SKS: A Platform for Big Data Based Scientific Knowledge Graph
Zhou Yuanchun1,2, Chang Qingling1, Du Yi1收稿日期:2019-08-15网络出版日期:2019-01-20
| 基金资助: |
Received:2019-08-15Online:2019-01-20
作者简介 About authors

周园春,1975年生,中国科学院计算机网络信息中心,博士,研究员,博士生导师,中科院特聘研究员,中心主任助理,中心学位评定委员会主席,大数据技术与应用发展部主任,大数据分析与计算技术国家地方联合工程实验室秘书长,国家烟草专卖局烟草科研大数据重大专项技术首席。发表SCI/EI收录论文90多篇。主要研究方向为云计算、大数据分析与处理。
本文主要承担工作为SKS整体架构设计及应用项目整体框架设计。
Zhou Yuanchun was born in 1975. In 2006, he received his Ph.D. from the Institute of Computing Technology, Chinese Academy of Sciences. He is the research fellow, Ph.D. supervisor and the assistant Director in Computer Network Information Center, Chinese Academy of Sciences and the Director of the Department of Big Data Technology and Application Development. He is also the Chairman of the Degree Evaluation Committee in Computer Network Information Center, Chinese Academy of Sciences. His research interests include cloud computing, big data analysis and processing. He has published more than 90 papers included in SCI/EI.
In this paper he is mainly responsible for the overall framework design of SKS.
E-mail: zyc@cnic.cn

杜一,1988年生,中国科学院计算机网络信息中心,博士,副研究员,硕士研究生导师,大数据技术与应用发展部大数据应用服务技术实验室主任,主要研究方向大数据管理与处理技术、大数据挖掘与分析技术、科学大数据技术。发表SCI/EI收录论文30多篇。
本文主要承担文献调研及平台概述。
Du Yi was born in 1988. He received his Ph.D. in Institute of Software, Chinese Academy of Sciences in 2013. He is an associate professor at the Department of Big Data Technology and Application Development at Computer Network Information Center, Chinese Academy of Sciences. His research interests include big data management, processing, mining, analysis and other related technologies. And he has published over 30 papers included in SCI/EI.
In this paper he is mainly responsible for literature research and platform overview.
E-mail: duyi@cnic.cn

摘要
【目的】科技领域大数据知识图谱致力于为科研工作者提供更精准、更全面、更有深度和广度的检索与分析结果,进而为学科研究提供切实的、有价值的参考。【文献范围】文章重点调研国内外基于数据的科技评估方法、基于知识图谱的交叉学科研究,以及知识图谱构建中的关键技术方法和基于领域知识的知识图谱建设应用等。【方法】本文给出一种科技领域大数据知识图谱平台SKS,基于SKS平台的整体架构,阐述构建科技领域知识图谱的关键技术及平台工具,并给出相关关键技术及平台在不同领域的应用。【结果】SKS平台及应用在为相关领域构建资源知识管理系统的同时,为科研人员提供了精准的、多维的、相互关联的智能检索服务。【局限】科技领域大数据知识图谱在不断发展中,数据质量(数据源自身质量及数据融合产生的误差)在一定程度上影响了平台的应用效果,未来希望在数据消歧方面进行更多的探索。【结论】科技领域大数据知识图谱以其较强的语义处理能力和关系发掘能力,较好的组织了科技领域的人员、机构、成果、事件等海量异质异构数据,为科技评估提供辅助功能,其在具体项目中的应用效果均获得领域专家的认可。
关键词:
Abstract
[Objective] The big data knowledge graph in the field of science and technology is dedicated to providing researchers with more accurate, comprehensive, deeper and broader search and analysis results, and thus providing a practical and valuable reference for disciplinary research. [Scope of the literature] The article focuses on the research of data-based scientific and technological evaluation methods at home and abroad, the interdisciplinary research based on knowledge graph, the key technical methods in the construction of knowledge graph and the application of knowledge graph based on domain knowledge. [Methods] This paper presents a large-data knowledge graph platform SKS in the field of science and technology. Based on the overall architecture of the SKS platform, we expound the key technologies and platform tools for constructing knowledge graph in the field of science and technology, and gives relevant key technologies and applications in different fields. [Results] The SKS platform and application provide a precise, multi-dimensional and interrelated intelligent retrieval service for researchers while constructing a resource knowledge management system for related fields. [Limitations] The big data knowledge graph in the field of science and technology is constantly developing. The data quality (the error caused by the data fusion and the quality of source data) affects the application effect of the platform to a certain extent. In the future, we hope to carry out more in data disambiguation. [Conclusions] The big data knowledge graph in the field of science and technology, with its strong semantic processing ability and relationship exploration ability, can organize massive data of personnel, institutions, achievements, events, etc. in the field of science and technology in a better way, which provides auxiliary functions for technology evaluation. The application effects in specific projects are recognized by corresponding domain experts.
