 ,1,2,*, 施卓敏,1, 于建军,1
,1,2,*, 施卓敏,1, 于建军,1Tree Model Based Prediction of Financial Reimbursement Approval
LIU Chunyu,1,2,*, SHI Zhuomin,1, YU Jianjun,1通讯作者: *刘春雨(E-mail:liuchunyu@cnic.cn)
收稿日期:2021-03-5网络出版日期:2021-04-20
Received:2021-03-5Online:2021-04-20
作者简介 About authors

刘春雨,中国科学院计算机网络信息中心,中国科学院大学,在读硕士研究生,主要研究方向为数据挖掘、机器学习、用户行为分析等。
本文中负责数据分析、模型构建、实验设计及文献撰写。
LIU Chunyu is a graduate student in Computer Network Information Center of Chinese Academy of Sciences. Her research interests cover data mining, machine learning, user behavior analysis, etc.
In this paper, she is responsible for data analyzing, model construction, experiments design and paper writing.
E-mail:

施卓敏,中国科学院计算机网络信息中心,硕士,高级工程师,主要研究方向为大数据分析、管理信息化、智能财务应用等。
本文中承担数据分析。
SHI zhuomin, master, is a senior engineer at Computer Network Information Center, Chinese Academy of Sciences. Her research interests cover big data analysis, management informatization, and intelligent financial application.
In this paper, she is responsible for data analysis.
E-mail:

于建军,中国科学院计算机网络信息中心,研究员,博士生导师,管理信息化部副主任,主要研究方向为大数据分析、协同推荐、云计算,当前主要从事新一代ARP相关技术研究。
在本文中负责总体统稿。
YU Jianjun is currently the researcher, doctoral supervisor, and the deputy Director of Management informazation Deparment, Computer Network Information Center, Chinese Academy of Sciences. His research interests cover big data analysis, collaborative filtering recommendation, and cloud computing. Recently, he is working on New ARP technical research.
In this paper, he is responsible for the overall draft.
E-mail:

摘要
【目的】针对目前科研院所财务报销不规范导致的反复审批等问题,本文研究通过预测结果提升报销审批效率。【方法】本文针对财务报销审批进行业务建模,形成可机器理解的报销审批脱敏数据,并根据实际业务特点构造变量特征与标签,采用随机森林对重构后的变量进行重要度分析。使用决策树、随机森林、梯度随机树以及XGBoost四种分类算法对报销审批结果进行预测。【结果】通过随机森林算法证实重构变量对于报销审批结果预测的可靠性。四种树模型根据重构后的训练数据集归纳出一组分类规则,采用该规则对未审批的报销单进行预测,通过预测结果从四种树模型中评定出最佳模型。【结论】文章基于树模型,通过构造随机森林辅助判断影响报销审批结果的关键因素,并选用树模型算法实现报销审批预测模型的构建,为树模型在报销审批预测中的应用提供了算法基础。
关键词:
Abstract
[Objective] Nowadays, how to reduce repeated submissions caused by irregular reimbursements for financial reimbursement approval to improve the efficiency of financial reimbursement becomes a big issue in daily scientific research management of CAS institutes. This paper studies the use of prediction results to improve the efficiency of reimbursement approval. [Methods] This paper conducts a business model for financial reimbursement approval, obtains desensitized data for reimbursement approval that can be machine-understood, constructs variable characteristics and labels according to actual business characteristics, and then uses a random forest approach to analyze the importance of reconstructed variables. Decision tree, random forest, gradient random tree, and XGBoost algorithms are used to predict the reimbursement approval results. [Results] The importance analysis by constructing random forest makes the reconstruction variables more credible, provides reliable support for the approval results predicted by the subsequent four tree-model algorithms, and evaluates the best model from the results. [Conclusions] Based on the tree model, this paper identifies the key factors that affect the results of reimbursement approval and applies the machine learning algorithms to predict financial reimbursement approvals, which provides an application basis for tree models in predicting reimbursement approval.
Keywords:
PDF (5668KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
刘春雨, 施卓敏, 于建军. 基于树模型的财务报销审批预测. 数据与计算发展前沿[J], 2021, 3(2): 60-67 doi:10.11871/jfdc.issn.2096-742X.2021.02.007
LIU Chunyu, SHI Zhuomin, YU Jianjun.
