摘要: 链接预测问题是复杂网络分析领域的重要问题. 现有链接预测方法大多针对静态网络, 忽视了动态信息在网络中的传播. 为此, 针对动态网络中的链接预测问题, 本文提出了一种基于动态网络表示的链接预测(dynamic network representation based link prediction, DNRLP)模型. 该模型对网络中不均匀的动态信息进行了学习, 提出了基于连接强度的随机游走算法来模拟动态信息在网络中的扩散, 从而得到新时刻下的节点表示, 然后通过度量节点表示之间的相似度进行链接预测. 实验使用平均交互排序(mean reciprocal rank, MRR)和召回率(
Recall @
k )指标在四个公开动态网络数据集上进行实验, 结果显示DNRLP模型的MRR指标较对比模型平均提高了30.8%. 实验结果表明DNRLP模型不仅学习了网络中的动态信息, 还考虑了其对邻居节点的影响以及时间间隔对信息更新的影响, 得到了更为丰富的节点表示, 对于链接预测任务具有明显优势.
关键词: 链接预测 /
动态网络 /
表示学习 /
随机游走 English Abstract Link prediction model based on dynamic network representation Han Zhong-Ming 1,2 ,Li Sheng-Nan 1 ,Zheng Chen-Ye 1 ,Duan Da-Gao 1 ,Yang Wei-Jie 1 1.College of Computer and Information Engineering, Beijing Technology and Business University, Beijing 100048, China Fund Project: Project supported by the Natural Science Foundation of Beijing, China (Grant No. 4172016) and the General Project of Beijing Philosophy and Social Science Foundation (Grant No. 14ZHB006)Received Date: 29 July 2019Accepted Date: 07 May 2020Available Online: 25 May 2020Published Online: 20 August 2020Abstract: Link prediction is an important issue in network analysis tasks, which aims at detecting missing, spurious or evolving links in a network, based on the topology information of the network and/or the attributes of the nodes. It has been applied to many real-world applications, such as information integration, social network analysis, recommendation systems, and bioinformatics. Existing link prediction methods focus on static networks and ignore the transmission of dynamic information in the network. However, many graphs in practical applications are dynamic and evolve constantly over time. How to capture time information in a dynamic network and improve the accuracy of link prediction remains a conspicuous challenge. To tackle these challenges, we propose a dynamic network representation based link prediction model, named DNRLP. DNRLP can be mainly divided into two modules: a representation learning module on dynamic network and a link prediction module, where the representation learning module is composed of a node information dynamic update unit and a node neighborhood update unit. Node information dynamic update unit leverages the benefits of the long short-term memory (LSTM) in capturing time information and uses a Time Interval based Filter Unit (TIFU) to introduce time interval information between two links, while for the node neighborhood update unit we present a random walk algorithm based on connection strength to simulate the diffusion of dynamic information. Through