 ,1,2, 杜义华,1,*, 赵以霞,1
,1,2, 杜义华,1,*, 赵以霞,1A Method of Opinion Leader Discovery Based on Comprehensive Influence and Sentiment Characteristics
WANG Jiaqi,1,2, DU Yihua,1,*, ZHAO Yixia,1通讯作者: *杜义华(E-mail:yhdu@cashq.ac.cn)
收稿日期:2021-02-22
| 基金资助: |
Received:2021-02-22
作者简介 About authors

王嘉麒,中国科学院计算机网络信息中心,中国科学院大学,硕士研究生,主要研究方向为传播分析与引导、中文情感分析。
本文中负责数据采集,实验设计和实现。
WANG Jiaqi is a master student at Computer Network Infor-mation Center of the Chinese Academy of Sciences and Univ-ersity of the Chinese Academy of Sciences. His main research directions are public opinion communication analysis and gui-dance, and Chinese sentiment analysis.
In this paper, he is responsible for dataset construction, experi-mental design and implementation.
E-mail:

杜义华,中国科学院计算机网络信息中心,高级工程师,部门副主任,硕士生导师,主要研究方向为传播分析与引导、软件设计开发。
本文中负责结论展望。
DU Yihua, Master Supervisor, is a senior engineer and deputy department director at Computer Network Information Center of the Chinese Acad-emy of Sciences. His research directions are public opinion communication analysis and guidance, and software design and development.
In this paper, he is responsible for the conclusion outlook.
E-mail:

赵以霞,中国科学院计算机网络信息中心,高级工程师,主要研究方向为在线学习技术。
本文中负责研究现状介绍。
ZHAO Yixia is a senior engineer at Com-puter Network Information Center of the Chinese Academy of Sciences. Her research direction is online learning technology.
In this paper, she is responsible for the current studying status introduction.
E-mail:

摘要
【目的】针对传统意见领袖发现方法局限于部分数据特征导致忽略部分意见领袖的现象,提出一种基于综合影响力和情感特征的发现方法CI-SC,可筛查出部分被传统方法忽略的意见领袖。【方法】综合考虑用户在个人属性和互动行为两方面的特征作为综合影响力,同时引入情感特征,通过聚类分析发现意见领袖,并根据身份信息和社交关系评价结果。【结果】本方法能有效地发现意见领袖,结果具有统计学显著性。本方法与传统方法的发现结果重合率较低,证明可以有效发现部分被传统方法忽略的意见领袖。【局限】目前只在有限规模数据集中进行了实验,其有效性需在更大规模数据集中进一步验证。【结论】提出了基于综合影响力和情感特征的意见领袖发现方法,实验证明此方法能有效发现被传统方法忽略的部分意见领袖,可作为传统方法的补充,在舆情分析与引导中具有一定实用价值。
关键词:
Abstract
[Objective] In response to the phenomenon that traditional opinion leader discovery methods are limited to partial data features and lead to ignoring of some opinion leaders, this paper proposes a new opinion leader discovery method called CI-SC to achieve the purpose of discovering the ignored opinion leaders. [Methods] CI-SC integrates the influence characteristics of users in both profile attributes and post interaction behaviors to build a comprehensive influence evaluation index. By introducing users' sentiment characteristics, CI-SC achieves the discovery of opinion leaders through cluster analysis based on the above characteristics. The results are evaluated by analyzing identity information and social connections. [Results] According to the experimental results, the opinion leaders found by our method have higher statistical significance and lower overlap ratio compared with those found by traditional methods, which means that by considering more aspects of information, our method can effectively identify opinion leaders with greater influence and obvious sentiment characteristics that are ignored by traditional methods. [Limitations] The proposed method has only been tested on a small dataset so far. Thus, more experiments on larger datasets are needed to further validate its effectiveness. [Conclusions] This paper proposed a new opinion leader discovery method called CI-SC, which is based on comprehensive influence and sentiment characteristics. Experimental results prove that by taking into account the influence of a user in different aspects and further combining the influence with the sentiment characteristics, CI-SC improves the traditional opinion leader discovery methods in discovering opinion leaders without neglecting some information. Therefore, our method can be an effective supplement to traditional methods and has practical value in opinion analysis and guidance.
Keywords:
PDF (11065KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
王嘉麒, 杜义华, 赵以霞. 基于综合影响力和情感特征的意见领袖发现方法[J]. 数据与计算发展前沿, 2021, 3(4): 126-139 doi:10.11871/jfdc.issn.2096-742X.2021.04.011
WANG Jiaqi, DU Yihua, ZHAO Yixia.
