 ,1, 林潇霏,1, 孙永谦,1,*, 张玉志,1, 裴丹,2
,1, 林潇霏,1, 孙永谦,1,*, 张玉志,1, 裴丹,2Research on Unsupervised KPI Anomaly Detection Based on Deep Learning
Zhang Shenglin,1, Lin Xiaofei,1, Sun Yongqian,1,*, Zhang Yuzhi,1, Pei Dan,2通讯作者: 孙永谦(E-mail:sunyongqian@nankai.edu.cn)
收稿日期:2020-04-10网络出版日期:2020-06-20
| 基金资助: |
Received:2020-04-10Online:2020-06-20
作者简介 About authors

张圣林,南开大学软件学院,博士,讲师,主要研究数据中心网络中的故障检测、诊断和预测。发表SCI/EI收录论文15篇以上。
本文主要设计文章架构并修改论文。
Zhang Shenglin is currently an assistant professor in the College of Software, Nankai University, Tianjin and Beijing, China. His current research interests include failure detection, diagnosis and prediction in data center networks. He has published 15 papers that are indexed by SCI/EI.
In this paper he is mainly responsible for the design of the paper architecture and paper revision.
E-mail:

林潇霏,南开大学软件学院研究生在读,主要研究异常检测和深度学习。
本文主要承担文献调研及实验。
Lin Xiaofei is currently a master student in the College of Software at Nankai University, Tianjin, China. Her research interests include anomaly detection and deep learning.
In this paper he is mainly responsible for the related work investigation and experimental evaluation.
E-mail:

孙永谦,南开大学软件学院,博士,讲师,主要研究异常检测、根本原因定位以及数据中心的高性能切换。
本文主要承担文献调研。
Sun Yongqia is currently an assistant professor in the College of Software, Nankai University, Tianjin, China. His research interests include anomaly detection, root cause localization, and high performance switching in datacenter.
In this paper he is mainly responsible for the related work investigation.
E-mail:

张玉志,南开大学软件学院,院长,博士,讲席教授,主要研究方向为人工智能。
本文主要承担文献调研及指导。
Zhang Yuzhi is currently a distinguished professor and the dean of the College of Software, Nankai University. His research interests include deep learning and other aspects in artificial intelligence.
In this paper he is mainly responsible for the related work investigation.
E-mail:

裴丹,清华大学计算机系,博士,副教授,主要研究方向为网络和服务管理。
本文主要承担文献调研。
Pei Dan is currently an associate professor in the Department of Computer Science and Technology, Tsinghua University. His research interests include network and service management in general.
In this paper he is mainly responsible for the related work investigation.
E-mail:

摘要
【目的】关键性能指标(Key Performance Indicator, KPI)异常检测作为互联网智能运维的基础,对快速故障发现和修复具有重要意义。【文献范围】本文重点调研国内外基于深度生成模型的无监督KPI异常检测方法。【方法】系统地阐述了Donut、Bagel和Buzz三种无监督KPI异常检测方法的理论模型,并分析了它们在准确性和效率等方面的优势与不足。【结果】本文基于生产环境中的KPI数据验证了三个方法的性能。【局限】基于深度生成模型的KPI异常检测方法仍在不断地演进,未来将探索更多该领域的新方法。【结论】针对不同特征的KPI数据,需要采用不同的深度生成模型:对于时间信息敏感的KPI数据,需要采用Bagel进行异常检测;对于非周期性的复杂KPI数据,需要采用Buzz检测其异常行为。
关键词:
Abstract
[Objective] Automatic key performance indicator (KPI), the basis of Internet artificial intelligence operations (AIOps), is of vital importance to rapid failure detection and mitigation. [Scope of the literature] In this paper, we investigate unsupervised KPI anomaly detection methods, which are based on deep generative models. [Methods] We systematically describe the theoretic model of Donut, Bagel, and Buzz, which are all unsupervised KPI anomaly detection methods, and analyze their advantages and limitations in terms of accuracy and efficiency. [Results] We evaluate the performance of those three approaches based on real-world KPI data. [Limitations] The KPI anomaly detection methods based on deep generative model are continuously evolving, and we will explore more methods in this area. [Conclusions] Choosing a deep generative model should consider the characteristics of KPI data. Generally, if the KPI data is sensitive to timing information, we should apply Bagel to perform anomaly detection. Moreover, Buzz should be used if the data is non-seasonal and complex.
