Application-driven Big Data and Artificial Intelligence Integration Platform Construction
Kang Bo1,2, Xia Zijun2, Meng Xiangfei2收稿日期:2019-08-25网络出版日期:2019-01-20
| 基金资助: |
Received:2019-08-25Online:2019-01-20
作者简介 About authors

康波,1986年生,博士,国家超级计算天津中心高级工程师,目前主要开展不同体系结构下大规模深度学习并行实现、人工智能可视化交互建模训练、典型场景算法开发与应用等研究。
本文中负责融合平台框架设计、应用分析。
Kang Bo, born in 1986, male, Ph.D., senior engineer of the National Supercomputing Tianjin Center, is currently conducting research on parallel implementation of large-scale deep learning under different architectures, interactive modeling training of artificial intelligence, and industrial-based AI development and application.
In this paper, he is responsible for the design and application analysis of the fusion platform.
E-mail: kangbo@nscc-tj.cn

夏梓峻,1986年生,硕士,国家超级计算天津中心应用研发部副部长,主要研究方向为高性能计算应用研发、大规模并行计算研发与优化、高性能应用软件研发、数据分析与处理、深度学习应用研发、企业智能应用场景解决方案。
本文中负责融合环境方法介绍和应用分析。
Xia Zijun, born in 1986, male, deputy director of Research & Application Department,National Supercomputer Center in Tianjin. His main research field contains HPC application R&D, massively parallel computing R&D, data Analysis, deep learning and industrial application solution.
In this paper, he is responsible for writing the introduction and application analysis of the integrated environmental approach.
E-mail: xiazj@nscc-tj.cn

孟祥飞,1979年生,理学博士,国家超级计算天津中心教授级高级工程师,主任助理,应用研发部部长,中华人民共和国国家发展和改革委员会“大数据处理技术与应用”国家地方联合实验室主任工程师;中国计算机学会高性能计算专家委员会常委,中国医促会医学数据与医学计量分会副主委,中国抗癌协会肿瘤人工智能委员会副主任委员。主要研究方向为大规模并行处理技术、大数据技术研发与应用等。
本文中完成了论文的国内外现状分析、方法原理和结论展望。
Meng Xiangfei, born in 1979, male, Ph.D., professor-level senior engineer, assistant director of the National Supercomputing Tianjin Center, lead of application research and development department, director of "Big Data Processing Technology and Application" National and Local Joint Laboratory, Member of the Standing Committee of the CCF High Performance Computing Expert Committee, Vice Chairman of the Medical Data and Medical Measurement Branch of the China Association for the Promotion of Medical Sciences, and Deputy Director of the Cancer Artificial Intelligence Committee of the China Anti-Cancer Association (CACA). His main research focuses on large-scale. parallel processing technology, big data technology R&D and application.
In this paper, he is responsible for completing the analysis of both domestic and foreign research review, method principle and conclusion.
E-mail: mengxf@nscc-tj.cn.

