High Performance Computing Framework Software——SC_Tangram
Chi Xuebin1,2,*, Zhao Lian1,*, Wang Shanshan1,2, Zhang Jian1, Jiang Jinrong1通讯作者:
收稿日期:2019-08-15网络出版日期:2019-01-20
| 基金资助: |
Received:2019-08-15Online:2019-01-20
作者简介 About authors

迟学斌,1963年生,中国科学院计算机网络信息中心,研究员,博导,主要研究方向为高性能计算、并行计算。
本文承担工作为:框架的整体结构设计、研究指导。
Chi Xuebin, born in 1963, Computer Network Information Center of the Chinese Academy of Sciences, reasearch fellow, PhD supervisor. His main research interests are high performance computing and parallel computing.
In this paper he undertakes the following tasks: the design of overall paper structure and research guidance of the frame.E-mail: chi@sccas.cn

赵莲,1989年生,中国科学院计算机网络信息中心,助理研究员,博士,主要研究方向为高性能计算、并行计算。
本文承担工作为:框架代码实现,并行算法实现,力学应用测试。
Zhao Lian, born in 1989, Computer Network Information Center of Chinese Academy of Sciences,assistant research fellow, PhD. Her main research interests are high performance computing and parallel computing.
In this paper she undertakes the following tasks: code implementations of the whole framework, parallel algorithms and mechanical application testing.E-mail: zhaolian@sccas.cn

王姗姗,1995年生,中国科学院计算机网络信息中心,在读研究生,主要研究方向为高性能计算、相场模拟。
本文承担工作为:相场模拟程序在框架上实现,应用测试。
Wang Shanshan, born in 1995, Computer Network Information Center of Chinese Academy of Sciences,master student. Her main research interests are high performance computing and phase field simulation .
In this paper she undertakes the following tasks: code implementations of the phase field simulation and its testing.E-mail:wangshanshan@cnic.cn

张鉴,1972年生,中国科学院计算机网络信息中心,研究员,博导,主要研究方向为高性能计算、偏微分方程数值算法和并行算法研究。
本文承担工作为:相场模拟程序在框架上开发设计及指导。
Zhang Jian, born in 1972, Computer Network Information Center of Chinese Academy of Sciences,research fellow, PhD supervisor. His main research interests are high performance computing, numerical algorithms for partial differential equations and parallel computing.
In this paper he undertakes the following tasks: code design and execution director of the phase field simulation.E-mail:zhangjian@sccas.cn

姜金荣,1977年生,中国科学院计算机网络信息中心,研究员,主要研究方向为并行算法与框架软件、计算地球科学。
本文承担工作为:框架代码开发指导。
Jiang Jinrong, born in 1977, Computer Network Information Center of Chinese Academy of Sciences, research fellow. His main research interests are parallel computing algorithms and frameworks.
In this paper he undertakes the following tasks: code design and execution director of the whole framework.E-mail:jjr@sccas.cn

摘要
【目的】为降低并行编程难度,加速应用程序开发,本文设计并实现一种面向新型开发模式的并行框架软件——SC_Tangram,其中SC表示科学计算(Scientific Computing),Tangram(七巧板)寓意灵活组装。【方法】框架开发采用面向百亿亿次高性能计算的新型编程模型Charm++,为应用软件的并行扩展性和自适应性提供了保障。基于组件化软件开发方法,通过抽取应用中的共性部分,进行封装和隐藏,通过组件或配置文件接口的方式,供用户调用。【结果】针对现阶段的开发,框架已应用到力学计算、相场模拟等应用领域上,实验结果表明能得到较好的加速效果。【局限】目前框架软件上的功能模块还不全面,需针对不同应用需求开发相应的接口。【结论】SC_Tangram可以支持针对应用的共性和特性组件开发,随着在框架上开发更多的功能组件,未来将应用到更多的科学计算领域中。
关键词:
Abstract
[Objective]In order to reduce the difficulty of parallel programming and accelerate the development of application program , this paper designs and implements a parallel framework software, SC_Tangram, in which SC represents scientific computing and Tangram implies flexible assembly. [Methods]To guarantee the massively parallel scalability and adaptivity, the programming model Charm++ is adopted in the runtime system layer of the framework. By the method of component software development, SC_Tangram encapsulates and hides the common parts and can be invoked by users in term of component or configuration file interfaces. [Results]For the current development stage, the framework has been applied to mechanical calculation, phase field simulation and other applications. The experimental results show that it can perform more efficient computations. [Limitations]At present, the functional modules of the framework software are not comprehensive, so it is necessary to develop corresponding interfaces for different application requirements. [Conclusions]SC_Tangram can support the development of common and characteristic components for applications. With the development of more functional components in the framework, it will be applied to more fields of scientific computing in the future.
