全文HTML
--> --> -->类星体被发现后不久, 其辐射流量的变化就被观测到了. 已有研究对类星体光变现象从不同角度做了大量的分析. MacLeod等[4]认为类星体光变可以利用随机游走模型来拟合, 但Kasliwal等[5]却认为该模型并非适合所有的类星体, Guo等[6]认为随机游走模型不能极好的拟合部分类星体光线曲线. 解释光变现象发生常用的吸积盘不稳定模型也是将光变视为随机事件, 盘通过黏滞耗散和随机因素同外部介质产生作用[3,7]. 随着观测技术水平的提高和一些大型望远镜的使用, 在对一些长期监测的类星体光变资料分析时发现光变呈显出准周期现象[8,9], 如OJ 287长期光变曲线存在约12年的长周期[10,11], 运用该周期推测OJ 287下一次可能爆发的时间, 其后观测到的爆发时间与该预测时间非常吻合[12,13]. 随着非线性动力学理论的发展, 非线性动力学分析方法被引入到类星体光变的研究中来[14—16]. 如果光变具有混沌特性, 非线性机制就可以被用来解释类星体光变.
类星体光变资料里隐含有线性和非线性的成分, 是极其复杂的[17]. 将不规则的光变现象视为复杂的, 仅是一种假设, 简单的定性分析缺乏说服力. 类星体光变是不是属于复杂系统? 若其存在复杂性, 复杂到何种程度? 这些问题值得进一步深入研究. 复杂性研究处于有序与混沌的边缘, 现在主要指的是对非线性现象的研究[18]. 混沌动力学理论可以进行复杂性分析, 但混沌分析方法一般要求数据量非常大, 少则上千, 多则上万, 对观测资料的质量要求也较高, 要想获得较完整的类星体光变的资料需要占用望远镜较长的观测时间. 尽管与过去相比, 目前类星体的监测项目增多, 但监测样本数还是较少, 观测时间的跨度也较短.
斯隆数字化巡天(Sloan digital sky survey, SDSS)项目提供了大量类星体测光监测数据, SDSS第7次释放数据(data release 7, DR7)释放有光谱证认过的类星体5个波段10年观测的数据, 但单个类星体样本光变资料数据量少. 常用的、对时间序列长度要求相对较低的复杂性分析方法有近似熵[19,20]、Lempel-Ziv算法[21]、样本熵[22]和Kolmogrov熵[23]等方法. 超过100个数据量时, 利用近似熵方法就能获得比较可靠的估计值, 并且没有粗粒化处理要求, 这样可以保留原始数据的有效信息[19], 近似熵方法优于后两种方法. 本文利用近似熵方法计算和度量类星体光变的复杂性, 分析类星体光变的复杂度有助于我们更好地了解光变的复杂特征, 揭示复杂光变的非线性动力学特性.
若存在一个给定长度的一维时间序列










5种典型时间序列如图1所示, 其中周期序列(用Sine表示)为



 图 1 典型时间序列
图 1 典型时间序列Figure1. Typical time series
对于时间序列长度的选取, Pincus和Huang[19]通过他们的大量研究, 建议数据点数最好取100以上, 一般也不要超过5000. 我们将时间序列长度都取900, 模式维数m = 2, 相似容限r取0.05—0.50, 5种典型时间序列的近似熵分析结果见图2. 从近似熵值分布可以看出: 周期序列的近似熵最小, 白噪声序列的近似熵最大, 混沌序列的近似熵值介于周期序列和白噪声序列之间, 混沌序列叠加周期序列比混沌序列的近似熵值略大, 相似容限小于0.35时, 混沌序列叠加白噪声序列比白噪声序列的近似熵值小; 相似容限大于0.35时, 混沌序列叠加白噪声序列比白噪声序列的大. 对于不同类型的时间序列, 近似熵值按周期序列、混沌序列、混沌序列叠加周期序列、混沌序列叠加白噪声序列到白噪声序列的顺序逐渐增大, 近似熵值越大复杂性也越高, 周期序列、混沌序列、白噪声序列的近似熵值差别很大, 各自分别在不同的区间, 白噪声序列是混沌序列的近似熵值近5倍, 白噪声序列和混沌序列叠加白噪声序列复杂度差别不大, 白噪声序列近似熵值接近组合序列, 近似熵值都超过1.