引言
随着互联网的快速发展,公众较以往更加积极地使用网络社交平台参与对社会热点事件的讨论。以推特和新浪微博为代表的网络社交平台逐渐成为了大量公众获取信息的重要渠道,在近年来所有舆情事件的传播中都产生了重要影响[1]。社交平台的庞大规模使得舆情事件更容易快速传播和发酵,如果缺乏合理的舆情分析与引导,会导致舆论迅速恶化,加剧社会矛盾。研究表明,社交平台上的意见领袖能够对大量用户产生影响,在很大程度上左右舆论走向[2]。“意见领袖”这一概念最初由Lazarsfeld提出,指在信息传播过程中通过发表观点和引导舆论,对其他用户的态度造成影响,并受到媒体和知名人士关注,从而在舆情事件中产生极大影响力的重要人物[3]。对意见领袖的发现,在舆情分析与引导等方面具有不可忽略的价值[4]。目前关于意见领袖发现的研究主要基于用户和帖子的数据特征构建影响力指标以衡量用户在舆情事件中的影响,并根据相关指标进行排序或聚类以发现意见领袖,属于典型的多方面评分问题[5]。传统方法大多将用户个人属性和帖子互动行为视为互相独立的特征,较少涉及用户和帖子的综合作用与相互影响,因此会忽略部分信息,导致部分意见领袖被遗漏,不利于相关的舆情分析与引导[6]。此外,有研究表明意见领袖在舆情事件中会表现出特定的情感特征,在基于影响力的意见领袖发现方法的基础上引入情感分析手段,有助于更有效地发现意见领袖[7]。
本文融合用户个人属性和帖子行为特征,提出基于综合影响力和情感特征的意见领袖发现方法(opinion leader discovery based on comprehensive influence and sentiment characteristics,简称CI-SC)。CI-SC方法综合考虑用户个人属性和帖子互动行为两方面的影响力特征,并在此基础上引入用户的情感特征,通过聚类分析实现意见领袖发现。
1 相关研究
1.1 基于影响力的意见领袖发现方法
现有的意见领袖发现方法主要通过用户的部分数据特征,如粉丝数和转发数等,构建影响力指标以衡量不同用户的影响力大小,从而发现具有较大影响力的意见领袖。根据采用的数据特征的区别,影响力指标主要分为用户影响力和帖子影响力两大类。用户影响力指某一用户发表的言论被推送给其他用户并影响其他用户的能力。相关方法主要基于用户个人属性特征计算用户影响力,包括关注数、发帖数和粉丝数等[8]。部分研究在此基础上参考google的PageRank算法[9],康奈尔大学的HITS算法[10]及相应变种[11,12,13,14],将社交网络结构纳入用户影响力的计算。王君泽等提出了基于粉丝数、关注数和发博数的微博意见领袖识别模型[15]。Kwak等依据粉丝数和PageRank算法对Twitter用户进行影响力排名,发现意见领袖的影响力排名并不完全受限于其个人属性[16]。Weng等提出TwitterRank算法,将用户的影响力定义为其所有粉丝的影响力之和[17]。石磊等则在粉丝数基础上,进一步引入了活跃指数来计算用户影响力[18]。
帖子影响力指的是某帖子成为热门内容并影响大量用户的能力。相关研究主要基于帖子的互动行为特征构建帖子影响力,包括评论数、转发数和点赞数等。童薇等提出一种基于微博互动行为特征的检测算法,该算法可检测出影响较大的热门微博[19];李华等提出了计算热度值的IEED算法,该算法同时考虑了帖子的互动行为数据和发布用户粉丝数[20];郭跇秀等则将用户影响力和文本特征结合作为微博影响力[21]。
目前已有的基于影响力的意见领袖发现方法在构造影响力指标时,往往只考虑一部分数据信息,这使得关于用户影响力的研究主要局限于用户本身的个人属性数据,而没有考虑该用户发表的帖子在传播过程中产生的影响,如转发等互动行为所蕴含的影响力都未被考虑。一些研究表明,仅考虑用户个人属性得出的意见领袖,在其他评价指标下并不一定具有较强的影响力[22]。另一方面,基于PageRank和HITS算法的发现方法为了构建社交网络结构,需要额外获得所有用户之间的关注关系,这极大提高了数据采集的复杂度,限制了此类方法在用户数量较多的场景中的应用。关于帖子影响力的研究也主要局限于帖子的互动行为特征本身,如评论数等,此类数据只能反映与帖子的互动行为产生的影响力,而很多用户被推送帖子后,不一定会发生评论、转发等互动行为,因此仅凭互动行为特征也不能全面客观地反映出帖子产生的实际影响[18]。即传统的基于影响力的意见领袖发现方法局限于部分数据特征,并不能全面客观地反映出用户在具体话题中实际表现出的影响力。
