 ,1,2, 王鹏飞,3, 张峰,1,2, 刘海龙,3, 林鹏飞,3, 王涛,1, 韦俊林,1,2, 田少博,1,2, 姜金荣,1,*, 迟学斌,1
,1,2, 王鹏飞,3, 张峰,1,2, 刘海龙,3, 林鹏飞,3, 王涛,1, 韦俊林,1,2, 田少博,1,2, 姜金荣,1,*, 迟学斌,1The Implementation and Optimization of LICOM on GPUs
Zhang Liuying,1,2, Wang Pengfei,3, Zhang Feng,1,2, Liu Hailong,3, Lin Pengfei,3, Wang Tao,1, Wei Junlin,1,2, Tian Shaobo,1,2, Jiang Jinrong,1,*, Chi Xuebin,1通讯作者: * 姜金荣(E-mail:jjr@sccas.cn)
收稿日期:2020-03-13网络出版日期:2020-08-20
| 基金资助: |
Received:2020-03-13Online:2020-08-20
作者简介 About authors

张留莹,中国科学院计算机网络信息中心,在读硕士研究生,主要研究方向为高性能计算与应用。
本文承担工作为:LICOM3程序在GPU上的代码实现,应用测试。
Zhang Liuying is a master student at Computer Network Information Center of the Chinese Academy of Sciences. Her main research interests are high-performance computing and applications.
In this paper she undertakes the following tasks: code implementations of LICOM3 on the GPUs and its testing.
E-mail:

王鹏飞,中国科学院大气物理研究所,高级工程师,主要研究方向为数值模拟、气候系统模式研发与应用、海气相互作用、可预报性。
本文承担工作为:LICOM3程序的开发指导,正确性验证。
Wang Pengfei is a senior engineer at Institute of Atmospheric Physics, Chinese Academy of Sciences. His main research interests are numerical simulation, development and application of climate system models, air-sea interaction and predictability.
In this paper he undertakes the following tasks: research guidance of LICOM3 and the correctness verification.
E-mail:

张峰,中国科学院计算机网络信息中心,在读博士研究生,主要研究方向为高性能计算与应用。
本文承担工作为:LICOM3程序在GPU上的代码实现,应用测试。
Zhang Feng is a PhD student at Computer Network Information Center of the Chinese Academy of Sciences. His main research interests are high-performance computing and applications.
In this paper he undertakes the following tasks: code implementations of LICOM3 on the GPUs and its testing.
E-mail:

刘海龙,中国科学院大气物理研究所,研究员,主要研究方向为海洋环流及其数值模拟。
本文承担工作为:LICOM3程序开发指导,正确性验证。
Liu Hailong is a research fellow at Institute of Atmospheric Physics, Chinese Academy of Sciences. His main research interests are ocean circulation and its numerical simulation.
In this paper he undertakes the following tasks: research guidance of LICOM3 and the correctness verification.
E-mail:

林鹏飞,中国科学院大气物理研究所,研究员,主要研究方向为海气相互作用、海洋模式发展、海洋生物与物理相互作用。
本文承担工作为:LICOM3程序开发指导。
Lin Pengfei is a research fellow at Institute of Atmospheric Physics, Chinese Academy of Sciences. His main research interests are ocean modeling, physical oceanography, aquatic ecosystems, air-sea interactions and their climate effects, mesoscale eddies.
In this paper he undertakes the following tasks: development guidance of LICOM3.
E-mail:

王涛,中国科学院计算机网络信息中心,工程师,主要研究方向为高性能计算。
本文承担工作为:LICOM3程序在GPU上实现。
Wang Tao is an engineer at Computer Network Information Center of the Chinese Academy of Sciences. His main research interests is high performance computing.
In this paper he undertakes the following tasks: code implementations of LICOM3 on the GPUs.
E-mail:

韦俊林,中国科学院计算机网络信息中心,在读硕士研究生,主要研究方向为高性能计算与应用。
本文承担工作为:LICOM3程序在GPU上实现。
Wei Junlin is a master student at Computer Network Information Center of the Chinese Academy of Sciences. His main research interests are high-performance computing and applications.
In this paper he undertakes the following tasks: code implementations of LICOM3 on the GPUs.
E-mail:

田少博,中国科学院计算机网络信息中心,在读博士研究生,主要研究方向为高性能计算和科学计算。
本文承担工作为:LICOM3程序在GPU上实现。
Tian Shaobo is a PhD student at Computer Network Information Center of the Chinese Academy of Sciences. His main research interests are high performance computing and scientific computing.
In this paper he undertakes the following tasks: code implementations of LICOM3 on the GPUs.
E-mail:

姜金荣,中国科学院计算机网络信息中心,研究员,主要研究方向为并行算法与框架软件、计算地球科学。
本文承担工作为:LICOM3程序在GPU上整体结构设计,研究指导。
Jiang Jinrong is a research fellow at Computer Network Information Center of the Chinese Academy of Sciences. His main research interests are parallel computing algorithms and frameworks.
In this paper he undertakes the following tasks: the design of overall structure and research guidance of LICOM3 on GPUs.