the above two parts, the model can obtain the node representation at the new moment, then link prediction is performed by the link prediction module by measuring the similarity between the node representations. The experiment uses MRR and Recall @k indicators to evaluate performance of model on four public dynamic network datasets. The experiments demonstrate the effectiveness and the credibility of the proposed model in link prediction tasks as compared with the comparison models, the MNR index of the DNRLP is increased by 30.8%. The model proposed in this paper not only learns the dynamic information in the network, but also considers its influence on neighbors and the impact of time interval on information update. Therefore, the model has learned more abundant dynamic information and has obvious advantages for link prediction tasks.Keywords: link prediction /dynamic network /representation learning /random walk 全文HTML --> --> --> 1.引 言 在现实世界中, 很多复杂系统以复杂网络的形式出现, 如社会网络、引文网络、生物网络和web网络等. 网络提供了一种组织现实世界中的多样化信息的方式, 成为人们工作生活中不可或缺的一部分, 对这些网络进行分析研究具有非常大的学术价值和潜在应用价值[1 ] . 在这些网络中, 节点之间的交互行为通常以“链接”的形式表示, 即使用边将两个节点连接. 以社交网络为例, 网络节点用于描述用户, 边用于描述用户之间的交互行为. 链接预测[2 ] 通过分析网络中的信息来预测未来网络中任意两个节点之间是否可能出现链接. 有效的链接预测对人们生活中各个方面都具有重要意义, 例如帮助人们控制信息在网络上的传播, 帮助社交平台进行更准确的好友推荐等.图1 展示了一个动态网络示意图, 假设在对网络进行链接预测任务时, 以节点共同邻居个数度量节点相似性, 相似度越大的节点对在下一时刻发生链接的可能性越大. 在T1时刻, 网络中的节点2和节点5拥有一个共同邻居(节点4), 在T2时刻, 该网络在节点3和节点5之间新增了一条边, 即节点3变成了节点5 的邻居. 此时节点2和节点5拥有两个共同邻居(节点4和节点3), 它们在下一时刻产生链接的可能性变大. 由此可见, 虽然新增加的边只涉及到节点3和节点5, 但其邻域中的节点2的属性也受到了影响. 因此, 网络动态演化对节点及其邻域的特征信息有着非常重要的影响, 在链接预测过程中加入动态信息将会提高链接预测的性能.图 1 动态网络示意图Figure1. Schematic diagram of dynamic network.2.相关研究 22.1.链接预测 2.1.链接预测 现有的链接预测研究方法主要分为两类, 基于网络拓扑结构特征分析的方法和基于机器学习的方法. 传统的链接预测方法主要是通过对网络拓扑结构进行特征分析, 计算节点之间的相似度, 认为相似度高的节点在将来会发生链接. Newman等[3 ] 首先提出基于网络共同邻居的节点相似度计算方法, 即节点拥有的共同邻居越多, 越可能在未来发生链接. Adamic等[4 ] 提出了一种新的网络节点相似性度量方法, 该方法根据共同邻居节点的链接情况为每个邻居节点设置权重, 并使用其加权和作为节点对的相似度. Fouss等[5 ] 通过随机游走算法对网络中节点的邻域信息进行采样, 得到目标节点的随机游走序列, 然后计算节点随机游走序列的相似性进行链接预测.[6 ] 将链接预测问题转化为机器学习中的二分类问题, 尝试使用支持向量机[7 ] , 多层感知机等机器学习方法进行链接预测, 若两节点间未来可能产生链接则预测值为1, 否则为0. Freno等[8 ] 使用自然语言处理领域的词袋模型对论文引用网络中论文的摘要进行建模, 得到论文节点的特征表示, 然后使用神经网络进行链接预测. Hosein等[9 ] 针对引文网络使用论文作者和论文的互聚类方法进行链接预测. Xu等[10 ] 将信息熵应用于加权网络中的链接预测, 提出基于路径贡献的加权相似度指标, 实现了加权网络的链接预测. Lai等[11 ] 针对复杂网络, 用模块化的置信度传播算法来获得网络的底层块结构, 并通过块结构信息对节点间产生链接的可能性进行建模, 从而实现链接预测. Kovács等[12 ] 针对蛋白质相互作用网络, 根据蛋白质之间的交互特性, 使用长度为3的网络路径(L3)进行链接预测. Pech等[13 ] 提出了一种新的链接方法, 由节点邻居贡献率的线性和来估计链接的可能性, 从而将链接预测问题转化为似然矩阵的优化问题. Zhang等[14 ] 认为现有的相似性度量方法往往只适用于某几种网络, 为此提出了一种γ -衰减理论来统一现有的相似性度量方法, 同时还提出了一种基于图神经网络(graph neural network, GNN)[15 ] 的链接预测框架SEAL, 从网络中的局部子图来学习节点表示以进行链接预测. 