Survey on Federated RDF Systems
Peng Peng1, Zou Lei2收稿日期:2019-08-30网络出版日期:2019-01-20
| 基金资助: |
Received:2019-08-30Online:2019-01-20
作者简介 About authors

彭鹏,1987年生,湖南大学信息科学与工程学院,助理教授,博士,主要研究方向为基于图的分布式知识图谱数据管理。
本文主要贡献:文献调研。
Peng Peng, born in 1988, is currently an Assistant Professor in College of Computer Science and Electronic Engineering at Hunan University. He received the Ph.D. degree in Computer Science from Peking University in 2016. His research interest includes graph-based management on distributed knowledge-graph database.
In this paper he is mainly responsible for literature research.
E-mail:hnu16pp@hnu.edu.cn

邹磊,1981年生,北京大学王选计算机研究所,教授,博士,主要研究方向为图数据库与语义数据管理。
本文主要贡献:背景介绍。
Zou Lei, born in 1981, is currently a Professor in Wangxuan Institute of Computer Technology at Peking University. He received the Ph.D. degree in Computer Science from Huazhong University of Science and Technology in 2009. His research interests include graph database and semantic data management.
In this paper he is mainly responsible for the introduction of background.
E-mail:zoulei@pku.edu.cn

摘要
【目的】资源描述框架(Resource Description Framework,英文简写RDF)作为一个知识表示的模型,已经被广泛地用在各种科学数据管理的应用中来表示知识图谱。同时,SPARQL(Simple Protocol And RDF Query Language)作为一种结构化查询语言则被用来支持对RDF知识图谱数据进行查询检索。随着越来越多的数据提供者将他们的数据表示成RDF知识图谱形式,如何将不同数据提供者“自治”的RDF知识图谱数据整合成一个“联邦型RDF数据管理系统”就成为一个挑战。【文献范围】本文对现有不同的联邦型RDF数据管理系统进行综述。【方法】不同联邦型RDF数据管理系统之间主要的区别体现在查询分解与数据源选择策略以及查询处理与优化策略。【结果】目前联邦型RDF数据管理系统的查询分解与数据源选择策略可以分成基于元数据的策略和基于ASK查询的策略;而联邦型RDF数据管理系统的查询处理与优化策略是在System-R 式动态规划的基础上提出了若干优化连接策略。【局限】目前联邦型RDF数据管理系统尚未研究如何支持SPARQL 1.1。【结论】联邦型RDF数据管理系统可以支持分布在多数据源知识图谱数据的整合,是未来知识图谱数据管理的一个重要研究方向。
关键词:
Abstract
[Objective] Resource Description Framework (RDF), a standard model for knowledge representation, has been widely used in various scientific data management applications to represent the scientific data as a knowledge graph. Meanwhile, Simple Protocol And RDF Query Language (SPARQL) is a structured query language to access RDF repository. As more and more data publishers release their datasets in the model of RDF, how to integrate the RDF datasets provided by different data publishers into a federated RDF system becomes a challenge. [Coverage] In this paper we provide an overview of the studies of federated RDF systems. [Methods]The major differences among different federated RDF systems are different strategies for source selection guided query decomposition and query processing optimization. [Results] Existing query decomposition and source selection strategies in federated RDF systems can be divided into two categories: metadata-based and ASK-based strategies; Query optimization strategies in existing federated RDF systems are some joint optimizations based on System-R style dynamic programming. [Limitations] Existing federated RDF systems still do not discuss how to support SPARQL 1.1. [Conclusions] Federated RDF systems can integrate distributed RDF graphs among different sources, which means that it is an important future research direction.
Keywords:
PDF (7483KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
彭鹏, 邹磊. 联邦型RDF数据管理系统综述. 数据与计算发展前沿[J], 2019, 1(1): 73-81 doi:10.11871/jfdc.issn.2096.742X.2019.01.008
Peng Peng.