Keywords:
PDF (11789KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
周园春, 常青玲, 杜一. SKS:一种科技领域大数据知识图谱平台 *. 数据与计算发展前沿[J], 2019, 1(1): 82-93 doi:10.11871/jfdc.issn.2096.742X.2019.01.009
Zhou Yuanchun.
引言
科学技术是第一生产力。2007年至今,我国科研支出从0.4亿元增加到1.7万亿元,增长幅度超3倍[1]。以国家自然科学基金委为例,其资助的科研项目数近10年增加了近1倍。与此同时,依托各类科研投入的科技论文、发明专利等科研产出迅速增加,产生了科技项目、科研人员、科技成果等多源、异构的海量数据。如何准确、高效的对科技项目、科研人员、科技成果的影响力、潜力以及对社会经济发展的促进作用进行评估,成为制约科技进一步发展的瓶颈。在该背景下,国家及各地方科技管理部门、研究机构、咨询公司等尝试基于数据的科技评估方法[2,3,4,5,6,7,8],科技领域知识图谱成为首选。近年来,国内外涌现了较多的基于科技领域知识图谱技术的新学科与新技术发现、成果评价等理论[9,10],诸如基于领域知识图谱的立项推荐、交叉学科发现[11,12]等技术也已在美国国家自然科学基金委(NSF,National Science Foundation)、中国国家自然科学基金委(NSFC,National Natural Science Foundation of China)、科技部等众多单位进行了应用与尝试,并取得了较好的效果。然而,由于科技发展的高速变化以及各科技机构对科技评估辅助的需求不尽相同,需要建立一个相对通用的科技领域大数据知识图谱平台,能够支持来自不同关注点的科技需求。
本文面向科技领域知识图谱构建的核心技术,突破海量知识图谱数据的采集、清洗、存储与管理难题,融合科技成果、科研人员、科研机构、科技项目、关键词等科技实体,构建面向科技辅助决策的领域知识图谱,提出一种科技领域大数据知识图谱平台SKS(Scientific Knowledge Store)。通过构建科技领域知识图谱,提供科技人员、项目、成果相关的概念、知识与关系的查询与统计分析,提供科技领域项目、专家、成果的查询与分析等功能;在科技领域知识图谱基础上,结合传统的文献计量学方法[13]、网络表示学习及神经网络等最新机器学习方法提供包括新技术发现、规划制定、项目立项、成果评价的分析与服务。实现包括影响力评价、关联挖掘、学科分析、立项评价在内的科技评估。
1 相关工作
谷歌于2012年,在原有知识库、知识工程基础上提出知识图谱的概念,并成功应用与其搜索引擎等核心业务。领域知识图谱促进了知识图谱技术落地,而科技领域作为知识密集型的领域,亟需具有较强分析及组织能力的知识图谱对其进行更好的组织管理及分析处理。科技领域知识图谱面向科学技术领域,构建以科研项目、学术论文、专利、科技动态等为主要数据源,以论文、专利、科研人员、机构、项目、关键词等为主要实体,以支持面向科技领域的学科分析、影响力评价、关联挖掘为主要目的的领域知识图谱。在科技领域知识图谱相关平台建设上,VIVO [14,15]项目汇聚了CASRAI (Consortium Advancing Standards in Research Administration Information), EuroCRIS (Current Research Information Systems) 及 ORCID (Open Researcher and Contributor ID) 等不同科研体系及数据源,并以数据接口的形式提供了服务于科技人员的知识库。国家自然科学基金委于2016年部署了“国家自然科学基金大数据知识管理服务平台”项目,明确提出了构建以科研项目为核心、以科研成果为依托的大数据平台,并构建“项目-成果-人员-机构-关键词”组成的科技领域知识网络,为基金委科研项目管理与评估提供智能支持[16]。中国科学院于2017年部署了“智慧中科院”项目,将采集全球科技相关的成果、人员、团队数据,并构建全球科技知识图谱,为科学决策提供辅助支撑。中国科协于2018年部署了“中国科协大数据与人工智能大数据知识管理服务平台”,构建“成果-人员-学术机构-学会-关键词”为核心的科技领域知识图谱,为包括学会评估在内的智慧科协的建设提供数据和分析支持。