以上方法大多是针对特定网络提出了新的相似性度量方法. 除此之外, Ostapuk等[16 ] 首次将深度主动学习[17 ] 应用于链接预测, 基于贝叶斯深度学习[18 ] 提出了一种深度主动学习框架ActiveLink, 将不确定性采样引入到聚类算法中, 并且采用基于元学习[19 ] 的无偏增量的方法进行训练, 提高了模型的训练速率. 相较于传统的基于网络结构相似度的链接预测方法而言, 有监督的机器学习模型使链接预测的结果有了明显提升.2.2.动态网络表示学习 -->2.2.动态网络表示学习 由于复杂网络通常包含数十亿的节点和边, 且数据具有稀疏性, 在网络上很难直接进行复杂的推理过程, 为了有效地进行复杂网络分析, ****们提出了各种各样的网络表示学习[20 ] 方法. 网络表示学习作为网络分析领域的一个重要基础问题, 其核心思想是寻找一个映射函数将网络中的节点转化成低维稠密的实数向量, 即网络节点表示. 这些网络节点表示保存了网络中所包含的信息, 为网络分析任务提供了良好的特征基础, 并可以直接用于各种网络分析任务中, 如链接预测, 社团检验, 推荐系统等. 网络表示学习的形式化定义如下:$ G=(V, E) $ , 使用映射函数$ {f}_{v}\to {\tau }^{k} $ 为网络中的每个节点$ v\in V $ 学习到一个低维稠密的实数向量$ {{R}}_{v}\in {\mathbb{R}}^{k} $ 作为节点的表示向量, 该向量的维度$ k $ 远远小于网络节点的总个数$ \left|V\right| $ .[21 ] , LINE[22 ] , node2vec[23 ] , SDNE[24 ] , GCN[25 ] , GraphSAGE[26 ] 等.[27 ] 基于复杂网络动力学以及多元微分方程定义节点在不同时刻的表示, 提出了一种复杂网络的多尺度动态嵌入技术. Kumar等[28 ] 基于递归神经网络提出了JODIE模型, 对网络中的用户和项目分别进行动态表示学习, 并提出了一种并行批处理算法t-Batch. 李志宇等[29 ] 通过对不同阶层的网络节点关系进行正负阻尼采样, 构建针对新增节点的动态特征学习方法, 使得模型可以提取大规模社会网络在动态变化过程中的结构特征. Palash等[30 ] 基于深度自编码器提出DynGEM模型, 该模型可以动态学习网络中高度非线性的表示. 同时很多****针对动态网络表示学习中的链接预测任务进行了相关研究. Chen等[31 ] 将长短期记忆网络[32 ] (LSTM)与编码器-解码器体系结构相结合, 提出了一种新颖的encoder-LSTM-decoder(E-LSTM-D)深度学习模型来预测动态链接. Li等[33 ] 基于SDNE算法提出了DDNE模型, 使用门控循环单元[34 ] (GRU)作为编码器来捕获动态网络中的时间信息, 从而在动态网络中进行链接预测. Lei等[35 ] 结合了图卷积网络(graph convolutional network, GCN)、长短期记忆网络(long short-term memory, LSTM)以及生成对抗网络[36 ] (generative adversarial networks, GAN)的优势, 用深度神经网络(即GCN和LSTM)来探索网络中隐藏的拓扑结构和演化模式的非线性特征, 用GAN来解决动态网络中链接的稀疏性问题, 同时通过对抗的方式在动态网络中进行链接预测. 这些研究方法大多只考虑了发生变化的节点本身的信息变化情况, 而没有关注节点邻域所受到的影响. 并且现有方法大多仅考虑了均匀间隔的时间间隔, 而忽视了不同时间间隔对节点偏好信息的影响. 由于网络表示学习是网络分析的基础任务, 如何设计具有动态适应性的网络表示学习模型, 学习网络节点及其邻域的信息变化并对它们的表示进行快速更新, 对现实世界中的网络分析任务有着至关重要的作用.3.基于动态网络表示的链接预测模型 本文针对动态网络的链接预测问题提出了基于动态网络表示的链接预测模型DNRLP. 该模型对LSTM进行了改进, 考虑了网络演化过程中产生新信息的非平均时间间隔问题以及新信息的扩散问题, 有效地捕获和学习了网络中的动态信息, 并得到了含有节点偏好信息的节点表示. 然后通过计算习得节点表示之间的相似度, 最终得到链接预测的结果.图2 给出DNRLP模型的结构示意图, DNRLP模型主要分为两个模块: 动态网络表示学习模块和链接预测模块, 其中动态网络表示学习模块由节点信息动态更新单元和节点邻域更新单元组成. DNRLP模型根据$ {T}_{i } $ 时刻网络中出现的新增信息, 得到与其直接关联的节点集合, 使用节点信息动态更新单元对该集合内的节点进行节点表示更新. 然后对该集合内的节点进行邻域采样, 得到与新增信息间接关联的节点集合, 使用节点邻域更新单元对邻域节点进行更新, 最终得到当前时刻更新后的网络节点表示. 基于这些节点表示使用链接预测模块计算节点间的相似度并进行排序, 最终得到链接预测的结果.图 2 基于动态网络表示的链接预测模型结构Figure2. The architecture of link prediction model based on dynamic network representation.3.1.节点信息动态更新 3.1.节点信息动态更新 随时间动态演化的网络可以看作不同时刻下的静态网络, 使用$ G({V}^{t}, {E}^{t}, t) $ 表示$ t $ 时刻的网络, 其中$ {V}^{t} $ 为该时刻的节点集合, $ {E}^{t} $ 为该时刻的边集合, $ t $ 为对应的时间戳. 随着时间的推移, 网络中的节点会不断地与网络中的其他节点建立新链接, 这些新链接会改变当前节点的属性信息. 例如在社交网络中, 如果两个用户有联系, 他们会逐渐分享共同的兴趣爱好. 新链接的建立顺序以及它们建立的时间间隔对节点属性特征的变化也有着非常重要的影响. 