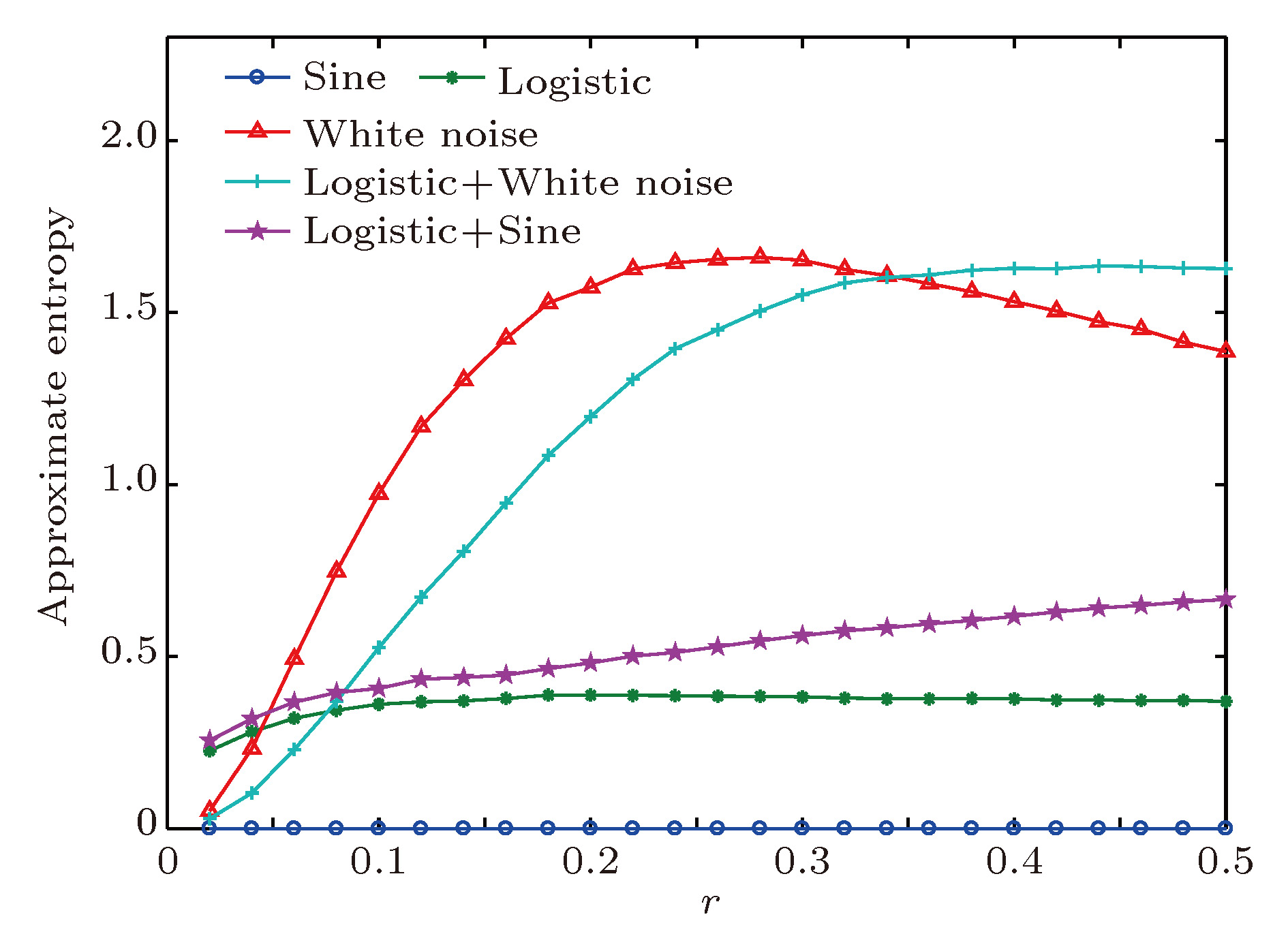 图 2 典型时间序列的近似熵
图 2 典型时间序列的近似熵Figure2. The approximate entropy of typical time series
这些结果说明近似熵能有效将混沌序列、周期序列、白噪声序列和不同成分组合序列区分开, 复杂性能够区分不同随机程度的时间序列, 验证了近似熵可以描述时间序列随机程度, 对混沌有一定的识别能力, 较好地表征了非线性结构的复杂性, 且复杂度随着随机成分增加而增大.
