 ,*成都信息工程大学并行计算与大数据研究所,四川 成都 610225
,*成都信息工程大学并行计算与大数据研究所,四川 成都 610225Sentiment Classification of Microblog Short Text Based on Feature Fusion
CHEN Tao, AN Junxiu,*Institute of Parallel Computing and Big Data, Chengdu University of Information Technology, Chengdu, Sichuan 610225, China通讯作者: 安俊秀(anjunxiu@cuit.edu.cn)
收稿日期:2020-07-23网络出版日期:2020-12-20
| 基金资助: |
Received:2020-07-23Online:2020-12-20
作者简介 About authors

陈涛,成都信息工程大学,硕士研究生,主要研究方向为大数据与并行计算、数据挖掘、自然语言处理。本文主要负责论文撰写、算法设计和实验验证。
CHEN Tao is a MS student of Institute of Parallel Computing and Big Data, Chengdu University of Information Technology. His research interests include Big data and Parallel computing, data mining, and natural language processing.In this paper, he is responsible for the paper writing, algorithm design and experimental verification.E-mail:

安俊秀,成都信息工程大学,教授,成都信息工程大学并行计算与大数据研究所负责人,主要研究方向包括大数据与并行计算、数据挖掘、社会计算等。本文主要负责论文指导和国内外研究现状分析等。AN Junxiu is a professor of Chengdu University of Information Technology and the Director of Institute of parallel computing and big data. Her main research interests include big data and parallel computing, data mining, social computing, etc.In this paper, she is responsible for the paper guidance and literature review, etc.E-mail:

摘要
【目的】随着信息技术和互联网的快速发展,微博等短文舆情的研究对网络舆情的研究十分重要,针对中文短文本信息量小、特征稀疏的特点,研究了微博短文本的情感分类,本文旨在提高微博短文本的特征提取能力以便于对网络舆情进行预测。【方法】为了更好地提取微博短文本的情感特征,本文首先利用BERT(Bidirectional Encoder Representation from Transformers)模型实现文本向量化,再利用卷积神经网络CNN(Convolution Neural Network)进行文本局部语义特征提取,最后将局部语义特征向量和BERT训练的特征向量进行特征融合。该方法有效地解决了短文本特征提取难的特点。【结果】实验结果表明,将该方法提取的文本向量带入到LSTM文本分类模型中,本文模型的分类准确率比BiLSTM+CNN+Attenion模型高出1.24%,比BiLSTM+Attenion模型高出3.22%,比LSTM+Attenion模型高出5.24%,比Text-CNN模型高出6.46%,比SVM高出8.47%。【结论】所提特征融合模型有效提升了文本情感分类的准确率。
关键词:
Abstract
[Objective] With the rapid development of information technology and the Internet, the opinion research of microblog and other public short text is very important to study the network public opinion. Aiming at Chinese short text that represents only a small amount of information with sparse features, this paper studies the sentiment classification of microblog short text. The purpose of this paper is to improve the ability of feature extraction from microblog short text to facilitate the prediction of network public opinion. [Methods] For better motional feature extraction from microblog short text, this paper first uses the BERT model to realize the vectorization of the text, then uses CNN to extract the local semantic features of the text, and finally combines the local semantic feature vector and the feature vector trained by BERT. This method effectively solves the problem of feature extraction for Chinese short text. [Results] The experimental results show that the classification accuracy of this model is 1.24% higher than that of BiLSTM+CNN+Attenion model, 3.22% higher than BiLSTM+Attenion model, 5.24% higher than LSTM+Attenion model, 6.46% higher than Text-CNN model and 8.47% higher than SVM. [Conclusions] The proposed feature fusion model effectively improves the accuracy of text sentiment classification.
Keywords:
PDF (6514KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
陈涛, 安俊秀. 基于特征融合的微博短文本情感分类研究[J]. 数据与计算发展前沿, 2020, 2(6): 21-29 doi:10.11871/jfdc.issn.2096-742X.2020.06.003
CHEN Tao, AN Junxiu.
