 ,*, 肖邓杰, 乔予思, 万金宇中国科学院高能物理研究所,北京 100049
,*, 肖邓杰, 乔予思, 万金宇中国科学院高能物理研究所,北京 100049Machine Learning Applications for Particle Accelerators
Chu Zhongming,*, Xiao Dengjie, Qiao Yusi, Wan JinyuInstitute of High Energy Physics, Chinese Academy of Sciences, Beijing 100049, ChinaCorresponding authors: (E-mail:chuzm@ihep.ac.cn)
Online:2019-12-20
| Fund supported: |
作者简介 About authors

Chu Zhongming was born in 1964. He received his Ph.D. in Physics from the University of Michigan, Ann Arbor in 1994. Through the SNS construction and beam commissioning stages, he was one of the core developers for the XAL software platform. During the LCLS-I commissioning he was in charge of high-level Physics model software.He served as the FRIB Controls leader responsible for budget, schedule and group management. Paul has joined IHEP as a senior research scientist under the Chinese Academy of Sciences “100 Talent Leadership Program”, and the head for the HEPS Technical Support Division and BEPC-II Controls Group leader. His research fields are accelerator physics and accelerator controls. E-mail:chuzm@ihep.ac.cn

摘要
【目的】机器学习是一个快速发展的领域,它能解决许多传统方法所无法有效解决的复杂问题。而一台现代粒子加速器如正在北京近郊建造中的超低发射度同步辐射光源,高能同步辐射光源(HEPS),则需要对数以千计的装置设备达到非常高的控制精度,才能用这台光源产出高效科研成果。本文主要为将机器学习应用于粒子加速器做一个简单介绍。【方法】对这样大型的加速器,传统控制方法可能无法满足如此复杂的运行,而本文将介绍机器学习技术可以在加速器的许多系统提供可能的帮助,并提出如何准备数据,及介绍一个适合机器学习的软件架构。【结果】一个能涵盖绝大部分加速器数据的数据库结构已经设计完成并开始开发编程。另外机器学习在加速器运行与设计上的初步应用也有了结果。【结论】机器学习在加速器的应用有很好的开始及正面的初步结果。同时,与其他单位的合作也已开展以分担工作及加速开发。随着软件架构成型及获取更多高质量数据,机器学习在加速器上应有更多很好的结果。
关键词:
Abstract
[Objective] Machine Learning (ML) is a booming field for many complicated problems which were previously unable to solve effectively with conventional methods. In order to deliver big science findings, a modern accelerators such as the under construction low emittance synchrotron radiation based light source, High Energy Photon Source (HEPS), located in suburban Beijing require very high precession control systems to handle thousands of individual devices to work coherently and smartly to perform at its highest running level. This paper introduces some initial work for adopting ML in the accelerator field. [Method] For such a large accelerator, conventional control approach may be insufficient for handling the complexity of operations. This paper outlines that ML techniques may help the accelerator in many aspects and, more importantly, discusses how to prepare the data for ML. Also, a software architecture which is suitable for ML applications applied to accelerator field is introduced. [Results] A global database structure which can cover nearly all accelerator data has been designed and under implementation. In addition, initial works of ML for both accelerator operation and design are shown. [Conclusion] The ML techniques for accelerator start well with some positive results. In the meantime, collaborations between organizations are formed to share work load and speed up development. As the software infrastructure being developed and more good quality data being collected, the ML for accelerators should produce much better results.
Keywords:
PDF (10380KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
储中明, 肖邓杰, 乔予思, 万金宇. 机器学习在粒子加速器的应用. 数据与计算发展前沿[J], 2019, 1(2): 110-120 doi:10.11871/jfdc.issn.2096-742X.2019.02.010
Chu Zhongming.
