值的方法进行特征图尺寸还原。训练过程中,针对遥感影像地块分割任务,专门设计了训练时的数据增强策略,从而增强模型的泛化能力。使用联合Lovasz loss和Softmax loss的损失函数克服样本类别分布不平衡的问题。【结果】实验结果选用平均交并比作为评价指标,最终模型的平均交并比可以达到70.3%,相比遥感图像分割常用的UNet方法提高了7.6%。【局限】部分分割图像的区域不够完整,还需要进一步提高分割图像的连通性。【结论】本文提出的遥感影像地块分割方法,可以实现对高分辨率遥感图像的精细分割,为遥感图像分割的研究提供借鉴。
关键词:
Abstract
[Objective] Remote sensing image parcel segmentation is a specific task of remote sensing image interpretation. Good results of remote sensing image parcel segmentation can provide guidance for environmental protection, agricultural production and town construction. [Methods] In this paper, DeepLabV3+ network is built using Pytorch framework. The encoder uses ResNet101 and atrous spatial pyramid pooling module for feature extraction, and the decoder uses the bilinear interpolation method for feature map resizing. During the training process, a data augmentation strategy is specifically designed for the remote sensing image parcel segmentation task, so as to enhance the generalization ability of the model. A loss function with joint Lovasz loss and Softmax loss is used to solve the problem of unbalanced distribution of sample categories. [Results] The mean Intersection over Union is chosen as the evaluation index for the experimental results. The mean Intersection over Union of the final model can reach 70.3%, which is 7.6% higher than the UNet, a commonly used method for remote sensing image segmentation. [Limitations] The region of some segmented images is not complete, and the connectivity of segmented images needs to be further improved. [Conclusions] The remote sensing image parcel segmentation method proposed in this paper can achieve fine segmentation results of high-resolution remote sensing images and provide a reference for the research of remote sensing image segmentation.
Keywords:
PDF (7505KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
赵伟昱, 张宏海, 仲波. 基于深度学习的遥感影像地块分割方法. 数据与计算发展前沿[J], 2021, 3(2): 133-141 doi:10.11871/jfdc.issn.2096-742X.2021.02.015
ZHAO Weiyu, ZHANG Honghai, ZHONG Bo.
引言