Keywords:
PDF (11129KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
张圣林, 林潇霏, 孙永谦, 张玉志, 裴丹. 基于深度学习的无监督KPI异常检测. 数据与计算发展前沿[J], 2020, 2(3): 87-100 doi:10.11871/jfdc.issn.2096-742X.2020.03.008
Zhang Shenglin, Lin Xiaofei, Sun Yongqian, Zhang Yuzhi, Pei Dan.
引言
随着互联网的高速发展与普及,基于互联网的应用服务已经深入到人类社会生产生活的各个方面,包括通信、资讯、娱乐、学习、本地生活、金融、购物、出行、医疗、教育等。智能运维是保证互联网服务的用户体验、性能、稳定和安全的重要技术体系。其中,关键性能指标(Key Performance Indicator, KPI)异常检测是互联网智能运维的一个核心技术。大部分智能运维的关键技术,包括故障根因分析、异常定位、变更评估、异常事件关联关系挖掘、异常报警聚合、快速止损、故障预测、热点预测等,高度依赖 KPI 异常检测的结果。目前,学术界已经提出一系列KPI异常检测方法。这些方法包括基于统计概率的方法、基于有监督机器学习的方法、基于无监督机器学习的方法。由于基于统计概率的KPI异常检测方法需要为每一个KPI序列调整最优参数,耗费大量人力资源,因此逐渐退出历史舞台。基于有监督机器学习的KPI异常检测方法需要大量的异常标注来训练模型,同样耗费大量人力资源,因此难以应用于大规模互联网服务场景。基于无监督机器学习的KPI异常检测算法,既不需要逐个KPI序列调参,也不需要标注异常数据,已经成为KPI异常检测的未来发展趋势。此外,由于深度生成模型能够准确捕获复杂的KPI数据特征,因此近年来受到学术界和工业界的广泛关注。
本文重点介绍三种基于深度生成模型的无监督KPI异常检测算法——Donut,Bagel,Buzz,并在理论和实验两个方面分析它们的性能。
1 背景
1.1 KPI基本概念
为了保证向千万级甚至上亿级用户提供可靠、高效的服务,互联网服务的运维人员通常会持续地监测服务和底层机器的KPI。一个典型的 KPI案例是某服务在单位时间内被访问的次数—— PV(Page Views)。PV会直接影响Web服务供应商的广告收益和市场份额[1]。其它典型的KPI类型还包括单位时间交易量(应用于银行、互联网金融、证券、电商、团购、移动出行等行业)、当前在线用户数(应用于电商、网络游戏、无线接入网络,移动出行应用等)、Web主页首屏时间、移动应用加载时间、软件报错数、服务器CPU使用率、容器内存使用率、网络吞吐率等。根据服务类型和数据特征,可以将KPI分成两种类型:
(1) 周期性服务KPI
服务和业务层面的KPI,如网络吞吐量、页面浏览量、在线用户数量等,往往具有周期性,且其噪声服从高斯分布。
(2) 非周期性机器KPI
服务底层机器的KPI,如服务器每秒处理的I/O请求数量、容器内存使用率等,往往不具有周期性。它们的噪声不服从高斯分布,虽然短时间内剧烈抖动,但是长时间内又有一定的趋势性。因此,这类KPI的分布十分复杂,较难建模。
1.2 KPI异常基本概念
当 KPI 呈现出异常(如突增、突降、抖动)时,往往意味着与其相关的应用可能发生了故障 [2,3,4,5],如网络故障、服务器故障、配置错误、缺陷版本上线、网络过载、服务器过载、外部攻击等。图1展示了某搜索引擎一周内的PV数据,其中标红圈标识的两个部分为异常。图1
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1KPI异常示例:某搜索引擎PV发生异常
Fig.1An example of anomalous KPI: the PV of a search engine become anomalous
对于周期性服务KPI,KPI异常指的是KPI数据不遵循周期性模式,即KPI数值的大小发生了明显变化使得数据整体不再呈现周期性。对于非周期性机器KPI,KPI异常指的是KPI数值的大小、变化等特征发生了明显改变。