E-mail:

迟学斌,中国科学院计算机网络信息中心,研究员,主要研究方向为高性能计算、并行计算。
本文承担工作为:LICOM3程序并行算法设计指导。
Chi Xuebin is a research fellow at Computer Network Information Center of the Chinese Academy of Sciences. His main research interests are high performance computing and parallel computing.
In this paper he undertakes the following tasks: the research guidance of LICOM3 on GPUs.
E-mail:

摘要
【目的】为了加速海洋环流模式LICOM的积分计算,降低因分辨率的提升而带来的运行成本,本文设计并实现了基于CUDA C的GPU加速版本。【方法】本文基于目前最新的LICOM3版本,在分析LICOM海洋网格块的并行算法的基础上,结合使用CUDA线程并行计算海洋网格点,将LICOM主要计算程序移植到GPU平台上,并从数据传输和设备内存的使用两个方面进行优化。【结果】实验表明,GPU版本模拟结果的与原CPU版本基本一致。与使用相同数量的Intel Xeon E5-2680 V2 CPU相比,使用2至16块NVIDIA K20 GPU单个模式天加速了9.31到1.27倍。【局限】由于LICOM3计算的边界同步通信比较多,限制了程序的可扩展性,未来需要通过边界通信优化和算法优化来提高模式的可扩展性。【结论】本文对LICOM3程序进行了GPU版本的实现和优化,取得了一定的加速效果并保持较好的扩展性,为今后面向更大规模计算的海洋环流模式发展提供了经验和参考。
关键词:
Abstract
[Objective] In order to accelerate the calculation of the LICOM oceanic circulation model and reduce the cost caused by the high resolution, this paper designs and implements a GPU accelerat-ed version using CUDA C. [Methods] Based on the latest version of LICOM3, this paper analyzes the parallel algorithms of ocean grid block, and uses CUDA threads to calculate the grid points in parallel, which enables porting of the main program of LICOM to the GPU platform, and data transmission and device memory usage are optimized. [Results] Experiments show that the simulation results of GPU version program are basically same as the original CPU version program, while achieving 9.31x to 1.27x speedup on 2 to 16 NVIDIA K20 GPUs compared with the same number of Intel Xeon E5-2680 V2 CPUs. [Limitations] Because there are many boundary synchronous communications in LICOM3, which limits the scalability of the program, and it is necessary to improve the scalability of the model through boundary communications optimization and algorithm optimization. [Conclusions] This paper implements and optimizes the GPU version of the LICOM3 program, achieves some speedup and keep a good scalability, which provides experience and reference for the development of larger-scale oceanic circulation model in the future.
Keywords:
PDF (13769KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
张留莹, 王鹏飞, 张峰, 刘海龙, 林鹏飞, 王涛, 韦俊林, 田少博, 姜金荣, 迟学斌. 海洋环流模式LICOM的GPU实现与优化. 数据与计算发展前沿[J], 2020, 2(4): 92-104 doi:10.11871/jfdc.issn.2096-742X.2020.04.008
Zhang Liuying, Wang Pengfei, Zhang Feng, Liu Hailong, Lin Pengfei, Wang Tao, Wei Junlin, Tian Shaobo, Jiang Jinrong, Chi Xuebin.
开放科学标识码(OSID)

引言
海洋环流模式是一个包含遥感、计算机和动力学等多学科研究课题。通过遥感进行监测和分析,利用动力学方法在理论上模拟海洋环流的变化并建立偏微分方程,通过计算机求解,预测在未来某个时刻海洋的高度、温度、盐度等重要因素。LICOM(LASG/IAP Climate system Ocean Model)是由中国科学院大气物理研究所(IAP)大气科学和地球流体力学数值模拟国家重点实验室(LASG)自主研发的全球海洋环流模式,它是中国科学院地球系统模式CAS-ESM的重要组成部分[1, 23],而CAS-ESM 又是开展全球变化研究的主要工具。IAP海洋环流模式经历了长足的发展,分辨率从20 世纪 80 年代后期第一代模式[2]的5°(赤道上经纬度1°约等于 111km)提高至2001年第四代模式LICOM1[3]的0.5°。目前,LICOM已经发展了三个版本,LICOM3[4]是一个分辨率为7km的全球版本。模式的分辨率不断提高使得模式的计算量大幅增加,这导致的一个严重问题是运行代价变的很大,一是运行时间很大,二是在大型机器运行的费用很高[5,6]。高分辨率海洋模式是科学研究的重要手段,也是提高海洋预报精度的重要技术。面向更大规模计算的全球超高分辨率海洋模式是未来几十年的研究方向,对海洋环流模式的并行加速研究已经成为了模式发展的必要条件。
目前国内已经有很多针对LICOM进行的并行加速研究。2015年,王文浩等人基于LICOM2应用OpenMP和指令优化等手段进行MIC移植优化[7],整体加速了2.09倍。MIC是一个众核协处理器,每个处理器有几十个核,每个核都是基于X86架构,控制性能与CPU相似,虽然降低了程序实现的难度,但是增加了优化的代价。2017年,赵晓溪等人针对LICOM2进行并行框架SC_Tangram移植[8],有效的增加了程序的可维护性和开发效率,但是程序性能与移植前基本一致。 2019年,Jinrong Jiang等人基于LICOM2使用OpenACC从通信掩藏和循环优化等方面进行GPU移植优化[9],整体加速了6.6倍。GPU与MIC一样都是众核协处理器,不同的是GPU有成百上千个核,每个核只有计算单元,多个核共用相同的控制单元。相比于MIC,GPU的并行优化更加可控和高效。OpenACC 是基于指令的GPU并行编程标准,编译器会自动的管理数据移动、启动并行执行和优化循环、将代码映射到GPU中。OpenACC为编程人员提供了一个相对学习成本较低的编程模型,但是在性能优化方面存在较大的局限性,应用程序不能充分的利用硬件资源,与完全优化的CUDA程序相比存在明显的性能差距。Hoshino T等人使用两个微基准测试和一个计算流体动力学应用程序对比了OpenACC和CUDA的性能差异[10]。两项评估均表明OpenACC性能比CUDA约低50%,对于某些使用CUDA精心优化的应用程序,这种性能差异可达98%。CUDA相对于OpenACC属于更底层的编程语言,为编程人员提供了更多的硬件资源控制接口,性能优化空间更大,但是程序实现难度也更大、周期更长。目前已有的针对LICOM加速研究成果并没有充分发挥GPU平台的优势,而且程序的扩展性受到了限制。
GPU(Graphics Processing Unit)已经成为高性能计算系统和科学应用中一个重要的加速解决方案[11-13, 23, 24],它是一个通用的、可编程的、数据和任务并行的、低成本的、高性能处理器,CUDA为GPU提供了更加高效、通用的编程模型。2013年,Huadong Xiao等人使用CUDA将天气预报模式GRAPES中最耗时的WSM6模块进行GPU并行加速优化[14],获得了近140倍的加速。2012年,Mielikainen等人通过使用CUDA将天气预报模式WRF中的Goddard太阳辐射传输模块进行GPU移植优化[15],获得了116倍的加速。2012年,郭松等人采用CUDA编程模型将POP海洋环流模式移植到GPU平台上[16],获得了8.47倍的加速。2013年,王春晖等人使用CUDA将非静压海洋数值模式进行GPU加速优化[17],获得了142倍的加速。GPU为大型应用的加速提供了可行方案,为LICOM更加便捷高效的研究提供可能。LICOM网格点与GPU线程一一对应的关系使其具有天然的可并行性。与此同时也存在着很多困难,例如LICOM海洋模式具有变量多、计算分散、分支计算多、计算访存比低、上下文依赖严重、通信同步多、代码量大等特点。