遥感影像地块分割是遥感图像分割的一项具体任务,其目的是对遥感图像上的水体、草地、建筑、林地等按像素进行分类,自动化地进行遥感图像标注。遥感影像地块分割的结果可以为环境保护、农业生产、城镇建设提供指导意见。因为遥感影像地块分割是许多后续研究的基础,研究鲁棒、准确的遥感影像地块分割方法无疑有着重要的理论意义与实际意义。传统的遥感图像分割方法主要是使用图形学算法,包括基于阈值的分割方法、基于区域提取的分割方法和基于边缘检测的分割方法。于东方等人[1]通过对遥感图像的灰度直方图设置分割阈值,实现了一种快速的遥感图像阴影自动检测方法。陈波等人[2]提出了一种基于距离变换图搜索种子点的分水岭算法及改进的区域合并的遥感图像分割方法。刘永学等人[3]使用Canny算子提取单波段遥感图像中的边缘信息并结合边缘细化、边缘生长算法实现了对多光谱遥感图像分割。以上的传统的遥感图像分割方法需要人工构造特征,通常只能实现前景和背景的分割,准确率也不够理想,无法满足对遥感图像中多种地块分割的需要。
另一类重要的遥感图像分割方法是使用机器学习的方法,如马尔可夫随机场、EM算法。郑玮等人[4]考虑到图像分割中的随机性与模糊性,使用马尔科夫随机场作为先验模型,实现了一种无监督的遥感图像分割算法。王民等人[5]提出了一种基于核模糊均值聚类和EM混合聚类算法的遥感图像分割方法。使用机器学习的方法进行遥感图像分割,相比于图形学算法有所提升,但准确率依然不高。
近年来,得益于数据资源的极大丰富和计算技术的飞速发展[6-7] ,人工智能中的神经网络方法复兴,并演化成为深度学习。2012年,深度神经网络AlexNet[8]在ImageNet大赛的图像分类项目上摘得桂冠,其远超传统方法的成绩引起了计算机视觉领域的革命。随后,VGG[9]、ResNet[10]等网络不断在竞赛中刷新图像分类领域的纪录,计算机视觉能力已经在图像分类任务中超过人类视觉精度水平[11]。受图像分类任务的启发,图像分割任务也开始使用深度学习方法。2015年,Shelhamer E等人[12]提出了一种使用全卷积网络进行图像分割的网络FCN。FCN是将VGG网络最后的全连接层替换为卷积层,所以将其命名为全卷积网络(Fully Convolutional Networks)。FCN被认为是深度学习在图像分割领域的开山之作,在FCN之后的很多网络都可以看到FCN的影子。在FCN出现的同年,Ronneberger O等人[13]提出了一种使用编码器-解码器结构的网络UNet,其特点是结构简单、进行了多尺度特征融合。UNet之后的重要网络是H. Zhao等人[14]提出的PSPNet,PSPNet中加入了空间金字塔池化模块,在其中使用了自适应池化层对特征图进行多尺度的特征提取。由于以上网络都不是专门针对遥感图像分割任务设计的,所以将这些网络迁移到遥感图像分割任务时,会出现分割不精确的问题。在本文中,提出了一种基于DeepLabV3+[15]的遥感影像地块分割方法,它可以对RGB频段、存在小样本、不精确人工标注的遥感图像进行分割。本文的工作可以概括为:(1)使用端到端的深度神经网络对遥感图像进行地块分割;(2)为增强模型的泛化能力,加载数据时会随机进行数据增强;(3)为应对样本类别不均衡问题,替换了网络的损失函数。
1 方法
1.1 网络结构
本文提出的基于深度学习的遥感影像地块分割方法是建立在对DeepLabv3+网络的改进上。DeepLabv3+网络是DeepLab系列[15,16,17]图像分割网络的最新作品,DeepLabv3+在DeepLabv3网络的基础上引入了编码器-解码器结构。这项改进使DeepLabv3+网络既有多尺度和在多个感受野上提取特征的能力,又使其在上采样还原图像尺寸阶段可以更加精准地利用物体边缘信息。DeepLabv3+网络的结构如图1所示。左侧为编码器部分。输入图像(Input Image)最先进入了编码器的Stem模块,输入图像在Stem模块经过了卷积操作、归一化操作和最大池化操作,在通道数、高、宽的维度上都发生了变化,成为了新的特征图S。特征图S之后进入了以ResNet101作为骨干网络的特征提取网络。ResNet101是一种基于残差学习思想设计的网络,它在卷积层之间加入了残差连接。ResNet101解决了卷积神经网络层数增加引发的性能退化问题,使训练更深层次的网络成为了可能。ResNet101可以划分为四个阶段。特征图S在经过ResNet101第一阶段后会生成特征图R1,R1会被保留用于解码器部分。特征图R1再顺序进入ResNet101的第二、三、四阶段,生成特征图R4。特征图R4之后进入ASPP模块。ASPP模块的全称是空洞空间金字塔池化 (Atrous Spatial Pyramid Pooling),其作用是可以从多尺度提取特征。
图1
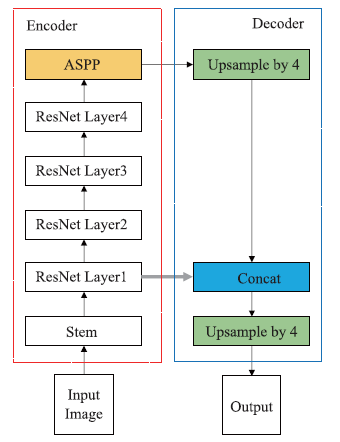 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1DeepLabv3+网络结构
Fig.1DeepLabv3+ network structure
ASPP模块的组成如图2所示。特征图R4进入ASPP模块,分别对其进行了5种不同的操作——卷积核为1×1的卷积、卷积核为3×3且空洞率为6的卷积、卷积核为3×3且空洞率为12的卷积、卷积核为3×3且空洞率为18的卷积、自适应池化并上采样。这5种操作后会得到5张新的特征图,将这5张特征图进行通道维度的拼接操作后,再进行一次卷积核为1×1的卷积操作将通道数压缩,得到特征图A。至此,DeepLabv3+网络的编码器部分完成,得到的特征图A的高度和宽度都是输入图像的1/16。