1.3 KPI异常检测基本概念
为了保障互联网公司能提供可用、高效的服务,公司必须实时监测这些服务的KPI,及时发现KPI中的异常,为后续的故障诊断和修复赢得宝贵的时间,尽可能地减少故障带来的损失。同时,那些持续时间较短的KPI抖动也必须被准确检测出来,从而快速找出导致抖动的根本原因,消除小抖动累积成剧烈变化的隐患,避免发生更大的损失。自动KPI异常检测指的是异常检测算法根据历史数据判断实时数据的异常分数,并基于阈值判断该异常分数是否为异常[6]。异常检测问题的关键在于正确地捕获“正常数据的模式”,并通过观测实时数据与正常数据之间的差异程度判断KPI是否发生了异常。如图2所示,这些异常检测算法一般包括以下两个步骤:
(1)对于单个KPI数据点或者一段连续KPI数据,使用异常检测算法计算异常分数,该分数表征其异常程度。
(2)当异常分数大于某个阈值时,将其标注为异常。
自动KPI异常检测不仅提高了异常检测的效率,而且减轻了运维人员的工作量,对于保障大型互联网服务的服务质量具有重要意义。
图2
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2异常检测算法步骤
Fig.2Anomaly detection algorithm steps
2 相关工作
本节简要回顾了KPI异常检测的三个主要方向:基于统计概率的方法,基于有监督机器学习的方法,基于无监督机器学习的方法。在过去的几十年中,研究人员将许多传统的统计概率方法用于KPI异常检测[5,7-24]。这些方法对KPI进行了一些简单的假设,因此运维人员必须为每条KPI选择合适的算法,并为每个KPI序列调整最优参数。即便如此,这些异常检测模型的性能普遍较差。例如,文献[2]使用WoW(周-周)方法检测搜索响应时间中的异常,但KPI的周期性可能不仅存在以周为单位的周期性,而且存在以天为单位的周期性、假期周期性等。此外,即使将这些统计概率方法进行简单集成,如多数表决[17]、归一化[25]等,并不能取得好的异常检测性能[5]。
为了自动组合上述异常检测算法,一些研究如EDGAS [12]、Opprentice [5]等使用有监督机器学习方法进行异常检测。这些方法的原理简单明了:由于简单组合统计概率方法是不够的,因此可以使用历史数据学习统计概率方法的最佳组合。这些方法首先使用统计概率方法计算特征,然后使用用户反馈(通常是异常标注)训练有监督机器学习分类器(例如随机森林)。这些监督方法具有优异的性能。例如,实验表明Opprentice优于所有传统的统计概率方法。图3展示了 Opprentice 利用有监督机器学习进行KPI异常检测的主要思想:首先通过历史数据产生训练集以训练分类模型,同时使用一系列基于统计概率的异常检测方法检测数据异常并得到各个方法计算的异常程度,然后将异常标注和异常程度数据组成训练集。机器学习算法据此在特征空间中构建分类模型。因此,这些分类模型可以检测实时数据中的异常。例如,图3中的“?”所标示的数据会被判定为异常。
图3
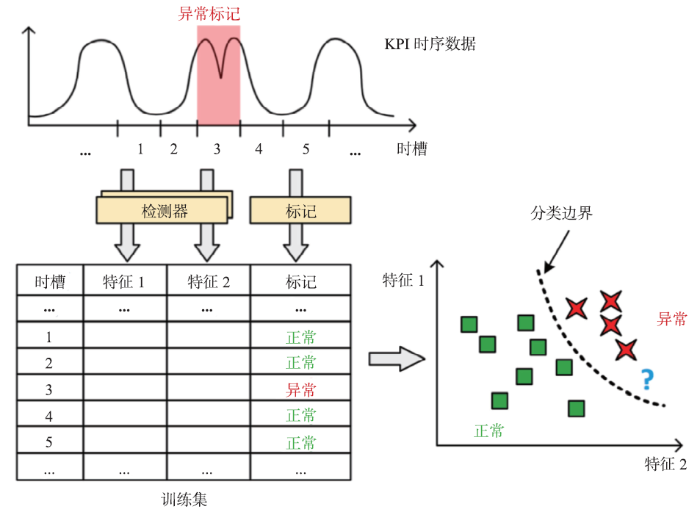 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3Opprentice设计框架
Fig.3The Framework of Opprentice
但是,有监督机器学习算法过度依赖异常标注,而获得足够多的异常标注往往耗费大量的人力物力资源。此外,由于这些方法集成了多种基于统计概率的算法,因此其训练和检测开销很大。所以,这些方法难以应用于大规模互联网服务。
基于无监督机器学习的异常检测方法(不局限于KPI异常检测),如one-class SVM [14,16],GMM [19],VAE [6,25-26]和 VRNN [14]等,使用机器学习方法学习数据的正常模式,并判定未遵循正常模式的点为异常。这些方法可以分为两种类型:基于无监督分类器的算法和基于深度生成模
