现有的目标跟踪方法主要以生成式跟踪方法和判别式跟踪方法为主。前者[2-6]将跟踪问题视为搜索与目标模型最相似的区域,通过寻找使重构误差最小的区域来跟踪目标;后者[7-10]将跟踪问题视为二分类问题,其通过寻找目标与背景的最佳决策边界,将目标从背景中区分出来。生成式跟踪方法通过提取目标的重要特征建立目标的外观模型,但其在跟踪过程中未考虑目标的背景信息,忽略了许多区分目标与背景的重要信息;因此在背景相对简单的环境中具有较准确的跟踪结果,但当跟踪目标发生遮挡、旋转、尺度变化以及背景杂乱干扰时,其不能准确地建立目标的外观模型,跟踪结果很差;其代表方法主要有增量式学习跟踪(Incremental learning of Visual Tracing,IVT)算法[2]、特征跟踪(eigen tracker)算法[3]、均值漂移跟踪(mean shift tracker)算法[4]、部件跟踪(fragment-based tracker)算法[5]和基于跟踪分解(Visual Tracking Decomposition,VTD)算法[6];而判别式跟踪在跟踪过程中同时考虑目标及背景的变化信息,在环境发生较大变化时具有较强的鲁棒性,其代表方法主要有在线自适应增强跟踪(Online AdaBoost,OAB)算法[7]、集成跟踪(ensemble tracking)算法[8]、半监督在线自适应增强(semi-online boosting)跟踪算法[9]及多示例学习(Multiple Instance Learning,MIL)跟踪算法[10]。
MIL跟踪算法作为判别式跟踪算法的典型代表,在视频目标跟踪中获得了很大的成功。2011年,Babenko等[10]提出在线MIL目标跟踪算法,该算法利用多个样本同时学习,只要样本中包含一个正样本,就能够学习到正确的结果,从而保证分类器正确更新[11],但该算法中多示例包的构建采用haar-like特征[12],而该特征是一种基于结构的矩形特征,对目标的表达能力有限,只能描述水平、垂直等特定走向的结构,从而当所跟踪目标发生遮挡、尺度及光线变化时不能准确地提取目标信息,影响外观模型的准确建立;其次,该算法在构建分类器的过程中,对所有样本包中的正负样本示例赋予相同的权值,忽略了不同示例包对所跟踪目标的重要程度不同,最终影响算法的跟踪精度[13]。
针对上述问题,提出一种基于MIL框架的在线视觉目标跟踪方法,受文献[14-15]的启发,为增强特征表达的能力,针对MIL采用单一haar-like特征不能准确描述目标外观变化的特点,本文在haar-like[12]特征的基础上引入梯度直方图(Histogram of Gradients,HOG)[16]特征,图像灰度(intensity)特征作为互补特征构造目标外观模型。通过将多特征互补特性融入在线MIL过程中,克服在线多示例跟踪算法在跟踪过程中容易发生目标丢失及不能良好适应目标外观变化的问题;同时,依据各样本包中不同的正负样本示例对跟踪过程的重要性进行相应的权值分配,利用多特征的互补属性建立较为准确的目标外观模型构造相应的分类器;然后采用粒子滤波方法预测目标的位置,通过构造强分类器确定所跟踪目标的位置;最后,利用更新后的目标位置采样下一帧图像序列的正负样本包,用生成的分类器对正负样本包分类,进而跟踪目标。通过对不同的视频序列进行测试,实验结果表明,本文算法能够较好地解决跟踪漂移问题及对目标遮挡、光线变化、尺度变化及平面旋转具有较好的鲁棒性。
1 多特征表示的MIL跟踪 1.1 基于MIL的正负样本包选取 基于在线学习的目标跟踪将目标跟踪看成二分类问题,因此如何选取正负样本包对后续正确分类至关重要。传统的目标跟踪方法通常选取单个候选区域对目标进行跟踪,容易产生误差的累积,导致目标偏移或丢失。而MIL通过采样多候选目标区域生成正负样本包克服单候选目标区域跟踪算法的局限性[10, 13]。设目标和背景分别表示正负样本,用X+和X-表示,其正负样本包选取的具体步骤如下所述。
步骤1??初始化目标:在起始帧中手动选取待跟踪的目标,确定目标位置lt(x0)及搜索半径γ。
步骤2??选取正负样本包:
以当前目标位置lt(x0)为中心,α为半径采集N个正样本示例构成正样本包X+={x|lt(x)-lt(x0) < α}。
同理,以当前目标位置lt(x0)为中心,半径为α < ξ < β的区域内随机选取L个负示例构成负样本包X-={x|ξ < lt(x)-lt(x0) < β}。
步骤3??使用正负样本包更新分类器HK(·)。