引 言
随着信息技术和互联网的快速发展,人们的生活跟互联网已经紧密地融为一体。人们每天通过社交媒体和各种应用软件发表自己的见解、情感、评价和一些舆论,为互联网产生了大量的文本信息。然而如何从这些海量的文本数据中及时地发掘出有用的情感信息是一个巨大的挑战。文本情感分析又称意见挖掘或评论挖掘[1,2],作为自然语言处理(Natural Language Processing)的热门任务之一,由Nasukawa等[3]于2003 年首次提出。短文本情感分析主要对微博、微信、电商买家评价、时事新闻评论等主观性短文本进行情感分类。不同于普通文本的情感分类,由于短文本表达简洁、携带特征少,所以加强短文本情感特征提取能力的研究一直是情感分析领域的难点和重点。目前,文本情感分析的方法主要有三种:基于情感词典的方法、基于传统机器学习的方法、以及基于深度学习的方法。
情感词典最早可以追溯到1998年,由Whissell[4]等提出。基于情感词典的方法主要是根据情感知识构建情感词典,词典的好坏对情感分类的影响很大,在针对短文本处理方面,随着研究的深入,众多方法被提出。Andreevskaia等[5]提出一种利用情感标签抽取WordNet带有情感形容词的方法来构建情感词典。陈珂等[6]提出一种基于情感词典和Transformer结合的情感分类方法,该方法不仅充分利用了情感词典的特征信息,还将词与词之间的关联信息融入到词典中。尽管对情感词典的研究在不断进行拓展完善,但是仍有一定的局限性,情感词典无法涵盖所有情感表达形式且随着时代发展出现的新词无法及时涵盖进去,这使得文本情感判断准确率较低。
在针对短文本处理方面,机器学习领域也取得了一些突破。Manek等[7]针对大型影评数据集的情感分类问题提出了基于基尼指数的支持向量机分类器的特征选择方法,该方法利用支持向量机做分类时,结合了文本的语义信息使得模型取得很好的效果。Abbasi等[8]提出一种基于规则的多元文本特征选择方法,该方法利用n元特征之间的句法关系构建了一个特征关系网络,不仅考虑了语义信息,还有效地解决了特征冗余的问题。
在深度学习方面,虽然深度学习在文本情感分析这一领域还处于探索阶段,但相比于传统的研究方法,深度学习还是具有一定的优势。其中CNN(Convolution Neural Network)和RNN(Recurrent Neural Network)被广泛地用作情感积极性分析的模型工具。Kalchbrenner[9]等人第一次把CNN运用于自然语言处理,卷积神经网络的一个优点是它比RNN更可并行化,而且在语义信息的局部特征提取上更优于RNN,所以在针对短文本特征提取方面很多研究者都会引入CNN模型来加强文本特征的提取。SUN等人在文献[10]中利用卷积神经网络CNN扩展了微博短文本的内容,作者把多条短评论微博相互结合扩展成一条更完整的微博语料,解决了微博短小稀疏的问题。陈钊等在文献[11]中将句子结构考虑进来,使用CNN分段提取句子不同结构的主要特征,并结合词语情感序列特征来提高文本特征的提取能力。Giatsoglou等[12]将词向量嵌入技术引入到词典构建中考虑了单词的上下文信息,有助于文本信息的特征提取。梁斌等[13]从词向量、词性、词位置三个角度引入注意力机制,并将其结合构建了多注意力卷积神经网络,有效地提高了文本特征的提取能力。韩虎等[14]将注意力机制应用于神经网络加强了原有神经网络的特征提取能力。袁和金、张旭等在文献[15]中使用多通道卷积神经网络对文本不同粒度的特征信息进行提取,并结合注意力机制获得文本的上下文情感特征,模型在IMDb及SST-2数据集上比传统CNN-RNN模型的分类精确度有所提升。Yanmei等人在文献[16]中提出采用模型融合的方法进行微博情感分类,该方法首先利用卷积神经网络CNN提取微博短文本的特征向量,然后分别使用SVM和递归神经网络RNN构建情感分类器对微博进行情感分类。