按照时间戳对节点$ v $ 新产生的链接进行排序得到链接序列$ {S}_{v}=\{\left(v, {v}_{i}, {t}_{0}\right), \left(v, {v}_{i}, {t}_{1}\right), \dots, (v, {v}_{i}, {t}_{n}\left)\right\} $ , 其中$ (v, {v}_{i}, t) $ 表示$ t $ 时刻节点$ v $ 与节点$ {v}_{i} $ 之间新建立的链接, $ {v}_{i}\in {N}_{v} $ 表示节点$ v $ 的一阶邻域节点, $ {N}_{v} $ 表示节点$ v $ 的一阶邻域节点集合; $ t $ 表示链接建立的时间戳, $ {t}_{0}<{t}_{1}<\dots <{t}_{n} $ . 在链接序列$ {S}_{v} $ 中, 链接建立的时间$ t $ 越晚, 链接的排序越靠后, 则对节点$ v $ 属性变化的影响越大. 新链接之间的时间间隔$ \Delta t $ 即链接序列$ {S}_{v} $ 里两个相邻新链接($ \left(v, {v}_{i}, t-{x}\right){\text{与}}\left(v, {v}_{i}, t\right) $ )之间的时间戳之差的绝对值, $ \Delta t=\left|t-(t-{x})\right| $ . 其形式化定义如下: 给定一个链接序列$ {S}_{v}=\left\{\right(v, {v}_{i}, {t}_{0}), (v, {v}_{i}, {t}_{1}), \dots, (v, {v}_{i}, {t}_{n}\left)\right\} $ , 新链接之间的时间间隔$ \Delta t $ 定义为: 在链接序列$ {S}_{v} $ 中, 链接$ \left(v, {v}_{i}, t-x\right) $ 建立的时间戳$ t-x $ 与其后一个链接$ \left(v, {v}_{i}, t\right) $ 建立的时间戳$ t $ 的差的绝对值$ \left|t-(t-x)\right| $ , 即$ \Delta t=\left|t-(t-x)\right| $ . 时间间隔$ \Delta t $ 的值越大则次序较后的链接对节点属性变化的影响越大. 如在社交网络中, 用户的新增关注可能呈现了该用户最新的偏好, 而时间较久远的关注对用户产生的影响会随着时间的推移不断减小. 因此, 节点建立的两个链接之间的时间间隔将会影响节点表示向量的更新策略. 如果节点两次建立链接之间的时间间隔较大, 那么模型应更关注新链接所带来的信息, 而对时间较久远的信息进行遗忘.图3 所示.图 3 基于时间间隔的LSTM单元Figure3. Time interval based LSTM unit.图3 左半部分描述了TIFU的示意图. TIFU的工作原理是根据时间间隔$\Delta {{t}}$ 的大小, 决定当前细胞状态信息$ {{C}}_{t-1} $ 传递到下一时刻t 的信息$ {{C}}_{t-1}^{*} $ . $ {{C}}_{t-1}^{*} $ 的具体计算过程如下所示:$ t-1 $ 标准LSTM计算单元输出的细胞状态$ {{C}}_{t-1} $ 分成了两个部分: 短期记忆$ {{C}}_{t-1}^{L} $ 和长期记忆$ {{C}}_{t-1}^{ T} $ . 我们认为细胞状态$ {{C}}_{t-1} $ 是由长期记忆和短期记忆两个部分构成的, 短期记忆对信息的存储时间较短, 容易被遗忘, 而长期记忆对信息的存储时间较长, 不容易被遗忘. 同时短期记忆与长期记忆并不是完全割裂的, 通过重复、巩固短期记忆可以转化为长期记忆, 即随着时间的流逝, 部分短期记忆可以演变为长期记忆. (1 )式使用神经网络和tanh激活函数自动选择历史信息中较为短暂的历史信息, 即单元的短期记忆, 其中$ {{C}}_{t-1}^{L} $ 为根据$ t-1 $ 时刻的细胞状态生成的短期记忆. (2 )式中$ {{C}}_{t-1}^{ T} $ 为相应的需要传递给下一时刻$ t $ 的长期记忆. TIFU根据时间间隔$ \Delta t $ 对单元短期记忆$ {{C}}_{t-1}^{L} $ 的部分信息进行丢弃, 如(3 )式所示, 其中$ {\widehat{{C}}}_{t-1}^{L} $ 为保留下来的短期记忆信息, $ \Delta t $ 越大丢弃的短期记忆信息越多. 经过上述计算, 完成对节点历史信息保留的决策, 并得到需要传递给下一时刻t 的历史信息, 如(4 )式所示, $ {{C}}_{t-1}^{*} $ 将$ {{C}}_{t-1}^{T} $ 和$ {\widehat{{C}}}_{t-1}^{L} $ 进行组合, 并作为下一时刻$ t $ 标准LSTM单元的输入, 即最终传递给下一时刻t 的节点历史信息是由节点的部分短期记忆与全部长期记忆所组成的.图3 中右半部分为标准LSTM计算单元示意图, 其具体计算过程如下所示:$ {{x}}_{t} $ 为当前时刻$ t $ 的输入向量, 表示网络的新增信息. 由于新增信息由节点$ {v}_{i} $ , $ {v}_{j} $ 之间的新增链接产生, 因此可以通过计算两节点当前表示的加权和来得到$ {{x}}_{t} $ , 计算方式如(5 )式所示. 接下来分别对标准LSTM单元的输入门、遗忘门及输出门进行计算, 其中$ {\rm{\sigma}} $ 表示sigmoid激活函数, $ \odot $ 表示矩阵乘积运算, $ {{i}}_{t} $ , $ {{f}}_{t} $ , $ {{o}}_{t} $ 分别代表$ t $ 时刻LSTM单元输入门、遗忘门以及输出门的系数. $ \{{{W}}_{i}, {{U}}_{i}, {{b}}_{i}\} $ , $ \{{{W}}_{f}, {{U}}_{f}, {{b}}_{f}\} $ 和$ \{{{W}}_{o}, {{U}}_{o}, {{b}}_{o}\} $ 分为上述三种门的网络参数. $ {\tilde{{c}}}_{t} $ 表示用于更新细胞状态$ {{c}}_{t} $ 的候选状态. $ \{{{W}}_{c}, {{U}}_{c}, {{b}}_{c}\} $ 是网络产生候选记忆的参数. $ {{h}}_{t} $ 是在时刻$ t $ 时经过上述三种门的过滤后的隐藏状态, 该状态记录了$ t $ 时刻之前习得的所有有用信息. $ {{c}}_{t} $ 经过输出门舍弃掉部分信息后形成当前时刻$ t $ 的输出向量$ {{h}}_{t} $ . 