Introduction
Recently, as the GPUs have been greatly improved, the deep neural network algorithms become realistic and successful in many areas. Machine Learning (ML) in general has also gained attention in particle accelerator community. Major accelerator conferences such as the International Particle Accelerator Conference (IPAC) [1], the International Workshop on Personal Computers and Particle Accelerator Controls (PCaPAC) [2], and the International Conference on Accelerator and Large Experimental Physics Control Systems (ICALEPCS)[3] now all have dedicated sessions for ML related works. So far, ML for accelerators can be applied to at least the following four types of issues: facility needs, tuning, optimization and prognostic modelling and simulations. Actual applications have already been proposed in accelerator lattice design, equipment control, beam tuning optimization, and accelerator theoretical studies. However, the results are somehow mixed with more failures than successes.Based on these early experiences, some of the failures are due to inappropriate data sets and unrealistic models. In order to deal with the design, construction, beam commissioning, and operation of accelerators, as well as combine the knowledges of accelerator physics, controls, data science, and scientific computing, we have designed a suitable infrastructure for ML in the accelerator field. Also, because the ML for accelerator is a very new field, we start early with systematic approaches, a solid foundation has been set[4].
To be able to improve the ML success rate, it is better to have complete data sets to train the model. Besides, knowledges to understanding the system issues well and as much data as possible with high quality are also required to make models perform better. With the proper data sets, ML applications can cover areas such as accelerator design, accelerator and beamline controls, beam tuning, operation optimization, maintenance, and many others.
In the meantime, an ultra-low emittance and high brightness 4th generation synchrotron light source, the High Energy Photon Source (HEPS) which contains over 2500 magnets and another over 1000 diagnostic devices designed by the Institute of High Energy Physics (IHEP), Chinese Academy of Science (CAS), has started its construction since June 2019. To reach the world leading goals listed in Table 1, it is necessary to have accurate installation, state-of-art equipment and high precision controls with the most advanced techniques such as machine ML. And most importantly, complete data logging systems which provide necessary data for ML and Big Data analysis in the future are required. Therefore, the control systems are vital for the HEPS which includes not only traditional control architecture design but also quality control for the projector. Also, the HEPS control system covers not only the accelerator but also the first 14 beamlines which will be constructed at the same time. To build such a complex accelerator based user-facility, it is necessary to have a complete design for the control systems along with related data and computing systems.
Table 1
Table 1HEPS main parameters
| Main parameters | Value | Unit |
|---|---|---|
| Beam energy | 6 | GeV |
| Circumference | 1360 | m |
| Emittance | 58 (<40 anti-bend) | pm·rad |
| Beam current | 200 | mA |
| Brightness | >1022 | Phs/s/mm2/mrad2/ 0.1%Bw |
| Injection | Top-up | |
| Bunch structure | 680 bunch, high brightness mode 63 bunch, timing mode | |
新窗口打开|下载CSV
Preparation for HEPS ML work will start with databases and data collection. Also, to facilitate ML for accelerator more easily, a high-level software architecture has been designed. Some preliminary results for ML on accelerators will be shown below.
1 Database Work
In the modern data era, it is essential to record every useful data and store the data systematically in persistent stores. Furthermore, applications to utilize the data should be developed. However, due to the large database scale and tremendous amount of work, it is necessary to divide the entire database into many nearly independent sub-database modules and connect them via API (Application Programming Interface) or services, or later re-join them with minor modifications. In this way the database modules can be developed independently by many institutes so that avoid accumulating data complexity to a high level which would overwhelm a single monolithic database. Furthermore, among the core database modules, they can be optionally merged via links by either device ID which is based on the role the device is played in an accelerator, or equipment ID which is merely a unique QR code or bar code.Based on IRMIS[5] which is a good overall database system for accelerators, as listed in Table 2, there are 17 database modules identified. At this stage of the project, i.e. the design and early implementation phase, databases such as Parameter List, Naming Convention, and Magnet have been developed to meet the project’s current needs. In addition, colleagues from another IHEP facility, the China Spallation Neutron Source (CSNS) is collaborating with the HEPS team to develop a Logbook, Issue Tracking database and applications for CSNS’s early operation needs. Besides the four database modules currently under development, a few others like Accelerator Model/Lattice, Physics Data and Machine State, and Work Flow Control/Traveler have been developed by colleagues for other projects which can be migrated here easily. The rest of the database modules listed in Table 2 will be developed at later time while they are needed. HEPS select MySQL as the database primary tool. Details for the three currently developing databases are described below.