步骤4??对于t+1帧图像,以第t帧的目标位置为中心,半径为γ的区域内采集样本示例,并用之前训练的分类器寻找具有最大置信度的样本x*,即x*=arg max p(y=1|x);以x*位置l(x*)作为t+1帧中目标的位置。
步骤5??基于新的目标位置l(x*),重复上述过程,获得下一帧目标的正负样本包X+及X-,并对示例样本赋予相应的类别标签,y={0, 1},y=1表示示例样本x为正示例,属于目标;反之x为负示例,属于背景。
1.2 基于多特征联合表示的目标外观模型 基于单一特征的跟踪在目标外观模型发生较大变化时显示出很多的局限性[10, 17]。不同的特征对目标的描述能力不同,而单一的特征对目标的描述能力有限[18]。传统的MIL跟踪算法仅采用单一的haar-like特征描述目标外观,由于haar-like特征定义为黑色矩形所有像素值之和减去白色区域所有像素值之和[12],这种矩形特征能反映图像局部的灰度变化。对目标的表达能力有限,只能描述水平、垂直等特定走向的结构,因此仅使用haar-like特征描述目标外观其判别能力有限。从而降低分类器的分类性能,以致影响算法的跟踪效果[19]。针对上述问题,受文献[18, 20]的启发,为了增强特征的表达能力,本文联合图像的灰度特征、haar-like特征及HOG特征来构造目标的外观模型。HOG特征描述了图像局部区域的梯度强度和梯度方向的分布情况,该特征对光照和局部几何变化都具有较强的鲁棒性。而基于MIL的跟踪主要是在灰度级图像上进行的,而灰度特征能在灰度级图像上较好地保留图像的原始信息。因此,本文引入HOG特征和灰度特征的主要目的是为了补偿haar-like特征的不足,在haar-like特征表现较差的区域HOG特征得到较好的结果。基于此,本文提出一种基于多示例跟踪框架的多特征联合表示及考虑权值分配的目标跟踪方法。该方法充分利用不同特征在目标描述能力方面的互补特性,克服了传统MIL跟踪算法采用单一特征进行目标描述时表现出的局限性。
首先,经过1.1节方法提取获得N个正样本示例{x1j, j=0, 1, …, N-1}和L个负样本示例{x0j, j=N, …, N+L-1},由此构成两个正负样本包{X+, X-}。然后,对该样本包中所有的示例分别提取其HOG特征、haar-like特征和灰度特征。对于正负样本包中的每个示例,提取其HOG特征fHOG=(v1, v2, …vN-1, vN, …vN+L-1)、haar-like特征fhaar=(u1, u2, …uN-1, uN, …uN+L-1)及灰度特征fintensity=(q1, q2, …qN-1, qN, …qN+L-1)。由每个示例的HOG、haar-like及灰度特征所组成的特征样本集f(x)={fHOG, fhaar, fintensity}构造目标的外观模型。
1.3 基于权值分配的多示例分类器 由MIL跟踪算法定义[10],若包中含有一个正示例即认为是正样本,若包中不存在正示例即认为负样本;其不区分所采集的多个正负样本包,对所有的示例赋予相同的权值,忽略示例间的差异性,从而使分类器的分类性能下降,造成跟踪漂移等问题。针对此问题,本文在正负样本包概率的计算中,考虑各示例对包的重要程度并赋予相应的权值;依据Bhattacharyya系数计算不同正样本示例与目标之间的相似性衡量其对样本包的重要程度,从而进行相应的权值分配。
1.3.1 正样本包的权值分配 本文在正负样本包概率的计算中,权值分配以各示例所提取的3种特征与当前目标3种特征之间的相似度来决定。设样本x10为当前帧的目标位置,其相似度采用Bhattacharyya系数ρ来度量[21],即
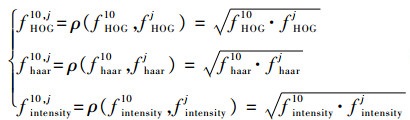 | (1) |
式中:f10为当前目标的特征;j为第j个示例。
则正样本包的概率为
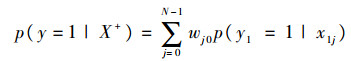 | (2) |
式中:p(y=1|x)=σ(HK(x))为样本x的后验概率,H(·)为强分类器;p(y1=1|x1j)=σ(HK(x1j))为样本x1j的后验概率;权值wj0定义为
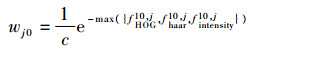 | (3) |