Keywords:
PDF (8526KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
迟学斌, 赵莲, 王姗姗, 张鉴, 姜金荣. 高性能计算框架软件——SC_Tangram. 数据与计算发展前沿[J], 2019, 1(1): 11-21 doi:10.11871/jfdc.issn.2096.742X.2019.01.003
Chi Xuebin.
引言
高性能计算是科学技术发展的重要工具,是世界各国争夺的战略制高点。日益增长的计算能力为解决复杂方程、模拟自然和人为的复杂处理以及可视化数据提供了前所未有的能力。为了降低科学家和工程师使用科学计算工具的难度,应对科学计算的新挑战,高性能编程框架是当前高性能计算学科的前沿研究方向之一。国内外已有很多对编程框架软件的研究工作。比如说在生物、大气海洋环境、物理、数值天气预报[1]、有限元计算等领域,都针对并行应用软件编程框架做了很多的探索研究。目前国内外比较知名的框架包括:(1)JASMIN(J Adaptive Structured Meshes applications INfrastructure)[2,21]是由北京应用物理与计算数学研究所研发的并行应用框架软件。基于C++和Fortran77语言开发,并采用MPI和OpenMP实现并行混合计算,提高性能。目前已广泛应用于流体力学、计算电磁学和粒子模拟等应用领域。
(2)FLASH[3,4],是由芝加哥大学的计算科学Flash中心研究和开发的一款模块化、可扩展的软件系统。Flash主要针对欧拉网格和拉格朗日粒子两类模拟,通过PYTHON脚本配置实现模块之间的交互、显式指明模块之间的访问权限以及继承关系,在多物理多尺度领域已经得到了广泛使用。
(3)Uintah[5,6],是基于AMR(自适应结构网格)上的偏微分方程求解开发的用于模拟和分析化学物理反应的软件库。是由犹他大学的火灾与爆炸模拟中心(Center for the Simulation of Accidental Fires and Explosions,C-SAFE)和科学计算与可视化研究所(Scientific Computing and Imaging Institute,SCI)共同完成研究和开发。 在该框架上使用有向无环图实现组件之间的依赖和通信关系,以提高并行可扩展性,在BG/Q超级计算机上扩展到500KCPU核心[6]。
(4)PHG[19,20],是中科院数学与系统科学研究院计算数学与科学工程计算研究所张林波老师带领的团队开发的三维自适应有限元并行程序开发设计平台。PHG的设计隐藏了并行处理的细节,对三维有限元程序实现有足够的灵活性。
SC_Tangram[12]是由中国科学院计算机网络信息中心开发的高性能计算框架软件。SC_Tangram基于Charm++[8,9,18]和Cactus[7]框架开发,通过组件化思想调用,并且拥有自动负载均衡、容错以及自动检查点的优点,可以大幅降低编程难度,加速应用的开发和移植。本文主要内容为通过组件化思想设计框架驱动组件、Flesh组件等基础组件构建SC_Tangram整体架构,通过抽取和封装应用共性实现共性组件以及面向领域的数据类型组件,通过调用CUDA、BLAS等外部库组件实现异构编程以及对于基础数值库的调用,目前SC_Tangram已经应用到力学计算以及相场模拟等应用领域。
1. SC_Tangram框架软件介绍
Cactus框架是由路易斯安娜州立大学(LSU)开发的,基于组件开发的软件思想和MPI通信实现,为多组件协作开发和跨平台并行应用设计提供的开发平台。Cactus框架组件具有即插即用的特点,即组件可以与其他组件一起编译和运行,并且组件可以在运行时按需组合而无需重新编译,根据应用程序的特点,通过组件列表文件指定组件实现程序。Cactus使用Cactus配置语言(Cactus Configuration Language,CCL)为组件的变量、参数和编译提供描述语言。配置完CCL文件后,框架通过CST(Cactus Specification Tool)工具解析每个组件内部的CCL文件,并处理组件关系,最终将各组件整合成完整的运行程序。