上述研究中大多使用Word Embedding(词嵌入)进行词向量表示和使用模型融合的方法来提高文本特征的提取能力。在使用Word Embedding进行词向量表示时,虽然充分考虑到了文本的局部信息和整体信息,相比于传统的词向量表示方法有很大的性能提升。但通过Word Embedding方法训练的词向量是一种静态编码,其训练后得到的词向量是固定的,不会发生变化。但在文本中一个词在不同的上下文中所表达的语义是不同的,例如“苹果”这个词,在文本中即可以表示手机又可以表示成水果。所以上述方法都没考虑到词在不同文本场景中的语义信息。通过模型融合的方法在针对微博短文本特征提取上也没考虑词在不同文本场景中的语义信息,所以效果也不是很理想。
本文旨在提高微博短文本的特征提取能力以便于对网络舆情进行预测。为了更好地提取短文本的情感特征,本文首先利用BERT(Bidirectional Encoder Representation from Transformers)模型实现文本向量化,再利用卷积神经网络CNN进行文本局部语义特征提取,最后将局部语义特征向量和BERT训练的特征向量进行特征融合。该方法有效地解决了短文本特征提取难的问题。
1 相关概念
1.1 词向量的表示
在自然语言处理任务中,词向量的表示是至关重要的,通常词向量的表示有两种,一种是离散表示(one-hot representation),另一种是分布式表示(distribution representation)。其中离散表示存在维度灾难和语义鸿沟等问题,现在几乎已被遗弃。为了解决离散表示带来的问题,Hinton[17]在1986年提出了使用低维的分布式向量表示词,有效地降低了维度灾难。后来Bengguo[18]在2003年提出神经网络语言模型(Neural Network Lauguage Model,NNLM),NNLM模型生成的词向量能够很好地根据特征距离度量词与词之间的相似性。但是NNLM模型在训练文本时只考虑到前n-1个词的文本信息,没有考虑到整个文本的上下文信息。为了让训练的词向量获得上下文的语义信息,2013年Google[19]提出了word2vector模型来训练词向量。通过word2vector模型训练的词向量不仅包含了上下文信息,还很好体现了真实世界中词与词之间的关系。如king-man = queen-woman,但是word2vector模型在训练词向量时只考虑了文本的局部信息,没有考虑整体信息。2014年Pennington[20]等人提出了GloVe模型,在训练词向量时利用矩阵分解(LSA)的技术,同时考虑了文本的局部信息和整体的信息。以上训练词向量均是静态的词向量,无法解决一词多义等问题。在情感分析中,一个词语的不同语义有时候对一句话的情感倾向有着很大的影响。为了解决这个问题,2018年10月google的Devlin J[21]等提了BERT模型,该模型有效地解决了一词多义的问题。1.2 注意力机制
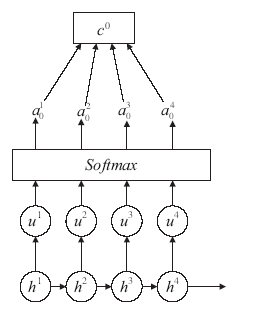
注意力机制(Attenion)最初被Bahdanau[22]等人用于机器翻译。现在已成为神经网络领域的一个重要概念,近几年在深度学习各个领域被广泛使用。注意力机制可以利用人类视觉机制进行直观解释。例如,我们的视觉系统倾向于关注图像中辅助判断的部分信息,并忽略掉不相关的信息[23]。在文本特征提取时,注意力模型允许模型动态将注意力集中在情感信息重点的某些部分,而忽略其他不重要的因素。其主体结构如图1所示。图1
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1注意力机制图
Fig.1Attention mechanism
通过注意力模型计算文本中各个词语的注意力值的计算公式如下:
uit = vttanh(w1hi + bw)
ait = softmax(Uit)
ct = Σaithi
其中,hi为得到的文本特征向量,W1为参数向量,bw为偏置量,uit为通过神经网络得到的对hi的隐层表示。ait是通过对uit进行softmax函数归一化得到的权重矩阵。最后通过权重矩阵ait与文本特征向量hi进行加权和,得到包含文本各词语重要性信息的文本向量ct并将其作为分类器的输入。
1.3 BERT模型
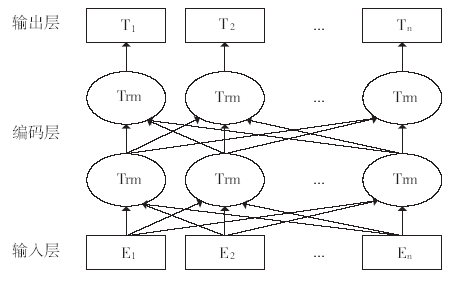
相比于word2vector和GloVe模型,BERT模型训练的词向量,充分描述了字符级、词级、句子级甚至语句之间的关系特征,其模型结构如图2所示。与同年出来的ELMo(Embedding from Language Model)和GPT(Gererate Pre-Training Model)模型相比,BERT在文本特征提取上采用了双向Transformer模型。图2
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2BERT模型结构图
Fig.2Structure diagram of BERT model
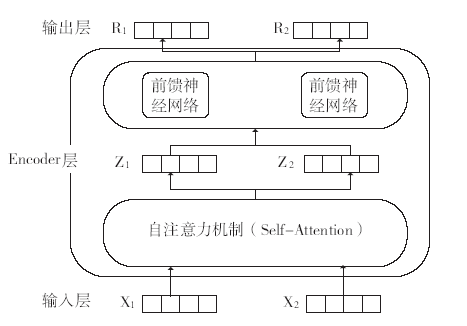
Transformer编码层是BERT模型最核心的部分,在进行文本特征提取时,BERT使用的是Transformer的Encoder特征抽取器,Encoder由自注意力机制(self-attention)和前馈神经网络(feed fordward neural network)构成,其结构如图3所示。其中self-attention是Encoder的核心,其思想和Attention差不多。它可以挖掘一句话中词与词之间的相互关系,并且没有距离限制,几百甚至上千词之间的关系都能找到,这样就能找到一句话中每个词的左右上下文关系,从而得到词的双向表示。
图3
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3Encoder模型结构图
Fig.3Structure diagram of Encoder model
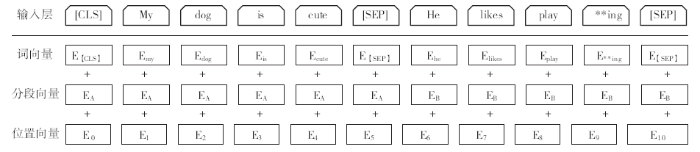
BERT模型的输入由三个向量组成,分别为词向量(token embeddings)、段向量(segment embeddings)和位置向量(position embeddings),如图4所示。其中词向量是模型中关于词最主要的信息,段向量的引入是因为BERT里面的下一句的预测任务会将两句拼接起来,上句有上句段向量,下句则有下句段向量,也就是图中EA与EB,所以要对当前词所在的句子的位置编码。位置向量是因为Transformer模型不能记住时序,所以人为加入表示位置的向量。
图4
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4BERT输入表示
Fig.4Input representation of BERT
1.4 CNN模型
卷积神经网络CNN最开始应用于机器视觉领域,由于其在数字图像处理领域取得了巨大的成功,从而掀起了深度学习在自然语言处理领域的狂潮。由于短文本信息量小、特征稀疏的特点,使得在做短文本情感分析时,一句话的情感倾向有可能只集中在文中某些情感词上,为了进一步提取这些情感词,本文将引入CNN模型对文本做进一步的局部特征提取。本文采用单层CNN进行局部特征提取,结构图如图5所示。图5
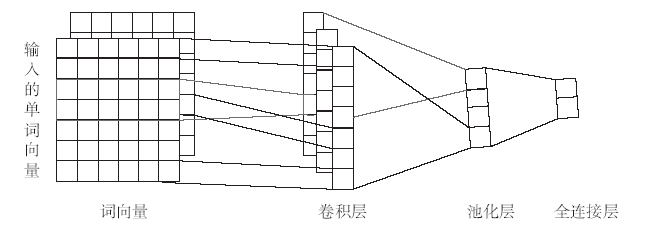 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5卷积神经网络模型结构图