引言
借助新一代信息技术驱动管理创新,已成为科研院所数字化建设的研究热点[1] 。数字研究所建设是一个长期持续的过程,信息化只能部分解决科研管理数据问题。例如:针对繁杂的财务数据,报销审批流程电子化一定程度上可提升报销效率。根据财务管理要求,财务人员主要从费用的真实性、合规、合理性及必要性等角度进行审批[2] 。在审批过程中,财务人员由于不了解支出项目具体情况, 需要阅读众多报销原始凭证影像文件。此外,各单位财务管理制度繁杂等原因增加了报销单审批成本。审批单据如存在不符合规定的报销事项,还需要退回修改并反复审批。反复审批增加研发工作负担,不能很好地顺应国家“放管服”政策趋势。机器学习算法能够自动在海量数据中学习其规律和模式,挖掘潜在信息,被广泛应用于分类等问题[3] 。目前,报销审批流程电子化处于发展初期,绝大多数研究偏向报销系统的构建,缺少对报销审批数据的挖掘。已有研究将机器学习算法与财务报销审批结合,主要针对报销审批业务的审批时长进行预测[4] ,但缺乏对审批结果预测的研究。本文旨在通过机器学习算法对历史报销单据的审批数据信息深度挖掘,建立智能化报销审批预测模型[5] ,辅助财务人员进行报销单据审批,助力规范报销流程、提升报销审批效率。为实现报销审批预测,本文对历史数据进行脱敏,形成可用于分析的原始数据;结合历史审批结果数据进行采集、结合业务特点对报销单审批数据进行变量重构以及变量筛选。在变量筛选时采用过滤法和树模型嵌入法:过滤法结合阈值过滤掉贡献不大的特征,树模型嵌入法通过样本数据构造随机森林来确定不同特征的重要度,证实采集变量在构建预测模型的可靠性。文章在变量筛选后分别采用决策树、随机森林[6] 、GBDT分类树以及XGBoost算法[7] 对报销数据进行模拟及分析。本文研究为报销审批智能预测算法逐步代替人工审批提供算法基础,为科研院所单位“报销繁”问题提出解决方案,在科研院所财务报销审批结果预测的应用中有较高的参考价值。
1 财务报销审批数据
原始报销数据经过编写的脱敏工具,将原始数据自动表示为可机读的脱敏数据,如报销人ID、报销单编号用自动生成的ID数字表示,报销部门、人员类型等用自动生成的字符串表示。结合财务报销实际业务情况,本文选取脱敏后的报销审批记录与报销人个人信息记录组成数据源。针对报销审批记录,本文选取报销单编号、报销单类型、支出明细科目、预算科目、报销金额等15项变量;针对报销人个人信息,选取其用户ID、人员类型、年龄、来所年限、报销部门共5项变量。本文基于原始变量,考虑报销审批预测模型的可靠性,为数据源构造新的特征变量“报销人员业务熟练度”,构造标签变量“是否通过审批”。重构后的数据源包含14项变量,12,080条样本。2 数据解读与处理
数据采集作为构造预测模型的基础工作,需要重点考虑变量的选择。将 “原始”输入变量和为输入变量构造的“特征”变量统称为“变量”[8] 。财务报销审批业务还包含诸多冗余变量。理论上讲,更多的变量应提供更多的区分能力;实际上在训练数据量有限的情况下,过多的变量会混淆学习算法,导致分类器过拟合[9] 。2.1 数据清洗
2.1.1 缺失值处理针对报销审批数据源,结合统计学方法,我们检测到原始数据中存在部分在途单据以及在电子化审批上线前的历史迁移数据,需要对这部分数据进行清洗。本文对不包含足量信息的变量及样本进行处理,经过缺失值处理后的数据源包括13项变量,10,074条样本。
2.1.2 离群点和异常值处理
(1)离群点处理
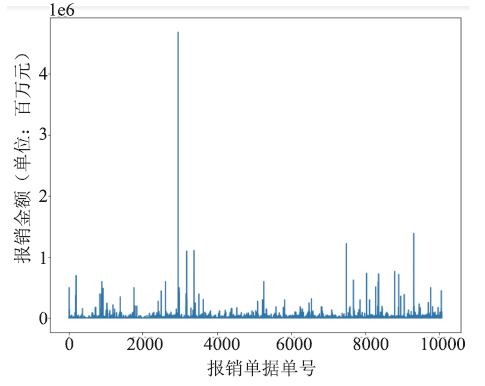