Charm++是一个基于C++语言的并行编程系统,建立在可迁移对象编程模型上,具有动态负载均衡、容错、可迁移、过分解以及自动检查点等优点。不同于MPI编程模型,Charm++程序中没有处理器的概念,计算任务被分解成大量的对象,对象的数量与处理器数量无关。并且这些对象通过异步方式进行通信交互。这些特性使得Charm++的运行时系统RTS(Charm++ run time system)可以在一个处理器上放置多个chare对象,并且在程序运行期间改变它们的分布。应用程序逻辑和资源管理之间的分离是这种编程模型赋予应用程序开发人员的许多好处的核心。目前基于charm++开发的软件包有NAMD[14,15]、ChaNGa[16,17]等。
SC_Tangram框架设计自下而上为运行时系统层、共性算法层和应用层,见图1[14]。每一层都在下层的基础上进行抽象。运行时系统层包括多CPU节点、异构计算机等硬件系统以及相应的网络连接,运行时系统层主要为框架软件上开发的所有功能模块提供运行时自适应性支持。在其上面是共性算法层,主要是共性算法模块的开发,主要包括一系列面向领域的数据结构和通信关键字实现模块,通过组件化实现可供灵活调用。最上面层则是应用层,在开发应用时可以灵活调用共性算法层的组件也可以添加与应用相关的个性化组件,在建立应用组件时还应配置组件间交互的配置文件。此外,框架还自带多语言混合编译的编译系统以及自动代码生成[10,11]等高级接口翻译器。
图1
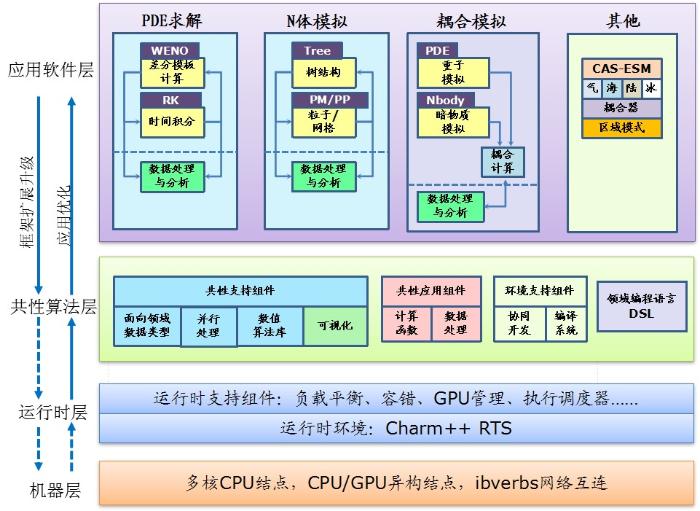 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1SC_Tangram框架图[12]
Fig.1SC_Tangram framework[12]
(1)运行时系统层。这一层直接作用的对象是Charm++并行对象chare,每个chare使用成员变量的方式携带部分计算数据。SC_Tangram利用chare的可迁移性、异步通信特性,为其开发的应用提供运行时自适应性支持。并且SC_Tangram直接针对每个chare私有的连续内存空间进行容错、负载均衡操作。此外,SC_Tangram提供执行流控制器,用于解决面向过程的执行流接口向消息驱动的运行时执行环境的转化问题。
(2)共性算法层。本层包括对应用的并行支持组件、应用算法组件以及编译环境组件。在共性算法层主要集成了部分具有共性的并行算法模块供应用软件层调用,对于应用软件层的调用可以屏蔽掉底层的并行代码实现,以组件的方式进行调用。在本层,同样也可把具有共性数据结构、通信等针对某一类算法的相关并行操作封装在特殊的数据类型。目前SC_Tangram中已经集成了针对模板计算的“GF”数据类型和针对粒子类计算的“GP”数据类型。SC_Tangram通过提供这种面向领域的数据类型为应用提供并行支持,实现此种数据类型的组件是并行驱动组件。在编译环境组件中,SC_Tangram的编译系统支持组件内多语言混合编程,如C/C++/Fortran/CUDA。
(3)应用层。用户根据应用程序结构选择性添加框架中已提供的组件以及共性算法层提供的特殊数据类型,利用通信关键字进行并行和自动通信,并加入自己的计算程序,最后组装成完整的应用程序。用户也可以按照框架组件体系的交互规则,开发新的组件,添加或删除框架本身提供的组件。
2. 框架组件设计
SC_Tangram基于Cactus框架组件化思想开发。其结构由被称为刺(thorn)的模块和核心代码肉(flesh)组成,flesh和thorn通过CCL(Cactus Configuration Language)配置文件(interface.ccl, param.ccl, schedule.ccl)进行连接.框架使用CST(Cactus Specification Tool)工具解析每个组件内部的CCL文件,来处理组件间的访问权限和继承关系。2.1 Flesh组件