摘要
【目的】介绍了面向产业需求的大数据与人工智能融合平台建设思路,形成了推动传统产业智能化、智能科技产业化的发展实施方案,为计算创新驱动提供参考。【方法】基于面向行业应用场景的数据特征理解和融合平台需求分析,阐述了基于应用驱动的超级计算与大数据、云计算、人工智能、物联网融合的平台层次结构,在基础融合环境、数据整合框架、业务系统几个方面系统介绍了该融合平台的体系架构和实现。【结果】基于该平台,实现了在装备制造、网联汽车、医疗健康等领域的典型应用,具备较好的适用性。【局限】作为公共开源开放平台提供服务,机构公信力、数据安全性是其下一步需要解决的重要问题。【结论】应用驱动的大数据与人工智能融合平台可作为社会开发、政府可控的智能产业科学发展生态的重要组成部分,进一步解决我国智能产业领域创新能力和创新支撑平台不足的现实问题。
关键词:
Abstract
[Objective]In order to provide references for computational innovations, an industrial needs driven integration platform for big data and artificial intelligence analysis and application is proposed to promote the traditional industry intelligence and intelligent technology industrialization. [Methods]Based on the integration of both data feature understanding and platform requirements in industry-oriented application scenarios, the application-driven platform hierarchy in supercomputer center is designed in a fused architecture consists of supercomputing, big data, cloud computing, artificial intelligence and internet of things, which contains implications on physical facilities, system software and management system. In the supercomputer center, it mainly integrates service-related hardware facilities for big data, super-computing and cloud computing to realize data sharing, high-performance processing, and data security control. By eliminating the difference between various data sources, the platform provides an unified standard data access interface for upper-layer applications, which promotes standardization of big data processing in related industries for resource and data sharing. As an important field of big data applications, the high-efficiency big data application platform for industrials combines with the industrial cloud platform to realize data collection, transmission, collaboration and application by integrating the physical