图2
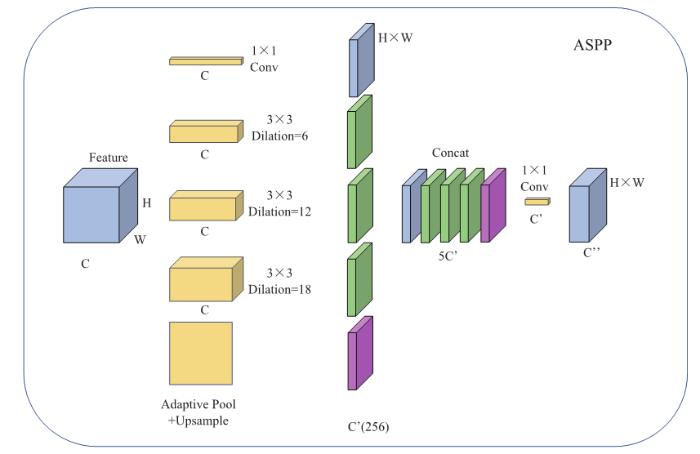 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2ASPP模块
Fig.2ASPP module
图1的右侧为DeepLabv3+网络的解码器部分。解码器部分的作用是将深层网络提供的语义信息与浅层网络提供的细节信息融合。特征图A先经过一次高度和宽度放大为原来4倍的上采样操作得到特征图U,采样方法为双线性插值法。特征图U与之前保留的特征图R1进行在通道维度的拼接操作之后会得到新的特征图,将这张特征图再进行一次4倍上采样操作,就可以获得输出图像。输出图像是对输入图像进行图像分割的结果。
1.2 损失函数
在进行图像分割任务时,传统上使用的损失函数是交叉熵损失和Softmax loss。但这些损失函数没有考虑数据集样本类别分布不均匀的情况,本文选择使用联合Lovasz loss[18]和Softmax loss作为损失函数解决这个问题。根据分割任务的类别数量的区别,可以将Lovasz loss分为两种:适用于图像前景背景分割的Lovasz_hinge_loss和适用于多类别分割的Lovasz_softmax_loss。本文主要用到的是Lovasz_softmax_loss,其定义如下:对于每一类别有:
对于全部类别有:
上述公式中,c代表输出图像的预测类别,$c$代表真实类别,$y^*_i$代表像素点被分类为c类的概率,$f_{i}(c)$代表像素点被分类为c类的概率,$k$+1代表类别总数。
Lovasz_softmax_loss的核心思想是:如果一个像素点被错误分类,就会产生较大的损失;如果一个像素点被正确分类,那么将会产生较小的损失。
2 实验数据
2.1 数据说明
本文使用的实验数据是“遥感影像地块分割”竞赛发布的数据集。数据集包含140 000张高清遥感图像,分辨率为2米,尺寸为256×256,格式为JPG。标签文件与图像文件数量相同,每张标签是单通道伪彩色标注图片,尺寸为256×256,格式为PNG。标签文件中的类别与像素值的对应关系见表1。Table1
表1
表1标签文件中的类别与像素值的对应关系
Table1
| 类别 | 像素值 |
|---|---|
| 建筑 | 0 |
| 耕地 | 1 |
| 林地 | 2 |
| 水体 | 3 |
| 道路 | 4 |
| 草地 | 5 |
| 其他 | 6 |
| 未标注区域 | 255 |
新窗口打开|下载CSV
2.2 数据统计
在进行模型训练前,需要了解数据集中不同类别的分布情况。对数据集中的所有标签文件的标注区域像素点进行统计,绘制出图3所示的环形图。从图3分析可知,样本数据存在不平衡的情况,代表耕地的像素点最多,占到了52.44%;而代表道路的像素点最少,占比仅0.40%。克服数据集样本类别分布不均衡的问题将成为实验的重点研究之一。图3
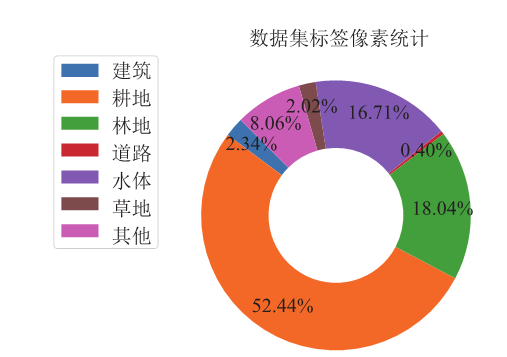 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3数据集标签像素统计
Fig.3Pixel statistics of data set label
2.3 数据增强策略
为了增强模型的泛化性能以及鲁棒性,在样本数量较小时,会对数据集使用一些数据增强方法扩充数据量:使用上下翻转让模型获得旋转不变性;使用裁剪、拉伸等方法让模型获得尺寸不变性;使用添加噪声的方法避免模型学到无用的高频特征,避免过度拟合。由于数据集中的图像已经达到140 000张,如果再对数据集进行扩充,训练时间将会大幅度增加。本文在进行实验时采用了数据加载时随机进行数据增强的策略,具体策略是:在网络训练过程中,每张图像在送入网络前,有5%的概率进行上下翻转;有5%的概率进行0.5至1.5倍的缩放;有10%的概率加入高斯噪声。当图像进行翻转、缩放变换时,对应标签会进行相同的变换。
3 实验研究及分析
实验环境为安装RHEL7.5操作系统、装配12GB显存的NVIDIA显卡的服务器。实验中涉及到的深度神经网络使用深度学习框架Pytorch实现。3.1 评价指标
为了对实验结果进行度量,实验选取在图像分割领域的国际通用指标平均交并比mIOU作为评价指标。交并比IOU的定义为:计算两个集合的交集和并集之比,在图像分割领域这两个集合分别为真实值和预测值。平均交并比IOU是在计算每个类别的IOU之后计算平均值。计算公式如下:
在公式(3)中,i代表真实类别,j代表预测类别,$k$+1代表类别数。
3.2 实验方案
实验开始前,我们将数据集按13:1的比例划分为训练集和测试集,即130 000张图像和对应标签用于训练网络,10 000张图像和对应标签用于评估模型。实验的batchsize设置为32,epoch设置为50。初始学习率设置为0.001。