利用科技领域知识图谱相关平台提供的数据及技术能力,基于各类评估方法及分析方法,国际上研发了多种科技评估辅助系统。CiteSpace[17]、SCI2 Tool[18]是面向科技文献分析的专用工具,提供了包括文献共被引、文献耦合、作者合作等分析功能;Gephi[19]、Pajek[20]是通用网络数据分析工具,融合了包括模块化分析、中心性分析等复杂网络的分析方法,以上工具广泛应用于文献情报学研究领域。然而,其在数据源上与科技论文数据紧密耦合及学科评价、趋势分析等方面的分析能力较弱。由科睿唯安研发的Web of Science基于SCI评价体系[21],研发了InCites系统,提供以论文为核心的国际影响力评价、机构关联分析等功能,并提供了基本的可视分析功能。Google Scholar及Microsoft Academic[22]是基于开放及内部的各类论文、专利、报告等数据,构建了以学术成果、科学家为核心的海量学术知识库,并基于此提供引文分析、学术趋势分析、个人及机构影响力分析等功能。在国内,万方、知网等出版商也依托各自在中文学术期刊、会议上数据的优势,研发出相应的辅助分析系统。由清华大学牵头研制的AMiner系统[23],通过融合海量科技论文数据,构建了以论文和科学家为核心的知识网络,并提供了包括****评价、****迁徙分析在内的特色功能。中国工程院于2012年启动建设“中国工程科技知识中心”(CKCEST,China Knowledge Centre for Engineering Sciences and Technology),该项目汇聚了超44亿条论文、行业报告在内的成果数据,并提供了包括主题分析、战略咨询、交叉领域分析等功能。以上系统为科技辅助分析与决策提供了强有力的支持,然而仍有改进的空间。首先,虽然均利用了海量开放数据,但在数据汇聚、更新与融合上,过多的依赖算法,而忽略了各类精准分析对准确性的苛刻要求;其次,在分析粒度上仍主要基于论文、专利的标题、作者、机构等基本信息,对于论文主题、关键词甚至全文的利用较弱,难以挖掘细粒度的学科关联与学科发展;再次,在数据利用上,没有考虑科研项目生命周期的相关数据,对科研项目指派、立项、评价等的决策支持能力有限。
文中给出一种科技领域大数据知识图谱平台,该平台在大数据基础环境支撑下,利用分布式大数据采集与融合技术,设计一整套领域知识图谱构建流水线。以科技领域为切入点,突破大规模网络数据存储、实体发现与链接预测、行业趋势与交叉学科预测等关键技术,构建科技领域知识图谱,并为不同的应用场景提供科技辅助决策服务。
2 SKS概述
SKS平台架构如图1。整体流程从数据源开始,经过对各类开放数据进行采集、一次清洗、二次清洗及初步融合后,抽取出相关科技类实体与关系,构建初步科技领域知识图谱,并在此基础上抽取子图,经过数据二次加工,实现包括趋势预测、影响力评价、****推荐在内的科技辅助决策服务。图 1
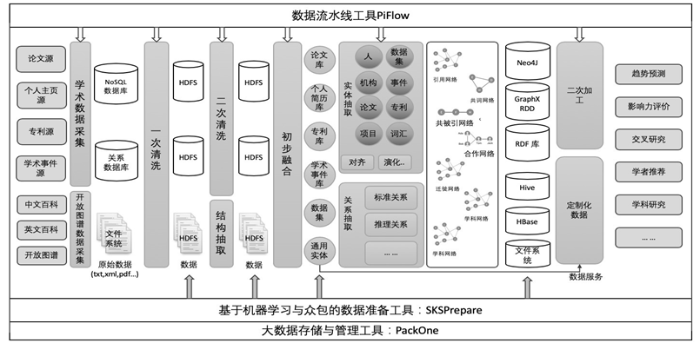 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 1SKS平台架构图
Fig.1SKS platform architecture
2.1 采集与获取
SKS平台的实现依赖于丰富的开放数据的积累,为实现该目标,平台首先对基本科技实体及实体间关系进行元数据定义。其中基本科技实体包括科技人员、科技机构、学术期刊或会议、科技成果(期刊论文、会议论文、学术论文、专著、专利、标准、软件著作权等)、奖励、科研数据集、科技事件。在此基础上,为主要科技类实体定义关系元数据,同时,维护并更新包括民族、国籍、职称、学位在内的一系列字典。表1示意了元数据中对科技实体关系的定义。其中实体1和实体2表示两个实体;关系是指两个实体之间都有哪些关系,如人与机构两个实体之间的关系可能有就读于,工作于,任职于等等;属性则是对该关系的描述,主要包含该关系的起始时间,确定该关系的依据即来源以及该条记录的更新时间。例如:张三任职于中科院计算机网络信息中心,2013年9月,2018年6月,Table 1
表1
表1科技实体关系示意表
Table 1
| 实体1 | 实体2 | 关系 | 属性 |
|---|---|---|---|
| 人 | 机构 | 就读于 | 开始时间,结束时间,来源,最后更新时间 |
| 工作于 | 开始时间,结束时间,来源,最后更新时间 | ||