为了展示近似熵方法在度量SDSS类星体光变复杂性的能力, 我们先以类星体SDSS J012228.72-001332.0为例来分析该方法的可行性. 由于SDSS有很多观测任务, 望远镜观测时间有限, 不可能长时间观测某个类星体, 这些类星体大多是间隔90—270 d才有测光数据. 为了便于计算近似熵, 缺失值用插值方法求得, 图3给出了类星体SDSS J012228.72-001332.0原始和插值处理后的5个波段光变曲线.
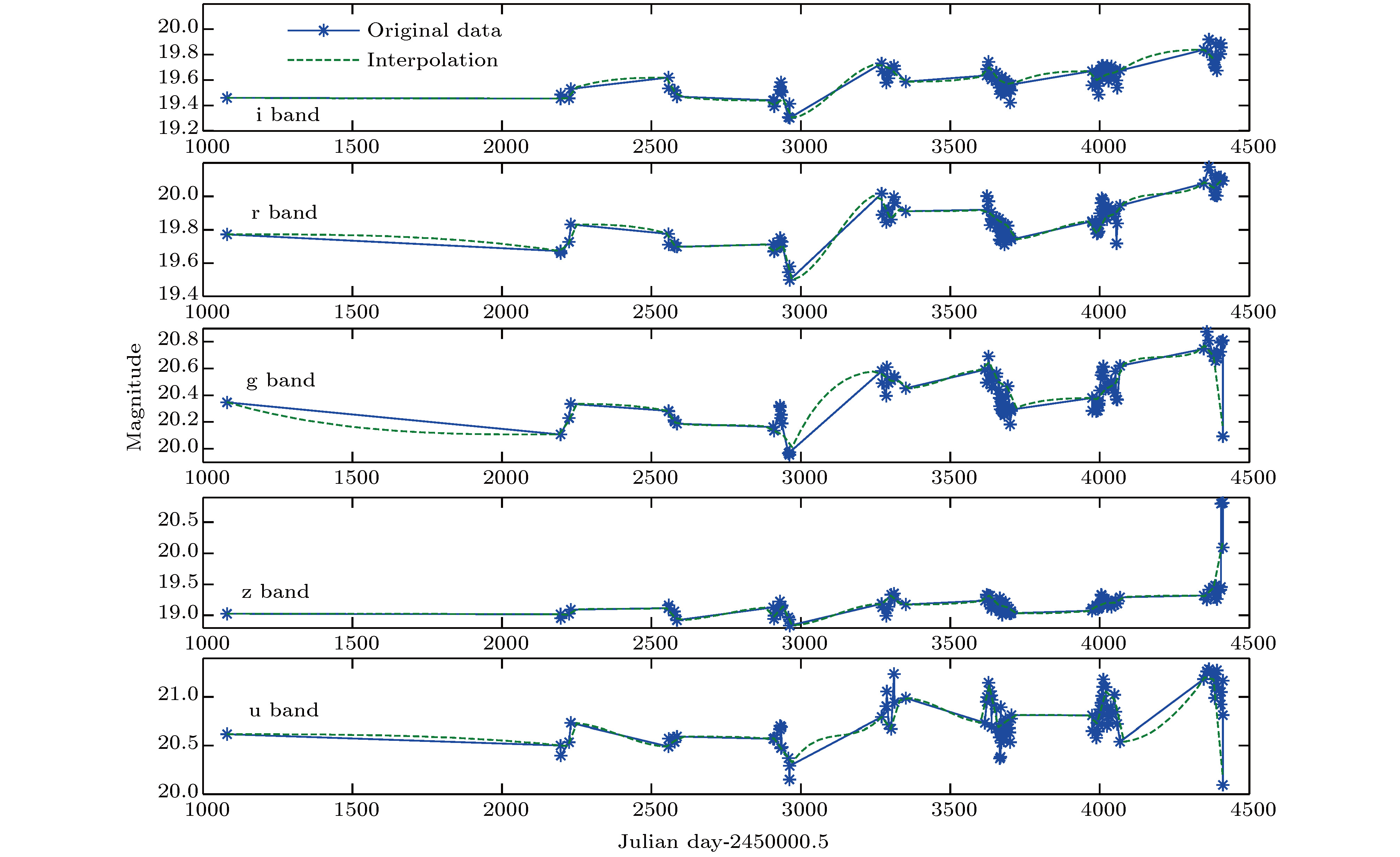 图 3 SDSS J012228.72-001332.0的光变曲线
图 3 SDSS J012228.72-001332.0的光变曲线Figure3. Light curve of SDSS J012228.72-001332.0
在计算近似熵的值前, 需要先选取模式维数m、相似容限r和时间序列的长度N. 对于N的选取, Pincus和Huang[19]通过他们的大量研究, 建议数据点数最好取100以上, 一般也不要超过5000, 本文对原观测数据每隔10 d插值一个数据, 数据量完全满足条件. 对于模式维数m, 一般选取m = 2, 相对于m = 1, 可以在时间序列的联合概率重构过程中, 获得更多更详细的信息; 若取m大于2, 相似容限r要求比较大, 但这样会导致丢失许多信息. 对于参数相似容限r, Pincus和Huang[19]认为相似容限r取0.10—0.25倍原始数据的标准差, 可以估计出比较理想的统计特性.