因此,本文正样本示例的权值分配依据其对包概率的重要程度决定。正样本包的概率与所描述示例的特征在前后帧中的相似度有关,相似度大的特征对包概率的贡献程度大,相似度小的特征对包概率的贡献程度小;当目标外观发生较小变化时,各特征在前后帧之前的变化较小,故而各特征都具有较高的相似度;反之,目标外观发生剧烈变化时,各特征在前后帧中发生较大的变化。如,当目标发生遮挡时,haar-like特征对遮挡具有较强的鲁棒性,其在前后帧中的变化较小,具有较高的相似度,而HOG特征和灰度特征对遮挡敏感,在前后帧中发生较大的变化,其具有较小的相似度;当目标发生姿势及尺度变化时,HOG特征能够较好地适应这种变化,因此其具有较高的相似度,而haar-like特征和灰度特征不能适应目标的这种变化,故而其具有较小的相似度。因此本文通过联合haar-like、HOG及灰度特征对目标外观进行建模,并依据其描述目标能力的大小进行相应包概率权值的分配,有效克服传统方法MIL的不足,提高算法跟踪的准确性。
1.3.2 负样本包的权值分配 由于负包中的示例与当前帧中的目标位置较远,其包中各示例与所跟踪的目标有很大的区别,故而可以认为其对目标跟踪结果的影响较小。因此可视负包中各示例对包具有相同的重要性,在进行负包概率计算时采用恒定的权值分配策略,即
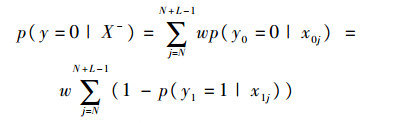 | (4) |
式中:w为一常数。
1.3.3 分类器构造 基于上述正负样本权值分配策略,可获得正负样本包的log-likelihood函数为
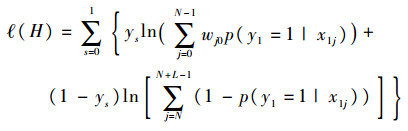 | (5) |
对于所采集的正样本包X+采用贝叶斯估计理论计算其后验概率:
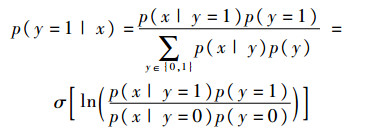 | (6) |
式中:σ(z)=1/(1+e-z)为sigmiod函数;y∈{0, 1}为x样本的二值标签。
由每个样本的特征所组成的特征样本集f(x)={fHOG, fhaar, fintensity}构成目标的外观模型,根据样本示例x所提取的特征向量F(x)=(f1(x), f2(x), …, fK(x))建立分类器表示目标的外观模型,即
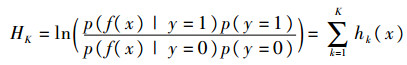 | (7) |
其中:hk(·)为弱分类器,其生成规则为
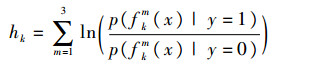 | (8) |
式中:fkm(x)={fHOG10, j, fhaar10, j, fintensity10, j},m=1, 2, 3。hk(·)服从Gaussian分布,即p(fkm(xij)|yi=1)~N(μ1, σ1)和p(fkm(xij)|yi=0)~N(μ0, σ0),则μ1和σ1的更新规则为
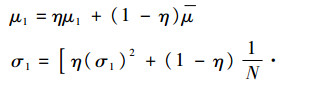 | (9) |
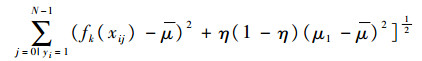 | (10) |
式中:

因此,式(6)中的后验概率可表示为
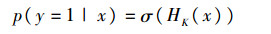 | (11) |
在线MIL分类器是从由M个弱分类器构成的分类器集Φ={h1, h2, …, hM}中挑选出K个弱分类器级联形成一个强分类器HK,用于确定下一帧中目标的位置信息。即
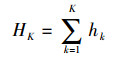 | (12) |
通过最大化包的log-likelihood函数
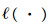
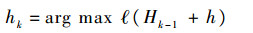 | (13) |
式中:
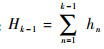
2 本文算法流程 基于上述分析,本文在MIL框架下,将权值分配及多特征表示融入MIL跟踪中,该算法充分考虑了特征的互补特性及其在跟踪过程中的重要性,并根据其重要性分配相应的权值建立包的似然函数,从而可以有效选择最具判别力的分类器,提高分类器的性能和跟踪算法的精度。其算法流程图如图 1所示。
 |
| 图 1 基于权值分配及多特征联合表示的MIL跟踪算法流程图 Fig. 1 Flowchart of MIL tracking algorithm based on weight distribution and joint multiple feature representation |
| 图选项 |
综上所示,基于权值分配及多特征联合表示的MIL跟踪算法具体步骤如下所述。
步骤1??输入视频图像,在起始帧中手动选取待跟踪的目标,生成正负样本示例包{X+, X-},其中X+={x1j, y1=1, j=0, 1,…, N-1},X-={x0j, y0=0, j=N, …, N+L-1};对于第t帧的目标位置lt*,采用粒子滤波估计下一帧中目标的位置l(x)={l1(x), l2(x), …, ln(x)},依据目标位置得到图像的正负样本包Xγ={X+, X-}。