本文对数据源中的数值型数据绘图后发现,“报销金额”存在明显离群点,如图1所示。根据财务报销审批业务选定阈值对离群点进行处理后不同报销单据的报销金额分布如图2所示。
图1
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1报销金额分布(未处理)
Fig.1Distribution of reimbursement amount(untreated)
图2
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2报销金额分布(处理后)
Fig.2Distribution of reimbursement amount(treated)
考虑到正负例样本间不均衡问题,本文对样本中类别属性仅包含单种审批结果的数据根据其语义相似性进行归纳处理。
(2)异常值处理
通过数据统计方法可知,“人员类型”变量中存在“退休”人员。但在实际系统操作中,退休人员本人不会在系统中进行操作,而是委托岗位聘用人员代为操作。为保全数据源样本多样性,本文在处理此部分异常数据时,将退休人员类型样本归并到岗位聘用人员中,同时为弱化极端年龄的影响力,采用年龄特征以及来所年限特征的中位数对这部分异常数据进行更新。
2.2 变量筛选及验证
合宜的变量选择不仅可以提供更快、更经济的预测变量,而且对于提高预测性能也十分重要[10] 。为了使报销审批预测模型更加可靠,本文针对重构后的数据源变量,采用过滤法进行初步变量筛选后,从机器学习的角度验证剩余不同变量的重要度。缩减变量维度的同时,为模型提供可解释性,使得预测结果更为准确。2.2.1 过滤法
过滤法是按照发散性或者相关性对各个变量特征进行评分,并与所设定阈值比较实现特征的过滤。本文中采用方差作为评判标准进行变量的筛选,通过计算各变量的方差后选择方差大于阈值的特征,最终排除“报销年份”、“报销月份”以及“报销单状态”三个变量。“报销单状态”所包含的语义信息可以由报销单最终审批结果(即标签值)囊括。
2.2.2 变量重要度分析
本文采用随机森林算法对不同变量的重要度进行分析。随机森林利用所构造的多棵决策树的输出结果决定其最终输出结果。其中每个决策树的生长都建立在Bootstrap方法[11]构建的训练集上。
本文研究中采用基于基尼指数Gini(p)评估特征重要性:
$\operatorname{Gini}(p)=\sum_{k=1}^{K} p_{k}\left(1-p_{k}\right)=1-\sum_{k}^{K} p_{k}^{2}$
其中k代表k个类别,pk代表类别k的样本权重。
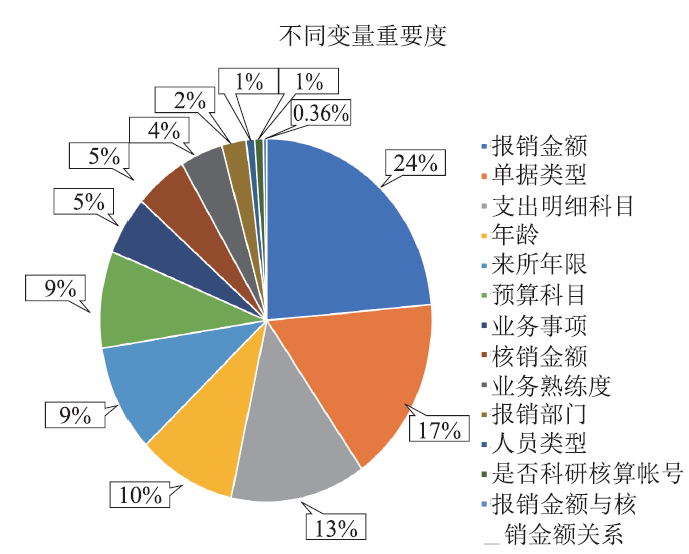
以计算结果中的最重要特征为基准,本文绘制特征重要性饼状图,不同特征的重要度占比如图3所示。
图3
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3变量重要度分布
Fig.3Variable importance distribution
图3表明所有特征中对于审批通过结果影响较大的因素依次为:报销金额、报销单类型、支出明细科目、报销人年龄、来所年限、预算科目、业务事项、业务熟练。相反,报销人部门ID、人员类型、是否科研核算账号以及报销金额与核销金额间关系对报销审批预测结果影响不大。结合实际中报销业务分析后得到的结论与随机森林算法评估结果大致相同。因此,本文认为构造数据集所提取变量合理且有效,为接下来模型的构建奠定良好基础。
2.3 数据预处理