型的算法。基于无监督分类器的算法或者直接把KPI数据以滑动窗口形式输入到无监督分类器中(outlier detector),或者通过传统的统计概率方法提取KPI数据的特征,然后将特征输入到无监督分类器进行分类。常用的无监督分类器有one-class SVM [14,16], isolation forest[30]等。由于深度生成模型能够更加充分地捕获KPI数据的复杂特征,因此基于深度生成模型的KPI异常检测方法具有更高的准确性。所以,本文重点介绍三种基于深度生成模型的无监督KPI异常检测模型——Donut[6]、Bagel[27]和Buzz[28]。
3 基于深度生成模型的无监督KPI异常检测
3.1 基于深度生成模型的KPI异常检测方法概述
深度生成模型指的是使用深度学习技术的生成模型,它通常包括多个神经网络。例如,在生成对抗网络(GAN[31])中有两个子网络:生成网络和分类网络。相反,对于深度贝叶斯网络(Deep Bayesian network)和深度马尔科夫随机场(Deep Markov random field)等深度概率模型[32],单一的神经网络即可导出随机变量之间的概率分布并构建整个概率模型。Donut 是第一个将深度生成模型应用于KPI异常检测的无监督模型。它是在 VAE[29](Variational Auto-encoder)的基础上实现的。Donut 在 VAE 基础上提出了M-ELBO、MCMC迭代和缺失值填零等创新点,在周期性 KPI 上具有优异的性能。由于Donut 将时间序列视为滑动窗口,不处理时间信息,所以当异常检测依赖时间信息时 Donut 的性能欠佳。为了解决这一问题,****们提出了另一个无监督深度生成模型——Bagel以弥补 Donut 在时间信息处理上的缺陷。Bagel 同样也是针对周期性 KPI 的无监督异常检测方法。它使用了 CVAE[33,34](Conditional Variational Auto-Encoder)作为基础模型,引入了时间信息,因此在部分依赖时间信息的KPI 异常检测上取得了比 Donut 更好的性能。为了检测非周期性机器 KPI 中的异常,****们提出了第三种基于深度生成模型的 KPI 异常检测方法——Buzz。Buzz 基于分区的思想,将 WGAN[35] 和VAE 进行了结合。它通过生成对抗训练优化了一个变种 VAE 的似然证据下界。
3.2 Donut
Donut 是首个采用 VAE 进行 KPI 异常检测的模型,可以处理周期性服务KPI。VAE 是最简单的深度贝叶斯网络之一,主要刻画了观测变量(observed variable)图4
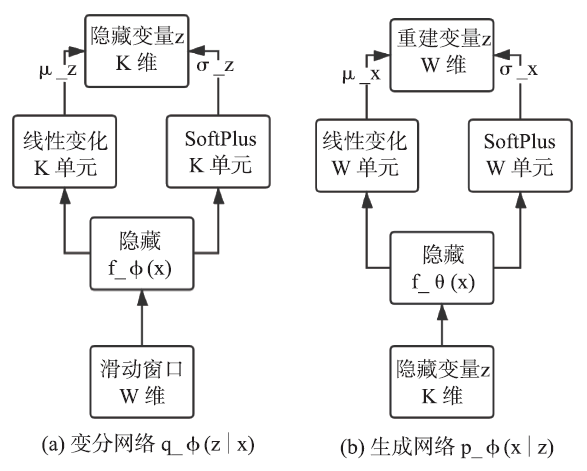 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4Donut的网络结构
Fig.4The network structure of Donut
为了在 VAE 中处理 KPI 时序数据,Donut采用滑动窗口[21](sliding window)对 KPI 序列进行预处理:对于每一个时刻 t,子序列
隐变量z被指定了一个先验分布(prior,通常是多维高斯分布
模型采用全连接层作为隐藏层,输入
其中
生成网络同理,隐变量
同样的,
需要注意的是,在测试时 Donut 并不使用
当然,由于 VAE 模型结构的因素,每个维的 W 滑动窗口会产生所有 W 个重建概率,但每个窗口只取最后一个时刻的重建概率,其他时刻的重建概率均被忽略。
Donut 论文中所研究的 KPI 数据是等时间间隔的监控数据。在真实的场景中,会不可避免地在采集或存储的过程中丢失部分数据——这种点称为“缺失点”。由于滑动窗口要求在每个时刻t得到一个定长的窗口,即缺失点必须被填补一个数值以构成完整的窗口。Donut 在缺失点处填补了0,而非通过一些现有的算法[16]填补这些缺失点,这是因为 VAE 本身就是一个生成模型,它自身就能产生数据、填补空缺。使用任何比 VAE 更弱的算法来填补缺失点会降低 VAE 模型的性能。