3.3 实验结果
训练得到的最终模型在测试集上获得的预测图像的平均交并比可以达到70.3%,部分图像的预测效果如图4所示。从图中可以看出,我们的方法训练出的分割模型表现出了很强的分割能力,不同类型之间的分割边界也相当准确,在一定程度上克服了样本数量不均衡的问题。不过在边缘处的细节还有一定的提升空间。图4
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4部分图像的预测效果
Fig.4The prediction effect of some images
3.4 实验对比
为了更好的对本文的方法进行评估,我们还使用三种其他方法进行了对比实验:第一组对比实验采用遥感图像分割领域常用的网络UNet进行训练,UNet分为特征提取网络和上采样网络两部分,原图像经过特征提取网络生成特征图,特征图在上采样网络通过双线性插值的方法被还原到原图像的尺寸。第二组实验使用的网络就是未经修改的DeeplabV3+网络,在训练时没有使用数据增强方法,也没有使用Lovasz loss作为损失函数。第三组实验使用了高分辨率网络HRNet[19],该网络中最上面一层始终维持着高分辨率特征图,在网络的不同阶段进行特征融合。四组实验的骨干网络的预训练数据集相同。四组实验在测试集上的平均交并比如表2所示。Table 2
表2
表2不同方法获得的预测图像的平均交并比
Table 2
| 方法 | 平均交并比 |
|---|---|
| 本文方法 | 70.3% |
| UNet | 62.7% |
| 未修改的DeeplabV3+ | 66.8% |
| HRNet | 64.7% |
新窗口打开|下载CSV
从实验结果可以看出,使用本文提出的方法得到的模型对比UNet网络有了7.6%的提升,对遥感图像具有更强的分割能力。与未修改的DeeplabV3+网络相比,本文方法有3.5%提升。与HRNet相比,本文方法有5.6%的提升。这说明使用本文方法训练时可以在一定程度上克服样本分布不均衡的问题,得到的模型鲁棒性更强,因而具备更精细的分割能力。
由于本文方法的骨干网络加载了预训练的参数,为探寻预训练数据集对于实验结果的影响,我们又进行了两组对比实验。第一组实验使用在Imagenet数据集上预训练的ResNet101作为骨干网络。第二组实验使用在Cityscapes数据集上预训练的ResNet101作为骨干网络。而本文方法使用的ResNet101骨干网络是在MS-COCO数据集上预训练得到的。三组实验在测试集上的平均交并比如表3所示。
Table 3
表3
表3使用不同预训练数据集作为主干网络训练出的模型获得的预测图像的平均交并比
Table 3
| 预训练数据集 | 平均交并比 |
|---|---|
| MS-COCO(本文方法) | 70.3% |
| Imagenet | 67.9% |
| Cityscapes | 68.5% |
新窗口打开|下载CSV
分析实验结果,预训练数据集会对模型的分割能力造成影响,使用在MS-COCO上预训练的骨干网络能获得最好的效果,其他数据集上的结果相对较差。我们对数据集进行分析,Imagenet数据集上的每张图像仅有一个标注,会限制网络学习多类别的能力;Cityscapes数据集的图像都是城市景观,与遥感图像数据集偏差很大;MS-COCO数据集因为具有多类别、多场景的特点,因而有最好的效果。
4 结语
本文所研究的基于深度学习的遥感影像地块分割方法,通过使用深度学习框架Pytorch搭建DeepLabV3+网络,并针对样本类别分布不平衡的问题使用了Lovasz softmax loss损失函数。网络搭建完成后,在“遥感影像地块分割”竞赛数据集上训练模型,在训练过程中加入了随机的数据增强策略。最终的模型在测试集上取得了明显的提升,预训结果的平均交并比mIOU比遥感图像分割常用的UNet网络以及未修改的DeepLabV3+网络有明显提升,证明本文方法训练出的模型有更强的分割能力。本文的方法也存在着一些不足,从预测图像可以观察到,一些区域的连续性不够好,分割结果显得不够完整;部分类型的分割存在过拟合的现象,即使是分散在其他类别的很小的部分也会被分割出来,这种过于灵敏的分割能力实际上是应该避免的。提高分割结果的连续性以及避免模型的过拟合将成为下一步工作的重点,也是提升预测结果的准确度的关键。
本论文的实验和数据发布在
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1109/TPAMI.2016.2572683URL [本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 2]
[C]//
[本文引用: 1]
[J].
DOI:10.1109/TPAMI.2017.2699184URL [本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}