步骤2??利用样本包{X+, X-}更新弱分类器集Φ中所有的M个弱分类器,初始化强分类器H0(xij),i∈{0, 1}。
步骤3??用生成的示例样本根据1.2节中所述特征提取算法提取样本集的特征,分别生成其特征向量。依据式(2)、式(4)及式(5)分别计算正负样本包的概率及包的log-likelihood函数。
步骤4??使用MIL分类器对每一个示例x进行估计p(y=1|x)。
步骤5??依据式(13)选择最具判别力的弱分类器hk,从而构造相应的强分类器。
步骤6??依据式(9)、式(10)分别计算分类器的参数(μ1, σ1, μ0, σ0)。
步骤7??更新目标的位置:
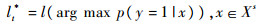 |
步骤8获取下一帧新的正负样本包:
 |
步骤9输出当前帧目标的位置
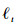
3 实验结果与分析 为了验证文中跟踪算法的有效性,将该算法与IVT[2]、MIL[10]及OAB[7]跟踪算法进行对比,如图 2所示。对所有的测试视频都采用手工标定起始帧中待跟踪目标的位置;并对所有测试视频进行定性和定量两方面的评估分析。本文在实验过程中,设搜索半径γ=30,学习率η=0.85;正样本的采样半径α=5,数目N=45;负样本的采样半径ξ=2α, β=1.5γ,数目L=40;弱分类器数目M=150,从中选出K=15构造强分类器。
 |
| 图 2 本文算法与其他3种算法在5组测试序列上的对比实验结果 Fig. 2 Experimental results of proposed algorithm compared with other 3 algorthms on 5 groups of test sequences |
| 图选项 |
在定量分析方面,选取目标中心位置误差进行评估分析,其为各跟踪算法得到的目标中心位置与真实目标中心位置的欧式距离,即:Eerror=
 |
| 图 3 不同算法的中心位置误差曲线 Fig. 3 Center position error curves of different algorithms |
| 图选项 |
表 1 平均中心位置误差 Table 1 Average center position error
| 像素 | ||||
| 视频 | IVT | MIL | OAB | 本文算法 |
| mountainBike | 12.07* | 15.28 | 28.32 | 11.69** |
| faceocc1 | 24.32* | 32.02 | 88.69 | 22.19** |
| faceocc2 | 16.22* | 18.15 | 24.32 | 8.87** |
| girl | 29.37 | 14.12 | 8.56* | 2.66** |
| singer1 | 7.97* | 21.86 | 18.31 | 5.30** |
| 平均 | 17.99* | 20.29 | 33.64 | 10.14** |
| 注:*代表次优;**代表最优。 | ||||
表选项
实验1??非刚性目标尺度变化
如图 2(a)所示,在mountainBike视频序列中,跟踪目标为一个在复杂背景下快速移动的非刚体目标,由于在跟踪过程中伴有目标的快速运动,MIL和OAB跟踪算法在第195帧开始出现不同程度的偏移,并在随后帧的跟踪过程中其跟踪框不能恢复,平均中心位置误差分别为15.28像素和28.32像素;而IVT和文中算法较理想地实现了对非刚性目标的跟踪,由于在整个视频序列中,所跟踪目标的尺度和外观并没有发生大的变化,IVT方法在该条件下能够实现对非刚性目标较为准确的跟踪,平均中心位置误差为12.07像素,仅次于本文跟踪算法,本文算法的跟踪误差为11.69像素,在4种跟踪方法中处于最优。
实验2??遮挡和旋转
在实验序列faceocc1中存在若干帧的脸部遮挡,如图 2(b)所示,在该视频序列中,目标位置几乎没有发生改变,从实验结果可以看出,文中方法、IVT跟踪算法和MIL跟踪算法都能较有效地处理这种遮挡,其平均中心位置误差分别为22.19、24.32和32.02像素;而OAB跟踪算法不能有效地处理遮挡,从第90帧开始就出现跟踪偏移的现象,其平均中心位置误差为88.69像素;各种方法的跟踪误差曲线如图 3所示。