通过观测数据源发现,采集到的数据根据变量属性的不同可分为有序型变量、类别型变量和数值型变量三种不同类型。本文对于不同类型变量对应的数据采取不同的数据处理方式。有序型变量包括:业务熟练度、报销金额与核销金额间关系以及是否科研核算账号。针对此三项变量包含的数据,本文为不同类别进行标定,如:(1)业务熟练度共分为“很不熟练”、“不熟练”、“普通”、“熟练”四个等级,按照等级高低采用Replace方法做替换。(2)报销金额与核销金额间关系共有“大于”、“等于”、“小于”三种,同样采用Replace方法直接替换。(3)对于是否科研核算账号采用0/1二值化。
类别型变量包括:支出明细科目、业务事项、报销单类型等六项变量。由于每一项变量中均有多种类别,因此本文采用标签编码技术对特征数据中的文本内容进行编号。为变量的n个唯一取值分类[0, n-1]之间的编码,实现文本与连续数值型变量的转换。
数值 型变量包括:报销人年龄、来所年限、报销金额以及核销金额。针对数值型变量数据,本文对此类型数据选择Min-Max归一化处理,归一化公式如下:
$x^{*}=\frac{x-x_{m i n}}{x_{\max }-x_{\min }}$
其中$x_{max}$为样本数据中的最大值,$x_{min}$为样本数据中的最小值。$x^{*}$为数据源在[0,1]之间的线性映射。
3 基于树模型的审批结果预测
3.1 模型选择
通过观测报销审批数据可知,其中数值型变量占比低于多分类的类别型变量。为避免类别型变量数据标签化后的距离计算不准确,选用对空间距离影响小的树模型实现报销单审批结果的预测。3.2 评价指标
财务报销审批预测属于二分类问题。为了评价各模型在报销审批预测应用中的性能优劣,本文引入混淆矩阵衡量不同分类模型在测试样本上的性能。具体采用4个常规评价指标:准确率(Accuracy)、精确度(Precision)、召回率(Recall)以及F1值(F1 score)。准确率(Accuracy)指的是正例及负例中预测正确的数量与总数量间的比例。通常Accuracy被认为是最直观评估模型好坏的指标。但是在本报销审批结果预测应用中,由于正负例样本间不均衡,故还需要引入其他指标进行评估,Accuracy计算公式如下:
$\text { Accuracy }=\frac{T P+T N}{T P+F P+T N+F N}$
精确度(Precision)又称为“查准率”,是以预测结果为判断依据,观测预测为正例的样本中预测正确的比例。同样因正负例样本不均衡,预测结果中预测为正的比例很大,即Precision结果偏大,所以单纯采用Precision指标评价模型性能是不完整的,还需要结合召回率(Recall)。精确度Precision计算公式如下:
$\text { Precision }=\frac{T P}{T P+F P}$
召回率(Recall)又称为“查全率”,不同于精确度的以预测结果为依据,召回率是以实际样本作为判断依据。召回率Recall计算公式如下:
$\text { Recall }=\frac{T P}{T P+F N}$
F1值(F1 score)是查准率和查全率的一个加权平均,F1值把假反例和假正例都考虑在内,尽管它不像Accuracy这么容易理解,但是在本文研究的报销单审批结果预测场景中F1比Accuracy更为适用,因为报销单审批数据集中类别分布并不均衡。F1值计算公式如下:
$\begin{array}{r}F_{1}=\left(\frac{2}{r e c a l l^{-1}+\text { precision }^{-1}}\right) \\=2 * \frac{\text { precision } * \text { recall }}{\text { precision }+\text { recall }}\end{array}$