| 任职于 | 开始时间,结束时间,来源,最后更新时间 | ||
| 法人 | 开始时间,结束时间,来源,最后更新时间 | ||
| 人 | 人 | 论文合作 | 开始时间,结束时间,来源,最后更新时间 |
| 项目合作 | 开始时间,结束时间,来源,最后更新时间 | ||
| 评审组成员 | 开始时间,结束时间,来源,最后更新时间 | ||
| 论文答辩专家 | 开始时间,结束时间,来源,最后更新时间 | ||
| 同事 | 来源,最后更新时间 | ||
| 是老师 | 开始时间,结束时间,来源,最后更新时间 | ||
| 同学 | 开始时间,结束时间,来源,最后更新时间 | ||
| 亲属 | 来源,最后更新时间 | ||
| 朋友 | 来源,最后更新时间 |
新窗口打开|下载CSV
在SKS平台中,定义了超20类科技实体、超70类实体关系,超400个属性定义的元数据。依据该统一元数据描述规范,对采集到的数据进行清洗并存储,确保异构异源数据的格式对齐,为多源数据的融合提供基础,且在一定程度上确保科技领域知识图谱的准确性,除此之外,在数据采集与获取时,还解决了以下技术问题:
● 分布式数据爬取技术,解决科技相关数据爬取的问题。
● 属性自动映射技术,解决数据采集后与元数据中基本属性的映射问题。
● 定时数据获取技术,解决增量数据的采集与获取问题。
2.2 处理与融合
SKS平台的数据处理与融合,由多个不同的数据处理流程构成。由于数据海量、多源、异构的特点,在第一步数据清洗中,进行数据的标准化、缺失数据补全与处理、数据校对等工作。第一步的数据清洗完成了数据字段的规范化,一定程度上提高了数据的质量。第二步数据清洗主要进行数据处理与融合,该过程设计并实践了通用数据清洗流程如图2。其中关键属性指能够明确标识一类实体或数据的属性,例如科技人员的ID、期刊论文的DOI等;同时,在该清洗流程中,还给出了通过模糊匹配等方式实现进一步的数据融合。经过数据的二次清洗及校验,逐步形成高质量科技领域知识数据,最终构建科技领域知识图谱。图2
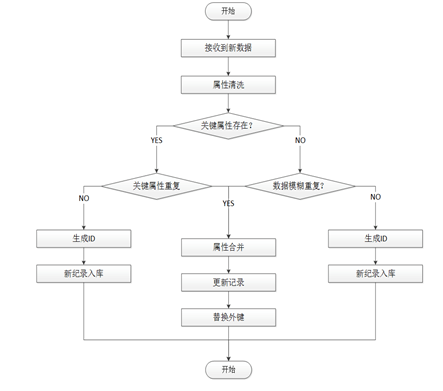 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2通用数据清洗流程图
Fig.2General data cleaning flowch
2.3 分析与挖掘
在构建的科技领域知识图谱基础上,提供一系列分析与挖掘支持,以实现SKS平台的深度挖掘功能。这些分析与挖掘功能包括:● 论文引文网络分析;
● 论文共词网络分析;
● 论文共被引网络分析;
● ****迁徙网络分析;
● 关键词与学科网络分析;
● 学科趋势预测;
● 科技实体影响力评价;
● 学科交叉研究;
● ****关系挖掘与推荐。
在SKS平台构建及运行过程中,以作者、机构为典型的实体及属性的融合是决定平台成功与否的核心问题。SKS平台在不同阶段融合不同技术,保障数据的质量:
● 面向不同数据源,利用专家经验,设计实体及属性映射规则,实现数据映射质量的保障。
● 融合基于规则及基于异质图神经网络嵌入(Heterogeneous Graph Convolutional Network Embedding)的方法,对作者及机构实体进行消歧。
● 利用基于众包(Crowd Sourcing)的工具,面向不同任务,设计不同的众包标注及校验流程,进一步增强数据质量。
● 在数据融合不同阶段均进行合理标记,保证不同质量的数据的对齐、融合过程可追溯。
3 关键技术与工具
SKS平台突破海量数据的采集、清洗,大规模网络数据存储管理,多源异质数据的融合,实体发现及关系挖掘等关键技术,并基于相关技术研发了大数据处理分析工具,它们在SKS平台的数据流动过程中扮演着重要的角色, 其中,PackOne[24]作为大数据存储与管理工具,保证整个流程的基础大数据环境的稳定、高效;SKSPrepare作为一款基于机器学习与众包的数据准备工具,能够提高数据的清洗及校对效率;PiFlow[25]作为数据处理流水线工具,提供从数据采集、清洗、融合到深度分析挖掘在内的一系列处理模块。3.1 大数据管理工具(PackOne)
PackOne致力于实现主流大数据软件在云端的快速弹性部署。通过对云API和Apache Ambari API的联合调用,完成Hadoop、Spark、NiFi、PiFlow、Kylin、MangoDB、Neo4J等流行的大数据管理/处理软件在云端的一键部署和一键伸缩。实现大数据环境的快速部署、弹性收缩和集中监管。PackOne大数据管理工具如图3所示。主要特性包括:图3