SC_Tangram的核心组件是Flesh组件, Flesh组件是整个框架程序执行的入口,并行环境的初始化以及变量空间的申请均在Flesh组件中完成。框架的Flesh组件在启动框架软件时,会自动创建一个charm++的“main” 对象,而整个程序的入口便是“main”对象的构造函数。如图2是框架入口函数的执行流。入口函数的主要功能是完成其他对象的创建和初始化环境。运行框架程序时,仅有一个main对象的实例,SC_Tangram设计在main对象中将创建另外两种用于并行的类PeMgr类和ParGH类,分别是用来初始化每个处理器环境和用于并行计算。图 2
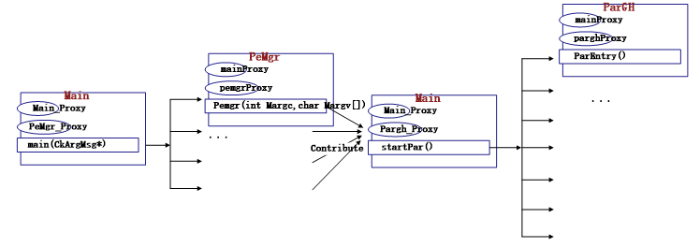 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 2框架入口函数执行流
Fig.2Framework entry function execution flow
PeMgr类需要完成每个处理器上框架计算环境的初始化。主要包括应用程序用到的组件的初始化和变量绑定以及确定函数模块的执行流。在编译程序时,PeMgr类首先通过活动组件列表获取真正参与计算的组件信息。在编译和执行时只编译和运行活动列表中的组件,根据不同的活动组件列表获得不同应用的计算结果,这种功能进一步突出了组件灵活插拔的特性,避免了对框架中所有的组件进行编译。PeMgr类通过用户编写的par.ccl和interface.ccl文件,获取变量、常量的绑定以及变量的空间申请。通过schedule.ccl中函数模块的调度信息(例如in,after,before等)确定函数模块的运行顺序。如图3所示。 ParGH对象的创建在Flesh组件中,但是ParGH对象的具体操作是并行驱动组件的一部分,将在并行驱动组件章节详细说明。
图 3
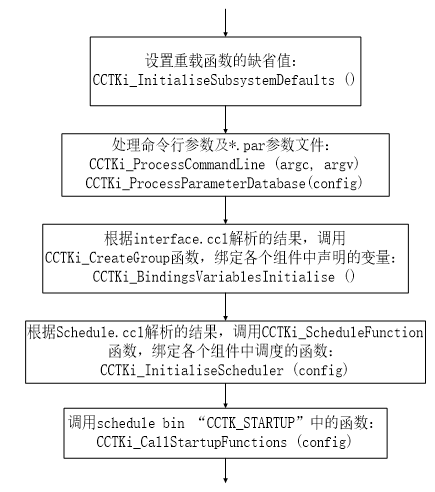 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 3框架计算环境的初始化流程
Fig.3Initialization process of framework computing environment
2.2 驱动组件
并行驱动driver组件,具体实现名叫PUGH,提供执行流控制器,是整个框架的并行支持。主要包括区域分解、通信关键字并行代码实现以及封装应用程序共性面向领域的数据结构。每个处理器的框架计算环境通过PeMgr类初始化完成后,就正式进入并行计算的主体部分。ParGH类的所有成员实现的第一个操作就是根据interface.ccl文件对所有变量进行区域分解以及ParGH并行对象中内存空间的申请。在区域分解和内存空间申请完成后,根据每个应用完成的不同操作开发相应的并行模块,在driver组件中,可以将并行模块封装成一个通信关键字,应用程序可以通过通信关键字实现对该并行程序的调用。目前在SC_Tangram中实现了两种面向领域的数据结构:结构均匀网格“GF”数据结构和粒子网格“GP”。在框架上开发应用程序,直接声明面向领域的数据类型变量组,能够极大地减少代码量。
2.2.1结构均匀网格“GF”数据结构
“GF”数据结构封装了针对模板计算的Stencil数据结构、区域分解以及通信方式。以最简单的Stencil计算三维7点Jacobi迭代为例。如图4,Jacobi迭代是用于求解线性方程的经典算法。
图4
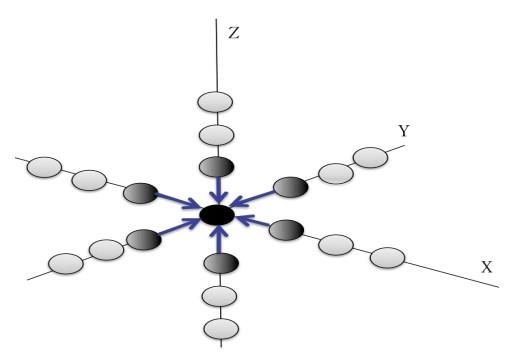 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4三维空间格点Stencil计算示意图
Fig.4Schematic diagram of three-dimensional space lattice calculation
图4代表三维空间进行网格剖分后的一部分格点,以位于正中的深黑色格点为中心,使用插值的方法近似表示中心格点的微分,进而求解整个偏微分方程。框架软件提供基于结构均匀网格的“GF”高级数据类型(图5)。声明“GF”类型的变量组的自定义参数包括:数据类型、维度dim、每个维度的总边长(格点数)size、每个维度的边界网格宽度ghostsize等。“GF”数据类型不但提供了数据结构的定义和相应数据空间的区域分解算法,还提供通信关键字“SYNC”,用于网格变量的边界通信操作。