Table 2
Table 2Planned database work
| ParameterList | Logbook and ssue Tracking | Cable |
|---|---|---|
| Naming Convention | Maintenance/Operǝtion | Security |
| Magnet | Inventory | Alarm |
| Accelerator Model/Lattice | Survey and Alignment | Machine Protection/Interlock |
| Equipment and Configuration | Work Flow Control/Traveler | MPS Postmortem |
| Physics Data Machine State | Document DB |
新窗口打开|下载CSV
Design Parameter Database This is a database which stores the essential HEPS parameters for keeping tracks of different design versions. The database schema was based on ESS design[6] with necessary modifications to fit HEPS own needs. Naming Convention Database For a large accelerator project like HEPS, everything has to be named according to strict rules or it is hard to manage the names. The HEPS Naming Convention database provides such a systematic tool for generating names automatically according to the rules which will be applied to both accelerator and beamline experiment instruments. Magnet Database There are about 2500 magnets in HEPS with many types. The Magnet database provides a whole magnet lifetime data storage throughout from design, manufacture, test, operation and maintenance phases. At present, the design for data tables and several test methods have completed.
2 Accelerator Controls
HEPS accelerator control system is a distributed system based on EPICS [7]. The system design principles are applying industrial standards: global timing system for both accelerator and experiments, as well as modularized subsystems for easy upgrade and maintenance. The overall accelerator control system architecture is shown in Fig. 1 with Device, Middle, and Presentation layers. The Device layer provides the control interface, such as μTCA, PXI or PLC, to devices. The Middle layer performs data assembly and persistence, and online analysis computation. Details for some control system components are described below.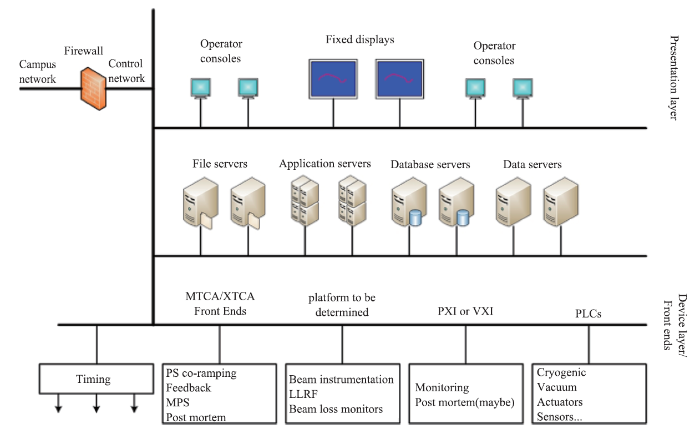 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPTFig.1HEPS accelerator control system architecture
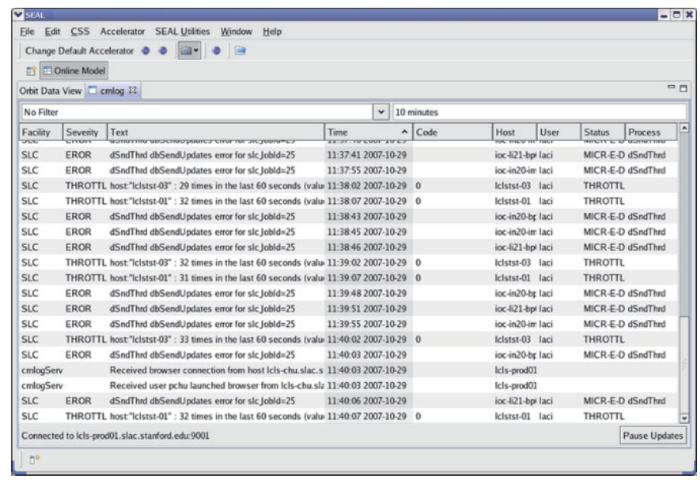
Device Control Presently HEPS selects the latest EPICS version 3 as the control system platform. The EPICS-based device control will choose mostly industrial standard with EPICS driver support. Besides fast communication networks for global timing system and fast machine protection system, the standard communication is through EPICS Channel Access (CA) protocol.One feature HEPS would like to implement is Common Message Logging (CMLog) System which basically records every single action happened in the system. When an action occurs, CMLog sends a short message with accurate timestamp via a set of API embedded in a device control routine or a software application to the CMLog database. CMLog data was mainly for fault post-mortem analysis in the future. With other accelerator and experiment data, CMLog data can also serve as the training set for ML for optimization. Fig.2 shows an example of the CMLog saved messages. The CMLog API language support should cover C, C++, Java, and Python.
