| 针对无切分维吾尔文文本行识别的字符模型优化 |
| 姜志威, 丁晓青, 彭良瑞 |
| 清华大学 电子工程系, 智能技术与系统国家重点实验室, 清华信息科学与技术国家实验室, 北京 100084 |
| Character model optimization for segmentation-free Uyghur text line recognition |
| JIANG Zhiwei, DING Xiaoqing, PENG Liangrui |
| State Key Laboratory of Intelligent Technology and Systems, Tsinghua National Laboratory for Information Science and Technology, Department of Electronic Engineering, Tsinghua University, Beijing 100084, China |
摘要:
| |||
| 摘要基于隐含Markov模型(hidden Markov model, HMM)的无切分文本行识别方法能够利用概率图的思想, 同步完成文本行图像的切分与识别, 避免因字符预切分失败而导致的识别错误, 但对字符模型的设计与训练要求很高, 并且在多字体融合问题中难以提高模型泛化性能。该文通过分析模型状态在图像层面的聚类意义, 先提出基于观测合理聚类的模型结构优化方法, 再提出结构与参数相结合的字符模型优化策略, 最后将其应用于多字体维吾尔文文本行的无切分识别系统。实验结果表明, 该方法能够改善模型的状态分配合理性, 并且在多字体融合问题中提高了模型泛化性能和状态利用效率。 | |||
| 关键词 :信息处理,文字识别,隐含Markov模型,统计学习,维吾尔文 | |||
| Abstract:A text line recognition method was developed without pre-segmentation using a hidden Markov model (HMM) for simultaneously segmenting and recognizing text line images. The algorithm uses a probability graph to reduce recognition error from failed pre-segmentation results. However, the HMM design and training is complicated and the HMM generalization performance can not be easily improved in multi-font texts. Therefore, a character model optimization method with reasonably clustered observations was developed based on the most common HMM state in images. Then, a method was developed to optimize the model structure and parameters together for a multi-font Uyghur text line recognition system. Tests show that this method improves the state allocation, the generalization performance and the state efficiency of the character model for multi-font texts. | |||
| Key words:information processingcharacter recognitionhidden Markov model (HMM)statistical learningUyghur | |||
| 收稿日期: 2015-04-15 出版日期: 2015-09-30 | |||
| |||
| 通讯作者:丁晓青,教授,E-mail:dingxq@tsinghua.edu.cnE-mail: dingxq@tsinghua.edu.cn | |||
| 引用本文: |
| 姜志威, 丁晓青, 彭良瑞. 针对无切分维吾尔文文本行识别的字符模型优化[J]. 清华大学学报(自然科学版), 2015, 55(8): 873-877,883. JIANG Zhiwei, DING Xiaoqing, PENG Liangrui. Character model optimization for segmentation-free Uyghur text line recognition. Journal of Tsinghua University(Science and Technology), 2015, 55(8): 873-877,883. |
| 链接本文: |
| http://jst.tsinghuajournals.com/CN/或 http://jst.tsinghuajournals.com/CN/Y2015/V55/I8/873 |
图表:
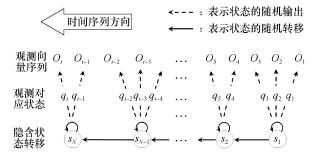 |
| 图1 HMM 基本原理示意图 |
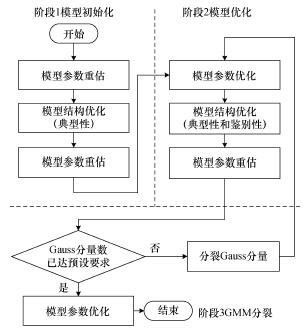 |
| 图2 结构与参数相结合的字符模型优化策略 |
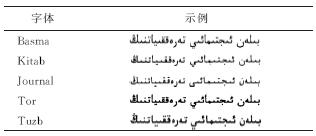 |
| 表1 THOCR-Uy360数据库的5种字体 |
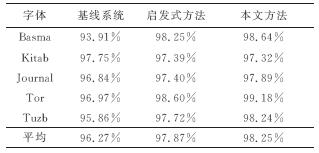 |
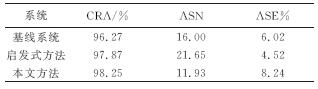
| 表2 各个系统的CRA |
 |
| 表3 各个系统的建模效率 |
 |
| 表3 各个系统的建模效率 |
参考文献:
| [1] 王华, 丁晓青, 哈力木拉提. 多字体多字号印刷维吾尔文字符识别 [J]. 清华大学学报(自然科学版), 2004, 44(7): 946-949. WANG Hua, DING Xiaoqing, Halmurat. Multi-font multi-size printed Uyghur character recognition [J]. Journal of Tsinghua University (Science and Technology), 2004, 44(7): 946-949. (in Chinese) [2] 贾建忠. 脱机印刷体维吾尔文字识别特征选择和分类器设计方法的研究 [D]. 苏州: 苏州大学, 2008.JIA Jianzhong. The Research of feature selection and classifier design for Printed Offline Uygur character recognition [D]. Suzhou: Soochow University, 2008. (in Chinese) [3] 陈卿. 印刷体维吾尔文识别系统分类识别技术研究 [D]. 新疆: 新疆大学, 2012.CHEN Qing. Classification and Recognition Technology Research in Print Uighur Recognition System [D]. Xinjiang: Xinjiang University, 2012. (in Chinese) [4] 陆钢锋. 印刷体维吾尔文识别系统识别技术相关研究 [D]. 新疆: 新疆大学, 2013.LU Gangfeng. Recognition Technology Correlational Research in Print Uighur Recognition System [D]. Xinjiang: Xinjiang University, 2013. (in Chinese) [5] 阿地力·依米提, 刘吉超, 杜力坤·苏来曼. 复杂背景图像中维吾尔文字切分与识别技术的研究 [J]. 新疆师范大学学报(自然科学版), 2014, 33(1): 65-68.Adili Y, LIU Jichao, Dulikum S. Study on Character Segementation and Recognition Technology of Uyghur in Image with complex Background [J]. Journal of Xinjiang Normal University (Natural Sciences Edition), 2014, 33(1): 65-68. (in Chinese) [6] Zimmermann M, Bunke H. Hidden Markov model length optimization for handwriting recognition systems [C]// Proc of International Workshop on Frontiers in Handwriting Recognition. Niagara on the Lake, Canada: IEEE Press, 2002, 369-374. [7] Gunter S, Bunke H. Optimizing the Number of States, Training Iterations and Gaussians in an HMM-based Handwritten Word Recognizer [C]// Proc 7th Int Conf on Document Analysis and Recognition. Edinburgh, Scotland, UK: IEEE Press, 2003, 472-476. [8] JIANG Zhiwei, DING Xiaoqing, PENG Liangrui, et al. Analyzing the information entropy of states to optimize the number of states in an HMM-based off-line handwritten Arabic word recognizer [C]// Proc 21st Int Conf on Pattern Recognition. Tsukuba, Japan: IEEE Press, 2012, 697-700. [9]Kullback S, Leibler R A. On information and sufficiency [J]. The Annals of Mathematical Statistics, 1951, 22(1): 79-86. [10]王欢良, 韩纪庆, 郑铁然. 高斯混合分布之间K-L散度的近似计算 [J]. 自动化学报, 2008, 34(5): 529-534.WANG Huanliang, HAN Jiqing, ZHENG Tieran. Approximation of Kullback-Leibler Divergence between Two Gaussian Mixture Distributions [J]. Acta Automatica Sinica, 2008, 34(5): 529-534. (in Chinese) [11]Bicego M, Murino V, Figueiredo M A T. A sequential pruning strategy for the selection of the number of states in hidden Markov models [J]. Pattern Recognition Letters, 2003, 24(9): 1395-1407. [12]Fink G A. Markov Models for Pattern Recognition: From Theory to Applications [M]. New York: Springer, 2008. [13]Clemente I A, Heckmann M, Sagerer M, et al. Multiple sequence alignment based bootstrapping for improved incremental word learning [C]// Proc 35th Int Conf on Acoustics, Speech, and Signal Processing. Dallas, TX, USA: IEEE Press, 2010, 5246-5249. [14]Young S, Evermann G, Gales M, et al. The HTK Book (for HTK Version 3.4) [M]. Cambridge, UK: Cambridge University, 2009. [15]Al-Hajj R M. Combining slanted-frame classifiers for improved HMM-based Arabic handwriting recognition [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2009, 31(7): 1165-1177. [16]Mahmouda S A, Ahmada I, Al-Khatiba W G, et al. KHATT: An open Arabic offline handwritten text database [J]. Pattern Recognition, 2014, 47(3): 1096-1112. |
相关文章:
|