引言
由于科学数据本身存在的复杂结构,以及它们之间的复杂关联性,很多科学数据发布者将其数据表示为知识图谱的形式。比如,由欧洲生物信息研究所、瑞士生物信息研究所以及美国蛋白质信息资源中心构建的一个全面的、高质量的、可免费使用的蛋白质序列与功能信息知识图谱UniProt[1];由阿尔伯塔大学构建的一个生物信息学和化学信息学知识图谱DrugBank[2];由京都大学化学研究所构建的关于基因组、生物化学物质等信息的知识图谱KEGG[3]。目前,在生命科学领域构建知识图谱的过程中,知识图谱的表示方式以W3C 提出的RDF [4]最为有名且已经被广泛地应用。RDF (Resource Description Framework,即资源描述框架) 是W3C 提出的一组知识表示的模型,以便更为丰富地描述和表达网络资源的内容与结构。RDF 利用国际化资源标识符(Internationalized Resource Identifier,IRI)来标识对象。这些IRI所对应的对象既可以是真实世界中的实体(比如一个蛋白质),也包括人们在社会实践中形成的概念(比如疾病)等。这些IRI 所对应的事物又被称为资源。RDF 的基本数据单元是一个三元组,可以表示为< 主体,属性,客体>。每个三元组表示某个资源的一个属性值或者某个资源与其他资源的关系。在实际中,人们还经常将RDF 数据视为通过预先定义的语义所构成的一个或多个连通图。其中,RDF 数据中每个资源被视为一个点,而每个三元组被视为连接两个资源的一条边。而基于图模型的RDF数据模型是被最普遍应用的知识图谱数据模型。
在定义RDF 数据模型的同时,W3C 也定义了结构化查询语言SPARQL(Simple Protocol and RDF Query Language)[5],以实现针对RDF 知识图谱数据的查询与管理。SPARQL语言与目前关系数据库中的SQL 语言是很相近的。在SPARQL 语法中,用户也是用SELECT语句查询满足特定条件的RDF 知识图谱数据片段。具体而言,对于一个SELECT 语句中,SELECT子句指定查询应当返回的内容,FROM 子句是指定将要使用的数据集,WHERE 子句一组三元模式组成用以指定所返回的RDF 数据片段需要满足的模式。与RDF 数据的图形式表示类似,一个SPARQL 查询可以表示为一个查询图[6, 7],查询中每个变量或者常量对应一个查询图上的点,每个WHERE 子句中的三元模式对应一条边。
实际科学数据管理应用中,特别是生命科学领域应用中,RDF知识图谱数据存储被数据方存储在若干分布于不同机器的、各自“自治”的RDF知识图谱数据源上,即联邦型分布式RDF知识图谱。如UniProt被存在欧洲生物研究机构的RDF知识图谱数据源上;DrugBank被存在加拿大阿尔伯塔大学的RDF知识图谱数据源上;KEGG被存在日本京都大学的RDF知识图谱数据源上;中国科学院微生物研究所落户的世界微生物数据中心存储着微生物资源、微生物及交叉技术方法、研究过程及工程、微生物组学、微生物技术以及微生物文献、专利、专家、成果等微生物方面的RDF知识图谱数据。
针对上述如此之多的RDF知识图谱数据源,我们需要将它们集成到一个系统下,以方便用户使用。这样的系统就被称为“联邦型RDF数据管理系统”。在这种系统中,不同机器上的子数据库系统独立地进行查询处理且不被干涉。具体到在联邦型RDF知识图谱数据管理系统,RDF 数据存储在若干分布于不同机器的、各自“自治”的RDF知识图谱数据源上。当处理SPARQL 查询时,一个中心机器对查询进行调度并得到最终结果。
目前,已有一些生命科学领域的研究机构构建了自己的联邦型RDF知识图谱数据管理系统来进行RDF数据管理。欧洲分子生物学实验室下属的生物信息学研究所发布了他们SPARQL查询接口,可以支持联邦式地查询多个RDF数据源,包括Biomodels、Biosamples、ChEMBL、Ensembl、Reactome、ExpressionAtlas等;德国莱比锡大学、爱尔兰国立大学等研究机构的研究人员针对著名的癌症基因组地图项目(The Cancer Genome Atlas,TCGA)构建了联邦型RDF知识图谱数据管理系统——TopFed,来协助研究人员管理和查询癌症基因组RDF数据。
本文将介绍现有的联邦型RDF数据管理系统。在第二章,本文将给出联邦型RDF数据模型的形式化定义;在第三章,本文将介绍常见联邦型RDF数据管理系统的架构;在第四章,本文将介绍常见联邦型RDF数据管理系统重点查询分解与数据源选择方法;在第五章,本文将介绍常见联邦型RDF数据管理系统重点查询处理与优化方法。最后,本文给出对现有联邦型RDF数据管理系统的总结。