上文已经提到过,数据中的异常点和缺失点会影响后续点的检测。事实上,这些异常点和缺失点也会影响模型的训练,毕竟 VAE 需要学习正常的数据模式,异常点和缺失点的存在会让 VAE 学习到错误的模式。Donut 分别提出了不同的方法来降低这些点在训练和测试时影响。
Donut 主要有三个创新点,即 M-ELBO(Modified ELBO),缺失值注入,蒙特卡洛马尔可夫链填补(Monte Carlo Markov Chain Missing Data Imputation,下称为 MCMC 填补) ,其整体过程如图5 所示。
图5
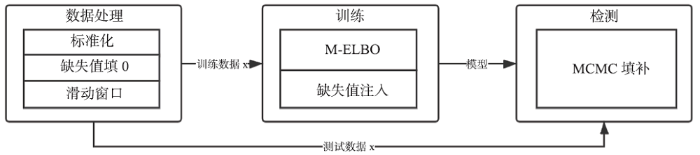 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5Donut设计框架
Fig.5The design architecture of Donut
在训练的时候 Donut 并没有把带有异常点和确实点的窗口完全抛弃,在朴素VAE基础上,Donut 修改了 VAE 的 ELBO(Evidence Lower Bound Objective,证据下界):
其中
在 Donut 的实验中,M-ELBO 是其优于朴素 VAE 模型的重要因素。原理大致如下:在训练时包含带有异常点和缺失点的数据,并且使用 M-ELBO,会迫使VAE在
图6
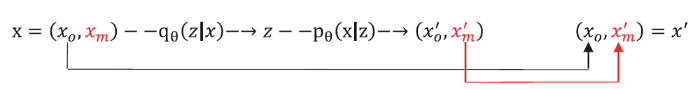 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6MCMC 填补技术
Fig.6MCMC Imputation
3.3 Bagel
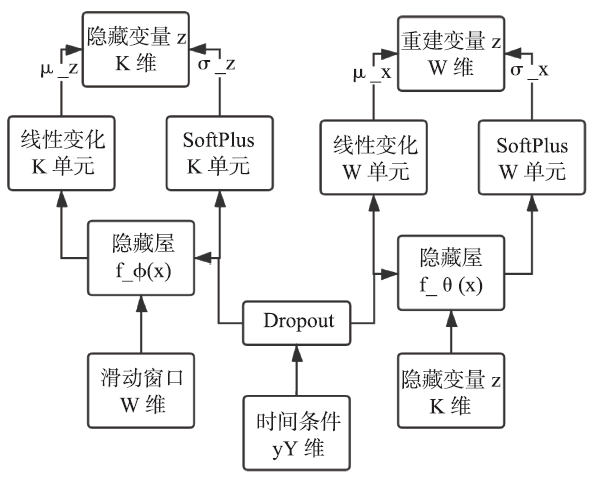
Bagel沿用了Donut的三个创新点——M-ELBO、缺失值注入、MCMC 填补。但是,Bagel不再使用变分编码器(VAE)作为模型的基础,而是使用条件变分编码器(CVAE)。CVAE的原理与VAE类似,同属于深度贝叶斯网络。CVAE主要刻画了观测变量x与额外信息Bagel同Donut一样适用于处理周期性KPI,不同之处在于Bagel在滑动窗口上额外添加了时间信息,对于Donut可以处理的KPI数据,Bagel有同等的处理能力,对于更依赖时间信息的KPI异常检测,Bagel具有比Donut更强的处理能力。Bagel整体结构如图7 所示。Bagel的整体结构与Donut相似,但Bagel比Donut多了一个Dropout层,其原因是由于时间信息的one-hot编码比KPI要简单的多。具体而言,如果同时处理时间信息与KPI数据会出现过拟合现象,所以为了防止时间信息的过拟合,Bagel添加了Dropout层,对额外信息y做了Dropout处理。
图7
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7Bagel模型整体结构
Fig.7Overall structure of Bagel
在Bagel中,在滑动窗口添加时间信息的one-hot编码,选取的时间信息为星期,小时和分钟,如表1所示。模型不考虑年份、月份等信息是因为周期性KPI曲线的周期跨度通常小于一个月,考虑年月等信息意义不大。时间的one-hot编码即将数字转位二进制形式,由于星期数最多为7,小时数最多为24,分钟数最多可为59,所以星期数选取7位表示。例如,用one-hot编码表示星期二,则七位的第二位设置为1,其余为0,小时数选取24位表示,分钟数选取60位表示。
Table 1
表1
表1Bagel 时间信息编码示例
Table 1
| 日期和时间 | 2018/7/3 16:25:13 星期二 |
| 分解信息 | 25(minute),16(hour),2(day of week) |
| one-hot编码 | 0…0,1,0…0|0…0,1,0000000,|0,1,00000(其中第一处省略23个0,第二处省略32个0,第三处省略14个0) |
