 ,1,*, 刘俊1,2, 李观1,2, 高阳1, 徐涛1, 田东1,2
,1,*, 刘俊1,2, 李观1,2, 高阳1, 徐涛1, 田东1,2GPVis: A Scientific Visualization System for Large Scale Data
Shan Guihua,1,*, Liu Jun1,2, Li Guan1,2, Gao Yang1, Xu Tao1, Tian Dong1,2通讯作者: * (E-mail:sgh@cnic.cn)
收稿日期:2019-08-15网络出版日期:2019-01-20
| 基金资助: |
Received:2019-08-15Online:2019-01-20
作者简介 About authors

单桂华,1976年生,中国科学院计算机网络信息中心,研究员,主要研究方向为可视化与可视分析、智能交互。
本文承担工作为: GPVis整体架构设计、研究指导。
Shan Guihua, born in 1976,Computer Network Information Center of the Chinese Academy of Sciences, research fellow. Her main research interests are visualization, visual analysis and intelligent interaction.
In this paper she undertakes the following tasks: the overall structure design and research guidance of the framework.E-mail:sgh@cnic.cnE-mail:sgh@cnic.cn

刘俊,1982年生,中国科学院计算机网络信息中心,高级工程师,主要研究方向为科学数据可视化及可视分析。
本文承担工作为:任务及需求分析、软件框架实现、核心算法研究与实现。
Liu Jun, born in 1982, Computer Network Information Center of the Chinese Academy of Sciences, senior engineer. His main research interests are scientific data visualization and visual analysis.
In this paper he undertakes the following tasks: task and demand analysis, software framework implementation and key algorithms research as well as their implementation.E-mail: liujun@sccas.cn

李观,1990年生,中国科学院计算机网络信息中心,博士研究生,主要研究方向为科学可视化与可视分析。
本文承担工作为:粒子可视化研究与实现、多终端协同组件设计与开发、可视化应用研发。
Li Guan, born in 1990, Computer Network Information Center of Chinese Academy of Sciences,PhD student. His main research interests are scientific visualization and visual analysis.
In this paper he undertakes the following tasks: visualization, design and implementation of particle data, cooperative component development design and visualization application implementation.E-mail: liguan@sccas.cn

高阳,1987年生,中国科学院计算机网络信息中心,工程师,主要研究方向为科学可视化与可视分析。
本文承担工作为:可视化组件开发与测试、可视化应用开发。
Gao Yang, born in 1987, Computer Network Information Center of Chinese Academy of Sciences, engineer. Her main research interests are scientific visualization and visual analysis.
In this paper she undertakes the following tasks: visualization component development and test, visualization application implementation.E-mail: gaoyang@cnic.cn

徐涛,1992年生,中国科学院计算机网络信息中心,助理工程师,主要研究方向为科学数据可视化、先进渲染技术。
本文承担工作为:可视化组件设计开发, 可视化应用开发。
Xu Tao, born in 1992, Computer Network Information Center of the Chinese Academy of Sciences, assistant engineer. His main research interests are scientific data visualization and photorealistic rendering.
In this paper he undertakes the following tasks: visualization component design and development, domain visualization application implementation.E-mail: xutao@cnic.cn

田东,1983年生,中国科学院计算机网络信息中心,高级工程师,主要研究方向为数据可视化及可视分析。
本文承担工作为:核心算法研究与实现。
Tian Dong, born in 1983, Computer Network Information Center of Chinese Academy of Sciences, senior engineer. His main research interests are data visualization and visual analysis.
In this paper he undertakes the following tasks: key algorithms research and implementation.E-mail: tiandong@cnic.cn

摘要
【目的】为解决大规模科学数据可视化所面临的一系列问题,提供一套灵活可扩展的科学数据可视化框架,本文设计并实现一种面向大规模数据的科学可视化系统GPVis。【方法】本文基于科学数据可视化在方法和工具层面所面临的挑战和机遇进行了分析,结合数据预组织、图形渲染、高性能计算、人机交互、VR/AR等相关的先进技术,提出了新型的可视化计算及服务框架。【结果】针对常用的可视化方法,本文提出了适用于GPVis框架的可视化处理模式,并列举了多个该可视化框架系统在典型领域的应用案例的具体方法及结果,实现并满足了科学研究人员在数据分析中的可视化需求。【局限】GPVis在智能分析方面还有待进一步提升,未来将与人工智能技术更紧密结合。【结论】GPVis提供了强大且可扩展的大规模科学数据可视化的平台框架,可以针对不同的数据类型及应用需求进行灵活的组件设计,随着系统在框架结构及可视化算法上的不断发展完善,将在更多的科学领域得到应用。
关键词:
Abstract
[Objective]To solve a series of problems brought about by large-scale scientific data visualization, and to provide a flexible and scalable scientific data visualization framework, this paper proposes GPVis, a scientific visualization system for large-scale data. [Methods]In this paper, we analyzed the challenges and opportunities faced by scientific data visualization at both the method and tool level. A new visual computing and service framework, GPVis, is proposed by using advanced technologies such as data pre-organization, graphics rendering, high-performance computing, human-computer interaction, VR/AR, etc.. [Results]For some common visualization methods, this paper proposes several visualization processing models for GPVis framework, and enumerates several application cases of the system in typical fields with provided specific implementation methods and results. In these cases, different types of visualization need of scientific researchers for data analysis were met. [Limitations]GPVis needs more intelligence for data analysis which leads us to incorporate artificial intelligence technology into future developments and introduce more natural human-computer interaction methods. [Conclusions]GPVis provides a powerful and scalable platform framework for large-scale scientific data visualization, enabling flexible component design for different data types and application requirements. As the system continues to evolve by providing more complete framework functions and visualization algorithms, it will be applied to more scientific fields in the future.
Keywords:
PDF (43072KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
单桂华, 刘俊, 李观, 高阳, 徐涛, 田东. 面向大规模数据的科学可视化系统GPVis. 数据与计算发展前沿[J], 2019, 1(1): 46-62 doi:10.11871/jfdc.issn.2096.742X.2019.01.006
Shan Guihua.