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPTFig.2CMLog stored message display (from SLAC National Accelerator Laboratory)
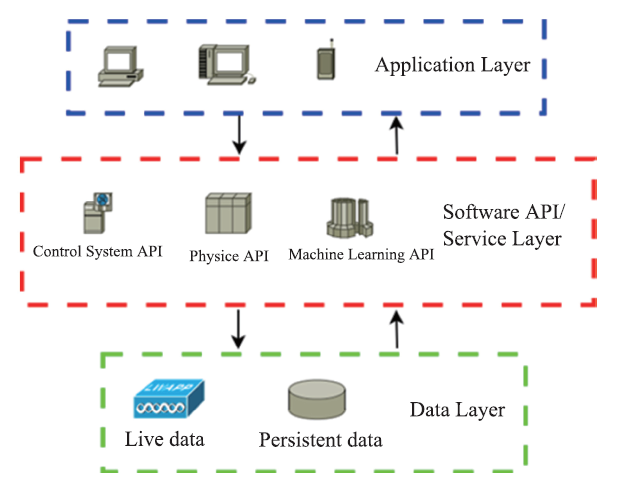
High-level Applications As shown in Fig. 3, application flow can be divided into three layers: data, software API or services, and application GUI. For better software architecture and code reusability, same functions appear in multiple applications should be converted to either regular callable APIs or service APIs in the middle layer. Furthermore, due to the nature of the functions, it is better to separate them in three groups so they don’t mixed together and lose the flexibility: control system API, physics and general-purpose API, and machine learning API. The three API groups are also released independently as separate software packages. Details for these APIs will be described below.
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPTFig.3HEPS control system architecture
Control System API HEPS accelerator as well as optical beamline control is based on EPICS control systems. APIs such as CA calls are packaged along with connection exceptions and operation loggings, so application developers do not have to go through tedious details. If there is any needs for swapping with another control system, one can simply replace the EPICS wrapper with a different alternative. HEPS is considering CS-Studio as the control system API platform. Physics and General-Purpose API Physics API provides physics specific functions such as online model calls, and general-purpose API supports certain operations like parameter scan or correlation plot. On one hand, HEPS is considering a Java-based Open XAL [8] toolkit includes not only definitive accelerator data structure but also quite comprehensive functions for most accelerators. On the other hand, beamlines can have a similar platform(s) for their physics needs. Machine Learning API Naturally different from the two categories of API mentioned above, ML API is the third API set for high-level applications. A Python-based ML API platform has been tailored for accelerator control and experiment data. Besides, ML API is also designed for accelerators to access popular ML APIs such as Scikit-Learn [9] and TensorFlow[10] easily. For instance, along with the API for calling ML algorithms, APIs for pre-processing raw data from various accelerator data sources, and the computation results showing in visual form for easy read should also be provided. All these can be done with simple APIs to greatly cut development costs down. With such a platform, physicists can use Python, a popular scripting language, to quickly develop ML-based data analysis applications. Also, one can switch among ML algorithms for quick tests. The ML API will also be responsible for converting data format to suit many popular Big Data platforms for further data analysis.