1. 问题定义
本章将首先给出了联邦型RDF 数据管理的形式化定义,然后给出SPARQL查询模型的定义。一个RDF 数据集可以看做一系列三元组的集合。每一条三元组又可被称为一条声明(statement)。一条三元组包括三个元素:主体(subject)、属性(property)及客体(object),通常描述了两个资源间的关系或是一个资源的某种属性。当某条三元组描述了某个资源的属性时,其三个元素也被称为主体、属性及属性值(property value)。相关的形式化定义如下。
定义1:资源。资源(resource)是可区别性且独立存在的某种事物。RDF知识图谱数据中的每一个资源均被分配一个独一无二的标识,称为国际化资源标识(IRI,Internationalized Resource Identifiers)。
定义2三元组。RDF 数据中的三元组(triple)又称声明(statement),通常被表示为<主体(subject), 属性(property), 客体(object)>。同时三元组也可表示为<主体(subject), 属性(property), 属性值(property value)>,这种方式主要用来描述实体的相关属性。三元组的取值空间可形式化表示为(U ∪ B)×(U ∪ B) ×(U ∪ B ∪ L),其中U 代表URI 的集合,B 代表空值点,L 代表文本。
除了基本的三元组模型,图模型也被广泛地用来描述RDF 数据。通过将主体及客体视为顶点且将三元组视为连接顶点与顶点之间的有向边,RDF 数据集可以被看作为一张有向图。定义3给出了RDF数据图的定义。
定义3:RDF 数据图。RDF 数据图被表示为有向图 G = <V,E,L>, 其中:V 表示 RDF 数据图中的点集,V 中的每个点对应于所有 RDF 三元组中的主体或者客体,其可以是资源点、空值点或者文本点;E =V ×V 是 RDF 数据图中的有向边集,每条边对应于 RDF 数据中的一个三元组;L 是所有边的标签集合,即属性集合,每条边的标签是其所对应三元组中的属性。
对于联邦型RDF 数据管理系统,RDF知识图谱数据分布在若干“自治”的RDF知识图谱数据源上。每个RDF知识图谱数据源提供一个SPARQL 查询处理接口。SPARQL 查询处理接口能支持输入SPARQL 查询并求出解。针对这个特性,本文扩展前人工作关于关联数据的定义[8]来描述联邦型的RDF数据管理系统如下。
定义4:联邦型的RDF 数据系统。 一个联邦型的RDF 数据系统被定义为一个三元组W = (S, g, d)。其中S 是一个RDF 数据源的集合,其中每个数据源通过查询IRI来获得;g : S →2E是一个映射,用以将每个数据源映射到存储于其中的RDF 数据图的子图;d : V→S 是一个满射的部分函数用以将RDF 数据图中每个点映射到唯一对应的数据源。点u 对应的数据源d(u) 称为u 的主机。
由此,整个RDF 数据图可以通过整合所有RDF 数据源的数据来得到,即∪s∈S g(s)=G。
对于SPARQL查询而言,其基本单元是基本图模式(Basic Graph Pattern)。本文基于 Jorge Pérez 等人的工作[9]来定义SPARQL查询及它的匹配。
定义5:变量。SPARQL 查询中的变量是以“?”开头的一串字符,当且仅当两个字符串完全相同时,相对应的变量被视为同一个变量。任何主体、属性或客体均视为变量的一个匹配。
定义6:三元组模式。当三元组中的主体、属性或客体被变量取代时,该三元组被称三元组模式(triple pattern)。三元组模式的取值空间为 (U ∪ B∪ V)×(U ∪ B ∪ V) ×(U ∪ B ∪ L ∪ V),其中 V 为所有可能变量的集合。一个三元组称为是某个三元组模式的匹配当且仅当该三元组与三元组模式的对应元素相匹配,其中变量可以匹配到任何常量,而常量仅能匹配与其标签完全一致的常量。
定义7:SPARQL查询。一个SPARQL查询是一系列三元组模式以点操作 “.”相连接的组合。一个图结构视为某个基本图模式的匹配当且仅当该SPARQL查询中的变量和三元组模式与该图结构中的顶点和三元组的匹配关系形成一一映射。
一个SPARQL 查询同样可以被表示为一个图结构。其定义如下。