引言
随着大科学计划和大科学工程的规划实施,近年来我国建成了以同步辐射光源、高能粒子加速器、大尺寸球面射电望远镜“天眼”、暗物质卫星、“墨子号”卫星为代表的一系列科学装置仪器设备,并有大量在建或计划建设的科研基础设施装置。这些包括超级计算机、高能粒子对撞机、传感器网络、卫星、高通量实验仪器、高分辨率电子显微镜在内的大科学装置均具有一个共同的特点,那就是它们都在源源不断地产生海量的科学数据。虽然随着现代统计方法的发展,如大数据、人工智能、机器学习等技术为大规模科学数据分析提供了各类自动化的分析方法。然而,很多科学问题的天然复杂性使得数据分析过程不可避免地需要加入人类智能的因素。可视化及人机交互技术让数据分析人员将他们所拥有的人类的灵活性、创造力以及背景知识与现今计算机所拥有的巨量的存储及处理能力相结合,从而对复杂状况做出更好的判断和决策。因此,针对大规模数据的科学可视化技术的研究和应用对于促进科学研究与探索具有非常重要的意义。科研的深入带动了特定领域的科学问题在范围、规模、复杂性上不断扩大,科学装置产生的数据规模也在不断提升。尤其是近年来在国内发展迅速的超级计算机,基于大容量的存储及计算资源为科学家们提供了对各类科学问题进行数值模拟的广阔空间。而随着应用的物理建模不断精细,数值模拟分辨率越来越高,计算所产生的数据量也从以前的可由单机处理的数据规模迅速发展为TB、PB甚至更高数量级的规模。要对这些海量的科学数据进行可视化,显然无法再采用传统的可视化工具和方法,我们需要利用现有的先进IT技术发展一套适用于大规模科学数据可视化的框架方法及服务平台。
科学数据的海量规模首先为可视化处理带来了存储及IO等一系列相关问题。在对海量数据进行分析时,如果要对整个数据进行可视化,冗长且易出错的数据IO及传输过程将非常耗时费力。对于超级计算机上由大规模模拟产生的计算结果的可视化,由于模拟计算结果的可重现性,我们可以采用原位可视化的方法,在不将数据写入外部存储的情况下,原位地对数据进行减量或转换。但对于更多的大科学装置,将产生的数据持久化保存再进行分析是不可避免的操作流程。
从计算量的角度看,如果要求采用如等值面、体绘制、整体视觉映射等能够体现数据全局结构或数据分布的可视化方法,那么在不进行数据下采样或区间截取的情况下,单时间步数据的可视化计算量将达到
实际应用中的可视化方案复杂多样,可能是多种可视化方法的串连或并列组合,也有可能需要穿插多种分析计算过程或用户交互过程。这些情况的复杂性是由于各类数据分析人员的可视化需求的多样化造成的,想要统一化或标准化可视化流程几乎是不可实现的。为了更快更好地将用户的可视化需求体现到可视化流程中,一些可视化系统采用可定制的可视化工作流以提供可视化实现方案的灵活性。实践证明,通过可视化工作流配置来调整可视化参数的方法可以很快地适应用户的需求变化,提高了系统的通用性,但同时也提高了系统在运行和开发过程中的复杂度,系统的稳定性和易用性也相对于专用可视化系统有所降低。
解决大规模科学数据可视化过程的数据存取及计算问题,最常用的办法是借助高性能计算技术,通过并行IO软硬件及并行可视化算法,化整为零,分而治之,将庞大的计算任务平均分布到超级计算机所包含的众多的计算节点上。同时,传统的高性能计算环境也存在资源调度不灵活的问题,新兴的云计算技术作为先进的分布式计算存储资源服务形式,与并行可视化技术相结合,可提高并行计算资源调度的灵活性,也为大规模科学数据远程可视化提供了更便利的对外服务平台形式。另外,以大尺寸屏幕、移动终端、VR设备为代表的新型显示及交互终端,也可以在大规模数据可视化过程中起到非常重要的作用。如以分辨率高、沉浸感强为特点的大尺寸屏幕可实现更高带宽的信息传递通道;以形式便捷、交互灵活为特点的移动终端可与云计算服务完美结合,提供无处不在的信息出口;以自然交互、完全沉浸、内容可协同为特点VR终端则可实现数据与人类洞察力更紧密的融合,适合于更深层次的数据交互。
为此,本文提出了一种针对于大规模科学数据的可视化平台GPVis,基于一套适应性强且功能完善的软件框架,结合了多种先进的可视化技术和方法,支持科学数据的云共享可视化以及多终端协同的虚拟现实交互,在多学科领域开展了大规模科学数据可视化应用,并取得了良好的效果。GPVis平台的主要开发目标是针对科研人员日常需求,数据类型也主要面向于大科学装置产生的科学数据以及以科研目的为主而产生的数据。本文提到的“大规模数据”主要指数据规模超越桌面计算机单机处理能力的数据,因此,原始数据将存储于远端服务器、高性能计算机或云端存储中,GPVis可视化系统提供基于层次细节的可视化的数据访问策略,以实现数据的实时响应可视化(详细说明见2.1节),提供并行化框架以实现可视化任务的分布式计算(详细说明2.2节),以上策略的适用性不局限于数据的规模,对数据规模的支持能力主要取决于原始数据所在服务器的处理能力和存储能力。
1. 相关工作
1.1 传统的可视化方法及软件
很多科学和工程模拟问题都要求借助科学可视化工具来辅助分析或展示数据,常用的通用可视化软件如ParaView[1]和VisIt[3]从一般化的应用角度出发设计了较完备的数据可视化交互工具。这两个可视化软件有一个共同点,均基于可视化工具库VTK[18]构建。VTK将可视化工作流程进行了分解,提供了数据读写、解析过滤、视觉映射、渲染绘制等一系列功能模块,从算法层面提供了标准化的结构及接口模板,让可视化研究及工程实现人员跳离操作系统文件操作、图形图像处理、OpenGL渲染等底层技术,将精力聚焦在可视化设计及其与应用相衔接方面,极大提高了可视化应用开发效率,并逐渐被业界广泛认可,成为科学可视化领域重要的基础工具。由于很多专业领域有其本身的传统图形表达习惯,通用可视化软件很难得到领域内用户的广泛认可。比如地球遥感、大气海洋模式、地球物理、地质地理等地球相关学科领域,由于存在遥感影像、地图制图学等与专业技术密切相关的图形图像技术,由此为中心所发展的一系列可视化工具,由于本身独特的可视化习惯,形成一系列行业惯用的可视化工具,如GMT、GrADS、NCL等具有强大的地图制图能力的可视化工具被广泛使用,人们较习惯使用Vis5D等三维可视化工具对反演或模拟计算所产生的数据进行可视化分析,并辅以地点及边界标注、遥感图像贴图、地形映射等特定的视觉映射方法,强化数据所处的地理位置信息及环境情况。
而对于与水气流体相关的CFD流场以及有限元应力分析模拟结果数据,涉及到模拟场多样以及模拟物体外形复杂等特点,业内人员常用TecPlot、FieldView等商业可视化软件。在化学药物分子结构、生物大分子、生物影像相关的可视化应用中,人们常用Amira、Chimera软件。除此之外,被广泛应用的适用于特定领域的科学数据商业可视化软件还包括Matlab、SigmaPlot等绘图工具。