Fig.5Structure diagram of convolution neural network model
2 融合模型结构
本章将介绍使用BERT+CNN模型对微博短文本做深度特征抽取,其中CNN结构主要采用图5所绘制的模型结构。2.1 数据预处理
本文首先对网上爬取的微博文本做数据清洗和预处理,在文本处理中发现短文本长度超过25汉字的文本占6.3%,为了尽量保留文本信息的同时提高训练效率,且使得数据满足模型的要求,将单条文本长度设置为25汉字,超过25个汉字的文本将保留文本关键情感部分,舍弃其它描述性部分,长度不足25汉字的文本用0补齐。2.2 特征抽取
由于BERT能很好地提取文本的双向语义获得更好的词分布式表示,并且其采用动态编码的形式能很好地解决一词多义的问题,所以本次实验将利用BERT来生成词向量。在融合模型中本文首先将处理好的文本送入BERT生成词向量,然后为了进一步提取文本的局部信息,本文将使用卷积神经网络(CNN)对训练的词向量进行再一次特征提取,得到具有重要局部特征的词向量。本文采用单层CNN进行局部特征提取,结构图如图6所示。其中输入层为BERT训练的词向量。首先将词向量送入1维卷积层(Conv1d)进行局部特征提取,然后通过池化层(Max_pooling)找到最重要的局部特征,接着通过一个全连接层整合所有的局部特征。同时,为了防止过拟合现在的发生,融合模型中会加入Dropout层。最后将得到的词向量代入各个文本分类模型中完成情感分类。
图6
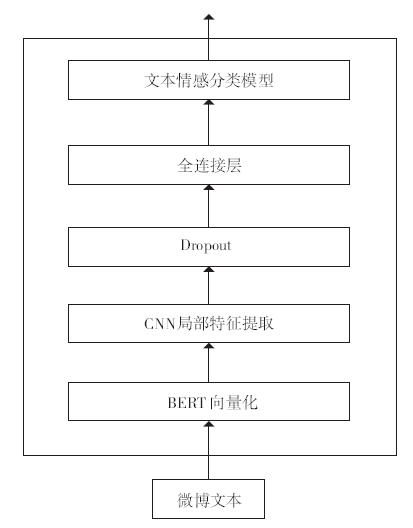 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6融合模型结构图
Fig.6Structure diagram of fusion model
3 实验分析
3.1 实验环境
本次实验环境如下:操作系统为Windows10.0,CPU为Intel Core i7,GPU为GeForce GTX1070,内存为DDR3 16GB,主板为Intel X79,开发环境为TensorFlow-GPU 1.12.1,开发工具为Pycharm,开发语言为Python。3.2 实验数据
本次实验数据共有五大类,都是通过网络爬虫在微博上爬取的一些服务行业的客户评论信息,分别为物流快递服务、医疗服务、金融服务、旅游住宿服务、食品餐饮服务,并在表1中做了详细统计。Table 1
表1
表1数据集统计
Table 1
| 领域 训练集 测试集 情感比例/% |
|---|
| 食品餐饮 13650 5400 50 旅游住宿 18935 6000 50 金融服务 14355 5500 50 物流服务 15645 5600 50 医疗服务 17655 6000 50 |
新窗口打开|下载CSV
3.3 实验参数
实验参数的设置对实验结果的影响很大,本次实验的参数设置是通过大量的重复试验并且结合实验环境硬件的最大性能而确定的。其中表2列出了训练词向量时BERT中的参数和与其参数对应的参数值。表3列出了卷积神经网络中的参数和与其参数对应的参数值。由于实验机器设备原因,本次实验采用的是Google发布的一个参数较小的预训练好的BERT中文模型“chinese_L-12_H-768_A-12”。该模型共有五个文件,其中“bert_model.ckpt”开头的文件是负责模型变量载入的,而“vocab.txt”是训练时中文文本采用的字典,最后“bert_config.json”是BERT在训练时可选调整的一些参数。
Table 2
表2
表2BERT模型参数
Table 2
| 参数 值 | 参数 值 |
|---|---|
| 输入序列长度 128 优化器 Adam Transformer 12 | 学习率 2E-5 迭代次数 3 Batch size 32 |
