现有的跟踪算法根据所使用的目标外观模型大体分为2类:生成式跟踪和判别式跟踪。生成式跟踪通过寻找与所构造的外观模型最匹配的候选样本实现目标的跟踪[2-6]。判别式跟踪认为跟踪是一个二分类问题,其通过利用来自目标与背景区域的正负样本训练相应的分类器,使用分类器的得分区分背景与目标[7-11]。
基于判别式外观模型的跟踪由于在跟踪过程中同时考虑目标区域与背景区域,其跟踪精度一般高于生成式跟踪。但是判别式跟踪算法在跟踪过程中由于不准确的分类及使用不精确的样本训练分类器,导致跟踪过程中误差积累及分类器性能下降。针对此问题,Babenko等[10]提出多示例跟踪算法解决判别式跟踪算法存在正样本不确定的问题,其通过对多示例样本包进行标记取代对单个示例样本进行标记的问题,达到训练过程中弱化监督的目的,从而有效解决示例样本标签歧义性导致的跟踪漂移问题。但是多示例跟踪算法存在如下问题:① 由于外观环境的变化使得目标和背景在跟踪过程中不断发生变化,某些示例样本不能有效地区分目标与背景,对所构造的分类器贡献甚小;② 多示例学习(MIL)跟踪算法在弱分类器选择过程中存在分类器选择复杂度高的问题,其弱分类器的选择依据是最大化log-likelihood函数,从M个弱分类器所构成的弱分类器池中选择K个最强分类能力的弱分类器构造相应的强分类器,在选择最优弱分类器过程中,需要对每个示例样本概率及包概率重复迭代学习M次[12]。
针对多示例学习过程中存在的上述问题,本文提出了一种基于目标性权值学习的多示例目标跟踪算法,其主要特点如下:① 利用所跟踪物体的目标性属性对样本的重要性进行度量,根据其目标性测量结果对每个正示例样本赋予相应的权值,从而判别性地计算包概率,提高跟踪精度;② 在分类器选择过程中,采用最大化弱分类器与似然函数概率内积的方法从弱分类器池中选择弱分器构造强分类器,从而避免在弱分类器选择过程中对每个示例概率及包概率额外计算M次,提高计算效率。
1 多示例学习 多示例学习算法用多个示例构成的样本包替代单一正样本对分类器进行训练,从而有效解决了由于正样本位置模糊而导致的跟踪漂移问题。训练样本包为{(X1, y1), (X2, y2), …, (Xn, yn)},Xi={xi1, xi2, …, xim},yi为样本包的label,y=1表示正样本集,y=0表示负样本集。多示例学习假设样本包中只要存在一个正示例,则该包为正包,其label y=1;反之,负样本包仅由负示例组成[10, 13]。在目标跟踪过程中,以t时刻的目标位置lt*为中心,半径为α的区域内采集N个正样本组成正样本包X+={x| ||lt(x)-lt*|| < α},半径为α < ξ < β的环形区域内采集L个负样本组成负样本包X-={x|ξ < ||lt(x)-lt*|| < β}。
利用正负样本包中的示例特征训练弱分类器,其特征f(·)服从高斯分布,即
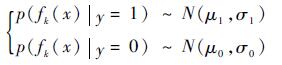 | (1) |
式中:fk为示例样本的第k个haar-like特征[14];μ1、σ1、μ0和σ0为弱分类的4个参数,且先验概率满足p(y=1)=p(y=0)[12]。因此,相应的弱分器为
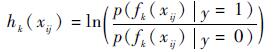 | (2) |
在跟踪过程中采用最大化log-likelihood函数的方法选择K个分类能力最强的弱分器h(·)级联形成强分类器H(·)。
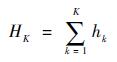 | (3) |
其中,弱分类器log-likelihood概率为
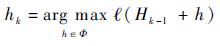 | (4) |
特征池Φ={h1, h2, …, hM}是由所有haar-like特征中随机产生的M个特征组成,M > K。
?(H)为正负样本包的log-likelihood概率,即
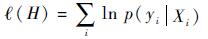 | (5) |
式中:p(yi|Xi)为正负样本包的概率,其由示例的概率p(yi|xij)采用Noisy-OR模型表示,即
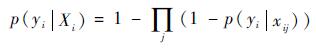 | (6) |
包中样本示例的概率为
 | (7) |
式中:σ(x)=1/(1+e-x)为sigmoid函数。
对于第t+1帧图像,在第t帧位置lt*邻域,搜索半径为γ的区域采集候选样本集Xγ,即Xγ={x| ||lt+1(x)|-lt*|| < γ},lt+1(x)为候选样本x在第t+1帧中的位置。强分类H(·)根据其对候选样本分类的置信度选择具有最大置信度的样本x*的位置为第t+1帧图像中目标的位置,即
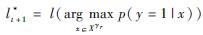
 | (8) |
式中:
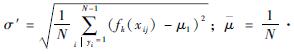