图 5
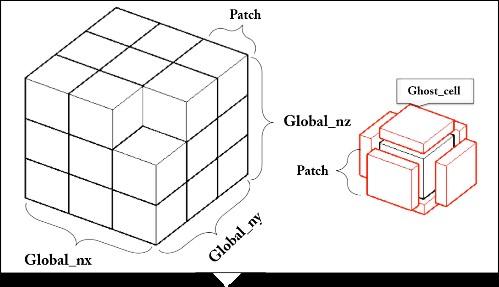 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 5“GF”区域分解示意图
Fig.5“GF”domain decomposition diagram
完成变量的定义、空间申请以及区域分解操作后,每个并行对象可以运行本地的计算程序。但是,在每次迭代计算开始前,邻居对象之间需要通信对计算结果进行更新并存储在ghostzones区域,如图6所示。所以在“GF”数据类型中封装了边界通信的操作关键字“SYNC”,“SYNC”关键字后追加变量组名,指定执行通信操作的变量。“SYNC”是调度块的一个内部属性,调度声明块的函数或组执行结束后,“SYNC”关键字启动相关变量的边界网格数据通信操作。
图6
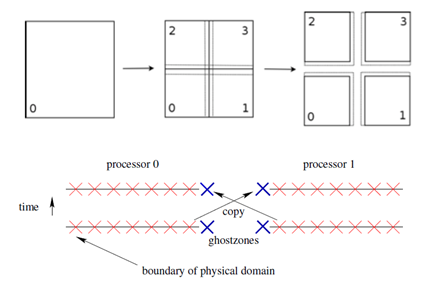 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6边界网格的数据交换示意图[7]
Fig.6Boundary grid data exchange diagram
“SYNC”通信主要包含边界网格数据的发送和接收两步操作。基于Charm++编程环境的通信操作具有异步性,发送方提前根据邻居对象的拓扑信息确定发送接收关系,根据通信关系向邻居对象发送自身的边界网格数据,不同于MPI中的阻塞式消息通信,每一个并行对象chare发出消息后直接返回继续执行函数中的剩余代码或结束退出。因此,在Charm++程序中,消息的发送和接收都不能在当前执行函数中显式等待,函数的调用执行反而依靠接收到的消息所驱动。
2.2.2 粒子网格“GP”数据结构
无论是对于大规模N体粒子系统的模拟或是N体粒子模拟与其他模拟的耦合,都需要用到PIC(Particles in Cell)模型,根据粒子和网格的位置关系,进行近似计算。因此,SC_Tangram中将算法的共性部分抽取为粒子网格的高级数据类型。
针对N体粒子系统的相关科学计算,框架软件提供基于粒子网格的“GP”高级数据类型(图7)。“GP”数据类型封装了N体数据结构、希尔伯特空间填充曲线(Hilbert space-filling curve)区域分解算法以及相关的通信关键字,如图7所示。“GP”类型声明变量的参数包括:粒子的总个数total_nparts、网格维度dim和各维度总长size,还有与粒子作用的网格最大距离pad。“GP”数据类型提供了两个通信关键字“FRONTIER”、“SHUFFLE”。“FRONTIER”封装了相关区域分解算法下的边界网格、边界粒子通信,“SHUFFLE”封装了粒子根据受力更新位置并迁移至新的并行对象的全局通信操作。
图 7
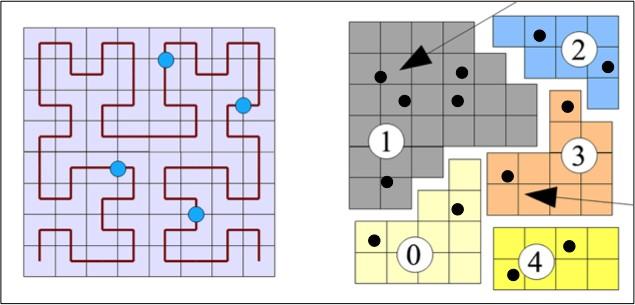 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 7面向应用的数据类型“GP”
Fig.7Application-oriented data types
在“GP”数据类型中,采用希尔伯特空间填充曲线作为区域分解的算法。该算法的主要思想是将每个网格计算出一个长整型的键值(key),按照键值进行排序,如图7所示,最后对一维空间的序列进行并行划分,保证每一段曲线内的粒子数均等,可以达到计算负载和内存占用量的均衡的目的。在并行代码实现中,由mainchair完成对采样信息的收集、排序以及分发。通过广播通信操作,mainchare告知每个对象区域分解的结果。每个对象再根据区域分解信息把在本地初始化的粒子发送给对应的对象,完成一次“SHUFFLE”通信。
2.2.3 共性通信关键字
在SC_Tangram框架软件中不仅仅针对应用问题实现了面向领域的数据结构,还针对不同应用的共性模块进行实现,封装为共性通信关键字,也集成在driver组件中。目前在SC_Tangram中实现了通用的规约MAX、收集、分发以及针对相场模拟程序的LEFTRIGHT、TOPBOTTOM、FRONTBACK三个关键字。针对力学应用,实现了数据分发、虚边界通信等模块。