新窗口打开|下载CSV
通过参数固定的方法,在训练词向量时,窗口大小比较了4、5、6大的窗口,滑动窗口数量分别取40、100、128进行比较,dropout的比例对比了0.3、0.5、0.6通过对比以上参数对模型准确率的影响,最终取表3参数值时词向量的训练效果最好。
Table 3
表3
表3CNN模型参数
Table 3
| 参数 值 | 参数 值 |
|---|---|
| 词向量维度 100 滑动窗口大小 3 滑动窗口数量 128 | 激活函数 RELU Pooling方法 Max dropout 0.5 |
新窗口打开|下载CSV
3.4 对比实验
本次实验训练数据集共有80 000多条微博短文本,测试文本有30 000多条。在进行文本分类之前首先对训练文本进行了预处理,然后将处理好的数据代入到BERT模型和CNN中训练得到词向量。最后再将得到的词向量分别代入各种文本分类模型中进行情感分类。为了验证本文提出方法的分类效果,本次实验设置了以下对比实验。(1)SVM:机器学习领域最经典的处理文本分类的方法,根据文本和情感词典构建特征,然后训练SVM分类器得到相应的准确率。
(2)Text-CNN:深度学习领域最常用的处理文本分类的模型,结构简单,效率很高。
(3)LSTM+Attenion模型:LSTM模型基于RNN模型的改编,是深度学习处理文本分类方面运用最多的模型之一。
(4)BiLSTM+CNN+Atenion模型:针对LSTM模型的不足所提出的改进模型,也是深度学习处理文本分类方面目前识别效率最高模型之一。
3.5 实验结果与分析
由于设备和时间原因,本次实验将得到的融合特征只带入到了LSTM模型中进行了实验验证,并将所得情感分类模型与传统的基于Word Embedding(词嵌入)的Text-CNN模型、LSTM+Attenion模型、双向的BiLSTM模型,以及传统的机器学习SVM、朴素贝叶斯等和其他深度学习模型进行对比实验。本文模型的准确率和损失函数的收敛图如图7和图8所示。图7
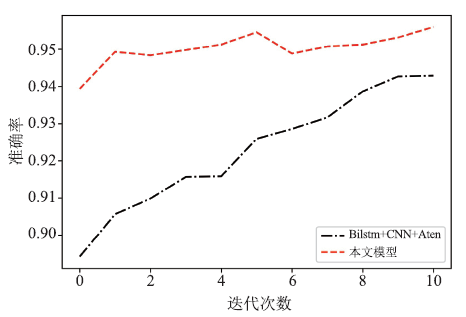 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7模型准确率对比图
Fig.7Model accuracy comparison chart
图8
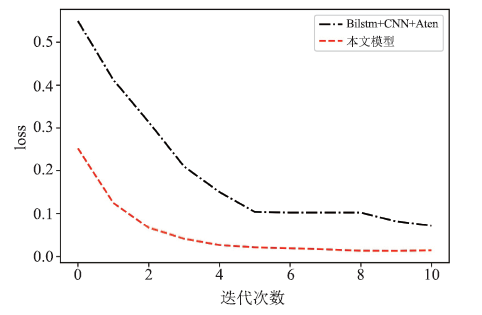 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8模型损失收敛对比图
Fig.8Comparison chart of model loss convergence
由于设备原因本次实验迭代次数只设置了10轮,由图7可以看出本文模型在测试数据集上的精确度在模型迭代的各个阶段都高于BiLSTM+CNN+Attention模型。从图8可得经过10轮迭代后两模型的loss值都降到了一个相对稳定的值。
Table 4
表4
表4本文模型与其他模型的结果对比
Table 4
| 模型 准确/% | 模型 准确率/% |
|---|---|
| SVM 87.03 Text-CNN 89.04 LSTM+Aten 90.26 | BiLSTM+Aten 92.28 Bi+CNN+Aten 94.26 本文模型 95.50 |
新窗口打开|下载CSV
由表4可以看出本文模型的分类准确率比BiLSTM+CNN+Attenion模型的分类准确率高出1.24%,比BiLSTM+Attenion模型的分类准确率高出3.22%,比LSTM+Attenion模型的分类准确率高出5.24%,比Text-CNN模型的分类准确率高出6.46%,比SVM模型高出8.47%。由表4可得,利用BERT和卷积神经网络CNN结合提取的融合特征比单模型所提取的文本特征和基于Word Embedding(词嵌入)的融合模型所提取的文本特征有更好的文本表征效果。
