| |
|
| 基于深度神经网络和Bottleneck特征的说话人识别系统 |
| 田垚, 蔡猛, 何亮, 刘加 |
| 清华大学 电子工程系, 清华信息科学与技术国家实验室(筹), 北京 100084 |
|
| Speaker recognition system based on deep neural networks and bottleneck features |
| TIAN Yao, CAI Meng, HE Liang, LIU Jia |
| Tsinghua National Laboratory for Information Science and Technology, Department of Electronic Engineering, Tsinghua University, Beijing 100084, China |
| |
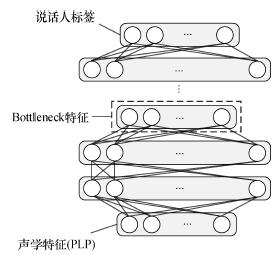
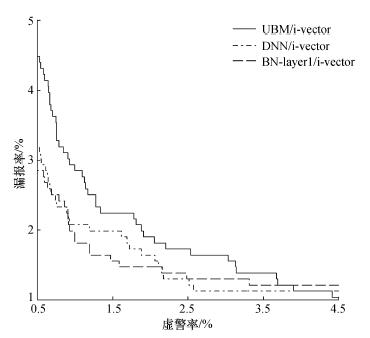
| 摘要近来,一种结合语音识别中深度神经网络(deep neural network,DNN)模型和说话人识别中身份认证矢量(identity vector,i-vector)模型的方法被证明对说话人识别十分有效。为了进一步提升系统性能,该文提出使用基于说话人标签的DNN模型提取Bottleneck特征代替该模型中的短时频谱特征来计算充分统计量,从而使统计量中包含更多有利于说话人识别的信息。在美国国家标准与技术研究院说话人识别库2008年度女性电话对电话英语测试任务上进行的实验证明了该方法的有效性。相比原来的短时频谱特征,基于Bottleneck特征的说话人识别系统在等错误率和最小检测代价上相对减小了7.65%和5.71%。 |
| 关键词 :说话人识别,深度神经网络,Bottleneck特征 |
| Abstract:A hybrid model combining the deep neural network (DNN) for speech recognition and the i-vector model for speaker recognition has been shown effective for speaker recognition. The system performance is further improved by using the DNN with speaker labels to extract bottleneck features to replace the original short-term spectral features for statistics extractions to make the statistics contain more speaker-specific information to improve the speaker recognition. Tests on the NIST SRE 2008 female telephone-telephone-English task demonstrate the effectiveness of this method. The relative improvements of the bottleneck features are 7.65% for the equal error rate(EER) and 5.71% for the minium detection function(minDCF) compared with the short-term spectral features. |
| Key words:speaker recognitiondeep neural networkBottleneck features |
| 收稿日期: 2016-06-20 出版日期: 2016-11-26 |
|
| 通讯作者:刘加,教授,E-mail:liuj@tsinghua.edu.cnE-mail: liuj@tsinghua.edu.cn |
| [1] | Kinnunen T, Li H. An overview of text-independent speaker recognition:From features to supervectors[J]. Speech Communication, 2010, 52(1):12-40. |
| [2] | Dehak N, Kenny P, Dehak R, et al. Front-end factor analysis for speaker verification[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4):788-798. |
| [3] | Hinton G, Deng L, Yu D, et al. Deep neural networks for acoustic modeling in speech recognition:The shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6):82-97. |
| [4] | Dahl G E, Yu D, Deng L, et al. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(1):30-42. |
| [5] | Yaman S, Pelecanos J, Sarikaya R. Bottleneck features for speaker recognition[C]//Proceedings on Odyssey. Singapore:International Speech Communication Association, 2012:105-108. |
| [6] | Variani E, Lei X, McDermott E, et al. Deep neural networks for small footprint text-dependent speaker verification[C]//Proceedings on ICASSP. Florence, Italy:IEEE Press, 2014:4052-4056. |
| [7] | Ghahabi O, Hernando J. i-Vector modeling with deep belief networks for multi-session speaker recognition[J]. Network, 2014, 20:13. |
| [8] | Lei Y, Scheffer N, Ferrer L, et al. A novel scheme for speaker recognition using a phonetically-aware deep neural network[C]//Proceedings on ICASSP. Florence, Italy:IEEE Press, 2014:1695-1699. |
| [9] | Bengio Y. Learning deep architectures for AI[J]. Foundations and Trends in Machine Learning, 2009, 2(1):1-127. |
| [10] | Hinton G, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7):1527-1554. |
| [11] | Garcia-Romero D, Espy-Wilson C Y. Analysis of i-vector length normalization in speaker recognition systems[C]//Proceedigs on Interspeech. Florence, Italy:International Speech Communication Association, 2011:249-252. |
| [12] | Prince S J D, Elder J H. Probabilistic linear discriminant analysis for inferences about identity[C]//Proceedings on ICCV. Rio de Janeiro, Brazil:IEEE Press, 2007:1-8. |
| [13] | Taigman Y, Yang M, Ranzato M A, et al. Deepface:Closing the gap to human-level performance in face verification[C]//Proceedings on CVPR. Columbus, OH, USA:IEEE Press, 2014:1701-1708 |