本文使用CUDA C对LICOM3进行GPU移植,将网格点映射为CUDA线程进行加速,并从主机与设备的数据传输、GPU内存使用方面对并行算法进行了优化。第1节介绍LICOM程序的基本计算流程和特点;第2节介绍GPU架构、CUDA编程模型和LICOM在GPU上实现;第3节介绍LICOM在GPU上的优化手段;第4节介绍实验环境,进行正确性验证和性能分析。
1 LICOM算法基本原理
LICOM数值模式可以归结为利用离散的时间和空间差分求解一组偏微分方程[18],包括动量方程、热力学方程、盐度方程、海水状态方程和太阳辐射、长波辐射等一系列参数化过程。海洋环流主要受海洋表面的风力作用影响和海水温盐度变化的影响,同时还受地球重力、地球自转和不同的波动等多方面的影响,其中重力外波速度快尺度小、重力内波速度慢尺度大等特点,使得模式的动量方程分为正压模态(Barotropic)和斜压模态(Baroclinic)两个独立的部分,正压模态负责二维外波积分,斜压模态负责三维内波积分。1.1 LICOM程序结构
如图1所示,LICOM模式运行的流程总体上分为三个阶段:图1
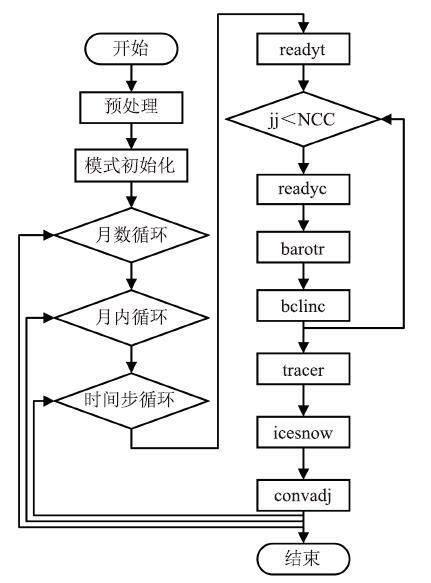 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1LICOM计算流程
Fig.1LICOM calculation flowchart
(1)预处理阶段。主要进行处理器设置和数据划分等;
(2)模式初始化阶段。主要进行初始数据的导入和迭代变量的设置[19],通过Netcdf将nc格式的源数据读入模式;
(3)模式迭代计算阶段。是整个模式的核心计算部分,是本文进行GPU移植目标程序。核心的7个积分计算模块分别为正压斜模态积分的预处理(readyc模块,readyt模块)、正压模态积分(barotr模块)、斜压模态积分(bclinc模块)、热盐积分(tracer模块)、海冰积分(icesnow模块)、GFDL全对流调整(convadj模块),包含在月数循环、月内循环、日内时间步循环这三层循环内。正压模态积、斜压模态积分和热盐积分采用不同时间步长的蛙跳形式进行迭代[18],每个模式天的积分迭代中,正压模态每积分Nbarotr时间步(步长为Tbarotr),斜压模态就积分一个时间步(步长为Tbclinc=Nbarotr×Tbarotr);在正斜压模态耦合积分Nbclinc个时间步后,热盐积分一个时间步(步长为Ttracer = Nbclinc × Tbclinc)。
1.2 LICOM海洋网格块并行方案
海洋在水平方向以交错的经纬度为坐标被离散为的二维网格点,纬度方向分为imt_global个网格点,经度方向分为jmt_global个网格点。垂直方向以海洋深度为坐标分为km层,海洋被离散成一个三维结构,在这基础上将海洋网格点组织为网格块,每个网格块包含了BLCKX×BLCKY×km个网格点。网格块与网格块之间存在正压模态通信,层与层之间会存在相互的压力和垂直速度的计算。如图2所示,整个海洋被分为了ceil(imt_global/ BLCKX)×ceil(jmt_global/BLCKY)个海洋网格块,其中ceil为向上取整函数。为了提高差分求解的效率,LICOM采用MPI进行网格块并行加速,为每个进程分配NBLOCKS_CLINIC个网格块,网格块内部的网格点串行计算。图2
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2网格块划分
Fig.2Ocean grid
每个网格有自己独立的计算数组,数组的规模随着并行度的增大而减小。因为差分计算需要邻接网格的边界值,所以需要频繁的进行网格边界数据通信,每个网格的计算数组根据二维逻辑上相邻进程的数组边界来更新。所以每个网格的计算数组除了存储本网格内的数据外还存储着邻接网格的边界数据(又称为“伪边界”,本地数组的边界称为“实边界”)。LICOM采用“可伸缩伪边界”的策略[18],即伪边界的条数可根据具体问题来确定。如图2右的深色部分显示了海洋网格块的“伪边界”,在程序中声明为变量ghost并赋值为2。相比于一条伪边界,将伪边界设置为两条,可以进行两次计算数组更新只进行通信一次,能够有效的降低通信计算比。
图3显示了在一次迭代中网格点的计算过程[18],首先进行网格块两条伪边界的更新:网格块1中的实边界c和d分别传递给网格块2的伪边界b和a,网格块2中的实边界c和d传递给网格块1的伪边界b和a;然后进行实边界更新:网格块1内部向右更新至b、网格块2内部向左更新至b;最后进行内部网格点的更新:网格块1内部向右更新至c、网格块2内部向左更新至c。
图3
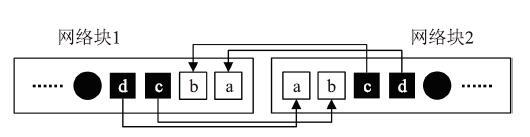 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3网格块边界通信