1.2 面向大规模科学数据的可视化系统
计算模拟作为第三科研范式,极大地改变了传统的科学研究模式,而高性能计算技术的发展则为计算模拟式的科学研究提供了强大的支撑,同时也产生了规模与日俱增的海量计算结果数据。传统的可视化软件一般只能运行于单台PC机或工作站上,在这样的运行模式下,其可能支撑的数据规模受到较大的限制。即使采用较强的计算存储能力的工作站,也会由于硬件成本的原因而不能进行广泛的推动和采用。因此,传统的可视化应用模式在数据规模如此大的情况下受到了极大的挑战。为解决大规模科学数据的可视化问题,可视化技术研究人员与领域科学家协作研究了一系列适用于海量科学数据可视化的平台。如美国犹他大学开发的ViSUS平台框架[13],集合了包括基于预组织的数据服务器、面向模拟计算的并行IO存储服务、兼容异构终端的LightStream可视化工作流以及交互式的客户端应用工具库等在内的一系列子系统模块,并针对不同的应用场景及数据结构进行灵活组合,开发了多种远程数据分析及可视化系统,如ViSUS-CDAT[15]、ISAVS[14]等。除此之外,针对大规模的特定类型数据的远程可视化,包括大规模几何结构数据[9,17]及三维体数据[6]等,人们也进行了大量的研究,并基于此类技术构建海量科学数据可视化系统[2]。1.3 可视化云服务平台
随着虚拟化技术、网络技术以及Web技术的不断发展,出现了云计算这种分布式计算的新模式,它提供了通过互联网技术交付和访问IT资源的新方法,也为远程协作可视化提供了灵活且可扩展的新平台。通过云模式的计算资源配置,可视化所需的设备及运维成本被平摊到其它的众多领域的应用中,从而降低了大规模数据可视化所需要硬件成本。我们知道,本地渲染效率是远程可视化交互体验中非常重要的指标,但由于人们通常使用如笔记本电脑、平板电脑或智能手机等计算和存储资源有限的设备远程访问云端服务,因此如何在有限的计算资源条件下实现云端和终端设备之间有效地传输数据成为了云模式可视化的主要挑战之一。为了应对这一挑战,云模式可视化一般要求在服务器端进行较复杂的数据预处理任务,并通过这些任务提取少量的数据传输到客户端,以减少可视化所需的数据量和计算量。例如可嵌入Web的体绘制框架Tapestry[16],基于计算资源的虚拟化等技术实现大规模数据的远程可视化,通过云端数据的预先分布式加载及并行渲染绘制,用户终端只需通过由服务器下传的少量的编码图像数据即可实现GB级体数据的实时可视化交互。1.4 基于VR/AR的科学可视化平台
随着虚拟现实终端硬件近年来的长足发展,将VR技术与科学数据分析相结合的应用案例层出不穷。虚拟现实技术是通过计算机生成一种模拟环境,通过输出设备使人感受到虚拟的物体或虚拟环境的存在,并且随着技术发展,模拟的真实度越来越高。虚拟现实技术同样提供了多种交互方式,目前比较常用的交互方式有:语言输入、手势、身体动作和手柄操作。通过这些交互方式,操作者可以与虚拟的物体或虚拟环境进行互动,极大提高了交互的效率。科学模拟很多是对真实存在的物体或者现象进行模拟,传统的二维显示器并不能很好展现这种三维物体,并且仅仅通过鼠标进行交互也不够便捷,基于此已经有些研究将科学可视化的结果使用虚拟现实技术进行展示。通过利用虚拟现实技术,可以使被模拟的物体或者环境更加真实的展现在科学家面前,而且通过这些交互方式可以极大的提高数据探索的效率。Zach等人[22]设计实现了交互式虚拟现实可视化工具Belle2VR,使用该软件作为学习和探索亚原子粒子碰撞的辅助工具,取得了非常好的效果。Okada等人[11]选择使用虚拟现实技术来可视化时空社交媒体数据,通过基于位置信息的微博可视化方法和VR技术的结合,极大的提高分析数据的效率和能力。因此,在科学可视化中使用虚拟现实技术是未来的发展趋势之一。2 GPVis科学数据可视化框架
面向大规模科学数据可视化系统GPVis的主要设计目的在于实现一套包含以下功能的软件系统:(1)支持包括体绘制、粒子绘制、流场可视化在内的通用科学可视化方法,并实现可视化参数的配置接口;(2)通过对大规模数据的预组织计算,支持基于层次细节(level-of-detail)策略的视角驱动的可视化,实现低延迟的交互式可视化过程;(3)通过对大规模数据的分布式存取,支持并行可视化计算,实现高精度的可视化输出;(4)支持多种类型的终端输出,包括异形屏及VR设备;(5)支持多种类型的可视化结果发布,包括带轻量交互的预览式可视化结果输出,或高分辨图像及视频等形式;(6)支持面向领域的交互式可视化应用定制。为实现上述目标,我们构建了如图1所示的一套软件架构,其中数据及通讯层负责与外部进行数据交换,以及常用的数据过滤、重组、压缩、解压及编解码等数据处理算法;可视化层负责实现各类可视化基础算法及可视化组件;视图层负责将可视化结果的渲染呈现;交互层负责提供针对系统中各类可调参数的用户交互界面;应用层负责形成总体业务逻辑,并面向特定领域进行应用封装,提供针对性的应用程序(如图2);发布层负责根据用户设定的发布参数,对科学数据进行批量化的可视化计算,发布生成高精度的图像、视频动画或者可轻量级交互的可视化Web应用。
图1
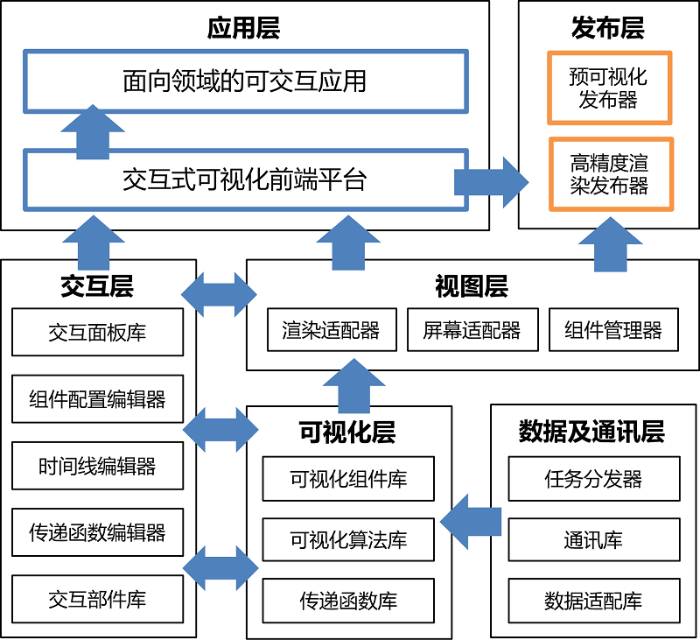 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1面向大规模科学数据的可视化系统GPVis软件架构图
Fig.1The software framework of GPVis , a visualization system for large-scale scientific data
图2
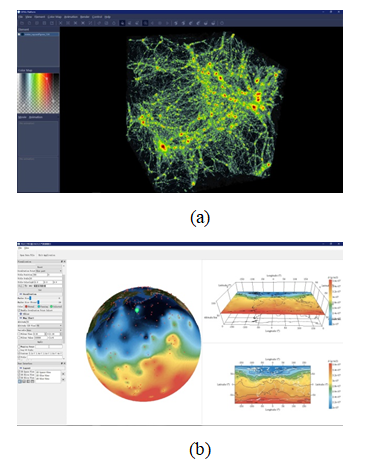 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2基于GPVis的交互式可视化应用软件界面截图,其中图(a)为GPVis前端平台,图(b)为面向掩星探测领域的交互式可视化应用平台GODAT
Fig.2User interfaces of two GPVis-based interactive domain visualization software. (a) shows the GPVis front-end platform. (b) shows GODAT, an interactive visualization application platform for the occultation data.
