 , 王飞儿1,2
, 王飞儿1,2 , 俞洁3
, 俞洁31. 浙江大学环境与资源学院, 杭州 310058;
2. 浙江省水体污染控制与环境安全技术重点实验室, 杭州 310058;
3. 浙江省环境监测中心, 杭州 310012
收稿日期: 2019-11-04; 修回日期: 2019-12-17; 录用日期: 2019-12-17
基金项目: 国家水体污染控制与治理科技重大专项(No.2018ZX07208-009)
作者简介: 王一旭(1994-), 男, E-mail:21814071@zju.edu.cn
通讯作者(责任作者): 王飞儿, E-mail:wangfeier@zju.edu.cn
摘要:流域水环境质量空间分布特征分析是推进流域精细化管理的基础.本研究基于流域特征指标与水质的关联性,以子流域为分析单元,利用自组织映射人工神经网络模型(SOM)对苕溪流域水质数据聚类分析为3类后与随机森林模型(RF)进行耦合,对全流域水质进行了空间差异性评估.研究结果显示,上游山地区域水质较好,而平原河网人口集聚区的CODMn、NH3-N及TP浓度较高,山地与平原过渡地带水质则主要受到CODMn和TN的影响.采用自然环境、社会经济及土地利用/覆盖指标作为流域特征进行水质分级模式识别,SOM与RF模型耦合模型的准确率稳定在80%左右;在对强相关性特征进行筛选识别后,将蒸发蒸腾量、坡度、人口密度、大于10℃积温、旱地占比、城镇用地占比及景观多样性指数为作为输入特征,准确率可达83%,可以有效地开展全流域水质分级评估.
关键词:水质评估机器学习模式识别自组织映射人工神经网络模型(SOM)随机森林模型(RF)
Self-organizing map random forest coupling model based spatial heterogeneity evaluation of water quality in the watershed
WANG Yixu1
, WANG Feier1,2, YU Jie31. College of Environmental and Resources Sciences, Zhejiang University, Hangzhou 310058;
2. Zhejiang Provincial Key Laboratory for Water Pollution Control and Environmental Safety, Hangzhou 310058;
3. Zhejiang Provincial Environmental Monitoring Center, Hangzhou 310012
Received 4 November 2019; received in revised from 17 December 2019; accepted 17 December 2019
Abstract: A systematic understanding of the spatial heterogeneity of water quality within watershed is very important for precision watershed management.In this study,sub-watershed scaled water monitoring data in Tiaoxi watershed was classified into 3 clusters by self-organizing map(SOM),and the cluster results was used as input features of water quality characteristics to train random forest model(RF).The trained RF model was then applied to the spatial heterogeneity assessment of watershed water quality.Results showed that water quality was better in the upstream mountainous region,and the concentrations of CODMn,NH3-N and TP were higher the plain area with high population density.The water quality of mid-stream area was mainly influenced by CODMn.Water quality pattern recognition was conducted by using watershed features including natural environmental and socio-economic features and land use/cover,and the generalization accuracy of SOM-RF coupling model was approximately 80%.After the identification of strongly correlated features,the accuracy of the model can reach 83% by using evapotranspiration,slope,population density,accumulated temperature greater than 10 degrees Celsius,dry field,urban are proportion,and the Shannon-Ville index of for landscape diversity as input features.The results indicate SOM and RF coupling model can provide decision support for water quality management and spatial control in the watershed.
Keywords: water quality assessmentmachine learningpattern recognitionself-organizing map(SOM)random forest model(RF)
1 引言(Introduction)流域水环境健康状况是流域自然特征与人类活动综合作用的结果(Sweeney, 2004), 水质的优劣则是水环境健康状况的直接反映.流域水环境评估是流域水环境管理的基础, 目前流域水环境评估或目标考核主要以现有的常规水质监测点位的数据为基础.然而常规水质监测点位在一个流域分布是有限的, 相应的水质数据仅能代表一定范围内的水质状况, 且容易受到点位布设的主观性影响(蒋艳君等, 2016), 难以对流域整体水质状况进行全面评估.