device, virtual network and big data analysis methods. The characteristics of industrial-based big data and artificial intelligence require innovative applications that support the production tasks, such as design, production, sales, operation and maintenance. [Results]Based on the platform, it has achieved typical applications in industrial fields such as equipment manufacturing, networked vehicles, medical health, etc., showing good applicability. In manufacturing, the platform is a tool for product supplier quality management control, carrying out abnormal inspection and prediction of parts and components, and achieving management ability to control the entire product chain. In networked vehicle, by collecting vehicle driving data and using deep learning modeling, it is possible to analyze the safety of autonomous driving and driving behavior. In disease screening, big data and artificial intelligence analysis for radiological imaging, pathology images, and electronic medical records can help doctors complete analysis of repetitive tasks and complex tasks. [Limitations]As a public open platform to provide services, institutional credibility and data security are important issue to be solved in the next step. [Conclusions]Application-driven big data and artificial intelligence integration platform acts as an important part of social development and government-controllable intelligent industry science development ecology, which further solves the practical problems that insufficient innovation ability in China's intelligent industry.
Keywords:
PDF (12472KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
康波, 夏梓峻, 孟祥飞. 应用驱动的大数据与人工智能融合平台建设. 数据与计算发展前沿[J], 2019, 1(1): 35-45 doi:10.11871/jfdc.issn.2096.742X.2019.01.005
Kang Bo.
引言