1.2 基于情感分析的意见领袖发现方法
基于情感分析的意见领袖发现方法通过分析用户发表的文本内容的情感倾向,以获得用户的情感特征,并基于情感特征构建相关分类指标。目前相关的意见领袖发现方法主要采用情感词典或机器学习方法进行情感分析[23]。肖宇等提出了基于情感词典的LeaderRank算法,该算法提高了意见领袖发现的准确度[6]。曹玖新等结合情感词典和决策树模型,从情感维度度量意见领袖的影响[24]。陈涛等通过BERT实现了短文本的情感特征提取与融合[25]。情感词典法将带有情感倾向的情感词集合映射到一个情感词典,每一个情感词在词典中都对应一个标签。对于给定文本,可以在情感词典中查找到每个情感词的对应极性值,从而把情感分类转化为一个数值计算问题。英语语料主要采用Gerneral Inquirer[26]或SentiWordNet[27]作为词典,中文语料则主要采用知网情感词典HowNet[28]、清华大学中文褒贬义词典和大连理工大学中文情感词汇库[29]等。机器学习方法则将情感倾向分析视为分类问题,使用较多的模型有朴素贝叶斯(Naïve Bayes)、最大熵(Maximmum Entropy)、支持向量机(SVM)等[30]。情感词典无需额外训练,使用成本较低,但效果和词典质量高度相关;机器学习方法则需进行预训练,实际应用中的成本较高。
2 基于综合影响力和情感特征的意见领袖发现方法流程设计
针对传统意见领袖发现方法因局限于部分数据特征导致无法全面反映用户实际具有的影响力,使得部分意见领袖被忽略的问题,本文提出一种基于综合影响力特征和情感特征的意见领袖发现方法(CI-SC),同时考虑用户影响力和帖子影响力作为综合影响力,并引入用户的情感特征作为筛查依据。CI-SC以综合影响力特征和情感特征对社交平台用户进行聚类,筛查发现在话题下具有较大影响力和明显情感特征的意见领袖。主要步骤如图1所示。图1
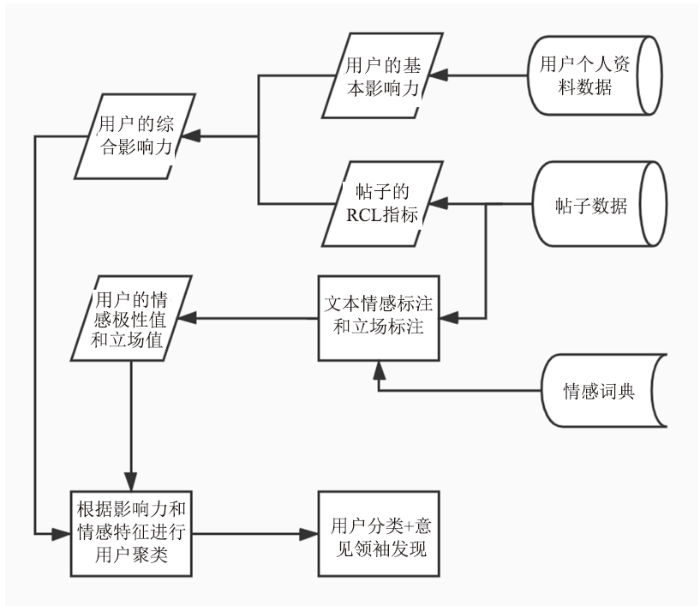 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1基于综合影响力和情感特征的意见领袖发现方法(CI-SC)流程图
Fig.1Flowchart of opinion leader discovery based on comprehensive influence and sentiment characteristics (CI-SC)
CI-SC的算法流程如图2所示。
图2
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2伪代码形式的CI-SC算法流程
Fig.2Algorithm of CI-SC in pseudo-code form
2.1 计算综合影响力特征
基于用户的个人属性特征,计算每个用户的基本影响力InfUseru,表示用户对其粉丝在理论上具有的影响力,定义InfUseru的计算公式如下:其中,WBu为用户u的微博数,WBmax为数据集中微博数最大值,WBmin为微博数最小值,FANu为用户u的粉丝数,FANmax为数据集中粉丝数最大值,FANmin为粉丝数最小值,FOu为用户u的关注数,FOmax为数据集中关注数最大值,FANmin为关注数最小值。由于相关指标的数据跨度较大,不利于后续计算,对原始数据进行对数归一化处理。Wwb,Wfan和Wfo分别为微博数、粉丝数和关注数的权重。采用层次分析方法AHP构建判断矩阵计算出各因素权重,根据该矩阵能否通过一致性检验判别是否接受该组权重。通过AHP法得出的权重值为Wwb=0.2583,Wfan=0.637,Wfo=0.1047,一致性检验结果为0.0331(小于阈值0.1),表明应接受该组权重。
基于帖子的互动行为特征,计算每个帖子的互动指标RCLScorei,表示转发、评论和点赞等行为具有的互动影响力,计算公式如下:
其中,Ri、Ci、Li表示帖子i的转发、评论和点赞数,Wr、Wc、Wl为转发、评论和点赞数的权重,分别为0.4、0.4、0.2[31]。threshold为数据集中上诉指标加权和的最大值。
基于发帖用户的基本影响力InfUseru和帖子i的互动指标RCLscorei,计算帖子i的综合影响力InfScorei,该影响力表示帖子在传播过程中发生的互动行为与单向推送产生的全部实际影响力。计算公式如下:
其中α∈[0,1],表示用户基本影响力和帖子互动影响力的相对权重,本方法设置α=0.5。
将属于同一用户u的所有帖子的综合影响力相加,得到用户u的总影响力TotalInfu和平均影响力AvgInfu,总影响力表示用户的实际影响,平均影响力表示用户造成影响的效率。计算公式如下:
其中D={D1,D2,…, Dn}为用户u在此话题下发表的所有帖子的集合,n为集合D的帖子数量。
2.2 计算情感特征
CI-SC基于中文情感分析,需构建针对中文文本的情感词典。目前在中文语料上最为常见的情感词典有知网Hownet、清华大学褒贬义词典和大连理工大学中文情感词汇本体库3种。其中,清华大学褒贬义词典只标注了每个词语的褒贬义倾向,没有标注极性强度值,且无除褒贬义词外的其他词语,如程度副词与否定词等,因此无法用于需要进行数值计算的CI-SC方法中。相比而言,大连理工大学中文情感词汇本体库包含更多数值特征,如词语的词性、情感类别、情感强度和极性等多方面的信息,因而更适合作为CI-SC的基础情感词典。其一般格式如表1所示。Table 1
表1
表1情感词汇本体库格式样例
Table 1
| 词语 | 词性 | 情感 | 强度 | 极性 |
|---|---|---|---|---|
| 周到 | adj | 赞扬 | 5 | 2 |
| 手头紧 | idiom | 烦闷 | 7 | 0 |
新窗口打开|下载CSV
在情感词汇本体库中,词语的情感被分为了7个大类下的21个小类;情感强度被分为1至9档,其中1强度最弱;极性则根据正负面分为4类,0代表中性,1代表正面,2代表负面,3代表同时具有正负两面。该词汇库的情感强度值和极性值将用于CI-SC方法的数值化计算过程,因此使用该词汇库作为CI-SC词典中的情感词典。
除情感词外,CI-SC的计算过程还需要程度副词词典,目前中文词典中,程度副词质量较高的是知网Hownet。其将常见的近400个中英文程度副词分为6个等级,分别为“最”、“很”、“较”、“稍微”、“略微”、“超过”。其程度副词词典较情感词汇库的副词更为直观简洁,更适合用于CI-SC方法的后续计算。
CI-SC综合使用知网Hownet和大连理工大学情感词汇库作为情感词典,对帖子文本的情感极性进行计算。其中情感词汇本体库作为基础情感词典,Hownet作为程度副词词典。
通过词典查找每条帖子中出现的所有情感词的极性强度值,如存在程度副词和否定词,则对相应情感词的极性强度乘以对应权重,将所有情感词的极性强度值加权求和作为帖子的极性值Sentid。计算公式如下:
其中L是帖子d包含的所有情感词的集合,Wi是情感词i在程度副词和否定词影响下的权重,Sentii是情感词i在词典中的极性强度值。
由于不同用户在同一话题下发表的帖子数量不同,为减少发帖量对后续情感分析的影响,对每个用户的所有帖子的情感极性取均值,作为用户的情感极性特征AvgSentiu,计算公式如下:
其中D={D1, D2, …, Dn}为用户u在话题下发表的所有帖子的集合,n为集合D的帖子数量。
通过对帖子所持立场进行标注,得出每个用户的立场倾向值Attitudeu,代表用户对于话题主体的态度,数值越大表示用户越倾向于支持话题主体,反之则越倾向于反对话题主体,计算公式如下:
其中D={D1, D2, …, Dn}为用户u在话题下发表的所有帖子的集合,Wd表示帖子d的立场权重,由帖子d的立场标记tag决定。由于帖子的情感倾向和立场倾向相互独立,一个立场上支持话题主体的帖子的情感可能是正面的也可能是负面的,因此在计算立场值时只需考虑情感极性值的绝对值。
2.3 用户聚类和意见领袖发现
基于用户综合影响力特征和情感特征对所有用户进行聚类分析,根据聚类分析结果发现具有较大影响力和明显情感特征的意见领袖。3 实验验证
3.1 实验数据和环境
使用爬虫工具weibo-search和weibo-crawler,爬取微博 “方方日记”话题下所有热门帖子的互动行为数据和发帖用户的个人属性数据作为实验数据集。采集时间为2020年9月,采集范围为2020年2月1日0时至2020年6月30日23时,共采集到2000条帖子的互动行为数据和920名用户的个人属性数据。该数据集包含的具体特征如表2所示。Table 2
表2
表2数据特征一览表
Table 2
| 类别 | 特征 |
|---|---|