视频序列faceocc2相比序列faceocc1增加了脸部旋转,且其遮挡较faceocc1序列严重。在跟踪的全过程中,如图 2(c)所示,其脸部旋转过程(321~540帧)伴有较为严重的遮挡(491帧);从第567帧开始到结束,跟踪目标戴上一顶与其T恤颜色相近的帽子,随后又用书对自己的脸部进行严重的遮挡(715帧);由于在跟踪过程中存在严重的遮挡使目标外观发生了剧烈的变化,IVT跟踪方法不能适应这种变化,从第579帧开始,跟踪发生轻微的漂移且跟踪框大小发生改变,以致在跟踪后期出现严重遮挡时(715帧)完全丢失目标;OAB跟踪算法在目标戴上帽子(579帧)瞬间,由于目标外观发生大的变化出现短时跟踪漂移现象,而在随后的跟踪过程中(620帧)恢复跟踪,接着,由于在第715帧目标出现严重遮挡,OAB算法又出现跟踪漂移的现象,严重的遮挡使目标外观发生剧烈变化,从而导致OAB算法在随后的跟踪中一直没有恢复跟踪;而MIL跟踪算法在跟踪的最后阶段(744帧开始)出现跟踪漂移的现象;文中算法在跟踪的全过程中都具有较为理想的跟踪效果,其平均中心位置误差仅为8.87像素,而对比算法IVT、MIL、OAB的平均中心位置误差分别为16.22、18.15和24.32像素。
视频序列girl跟踪过程相比faceocc1和faceocc2增加了360°的旋转,目标由静及远的尺度变化及相似目标遮挡的干扰。在跟踪的全过程中,目标一直经历平面的尺度变化和旋转,从78~130帧目标经历了第1次360°的平面旋转,IVT跟踪算法不能适应这种严重的旋转变化,从90帧开始跟踪框大小发生变化,在129帧已基本完全丢失目标;MIL和OAB算法在这一过程中出现略微的偏移;在165~265帧目标经历第2次360°的旋转时,MIL已出现较大的跟踪偏移;在第312帧目标进行脸部旋转时,OAB也出现跟踪漂移现象;从415帧开始,当一男子对目标进行遮挡干扰时,MIL和OAB出现不同程度的跟踪偏移现象(434帧),当遮挡消失后,MIL和OAB发生不同程度的恢复(446,449帧);本文跟踪算法在跟踪的全过程中都能较理想地跟踪目标,其跟踪鲁棒性较强,平均位置误差仅为2.66像素,而对比算法IVT、MIL及OAB的平均中心位置误差分别为7.97、21.86和18.31像素。
实验3??光线、尺度变化
在singer1视频序列中,由于存在严重的光线变化加剧了跟踪的难度。由图 2(e)、图 3和表 1可得,本文跟踪算法可以很好地处理光线剧烈变化问题。本文算法的跟踪误差仅为5.3像素;IVT跟踪算法在跟踪的全过程中也能较理想地跟踪上目标,其效果仅次于本文算法,跟踪误差为7.98像素;MIL和OAB跟踪算法在出现强光干扰(77帧)时,无法对准目标,跟踪框比真实的目标要大,且在跟踪后期由于摄像机视觉的变化,导致目标尺度发生变化,使MIL和OAB出现跟踪失败的现象,IVT的跟踪框也略微大于真实的目标(345帧),其MIL和OAB的平均中心位置误差分别为20.29像素和33.64像素,各种算法的中心位置误差曲线如图 3所示。
从实验结果可以得到,本文跟踪算法对场景光线剧烈变化、遮挡、尺度变化及平面旋转等干扰具有较强的跟踪鲁棒性,取得了较为理想的跟踪结果,其准确性和抗干扰能力优于其对比算法,从表 1可得,本文算法在5组测试视频序列上的平均中心位置误差远小于其他3种算法,仅为10.14像素,IVT、MIL和OAB的中心位置误差分别为17.99、20.29和33.64像素。
由于本文跟踪算法的目标表示是基于intensity、haar-like及HOG特征,而其对比算法IVT的目标表示基于灰度特征,MIL及OAB的目标表示基于haar-like特征。因此,其对比算法都是基于单一特征提取的,而本文算法在目标表示过程中进行多特征提取。由于特征提取在目标跟踪中相对比较耗时,因此本文算法的实时性相对于其对比方法较差,其平均帧率约为12帧/s。因此,如何在保证跟踪精度的同时提高跟踪的速度也是文中算法今后的主要研究方向之一。文中所提算法的主要局限性在于:①对所有视频序列都提取相同的3种互补特征,不能根据视频属性自适应的提取特征;②不能具体衡量出各特征描述目标能力的大小;③文中提取多个互补特征相对耗时,如何快速地提取目标的互补特征,是文中算法今后的主要研究方向之一。
4 结论 1)?本文通过将多特征互补特性融入在线多示例学习过程中,利用多特征的互补属性建立准确的目标外观模型,克服在线多示例跟踪算法对目标外观变化描述不足的问题。
2)?采用多特征联合表示目标外观构造分类器,依据Bhattacharyya系数计算不同正样本示例与目标之间的相似性,衡量其对样本包的重要程度并进行相应的权值分配,提高跟踪精度。