2.3 外部链接库组件
在开发科学计算应用程序的过程中,为了提高性能和开发时间,往往需要调用一些外部函数库,例如BLAS、MKL库等。使用SC_Tangram框架软件,可以把外部函数库封装成可灵活插拔的组件,这个特殊的组件没有源代码,只需要配置框架中的configuration.ccl文件。如图8所示,以链接BLAS库为例,首先使用PROVIDES语句块导出组件的BLAS函数库功能,只有使用该语句,在应用程序内才能包含BLAS库的调用。内部属性包括执行脚本名configure.sh、脚本语言bash。在configure.sh脚本中主要配置函数库的路径、库目录及头文件目录。图 8
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图 8外部链接库配置文件示例
Fig.8Example of external link library configuration file
把外部链接库封装为组件,有如下优点:首先,只需在configure.sh中依次填写函数库的路径,编译过程则交由框架的编译系统和规则完成,框架自会解析ccl文件生成Makefile文件,而对于用户而言无需知道链接库的原理,如链接库的具体放置位置等。其次,外部链接库组件可以灵活插拔,被不同的应用程序所调用。
3 应用
本文所有的应用程序测试均在中科院计算机网络信息中心超级计算机”元”上进行了测试,节点配置如下:每个主机配置2 颗 Intel Xeon E5-2680 v3 12核处理器, 主频为2.8GHz,网络采用Mellanox EDR Inifiniband。
编译环境为Intel Composer XE 2013编译器、Charm++版本为6.6.1,Charm++安装命令为./build charm++ net-linux-x86_64 ibverbs ifort icc --with-production。
3.1 力学应用
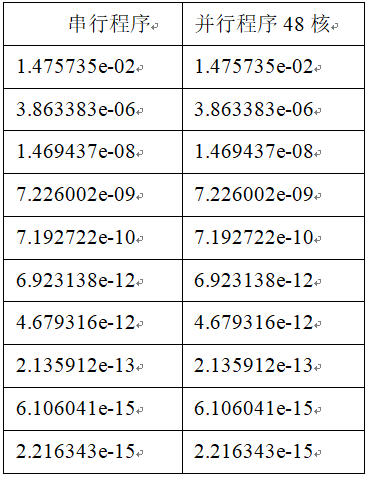
在SC_Tangram上主要针对力学软件CDEM[22]的材料连续变形的模拟过程进行实现,并进行测试。CDEM的材料连续变形模拟过程主要针对非结构网格进行计算。在框架软件SC_Tangram上开发程序时,主要剥离计算和通信模块,通信模块封装在框架的driver组件内。网格的划分调用metis软件包,将metis软件包封装到SC_Tangram中的外部链接库组件中,可以供不同的用户调用。首先通过12545网格算例验证程序的正确性,图9为在单核和48核心下程序输出的能量值。
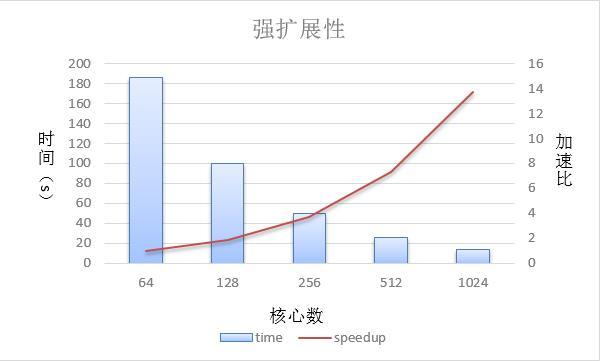
本测试固定网格点的规模为13720987,迭代步数为10000步。图10为从64核心到1024核心的强扩展测试,横坐标表示核心数,左侧纵坐标表示运行时间,右侧纵坐标表示加速比。核心数为1024时,相对于64核心达到13.72倍加速比,达到86%的并行效率。
图9
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图9串并行程序能量值
Fig.9Energy value of series-parallel programs
图10
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图10测试结果
Fig.10Test result
3.2 相场模拟
在SC_Tangram上开发相场模拟软件,主要针对Cahn-Hilliard方程进行求解,Cahn-Hilliard方程算例如下,计算区域为三维空间$\Omega ={{[0,0.5\pi ]}^{3}}$。在SC_Tangram上新建应用组件ScLETD[23],调用基础组件有PUGH、CharmppFT、GPart,此外,还用到了外部库组件BLAS。框架提供的配置文件对源码有辅助作用,configuration.ccl用于填写外部库的调用,interface.ccl用于填写全局变量,param.ccl用于填写常量参数,schedule.ccl用于填写程序执行流控制。