处于可视化层的可视化组件是GPVis框架的核心单元,其余的功能模块对可视化组件起到支撑或管理的作用。可视化组件其本质是一套黑盒封装的可视化工作流,该工作流将可视化所用到的数据流结构、可视化算法、传输函数、子任务分块策略等均隐藏在工作流各环节中,组件开发者可选择将工作流内部的部分参数以交互面板的形式进行暴露,也可直接暴露工作流本身。可视化组件可选择数据适配库中提供的标准化的数据接口,可选择采用传输函数库中封装的传输函数,可选择可视化算法库中的公用算法,也可采用自有的格式、接口及算法。组件开发者需要遵循规定的一套接口协议对可视化工作流进行封装,编译成可视化组件并以插件形式加载到软件框架中,这样才能保证可视化组件被纳入组件管理器的调度范畴,才能保证交互层各交互面板可与组件内部参数进行有效的交互。
GPVis是针对大规模科学数据可视化所设计,以下将从数据、计算、输出、发布等几个方面说明GPVis框架为解决科学数据超出单机处理能力的数据规模问题,并适应当前的技术及需求发展而做出的针对性设计。GPVis软件架构从功能调用关系角度将整体平台分为多个功能模块,而这些功能模块的运行环境则由具体应用的运行模式所决定。例如在普通的交互式可视化模式下,部署于服务器上的GPVis平台主要起到数据服务器的作用,其主要参与工作的功能模块包括数据通讯层以及可视化层中与数据流式访问策略相关的组件子模块,而可视化、界面交互、视图渲染相关的功能模块则运行于客户终端以支撑交互式可视化应用;而在可视化发布模式下,部署于高性能计算机上的GPVis平台将调用视图层及可视化层的核心功能,通过任务分发器并行化地完成发布任务所包含的一系列渲染任务;而多终端协同交互模式下,整体系统将从逻辑上分为数据服务器、渲染服务器、控制服务器、交互终端等多种角色分块,形成更为复杂的分布式计算模式,具体介绍见2.3节。
2.1 数据适配
GPVis数据适配库提供了针对大规模数据的一系列数据预组织算法,从而实现大规模数据的核外(out-of-core)部署,使得可视化组件可通过即时高效的流水线方式访问数据,这种方式有利于为核外计算模式而设计的可视化方法对数据的有效访问,从而避免可视化方法被限制采用高成本的传统系统IO模式。同时数据流的访问模式也是很多并行分布式可视化算法及层次细节的可视化算法所依赖的基础方法,因为实现数据传输及访问时间和数据处理时间的平衡是这类算法设计的一类重要问题。通常在针对可视化算法进行数据预组织策略设计时,我们会充分考虑算法的数据访问模式,并根据分析结果设计可最大化数据局部性并有利于降低外部存储IO成本的数据排布方法。而常用的针对大规模科学数据可视化方法都会考虑采用自适应层次细节(level-of-detail)的流式数据访问模式,即由低分辨到高分辨的次序加载数据,因为这样可以实现数据边加载边操作的实时可视化交互。为了与此模式相匹配,我们需要将同分辨率级别的数据在相邻近空间进行存储,能实现这一目标的数据组织方法包括层次化的八叉树、Lebesgue空间填充曲线[12]、虚拟多级体数据索引[6]、三角二分层次结构[9]等。这些方法均包含在GPVis数据适配库中为可视化组件提供方法支撑。
2.2 并行可视化
可视化算法的并行化研究是科学可视化领域的研究难点,而对于不同的可视化算法、不同的计算体系架构或者不同的应用场景,其并行策略可能在包括方法、流程、结构等多个层面上都有较大不同。由于GPVis的设计目标是面向通用科学数据的可视化平台,因此,我们不能单纯针对某一类数据或某一种可视化算法进行结构上的适应调整。我们需要的是一种灵活通用,适应性强的并行框架。为此,我们借鉴MapReduce简化并行模型的思想,构建了一套面向任务并行的分布式可视化计算框架,将有必要并行处理的可视化算法分解成较小粒度的计算任务,通过全局的任务分发器进行计算任务的动态分发调度。任务分发操作会充分考虑数据的分布情况以及计算节点的任务负载情况,因此,这种方法可以尽量减少数据通讯,同时实现较好的负载均衡。从GPVis平台的并行计算架构可以看出,任务分发器不仅可以支持并行可视化计算,也可实现平台普通任务的分布式分发,包括高精度渲染过程中的多帧渲染任务,以及数据预组织过程中的时变数据预处理任务都可借助此并行框架充分利用现有计算资源减少整体运行时间,提高处理效率。
2.3 终端输出
在商业娱乐媒体以及新型视听技术的影响下,人们对数据可视化显示及交互效果的要求不断提升,各种高分辨率的显示设备以及便携的虚拟现实沉浸式显示终端正逐步得到普遍采用。众多的终端显示设备类型多样,除了可直接接入普通计算显示输出信号的显示终端,其它设备主要可分为三类:一类是包括单通道球幕、穹幕在内在异形显示设备,一类是多投影或多模组拼接融合而成的拼接显示设备,一类是以Vive、HoloLens为代表的虚拟现实立体显示终端。为适应这几类显示设备,GPVis提供了渲染适配器和屏幕适配器以兼容不同的显示环境。渲染适配器提供兼容OpenGL标准的多种渲染环境配置接口,包括支持立体显示、分屏显示、脱屏绘制等相关参数的设置。为支持异形显示设备,屏幕适配器提供包括透视投影、方位角等距投影、六面体全景投影在内的多类投影模型的视图相机配置,后续还将提供基于样条曲面的非线性图像变形投影及非均匀亮度调整功能,用于多个异形屏幕拼接融合时所需的几何校正及边缘融合处理。在数据进行交互式分析时,很多时候需要多人协同进行,便捷的多人协同操作可以极大的提高数据分析的效率。为了可以支持多人协同分析,GPVis提供了多终端的协同模式。按此模式工作时,GPVis作为控制服务器运行,并于运行初始时刻将图像信息分发到多个终端,此时多个终端可保持同样的可视化输出。不同的终端实时检测用户的交互事件,并将交互事件回传GPVis控制服务器,服务器根据交互事件和当前的图像信息分发最新的终端图像数据,进而可以构成多终端统一的协同工作环境。
2.4 渲染发布
渲染发布是可视化的一种重要输出形式,GPVis通过高精度渲染发布器和预可视化发布器分别支持两种不同类型的发布操作。其中高精度渲染发布器可产生高分辨图像及动画视频,预可视化发布器可产生可轻量级交互的Web应用。2.4.1 高精度渲染发布