3 Beamline Controls
As shown in Fig. 4, HEPS beamline control system architecture is similar to the accelerator control. For better manpower resources sharing, the HEPS optical beamline control is handled by many accelerator control experts as well. Considering it is not practical for an individual database expert to handle all computing and data needs for every beamline processing, they should be divided into several groups for IT experts with tools and platforms built for sharing accelerators by beamlines. In addition, other standards like naming conventions and EPICS supported devices are also shared.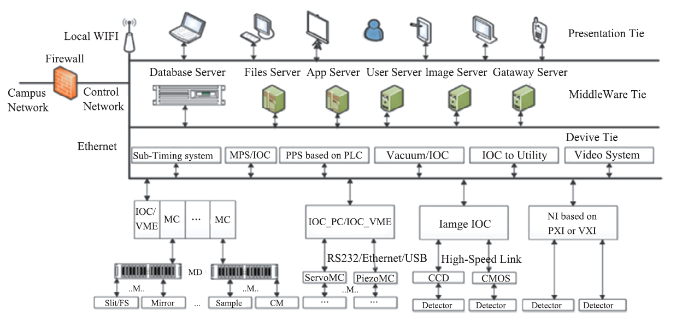 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPTFig.4HEPS beamline control system architecture
The beamline data may be much more highly-structured than the accelerator data. Therefore, EPICS 7 which support complicated data structure is considered as the data protocol for packaging the beamline and experiment data. Still, the data structure has to be compatible for future mobile applications.The data acquisition (DAQ) is considered along with the beamline controls. For the nature of fast DAQ and large amount experiment data storage requirements. Online data reduction and analysis are essential for the beamline controls. Standard data format should be chosen for compatibility with various data analysis tools and shareable among institutes.New technologies such as Internet of Things (IoT) and Edge Computing can be applied to the beamline control automation and optimization as the beamlines have distributed yet nearly isolated characteristics. With ML algorithms, beamlines have the potential to perform in much higher efficiency.With all the accelerator data are accessible to the beamline scientists, one can also perform Big Data analysis for tuning optimization and even scientific studies.
4 Preliminary Results
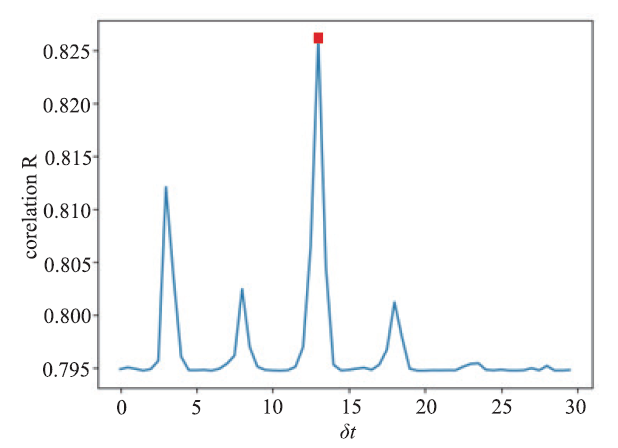
Although HEPS will not have any operation data for ML in a few years, IHEP, fortunately, has another two running facilities, BEPC-II and CSNS, which can provide data for testing ML ideas. So far, there have been two examples done with ML. Operation Data Timestamp Correction Timestamp misplacement, faced by many accelerator laboratories, is a common difficulty in accelerator machine learning application for temporal issues. Traditionally, one might have to check the timestamp synchronization between any two systems manually at tedious equipment level of settings, which is complex and requires a great effort. For older accelerators, due to the limited synchronization technologies, the problem could be even worse. Compared with traditional method, machine learning timestamp correction method, which is more convenient and with lower cost, can be used not only for detecting timestamp misplacement but also for correcting timestamps of history data.The first ML example is to align misplaced timestamps for pairs of BEPC-II Linac BPM (beam position monitors) and DC (dipole corrector) signals. In accelerator control system, because BPM and DC data acquisition programs are run in different server computers, BPM and DC signal timestamps may be misplaced after restart accelerator, which could bring troubles to orbit correction. A method based on machine learning is developed to align the misplaced timestamps. A correlation functionFig.5 shows the maximum correlation function R of each δt. It indicates that these two systems have best correlation when δt equals to 13 s.
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPTFig.5Maximum correlation function R
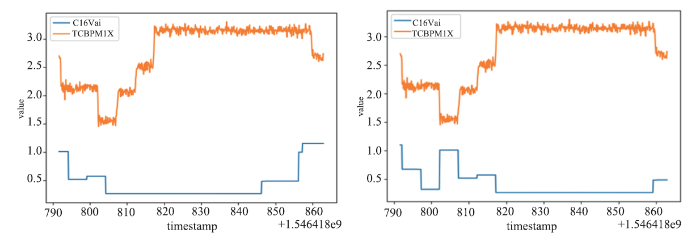
As shown in Fig. 6, after applying ML, the time shift between the DC and BPM was correctly found and was verified by the related system engineers.