3.3 实验结果
本实验以决策树算法为Baseline,各树模型算法应用于报销审批数据的性能如表1 所示。Table 1
表1
表1报销审批预测模型实验结果
Table 1
| DT | FR | GBDT | XGBoost | |
|---|---|---|---|---|
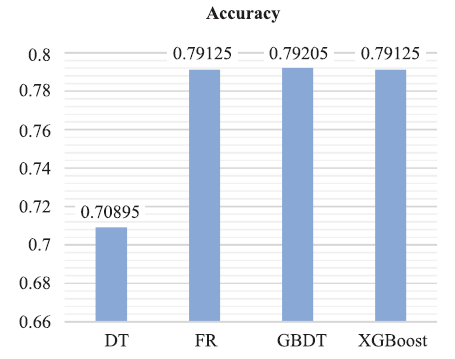
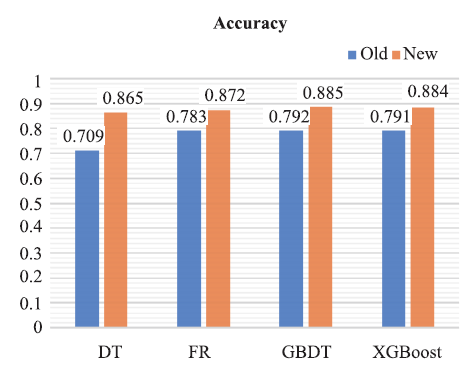
| Accuracy | 0.709 | 0.783 | 0.792 | 0.791 |
| Precision | 0.823 | 0.819 | 0.796 | 0.814 |
| Recall | 0.802 | 0.933 | 0.992 | 0.956 |
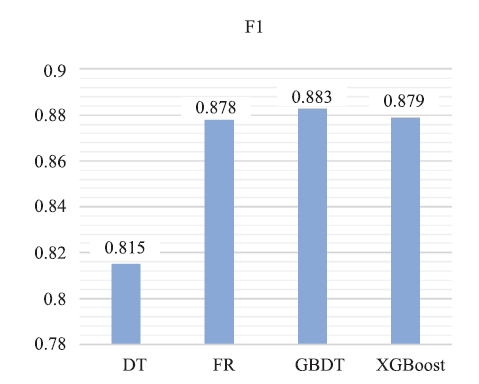
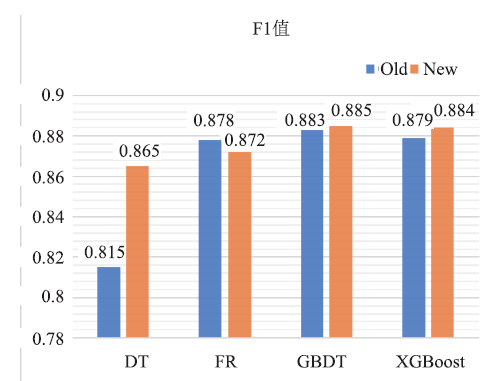
| F1 | 0.813 | 0.872 | 0.883 | 0.879 |
新窗口打开|下载CSV
由图4~图7可知:GBDT模型在除Precision指标外的其余三项指标中均优于其他模型。F1值综合考虑Precison指标与Recall指标,故本文在这里着重观测F1值与Accuracy的结果。从图中可以直观看出,四个模型中决策树模型(DT)在报销单审批结果预测场景中是表现最差的,其余三个模型更为适用于此场景。GBDT分类树在此场景准确率为0.792,F1值为0.883,在所有模型中表现最优。
图4
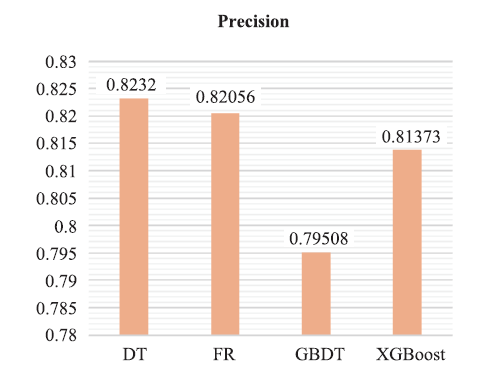 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4精确度对比图
Fig.4Precision chart
图5
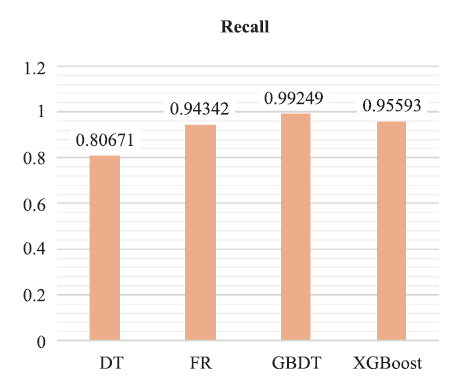 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5召回率对比图
Fig.5Recall chart
图6
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6F1值对比图
Fig.6F1-score chart
图7
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7准确率对比图
Fig.7Accuracy chart
3.4 模型优化
在报销单审批结果预测场景中,各分类器均包含多个参数,而内置参数的选择将直接影响到预测结果的准确性。因此借鉴贪心算法[12] 的思想,结合网格搜索[13] 和交叉验证,针对应用场景中的四种树模型进行优化。具体步骤为:依次对当前对模型影响最大的参数调优并通过交叉验证进行评价,直到所有的参数调整完毕。对模型进行优化后的结果如表2所示。Table2
表2
表2报销审批结果预测模型优化后的实验结果
Table2
| DT | FR | GBDT | XGBoost | |
|---|---|---|---|---|
| Accuracy | 0.864 | 0.873 | 0.885 | 0.884 |
| Precision | 0.805 | 0.820 | 0.794 | 0.799 |
| Recall | 0.932 | 0.934 | 1.00 | 0.989 |