定义8:SPARQL 查询图。一个SPARQL 查询可以被表示为有向图Q =?VQ, EQ, LQ?。其中,VQ =V ∪Vv,其中Vv 是表示变量的顶点的集合,而V 的定义与定义3中相同;EQ=VQ×VQ是 SPARQL 数据图中的有向边集,每条边对应于SPARQL查询中的一个三元组模式;LQ 是所有边的标签集合,即属性集合与边上的变量集合。
根据上述定义可知,寻找SPARQL 查询的结果的过程可以被视为在RDF 数据图中寻找子图匹配的过程。于是,一个SPARQL查询的匹配定义如下。
定义9:SPARQL查询匹配。给定RDF 数据图G 和基本图模式查询图Q,若Q 有n个顶点{v1, …, vn},图G 中的n 个顶点{u1, …, un} 被称为是Q 的一个匹配当且仅当存在一个匹配函数f 满足下列条件: 如果顶点vi 不是变量,则f (vi) 和vi 有相同的URL 或者字符值;如果顶点vi 是变量,则f (vi) 可为任意值;如果存在边<vi, vj>是Q中从vi到vj的一条边,那么在G 中存在相应的边<f(vi), f(vj)>,且如果<vi, vj>的标签为p,则<f(vi), f(vj)>也必须为p。
在上述语境下,SPARQL 查询的处理可以被视为在RDF 数据图中寻找相应的子图匹配的过程。
2. 联邦型RDF数据管理系统
目前,大部分联邦型RDF数据管理系统的系统框架如图1所示。图 1
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 1目前联邦型RDF数据管理系统架构
Fig.1System architecture of existing Federated RDF Systems
联邦型RDF数据管理系统中,系统需要提前将用户输入的SPARQL查询分解成若干子查询并传送到它们对应的RDF数据源,以让这些对应的RDF 数据源对子查询独立地进行处理并得到部分解。之后,系统将这些部分解收集起来并通过连接操作得到最终解。
对于联邦型RDF数据管理系统而言,由于各个RDF知识图谱数据源之间相互独立地自治,所以系统在查询处理阶段无法中断各个RDF知识图谱数据源的处理进程。因此,在联邦型RDF数据管理系统中,第一个挑战就是如何将SPARQL 查询分解成若干子查询并传送到它们对应的RDF知识图谱数据源。
之后,系统将这些子查询的匹配收集起来并通过连接操作得到最终匹配。在联邦型RDF数据管理系统中,第二个挑战就是如何优化子查询执行以及中间结果连接。
3. 查询分解与数据源选择
在查询分解与数据源选择阶段,联邦型RDF数据管理系统将用户输入的查询分解成若干子查询并确定出每个子查询所涉及的RDF知识图谱数据源。这些系统可以分成两类:基于元数据的方法和基于ASK查询的方法。DARQ [10] 是最早讨论如何在联邦型RDF数据管理系统上进行SPARQL 查询处理。当SPARQL 查询输入以后,DARQ 根据一个叫服务描述(Service Description)的索引确定出相关的RDF 数据源。所谓服务描述,就是DARQ 所构建的一种索引,用以标识出相关数据源。数据描述中包含若干性能,每个性能对应一个数据源。每个性能包含若干元组t = (p, r),其中p 表示该数据源有p 这个属性,r 对应于当属性为p 时主体或者客体若干限制。当用户输入查询之后,DARQ 首先根据服务描述确定相关RDF知识图谱数据源。然后,DARQ 将查询分解成若干子查询。基本的子查询是单个三元组模式,所以每个子查询都能根据服务描述确定其相关的数据源。如果两个三元组模式都只涉及一个相同的数据源,那么这两个子查询可合并成一个子查询。
在DARQ 的服务描述之外,还有Q-Tree[11,12]作为另一种用来确定子查询RDF知识图谱数据源的索引。在Q-Tree中,每个三元组中的主体、属性和客体都通过哈希函数映射到一个整数。于是,每个三元组都可以视为一个三维向量,进而视为一个三维空间上的点。然后,对这些三维空间上的点,系统构建一种类似于R-Tree的索引——Q-Tree。Q-Tree 与R-Tree 的不同体现于Q-Tree 叶节点所存储的不是一个个项,而是项的数量以及相应RDF知识图谱数据源集合。利用Q-Tree 索引,系统将SPARQL 查询中每个查询语句都可以视为一个Q-Tree 上的一个带界矩形框查询(MBB,Minimum Bounding Boxes)。于是,SPARQL 查询转化为MBB 的连接,进而得到每个查询三元组对应的RDF 数据源。