根据上述TIFU和标准LSTM计算单元的计算过程, 可将上述过程进行如下表示:$ f $ 对关系两端的节点信息(节点表示)进行更新, 其中$ {{C}}_{t-1} $ , $ {{h}}_{t-1} $ 为上一时刻$ f $ 计算得到的细胞状态和隐藏状态, $ {{x}}_{t}={{W}}_{1}{{u}}_{{v}_{i}}+{{W}}_{2}{{u}}_{{v}_{j}}+{b} $ 是网络新增关系为涉及到的两个节点$ {{v}}_{i} $ 和$ {{v}}_{j} $ 带来的新信息, $ {{W}}_{1} $ , $ {{W}}_{2} $ , $ {b} $ 是生成新信息的表示向量的模型参数. $ {{h}}_{t} $ 即为目标节点更新后的表示向量.$ f $ 的初始化的节点表示.3.2.节点信息扩散算法和更新 -->3.2.节点信息扩散算法和更新 网络中两节点$ {v}_{i} $ , $ {v}_{j} $ 之间的新增链接不仅会对链接两端的节点产生影响, 同时也会影响与$ {v}_{i} $ , $ {v}_{j} $ 距离较近的节点. 因此当网络产生新链接时, 涉及到的两个节点$ {v}_{i} $ , $ {v}_{j} $ 的邻域节点也应该进行信息更新. 为此, DNRLP模型通过对产生新链接的节点进行邻域采样来模拟新信息在网络中的扩散过程, 然后对采样到的邻域节点进行信息更新. 这么做的原因主要有三个方面: 第一, 文献[37 ]表明新链接对整个网络的影响往往是局部的. 第二, 由于网络的复杂性, 与新链接直接关联的节点不一定会将收集到的新信息传播给其所有的邻居, 同时新信息很有可能会被传播到与其较近但不直接相邻的节点. 第三, 通过实验发现, 当对目标节点的局部邻域进行信息更新时, 模型的性能会更好.$ {v}_{i} $ , $ {v}_{j} $ 的局部邻域. 其中边权重的计算过程如下:$ {{u}}_{v} $ 为节点$ v $ 的表示向量, $ {N}_{v} $ 表示节点$ v $ 的一阶邻居节点集合, $ {f}_{\rm{s}}\left({{u}}_{{v}_{i}}, {{u}}_{v}\right) $ 表示节点$ v $ 和其邻域节点$ {v}_{i} $ 间的连接强度, 可以将该连接强度看作一个归一化后的概率值, 根据该概率值来选择目标节点信息在下一时刻要扩散到的节点. 图4 给出一个简单网络实例, 图中实线代表历史链接, 虚线代表当前时刻新产生的链接. 分别对网络中新链接两端的节点$ {v}_{4} $ , $ {v}_{5} $ 进行随机游走. 以节点$ {v}_{5} $ 的随机游走邻域采样为例, 其具体的随机游走采样策略如下:图 4 节点邻域采样示意图Figure4. Schematic diagram of node neighborhood sampling.$ {R}_{{v}_{5}}=\left\{\right\} $ .$ {v}_{1} $ , 并将该节点加入$ {R}_{{v}_{5}} $ 中.$ {v}_{1} $ 是否有一阶邻居, 或者其一阶邻居是否全部在$ {R}_{{v}_{5}} $ 中, 是则退回到上一时刻的节点重复此步骤, 否则进入下一步.$ {v}_{2} $ 下一刻游走选择节点$ {v}_{5} $ , 则退回到节点$ {v}_{2} $ 重新进行决策.表1 给出了扩散算法的伪代码. 在表1 中, $ {E}_{{\rm{new}}} $ 代表新增链接的集合; $ v $ 代表与新增链接相关联的一个节点; $ m $ 代表随机游走了的长度; $ L $ 是给定的随机游走序列的最大长度; $ P $ 表示边权重概率分布; $ u $ 代表节点$ v $ 的一阶邻居; $ {R}_{v} $ 代表节点$ v $ 的随机游走结果集合; $ R $ 代表所有节点的随机游走结果集合. 步骤6—8实现节点间边权重的计算. 步骤9实现相关节点的邻域采样. 步骤4—12实现基于连接强度的随机游走算法, 找到了相关节点的局部邻域$ {R}_{v} $ , 其中$ {R}_{v} $ 是一个有序的随机游走序列, 越靠前的节点越容易从相关节点到达, 即相关节点的信息更容易扩散到序列中排位靠前的节点上去, 刻画出了相关节点信息的扩散过程. 整个算法得到了与新增信息直接相关的节点的随机游走序列$ {R}_{v} $ 的集合$ R $ , 描绘出了整个网络中新增信息的扩散过程.输入: 新增链接$ {e}_{ij}\in {E}_{{\rm{new}}} $, 随机游走长度$ L $ 输出: 随机游走序列$ R $ 1) For $ {e}_{ij} $ in $ {E}_{{\rm{new}}} $ do: 2) For $ v $ in $ {e}_{ij} $ do: 3) $ m=\mathrm{ }0 $ 4) While $ m < L $ do 5) 初始化权重分布$ P $ 6) For $ u $ in $ {N}_{v} $ do 7) 根据(13 )式计算$ {f}_{\rm{s}}\left({u}_{\rm{u}}, {u}_{v}\right) $, 加入$ P $ 8) End for 9) 根据$ P $选择下一个节点$u^\prime$加入${R}_{v}$ 10) $ m=m+1 $ 11) $ v=u' $ 12) End while 13) 将$ {R}_{v} $加入$ R $ 14) End for 15) End for