图4给出了类星体SDSS J012228.72-001332.0光变资料的相似容限-近似熵图, 在相似容限为0.2前, 近似熵值随相似容限的增加而增大, 相似容限r在增为0.2倍原始数据的标准差后, 5个波段光变资料的近似熵值基本保持一个比较稳定的值. g波段近似熵最小, 在0.3左右振荡; u波段近似熵最大, 最大值接近0.35, 相似容限在区间0.4—0.6时, 近似熵值随相似容限增加有减小的趋势. 因此, 在本文后面的大样本近似熵值分析时, 将相似容限r取为0.2倍原始数据的标准差. 从单个样本近似熵分析可以看出, 5个波段光变资料的近似熵值相差不多, 同一类星体不同波段光变曲线复杂性基本相同, 这可能是因为它们的光变曲线波形非常相似.
 图 4 SDSS J012228.72-001332.0的近似熵
图 4 SDSS J012228.72-001332.0的近似熵Figure4. The approximate entropy of SDSS J012228.72-001332.0
本文选取的类星体样本来源于SDSS DR7中的stripe 82天区光谱证认过的类星体, Macleod等[4]搜集整理提供了9258个类星体测光数据, 为了获得可靠的分析结果, 要求每隔360 d需要至少一次的观测数据, 由于2000—2003年观测数据太少, 起始时间选择从2003年开始, 并除去测光误差大于0.1个星等的数据点, 并且要求这些数据大致均匀分布, 按这些条件再选择观测数据点数超过20的作为样本. 最后, 我们得到i, r, g, z, u波段的样本数分别是6465, 6547, 6439, 6373和6092.