Fig.3Ocean grid boundary communication
1.3 LICOM3程序性能测试与分析
本文对LICOM3原CPU程序进行性能测试并分析热点模块。如图4所示,分别使用1(20)、2(40)、4(80)、8(160)个计算节点(MPI进程数量)测试了单个模式天内各个模块迭代计算的耗时占比。我们可以看出随着计算节点个数的增加、程序的并行度在增加、海洋网格块的大小在减小,整个模式的热点模块也随之改变。对于readyc这样计算密集的模块,在计算节点个数较少的情况下成为程序中影响最大的因素。对于barotr、bclinc、tracer等通信密集的模块,随着并行度的增加,单个进程通信量的占比在增加,在计算节点个数较多的情况下成为程序中影响最大的因素,限制着程序的可扩展性。对于icesnow、convadj这两个模块,运行时间占比一直小于1%,对整个LICOM程序性能的影响比较小。图4
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4各个模块的运行时间占比
Fig.4Time proportion of each module
2 LICOM在GPU上的实现
2.1 GPU架构
GPU是一种众核架构处理器[20],如图5所示,每个GPU卡包含多个流式多处理器SM(Streaming Multiprocessors),每个SM包含多个流处理器SP(Streaming Processors)、共享内存等部件。以Tesla K20为例,每个处理器包含15组SM,每组SM包含192个SP。一个SM上可以同时承载着多个线程块(Block),可同时并发执行数百个线程(Thread)。每个Block内的Thread被划分为每32个一组的线程束(wrap),以wrap为单位进行调度。GPU是CPU的一种协处理器,并不是一个独立运行的平台,必须通过PCIe总线与CPU相连,所以我们将CPU称为主机端(Host),GPU称为设备端(Device)。CPU+GPU异构系统上执行的应用通常由CPU进行数据初始化、设备端内存分配、数据拷贝和核函数的启动,GPU负责计算密集的程序部分的加速。这样的异构系统能够与充分发挥各自的特长,极大程度上加速了应用程序的计算。
图5
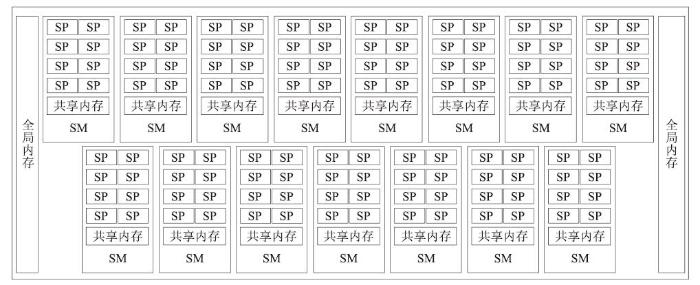 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5GPU架构
Fig.5GPU architecture
2.2 CUDA编程模型
CUDA编程模型[20]使得编程人员能够使用熟悉的C语言实现核函数(Kernel ),多个Kernel可以重叠运行在同一个GPU上。由于CUDA编程模型是异步的,Kernel也可以与CPU计算重叠执行。为了保持同步,可以显式的通过调用cudaDeviceSynchronize函数来实现,也可以隐式的通过调用变量拷贝cudaMemcpy函数来实现。CUDA程序是灵活、可扩展的,线程按照线程、线程块、线程格的多层次模型组织起来,通过各个层次的编号可以唯一的标识某个线程。一个Kernel开启一个线程格(Grid),Grid会被组织成三维的线程块,相同Grid内的Block可以通过blockIdx(x, y, z)唯一的标识。Block被组织成三维的线程,相同Block内的Thread通过threadIdx(x, y, z)唯一标识。
CUDA存储模型按照访问速度从快到慢分别为寄存器、共享内存、常量内存、全局内存和局部内存。如图6所示,寄存器和共享内存都是片上存储空间,供SM上的所有活跃线程使用,其中寄存器是不可编程的且属于线程私有,共享内存由同一个Block内的线程共享。全局内存、局部内存和常量内存都位于片外显存中,其中全局内存和常量内存由同一个Grid内的线程共享,而局部内存属于线程私有且不能合并访存。
图6
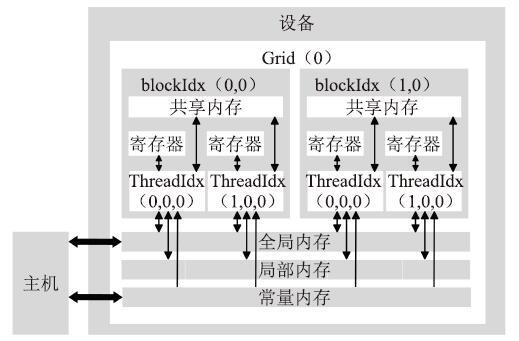 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6CUDA编程模型
Fig.6CUDA programming model
2.3 LICOM在GPU上的实现
本文将LICOM迭代计算过程中的7个模块使用CUDA C进行GPU移植,其他的预处理部分、模块初始化部分以及MPI通信部分仍保留原来的Fortran程序。在MPI并行计算海洋网格块的基础之上,结合使用CUDA线程并行计算海洋网格点。如图7所示,每个MPI进程负责一个海洋网格块的计算,海洋网格块内的网格点由GPU线程并行执行。图7
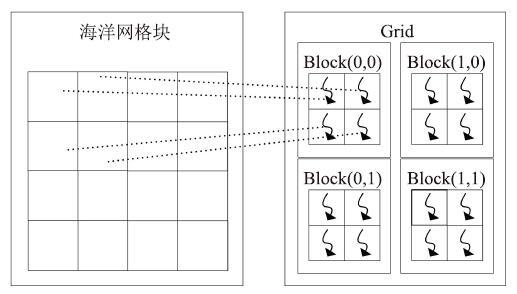 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7海洋网格点与CUDA线程的映射
Fig.7Mapping of ocean grid points to CUDA threads