新窗口打开|下载CSV
3.4 Buzz
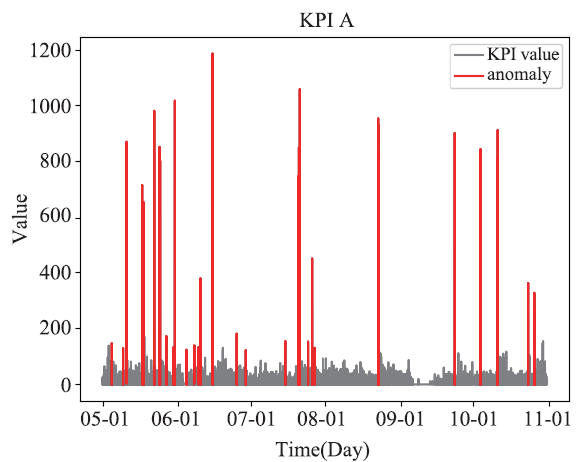
Donut和Bagel针对的是周期性服务KPI的异常检测问题,但它们对非周期性机器KPI的表现欠佳。这是因为VAE难以捕获非周期性机器KPI表现出来的非高斯的噪声和复杂的数据分布。如图8所示,非周期性机器KPI数据频繁抖动,同时在长时间范围内具有一定的趋势性。具体而言,不同的非周期性机器KPI数据有不同的局部模式和全局模式。Buzz专注于非周期性机器KPI的异常检测问题。图8
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8非周期性机器KPI示例
Fig.8An example of non-seasonal machine KPI
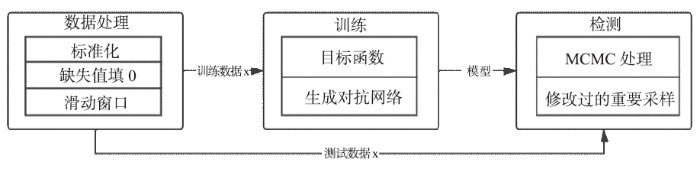
Buzz模型分为三个网络,分别是变分网络、生成网络和判别网络,如图9所示。变分网络和生成网络分别负责编码和解压重建,判别网络负责判断数据为生成数据还是原始数据,以此促进变分网络和生成网络的优化。如图所示,对于变分网络,模型先将窗口重塑为二维,然后进入卷积层,通过线性变化和SoftPlus得到和,进而得到变分网络的表示。对于生成网络,可以理解为变分网络的逆过程,隐藏变量z先进入全连接层,再经过反卷积,然后重塑为1维,再重塑为W维,得到重建变量y。判别网络同样使用反卷积层来接收重塑为二维的滑动窗口,随后数据进入全连接层得到判别结果。如图10所示,Buzz的主要流程和Donut 类似,不同之处主要在于Buzz的训练方式。Buzz沿用了Donut 的创新点:MCMC处理和缺失值填0。
图9
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图9Buzz的网络结构
Fig.9The network structure of Buzz
图10
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图10Buzz设计框架
Fig.10The architecture of Buzz
Buzz有几个核心思想:(1)为了对复杂KPI进行建模使用了分区划分的思想。Buzz将数据空间划分为数个子空间(分区),然后在每个子空间内计算某个距离指标。(2)当计算距离指标时,Buzz使用Wasserstein距离来度量生成分布和数据分布之间的距离(之后称作分布距离)。(3)Buzz提出了训练目标的原始形式和对偶形式,并将Buzz模型转化为贝叶斯网络。Buzz实际上通过生成对抗训练优化了一个变种VAE的似然证据下界。(4)Buzz将VAE作为一个生成模型来生成样本,并使用另一个神经网络作为判别器来区分生成样本和真实样本。(5)为了保证生成对抗训练的稳定性,Buzz使用了梯度惩罚方法,它是一种对WGAN(Wasserstein Generative Adversarial Network Wasserstein生成对抗网络[35])的改进策略。(6)异常检测通过贝叶斯推导来实现。
Wasserstein距离能够准确地在WGAN中度量概率分布之间的距离。此外,Buzz将数据空间划分为很多个小区域,然后在每个小区域上计算分布距离。每个小区域上的分布距离通过对抗训练方法获得,最后把每个小区域上计算得到的值进行平均以得到整体距离。分区扮演了连接WGAN损失函数和VAE的桥梁。
3.5 三个方法优缺点比较
由表2可以发现,三个方法都需要大量的训练数据。由于三个方法都是无监督学习模型,因此它们都不需要异常标注。Buzz可以处理Donut和Bagel无法处理的非周期性机器KPI。但是,它需要更高的训练开销。Bagel的优势在于添加了时间信息,对部分依赖时间信息的异常具有更好的性能。Table 2
表2
表2三个模型优缺点比较
Table 2
| 比较项 | Donut | Bagel | Buzz |
|---|---|---|---|