在上述方法之外,还有SPLENDID[13]、HiBISCuS[14]、TopFed [15]等方法。其中,SPLENDID[13]根据每个知识图谱数据源的VOID 信息建立一个倒排索引。这个索引将每个属性和类型信息映射到一个数据对(d, c),其中d 表示属性或类型信息所在的数据源,c 表示在d 这个数据源上属性或类型信息的数量。HiBISCuS[14]也构建了与DARQ 类似的索引。只是,在确定各个子查询的相关RDF 数据源阶段,HiBISCuS 将查询图建模成一个有向带标签的超图,并利用这个有向带标签的超图进一步减少每个子查询的候选RDF 知识图谱数据源。TopFed[15]是一个生物学方面关于肿瘤的联邦型RDF 数据库。在TopFed 中,其用来确定相关RDF 数据源的索引是一个N3文件和从组织源站点(Tissue Source Site)到肿瘤(Tumour)的哈希表。前者那个N3 文件用来描述每个RDF 数据源的元数据,后者那个从组织源站点(Tissue Source Site)到肿瘤(Tumour)的哈希表用来计算每个组织源站点到肿瘤信息的信息。
针对在国家重点研发项目“科学大数据管理系统”中中科院微生物所进行微生物RDF知识图谱数据管理的需求,本文作者所在实验室也构建了一个联邦型RDF数据管理系统——FMQO [16, 17]。FMQO先后获得了国际学术会议DASFAA 2018的Best Paper Award和APWeb-WAIM 2019的Best Demo Award。
FMQO提出利用基于RDF知识图谱数据源的拓扑关系进行查询分解与数据源选择方法。FMQO首先使用一个网络爬虫来找出哪些RDF知识图谱数据源有数据共享。基于所发现的共享数据,FMQO定义RDF知识图谱数据源拓扑关系图并将这个RDF 数据源拓扑关系图维护在控制机器上。于是,FMQO提出一个基于RDF知识图谱数据源拓扑关系图的策略来对每个本地查询相关的RDF 数据源进行剪枝。这个策略的基本思想在于两个子查询可以连接当且仅当两个子查询所对应的RDF知识图谱数据源在RDF知识图谱数据源拓扑关系图上相邻。
我们通过在一个包含1亿三元组的RDF数据管理基准测试数据集WatDiv[20]上进行实验,来评测了FMQO中所提出的基于RDF知识图谱数据源拓扑关系图的查询分解和数据源选择技术。图2显示了我们的评测结果。这里,我们与两种基准技术进行了对比。第一种作为对比的技术是没有使用任何RDF 数据源拓扑关系来进行查询分解和数据源选择(这种方法被记为MQO-Basic);另一种作为对比的技术是扩展自Q-Tree[11, 12](这种方法被记为Q-Tree)。Q-Tree仅仅使用RDF 数据源拓扑关系中两个RDF 数据源相邻这个关系来进行查询分解和数据源选择。图2所示,FMQO的查询分解和数据源选择技术导致的远程调用次数和查询响应时间都最少。
图 2
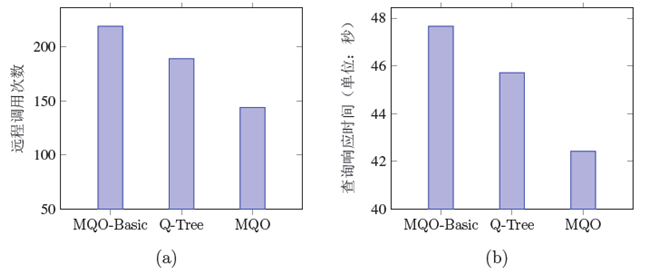 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 2查询分解和数据源选择技术的评测结果
Fig. 2Evaluating query decomposition and source selection technique
不同于上述利用索引来确定相关RDF 数据源的方法,FedX[19]则可以在查询处理阶段实时确定相关数据源。当SPARQL 查询输入以后,FedX[19]首先将查询中每个三元组模式都传到所有RDF知识图谱数据源上并通过SPARQL 查询语义中的ASK 来确定相关数据源。
4. 查询处理与优化
在查询分解与数据源选择阶段完成后,每个RDF知识图谱数据源都会对应若干需要它处理的子查询。这些子查询被执行并返回给控制机器之后,联邦型RDF数据管理系统将子查询的匹配连接起来得到最终匹配。基本的子查询匹配连接策略是扩展经典的关系数据库中的连接顺序确定算法System-R 式动态规划[18]来找出最优查询执行计划,然后按照此查询执行计划执行。然而,针对联邦型RDF数据管理系统,很多文章也提出自己的连接优化策略。
DARQ[10]所使用的代价生成方法是System-R 式动态规划[18]的变种。对于这种查询计划生成方式,最重要的就是如何估计代价。DARQ提出了两个子查询连接有两种方式:一是嵌套循环连接,就是一般的自然连接;二是绑定式连接,就是一个子查询先找出解,然后将解传输到另一个子查询那里,然后将解绑定到第二个子查询那里进行过滤。DARQ给出了这两种连接方式的代价模型,并基于这个代价模型进行System-R 式动态规划。