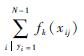
2 目标性权值学习的多示例算法 2.1 目标性权值学习
2.1.1 目标性度量 目标性度量(objectness measure)的基本思想是用一个函数值反映图像框所覆盖完整目标的程度。文献[15]指出,图像梯度特征(norm gradients,NG)是一种具有判别性的目标性度量方法。因此,本文参考文献[15-16]的方法,采用NG特征度量多示例跟踪中每个示例样本的目标性。首先,采用?1regularized SVM分类器对示例样本的NG特征进行分类[17],以每个样本的分类得分作为其目标性度量的结果。然后,利用目标性度量的结果对每个正示例样本赋予相应的权值,从而确定各示例样本对包概率的重要程度。对重要的样本赋予较大的权值,次优的样本赋予较小权值,实现判别性的包概率计算,达到提高跟踪精度的目的。正负样本示例的NG特征如图 1所示。
 |
| 图 1 正负样本示例及其NG特征 Fig. 1 Positive and negative sample instances and their NG features |
| 图选项 |
为了有效估计样本示例的目标性,首先将每个样本示例调整为8×8的图像块,使用1维模板[-1, 0, 1]计算示例样本在水平和垂直方向的梯度gx和gy,因此,样本的NG特征为
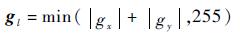 | (9) |
2.1.2 训练?1regularized SVM 由于视频图像跟踪过程中正样本数目非常有限,且在每帧跟踪中只存在一个正样本。因此,本文通过对初始帧中已知的正样本进行旋转和缩放方法获得大量的正样本。该方法在满足训练样本数量的前提下可以对目标的运动进行适当估计,从而提高分类器的抗干扰能力。按照上述方法,获得N个正样本构成正样本包X+={x1j, y1=1, j=0, 1, …, N-1};并以初始位置lt(x0)为中心,α < ξ < β为半径的环形区域内随机采集L个负样本构成负样本包X-={x0j, y0=0, j=N, N+1, …, N+L-1}。其正样本获取方式如图 2所示。
 |
| 图 2 ?1regularized SVM分类器正样本获取方法 Fig. 2 Acquisition method of positive sample for ?1regularized SVM classifier |
| 图选项 |
对于所采集的二分类样本集{X+, X-},X+={x1j, y1=1, j=0, 1, …, N-1}, X-={x0j, y0=0, j=N, N+1, …, N+L-1}, 按式(9) 计算每个示例样本的NG特征g,构造相应的NG特征集D+={g1j, y1=1, i=0, 1, …, N-1},D-={g0j, y0=0, j=N, N+1, …, N+L-1}。获得?1regularized SVM的分类判别函数,即
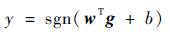 | (10) |
式中:w和b表示?1regularized SVM分类器模型[17]。
因此,所构造的多示例?1regularized SVM分类器为
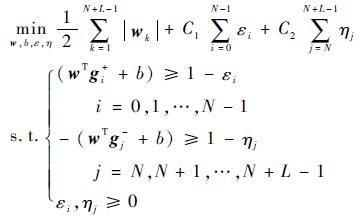 | (11) |
式中:εi和ηj为正负样本NG特征的松弛变量,其相应的约束总量分别为
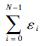
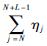
通过求解式(11) 的优化问题,获得最优的参数w*和b*。w*的大小决定第k个样本的权重。
因此,对于新一帧图像中的任意样本示例xk,依据?1regularized SVM计算每个样本示例的NG特征得分,其样本NG特征的得分决定其对样本包概率的贡献。
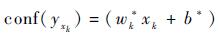 | (12) |
式中:conf(yxk)为经?1regularized SVM计算所得的样本xk的NG特征的得分。
2.2 包概率计算 从式(6) 可以看出,多示例学习跟踪算法采用Noisy-OR模型计算各示例样本的概率,在样本包概率的计算过程中只是简单地对示例样本进行求和,忽略各示例样本的差异性,导致分类器性能下降及误差累积,甚至跟踪漂移[18]。因此,本文根据各示例样本的NG特征判别性地区分不同样本的目标性,从而确定其对样本包概率的重要性,依据?1regularized SVM对每个样本示例NG特征分类的得分,对其进行相应的权值分配,即
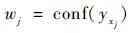 | (13) |
其相应正样本包的概率为
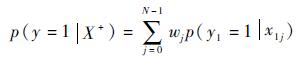 | (14) |