| 运行耗时 | 较短 | 较短 | 较长 |
| 运行性能要求 | 一般 | 一般 | 较高 |
| 需要大量数据 | 是 | 是 | 是 |
| 依赖异常标注 | 否 | 否 | 否 |
| 异常检测准确性 | 较好 | 较好 | 较好 |
| 适用于周期性KPI | 是 | 是 | 否 |
| 适用于非周期KPI | 否 | 否 | 是 |
| 对时间信息敏感 | 否 | 是 | 否 |
新窗口打开|下载CSV
4 实验评估
4.1 数据集
2018年笔者筹办了首届AIOps挑战赛[40],并收集了来自百度、搜狗、腾讯和Ebay的KPI数据。运维人员已经仔细地标注了该数据集中的每一个KPI序列。因此,本文使用该数据集测试Donut、Bagel和Buzz的性能。表3列出了数据集的详细信息。Table 3
表3
表3数据集详细信息
Table 3
| KPI序列数目 | 50 |
| KPI数据点数目 | 226 200 |
| 缺失值点数 | 1 539 |
| 异常数据点数目 | 2 844 |
新窗口打开|下载CSV
4.2 评估标准
所有算法都会为每个KPI数据点计算一个异常分数。可以选择一个阈值来进行决策:如果某个数据点的分数大于阈值,则将其判断为异常。这样,异常检测问题就转换为分类问题,并且可以计算每个阈值的精度和召回率,进而计算F-Score——精度和召回率的协调平均值。本文进一步枚举所有阈值对应的F-Score,并计算每种算法的最佳F-Score。在KPI异常检测问题中,KPI序列中的异常往往是连续的异常片段。运维人员通常只关心异常片段开始的时间[11]。因此,如果异常检测算法在异常开始后以足够快的速度(即在最大允许延迟之前)做出判断,则认为其成功检测到整个异常片段。警报延迟是该异常片段中第一个异常点与第一个检测点之间的时间差。如果异常检测算法未在最大允许延迟之前发出任何警报,则即使异常检测算法能够检测出异常,本文也认为算法未能成功检测出异常片段。
图11展示了警报延迟为一分钟(一格)的异常检测结果。第一行是人工确认后的异常标注,第二行是算法得到的异常分数,第三行显示了阈值为0.5时的异常检测结果,第四行是根据警报延迟修正后的异常检测结果。对于第一个KPI异常片段,异常检测算法在最长延迟警报内发现了异常(加粗斜体部分),则本文认为算法成功检测了整个异常片段。对于第二个KPI异常片段,虽然异常检测算法在该片段最后两分钟检测到了异常,但是由于该检测结果超过了警报延迟,所以本文认为异常检测算法未能成功检测到该异常片段。
图11
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图11修正后的异常检测结果
Fig.11The modified anomaly detection results
KPI异常检测通过设定阈值来评估KPI曲线上每个点的异常分数,即问题可以转化为二分类问题,分为异常和正常两类。对于该类问题,比较常用的评价指标有精度(Precision)、召回率(Recall)以及精度与召回率的调和平均(F1 Score)。计算公式如下:
其中,true positive (TP)表示成功检测出的异常点的数量,false positive (FP)表示正常点被模型判断为异常点的数量,false negative (FN)表示异常点被模型判断为正常点的数量。Donut论文提出了Best-Fscore,即设定多个阈值,比较每个阈值对应的F1 Score,然后选取最高的 F1 Score 作为模型在该曲线上的F1 Score。Bagel和Buzz沿用了这种评估方式。
4.3 三个方法的实验对比
本文使用10-fold方法分别测试Donut、Bagel和Buzz的准确性。三个方法在整个数据集的最佳precision、recall和F-score如表4所示。可以看出,捕获了时间信息的Bagel取得了比Donut更好的准确性。这是因为Bagel在滑动窗口添加了时间信息的one-hot编码。此外,虽然Buzz能够检测非周期性机器KPI中的异常,但是它在周期性服务KPI中的表现欠佳,导致其整体的F-Score低于Donut和Bagel。Table 4