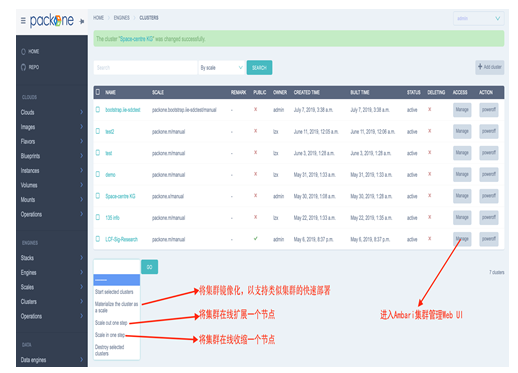 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3PackOne 大数据管理工具
Fig.3PackOne big data management tool
● 支持在空白虚拟机上完成大数据处理集群的全自动部署;
● 通过Apache Ambari对已部署的大数据软件进行状态监控、配置管理;
● 通过将模版集群物化为系统镜像,实现新集群的分钟级快速部署;
● 通过集群节点的全自动增删,实现各类大数据软件处理能力的分钟级弹性伸缩;
● 在同一个界面上对来自不同云的虚拟机、存储卷、镜像、模版等进行CURD操作。
3.2 基于机器学习与众包的数据准备工具(SKSPrepare)
SKSPrepare是基于机器学习与众包的数据准备工具。对于海量结构化与半结构化数据,可以快速部署并运行数据获取脚本,并对数据进行及时的管理。对于大量非结构化数据,它提供了模型驱动的众包数据采集方法,支持快速的数据录入界面设计与生成,并提供基于工作流的审核与协作流程配置。图4为SKSPrepare自动配置的数据录入界面。图4
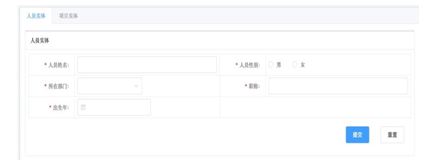 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4SKSPrepare自动配置的数据录入界面
Fig.4SKSPrepare automatically configured data entry interface
3.3 大数据采集、处理与融合工具(PiFlow)
PiFlow是一个基于分布式计算框架Spark开发的大数据流水线系统。该系统将数据的采集、清洗、计算、存储等各个环节封装成组件,以所见即所得的方式进行流水线配置。图5为PiFlow流水线配置的示例。图5
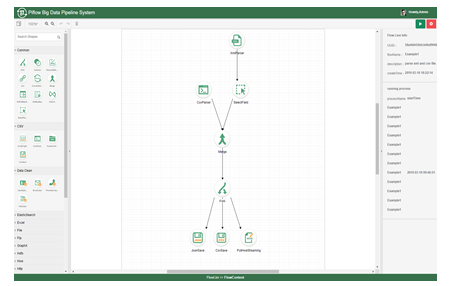 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5PiFlow流水线配置
Fig.5PiFlow flow configuration interface
系统基于模型驱动的大数据流水线描述语言PiFlowDL实现,该语言以模块化、层次化的方式对大数据处理任务进行描述。通过流水线配置的方式,提供状态监控、模版配置、组件集成等功能,极大程度上提高了大数据处理环境的构建与开发效率,其性能较Apache知名开源项目 Nifi提升至少3倍。PiFlow具有如下特性:
● 简单易用:提供可视化界面配置流水线,实时监控流水线运行状态,查看日志,提供模板功能;
● 功能强大:提供100+的数据处理组件, 包括Hadoop 、Spark、MLlib、Hive、Solr、Redis、MemCache、ElasticSearch、JDBC、MongoDB、HTTP、FTP、XML、CSV、JSON等,同时集成了微生物、AI、NLP等领域的相关算法;
● 扩展性强:支持自定义开发数据处理组件、满足项目实施过程中的特定需求;
● 性能优越:基于分布式计算引擎Spark开发,性能表现优越。
4 基于SKS平台的应用
面向科技领域的科技项目、科研人员、科技成果、科研组织、科研动态等数据,基于大数据关键技术及研发工具,实现对大数据的采集、清洗、汇聚、融合等,进而构建科技领域大数据知识图谱,并基于此为用户提供精准检索、趋势预测、影响力评价、****推荐在内的科技辅助决策服务。目前,基于科技领域大数据的知识图谱关键技术及平台工具已在烟草科技资源数据服务系统、中国科协计算机与人工智能大数据知识管理服务平台及空间科学领域的数据知识管理服务平台中部署应用,应用效果均得到专家认可。
4.1 烟草科技资源知识服务系统
烟草科技资源知识服务系统面向烟草领域科研人员、科研机构、科研项目,以及论文、标准、专利、成果报告、专著等科研成果和开放数据等,实现对烟草科技信息资源的汇聚整理、融合与深度挖掘,为烟草科研人员准确把握研究方向和提高科研活动效率提供支持。面对数据量庞大,结构复杂,特征繁多的烟草科技数据,采用PiFlow流水线系统,通过配置多条流水线,实现数据的采集、清洗融合,基于深度学习进行实体及实体关系抽取,进而构建烟草科技领域知识图谱。基于知识图谱,结合图深度优先遍历算法发现科研机构及科研人员之间的合作网络及关联路径,利用Louvain算法及文献计量学原理发现烟草科研活动的热点研究趋势等。大数据管理工具PackOne则为系统汇聚的海量数据及知识图谱图数据库提供数据的存储和管理,保障烟草科技资源知识服务系统的稳定运行。