表1和表2显示了LICOM程序片段的Fortran实现与CUDA实现的对应关系,CPU中的全局变量映射到GPU上的全局内存中,例如CPU全局变量VIV,在GPU申请为全局内存变量d_viv。
Table 1
表1
表1Fortran版本的程序片段
Table 1
| Example: vinteg.F90 |
|---|
| 25 DO IBLOCK = 1, NBLOCKS_CLINIC 26 DO K = 1, KM 27 DO J = 1, JMT 28 DO I = 1, IMT 29 WK2(I,J,IBLOCK) += DZP(K) * OHBU(I,J,IBLOCK) * WK3(I,J,K,IBLOCK) * VIV(I,J,K,IBLOCK) 30 END DO 31 END DO 32 END DO 33 END DO |
新窗口打开|下载CSV
Table 2
表2
表2CUDA版本的程序片段
Table 2
| Example: vinteg.cu |
|---|
| 15 i = (blockIdx.x)*blockDim.x + threadIdx.x; 16 j = (blockIdx.y)*blockDim.y + threadIdx.y; 17 if (i < d_imt&&j < d_jmt) { 18 for (k = 0; k < d_km; k++) { 19 d_wk2[j * d_imt + i] += d_dzp[k] * 20 d_ohbu[j * d_imt + i] * 21 d_wk3[k * d_jmt * d_imt + j * d_imt + i] * 22 d_viv[k * d_jmt * d_imt + j * d_imt + i]; 23 } 24 } |
新窗口打开|下载CSV
主机和设备的数据传输是整个应用程序的瓶颈,为了减少CPU-GPU频繁的内存拷贝,本文将GPU的全局内存申请和初始数据的拷贝前置到模式初始化阶段。在模式迭代计算的中间,遇到MPI通信(如barotr模块)的时候,将GPU变量显式的拷贝到CPU,进行MPI通信后再将数据拷贝到GPU上继续进行迭代计算。当模式计算完成后再将数据拷贝回CPU输出计算结果。但是中间的MPI通信是必要的,同时也影响着整个程序的效率。CUDA版本的LICOM程序实现过程大致如下:
(1)CPU进行预处理和模式初始化;
(2)GPU进行内存分配,并且将模式变量初始值拷贝至GPU;
(3)GPU进行模式迭代计算;
(4)GPU把计算结果拷贝回CPU,输出结果。
3 LICOM在GPU上的优化
在GPU上进行程序的性能优化的关键是合理的减少内存访问延迟和设备主机的数据传输延迟[21]。通过nvprof性能分析工具测试核函数和数据传输的时间占比,如图8所示,主机和设备数据传输(memcpyHtoD和memcpyDtoH)占总时间的42%,核函数的执行占总时间的58%。图8
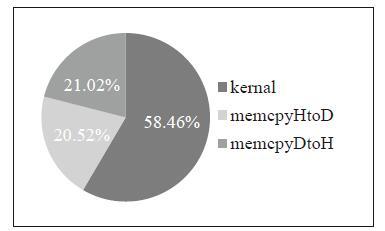 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8核函数和数据传输的时间比例
Fig.8Proportion of kernel and data transmission
3.1 数据传输优化
本文通过使用固定内存和CUDA流进行数据传输优化,减少程序中因MPI通信带来的数据传输的开销。主机上的变量一般存储在可分页内存(Pageable Host Memory)中,GPU设备不可以直接访问可分页内存。如图9左所示,在进行主机和设备的数据传输之前,需要开辟一个临时的固定内存(Pinned Host Memory),将需要传输的数据从分页内存中拷贝到固定内存,最后才将数据从固定内存传输到设备内存中。零拷贝内存其实是一块主机上的固定内存,通过使用零拷贝内存,避免了从分页内存到固定内存的拷贝过程。同时零拷贝内存映射到了设备地址中,允许设备直接访问,避免了显式的数据传输,而且CUDA自动的利用核函数的执行隐藏了数据传输。但是零拷贝内存适合少量的读写,每一次的读写都会产生一次数据传输,过多的使用或者不合理的使用零拷贝内存可能会带来性能的下降。
图9
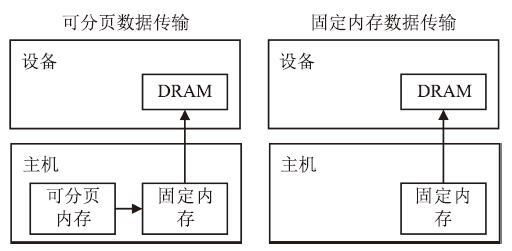 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图9数据传输
Fig.9Data transmission
CUDA流是一系列在设备端异步执行操作,同一个流内操作按照启动顺序执行,不同的流之间相互独立。结合cudaMemcpyAsync函数,通过CUDA流的控制也可以达到隐藏数据传输。
3.2 内存访问优化