将可视化结果用于出版物配图或是其它方式的静态展示是科研用户的常见可视化需求。考虑到计算及存储的瓶颈问题,针对大规模数据的实时交互可视化只要求实现达到屏幕分辨率的渲染结果,但这类渲染结果一般会采用经过下采样处理后的数据,不能忠实反映原始数据情况,而且渲染算法的一些优化也让渲染结果在质量和效果上大打折扣。因此,不适合直接采用交互系统输出的渲染结果作为静态分析的对象,我们需要一套可产生高精度高分辨率的渲染结果的大规模科学数据可视化机制。为此,GPVis提供了一套高精度渲染发布器,采取用户要求的分辨率,在不损失数据质量的前提下,通过通讯层任务分发器批量且并行地完成对原始数据的高精度渲染。
要产生高保真高真实感的渲染结果,有时我们需要借助一些第三方渲染器。为此,GPVis提供的渲染适配器的场景导出功能,将可视化场景导出成与POVRay和RenderMan兼容的场景数据。另外,除了高精度图像输出,视频动画输出也是可视化结果发布的重要形式,它提供了可多角度对目标数据进行展现的可视化结果。为实现动画发布操作,GPVis还提供了针对动画时间线的分镜编辑器以及高压缩率视频编码器等动画输出工具模块。
2.4.2 预可视化发布
数据可视化过程中的轻量级交互是指只通过简单的视角变换、时间步跳转等不涉及更改可视化工作流或场景组件的交互过程,同时也是可视化过程中最常见的一种交互形式。假定可视化工作流为
但是实际情况与假设的情况有较大差别。首先,渲染发布计算会要求较高结果分辨率,从而使
3 大规模科学数据可视化组件
科学数据按网格模型结构分类,主要包括体数据、粒子数据以及非结构数据等,而按数据包含的维度分类,则主要可分为标量数据、矢量数据、时变数据等。由于体数据和粒子数据的网格模型描述方法简便,不管是在数据采集或数值模拟方面均具有较强的可扩展性,从而造成这两种类型的大规模科学数据模型结构最为常见,因此,我们针对这两类大规模数据,结合常用的可视化方法设计了相应的可视化组件,具体的可视化策略将在3.1和3.2中进行介绍。针对流场可视化这一科学可视化领域难点,我们也从种子点选取、粒子追踪等方面制定了相应的可视化策略,形成平台特有的可视化组件,具体方法请参考3.3节。3.1 体数据可视化组件
随着软硬件能力的提升,包括宇宙模拟、气象模拟、力学模拟这类超算应用,以及电子显微镜、层析成像这样的三维图像获取方法,所能产生的三维体数据的规模越来越大,有的数据达到TB甚至PB级。针对如此大规模的体数据,我们无法将数据一次全部加载到内存中进行可视化,因此我们采用层次化的八叉树或者Lebesgue空间填充曲线对数据进行预组织计算,以多分辨率来表示整体数据,从而实现数据基于层次细节的实时交互。也正因为数据存取方法的变化,针对大规模三维体数据的等值面、切片及体绘制可视化具体算法均有别于常用算法。GPVis体数据可视化组件采用的动态切片绘制方法,在绘制切片前先根据切片位置计算各分辨率层级的数据块与切片的相交情况,并根据视点位置及数据块大小计算与切片相交的数据块的优先级,然后基于数据块之间的嵌套关系以及已加载的数据块情况对未加载的数据块进行加载顺序的排序形成加载队列,将无关数据块进行LRU排序后放入回收队列,最后按此队列依次加载和释放相应数据块并更新切片,从而实现大规模体数据的交互式切片浏览。
大规模体数据的等值面生成可通过并行化的Marching Cube算法完成,但这种方法很难实现交互级的可视化,尽管我们可以采用八叉树层级组织结构,由粗至细渐近式实现等值面生成,但这种方法生成的粗精度等值面拓扑结构保持度很差,且这类方法往往会带来内存的大量消耗,拖慢整个交互进程。因此,GPVis体数据可视化组件基于体绘制的方法实现了等值面的直接绘制[5],简化了组件架构的同时也提高的数据交互效率。
体绘制基于光线投射法逐像素地沿视线方向的取样体数据,并累积取样数据计算像素点颜色和透明度,是比较重要的一类体数据可视化方法。由于大规模体数据无法完全加载到内存或显存中,无法采用单独的数据块加载渲染模式,因此,GPVis体数据可视化组件基于八叉树的预组织结构采用光线导向[4]的体绘制模式,根据绘制光线的投射方向、深度以及取样步长进行数据块的动态加载及渲染。
传输函数作为颜色映射的方法,是可视化领域尤其是体绘制相关技术的重要概念。这是因为传输函数的选取对体绘制的可视化效果的影响是极大的。对此,我们针对常用的一维传输函数开发了多种函数模型以及相应的编辑器和自动生成算法,同时也为体绘制专用的二维传输函数开发了基于映射图模型以及基于GMM模型的编辑器和自动生成算法[19,20,21]。GPVis将这些不同的传输函数模型进行了标准化并封装形成了传输函数库。
3.2 粒子绘制组件
粒子数据是科学模拟中常用的数据类型,通常模拟通过粒子数据的运动近似的表达模拟的事物。随着近些年来计算机能力的不断增加,所用的粒子数也越来多。这种大规模的离散粒子数据的绘制对了解模拟数据非常有效。GPVis粒子绘制组件支持对粒子数据的三种绘制方式,即网格映射、粒子的抛雪球算法和四面体网格算法。网格映射是粒子绘制中常用的方法之一,通过网格映射的方式可以将粒子数据转换成体数据,进而使用体数据的相关绘制模块对数据进行绘制。为了适应于大规模粒子数据的处理,GPVis粒子绘制组件支持多节点并行的数据映射,可以将粒子数据在多节点上快速的进行映射,并且与体绘制组件可以直接对接,方便快速的生成粒子数据的可视化效果。为了降低大规模粒子绘制所需的存储量并优化计算性能,粒子绘制组件采用基于Hilbert空间填充曲线的数据快速裁剪办法[29],实现了大规模时变粒子数据的时间步间插值及投影绘制。同时利用所见即所得的时序特征可视化算法,实现大规模时序粒子的交互式可视化分析[30]。
抛雪球算法是一种常用的直接体绘制算法,对此算法我们经过改进,使之适用于粒子数据,即将粒子作为一个能量源,将每个粒子投向图像平面,以粒子的投影点为中点将粒子的权重扩散到图像的像素中。为了适应于大规模粒子数据的处理,GPVis粒子绘制组件支持多节点的并且处理,即多节点并行粒子的抛雪球算法。通过抛雪球算法将粒子数据映射到二维平面上,再经过颜色表的调整最终生成粒子数据的可视化结果。
为了将粒子可视化组件应用到天文模拟数据可视化应用中,GPVis粒子绘制组件采用将粒子间的六面体网格分解成四面体网格再进行绘制的算法[27],对大规模粒子数据进行重新组织再可视化,可视化结果可以很好地反映宇宙结构,特别是纤维状结构。为得到更好的宇宙结构可视化结果,我们还针对天文模拟的可循环特性,对基于四面体的粒子绘制法进行了优化及并行化,根据初始时刻粒子位置组织四面体网格,在时序处理时,维持组成四面体的粒子不变,以四面体为绘制单位进行绘制。通过此方式对粒子数据进行绘制,绘制的效果优于对粒子数据直接进行绘制,特别是对于模拟过程中粒子的运动和形成结构特征的表达。