3)?实验结果表明,该跟踪算法对场景光线剧烈变化、遮挡、尺度变化及平面旋转等干扰具有较强的跟踪鲁棒性和较理想的跟踪精度。但该算法在处理较长时间的遮挡、目标全部遮挡以及目标外观发生大的变化时无法实现正确的目标跟踪,并且该算法的实时性较差,如何更好地解决此类问题是今后研究的方向。
参考文献
| [1] | YILMAZ A, JAVED O, SHAH M. Object tracking: A survey[J].ACM Computing Surveys, 2006, 38(4): 1–45. |
| [2] | ROSS D A, LIM J, LIN R S, et al. Incremental learning for robust visual tracking[J].International Journal of Computer Vision, 2008, 77(1-3): 125–141.DOI:10.1007/s11263-007-0075-7 |
| [3] | BLACK M, JEPSON A. Eigentracking:Robust matching and tracking of objects using view-based representation[J].International Journal of Computer Vision, 1998, 26(1): 63–84.DOI:10.1023/A:1007939232436 |
| [4] | COMANICIU D, RAMESH V, MEER P.Real-time tracking of non-rigid objects using mean shift[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2000:142-149. |
| [5] | ADAM A, RIVLIN E, SHIMSHONI I.Robust fragments-based tracking using the integral histogram[C]//Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2006:798-805. |
| [6] | KWON J, LEE K M.Visual tracking decomposition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2010:1269-1276. |
| [7] | GRABNER H, GRABNER M, BISCHOF H.Real-time tracking via on-line boosting[C]//Proceedings of the British Machine Vision Conference 2006.Edinburgh:British Machine Vision Association, 2006:47-56. |
| [8] | AVIDAN S. Ensemble tracking[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(2): 261–271.DOI:10.1109/TPAMI.2007.35 |
| [9] | GRABNER H, LEISTNER C, BISCHOF H.Semi-supervised on-line boosting for robust tracking[C]//Proceedings of the 10th European Conference on Computer Vision.New York:Springer Berlin Heidelberg, 2008:234-247. |
| [10] | BABENKO B, YANG M, BELONGIE S. Robust object tracking with online multiple instance learning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8): 1619–1632.DOI:10.1109/TPAMI.2010.226 |
| [11] | LIN R S, ROSS D A, LIM J, et al.Adaptive discriminative generative model and its applications[C]//Advances in Neural Information Processing Systems 17.Cambridge:MIT Press, 2004:801-808. |