烟草科技资源知识服务系统如图6所示,其中,科技项目、科技成果、科技人员、科研单位等所有数据信息都可作为网络图中的节点,它们之间的关系是边。图中不同位置的节点组成以人员为核心的子网络,围绕在人员周围的节点分别是参与的项目、产出的成果以及所在的机构。子网络之间通过不同烟草知识数据相互关联,构成烟草大数据知识网络,并采用直观的交互式方式,为用户提供基础数据查询、知识关联查询、科研关系网络查询、影响力分析、科研社区发现等服务,并提供立体全景式的浏览形式。目前烟草科技资源知识服务系统已融合超30类实体与关系,并应用于烟草科研全领域科技人员及机构,主要分析与洞察结果也得到了领域专家的高度认可。
图6
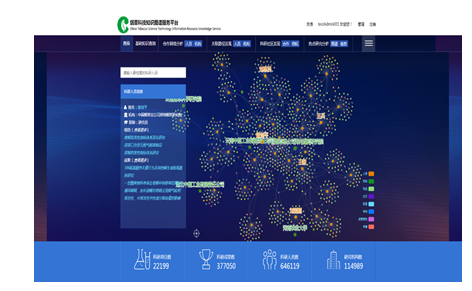 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6烟草科技资源数据服务系统
Fig.6Tobacco science and technology resource data service system
4.2 中国科协计算机与人工智能大数据知识管理服务平台
中国科协计算机科学与人工智能大数据知识管理与服务平台项目的主要建设目标是依托中国科协学科门类齐全、领域交叉充分、智力资源密集的独特优势,构建科技领域大数据知识图谱,形成“科技领域-专家人才-研究成果”的关系网络,提供计算机科学与人工智能科技领域研究热点、趋势、人才态势感知服务,利用复杂网络关系分析、机器学习等挖掘技术,为宏观科技管理与决策提供支持服务。项目利用PiFlow部署多条流水线对海量科协及公开数据进行采集、清洗、融合。针对特殊数据源,采用基于众包的SKSPrepare工具采集,进一步完善丰富知识管理平台数据资源。最后利用PackOne为系统搭建存储管理平台,为科协知识管理服务平台提供安全稳定的运行环境。
中国科协计算机科学与人工智能大数据知识管理与服务平台如图7所示,它结合基于规则和人工智能方法汇聚整合了科技领域中的科技人才、科技项目、科技组织、科技事件、科研成果等数据,构建面向科技服务的知识图谱,基于知识图谱挖掘科技资源价值,主要包括面向领域科技专家画像、基于H指数的科技成果影响力分析、基于PageRank的科研机构影响力分析、基于标签传播的LPA算法进行领域热点趋势分析等。为中国科协研究人员提供中国科协科研热点、科研影响力和科研趋势分析服务;提供立体、多维、高精度人才画像及专家推荐等智能服务。目前,中国科协计算机与人工智能大数据知识管理服务平台,融合了超过1亿科技实体,已在中国科协内部进行初步部署与展示。
图7
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7中国科协计算机与人工智能大数据知识管理服务平台
Fig.7China Association for science and technology computer and artificial big data knowledge management service platform
4.3 空间科学领域大数据知识管理服务平台
空间科学领域大数据知识管理服务平台主要面向空间领域科研活动数据,实现大数据的智能化管理,为空间领域科研工作者提供科研决策及科技管理等参考依据。项目利用PiFlow流水线及基于众包的SKSPrepare数据准备工具对空间科学领域大数据及网络公开数据进行采集汇聚,基于空间科学大数据,结合Seq2seq与Attention机制识别实体及实体间关系,进而构建空间科学领域大数据知识图谱。
空间科学领域大数据知识管理服务平台如图8所示,平台基于知识图谱,使用 TransE 模型挖掘实体关系,基于混合规则与分布式表示的隐含语义推理技术,实现实体、关系及隐含语义的推理,为空间领域科研人员提供交互式查询、知识关联查询分析、科研影响力分析、网络挖掘分析、科研合作网络分析、多维统计分析等智能化服务,将科研过程和科研成果有机的联系起来,使得空间领域的科研活动具有可解释性,为空间领域科研决策提供依据的同时,促进前沿技术在空间科学领域的应用。目前,空间科学领域大数据知识管理服务平台在传统科技领域实体关系基础上,进一步融合了空间科研特有的实体,如卫星、科研装置等,具有典型的领域特点。