2.3 弱分类器选择 根据式(5) 和式(6) 可知,多示例学习跟踪算法通过最大化正负样本包的log-likelihood函数学习分类器及在包概率计算过程中使用Noisy-OR模型,其由于反复迭代计算M次示例概率及包概率,加剧了算法的计算复杂度[12]。因此,本文采用最大化弱分类器与log-likelihood概率内积的方法从弱分类器池Φ中选择K个错误率最低的弱分类器构造强分类器,避免在弱分类器选择过程中对当前示例及包概率重复计算M次,从而降低算法的计算时间。
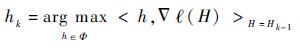 | (15) |
式中:
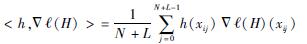
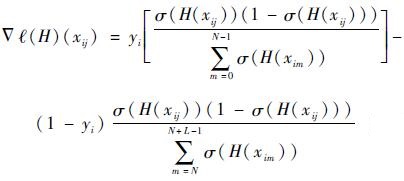 | (16) |
3 算法实现 综上所述,本文所提出的基于目标性权值学习的多示例跟踪算法的流程如图 3所示,具体步骤如下:
 |
| 图 3 本文算法流程图 Fig. 3 Flowchart of proposed algorithm |
| 图选项 |
Step 1??初始化。选取所跟踪的目标,生成训练?1regularized SVM所需要的正负样本,对样本按式(9) 计算其NG特征构造相应的特征集D+、D-,依式(11) 训练多示例?1regularized SVM,并根据式(12) 获得每个示例样本的目标性度量权值。
Step 2??初始化强分类器H0=0, k=0。
Step 3??对新一帧图像,采集正负样本包X+={x1 i| ||l(x)-lt+1 < α}, X-={x0 i|ξ < l(x)-lt+1|| < β}。按式(9) 计算其NG特征构造相应的特征集D+、D-,并根据式(12) 获得每个正示例样本的目标性度量权值,根据式(2) 训练得到M个弱分类器构造弱分类器池Φ={h1, h2,…,hM}。
Step 4??当k < K时,根据式(15) 从Φ中选择k-1错误率最低的弱分类器构造强分类器。
Step 5??初始化?m=0,m=1, 2, …,M。
Step 6??当m < M, i≤1, j≤N+L-1时,计算
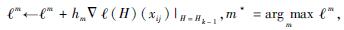
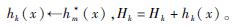
Step 7??输出强分类器:
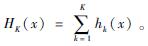
4 实验结果与分析 为了验证本文算法在视频目标跟踪中的有效性,将其与OAB跟踪[8]、MIL跟踪[10]及WMIL[12]跟踪进行对比,通过定性与定量2个指标对本文算法与其对比算法进行比较,测试视频序列来源为https://sites.google.com/site/trackerbenchmark/benchmarks/v10。
本文算法参数设置为:搜索半径γ=30,学习率η=0.85;正样本半径α=5,负样本半径ξ=2α, β=1.5γ;产生50个正样本,42个负样本;C1=C2=0.5。弱分类器数目M=150,从中选出K=25个构造强分类器。OAB[8]、MIL[10]及WMIL[12]跟踪算法的参数按原文设置。测试视频序列的特征如表 1所示。
表 1 测试视频序列的特点 Table 1 Characteristics of test video sequences
| 视频序列 | 帧数 | 主要特点 |
| david1 | 471 | 遮挡、尺度、旋转及光照变化 |
| trellic | 569 | 旋转、尺度及光照变化,复杂背景 |
| Shaking | 365 | 光照、尺度变化,旋转及复杂背景 |
| Tiger2 | 365 | 遮挡,快速运动,复杂背景 |
| deer | 71 | 运动模糊、形变、旋转及复杂背景 |
| carDark | 393 | 光照变化及复杂背景 |
表选项
定量指标采用目标中心位置误差及重叠率对各跟踪算法性能进行评估,其中心位置误差为各跟踪算法的目标中心位置与真实中心位置之间的欧氏距离。各跟踪算法在测试视频序列上的中心位置误差曲线如图 4所示,平均中心位置误差如表 2所示。重叠率定义为:overlap=
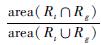
 |
| 图 4 中心位置误差曲线 Fig. 4 Center position error curves |
| 图选项 |
表 2 平均中心位置误差 Table 2 Average center position error
| 视频序列 | 平均中心位置误差/pixel | |||
| OAB[8] | MIL[10] | WMIL[12] | 本文算法 | |
| david1 | 27.74 | 21.07 | 19.97 | 15.18 |
| trellic | 77.35 | 68.79 | 63.96 | 20.94 |