FedX[19]连接操作顺序的计算方法也是System-R[36]的变种。FedX 所使用的连接方式也是和DARQ 相似的绑定式连接,但是FedX 在传输中间结果的时候不再是一个一个传,而是利用UNION操作符实现若干个中间结果合在一起传。
在实际应用中,传到一个RDF知识图谱数据源的子查询相互间经常共享部分结构。这些共享的结构使得这些本地查询在被处理时能共享一些计算。于是,FMQO[16, 17]提出一个基于查询重写的策略来优化每个RDF 数据源上的多子查询处理。这个方法利用了SPARQL 查询模型中的OPTIONAL操作符和FILTER操作符来将每个RDF知识图谱数据源所接受的子查询重写成更少的几个重写查询。图3给出一个FMQO进行查询重写的例子。
图 3
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 3FMQO [16, 17]中查询重写示例
Fig. 3Example query rewriting in FMQO[16, 17]
我们也在包含1亿三元组的RDF数据管理基准测试数据集WatDiv [20]上进行实验对在上述FMQO中所提出的查询重写规则进行评测。实验中,我们对比的包括4 个方法:仅仅利用基于OPTIONAL 操作符的查询重写规则进行重写的多查询处理方法(记为OPT-only);仅仅利用基于FILTER 操作符的查询重写规则进行重写的多查询处理方法(记为FIL-only);利用混合查询重写规则进行重写的多查询处理方法(记为MQO);此外,我们扩展了Wangchao Le 等人提出的单机版基于查询重写的多查询优化算法[21]在联邦型知识图谱数据管理系统中。图4显示了这4个不同的基于查询重写的多查询处理方法在查询响应时间与远程调用次数上进行对比实验的结果。如图所示,因为MQO 相对于其它方法是利用更全的重写规则进行重写的,所以MQO 所生成的重写查询数量最少,进而使得MQO 进行的远程调用更少,同时查询响应时间最短。
图 4
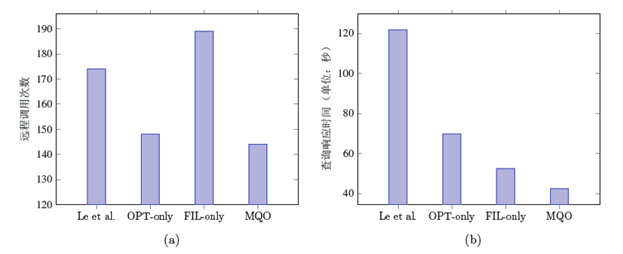 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 4FMQO中查询重写规则的评测结果
Fig. 4Evaluating rewriting strategies in FMQO
此外,FMQO讨论了在进行多个子查询匹配集的连接时如何通过共享部分计算来降低查询整体响应时间。实际中,用户在一个时间段内输入的查询会有些公共子结构,这些公共结构会使得由不同查询分解而得的本地查询匹配进行连接时有些连接操作计算是可以相同的。因此,处理这些用户输入的相似查询时,FMQO可以通过共享相同的连接操作计算来降低查询整体响应时间。具体而言,如果两组相互连接子查询结构一样且进行连接的变量位置一样,这两组连接可以合成一个连接。
5. 结论
在科学数据管理中,人们将越来越多的数据按照知识图谱进行组织,以便于人们操作与利用。现阶段,知识图谱模型很多都是以RDF 框架作为底层数据存储结构,而采用SPARQL 查询语言对数据进行查询。随着越来越多的科学数据以RDF模型的形式被不同数据提供者发布出来,如何利用联邦型RDF知识图谱数据管理系统进行多数据源的RDF数据管理和SPARQL 查询处理成为一个重要的研究问题。在本文中,我们简单介绍了现有联邦型RDF数据管理系统所采用的技术。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
URL [本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]
[EB/OL]. [
URL [本文引用: 1]
[本文引用: 1]
[M].
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[J].
[本文引用: 2]
[M].
[本文引用: 4]
[M].
[本文引用: 4]
[J].
[本文引用: 2]
[M].
[本文引用: 3]
[M].
[本文引用: 2]
[M].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}