通信在PUGH中具体实现。每次数据交换涉及子区域和邻居的前后、左右、上下三种通信,因此在PUGH中扩展LEFTRIGHT、TOPBOTTOM、FRONTBACK三个关键字。通信前将待通信的数据拷贝到缓冲区中,对缓冲区的数据进行发送和接收。
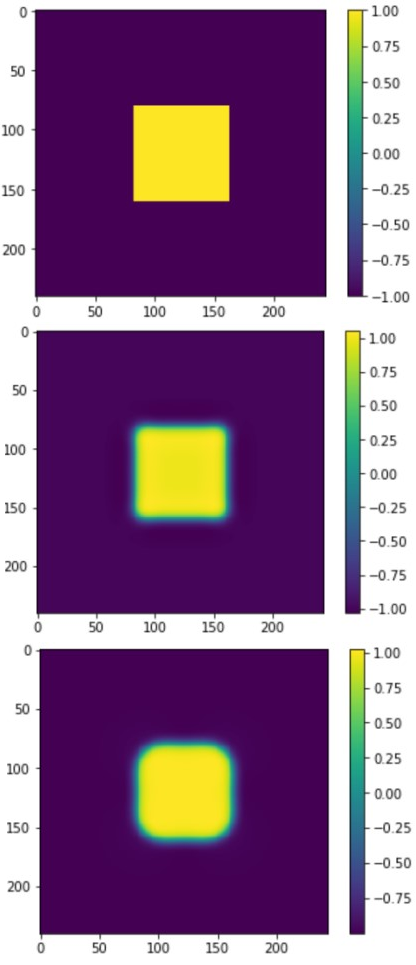
该方程主要是对从方形到圆形的演化过程进行模拟。以每个子区域上的网格数为nx*ny*nz = 64*64*64为例,在64个核心上进行子区域划分,网格宽度$h=6.135{{e}^{-3}}$,模型参数$\varepsilon =\sqrt{\beta }=0.02\approx 3\text{h}$.设T=0.0128,时间步长为$\Delta \text{t}=2{{e}^{-6}}$到1.28e-4,用更小的时间步$\Delta \text{t}=4{{e}^{-7}}$作为基准解。图11为演化过程截面图,从上到下依次为基准解初值、重启初值、模拟结束时刻。第一张图是基准解(时间步长为dt=4e-7)在t=0时刻的初值,此时从一个相到另一个相的过渡是尖锐的,当基准解演化一段时间以后,从一个相到另一个相的过渡达到相对平缓,也就是第二张图的时刻,将该时刻的场变量值作为较大时间步长dt=4e-6的模拟的场变量初值,第三张图是时间步长为dt=4e-6的模拟结束时刻T=0.0128的场变量的值。从计算结果演化过程验证了一个从方形变圆形的演化过程,也验证了程序计算的正确性。
图11
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图11演化过程截面图
Fig.11Section diagram of evolution process
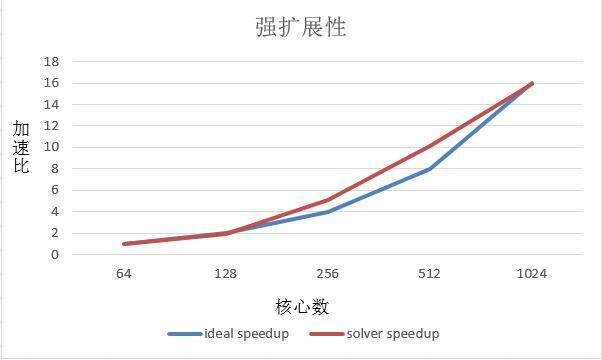
强扩展性测试,固定测试规模为33554432网格数,迭代步数为100步。测试核心数由64到到1024核心。图12为强扩展性能测试。在核心数达到1024时,得到15.93的加速比。
图12
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图12测试结果
Fig.12Test result
4. 结论与展望
本文介绍了由中科院计算机网络信息中心开发的高性能框架软件SC_Tangram。首先SC_Tangram采用面向百亿亿次高性能计算的新型编程模型Charm++ 作为框架的运行时系统层,具有可迁移、动态负载均衡和运行时容错功能等特点。基于Cactus框架组件化思想开发框架的核心并行驱动。主要包括面向领域的数据结构、通信关键字的开发,用于隐藏底层并行技术,加速开发。目前SC_Tangram已经应用到多领域,并得到了很好的测试结果。目前框架软件上的功能模块还不全面,需针对不同应用需求开发相应的接口。SC_Tangram可以支持针对应用的共性和特性组件开发,随着在框架上开发更多的功能组件,未来将应用到更多的科学计算领域中。利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[本文引用: 1]
[本文引用: 1]
URL [本文引用: 1]
35(
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
URL [本文引用: 2]
[J].
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
DOI:10.3233/SPR-2011-0333Magsci [本文引用: 1]