将模式维数和相似容限分别取m = 1, r = 0.2对选取的样本进行近似熵分析, 获得的结果如图5和表1所示. 可以看出, 类星体光变的近似熵值都处于0—0.6范围内, 最大值分别是0.552, 0.553, 0.575, 0.571和0.580, 最小值都为0.008, 接近于0. 白噪声序列和混有白噪声序列的混沌序列都比光变的近似熵最大值超过2倍, 因此类星体样本光变不可能完全是白噪声序列, 这是因为类星体观测总会有噪声干扰, 但其占的比例不大. 近一半的近似熵值分布在0.3—0.4的范围内, 远大于周期序列, 又远小于白噪声序列, 和混沌序列在初始值取为

| 近似熵值 | 0—0.1 | 0.1—0.2 | 0.2—0.3 | 0.3—0.4 | 0.4—0.5 | 0.5—0.6 | |||||||||||||
| 波段 | 总样本数 | 样本数 | 百分数/% | 样本数 | 百分数/% | 样本数 | 百分数/% | 样本数 | 百分数/% | 样本数 | 百分数/% | 样本数 | 百分数/% | ||||||
| i | 6465 | 39 | 0.60 | 365 | 5.65 | 1848 | 28.58 | 3106 | 48.04 | 1077 | 16.66 | 30 | 0.47 | ||||||
| r | 6547 | 40 | 0. 61 | 438 | 6.69 | 1898 | 28.99 | 3131 | 47.82 | 1003 | 15.32 | 37 | 0.57 | ||||||
| g | 6439 | 34 | 0.53 | 374 | 5.81 | 1794 | 27.86 | 3153 | 48.97 | 1033 | 16.04 | 51 | 0.79 | ||||||
| z | 6373 | 40 | 0.63 | 203 | 3.19 | 1438 | 22.56 | 3223 | 50.57 | 1400 | 21.97 | 69 | 1.08 | ||||||
| u | 6092 | 27 | 0.44 | 190 | 3.12 | 1503 | 24.67 | 3117 | 51.17 | 1214 | 19.93 | 41 | 0.67 | ||||||
表1SDSS类星体的近似熵
Table1.Approximate entropy of SDSS quasars
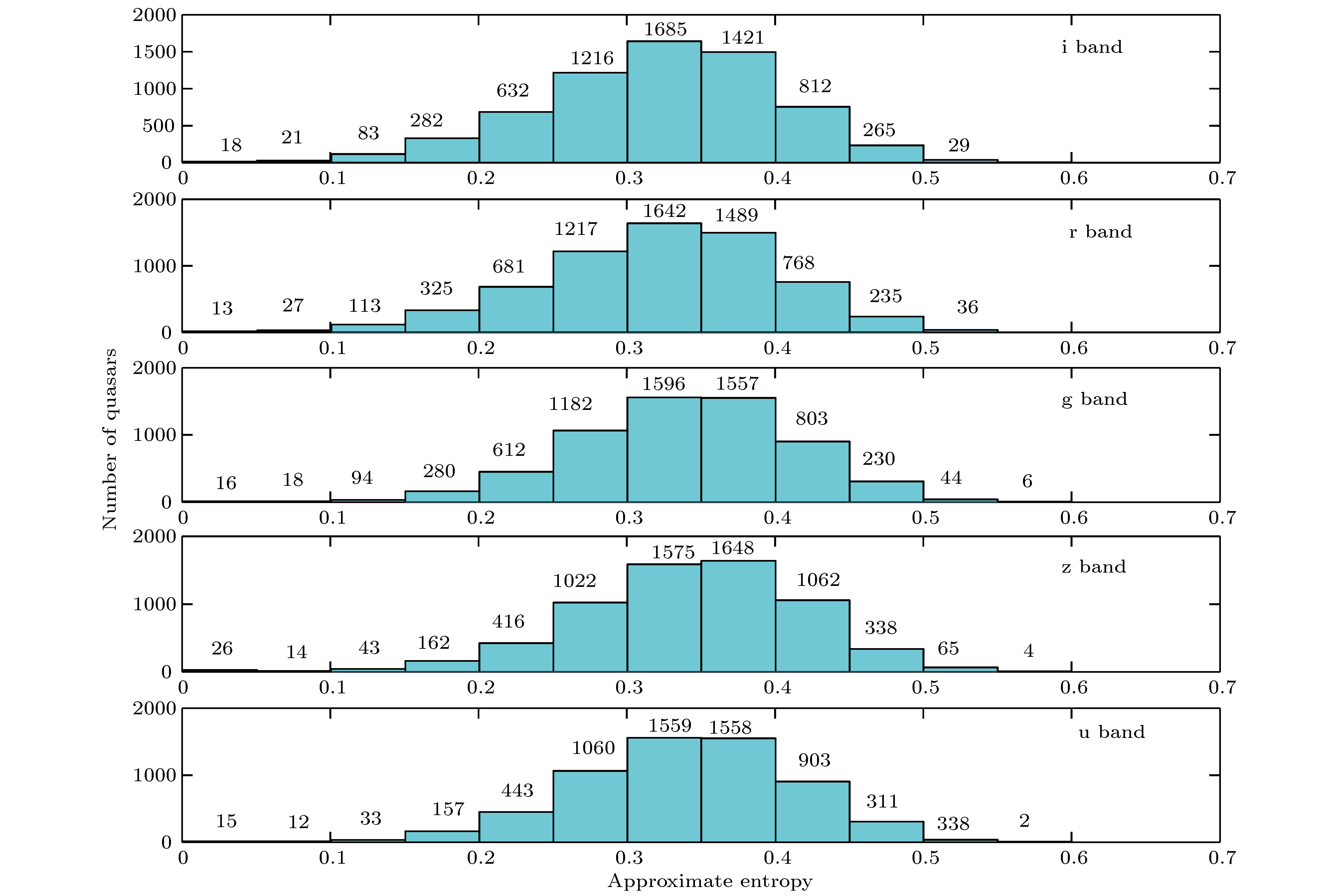 图 5 SDSS类星体的近似熵分布
图 5 SDSS类星体的近似熵分布Figure5. Approximate entropy distribution of SDSS quasars