表1 信息扩散算法Table1. Information diffusion algorithm.$ {v}_{i} $ 的随机游走序列进行信息更新, 更新过程如下:$ v\in {R}_{v} $ , $ {ind}_{v} $ 为节点$ v $ 在$ {R}_{v} $ 中的索引号, $ {{C}}_{v}^{t-1} $ 为节点$ v $ 上一时刻的细胞状态, $ {{x}}_{t}={{W}}_{1}{{u}}_{{v}_{i}}+ {{W}}_{2}{{u}}_{{v}_{j}}+{b} $ 为节点$ {v}_{i} $ 和$ {v}_{j} $ 之间新增关系产生的新信息. 更新后节点$ v $ 的表示向量为$ {{h}}_{v}^{t} $ . 上述相关节点邻域信息更新单元的结构如图5 所示.图 5 节点邻域更新单元Figure5. Node neighborhood update unit.3.3.参数训练 -->3.3.参数训练 为了在无监督方式下进行参数学习, DNRLP模型将输出的节点表示向量$ {{h}}_{v} $ , $ v\in V $ 应用于基于图的损失函数, 并使用梯度下降法对模型参数进行更新. 基于图的损失函数假设相互连接的节点有着相似的网络表示向量, 损失函数如下:$ {\rm{\sigma}}\left({h}_{v}^{T}{h}_{u}\right) $ 定义了节点$ v $ 和节点$ u $ 之间存在链接的概率, $ {p}_{n\left(v\right)} $ 为负采样分布, ${ {Q}}$ 定义了负采样的数量. 通过该损失函数习得的网络表示包含了网络节点之间的交互信息, 可以直接用于后续的链接预测任务.3.4.基于动态网络表示的链接预测 -->3.4.基于动态网络表示的链接预测 在网络中相似节点在未来发生链接的可能性更大, 因此, 本文通过度量网络节点之间的相似度来进行网络链接预测. 通过上述动态网络表示学习过程, 我们可以得到每次网络演化后的新节点偏好表示, 这些节点表示保存了节点的偏好信息, 可以直接进行节点间的相似度计算, 计算过程如下:$ {{h}}_{v} $ 和$ {{h}}_{u} $ 表示两个节点在当前时刻的表示向量, $ i $ 和$ j $ 表示节点偏好表示向量的分量. 相似度越大, 则节点间发生链接的可能性越大, 因此对网络目标节点进行链接预测时, DNRLP模型首先会计算该节点与网络中的其余节点之间的相似度并对其进行排序, 选择top-k的节点作为最终链接预测的结果.4.实验分析 24.1.实验设计 4.1.实验设计 为了验证DNRLP模型在网络链接预测任务下的性能和有效性, 本文在具有代表性的四个公开动态网络数据集上进行了对比实验. 这四个数据集的数据统计信息如表2 所示.数据集 节点数 边数 时间/d 聚类系数/% UCI 1899 59835 194 5.68 DNC 2029 39264 982 8.90 Wikipedia 1219241 2284546 4763 0.000837 Enron 384413 1751463 1140 4.96
表2 动态网络数据详细信息Table2. Dynamic network data details.[38 ] 是由加利福尼亚大学欧文分校的在线学生社区的用户之间的消息通信而组成的网络. 网络中的节点表示社区用户, 如果用户之间有消息通信, 那么用户之间就会有边连接, 与每条边相关联的时间表示用户之间的通信时间. DNC是2016年民主党全国委员会电子邮件泄漏的电子邮件通信网络. 网络中的节点代表人员, 边代表人员之间的邮件交互. Wikipedia talk, Chinese (Wikipedia)[39 ] 是中文维基百科的通讯网络, 节点表示中文维基百科的用户, 边表示在某一时刻某一用户在另一用户的对话页上发送了一条消息. Enron [40 ] 是由Enron员工之间发送的电子邮件所组成的电子邮件网络. 和DNC一样, 网络中的节点代表员工, 边代表电子邮件. 这些数据集涵盖了多种情况, 例如: UCI和DNC的节点数和边数较少, 而聚类程度较高, 形成较为密集的小网络. 但是它们在持续时间上又有所不同, UCI的持续时间短, 而DNC的持续时间较长. Enron是节点数和边数较多, 聚类程度也较高的数据集, 形成较为密集的大网络. 而Wikipedia是节点数和边数很多, 持续时间很长, 但聚类程度却极低的数据集, 形成稀疏的大网络. 使用这些数据集, 我们可以对模型的鲁棒性进行测试.表1 中所述的时序网络数据得到t 时刻的网络拓扑图以及时间信息, 使用平均交互排序(mean reciprocal rank, MRR)指标评估链接预测任务的质量. MRR计算了测试集中真实节点的排名倒数的平均值, 其计算过程如下所示:$ H $ 为测试集中的节点个数, 将目标节点与和其有真实连接的节点之间的余弦相似度进行降序排序, $ {rank}_{i} $ 则表示了它们的余弦相似度在降序序列中所处的位置. 当测试集中的节点与目标节点间有真实连接时, 其相似度排名应尽可能靠前, 因此MRR 值越大, 说明链接预测的质量越高, 即网络表示越精准有效. 实验按照时间顺序选取前80%的数据作为模型的训练数据, 后10%的数据作为验证数据, 其余10%的数据作为测试数据. 实验不但与现有的链接预测模型进行了对比, 还与使用了不同信息扩散策略的DNRLP模型的变体进行了比较. 并且, 为了验证DNRLP模型的准确性, 我们还选取了不同数量的训练数据来与对比模型进行对比. 对于测试集中的每个链接节点对, 我们固定链接一端的节点, 将其看作目标节点, 计算网络中其余节点与该目标节点的余弦相似度, 并进行降序排列.$ Recall@k $ 指标来计算在测试数据集中真实链接占预测结果集中Top-k的百分比, 其计算过程如下所示:$ \sigma \left\{{rank}_{i}\leqslant k\right\}=1 $ 表示在预测结果集中真实链接节点的排名$ {rank}_{i} $ 小于设定阈值$ k $ . $ Recall@k $ 的值越大, 说明链接预测任务的效果越好.$ Precision@k $ 指标来计算在测试数据集中预测结果占真实链接集中Top-k的百分比, 其计算过程如下所示:$\sigma \left\{{rank}_{i}\leqslant k\right\}=1 $ 表示在预测结果集中真实链接节点的排名$ {rank}_{i} $ 小于设定阈值$ k $ . $ Precision@k $ 的值越大, 说明链接预测任务的效果越好.表3 所示.项目 设置 数量 操作系统 Ubuntu 16.04 1 CPU Intel?i7-5280K, 6 核, 12线程 1 硬盘 512GB PLEXTOR?PX-512M6Pro SSD 1 内存 Kingston?8GB DDR4 2400 8 重要程序包 Python 3.7 1 深度学习 PyTorch 1