流域水质状况是多种复杂环境过程耦合的结果, 很大程度上受到诸如人类活动、土地利用/覆盖、土地管理、气候、大气沉降和地形等流域特征的影响(Sharpley et al., 2014; Janardan et al., 2018).目前有关流域自然特征与水质的相关性或内在关联性研究相对较少(Fatehi et al., 2015).随着环境信息化的发展, 利用环境大数据来预测流域水质演变、开展流域环境特征与水质关联性分析的应用越来越多(Singh et al., 2009; Mohammadpour et al., 2015; Woldesenbet et al., 2016; Janardan et al., 2018), 特别是利用长时间序列数据的积累, 采用基于机器学习算法的大数据模型来预测水质已成为一种趋势(Holloway et al., 2018; Amir et al., 2018).因此, 基于大数据集合来表征流域环境特征与水质相关性, 并构建相应的数据驱动模型来预测流域水质的演变, 对于流域精细化管理具有重要的现实意义.
基于此, 本研究拟以太湖流域的子流域苕溪流域为研究对象, 尝试利用集成式机器学习算法模型强大的非线性拟合能力, 探索流域特征指标的空间异质性对水质的影响, 并将其应用于监测数据缺失区域的水质分析及评估, 以期为流域水环境管理提供科学支撑.
2 材料和方法(Materials and methods)2.1 研究区域苕溪位于太湖流域南部, 是太湖的重要入湖河流.苕溪分为东、西两支, 流经杭州、湖州2市6区县, 于湖州城东交汇后经长兜港、小梅口、大钱港流入太湖, 流域面积约4576 km2.流域地处中热带季风区和北亚热带季风区交界处, 雨热同期, 四季分明, 森林覆盖率高, 种植业发达, 东部与杭嘉湖平原河网相接, 交汇区域河流坑塘密布, 景观格局复杂, 分为山溪性河流及平原河网两种水系特征, 研究区域范围见图 1.
图 1(Fig. 1)
 |
| 图 1 研究区域地形图 Fig. 1Topographic map of study area |
2.2 模型与方法2.2.1 研究思路流域水质主要受到流域自然特征、人类活动、水文传递等因素影响, 本研究拟利用机器学习模型探究汇水单元内环境变量与水质之间的内在关联性, 并以此对整个流域水质进行评估.具体技术路线见图 2.
图 2(Fig. 2)
 |
| 图 2 技术路线图 Fig. 2Technology roadmap |
采用“Burn-In”法(Luo et al., 2011)先将苕溪流域划分为297个子流域, 作为最小分析单元进行流域特征数据的空间离散化, 统计得到面板数据作为机器学习模型(随机森林模型)的输入样本;采用自组织映射人工神经网络模型(SOM)对监测断面水质污染模式进行识别, 将聚类结果作为模型分类标签, 并根据断面与子流域的空间位置关系将分类标签与面板数据逐一对应作为随机森林模型(RF)的输入数据集.采用超参数调优算法进行模型训练, 进行多轮调参以提升模型精度, 直至达到最优水平.最后利用经过训练的模型对无监测断面分布的子流域进行水质分析, 预测在一定自然环境及社会经济条件下的区域水质类别.同时利用随机森林模型的特征筛选机制计算各流域特征指标对模型的贡献度, 筛选出与水质相关性最强的流域特征子集, 为未来流域水质的预测分析提供支撑.
2.2.2 评估模型① 自组织映射人工神经网络(SOM)????自组织映射人工神经网络(Self-Organizing Map, SOM)是一种无监督学习的人工神经网络模型, 通过寻找最优参考矢量集合来对输入模式集合进行分类(Kohonen, 1990).SOM网络能有效地避免权重系数的影响, 计算过程简单, 具有很强的容错和记忆联想功能, 目前被广泛应用于水质评价(郑晓君, 2005;程学宁等, 2017).
本研究选取苕溪流域71个水质常规监测断面, 将水质数据作为训练数据集, 根据公式5
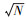
② 随机森林模型(RF)????随机森林(Random Forests, RF)是由Breiman提出的一种基于决策树的机器学习模型.通过自助法重采样技术, 从训练数据集中有放回地随机抽取训练样本及特征变量, 产生若干规模相同但包含不同样本的训练数据子集, 将训练得到的相应数量的决策树作为弱分类器组成随机森林, 由所有决策树投票得到预测结果.