3.3 流场可视化组件
大规模流场可视化的种子点选取对流场可视化,尤其是流场特征的描述至关重要。GPVis流场可视化组件支持传统以点、线、面、体为结构的种子耙选点法、均匀撒点法、网格点撒点法等种子点选择办法,同时也支持通过流场关键点及流场分析提取到的特征点,结合一定的选点策略进行种子点选取。流场可视化组件支持的流场特征点包括拓扑关键点(如源点、汇点、涡中心点、鞍点等),几何物征点(如零曲率点、高涡度点、涡度速度平行点等),物理特征点(如低压点、高温点、旋流点等)以及聚类表征点等。拓扑关键点提取是较常用的特征点提取方法,该方法基于流场梯度及其特征值计算得到符合特定情况的位置点,具体通过计算得到雅可比矩阵,此矩阵可用于计算物理点散度,涡度,旋度,加速度和曲率等信息,将此矩阵求特征值得到
粒子追踪积分是流线和轨迹线生成的必要计算过程,流场可视化组件采用高阶龙格库塔积分实现,包括RK4积分和RK45积分。对于粒子追踪积分过程中涉及频繁的物理点取样插值计算操作,在对均匀网格流场进行可视化时,可以采用反向索引函数快速定位数据块并进行三线性插值取样物理场,在对曲线网格或非结构网格流场进行可视化时,则只能根据网格点位置构建K-d树实现坐标反向索引。在粒子追踪算法基础上,流场可视化组件实现了流线、轨迹线、动态流线段等多种形式的直接流场可视化方法,以及基于FTLE脊线的LCS可视化等间接可视化方法。
流场可视化的主要计算负载集中于粒子追踪积分计算过程,在大量流线计算过程尤其是FTLE计算过程中粒子追踪计算占据了绝大多数的计算量,通过并行计算技术提高计算速度非常有必要。考虑到引入并行算法的必要性,GPVis流场可视化组件针对粒子追踪过程设计了相应的并行与硬件加速算法。该组件将追踪任务设计为相互独立的计算单元,在进行粒子追踪计算前,按各种子点位置生成大批的指定数据区域的计算任务,将这些计算任务提交给任务分发器进行调度。任务分发器将估算各计算任务在不同节点上运行所需的运行开销,并选择最适当的运行节点。任务在进行过程中不断更新任务所属数据区域,当所属区域发生改变时,任务将向任务分发器提出重新评估的请求,而任务分发器也将对计算任务将基于各节点负载情况及任务运行开销按评估结果将任务转移到适当节点。实践证明,在GPVis并行框架下,该流场可视化组件对于大规模的粒子追踪积分任务计算可实现较理想的负载均衡。
基于上述方法,GPVis流场可视化组件可实现定常流场流线以及非定常流场轨迹线的生成,还可结合流场可视化组件的时间线控制功能,绘制常用于表现流场动态流线段效果图(如图4)。在按照屏幕像素空间随机撒点的情况下,还可实现视角自适应的流线段生成及绘制。
4 应用案例与专家评价
4.1 大气模式数值模拟数据可视化
大气模式模拟结果数据可视化的主要难点在于数据带时序变化,物理变量较多,需结合地形及地理信息等外围数据进行融合展示等。中国科学院大气物理研究所针对我国随着城市化、工业化的发展造成的PM2.5污染问题,研发的嵌套网格空气质量模式[28],该模式的模拟结果能够体现我国区域尺度、城市尺度大气污染物的排放、时空演变和输送特征。我们采用GPVis科学可视化平台对空气质量模式模拟输出的大气污染数据进行了可视化。数据采用的对2014年10月的一次北京到武汉的污染物传输过程的模拟结果,数据变量包含PM2.5浓度场、风场、地面高程等信息。我们采用体绘制、纹理映射、流线可视化、地形可视化等多种形式相结合的方法进行多变量融合可视化,将PM2.5浓度、风场、地图纹理、地形等要素进行综合的可视化,并可以动画的形式输出可视化结果(如图3)。图3
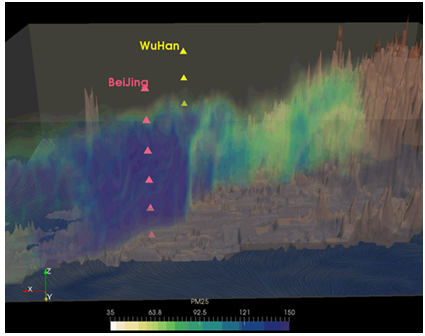 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3大气污染物模拟结果的多变量物理场可视化
Fig.3Visualization of atmospheric pollutant simulation results with multivariate field
相关的领域科学家表示,现有的用于分析模式模拟输出数据的工具,一般以二维图像为主,难以直观地了解数据的三维全貌,而GPVis科学可视化平台,不仅支持三维数据的呈现,更能够有效地将多元信息进行综合呈现,结合了地形的可视化能够将雾霾传输过程中地形的影响、风的作用也表现出来,对于雾霾传输过程的分析有很大的作用。
4.2 全球海洋环流数值模拟数据可视化
我们采用GPVis科学可视化平台对海洋模式模拟的输出数据进行了可视化。全球海洋环流数据来自中国科学院研发的地球系统高分辨海洋模式LICOM2[10](LASG/IAP Climate System Ocean Model Version 2)。该模式引入了先进的海洋内部等位密度面混合、垂直混合、短波穿透模型,可达到涡分辨的高精度全球海洋环流模拟水平。该模拟数据水平分辨率为0.1°,垂直层数30层,变量场包括温度场和速度场。通过信息熵和临界点相结合的种子点选取方法[25],GPVis将流场种子点覆盖了流场中变化剧烈的区域,而且兼顾了流场的拓扑结构特征,输出流线可视化结果(如图4)。相比于仅仅用信息熵的方法,GPVis种子点生成模块可准确捕捉流场中的漩涡等特征结构。图4
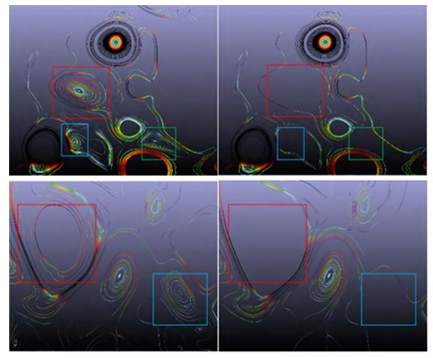 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4LICOM2模拟结果数据的流线生成结果对比,其中左侧为使用智能种子点生成的流线,右侧为不使用智能种子点生成的流线。
Fig.4LICOM2 simulation data streamline generation results comparison. The left side is the streamline generated with the feature-based seeding. The right side is the streamline generated without feature-based seeding.