表3 实验环境设置信息Table3. Experimental environment setup information.4.2.结果分析 -->4.2.结果分析 实验结果如表4 所示. 通过观察对比结果可以看出基于网络表示学习的链接预测方法比基于机器学习的链接预测方法更加有效. 这是因为网络表示学习方法可以对网络节点间的关系进行深入挖掘, 从而得到更加丰富的特征信息. 在基于网络表示学习的链接预测方法中, node2vec在四个数据集上均表现一般, 主要因为node2vec仅通过随机游走来捕获节点的邻域结构, 没有重视直接相连节点间的信息交互. 且其主要适用于静态网络, 忽略了网络中的动态信息. DynGEM、GCN-GAN和DDNE模型是针对动态网络的表示学习模型, 它们引入了网络中的动态信息, 因而预测效果优于node2vec, 这说明了动态信息在网络演化中的重要性. 但是DynGEM和DDNE模型的预测效果不如或者与GCN和GraphSAGE的效果相似, 这是因为它们仅对网络拓扑图的邻接矩阵进行学习, 只得到了网络的全局拓扑结构信息, 而忽略了网络中的局部信息, 因而学习到的网络特征并没有GCN和GraphSAGE丰富. 而GCN和GraphSAGE通过聚合邻居节点的信息来模拟信息在节点间的扩散过程, 既学习到了网络中全局信息也学习到了局部信息, 这表明了局部特征在网络中的重要性, 同时也体现出GCN和GraphSAGE模型适用于聚类系数较高的邻域信息丰富的网络. 但是GCN和GraphSAGE忽视了信息传播随时间的衰减, 没有对信息进行遗忘, 而GCN-GAN既考虑到了网络中的全局特征和局部特征, 又考虑到了网络演化过程中的动态信息, 因而效果优于GCN和GraphSAGE. 但是GCN-GAN模型忽视了时间间隔对信息更新的影响, 而DNRLP模型通过信息动态更新模块和信息扩散模块不仅学习到了网络的动态信息, 考虑到了节点邻域所受的影响, 同时还考虑了时间间隔对信息更新的影响, 因此, 该模型在链接预测任务中较其他模型有明显优势. 此外, 我们可以看到, 在Wikipedia数据集上所有方法的表现均不佳, 这是因为它的聚类系数太低, 持续时间又太长, 给链接预测任务带来了极大的挑战. 同时对比于其他数据集我们可以看出在聚类系数稍高的情况下, 我们的模型效果要远优于其他所有模型.方法 UCI DNC Wikipedia Enron Logistic Regression 0.005 1 0.020 9 0.003 7 0.005 2 SVM 0.003 2 0.018 2 0.002 1 0.002 9 Node2Vec 0.004 7 0.019 7 0.003 5 0.003 9 GCN 0.015 9 0.048 4 0.010 1 0.017 6 GraphSAGE 0.016 3 0.049 7 0.012 0 0.018 3 DynGEM 0.015 7 0.028 4 0.010 8 0.014 7 GCN-GAN 0.020 1 0.050 4 0.014 9 0.021 5 DDNE 0.014 2 0.026 8 0.009 6 0.011 6 DNRLP 0.035 1 0.053 9 0.018 7 0.036 3
表4 链接预测MRR结果对比Table4. Link prediction MRR results comparison.$ k $ 值下的$ Recall@k $ 指标, 实验结果如图6 所示. 本文所提出的DNRLP模型在不同$ k $ 值下的链接预测效果均优于对比模型. 同时随着$ k $ 值的不断增大, $ Recall@k $ 的值也在不断增大. 我们可以看出, DynGEM的预测效果与GraphSAGE的效果相似, 并且在DCN数据集中它的表现较差, 表明了学习局部信息的重要性. 而GraphSAGE在DCN数据集中的表现优异, 表明了GraphSAGE强大的学习邻域信息的能力, 也表明了GraphSAGE适用于聚类系数较高的网络. 在不同$ k $ 值下, GCN-GAN模型的预测效果基本位列第二, 表明了同时考虑空间信息与时间信息的重要性, 而GCN-GAN的预测效果要次于DNRLP, 表明了时间间隔在网络演化过程中的重要性. 上述实验结果表明, DNRLP模型可以更好的学习网络中的节点信息, 得到含有全局信息、局部信息以及节点偏好信息的节点表示.图 6 各数据集上的$ Recall@k $ 对比图 (a) UCI数据集; (b) DNC数据集; (b) Wikipedia数据集; (d) Enron数据集Figure6. $ Recall@k $ comparison diagram on each data set. (a) UCI dataset; (b) DNC dataset; (b) Wikipedia dataset; (d) Enron dataset$ k $ 值下的$ Precision@k $ 指标, 实验结果如图7 所示. 我们可以看出, $ Precision@k $ 指标与$ Recall@k $ 指标的实验结果相似. 