近年来,随着新兴信息技术的产生和应用,大数据、人工智能融合应用服务时代开启,并成为全球创新发展的重大驱动,国家、企业及相关行业机构都在向大数据、人工智能看齐,抢占数据创新的先机,努力成为数据创新的最大获益者。在“十三五”期间,国家相继发布大数据[1]、人工智能国家战略[2],推动大数据、人工智能发展成为国家在新的社会、技术发展阶段创新发展的重要手段。由于信息技术驱动,社会已进入计算范式与数据范式并存的高度信息化时代,大数据代表的信息化新阶段不断推动信息技术融合,物联网和互联网成为形成、产生海量数据的手段,云计算成为汇聚和处理海量数据的手段,新一代人工智能成为处理海量数据、实现数据价值再造的手段。因此,要推动两化深度融合,打造行业智能深度应用场景,需要一个系统性信息化手段,实现计算能力、数据能力与网络能力的融合,而超级计算可提供强大的计算能力与大规模数据存储能力,是实现这些信息技术融合的基础支撑,同时也是实现数据、计算、方法和应用场景融合的有效支撑平台[3,4,5]。
医疗健康、油气能源、生物基因、智慧港口、建筑信息模型(Building Information Model,BIM)+地理信息系统(Geographic Information System)、智慧城市、电子政务等这些关系国计民生的重要应用领域的快速发展均依赖于计算支撑的数据分析技术与基础设施[6],需要以高端信息技术特别是大数据、人工智能等技术为支撑来实现跨越式发展,国家超级计算天津中心已经在这些产业领域开展诸多创新,并进入实质产业化阶段[7]。因此要紧紧抓住发展先机,加快大数据、人工智能关键共性技术突破和自主高性能软硬件融合一体化服务研发,推动基础设施环境建设,促进面向产业的应用场景打造,为培育和发展战略性新兴产业提供动力支撑。
1 面向行业的数据特征理解
当前,面向行业领域智能应用场景打造过程中,数据作为最重要的资产和新型的生产要素,亟待解决如下问题:(1)数据采集。针对设备、系统和生产流程等生产业务不同对象的数字化实现,解决数据来源问题,同时为数据处理提供原料。
(2)数据融合。数字化之后,需要实现“从散到融”[7],通过网络实现数据的流动、交互、复用和共享,是促进业务能力从单项服务到整体覆盖的必经之路。
(3)数据价值挖掘。针对跨业务环节、复杂应用需求等背景,实现数据高价值信息提取,必须结合超级计算、大数据、人工智能、云计算等关键技术创新,实现基于应用需求的信息挖掘。
例如,工业大数据和传统互联网大数据在数据采集、数据传输、数据共享服用和数据价值提取等多个方面存在显著不同[8,9,10,11,12,13],如表1所示。
Table 1
表1
表1工业大数据和传统大数据区别
Table 1
| 业务环节 | 工业大数据 | 传统大数据 |
|---|---|---|
| 采集 | 必须通过传感器等实现生产环节、作业环节等数据采集,实时性要求高 | 互联网产生的数据为主,包括文字、图片等关系型数据,事务性操作衍生数据比例大 |
| 处理 | 包括格式转换、数据异常处理、质量控制等,真实性和可靠性、完整性要求高 | 数据异常处理,包括去重、约简等 |
| 存储 | 涵盖结构化和半结构化,非结构化数据也逐渐增多,数据关联性高 | 针对非结构化数据,有不同的存储方案支撑 |
| 分析 | 建模分析复杂,精度和可靠性要求非常高,实时性要求高 | 数据相关性分析为主,精度和可靠性要求不高 |
| 共享 | 逐渐从以往单个业务服务向业务整体覆盖过渡,数据共享要求高 | 以单项业务服务为主,对其他环节数据需求较少 |
| 可视化 | 实时性要求高,涉及工业流程,要求预警和趋势可视 | 数据分析结果展示 |
新窗口打开|下载CSV
与此同时,大数据、人工智能已经成为新的社会、技术发展阶段推动国家创新发展的重要手段,促使行业应用不断泛化和扩展。因此,应用驱动数据价值再创造、数据标准体系建设和基础设施能力建设三个方面是组织好数据、利用好数据、表达好数据,并且针对行业深度智能应用场景打造的重点:
(1)应用驱动的数据价值再创造。由于信息化、数字化关键技术突破和行业应用需求不断提高,数据管理困难、数据传输与共享不畅、数据价值密度低等实际问题突出,以应用为导向,实现数据价值再创造是发展的根本目标。
(2)数据获取、标准体系构建与科学管理。数据源多样化,数据结构不同,包括数据库、文本、图片、视频、网页等各类结构化、非结构化及半结构化数据,为后续数据分析带来了巨大困难和挑战,针对数据源采集数据、预处理和集成、分布式高效存储,为后续环节提供统一、完整、可靠的高质量数据集是发展基础。