| [12] | VIOLA P, JONES M.Rapid object detection using a boosted cascade of simple features[C]//Proceedings of the 2001 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2001:511-518. |
| [13] | ZHANG K, SONG H. Real-time visual tracking via online weighted multiple instance learning[J].Pattern Recognition, 2013, 46(1): 397–411.DOI:10.1016/j.patcog.2012.07.013 |
| [14] | XU C, TAO D C, XU C.A survey on multi-view learning[J/OL].Computer Science, 2013.https://arxiv.org/abs/1304.5634. |
| [15] | MORENO-NOGUER F, SANFELIU A, SAMARAS D. Dependent multiple cue integration for robust tracking[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(4): 670–685.DOI:10.1109/TPAMI.2007.70727 |
| [16] | DALAL N, TRIGGS B.Histograms of oriented gradients for human detection[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2005, 886-893. |
| [17] | KALAL Z, MATAS J, MIKOLAJCZYK K.P-N learning:Bootstrapping binary classifiers by structural constraints[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2010:49-56. |
| [18] | YOON J H, KIM D Y, YOON K J.Visual tracking via adaptive tracker selection with multiple features[C]//Proceedings of the 12th European Conference on Computer Vision.New York:Springer Berlin Heidelberg, 2012:28-41. |
| [19] | 宁纪锋, 赵耀博, 石武祯. 多通道Haar-like特征多示例学习目标跟踪[J].中国图象图形学报, 2014, 19(7): 1038–1045.NING J F, ZHAO Y B, SHI W Z, et al. Multiple instance learning based object tracking with multi-channel Haar-like feature[J].Journal of Image and Graphics, 2014, 19(7): 1038–1045.(in Chinese) |
| [20] | YOON J, YANG M, YOON K. Interacting multiview tracker[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015(99): 1–14. |
| [21] | DJOUADI A, SNORRASON O, GARBER F. The quality of training sample estimates of the bhattacharyya coefficient[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 1990, 12(1): 92–97.DOI:10.1109/34.41388 |