4 结束语
本文研究了短文本情感分析的主要方法,并对基于深度学习的短文本情感分析方法进行了研究。针对中文短文本信息量小、特征稀疏的特点,本文对微博短文本的情感分类进行了研究,提出一种基于BERT和CNN结合提取文本特征的方法。该方法首先通过BERT预训练模型获取包含上下文语义信息的词向量,然后利用卷积神经网络CNN再次提取含有重要局部语义信息的词向量,最后将所得融合特征的词向量带入到各个文本分类模型中进行情感分类。经过对比实验证明,该方法比本文提到的其他对比方法在情感极性分类的准确性上有了一定程度的提升。由于实验设备和时间原因,本次实验只将融合特征代入到LSTM模型中与其他模型做了对比,在下一步工作中,将做更多对比实验,并探索将本文提出的方法应用于NLP其他领域。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
URL [本文引用: 1]

意见挖掘是针对主观性文本自动获取有用的意见信息和知识,它是一个新颖而且十分重要的研究课题。这种技术可以应用于现实生活中的许多方面,如电子商务、商业智能、信息监控、民意调查、电子学习、报刊编辑、企业管理等。本文首先对意见挖掘进行了定义,然后阐述了意见挖掘研究的目的,接着从主题的识别、意见持有者的识别、陈述的选择和情感的分析四个方面对意见挖掘的研究现状进行了综述,并介绍了几个成型的系统。此外,我们针对汉语的意见挖掘做了特别的分析。最后对整个领域的研究进行了总结。
[本文引用: 1]
[J].
DOI:10.2466/pr0.1998.82.2.643URLPMID:9621741 [本文引用: 1]
Transcripts for episodes from 9 situation comedies (roughly 27,000 words in total) were scored by the program TEXT.NLZ in terms of emotional tone. To promote ease of interpretation scores for the dimensions of pleasantness and activation were depicted as vectors in a normative emotional space. Both numerical and figural representations of the data indicated that the words used in situation comedies were pleasant and mildly active, with small differences occurring between comedies. The emotional characteristics of situation comedies stood out in comparison to those of several other texts depicted in the same emotional space.
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1016/j.eswa.2016.10.043URL [本文引用: 1]
[J].
[本文引用: 1]
[J/OL].
[本文引用: 1]
[J].
[本文引用: 1]
[C]//
[本文引用: 1]
.[C]//
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}