(3)网络设施能力、高端电子信息技术发展。社会高度信息化将产生海量多源异构数据和场景应用需求;网络化使得数据传输、访问、共享更加方便、快捷和高效;标准体系建设则确保数据的一致性、可靠性、完整性。三者的协同发展是大数据产业发展的保障。
2 大数据与人工智能融合平台
面向产业的超级计算应用和面向人工智能的超级计算应用成为超级计算的热点。今年召开的国际超级计算会议(ISC 2019)专门设立了产业日和机器学习日,凸显出国内外高性能计算机构对这两个领域的重视[14]。“计算+仿真”成为工业应用热点,“计算+深度学习框架”是人工智能应用的主流模式,“云计算+数据处理”是目前各大互联平台数据处理的通用模式[15,16,17,18,19]。通过多年的实践,国家超级计算天津中心从应用需求和信息化技术发展需求两个维度,实现了“超级计算与云计算、大数据、人工智能”环境深度融合,并将之应用到了实际产业应用中,是国内外超级计算服务产业应用的新探索。2.1 超级计算与云计算、大数据、人工智能融合环境
大数据与人工智能融合平台首先是硬件设备的融合,在超算中心,主要是整合超级计算、云计算、大数据、人工智能等相关平台设施,实现不同平台数据共享、高效能处理和数据安全可控(图1)。同时,构建高效稳定的大数据存储环境,例如多层次式和动态可扩展的海量数据存储系统研究。另外,面向平台,形成分布式并行数据库、数据处理集成工具集等共性技术(图2)。图1
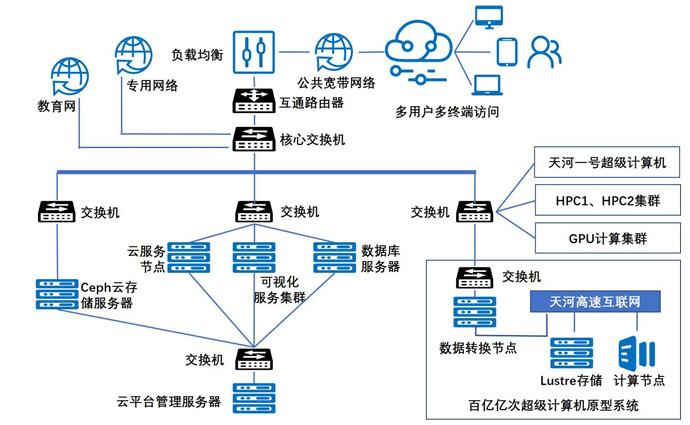 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1超级计算与大数据、云计算融合设施框架
Fig. 1Fusion architecture on supercomputing, big data and cloud computing infrastructures
图2
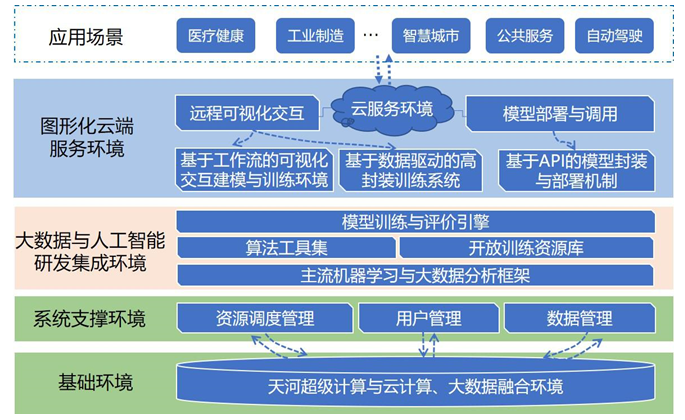 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2超级计算与大数据、云计算、人工智能融合服务环境
Fig. 2Fusion environment on supercomputing, big data, cloud computing and artificial intelligence
稳定高效的网络设施是融合环境的基础支撑。通过高效网络,保证了不同载体间的数据交换。整个融合环境构建了内部网络和外部网络体系。内部网络体系包括通用网络设施和天河高速互联网络,前者通过交换机等实现了超级计算机、云计算服务器、存储服务器、可视化服务器等不同设施之间的物理互联,后者用于实现超级计算机内部计算节点与Lustre公共存储之间的高速通信和数据交换。外部网络通过配备高带宽公共互联网络和多网冗余,满足大数据用户和企业对数据传输速度和效率的要求。同时结合地区实际,开通了面向天津市区、空港经济区、中新生态城的专有网络,以满足对数据传输要求非常高的应用企业和用户需求;开通了教育专网,以满足高校在线实训、科学计算资源调研等需求。通过互联网、专网建设构建和完善了高效的服务网络体系,保障用户数据传输的高效和实时性。
融合计算设施是融合环境的基础保证。大数据和人工智能分析需要充足的算力作为支撑。面对不同的场景,其所需算力类型差异较大。针对科学数据分析计算,如基因数据分析、材料数据分析等,需要双精度(64位)的高性能计算能力;对于人工智能模型训练,则需要有单精度(32位)或半精度(16位)的高性能计算能力;对于数据采集、统计等事务性数据处理,则需要云计算的能力;对于大规模数据的高效展示,则需要可视化渲染计算能力。因此,融合平台需要具备超级计算与云计算融合的计算处理设施,来实现对事务并发、数据并发的高效处理。在底层形成具有分布式计算、异构高性能计算、内存计算、众核计算等多类型计算资源,利用多层级资源调度策略,形成支撑多样性计算的融合资源池。