本研究以子流域为最小分析单元, 以SOM聚类结果作为RF模型的数据标签, 将水质监测断面所在的子流域特征指标与水质数据对应, 构建RF模型的训练数据进行初步模型构建.模型训练采用Hyperopt(Bergstra et al., 2015)及GridSearchCV(Swami et al., 2012)进行超参数调优, 并以袋外数据准确率(OOB score)作为模型适用性与泛化性的评价指标.由于RF模型由决策树模型作为弱分类器集成得到, 每个决策树都可根据抽样时遗落的袋外数据(Out of Bag Data)进行自身的误差分析, 对所有决策树的泛化准确率求平均便可得到OOB score.研究表明, OOB score是RF模型泛化准确率的无偏估计(Martínez-Mu?oz et al., 2010), 在某些情况下甚至比交叉验证的效果更好(张春霞等, 2011).通过训练得到模拟精度最高的模型后, 利用流域特征数据集进行流域水质的分析评估.
为了提升模型效率, 降低弱相关特征对模型的干扰, 统计单一特征在每棵决策树中形成的分支节点对基尼不纯度下降的贡献率, 计算其均值作为每个特征对模型的重要性, 并以此为依据对特征进行排序, 剔除末位特征后进行下一轮训练, 直至泛化准确率明显下降后停止, 筛选出子流域尺度上与流域水质相关性最强的特征组合.
2.3 数据来源及处理2.3.1 数据主要来源水质数据采自2015—2017年湖州市61个县控及县控以上监测断面3年的水质监测数据(频次为每月1次), 共计2268组监测数据;以及“十二五”水专项苕溪课题设置的10个自动站数据(频次为每2 h 1次), 共计34862组监测数据.各监测点位分布见图 1.
流域特征指标数据包括数字高程模型、坡度、蒸发量、归一化植被指数、平均降水量、大于10 ℃积温、表层土壤属性(包括容重、电导率、有机碳及pH)、人口数量、国民生产总值、景观多样性指数及土地利用/覆盖等.其中, 土壤数据来自联合国粮农组织(FAO)和维也纳国际应用系统研究所(IIASA)所构建的世界土壤数据库(Harmonized World Soil Database version 1.1)(HWSD)(Nachtergaele et al., 2009), 国民生产总值及大于10 ℃积温数据来自资源环境数据云平台(Liu et al., 2005;王英等, 2006), 其余数据均来自地理国情监测云平台.
2.3.2 数据预处理与分析将矢量河网数据刻入苕溪流域的数字高层模型(DEM), 利用ArcGIS软件的水文分析模块计算得到子流域划分图, 按子流域统计自然、经济指标数据, 以及土地利用/覆盖占比情况.
对每个监测站的水质指标数据进行Shapiro-Wilk正态分布检验(Shapiro, 1965), 结果表明, 置信水平为0.05时, 大部分断面水质数据呈偏态分布.为了避免异常值的影响, 选用中位数来代表断面水质状况.
由于不同类型指标数据的量纲存在差异, 为了避免其对分析预测产生影响, 对所有指标数据进行标准化处理:
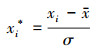 | (1) |
本研究的数据分析利用ArcGIS、Python和MATLAB实现.其中, 子流域划分及子流域指标数据的空间离散化采用ArcGIS 10.5实现, 指标数据标准化、Shapiro-Wilk正态检验及随机森林模型采用编程实现(Python 3.7), 自组织映射人工神经网络模型(Kangas, 2014)采用MATLAB R2017b实现.
3 结果与讨论(Results and discussion)3.1 水质指标数据聚类分析将71个监测断面的水质数据作为SOM网络的训练数据输入, 经过多轮迭代训练后, 得到各水质指标的权重矩阵(图 3a).由图 3a可知, CODMn、NH3-N、TN与TP这4项污染物指标都在网格上部存在高值分布的现象.根据分布格局可以看出, CODMn与TP、NH3-N与TN彼此之间的正相关性较强.DO是反映水质优良程度的重要指标, 高值主要分布在网格下缘, 说明该区域神经元所对应的监测断面水质较好, 同时也可以看出DO分布与CODMn等4项污染物指标存在明显的负相关.pH的数值高低无明显意义, 但与TN之间存在明显的负相关, 呈现出偏酸性TN高、偏碱性TN低的分布格局.