| 帖子特征 | 帖子id |
| 发帖用户id | |
| 发帖用户昵称 | |
| 正文文本 | |
| 转发/评论/点赞数 | |
| 用户特征 | 用户id |
| 用户昵称 | |
| 性别 | |
| 阳光信用 | |
| 微博数 | |
| 粉丝数 | |
| 关注数 | |
| 微博等级 | |
| 会员等级 | |
| 认证状态 |
新窗口打开|下载CSV
实验的硬件配置是Intel(R)Core(TM)i7-9750H 2.60GHzCPU,内存16GB,操作系统Windows10。
3.2 实验流程
计算用户综合影响力特征。按照2.1综合影响力计算公式,计算所有用户的总影响力TotalInfu和平均影响力AvgInfu作为用户的综合影响力特征。计算用户情感特征。按照2.2情感特征计算公式,计算所有用户的情感极性值AvgSentiu和在此话题下的立场值Attitudeu作为用户的情感特征。
依据综合影响力特征和情感特征,对采集到的所有用户进行聚类,发现具有较大影响力和明显情感特征的意见领袖。
3.3 实验结果分析
使用综合影响力特征和情感特征对所有用户进行K-均值聚类,如图3所示。图3
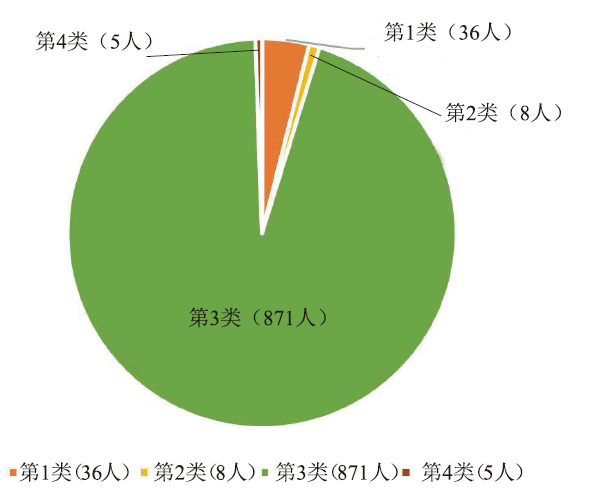 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3CI-SC方法的K-均值聚类结果
Fig.3K-means clustering results of CI-SC
用户被分为4类。第3类占94.67%,其影响力较低,代表主流人群;第2类占0.87%,其影响力和主流人群没有出现明显区别,但情感特征值出现了明显极化,代表主流人群中的少数极端派;第1类和第4类分别占3.91%和0.54%,其影响力指标显著高于主流人群,情感特征也表现出了明显不同于主流人群的模式,其中第4类的影响力指标最为突出,故第4类代表最为关键的核心意见领袖,第1类代表普通意见领袖。4类人群的综合影响力特征和情感特征统计见表3。意见领袖的各类综合影响力特征和情感特征都表现出了与主流人群的显著差异,尤其以核心意见领袖最为突出。
Table 3
表3
表3聚类结果的综合影响力特征和情感特征对比
Table 3
| 核心意见领袖 | 普通意见领袖 | 主流人群 | 少数极端派 | P值 | |
|---|---|---|---|---|---|
| 总影响力 | 28.47±5.75 | 5.66±3.64 | 0.86±0.86 | 0.53±0.16 | <0.001 |
| 平均影响力 | 0.66±0.08 | 0.63±0.08 | 0.52±0.10 | 0.48±0.11 | <0.001 |
| 情感极性值 | -26.67±19.04 | -77.07±86.12 | -26.51±101.19 | -978.00±258.71 | <0.001 |
| 立场值 | -1788.8±1081.9 | -734.4±523.2 | -2.3±161.7 | -422.8±1165.8 | <0.001 |
新窗口打开|下载CSV
核心意见领袖与普通意见领袖的平均影响力差别较小,平均值较主流人群高约0.12到0.14,标准差较主流人群低20%,说明意见领袖在舆情事件中造成影响的效率明显高于主流人群,且意见领袖之间的效率差别小于主流人群内部的效率差别,即意见领袖能够更高效且稳定地对舆论造成影响。在总影响力方面,核心意见领袖和普通意见领袖区别较大,但均与主流人群表现出显著差距,其中普通意见领袖约较主流人群高1个数量级,核心意见领袖约高2个数量级,说明意见领袖在舆情事件中造成的总影响远大于普通人,尤其是少数的核心意见领袖,其影响极为突出。
相比于主流人群,意见领袖同时表现出差异性和相似性。核心意见领袖的情感极性均值为-26.67,与主流人群均值-26.51几乎一致,但标准差仅为19.04,远小于主流人群的101.19,表明核心意见领袖在舆情事件中表现出的情感与主流人群非常相似,但变化更小,说明核心意见领袖能够得到主流人群广泛共情与认同。普通意见领袖的情感极性均值为-77.07,与主流人群区别较大,但标准差较为接近,为86.12,表明普通意见领袖在舆情事件中表现出的情感只与主流人群中的部分人相似,且变化更大,说明普通意见领袖只能得到部分人群的共情与认同。