大规模数据存储设施是融合环境的数据载体支撑。通过统筹云对象存储、数据库存储、高性能计算存储设施,形成大规模动态可扩展存储设施。针对数据采集、预处理、分析、建模、计算/训练、可视化、部署等不同应用环节和场景,构建了包含近线、在线、高速内存存储的海量层次式动态可扩展存储技术。针对结构化数据、非结构化数据和半结构化数据等不同来源和格式的数据对底层存储系统、时效性、应用处理的需求,平台解决了大数据分级存储构建、分级存储性能优化、数据共享、数据迁移和去重等关键问题,支撑了海量大数据的存储和处理。在容灾备份方面,平台采用符合信息系统灾难恢复规范的数据灾备管理技术,保障数据的安全。
2.2 多源异构数据整合框架
融合平台应充分屏蔽底层各类数据源之间的差异,为上层应用提供统一标准的数据访问接口。推动相关行业的大数据处理流程的标准化,实现资源共享、数据共享,其核心任务是将相互关联的分布式异构数据源集成到一起,让用户以透明的方式访问这些数据源,以便消除数据无法共享、业务流无法打通等信息孤岛现象。数据整合流程中,结合高性能计算,通过并行模式抽取通用数据的属性和关键词、并行格式转换,实现并行数据建模和管理。机器学习作为数据整合的有效手段,用其训练出统一数据模型,通过语义分析,实现产业数据多样性的横向关联和纵向关联,保证数据的高效查询、检索关联和简单分析处理。最后,整合形成数据分析处理需要的标准化数据。通过建立从数据采集到数据存储的规范流程,形成统一标记识别码,使数据在整合、存储、处理等环节进行有效传输。在数据表示标准上,需要构建数据编码、元数据、非结构化数据、大数据集统一描述规范等来保证数据的有效检索与管理。在数据存储标准上,需要结合融合环境的存储设施,构建非关系型数据库、非结构数据存储系统相关规范,借助分布式文件系统、非关系型数据库等技术实现,解决数据一致性、数据放置、故障检测、可扩展性等问题。基于此,构建研究交互式异构数据分析框架,最终形成一套高效的大数据分析软件框架,服务实际生产环境下的数据处理。
同时,整合目前已有的大数据分析方法,利用现有的Spark、Hadoop等工具,构建通用处理工具集,提供简单、直观的用户接口,支持交互式全可视化拖拉操作。针对接入的开源开放数据源和产业数据源,支持主流关系型数据库如MySQL、Oracle、PostgreSQL和非关系型数据库如MongoDB、Redis,避免繁琐的算法参数、数据类型、数据类别等因素影响,降低数据处理使用门槛,为用户多样性的大数据异构数据分析提供支持。
2.3 服务生产的业务处理系统
融合平台以国家超级计算天津中心的“天河一号”超级计算机与“天河”百亿亿次超级计算机原型系统、天河工业云平台、天河政务云平台等软硬件资源为依托,以大数据和人工智能产业创新发展为牵引,支持基础设施统筹发展,打破数据资源壁垒,形成大数据应用创新系统支撑环境、工业大数据应用创新平台和公共数据共享开放平台。工业领域是大数据和人工智能应用的重要领域,融合平台通过与工业云平台结合,实现物理设备与虚拟网络融合的数据采集、传输、协同和应用集成,运用大数据分析方法,结合工业领域特点,开发支撑设计、生产、销售、运维等工业大数据领域的创新应用(图3)。图3
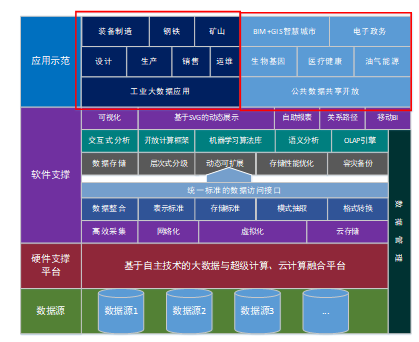 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3服务生产的业务处理系统框架示意图
Fig.3Schematic diagram of processing system framework for service production
在设计领域,以数字化模型为载体,利用仿真研发设计等技术,实现粗放式设计模式向精准化、数字化设计模式转变;通过制定面向行业的典型工业大数据字典,实现产品各设计环节大数据的高度有序化展示,为设计提供知识参考,提高设计效率。在生产领域,利用物联网技术开展生产线的工业大数据采集,构建大数据处理模型,实现生产全流程的实时监控,并基于仿真结果优化生产流程;建立生产各要素的模型仓库,利用人工智能等手段构建基于训练模型的专家库,对生产质量进行控制与预测。在销售领域,依托工业云平台,开展企业内部的历史经营大数据、用户行为大数据以及第三方大数据的综合分析,通过深度数据挖掘,建立用户行为、产品特征以及外部影响与销售的耦合关系,提出更符合市场规律的营销策略与销售模式。在运维领域,根据不同行业运维特点,构建“大数据+云计算+HPC”的多平台融合体系,高效整合各工业运行环节大数据,实现对运行各环节的可视化监控,对运行维护中的重大潜在问题及时进行数据分析与仿真模拟,降低故障风险与运维成本。