在DCN数据集中, 所有方法的表现都比较好, 且当$ k $ 值较小时, DNRLP与GraphSAGE、GCN-GAN的差别不大, 这是因为DCN数据的聚类系数较大, 网络中的局部信息相对重要, 而这三个模型均可以通过聚合邻居节点的信息来更新节点表示, 体现了学习网络中局部信息的重要性. 相反在Wikipedia数据集上所有方法的表现均不佳, 这是因为它的聚类系数太低, 持续时间又太长, 对进行准确的链接预测有很大的挑战. 在四个数据集上, 本文所提出的DNRLP模型在不同$ k $ 值下的$ Precision@k $ 指标均优于对比模型, 并且随着$ k $ 值的不断增大, $ Precision@k $ 的值也在不断增大, 当$ k $ 值较大时, 所提DNRLP模型的优势更为明显. 实验结果表明, 在动态网络中DNRLP模型可以更为准确地进行链接预测.图 7 各数据集上的$ Precision@k $ 对比图 (a) UCI数据集; (b) DNC数据集; (b) Wikipedia数据集; (d) Enron数据集Figure7. $ Precision@k $ comparison diagram on each data set. (a) UCI dataset; (b) DNC dataset; (b) Wikipedia dataset; (d) Enron dataset图8 所示, 可以看出在四个数据集上, DNRLP-prop模型的预测效果均优于其他两个变体模型, 且$ k $ 值越大, $ Recall@k $ 的值也越大, 而DNRLP-org模型的预测效果最差. DNRLP-org模型的低预测效果主要是因为它忽略了信息在网络中的扩散过程, 没有将新信息传播到节点邻域中去, 这表明了信息传播在网络中的重要性. DNRLP-prop模型的预测效果优于DNRLP-1st模型的预测效果, 这主要是因为新信息的扩散往往是局部性的, 不仅会对相关节点的一跳邻居产生影响, 也会对与其距离较近的多跳邻居产生影响. 实验结果表明, 动态信息对动态网络的表示学习有着至关重要的作用, 不仅对直接相关的节点有影响, 对其周围一定范围内的节点也有影响. 使用基于连接强度的随机游走算法可以有效地将网络中的动态信息更新到受影响的节点中去.图 8 DNRLP模型变体的Recall@k 对比图 (a) UCI数据集; (b) DNC数据集; (c) Wikipedia数据集; (d) Enron数据集Figure8. Recall@k comparison diagram of the variants of DNRLP. (a) UCI dataset; (b) DNC dataset; (c) Wikipedia dataset; (d) Enron dataset.图9 所示, 可以看出在两个数据集上, 随着训练数据比率的增大, MRR的值也在增大. 并且在任意比率下, DNRLP的训练效果均优于对比模型, 表现了我们所提模型在链接预测任务中优异的性能.图 9 不同训练率的MRR结果对比图 (a) DNC数据集; (b) Enron数据集Figure9. MRR results of different training rates. (a) DNC dataset; (b) Enron dataset5.结 论 本文针对现实世界中动态演化的网络提出了一种基于动态网络表示的链接预测模型DNRLP. 该模型根据动态网络的特性, 在标准LSTM单元的基础上引入了基于时间间隔的信息过滤单元, 来决策节点新、旧信息的去留. 此外, DNRLP模型还考虑了新信息在直接相关节点邻域内的信息传播问题. 本文在四个动态网络公开数据集上对模型的有效性进行了验证, 实验结果表明网络中的全局信息和局部信息对学习良好的网络表示有非常重要的作用, 同时动态网络中的时间信息以及动态信息在网络中的传播对网络节点表示的更新有着极其重要的影响. DNRLP模型可以学习到动态网络中丰富的信息, 能够有效地对新信息进行快速准确地学习, 在链接预测任务中表现出了明显的优势.  图 1 动态网络示意图
图 1 动态网络示意图






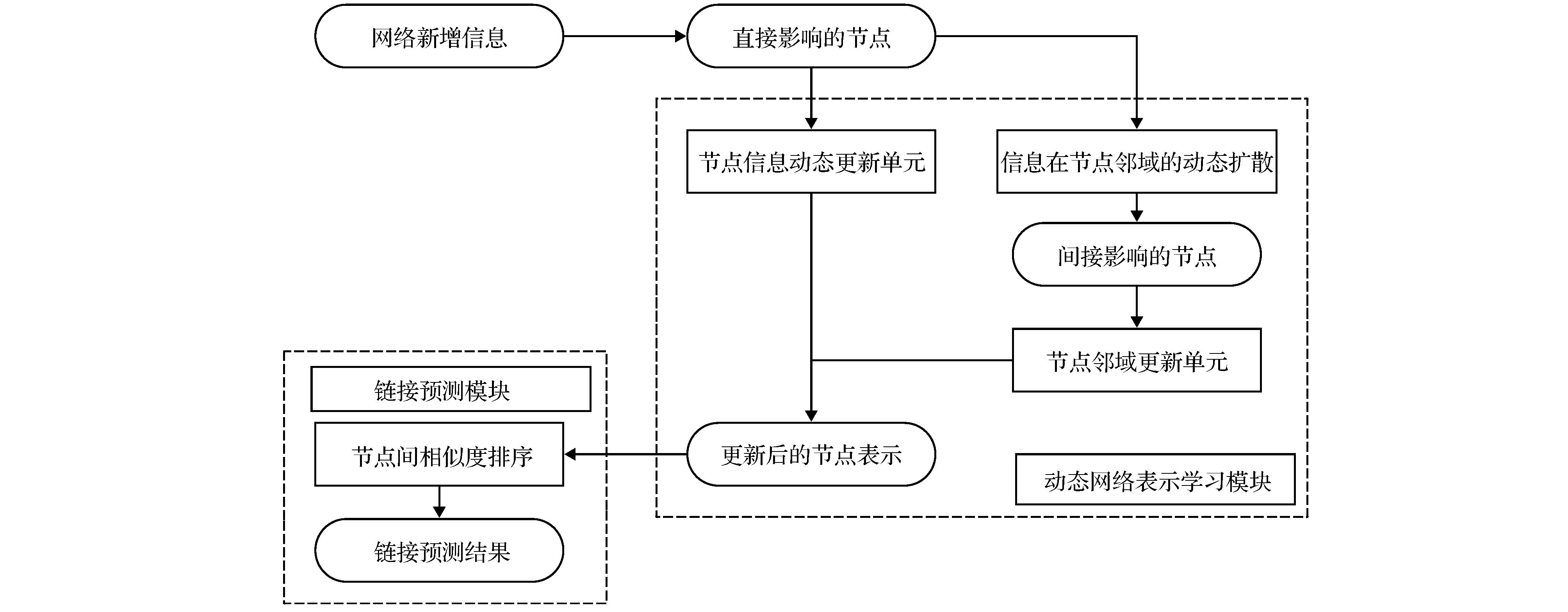 图 2 基于动态网络表示的链接预测模型结构
图 2 基于动态网络表示的链接预测模型结构

































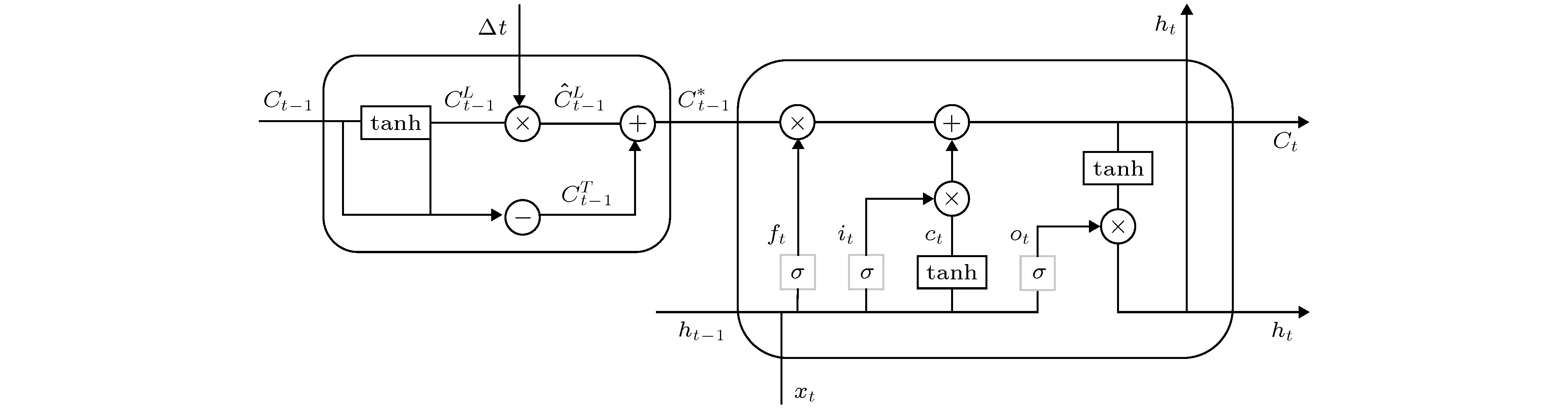 图 3 基于时间间隔的LSTM单元
图 3 基于时间间隔的LSTM单元









































































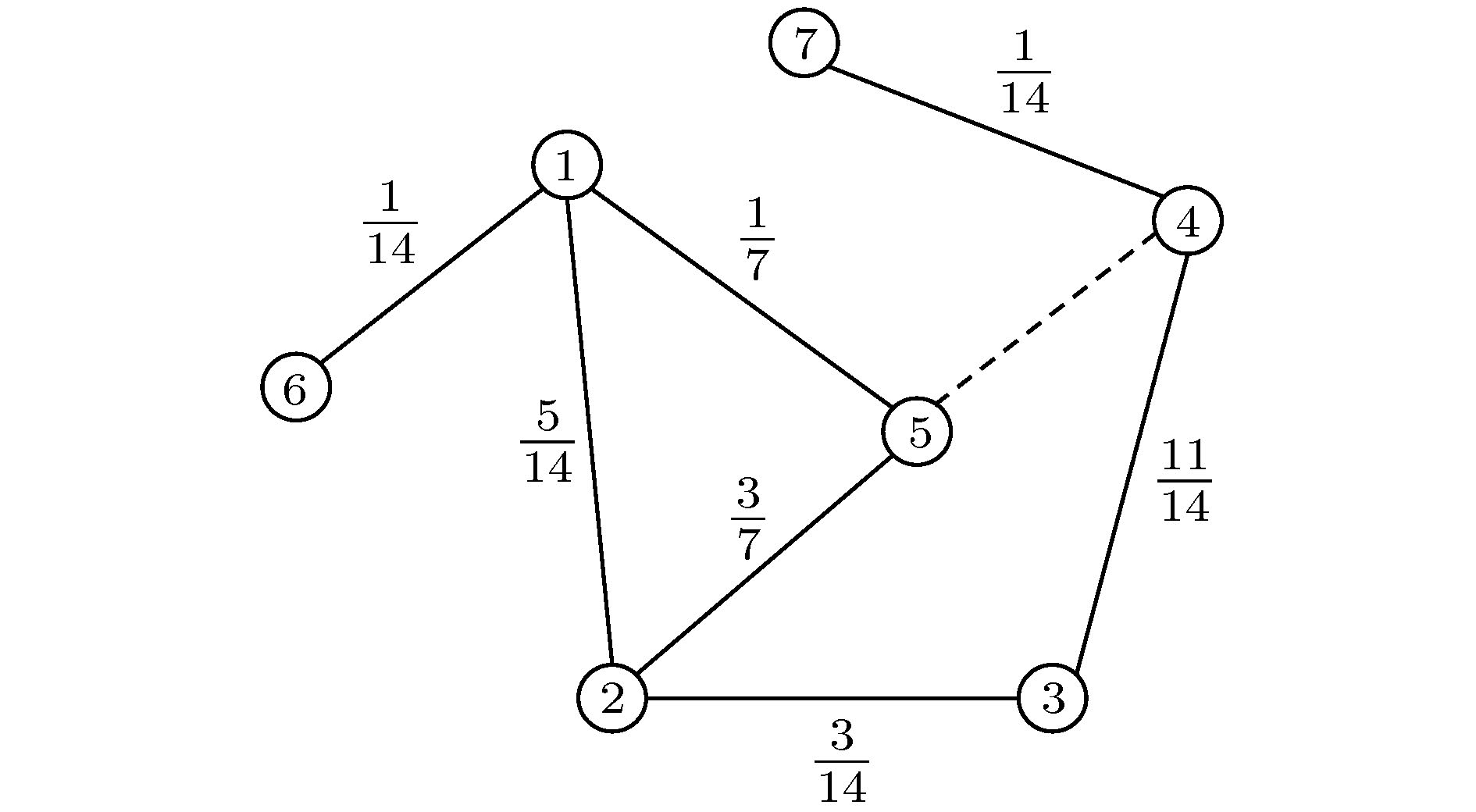 图 4 节点邻域采样示意图
图 4 节点邻域采样示意图

































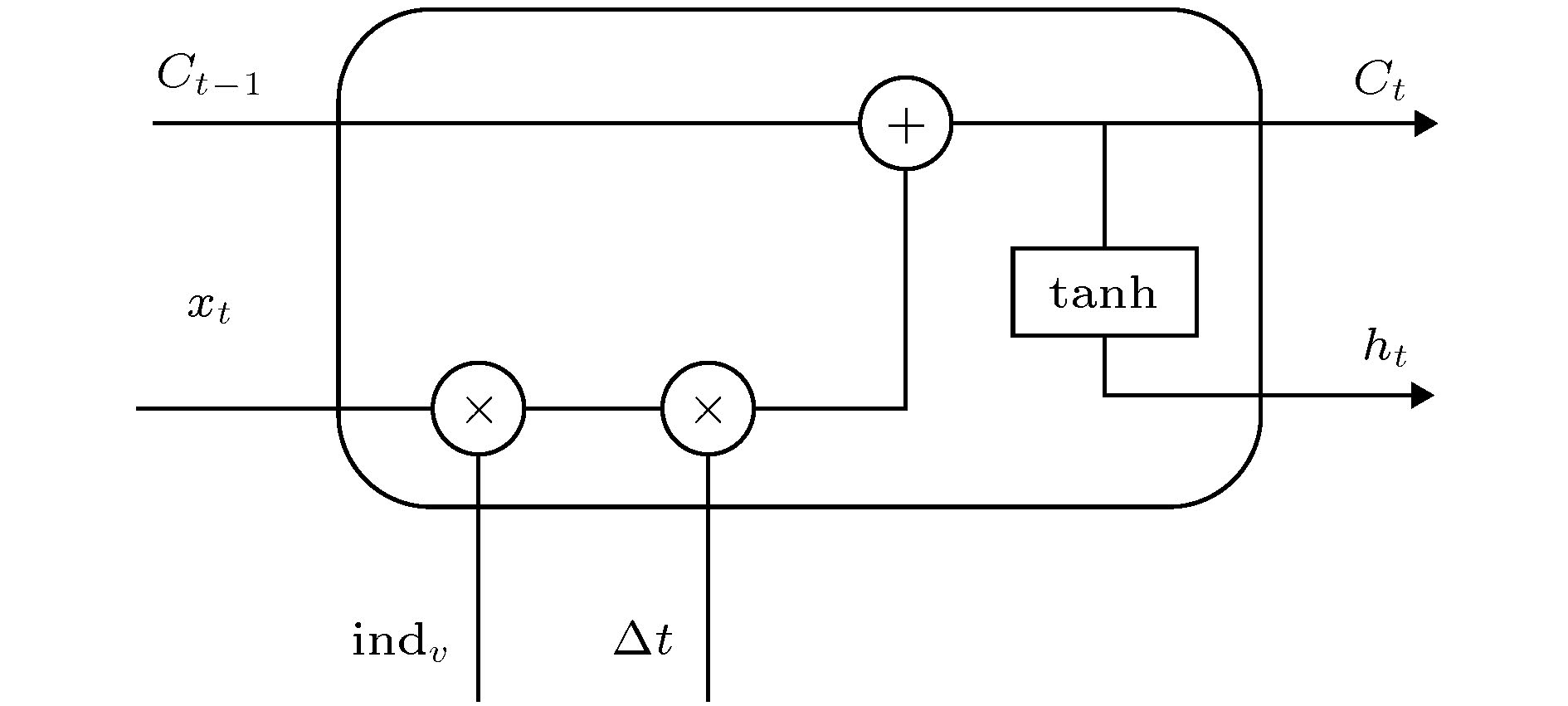 图 5 节点邻域更新单元
图 5 节点邻域更新单元




























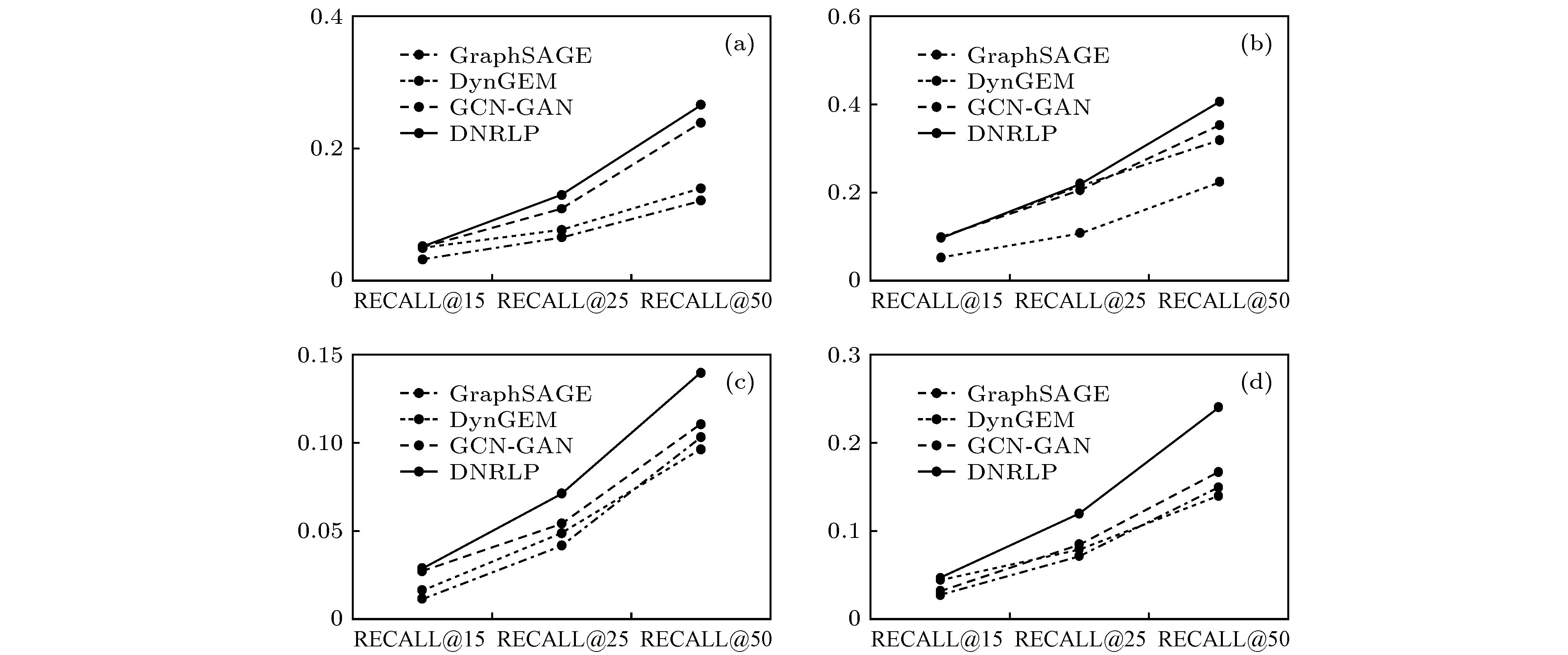 图 6 各数据集上的
图 6 各数据集上的











 图 7 各数据集上的
图 7 各数据集上的



 图 8 DNRLP模型变体的Recall@k对比图 (a) UCI数据集; (b) DNC数据集; (c) Wikipedia数据集; (d) Enron数据集
图 8 DNRLP模型变体的Recall@k对比图 (a) UCI数据集; (b) DNC数据集; (c) Wikipedia数据集; (d) Enron数据集 图 9 不同训练率的MRR结果对比图 (a) DNC数据集; (b) Enron数据集
图 9 不同训练率的MRR结果对比图 (a) DNC数据集; (b) Enron数据集