表4
表4三个方法准确性比较
Table 4
| Precision | Recall | F-Score | |
|---|---|---|---|
| Donut | 0.88 | 0.82 | 0.84 |
| Bagel | 0.91 | 0.85 | 0.88 |
| Buzz | 0.78 | 0.44 | 0.56 |
新窗口打开|下载CSV
在处理非周期性机器KPI时,Buzz能够取得比Donut和Bagel有更好的准确性。例如,图12展示了Donut、Bagel和Buzz在一个非周期性机器KPI上的precision recall curve (PRC)。在PRC曲线中,越靠近右上角,表示性能越好。可以看出,Buzz具有最好的准确性。这是因为:为了对复杂KPI进行建模,Buzz使用了分区划分的思想。它将数据空间划分为数个子空间(分区),然后在每个子空间内计算某个距离指标。
图12
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图12三种算法在一个非周期性机器KPI上的PRC曲线
Fig.12The PRC of the three methods on a non-seasonal machine KPI
5 总结
当前,****们已经提出了一系列基于深度生成模型的无监督KPI异常检测框架。其中,Donut、Bagel和Buzz 是三个典型的方法。Donut作为最早提出的面向KPI异常检测的深度生成模型,采用基于VAE的无监督学习架构,在周期性服务KPI上表现优异。Bagel使用CVAE替换Donut中的VAE,将时间信息编码进模型,对于时间敏感的KPI具有更好的异常检测性能。由于非周期性机器KPI通常表现出非高斯噪声和复杂数据分布,因此Buzz有效结合了WGAN和分区思想,提高了非周期性机器KPI的异常检测准确性。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[C]//
[本文引用: 1]
[J].
DOI:10.1145/2534169.2486035URL [本文引用: 2]
[C]//
[本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 4]
[C]//
[本文引用: 3]
[J].
[本文引用: 1]
[C]//
[J].
[C]//
[J].
[本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[J].
[本文引用: 3]
[J].
[J].
DOI:10.1016/j.patcog.2016.03.028URL [本文引用: 3]
[C]//
[本文引用: 1]
[C]//
[C]//
[本文引用: 1]
[C]//
[C]//
[本文引用: 1]
[C]//
[J].
[本文引用: 3]
[C]//
[C]//
[本文引用: 1]
[J].
[本文引用: 3]
[J].
[本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 1]
[J].
[本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 1]
[M].
[本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 1]
[J].
[本文引用: 2]
[J].
DOI:10.1136/bmj.b2393URLPMID:19564179 [本文引用: 1]
[C]//
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
http://iops.ai/[OL]. [
URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}