本文将核函数中频繁访问的全局变量优化为寄存器内存,用寄存器内存暂存中间计算量。对于通过cudaMemset将全局变量初始化为0的部分,优化为寄存器内存并在Kernel内部进行初始化。通过CUDA提供的cudaDeviceProp可以查询到本文实验所用的Tesla K20允许每个Block(或SM)最多可以使用65536个寄存器(每个寄存器内存为32-bit)。在核函数中定义局部变量,在少量使用局部变量的情况下会分配寄存器内存,寄存器内存的访问延迟较低。但是过多的定义局部变量会适得其反,因为当寄存器的数量不够用的时候,将分配访问速度较慢且不能合并访存的局部内存。所以适当的将核函数局部数组变量改变为全局内存变量,程序能够有效的合并访存,也可以带来性能提升。4 实验结果与分析
4.1 实验平台
本文实验所用的硬件环境为中科院计算机网络信息中心新一代超级计算机“元”。本文主要使用“元”上的GPGPU 异构计算系统,该系统共有30台曙光I620-G15,其中每个GPGPU计算节点配置2颗 Nvidia Tesla K20、2颗 Intel Xeon E5-2680 V2(10 core |2.8 GHz)。本文使用Intel MPI 4.1.3.049搭建MPI环境、CUDA 6.0.37搭建CUDA环境。通过Intel MPI提供的mpiifort编译器编译Fortran程序、CUDA提供的nvcc编译器编译CUDA程序。表3显示本文所用实验环境上单个节点配置情况。Table 3
表3
表3单个计算节点运行环境配置
Table 3
| 硬件/软件名称 | 型号/版本号 | 个数 |
|---|---|---|
| GPU | Nvidia Tesla K20 | 2 |
| CPU | Intel Xeon E5-2680 V2 (10 core | 2.8 GHz) | 2 |
| Intel MPI 4.1.3.0491 | 4.1.3.049 | 1 |
| CUDA | 6.0.37 | 1 |
新窗口打开|下载CSV
4.2 正确性验证
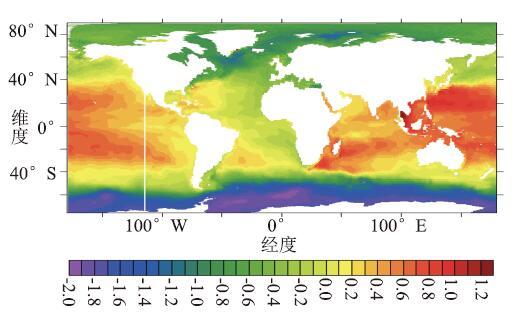
本文对LICOM3的原CPU版本和GPU版本进行独立的测试,对两个版本的模式运行至第1年2月1日瞬时的计算结果进行做差,分别从海表高度(SSH,Sea Surface Height)、海表温度(SST,Sea Surface Temperatures)、海表盐度(SSS,Sea Surface Salinity)三个方面进行验证。从图10-15可以看出,GPU版本与原CPU版本的模拟过程基本一致,计算偏差均在可接受的范围内。图10显示了LICOM3原CPU版本运行至第1年2月1日的瞬时SSH。图11显示了GPU版本在第1年2月1日的瞬时SSH差。GPU版本的SSH计算结果绝对误差平均值为-0.000080145。
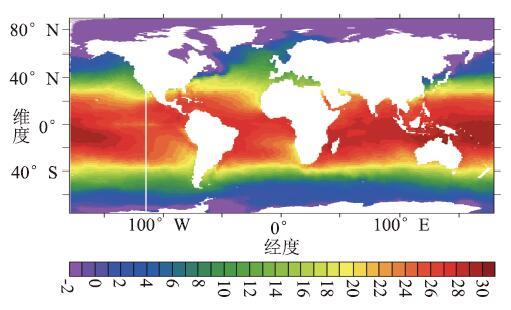
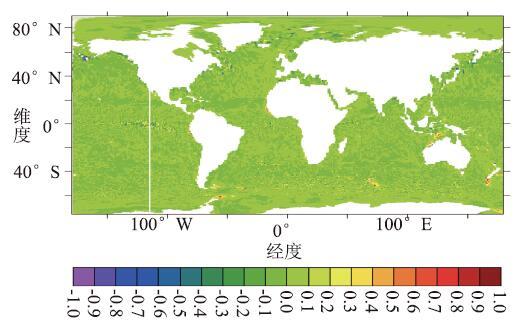
图12显示了LICOM3原CPU版本运行至第1年2月1日的瞬时SST。图13显示了GPU版本在第1年2月1日的瞬时SST差。 GPU版本的SST计算结果绝对误差平均值为-0.00027874。
图10
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图10CPU版本的瞬时SSH(米)
Fig.10Instantaneous SSH of CPU version (meter)
图11
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图11GPU版本的瞬时SSH差(米)
Fig.11Instantaneous SSH deviation of GPU version (meter)
图12
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图12CPU版本的瞬时SST(℃)
Fig.12Instantaneous SST of CPU version (oC)
图13
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图13GPU版本的瞬时SST差(℃)
Fig.13Instantaneous SST deviation of GPU version (oC)
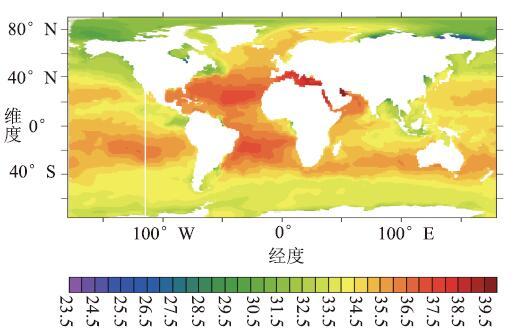
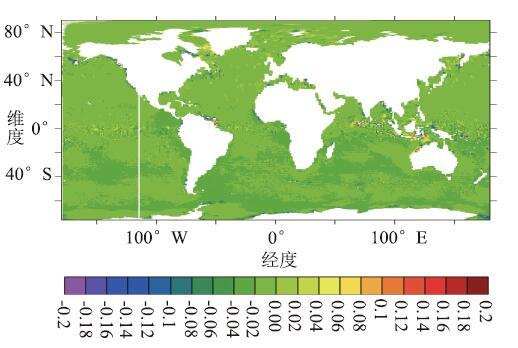
图14显示了LICOM3原CPU版本运行至第1年2月1日的瞬时SSS,图15显示了GPU版本在第1年2月1日的瞬时SSS差, GPU版本的SSS计算结果绝对误差平均值为-0.0021483。
图 14
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 14CPU 版本的瞬时 SSS(PSU)
Fig.14Instantaneous SSS of CPU version (PSU)
图15
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图15GPU版本的瞬时SSS差(PSU)