图 3(Fig. 3)
 |
| 图 3 水质指标数据SOM聚类分析(a.权重矩阵, b.聚类划分图) Fig. 3SOM result of surface water monitoring data(a.Weight matrix, b.Cluster division result) |
经二次聚类后得到3种水质聚类(图 3b).对比聚类划分图与权重矩阵可知, 聚类1断面水质良好, 溶解氧含量较高, 水质大部分偏碱性, 各项污染物浓度均处在较低水平;聚类2断面水质中等, 受NH3-N与TP的影响较小, 但CODMn与TN的浓度较高;聚类3断面水质相对较差, 污染物浓度较高, 水质偏酸性, 溶解氧浓度较低.
根据监测断面的聚类分布来看, 聚类1断面有23个, 聚类2断面有30个, 聚类3断面则有18个, 其空间分布见图 4.由图 4可知, 水质较差的断面主要分布在人口、产业密集的城市建成区或农田、居民点密布的平原河网区, 这些断面所处区域地形平坦流速较慢, 水体自净能力相对较弱, 又受到人类活动的影响, 污染物排放量较大, 导致水体污染相对严重.水质一般的断面分布在聚类1和聚类3断面的中间区域, 多为山地与平原的过渡地带, 这些区域内也存在一定规模的城镇和工业区, 但人口密度和经济发展水平相对较低.水质较好的断面则主要分布在各水系上游的源头区域, 这些区域受人类活动的扰动影响较弱, 多为生态红线区或水源涵养区, 生态环境优越, 水质较好.
图 4(Fig. 4)
 |
| 图 4 不同聚类的监测断面分布 Fig. 4Distribution of monitoring sites of three clusters |
根据地表水环境质量标准(GB 3838—2002)对3类聚类的断面水质数据进行水质级别判定, 发现聚类1中的断面水质级别均为Ⅱ类水, 聚类2中20%的断面为Ⅲ类水, 80%的断面为Ⅱ类水, 而聚类3的断面大部分为Ⅲ类水(具体见表 1).由此可知, SOM聚类对于水质评价的适应性较好, 将此聚类结果作为RF的训练标签可以反映断面水质的优良程度.
表 1(Table 1)
| 表 1 3种聚类断面的水质级别分布 Table 1 Category distribution of monitoring sites of three clusters | |||||||||||||||||||
表 1 3种聚类断面的水质级别分布 Table 1 Category distribution of monitoring sites of three clusters
| |||||||||||||||||||
3.2 基于流域特征指标的水质评估3.2.1 流域水质空间差异性评估利用水质聚类结果为标签, 对各个子流域的流域特征数据进行随机森林模型(RF)训练分类, RF模型的泛化准确率保持在77%以上, 稳定在80%左右, 表明模型适用.采用SOM-RF水质评估模型, 将苕溪流域水质状况分为3类(图 5).由图可知, 研究区域内的大部分山地区域都被归为1类区, 2类区子流域分布在河谷地区及山地平原过渡地带, 3类区子流域则主要分布在长兴平原、湖州城区及东部平原河网区.1类、2类、3类子流域面积占整个流域的面积比例分别为55%、32%、13%, 说明流域水质状况总体较好, 流域水质等级的评估结果与相关研究较为一致(李伟等, 2013;张敏等, 2017).
图 5(Fig. 5)
 |
| 图 5 流域水质评估结果 Fig. 5Result of water quality assessment |
由图 5可知, RF模型预测结果与水质监测数据聚类之间仍存在部分差异, 如长兴平原西部与安徽省的交界处, 断面水质归为聚类2, 而RF模型判断该子流域的水质等级好于监测数据, 可能原因是该区域特征因素对水质影响较小, 水质监测数据受到上游跨界污染物的影响.而长兴东部水质聚类类别与RF模型预测水质类别存在差异可能是由于该区域常年受到太湖逆流的影响, 导致水质评估结果与实际存在较大误差.