With the recent advent of new heterogeneous computing architectures there is still a lack of parallel problem solving environments that can help scientists to use easily and efficiently hybrid supercomputers. Many scientific simulations that use structured grids to solve partial differential equations in fact rely on stencil computations. Stencil computations have become crucial in solving many challenging problems in various domains, e. g., engineering or physics. Although many parallel stencil computing approaches have been proposed, in most cases they solve only particular problems. As a result, scientists are struggling when it comes to the subject of implementing a new stencil-based simulation, especially on high performance hybrid supercomputers. In response to the presented need we extend our previous work on a parallel programming framework for CUDA - CaCUDA that now supports OpenCL. We present CaKernel - a tool that simplifies the development of parallel scientific applications on hybrid systems. CaKernel is built on the highly scalable and portable Cactus framework. In the CaKernel framework, Cactus manages the inter-process communication via MPI while CaKernel manages the code running on Graphics Processing Units (GPUs) and interactions between them. As a non-trivial test case we have developed a 3D CFD code to demonstrate the performance and scalability of the automatically generated code.
[D].
[本文引用: 3]
[J].
[本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
Magsci [本文引用: 1]
地震力作为一种动态载荷,其作用是导致顺层结构面黏聚力及抗拉强度的丧失。由此,提出了一种动力分析法(数值分析法)与极限平衡法(公式法)相结合的顺层岩质边坡地震稳定性评价方法。该方法利用基于连续介质力学的离散元方法( CDEM )获取震后结构面处的残余强度,将残余强度代人极限平衡公式求解重力作用下的安全系数,并将此安全系数作为评价顺层岩质边坡地震稳定性的指标。分析结果表明,传统拟静力法用于顺层岩质边坡地震稳定性的评价是不适宜的,通过本文方法获得的顺层边坡动力安全系数具有明显的 3 阶段特征(水平段–速降段–水平段),而拟静力法获得的安全系数随着设防烈度的增大却呈现出逐渐减小的特征。此外,所述方法还可体现地震波频率对顺层岩质边坡稳定性的影响。
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}