| F1-score | 0.864 | 0.873 | 0.885 | 0.884 |
新窗口打开|下载CSV
由图8~图9可知:经过优化后的模型在F1值与Accuracy指标中均有提升。结合图例可知,在优化后的四种树模型中,表现最佳的仍为GBDT分类树,且优化后的GBDT分类树在报销单审批结果预测场景中准确率由0.792提升到0.885。
图8
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8调优前后F1值对比图
Fig.8Comparison chart of F1-score
图9
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图9调优前后准确率对比图
Fig.9Comparison chart of accuracy
4 结论与展望
在上述实验过程及结果中,本文就报销审批数据进行研究,通过对数据的采集、数据源的重构以及对重构后变量的重要度分析,结合四种树模型对财务报销审批结果进行预测。文章从变量重要度分析以及预测模型的构建两方面进行总结。采用随机森林算法对数据源变量进行重要度分析,旨在将实际业务与机器学习算法融合。使用机器学习算法分析提取变量的可靠性,进一步提高后期构建模型的可解释性。实验结果显示,筛选及重构后的数据源变量对于审批结果预测均具有一定指导作用。“报销金额”、“报销单类型”、“支出明细科目”、“业务熟练度”等因素在实际审批流程中确实是主要考虑因素。基于此分析结果,财务人员在财务报销单审批时可将注意力集中于以上几项变量,提高审批效率。
本文分别采用四种树模型算法实现财务报销审批预测模型的构建,采用四种二分类任务中最为常用的评价指标,对四种模型分别进行性能评估。之后加入网格搜索和交叉验证优化模型。在财务报销审批预测应用场景中,涉及到有序性、类别型和数值型三种不同类型的数据,通过对比各模型预测结果发现:无论优化前后均为GBDT分类树效果最佳,且模型在优化后准确率有明显提升。究其原因,是GBDT分类树在面对多种不同类别数据时的处理能力优于其他模型;在同等优化条件下的GBDT分类树得到的结果更优。
总体而言,本文所研究的基于树模型的财务报销审批预测模型对于辅助科研人员进行财务报销单智能审批,提升审批效率具有重要意义。但由于各科研院所报销流程和管理制度不尽相同,模型是否具有普适性,还需要经过更多研究所授权后获取报销数据从而进行模型训练,以提高模型的通用性。当然,由于该项研究内容在财务审批领域还处于起步阶段,受报销系统部分数据无法结构化、报销经办人操作不规范、各单位财务管理要求多样化等客观条件限制,目前预测的精确度仍有提升空间。随着管理日益成熟、信息化水平不断提升、算法模型不断优化,基于树模型的财务报销审批预算在科研院所应用前景广阔。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[D].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1023/A:1010933404324URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1111/test.2001.23.issue-2URL [本文引用: 1]
[J].
DOI:10.1162/neco.2006.18.7.1527URL [本文引用: 1]
[J].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}