| Tiger2 | 40.87 | 42.69 | 39.67 | 22.59 |
| Shaking | 144.67 | 14.55 | 25.80 | 19.47 |
| deer | 13.61 | 15.69 | 34.83 | 6.21 |
| carDark | 3.90 | 48.42 | 71.22 | 2.79 |
| 平均值 | 51.35 | 35.20 | 42.58 | 14.53 |
表选项
表 3 平均重叠率 Table 3 Average overlap rate
| 视频序列 | 重叠率 | |||
| OAB[8] | MIL[10] | WMIL[12] | 本文算法 | |
| david1 | 0.344 | 0.373 | 0.361 | 0.427 |
| trellic | 0.136 | 0.264 | 0.235 | 0.501 |
| Tiger2 | 0.348 | 0.382 | 0.453 | 0.529 |
| Shaking | 0.017 | 0.580 | 0.418 | 0.526 |
| deer | 0.643 | 0.611 | 0.417 | 0.710 |
| carDark | 0.741 | 0.153 | 0.089 | 0.762 |
| 平均值 | 0.372 | 0.394 | 0.323 | 0.575 |
表选项
实验1??遮挡、旋转、尺度及光照变化
在视频序列david1上对目标进行跟踪,该序列中所跟踪的目标尺度及光照不停地发生变化,在跟踪过程中还存在平面旋转,在第294帧目标摘掉眼镜并在第400帧重新戴上眼镜。实验结果如图 6(a)所示,OAB和MIL跟踪算法的性能最差,发生目标丢失的现象。WMIL跟踪算法的跟踪性能仅次于本文算法,本文算法能较好地对目标进行跟踪,其跟踪性能在4种算法中最优,其平均中心位置误差为15.18pixel,重叠率为0.427。
在trellic序列中,所跟踪的目标为在室外环境下运动的人的脸部,该视频中目标的尺度及环境光照不断变化并伴随平面的旋转,增加了跟踪难度。由实验结果(见图 6(b)、图 4、图 5及表 2、表 3) 可得,OAB、MIL、WMIL跟踪算法均不能适应目标的变化,发生跟踪丢失的现象,OAB从第120帧,MIL及WMIL从第170帧开始发生跟踪漂移的现象。本文算法能较为准确地实现对目标的跟踪,其平均中心位置误差为20.94pixel,重叠率为0.501。
 |
| 图 5 重叠率曲线 Fig. 5 Overlap rate curves |
| 图选项 |
视频序列Shaking中,所跟踪的目标存在严重的平面旋转及姿势变化并伴随舞台场景中光照的变化,由实验结果(见图 6(c)、图 4、图 5及表 2、表 3) 可得,MIL跟踪获得最优的跟踪结果,本文算法仅次于MIL跟踪,其在第231帧左右发生略微的跟踪漂移现象。OAB跟踪效果最差,从第35帧开始就发生目标丢失现象,WMIL跟踪性能次于本文算法,其在第139帧左右发生跟踪偏移的现象。
 |
| 图 6 对遮挡、旋转、尺度及光照变化视频序列的跟踪结果 Fig. 6 Tracking results for video sequences with occlusion, rotation, scale and illumination changes |
| 图选项 |
实验2??遮挡、快速运动及复杂背景
Tiger2视频序列中,目标存在严重的光照及姿势变化,并伴随快速的运动及复杂背景遮挡。如图 7(a)所示,OAB及MIL跟踪算法的性能最差,从第170帧开始出现不同程度的跟踪漂移现象。WMIL跟踪算法从第256帧开始出现稍微的跟踪偏移现象。本文算法相比其对比算法能较好地实现目标的跟踪,其平均中心位置误差为22.59pixel,重叠率为0.529。
 |
| 图 7 对遮挡、快速运动及复杂背景视频序列的跟踪结果 Fig. 7 Tracking results for video sequences with occlusion, fast motion and background clutters |
| 图选项 |
deer视频序列中,所跟踪的目标由于快速运动造成了运动模糊,加之复杂的背景和目标的运动形变加剧了跟踪的难度。如图 7(b)所示,OAB、MIL跟踪算法及本文算法表现出较好的跟踪性能,WMIL跟踪算法次之,在第40、49帧发生跟踪漂移的现象。
carDark视频序列中,所跟踪的目标为一辆夜间行驶的车辆,由于灯光及复杂背景的干扰,如图 7(c)所示,MIL和WMIL跟踪算法在第202、277、364帧发生跟踪失败的现象。本文算法和OAB跟踪算法在跟踪中表现出较好的性能,其中心误差分别仅为2.79和3.90pixel,重叠率分别达0.762和0.741,表现出较好的跟踪性能。