在流场交互方面,GPVis支持科学家交互式地对流场数据进行探索,通过交互式的多层次流线可视化方法(如图5),无需重组数据,在可见视窗内设置种子点,按图像空间动态自适应地生成和回收种子点,生成流线,使得在交互过程中,全局和局部流场特征都可以实现高精度的显示。
图5
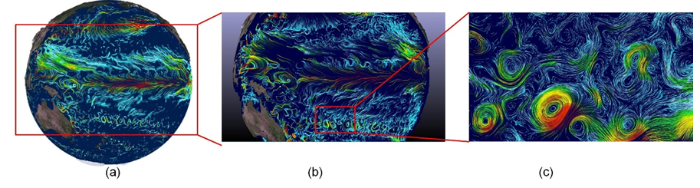 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5采用交互式的多层次流线可视化方法可视化LICOM2模拟结果数据的结果
Fig.5The visualization results of LICOM2 simulation data using an interactive multi-level streamline visualization method
据相关的领域科学家反馈,相比于传统的数据后处理工具,GPVis的流场数据可视化模块更为智能、灵活。涡旋对于海洋环流而言是非常重要的特征,往往需要耗费大量的人力、时间成本来发现涡旋,借助GPVis科学可视化平台,可以更为高效地对海洋环流数据进行分析及展示,提升了科学家的数据分析及学术交流效率。
借助HoloLens设备,以及GPVis的多终端协同工作模式,如图6所示,我们还采用多终端协同可视化的模式对海洋流场数据进行了可视化协同交互,该模式支持异地科研团队的协同分析,三维场景沉浸式显示和直观的协同交互,更有助于信息的高效获取和团队协作,更好激发科学家的探究。
图6
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6LICOM2模拟结果数据的多终端协同交互可视化
Fig.6Collaborative interaction visualization of LICOM2 simulation data
4.3 合金微结构演化相场模拟结果可视化
材料微结构决定了强度、延展性、硬度以及导电性等很多重要的材料属性,对微结构形成演化过程进行长时间模拟可了解合金晶粒粗化形成合金微结构的过程。中科院计算机网络信息中心的研究团队采用Cahn-Hilliard方程模拟两相微观结构的粗化动力学,并基于高性能并行计算机进行了长时间大规模的合金微结构演化相场模拟,得到了可进行量化分析的精细微结构[23]。该模拟网格规模达到67003,单时刻数据高达2.4TB,远超出了单台计算机的承载能力,为了实现发布级渲染需求,我们采用GPVis体数据可视化组件的并行等值面的高精度渲染发布器,通过并行化的可视化处理得到高分辨率的可视化结果(如图7)。图7
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7体数据可视化组件针对合金微结构演化相场模拟结果数据的高精度渲染结果
Fig.7High-precision rendering results rendered by the volume data visualization component for the phase field simulation results of alloy microstructure evolution
针对出版物插图输出而设计的高精度渲染发布器,可通过GPVis平台工作流调用提供发布接口的可视化组件实现数据预览以及批量化的高分辨图像渲染。针对图7所示的渲染结果,科学家表示该可视化结果可以清晰分辨材料微结构及其演化过程,可实现不同时刻数据的对比和分析。
4.4 电镜数据银行三维体数据远程可视化
电镜数据银行EMDB[7]提供了一个冷冻电镜EM数据发布分享的平台,目前汇集了全球8000多项由各国结构生物学研究机构生产的多类EM数据,每个完整发布的EM数据至少包含一个三维体数据,并配套元数据以说明数据相关信息。每个EM体数据的单方向网格规模从几十到上千不等,总数据量也大小不一,平均数据量在10M量级,目前最大的EM数据可达10G量级。为了给如此海量且多样化的数据集提供远程可视化服务一般需要制定复杂的前后台方案以及计算硬件支撑。我们采用GPVis科学可视化平台的预可视化发布器对EMDB数据进行预可视化处理,并以预览平台的形式发布,自动构建了一套远程可视化平台。如图8所示的EM数据预览平台已接入EMDB中国镜像网站,并作为EM数据项远程预览工具提供远程可视化服务。图8
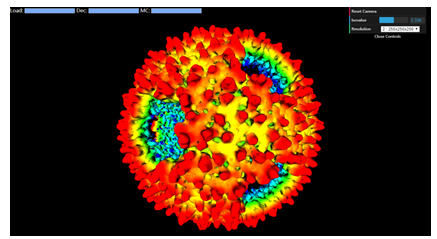 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8针对EMDB的EM数据预览及三维交互可视化工具VizEMEC界面截图
Fig.8User interface of VizEMEC, an EM data preview and 3D interactive visualization tool for EMDB
经过与领域科学家用户的沟通,我们了解到,由GPVis预可视化发布的EM数据预览可视化服务可满足EMDB镜像网站用户的日常预览需求,且具有稳定的数据加载过程、灵活的三维交互功能以及快速的交互响应速度。作为此远程Web预览服务的维护方,在完成定期进行数据更新任务时,只需设置服务器定期任务自动调用预可视化计算发布器更新计算结果即可完成日常更新维护任务,平台总体运行稳定且操作便捷。
4.5 宇宙结构演化模拟可视化
暗物质是形成宇宙大尺度结构的关键因素,通过N-body模拟可以使天文学家深入研究这一过程。可视化可以帮助天文学家将抽象的粒子数据转换成易于了解的可视化结果,进而提高数据分析和探索的效率。模拟中形成的宇宙特征结构如Void, Filament, Halo等,只有通过可视化的手段才可以使天文学家了解其真正的形态。中国计算宇宙学联盟盘古计划的超大规模的N体模拟[8,26]粒子规模数为3072^3个虚拟粒子,包含粒子的ID、三维坐标、质量、速度、粒子光滑半径、密度及速度弥散等多个变量,64个时刻数据,每个时刻数据量1.4TB,共90TB。基于GPVis科学可视化平台我们完成对该大规模天文粒子模拟数据的可视化(如图9)。通过清晰的宇宙特征结构的展现,直观帮助天文学家进行观察与分析模拟数据,并可生成时序演化动画,进一步帮助了了解特征结构演化过程动态信息,同时可通过所见即所得的时序交互式可视化功能,直观选择感兴趣的暗晕,进行交互分析。图9
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图9采用粒子绘制组件对大尺度宇宙暗物质模拟演化结果数据的可视化
Fig.9Visualization of large-scale dark matter simulation data rendered by particle data visualization component
5 总结与展望
对于与科学研究密不可分的科学可视化技术,在大科学时代的今天,其研究与应用的重要性日益突显。大科学装置产生的海量科学数据也为科学可视化带来了一系列的挑战,如何解决大规模科学数据可视化过程中所存在的存储方法、计算效率、交互方式等方面的瓶颈问题,都是可视化社区需要重点研究的课题。同时,如E级计算机、人工智能、云计算、虚拟现实等众多涌现的新技术也为科学可视化发展提供了新的机遇与挑战。针对当前面临的大规模科学数据可视化中的一些具体问题,本文介绍了一套功能丰富、形式灵活、可扩展性强的大规模科学数据可视化系统GPVis的具体设计和实现,针对包括体数据、粒子数据、流场数据等多种形式在内的科学数据,基于一系列先进的数据处理及图形图像技术,提供了从数据预组织到并行可视化,从多终端输出到高精度渲染发布,涉及科学可视化全流程的系统解决方案。经过不断的更新与发展,GPVis系统目前在众多领域得到应用,并且在多类应用场景下突显出系统优势,验证了该系统的TB级规模科学数据可视化能力。随着人工智能、虚拟现实和5G的发展,现代化的科学研究模式正发生着根本性的变化,为了适应新的科研范式,未来的GPVis发展将与人工智能相深度结合,并引入更自然的人机交互技术,提供分析更智能、效果更直观、使用更友好可视化分析功能。因此,我们后续的工作中,将深度学习、新型人机交互技术、原位计算等先进的方法及模式与GPVis系统相结合,从框架到算法层次进一步发展和完善GPVis。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[本文引用: 1]
Magsci [本文引用: 1]

This paper presents ConnectomeExplorer, an application for the interactive exploration and query-guided visual analysis of large volumetric electron microscopy (EM) data sets in connectomics research. Our system incorporates a knowledge-based query algebra that supports the interactive specification of dynamically evaluated queries, which enable neuroscientists to pose and answer domain-specific questions in an intuitive manner. Queries are built step by step in a visual query builder, building more complex queries from combinations of simpler queries. Our application is based on a scalable volume visualization framework that scales to multiple volumes of several teravoxels each, enabling the concurrent visualization and querying of the original EM volume, additional segmentation volumes, neuronal connectivity, and additional meta data comprising a variety of neuronal data attributes. We evaluate our application on a data set of roughly one terabyte of EM data and 750 GB of segmentation data, containing over 4,000 segmented structures and 1,000 synapses. We demonstrate typical use-case scenarios of our collaborators in neuroscience, where our system has enabled them to answer specific scientific questions using interactive querying and analysis on the full-size data for the first time.