在立场值方面,意见领袖相比主流人群,表现出了极为明显的负面立场。其中核心意见领袖的立场最为坚定,均值达到-1788.8,普通意见领袖次之,达到-734.4,而主流人群的立场均值仅为-2.3。说明意见领袖不同于主流人群,在舆情事件中会表现出非常明确的立场偏向。
聚类结果的显著性检验结果表明,在所有特征上得到的P值都小于0.001,说明CI-SC方法发现的意见领袖在综合影响力特征和情感特征上都与主流人群表现出了极其显著的统计学差异。
为进一步验证CI-SC方法发现结果的正确性,对发现的意见领袖进行其他特征的分析。由于目前并不存在一个公认精确的意见领袖评价标准,因此采用Rogers等提出的观察法[32],通过用户的其他身份信息和社交网络关系判定发现结果是否符合意见领袖的定义。
CI-SC方法发现的核心意见领袖的各项数据指标均远超主流人群平均水平,且在身份类型、活跃领域上表现出相似性(表4)。在个人属性特征方面,核心意见领袖的粉丝数超过主流人群中的大部分人,粉丝最多的“地瓜熊老六”高于主流人群中98%的用户,粉丝最少的“骑扫帚的老道士”高于主流人群中69%的用户。在互动行为方面,主流人群的人均被转发数、人均被评论数、人均被点赞数分别为294、342、3358,而核心意见领袖的对应数据分别为2428到50232、3062到46881、21792到631000,高出主流人群1到2个数量级。在身份类型方面,4名核心意见领袖具有自媒体身份,另外1名则是知名互联网社区的官方代表,这两类身份的用户在舆情事件的讨论中都较为活跃。在活跃领域方面,“帝吧官微”、“上帝之鹰_5zn”、“地瓜熊老六”均为时政类话题下的知名大V;另外2名的活跃领域虽不明确集中于时政类,但其发帖大量涉及新闻内容,与舆情事件联系较大。
Table 4
表4
表4CI-SC的核心意见领袖发现结果
Table 4
| 用户名 | 粉丝数 | 转发数 | 评论数 | 点赞数 | 身份类型 | 活跃领域 |
|---|---|---|---|---|---|---|
| 帝吧官微 | 1104011 | 50232 | 46881 | 631000 | 网络社区账号 | 时政,文化 |
| 上帝之鹰_5zn | 2305345 | 18143 | 27344 | 347728 | 翻译,自媒体 | 时政,军事 |
| 地瓜熊老六 | 6372786 | 13997 | 13436 | 122730 | 作家,自媒体 | 时政,文化 |
| 作者海菱 | 571272 | 7338 | 7148 | 73706 | 作家,自媒体 | 新闻,两性 |
| 骑扫帚的老道士 | 431468 | 2428 | 3062 | 21792 | 宗教人士,自媒体 | 新闻,国学 |
新窗口打开|下载CSV
图4展示了核心意见领袖的部分社交网络关系。研究发现核心意见领袖内部普遍存在关注关系,“帝吧官微”、“上帝之鹰_5zn”、“地瓜熊老六”三人互相关注,“作者海菱”和“帝吧官微”互相关注,“骑扫帚的老道士”则关注了所有人。核心意见领袖还普遍得到公认具有较大影响的其他用户的关注,如国家级媒体和知名公众人士等。“帝吧官微”被“共青团中央”、“中国日报”等官方媒体关注,“上帝之鹰_5zn”被“政委灿荣”等智库专家关注,“地瓜熊老六”被“观察者网”等半官方媒体关注。说明CI-SC方法发现的意见领袖受到了媒体、公众人物和其他意见领袖的普遍关注,符合意见领袖的定义。
图4
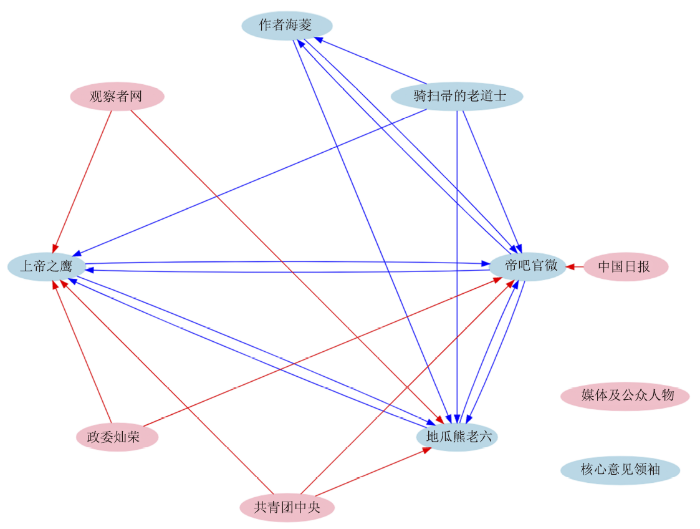 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4核心意见领袖的部分关注关系
Fig.4Part of the core opinion leaders' following relationships
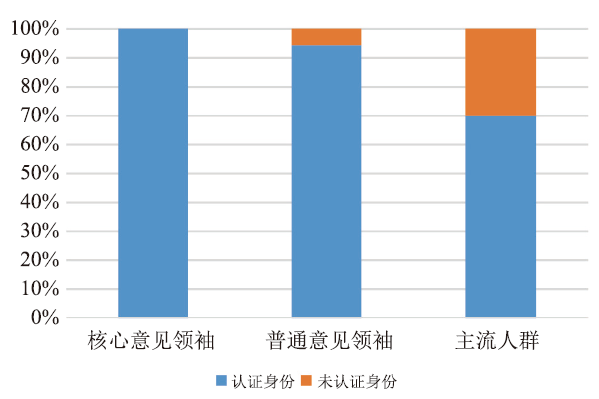
CI-SC发现的意见领袖在信用度和认证状态等方面都表现出了和主流人群的明显区别(图5、图6),其信用更好、认证比例更高,说明CI-SC发现的意见领袖的个人信息更为真实,信用更好,因而容易得到更多人认同。
图5
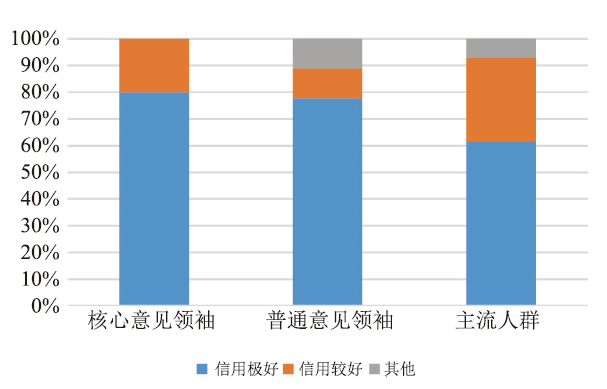 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5意见领袖和主流人群的信用等级对比图