应用平台按照工业大数据分析流程,按照多层次进行设计与建设。在数据采集与预处理方面,以生产经营业务、设备物联和外部数据为基础,汇总产品、物料、产线、工艺、质量、设计、客户、工业链、市场等多种类型工业数据。对多源异构数据进行规范化预处理,产生全链条可流动的整合数据。在数据建模与管理方面,结合工业云平台和大数据处理建模技术,开展用户、产品、流程、产线等的建模、处理与分析,实现各类工业场景数据结果的可视化,对数据质量、能力成熟度、数据共享性与安全策略进行管理。在工业化应用方面,基于建模数据和数据管理结果,开展虚拟仿真、协作设计、流程优化、远程维护、智能服务等不同工业场景应用[8,9]。
3 基于融合平台的典型应用服务
应用驱动的融合平台,目标是最大化地满足大数据应用对信息技术平台的要求,现在这一平台方案已经在气候气象、装备制造、智能网联车、智慧港口、油气能源、BIM+GIS智慧城市、电子政务等产业大数据应用领域开展服务支撑和应用示范,其中有些领域目前利用了这一平台方案中的部分能力,而工业制造、智能网联车、医疗健康等已经逐步成为融合平台系统能力充分施展的典型代表。3.1 基于大数据的生产供应链管理
生产供应链质量控制是制造业质量管理的重要方面,其直接决定了产品整体的质量水平。随着制造业发展,零部件的生产和采购越来约细化,一件产品可能需要多达上百家的供应链条来保证,传统的线下抽样检查已不能满足先进制造的需求。基于天河大数据与人工智能融合服务平台,接入到各产品零部件供应商的生产过程中,通过直接导入、线上录入或OCR智能录入等方式,将生产过程的过数据汇聚起来,形成面向供应链管理的数据资源池。针对生产能力水平较低(生产过程产品质量波动大、不稳定)的部件记录部件,通常有10多个特性,平台按照每天录入收集特性数据上百条,通过传统统计方法和业务分析,初步分析部件特性间的相关性,筛选构建形成部件特性的特征数据列,根据历史故障分析确定数据列的时间向量长度,以此采集整理形成训练数据集。利用平台集成工具集,开展数据特征工程和标准化处理。基于RNN的时序分析方法,利用平台训练系统和计算能力,开展模型训练和评估,实现其生产异常的监控和预测。基于结果,构建异常字典,形成可指导质量管理的智能专家库,为生产过程的质量智能监控提供帮助(图4)。图4
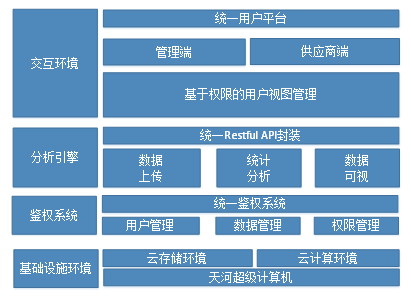 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4基于大数据的生产供应链管理框架示意图
Fig.4Schematic diagram of production supply chain management framework based on big data
3.2 汽车智能辅助驾驶应用
目前,融合平台结合视频检测、语音检测等技术,通过深度学习大规模数据训练,为汽车制造商提供辅助驾驶研发支撑,实现数据采集、预处理、特征提取、数据分析、模型设计与训练、模型部署全环节贯通的大数据与人工智能研发服务平台(图5)。图5
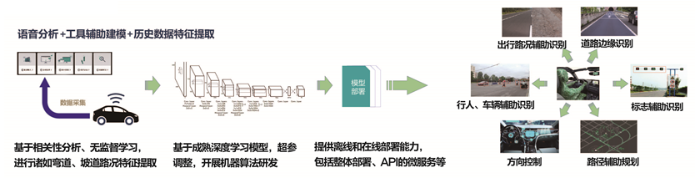 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5基于融合平台的智能驾驶辅助应用研发体系
Fig.5Intelligent driving assistance application development system based on fusion platform
基于天河大数据与人工智能融合服务平台的数据分析工具集和人工智能训练引擎,联合厂商共同设计实现路况识别、辅助标志识别、辅助驾驶、设备异常预测与预警等算法模型,并基于平台在算法、算力与应用场景的融合提供在线/离线相结合的应用部署服务。
例如,设备异常预测与预警方面,提供包括电子系统异常散点识别、电子系统异常关联识别、基于动力学的底盘异常分析、操作对异常的影响分析、环境对异常的影响分析等,实现数据解析、异常特征抓取、降低新车型召回风险,减少时间与人员成本,并系统化地积累经验,成为可重复执行的异常模型资产价值(图6)。
图6
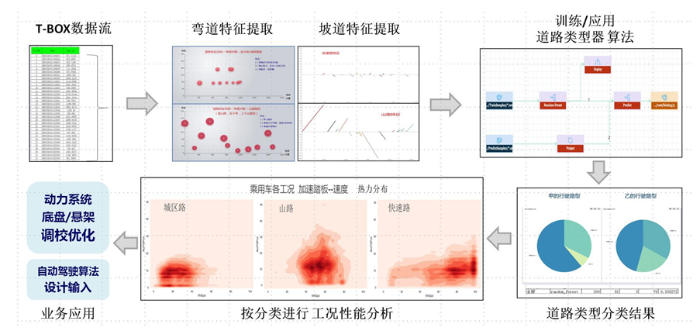 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6车辆应用特征分析与可视化