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPTFig.6Signals for an upstream dipole corrector (C16Vai) and a downstream BPM (TCBPM1X) were plotted against their timestamps. The left plot is the data directly from history archiver with the timestamps directly read from the control system, and the right plot is after a 13s relative time shift obtained from ML
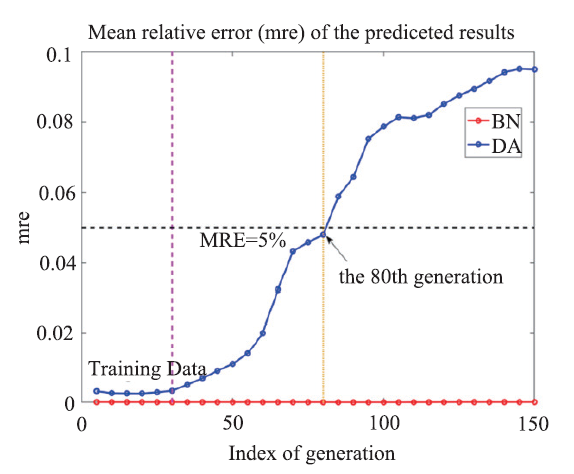
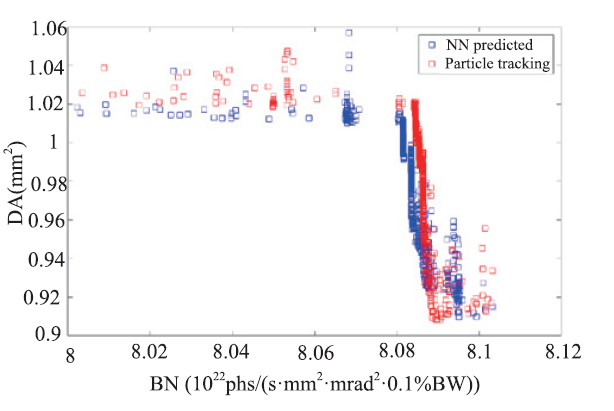
HEPS Lattice Design Application Designing a new accelerator lattice with hundreds of parameters to optimize is a very computation intensive and time-consuming job. It is very suitable to apply the ML to get surrogate quick models to replace those detailed particle tracking models.The second ML example is to apply Deep Learning Algorithm to HEPS lattice design for optimizing two competing parameters, the beam dynamic aperture (DA) and its brightness (BN). Traditionally, accelerator lattice design is done by finding the best solutions via numerous particle tracking runs. For HEPS lattice design by an optimization method based on multi-objective genetic algorithm (MOGA) [11], hundreds of iterations are needed in order to get sensible results. This work, in one hand, can take a long computation time but the project may not have so much time to wait for the best outcomes. Using Deep Neural Network (DNN) Algorithm to predict the tracking results, on the other hand, can greatly reduce the computing time for the lattice design and, therefore, leave more time for others.To shorten the optimization time, an artificial neural network is established. There are 61 free variables in total to be varied, including drift lengths, lengths and bending angles of longitudinal gradient bending magnets, gradients of quadrupoles, sextupoles and octupoles etc. These free parameters are considered as inputs of the network, and the values of DA and BN are taken as outputs. The data obtained by previous MOGA optimizations of this lattice are divided into two parts, the training data and the testing data. The data in the 1-30th generations of MOGA is treated as training data and the data in the 31-150th generations is for testing data. There are 30000 samples included in the training data and 120000 samples in the testing data. Each sample consists of 61 free variables as input and 2 objectives as output. As shown in Fig. 7, after trained with training data for several epochs, the network can predict the values of BN in testing data at a very high accuracy (more than 99.9%). When predicting the values of DA, however, it is difficult to achieving such an ideal percentage for the strong nonlinear effects. Nevertheless, a high accuracy of over 95% can be achieved when the network is used to predict DA of the data prior to the 80th generation of MOGA. This network is then applied to the MOGA optimization of the HEPS lattice to replace the particle tracking method to evaluate the objectives. After evolving for 100 generations, the objectives of the optimized solutions are compared with the results obtained with standard MOGA. Similar results are obtained by the artificial neural network accelerated MOGA and the standard MOGA, which is shown in Fig. 8.