Fig.5Comparison of credit ratings between opinion leaders and mainstream people
图6
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6意见领袖和主流人群的身份认证状态对比图
Fig.6Comparison of the authentication status between opinion leaders and mainstream people
综上,CI-SC方法能够发现在话题下具有较大影响力和明显情感特征的意见领袖。通过对发现结果的检查,可以验证CI-SC方法发现结果的正确性。
3.4 对比实验
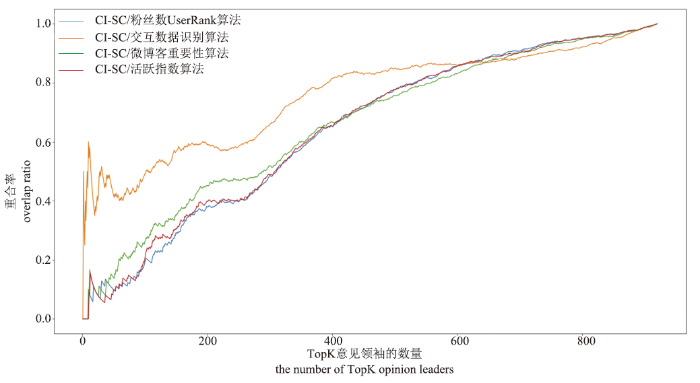
为验证CI-SC相对于传统意见领袖发现方法的创新性,在实验数据集上进行CI-SC方法和传统的基于影响力的意见领袖方法的对比实验。选用的对比算法为基于用户粉丝数的UserRank算法[17],基于交互数据的意见领袖识别算法,基于用户重要性得分的微博客意见领袖识别算法 和引入活跃指数的微博用户排名算法 。以不同算法发现的意见领袖集合的重合率作为评价指标,计算公式如下:其中K为发现的意见领袖数量,a和b代表进行对比的算法,TopResult表示基于对应算法发现的Top-K意见领袖集合。实验结果如图7所示。
图7
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图7CI-SC与各对比算法的结果重合率
Fig.7Overlap of results between CI-SC and each comparison algorithm
实验结果显示,在选取的意见领袖数量Top-K较少时,本方法和选用的所有对比算法的结果重合率都较低,随着选取的意见领袖数量上升,重合率也逐渐上升并趋于平稳。在选定的意见领袖数量不高于CI-SC发现的意见领袖数(41人)时,四种对比算法的重合率分别不高于0.136、0.601、0.166和0.155。其中,CI-SC与基于交互数据的识别算法的结果重合率相对较高,但波动较大,与其他三种算法的重合率则相对较低。由3.3中的分析可知,CI-SC方法的发现结果符合意见领袖的定义,且表现出了统计学显著性,说明CI-SC的发现结果正确有效。故对比实验中重合率较低的部分表明,CI-SC方法发现了被传统算法忽视的部分用户,这些用户在传统意义上影响力有限,但实际上其发表的内容在话题下能够得到其他用户的广泛传播和互动,属于应当被发现的意见领袖。除基于交互数据的识别算法外,其他三种算法的重合率曲线非常相似,说明这三种算法较为类似,都遗漏了相同一部分意见领袖,而CI-SC方法能够作为此类传统方法的有效补充,用于发现这部分被遗漏的意见领袖。
3.5 CI-SC适用范围的广泛性论证
上述实验基于新浪微博平台“方方日记”话题下的相关数据,对CI-SC方法的有效性和正确性进行了验证。事实上,除微博平台的此话题外,CI-SC也可以有效用于其他网络平台和事件中的意见领袖发现。CI-SC的核心数据是基于用户个人资料数据构建的用户基本影响力、基于用户在选定话题下发言的统计数据的RCL指标和基于用户发言内容的情感特征。这三大类数据指标的获取实际上是平台无关的,即在任何网络平台上都可以获得用户的这三类数据,并以此进行后续的相关计算与意见领袖发现,不同平台的区别仅仅在于最原始数据特征的名称与对应权重的取值。
以知乎平台为例,其用户的公开个人资料中包括“创作数”、“我关注的(人数)”和“关注我的(人数)”三项基本数据,分别对应微博平台的“微博数”、“关注数”和“粉丝数”,即公式(1)中的WB、FO和FAN,因此仅需要将上述数据带入(1)中的对应项,并修改对应权重,即可使用CI-SC获得知乎用户的基本影响力。另一方面,知乎帖子的数据指标与微博仅有微小不同,没有“转发数”,但同样具有“点赞数”和“评论数”指标,且另增了“喜欢数”和“收藏数”两个指标,因此仅需对(2)中的分子部分略作修改,将“点赞数、评论数、转发数的加权和”修改为“点赞数、评论数、喜欢数、收藏数的加权和”即可得到知乎帖子的RCL指标。此外,针对帖子文本内容的情感极性计算和立场计算仅仅与文本所用的语言种类有关,而不与平台直接相关,在知乎等中文平台上,CI-SC中情感分析部分的流程是完全一致的,都是对用户在话题下发表的中文文本进行分词后,调用中文情感词典进行计算。而在得到用户基本影响力、帖子RCL指标、情感特征后,CI-SC流程中剩余的数据都可被同样的计算公式得出。即在所有的中文平台上,CI-SC方法都可被应用,需要调整的部分仅包括计算用户基本影响力或帖子RCL指标时所采用的具体原始数据的个数与权重。