从实验结果可以看出,本文算法具有较高的跟踪精度,其在4组测试序列上的平均中心位置误差仅为14.53pixel,重叠率达0.575。OAB、MIL及WMIL跟踪算法的平均中心位置误差为51.35、35.20及42.58pixel,其重叠率分别为0.372、0.394及0.323。
对本文算法的计算复杂度进行必要分析。本文所选取的对比算法与所提出的算法相同,均属于判别式跟踪算法。因此,在最终所跟踪目标的判别方面所提出的算法与其他3种算法的计算复杂度相差不大。而相关算法复杂度最大的差异来自于正负样本包的选取和相关样本权值的设定。OAB跟踪算法中,由于仅存在正负样本的选取,因此相对而言其算法复杂度最低。而MIL跟踪算法引入样本包进行训练,相对于OAB跟踪算法增加了包选取的计算开销。此外,WMIL跟踪算法与本文算法均为MIL跟踪算法的改进算法,因此其计算复杂度相对于MIL跟踪算法略有提升。WMIL跟踪算法当中,所增加的算法复杂度主要来自于基于欧氏距离的权值估计。而本文算法所增加的计算复杂度主要来自于与NG特征的计算,而根据文献[15],其特征的计算复杂度为O(NC),N为正样本的数量,C为分类的类别(本文取C=2)。因此,总体来说,相对于MIL跟踪算法,本文算法虽然计算复杂度有所升高,但其所增加的复杂度仍在线性范围内。
5 结论 1) 通过将目标性测量引入到多示例学习中,利用目标性度量的判别性特征,在包概率计算过程中对不同的示例赋予权值,克服多示例学习跟踪算法在跟踪过程中不能有效区分重要样本,造成分类器性能下降的问题。
2) 利用最大化弱分类器与似然函数概率内积的方法选择相应的弱分类器,避免多示例学习跟踪算法在最优弱分类器选择过程中对样本示例及包概率的重复迭代学习,造成算法复杂度高的问题。
3) 实验结果表明,本文所提出的基于目标性权值学习的多示例跟踪算法在遮挡、光照变化、目标运动等复杂场景下具有较好的跟踪精度和鲁棒性。但是本文算法仅局限于单尺度跟踪,当所跟踪的目标发生大的尺度变化及跟踪漂移等问题时,本文算法表现出一定的局限性。因此,本文下一步的研究重点是将多尺度引入到多示例目标跟踪中以解决目标大尺度及跟踪漂移等问题。
参考文献
| [1] | WU Y, LIM J, YANG M H.Online object tracking:A benchmark[C]//IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2013:2411-2418. |
| [2] | ZHANG K, ZHANG L, YANG M H. Fast compressive tracking[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 36(10): 2002–2015. |
| [3] | ZHONG W, LU H, YANG M H. Robust object tracking via sparse collaborative appearance model[J].IEEE Transactions on Image Processing, 2014, 23(5): 2356–2368.DOI:10.1109/TIP.2014.2313227 |
| [4] | ROSS D A, LIM J, LIN R S, et al. Incremental learning for robust visual tracking[J].International Journal of Computer Vision, 2008, 77(1-3): 125–141.DOI:10.1007/s11263-007-0075-7 |
| [5] | ADAM A, RIVLIN E, SHIMSHONI I.Robust fragments-based tracking using the integral histogram[C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2006:798-805. |
| [6] | KWON J, LEE K M.Visual tracking decomposition[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2010:1269-1276. |
| [7] | KALAL Z, MIKOLAJCZYK, MATAS J. Tracking-learning-detection[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011, 34(7): 1409–1422. |
| [8] | GRABNER H, BISCHOF H.On-line boosting and vision[C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2006:260-267. |