Fig.6Vehicle application feature analysis and visualization
3.3 智能医学辅助诊断
面向医院的多模态分析,开展了面向放射医学影像、病理图像、电子病历的分析工作(图7)。医学智能分析需要解决大规模数据格式转换问题,比如单张的病理切片或单病例CT切片可达到2GB以上,导致用于训练分析的数据体量达到10TB的规模,通过格式转换、增广等处理后,构建的数据集会达到>100TB以上的数据规模,平台通过构建层次式动态可扩展存储和高性能计算的支撑系统来开展人工智能模型的训练。平台针对图像,集成了针对非结构化图像的存储格式、尺寸调整、对比度等处理算法。在放射医学影像方面,针对脑部出血点检测、肺结节识别,利用平台建模功能,分别形成了面向辅助医疗应用的医学影响检测系统。在病理图像方面,针对鼻咽癌、乳腺癌等癌变判别,达到了80%以上的敏感性和特异性,在推入实际应用后将有效降低患者额外仪器检验的成本,实现了对肿瘤辅助检测的支撑。在全院患者风险评估方面,通过对电子病理数据的特征提取,建立个人风险指标动态创建,实现对全院住院患者的动态监控,有望减少因漏诊或漏检引起的医疗事故,提高救治水平。图7
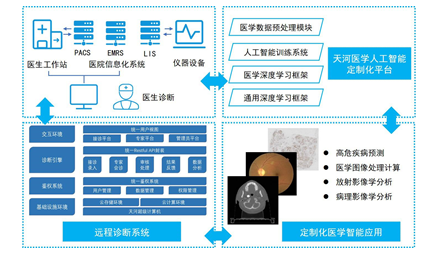 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7智能医学辅助诊断系统
Fig.7Intelligent system for computer-aided diagnosis
3.4 基于专有网络的协同大数据应用
结合天津的产业应用实际情况,面对实时气象预报、基因检测等对数据传输要求较高的行业,融合平台通过专有光纤网络接入,提供高速网络以实现超级计算和海量数据处理能力的软硬件支撑服务(图3)。使用机构将这些能力接入自身行业应用平台中,实现基础平台与实际应用场景的协同。在基因检测方面,由检测机构采集孕检相关数据,实时传送到超算中心基因数据处理应用平台,利用超级计算设施,进行数据的实时处理与分析,最后得出检测报告[7]。通过基于专网的融合平台接入,实现了数据处理和临床应用的无缝对接,更好地为用户提供健康服务。
在气象预测方面,通过专网接入,实现了实时气象基础观测数据和参数传入,并在融合平台设施上实现数据存储[7]。借助融合平台部署的不同模式的气象预报系统开展实时气象预报,基于深度学习框架具备了开展高维参数的7天内气象预测与参数优化等工作的能力。计算结果数据进行整合和部分可视化计算后,返回至气象局的气象预报系统,为气象预报提供决策参考。
4 结论与展望
应用驱动的大数据与人工智能融合平台可进一步解决我国智能产业领域创新能力和创新支撑平台不足的现实问题。产业领域智能研究、应用转化是一个跨界融合的系统工程,需要信息技术领域和产业行业领域深入合作,建立联合实验室、协同创新中心,实现强强联合、相互推动和支撑,这是非常有效的协同发展方式。大数据、人工智能促进了政府治理模式、产业生产方式、公共服务形式的变革,其同高性能计算、云计算、物联网等技术融合,支撑信息技术新时代的到来。在大数据、人工智能发展方面,不仅要促进芯片、通信、系统软件等电子信息基础产业的发展,同时在经济、社会发展的过程中,应注重标准化和信息化体系建设,加大网络基础设施建设,提升数据流通效率,降低流通成本。以计算创新驱动为切入点,加快推进“超级计算与云计算、大数据、人工智能、物联网”融合模式在工业制造、医疗健康、公共服务等领域的应用水平,形成自主可控、社会开放、公信力强的智能产业科学发展生态。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
URL [本文引用: 1]
URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 4]
[J].
[本文引用: 2]
[本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
https://2019.isc-program.com/. [2019-09-08].
URL [本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}