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPTFig.7Mean relative error of predicted lattice simulation results for BN and DA optimization
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPTFig.8The optimized results in the 100th generation of MOGA plotted in the objective space. The red squares are the results obtained from standard MOGA and the blue squares are obtained from the artificial neural network accelerated MOGA
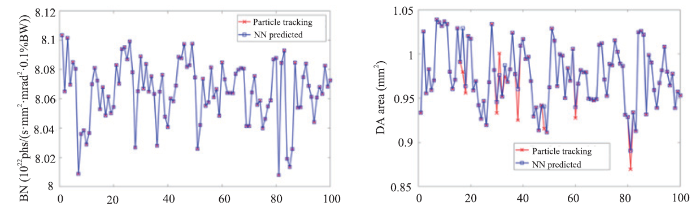
The computation time for the two approaches are very different as shown in Table 3, almost five orders of magnitude improvement with the artificial neural network. To avoid error of the predicted results impacting the comparison, the real values of the optimized solutions are also evaluated and compared with the predicted results, as shown in Fig. 9. The results are 100 randomly selected solutions in the population of the 100th generation of MOGA, which are numbered in the X-axis. The Y-axis represents the values of the objectives in the optimization. The predicted values of BN is almost the same as the evaluated results. On the other hand, the predicted values of DA are also almost the same as the evaluated results for most solutions, and only slight differences are observed for few solutions. As this model has been proven to be effective in prediction of the two nonlinear dynamics parameters in the HEPS lattice, the future plan is to train another model to predict other complicated physical parameters, such as Touschek lifetime of electron beam and to apply the trained model to regress these parameters to speed up the optimization time.
Table 3
Table 3Computation time comparison
| Single thread (s) | 62-thread parallel computing (s) | |
|---|---|---|
| DNN | 0.3944 | 0.0092 |
| Particle Tracking | 78020 | 1414.2 |
| Improvement | O(5) | O(5) |
新窗口打开|下载CSV
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPTFig.9Comparison of the results predicted by the neural networks and evaluated by the particle tracking method
5 Project Support
To better integrate project data with technical data, HEPS business sector’s procurement database and the Inventory database will be linked for better cost control and future operation maintenance utilization. The link between these two databases will be two unique equipment IDs in the form of bar code, or QR code. Applications will be developed to take advantage of these joint databases. Other project databases including document server and personal folders may be on SharePoint platform, but still can be connected with MySQL databases by simple programming.6 Conclusion
ML for accelerators has being gaining initial traction. Data preparation is crucial for ML and a good design for the database have been identified. Control systems and high-level software are also important to facilitate the ML for accelerators. The HEPS control systems have been initially designed and a few tasks have been started. Other future accelerators such as CEPC can also follow this approach to utilize the ML technology. Modern technologies will be applied to the actual implementations. Due to a large effort needed to complete the entire infrastructure, the architecture has been designed in modules which can be developed independently. Collaborations are formed to share the work load. All the databases are saved in GitHub repository for easy collaboration access[12]. This overall modularized architecture design gives us the highest flexibility and efficiency for development as well as ensure high-quality and reliable products. Also, researches in new fields such as Big Data analysis have been started.Acknowledgements
The authors would like to thank the Controls Group of CSNS, the HEPS Beamline Experiment Groups, and many other members of the IHEP Accelerator Center and IHEP Computer Center colleagues for many fruitful discussions.参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
https://ipac2019.vrws.de/.
URL [本文引用: 1]
http://accelconf.web.cern.ch/AccelConf/pcapac2018//.
URL [本文引用: 1]
http://icalepcs2019.vrws.de/.
URL [本文引用: 1]
[本文引用: 1]
URL [本文引用: 1]
pp.
[本文引用: 1]
[本文引用: 1]
pp.
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}