| [9] | GRABNER H, LEISTNER C, BISCHOF H.Semi-supervised on-line boosting for robust tracking[C]//Computer Vision-ECCV 2008, European Conference on Computer Vision.Berlin:Springer, 2008:234-247. |
| [10] | BABENKO B, YANG M H, BELONGIE S. Robust object tracking with online multiple instance learning[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011, 33(8): 1619–1632. |
| [11] | ZHANG K, ZHANG L, LIU Q, et al. Fast visual tracking via dense spatio-temporal context learning[M].Berlin: Springer, 2014: 127-141. |
| [12] | ZHANG K, SONG H. Real-time visual tracking via online weighted multiple instance learning[J].Pattern Recognition, 2013, 46(1): 397–411.DOI:10.1016/j.patcog.2012.07.013 |
| [13] | 丁建睿, 黄剑华, 刘家锋, 等. 局部特征与多示例学习结合的超声图像分类方法[J].自动化学报, 2013, 39(6): 861–867. DING J R, HUANG J H, LIU J F, et al. Combining local features and multi-instance learning for ultrasound image classification[J].Acta Automatica Sinica, 2013, 39(6): 861–867.(in Chinese) |
| [14] | VIOLA P, JONES M.Rapid object detection using a boosted cascade of simple features[C]//Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2001.Piscataway, NJ:IEEE Press, 2001:511. |
| [15] | CHENG M M, ZHANG Z, LIN W Y, et al.BING:Binarized normed gradients for objectness estimation at 300fps[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Piscataway, NJ:IEEE Press, 2014:3286-3293. |
| [16] | LIANG P, LIAO C, MEI X, et al. Adaptive objectness for object tracking[J].IEEE Signal Processing Letters, 2016, 23(7): 949–953.DOI:10.1109/LSP.2016.2556706 |
| [17] | YUAN G X, CHANG K W, HSIEH C J, et al. A comparison of optimization methods and software for large-scale L1-regularized linear classification[J].Journal of Machine Learning Research, 2010, 11(2): 3183–3234. |
| [18] | XU X, FRANK E. Logistic regression and boosting for labeled bags of instances[J].Lecture Notes in Computer Science, 2004, 3056(3): 272–281. |
| [19] | EVERINGHAM M, GOOL L V, WILLIAMS C K I, et al. The pascal visual object classes (VOC) challenge[J].International Journal of Computer Vision, 2010, 88(2): 303–338.DOI:10.1007/s11263-009-0275-4 |