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
Magsci [本文引用: 2]
This paper presents the first volume visualization system that scales to petascale volumes imaged as a continuous stream of high-resolution electron microscopy images. Our architecture scales to dense, anisotropic petascale volumes because it: (1) decouples construction of the 3D multi-resolution representation required for visualization from data acquisition, and (2) decouples sample access time during ray-casting from the size of the multi-resolution hierarchy. Our system is designed around a scalable multi-resolution virtual memory architecture that handles missing data naturally, does not pre-compute any 3D multi-resolution representation such as an octree, and can accept a constant stream of 2D image tiles from the microscopes. A novelty of our system design is that it is visualization-driven: we restrict most computations to the visible volume data. Leveraging the virtual memory architecture, missing data are detected during volume ray-casting as cache misses, which are propagated backwards for on-demand out-of-core processing. 3D blocks of volume data are only constructed from 2D microscope image tiles when they have actually been accessed during ray-casting. We extensively evaluate our system design choices with respect to scalability and performance, compare to previous best-of-breed systems, and illustrate the effectiveness of our system for real microscopy data from neuroscience.
44(
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
DOI:10.1007/s13351-012-0305-yMagsci [本文引用: 1]
The baseline performance of the latest version (version 2) of an intermediate resolution, stand-alone climate oceanic general circulation model, called LASG/IAP (State Key Laboratory of Numerical Modeling for Atmospheric Sciences and Geophysical Fluid Dynamics/Institute of Atmospheric Physics) Climate system Ocean Model (LICOM), has been evaluated against the observation by using the main metrics from Griffies et al. in 2009. In general, the errors of LICOM2 in the water properties and in the circulation are comparable with the models of Coordinated Ocean-ice Reference Experiments (COREs). Some common biases are still evident in the present version, such as the cold bias in the eastern Pacific cold tongue, the warm biases off the east coast of the basins, the weak poleward heat transport in the Atlantic, and the relatively large biases in the Arctic Ocean. A unique systematic bias occurs in LICOM2 over the Southern Ocean, compared with CORE models. It seems that this bias may be related to the sea ice process around the Antarctic continent.
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
DOI:10.1109/TVCG.2011.97Magsci [本文引用: 1]
The multidimensional transfer function is a flexible and effective tool for exploring volume data. However, designing an appropriate transfer function is a trial-and-error process and remains a challenge. In this paper, we propose a novel volume exploration scheme that explores volumetric structures in the feature space by modeling the space using the Gaussian mixture model (GMM). Our new approach has three distinctive advantages. First, an initial feature separation can be automatically achieved through GMM estimation. Second, the calculated Gaussians can be directly mapped to a set of elliptical transfer functions (ETFs), facilitating a fast pre-integrated volume rendering process. Third, an inexperienced user can flexibly manipulate the ETFs with the assistance of a suite of simple widgets, and discover potential features with several interactions. We further extend the GMM-based exploration scheme to time-varying data sets using an incremental GMM estimation algorithm. The algorithm estimates the GMM for one time step by using itself and the GMM generated from its previous steps. Sequentially applying the incremental algorithm to all time steps in a selected time interval yields a preliminary classification for each time step. In addition, the computed ETFs can be freely adjusted. The adjustments are then automatically propagated to other time steps. In this way, coherent user-guided exploration of a given time interval is achieved. Our GPU implementation demonstrates interactive performance and good scalability. The effectiveness of our approach is verified on several data sets.
DOI:10.1111/j.1467-8659.2011.02045.xMagsci [本文引用: 1]
Due to 3D occlusion, the specification of proper opacities in direct volume rendering is a time-consuming and unintuitive process. The visibility histograms introduced by Correa and Ma reflect the effect of occlusion by measuring the influence of each sample in the histogram to the rendered image. However, the visibility is defined on individual samples, while volume exploration focuses on conveying the spatial relationships between features. Moreover, the high computational cost and large memory requirement limits its application in multi-dimensional transfer function design.<br/>In this paper, we extend visibility histograms to feature visibility, which measures the contribution of each feature in the rendered image. Compared to visibility histograms, it has two distinctive advantages for opacity specification. First, the user can directly specify the visibilities for features and the opacities are automatically generated using an optimization algorithm. Second, its calculation requires only one rendering pass with no additional memory requirement. This feature visibility based opacity specification is fast and compatible with all types of transfer function design. Furthermore, we introduce a two-step volume exploration scheme, in which an automatic optimization is first performed to provide a clear illustration of the spatial relationship and then the user adjusts the visibilities directly to achieve the desired feature enhancement. The effectiveness of this scheme is demonstrated by experimental results on several volumetric datasets.
DOI:10.1111/j.1467-8659.2012.03122.xMagsci [本文引用: 1]
Two-dimensional transfer functions are an effective and well-accepted tool in volume classification. The design of them mostly depends on the user's experience and thus remains a challenge. Therefore, we present an approach in this paper to automate the transfer function design based on 2D density plots. By exploiting their smoothness, we adopted the Morse theory to automatically decompose the feature space into a set of valley cells. We design a simplification process based on cell separability to eliminate cells which are mainly caused by noise in the original volume data. Boundary persistence is first introduced to measure the separability between adjacent cells and to suitably merge them. Afterward, a reasonable classification result is achieved where each cell represents a potential feature in the volume data. This classification procedure is automatic and facilitates an arbitrary number and shape of features in the feature space. The opacity of each feature is determined by its persistence and size. To further incorporate the user's prior knowledge, a hierarchical feature representation is created by successive merging of the cells. With this representation, the user is allowed to merge or split features of interest and set opacity and color freely. Experiments on various volumetric data sets demonstrate the effectiveness and usefulness of our approach in transfer function generation.
[J].
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}