除中文平台外,CI-SC也可用于其他语言平台。以推特为例,其使用的原始数据与微博完全一致,用户具有“发推数”、“关注数”、“粉丝数”等数据,帖子具有“点赞数”、“转发数”、“评论数”等数据,其用户基本影响力和帖子RCL指标的计算与微博平台几乎完全相同;唯一的区别在于情感分析部分,对于推特上的其他语言用户,需要使用其他语言的情感词典。替换为对应语言词典后,CI-SC即可用于外语网络平台上的意见领袖发现。
CI-SC所使用的“发帖数”、“粉丝数”、“点赞数”等数据是应用最为广泛的数据特征,几乎所有主流平台都拥有上述数据,因此CI-SC可以在主流平台得到广泛应用。
除与平台无关外,CI-SC同样与具体的舆情事件无关。舆情事件的不同只意味着被收集到的原始数据不同,但每个事件能够收集到的原始数据最终都是确定的。而CI-SC是定量方法,在原始输入数据确定后,其输出结果就将确定。因此,不存在CI-SC只适用于某些舆情事件而不适用于另一些的可能性。只要确定了舆情事件对应的原始数据,CI-SC就可从中发现较为重要的意见领袖。
综上,CI-SC是平台无关与事件无关的,并不仅仅适用于微博平台的“方方日记”事件。在其他网络平台和其他舆情事件中,CI-SC同样可以对相关数据进行分析,并从中发现对应的意见领袖。CI-SC能够适用于大多数主流平台,对当前多平台舆情事件的意见领袖发现具有一定的实际价值。
4 总结与展望
本文针对传统的基于影响力的意见领袖发现方法局限于部分数据特征,使得一些在话题下产生了较大实际影响的意见领袖被忽略的问题,提出一种基于综合影响力和情感特征的意见领袖发现方法CI-SC。CI-SC综合考虑用户的个人属性特征和帖子的互动行为特征,并在此基础上引入用户的情感特征,通过聚类实现意见领袖发现。相比于pageRank和HITS类发现算法,CI-SC不需要获取用户之间的评论等互动关系,只需要获得用户自身的数据,因而数据采集的难度较低;此外,pageRank和HITS本质上是基于数种指标的排序算法,将对应指标排名靠前的用户视为意见领袖,而CI-SC的发现过程基于综合考虑影响力和情感特征的聚类算法,在得到类别后再使用影响力指标进行类内排序。实验表明,CI-SC方法的发现结果符合意见领袖的定义,表现出了统计学显著性,且与传统意见领袖发现方法的结果的重合率较低。说明CI-SC方法可以发现传统算法容易忽略的,在舆情事件中具有较大实际影响和明显情感特征意见领袖,在舆情分析与引导中具有一定的实际意义与应用价值。
目前对CI-SC方法的研究集中在有限规模的数据集,可在更大规模的数据集上进行进一步实验,并引入更多方面的特征,从而实现更有效的意见领袖发现。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[M].
[本文引用: 1]
[J].
DOI:10.1038/nature11421URL [本文引用: 1]
[J].
[本文引用: 1]
[C]
[本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[J].
DOI:10.1145/324133.324140URL [本文引用: 1]
[J].
DOI:10.1109/TKDE.2008.113URL [本文引用: 1]
[C]
[本文引用: 1]
[C]
[本文引用: 1]
[M]
[本文引用: 1]
[J].
[本文引用: 1]
[C]
[本文引用: 1]
[C]
[本文引用: 2]
[J].
[本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[D].
[本文引用: 1]
[C]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
DOI:10.1086/267118URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}