近似熵值的大小和被分析的时间序列复杂程度存在成正比例的关系, 时间序列越复杂, 其近似熵值也就越大, 时间序列越趋近于随机性, 反之, 近似熵值越小, 越趋于周期性. 类星体光变的近似熵值低于0.2的样本数很少, 最多的r波段才占到7.3%, 最少的u波段只有3.56%, 说明周期性光变占主导的类星体比例很少. 近似熵值高于0.5的类星体样本数也少, 除z波段刚超过1%, 其余波段1%都不到, 说明所有类星体光变的近似熵值都偏小, 类星体光变趋于随机性概率较少. 同一类星体样本不同波段, 近似熵值都比较接近, 说明同一类星体光变的复杂性基本一致. 不同类星体近似熵值不尽相同, 说明类星体光变的非线性结构是有区别的, 可能光变产生的原因不一样引起的.
本文利用近似熵方法分析了混沌序列、周期序列、白噪声序列和不同成分组合序列的近似熵, 发现近似熵值能有效区分不同随机程度的时间序列, 验证了近似熵对不同复杂性的时间序列有较好的识别能力, 金宁德等[20]也用模拟信号获得了跟我们一样的结论. 本文进一步基于SDSS stripe 82天区的类星体测光数据分析了类星体光变的复杂性, 从单个源的分析结果看来, 5个波段光变曲线波形非常相似, 它们的近似熵值相差较小, 同一类星体不同波段光变曲线复杂性基本相同. 对6000多个大样本的类星体分析发现, 所有的近似熵值都低于0.6, 最大值为0.58, 说明类星体光变中白噪声占的比例都不高. 近一半的类星体光变和Logistic方程产生的混沌序列的复杂性是一样的, 说明一部分类星体光变以混沌成分占主导. 小部分近似熵值接近于0, 这说明周期性成分占主导的类星体比例非常少. 类星体光变不可能是完全周期性的, 也不可能是白噪声, 因为若是完全周期性或白噪声, 近似熵值是0或超过1, 也不可能是完全混沌的, 因为观测中总夹杂着噪声的影响. 因此类星体光变可能是周期性成分, 混沌成分和噪声叠加在一起, 并以3种成分中的一种占主导.
用结构函数、功率谱等周期分析方法分析类星体长期光变资料, 发现光变具有周期性[1,8—13], 这和我们的结论并不矛盾, 这些文献只提取了类星体光变中隐含的部分周期信息, 忽略了其他部分的有效信息. MacLeod等[4]用随机游走模型来描述光变, 发现该模型能较好地拟合类星体光变曲线, 但Kasliwal等[5]和Guo等[6]认为随机游走模型在描述类星体光变中还是存在部分缺陷. Misra等[14]运用混沌动力学理论分析了GRS 1915+105 的光变曲线, 获得的结果是GRS 1915+105光变也存在混沌性叠加随机性的现象. 唐洁[17]应用集合经验模态分解方法将类星体光变资料分解成周期项、混沌项和趋势项, 认为类星体光变是由周期成分、混沌成分和趋势成分叠加而成. 这些已有的研究成果与我们分析的结论是比较一致的.
感谢美国SDSS项目提供的类星体光变数据.