对3类子流域分别进行指标数据统计(表 2), 结果表明, 1类子流域坡度较陡, 植被覆盖率高, 蒸发蒸腾量大, 表层土壤电导率及有机质含量较高, 景观复杂度低, 属于典型的受人类活动影响较少的山地区域;与其他两类子流域相比, 2类子流域景观多样性指数极高, 旱地占比最高, 其余指标数据大多处于中等水平, 表明该类区域为景观较为破碎的城镇边缘区;3类子流域表层土壤容重大, 人口密度最高, GDP也远高于其他两类, 在土地利用方面, 水田、城镇用地及农村居民点面积占比均为最高, 属于人类活动影响剧烈的城镇核心区.
表 2(Table 2)
| 表 2 不同水质类别子流域特征指标统计 Table 2 Statistics of watershed features | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
表 2 不同水质类别子流域特征指标统计 Table 2 Statistics of watershed features
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3.2.2 流域水质影响因子识别对不同参数组合训练的模型进行特征指标重要性计算并求均值, 结果见图 6.由图 6a可知, 蒸发蒸散量(ET)、坡度(SLOPE)、人口密度(POP)、大于10 ℃积温(ABO10)、旱地占比(DRYFIELD)等特征指标重要性相对较大, 说明这些特征指标形成的决策树分类节点后, 样本的基尼不纯度有较大程度的下降, 对模型构建的贡献较大(陈云樱等, 2004).在所选的流域特征指标中, 土壤属性指标(pH、BLKD、OC、ECE)对流域水质的影响相对较小, 相关性较弱, 这可能是由于山溪型流域地区流速相对较高, 与下垫面水量交换不充分, 小尺度分析难以反映其对水质的影响;同样在社会经济指标中, 部分土地利用指标(PADDY、LAWN、WATER)及GDP对模型构建的贡献相对较小, 这可能是由于子流域边界与经济活动边界之间的一致性较差, 削弱了这些特征与水质之间的相关性.
图 6(Fig. 6)
 |
| 图 6 模型评价指标分析(a.特征指标重要性帕累托图, b.OOB score趋势图) Fig. 6Analysis of model evaluation indexes(a.Pareto chart of feature importance, b.Trend chart of OOB score) |
以特征排序为基准, 以OOB score为模型性能的衡量标准, 逐一剔除末位特征后进行多轮模型训练, 结果见图 6b.由图可知, 以排位前9的特征组合进行模型训练的OOB score达到0.84最高值.增加特征指标虽然能使模型OOB sore保持一个较高水平, 但整体效率不是最佳, 而进一步剔除特征则会导致模型性能下降.这一结果说明当弱相关特征的数量较多时, 虽然模型仍然能保持较高的准确率, 但由于RF模型采用了随机子空间思想, 随机抽取一定数量的特征进行单颗决策树的构建, 也决定了如果决策树抽取了较多的弱相关特征, 可能会导致这部分决策树的分类结果存在偏差, 进而影响投票结果, 导致模型性能上限受到影响.而过度精简特征指标, 一方面可能会减少决策信息, 导致模型无法进行充分学习, 另一方面会导致组成RF模型的决策树之间的多样性下降(李毓等, 2011).因此, 要在保证一定特征数量的前提下进行指标筛选, 以避免影响RF模型的预测性能.根据OOB score峰值对应的特征组合可知, 该组合包含了进行水质分类评估所需要的绝大部分信息, 具体是蒸发蒸腾量(ET)、林地占比(FOREST)、坡度(SLOPE)、归一化植被指数(NDVI)、人口密度(POP)、大于10 ℃积温(ABO10)、旱地占比(DRYFIELD)、城镇用地占比(URBAN)、景观多样性指数(SDI), 而这些指标与流域水质具有较强的相关性.考虑到重要性排序靠前的特征指标之间可能存在相关性, 对特征指标进行了Spearman相关性检验(图 7), 结果显示, 排位靠前的特征(ET与NDVI、SLOPE与FOREST)之间存在较强的相关性.根据相关性检验结果, 在9项特征组合的基础上剔除NDVI与FOREST进行模型训练, OOB score为0.83左右.因此, 在保证可接受的高准确率(>0.80)的前提下, 蒸发蒸腾量(ET)、坡度(SLOPE)、人口密度(POP)、大于10 ℃积温(ABO10)、旱地占比(DRYFIELD)、城镇用地占比(URBAN)、景观多样性指数(SDI)为进行水质分类评估的推荐特征组合.