图8
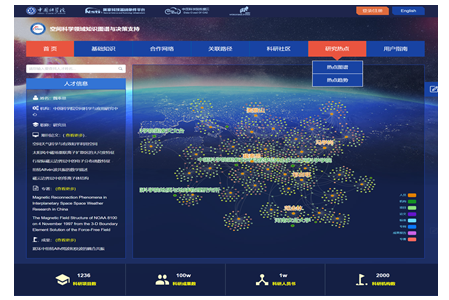 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8空间科学领域大数据知识管理服务平台
Fig.8Space science big data knowledge management service platform
4.4 信息领域数据平台
随着国家对大数据战略的部署及知识图谱在各个行业的深入应用,为更好的响应国家数据政策,将知识图谱关键技术应用于信息领域,构建信息领域数据平台。信息领域数据平台主要面向学术数据及开放图谱数据,利用PiFlow、SKSPrepare等平台工具采集获取相关论文、专利、著作、学术事件及中英文百科等开放数据,结合关联规则算法及聚类算法等挖掘数据之间的关联关系,进而构建信息领域知识图谱,基于知识图谱,结合深度学习和共被引分析原理及共词分析方法,发掘研究热点趋势。从而为用户提供基础知识检索、关联关系分析挖掘、专家画像、专家推荐、研究热点趋势分析及人才迁徙情况等智能服务。
信息领域数据平台初步研发结果如图9所示,它致力于信息科学领域数据资源的开放共享,为科研工作者提供领域数据资源的发现和获取服务,并在此基础上探索实践数据影响力的呈现。致力于提供包括新技术发现、规划制定、项目立项、成果评价的分析与服务。利用知识图谱、数据可视化等技术手段,平台服务旨在提高数据检索效率,打通数据与学术论文的信息链路,全方位、多维度助力信息科学领域科研人员的知识创新和科研发现,实现包括影响力评价、关联挖掘、学科分析、立项评价在内的科技评估。为科技活动对社会经济发展的促进作用提供评估策略。
图9
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图9信息领域大数据平台
Fig.9Information field big data platform
5 展望与下一步工作
本文提出了一种科技领域大数据知识图谱平台SKS(Scientific Knowledge Store) ,在介绍SKS平台架构的同时,介绍了SKS平台搭建过程中使用的大数据管理工具PackOne,数据准备工具SKSPrepare和大数据流水线PiFlow等,并给出相关关键技术及平台在烟草科研、空间领域科研及信息领域科研等项目中的应用。SKS平台及应用在为相关领域构建资源知识管理系统的同时,为科研人员提供了精准的、多维的、相互关联的智能检索服务。SKS平台研究的关键技术中的大数据采集、处理融合,知识抽取,关系挖掘及基于此研发的工具平台可应用于其他领域大数据的处理过程中,而构建知识图谱的逻辑架构已具有通用性,因此,在下一步工作中,将尝试探索SKS平台在不同领域的推广应用,并将继续探索基于机器学习及众包机制的数据处理方法,以提高数据的准确性,将SKS打造成覆盖全科研领域的权威科技知识图谱平台。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[EB/OL]. [
URL [本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
Magsci [本文引用: 1]

<html dir="ltr"><head><title></title></head><body><font >交叉学科是原始创新的发源地,其科学评价问题倍受关注。针对交叉学科同行评议专家选择的难点问题,提出利用科学知识图谱来判定交叉学科相近研究领域及热点研究主题,并据此确定合适交叉学科同行评议专家遴选的方法,为同行评议专家的遴选提供科学合理的凭据。</font></body></html>
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[J].
DOI:10.1002/asi.20317URL [本文引用: 1]