Fig.15Instantaneous SSS deviation of GPU version (PSU)
4.3 性能分析
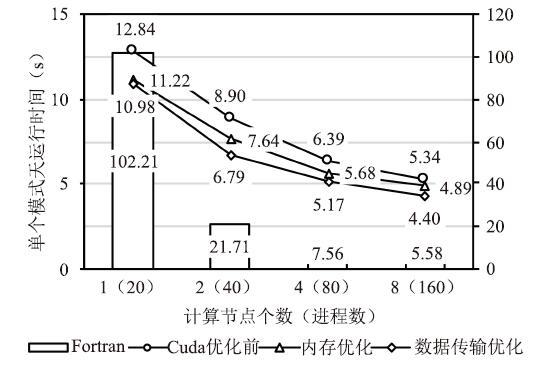
本文对LICOM3的原CPU版本和GPU版本分别通过gettimeofday、cudaEvent来获取运行时间,分别进行独立的性能测试。图16显示了在使用1(20)、2(40)、4(80)、8(160)个计算节点(MPI进程数量)的情况下,原CPU版本和GPU版本单个模式天的运行时间。在使用1个计算节点的情况下(开辟20个进程),原CPU版本的单个模式天运行时间为102.21秒,CUDA版本的运行时间下降到了10.98秒。
图16
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图16GPU版本与原CPU版本的执行时间
Fig.16Runtime of the GPU version and the CPU version
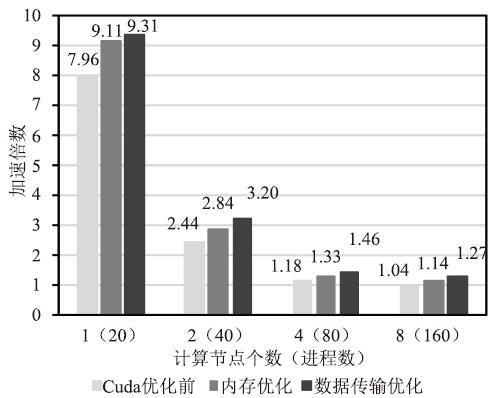
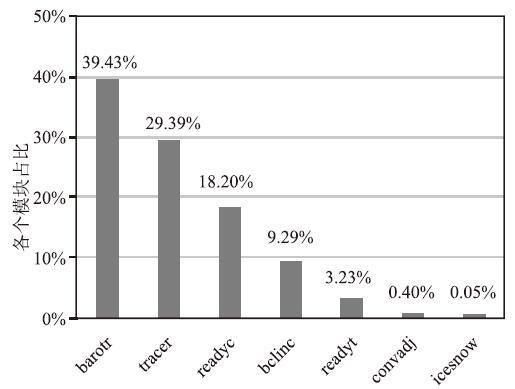
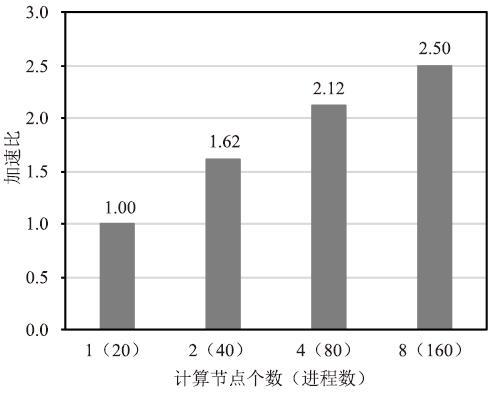
图17显示了对比原CPU版本,GPU版本化前后的加速倍数,使用1至8个计算节点加速了9.31至1.27倍。图18显示了在使用8个计算节点的情况下,GPU版本中各个模块耗时占比,从图中可以看出tracer、barotr、readyc模块是占比最大的三个模块,随着海洋网格块规模的减少,它们会变得更加突出。一是因为GPU适合大规模加速,当海洋网格块的规模减小,计算密集型模块的计算密度随之减小;二是因为通信密集模块中的通信比增大。这造成了在海洋网格块规模小的时候,数据传输时间占比较大、数据访存延迟未被合适的隐藏。图19显示了GPU版本的可扩展性,使用2、4、8个计算节点的加速比分别1.62、2.12、2.5。
图17
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图17优化前后GPU版本比原CPU版本的加速倍数
Fig.17Speedup of the before and after optimization GPU version compared to the CPU version
实验结果表明,GPU版本相对于原CPU版本取得一些加速效果,并具有一定的可扩展性。今后的工作将进一步的扩大数据规模,在更高分辨率的模式上进行测试。为了进一步的增加程序的可扩展性,可以从模式通信算法方面进一步的优化,减少通信次数;还可以通过使用支持CUDA-aware MPI的GPU平台,使得通信函数可以直接访问GPU内存,避免了数据传输的花销。
图18
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图18GPU版本各个模块耗时占比(8个计算节点)
Fig.18Time proportion of each module in GPU version (8 nodes)
图19
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图19GPU版本加速比
Fig.19The speedup of GPU version
5 结论
本文初步完成了全球海洋环流模式LICOM3的CUDA C移植,并利用固定内存和CUDA流等优化方法来提高数据传输效率,测试结果表明移植优化工作取得了一定加速效果。由于LICOM3计算的边界同步通信比较多,造成其可扩展性较差,后续将通过边界通信优化和算法优化来提高模式的可扩展性。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[D].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[EB/OL]. https://www.nvidia.cn/high-performance-computing/,
URL [本文引用: 1]
[J].
[EB/OL]. /,
URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 4]
[J].
[本文引用: 1]
[EB/OL]. https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html,
URL [本文引用: 2]
[EB/OL].https://devblogs.nvidia.com/how-optimize-data-transfers-cuda-cc/,
URL [本文引用: 1]
[J].
[J].
[本文引用: 2]
[J].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}