图 7(Fig. 7)
 |
| 图 7 特征相关系数矩阵 Fig. 7Correlation coefficient matrix of features |
4 结论(Conclusions)1) 利用机器学习算法建立社会经济环境与水质的关系模型, 能直观地对流域水质的空间格局进行分析评估, 从而为流域污染防治与水质管理提供决策支持.本研究耦合SOM与RF的水质分析评估方法, 在流域水质聚类评估的基础上, 构建了苕溪流域特征指标与水质之间的关系模型, 对流域不同子流域的区域水质进行了预测, 结果显示, 模型的泛化准确率稳定在80%左右, 最高可达83%, 说明该模型能较好地评估流域水质空间分布特征.
2) 苕溪流域水质评估结果表明, 流域水质总体较好, 森林覆盖率高的山地区域水质最好, 景观破碎度高的城镇边缘区水质一般, 而人口、产业集中的城镇核心区水质最差, 其中, 蒸发蒸腾量(ET)、林地占比(FOREST)、坡度(SLOPE)、归一化植被指数(NDVI)、人口密度(POP)、大于10 ℃积温(ABO10)、旱地占比(DRYFIELD)、城镇用地占比(URBAN)、景观多样性指数(SDI)这9项流域特征指标与苕溪流域水质具有较强的相关性.
3) 利用流域特征指标与水质指标建立的SOM-RF耦合水质评估模型, 可以用来定性分析没有水质监测断面分布区域的水质, 满足流域全面管理的需求.本研究通过筛选出影响区域水质的关键特征因子, 在保证精度的前提下可以降低模型应用和推广的成本.然而, 模型精度仍受到数据规模的影响, 在样本量较小或流域特征数量较少的条件下, 模型的准确性与稳定性将会有所欠缺.
参考文献
| Amir H, Ali N, Abbas P. 2018. Water quality prediction using machine learning methods[J]. Water Quality Research Journal, 53(1): 3-13. DOI:10.2166/wqrj.2018.025 |
| Bergstra J, Komer B, Eliasmith C, et al. 2015. Hyperopt:A Python library for model selection and hyperparameter optimization[J]. Computational Science & Discovery, 8(1). DOI:10.1088/1749-4699/8/1/014008 |
| Breiman L. 2001. Random forests[J]. Machine Learning, 45(1): 5-32. DOI:10.1023/A:1010933404324 |
| 陈云樱, 吴积钦, 徐可佳. 2004. 决策树中基于基尼指数的属性分裂方法[J]. 微机发展, 14(5): 66-68. |
| 程学宁, 卢毅敏. 2017. 基于SOM和PCA的闽江流域地表水水质综合评价[J]. 水资源保护, 33(3): 59-67. |
| Martínez-Mu?oz G, Suárez A. 2010. Out-of-bag estimation of the optimal sample size in bagging[J]. Pattern Recognition, 43(1): 143-152. DOI:10.1016/j.patcog.2009.05.010 |
| Holloway J, Mengersen K. 2018. Statistical machine learning methods and remote sensing for sustainable development goals:A review[J]. Remote Sensing, 10: 1365-1385. DOI:10.3390/rs10091365 |
| Fatehi I, Amiri B J, Alizadeh A, et al. 2015. Modeling the relationship between catchment attributes and in-stream water quality[J]. Water Resources Management, 29(14): 5055-5072. DOI:10.1007/s11269-015-1103-y |
| Janardan M, Heejun C. 2018. Landscape and anthropogenic factors affecting spatial patterns of water quality trends in a large river basin, South Korea[J]. Journal of Hydrology, 564: 26-40. DOI:10.1016/j.jhydrol.2018.06.074 |
| 蒋艳君, 谢悦波, 黄旻. 2016. 改进的物元分析法在水质监测断面布设优化中的应用[J]. 水资源保护, 32(4): 136-141. |
| Kangas J. 2014. SOM_PAK:the self-organizing map program package[J]. G3(Bethesda, Md.), 4(9): 1657-1665. DOI:10.1534/g3.114.012914 |
| Kohonen T. 1990. The self-organizing map[J]. IEEE Proc Icnn, 1(1/3): 1-6. |
| Liu H, Jiang D, Yang X, et al. 2005. Spatialization approach to 1 km Grid GDP supported by remote sensing[J]. Geo-information Science, 7(2): 120-123. |