This article describes the latest development of a generic approach to detecting and visualizing emerging trends and transient patterns in scientific literature. The work makes substantial theoretical and methodological contributions to progressive knowledge domain visualization. A specialty is conceptualized and visualized as a time-variant duality between two fundamental concepts in information science: research fronts and intellectual bases. A research front is defined as an emergent and transient grouping of concepts and underlying research issues. The intellectual base of a research front is its citation and co-citation footprint in scientific literature-an evolving network of scientific publications cited by research-front concepts. Kleinberg's (2002) burst-detection algorithm is adapted to identify emergent research-front concepts. Freeman's (1979) betweenness centrality metric is used to highlight potential pivotal points of paradigm shift over time. Two complementary visualization views are designed and implemented: cluster views and time-zone views. The contributions of the approach are that (a) the nature of an intellectual base is algorithmically and temporally identified by emergent research-front terms, (b) the value of a co-citation cluster is explicitly interpreted in terms of research-front concepts, and (c) visually prominent and algorithmically detected pivotal points substantially reduce the complexity of a visualized network. The modeling and visualization process is implemented in CiteSpace II, a Java application, and applied to the analysis of two research fields: mass extinction (1981-2004) and terrorism (1990-2003). Prominent trends and pivotal points in visualized networks were verified in collaboration with domain experts, who are the authors of pivotal-point articles. Practical implications of the work are discussed. A number of challenges and opportunities for future studies are identified.
[J].
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}