| 李伟, 姚笑颜, 梁志伟, 等. 2013. 基于自组织映射与哈斯图方法的地表水水质评价研究[J]. 环境科学学报, 33(3): 893-903. |
| 李毓, 张春霞. 2011. 基于out-of-bag样本的随机森林算法的超参数估计[J]. 系统工程学报, (4): 134-140. |
| Luo Y, Su B, Yuan J, et al. 2011. GIS Techniques for watershed delineation of SWAT Model in plain polders[J]. Procedia Environmental Sciences, 10(part-PC): 2050-2057. |
| Mohammadpour R, Shaharuddin S, Chang C K, et al. 2015. Prediction of water quality index in constructed wetlands using support vector machine[J]. Environmental Science and Pollution Research, 22(8): 6208-6219. DOI:10.1007/s11356-014-3806-7 |
| Nachtergaele F, Velthuizen H V, Verelst L, et al.2009.Harmonized world soil database[C].World Congress of Soil Science: Soil Solutions for A Changing World. |
| Ramezani H, Holm S. 2011. Sample based estimation of landscape metrics; accuracy of line intersect sampling for estimating edge density and Shannon's diversity index[J]. Environmental & Ecological Statistics, 18(1): 109-130. |
| Shapiro S S. 1965. An analysis of variance test for normality(Complete samples)[J]. Biometrika, 52: 591-611. DOI:10.1093/biomet/52.3-4.591 |
| Sharpley A, Wang X. 2014. Managing agricultural phosphorus for water quality:Lessons from the USA and China[J]. Journal of Environmental Sciences, 26(9): 1770-1782. DOI:10.1016/j.jes.2014.06.024 |
| Singh K P, Basant A, Malik A, et al. 2009. Artificial neural network modeling of the river water quality-A case study[J]. Ecological Modelling, 220(6): 888-895. DOI:10.1016/j.ecolmodel.2009.01.004 |
| Swami A, Jain R. 2012. Scikit-learn:Machine learning in Python[J]. Journal of Machine Learning Research, 12(10): 2825-2830. |
| Sweeney B W. 2004. Riparian deforestation, stream narrowing, and loss of stream ecosystem services[J]. Proceedings of the National Academy of Sciences of the United States of America, 101(39): 14132-14137. DOI:10.1073/pnas.0405895101 |
| Vesanto J, Alhoniemi E. 2000. Clustering of the self-organizing map[J]. IEEE Transactions on Neural Networks, 11(3): 586-600. DOI:10.1109/72.846731 |
| 王英, 曹明奎, 陶波, 等. 2006. 全球气候变化背景下中国降水量空间格局的变化特征[J]. 地理研究, 25(6): 1031-1040. DOI:10.3321/j.issn:1000-0585.2006.06.010 |
| Woldesenbet T A, Elagib N A, Ribbe L, et al. 2016. Hydrological responses to land use/cover changes in the source region of the Upper Blue Nile Basin, Ethiopia[J]. Science of the Total Environment, 575(C): 724. |
| 于松延, 徐宗学, 武玮, 等. 2014. 北洛河流域水质空间异质性及其对土地利用结构的响应[J]. 环境科学学报, 34(5): 1309-1315. |
| 张春霞, 郭高. 2011. Out-of-bag样本的应用研究[J]. 软件, 32(3): 1-4. |
| 张敏, 陈玮东, 茆传奇, 等. 2017. 浙江省太湖流域原生动物四季群落结构及水质评价[J]. 杭州师范大学学报:自然科学版, (16): 74. |
| 郑晓君.2005.利用SOFM网络评价杭州西湖水质的时空变化[D].杭州: 浙江大学 |
