 ,*, 万根顺科大讯飞股份有限公司,安徽 合肥 230088
,*, 万根顺科大讯飞股份有限公司,安徽 合肥 230088The Research Development and Challenge of Automatic Speech Recognition
Liu Qingfeng, Gao Jianqing,*, Wan GenshunIFLYTEK, Hefei, Anhui 230088, China通讯作者: (E-mail:jqgao@iflytek.com)
收稿日期:2019-09-17网络出版日期:2019-12-20
Received:2019-09-17Online:2019-12-20
作者简介 About authors

刘庆峰,1973年生,科大讯飞股份有限公司董事长,中国科学技术大学信号与信息处理专业博士学位,语音及语言信息处理国家工程实验室主任,中国科学技术大学兼职教授、博导,十届、十一届、十二届、十三届全国人大代表,全国大学生创新创业联盟首任理事长,中国语音产业联盟理事长。研究方向为信号处理,语音及语言信息处理。
本文承担工作为:框架的整体结构设计、研究指导。
Liu Qingfeng was born in 1973. He received the Ph.D. degree of signal and information processing from the University of Science and Technology of China (USTC). He is the CEO of IFLYTEK, as well as the director of National Engineering Laboratory for Speech and Language Information Processing, and the adjunct professor and PhD supervisor of USTC. He was selected as National People’s Congress deputy four times since 10th NPC. He serves as the first chairman of national union for college students’ innovation and entrepreneurship, and the chairman of Speech Industry Alliance of China. His research interests include signal processing as well as speech and language information processing.
Liu Qingfeng contributed to the organization of the paper and supervised the research.
E-mail: qfliu@iflytek.com

高建清,1983年生,中国科学技术大学电子与信息专业工程博士学位,科大讯飞AI研究院副院长。研究方向为语音识别、语音及语音信息处理、对话系统。
本文承担工作为:本文第1节,第2.1节的主要贡献者,全文的修改。
Gao Jianqing was born in 1983 and received D.Eng. degree in electronics and information from the University of Science and Technology of China (USTC). He is the vice dean of IFLYTEK AI Research. His research interests include automatic speech recognition, speech and language information processing and spoken dialogue system.
Gao Jianqing contributed to the chapter 1, 2.1 and revised the entire paper. E-mail:jqgao@iflytek.com

万根顺,1989年生,江苏大学通信与信息系统专业硕士学位,科大讯飞AI研究院研究主管。研究方向为语音识别、语音及语音信息处理。
本文承担工作为:本文第2.2、2.3、2.4节的主要贡献者。
Wan Genshun was born in 1989 and received B.Eng. degree in communication and information system from Jiangsu University. He is the director of research of IFLYTEK AI Research. His research interests include automatic speech recognition as well as speech and language information processing.
Wan Genshun contributed to the chapter 2.2, 2.3 and 2.4.
E-mail:gswan@iflytek.com

摘要
【目的】本文对语音识别系统的主流技术框架及主要挑战进行了系统而全面的介绍,为语音识别领域的进一步技术研究提供参考。【方法】首先,介绍了端到端语音识别框架的主流方案;然后,提出了语音识别应用中的四大挑战性问题,即恶劣场景的识别问题、中英文混合识别问题、专业术语的识别问题以及低资源小语种识别问题。【结果】针对端到端框架稳定性不足的问题,提出了带有强化和过滤注意力机制的改进方案。针对语音识别中的挑战性难题,探讨了主流的解决方案及未来的发展方向。【结论】端到端框架的大规模商用仍存在较大挑战,四大挑战性问题的解决将对语音识别的行业应用推广起到关键的作用。
关键词:
Abstract
[Objective] This paper firstly introduces the start-of-art technical framework and main challenges of Automatic Speech Recognition (ASR) systems, then provides reference for further research in the field of ASR. [Methods] Firstly, the newest framework of end-to-end speech recognition is introduced, including the Connectionist Temporal Classification(CTC) and attention based framework. Secondly, four challenging problems in ASR applications are presented, including the recognition of noisy and distant field speech, the recognition of code-switching, the recognition of domain related terms, and minority language speech recognition with limited resources. [Results] For the problem of robustness of end-to-end ASR system, an improved enhancement method and filtering attention mechanism is proposed. The start-of-art methods and future development directions are discussed regarding to the challenging problems of ASR systems. [Conclusions] There is a major challenge for the commercialization of the end-to-end ASR systems, and the research on four challenging problems plays a key role in the application of ASR systems.
Keywords:
PDF (9686KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
刘庆峰, 高建清, 万根顺. 语音识别技术研究进展与挑战. 数据与计算发展前沿[J], 2019, 1(2): 26-36 doi:10.11871/jfdc.issn.2096-742X.2019.02.003
Liu Qingfeng.
引言
近年来,人工智能技术正经历一场快速发展的浪潮,尤其是深度学习技术[1,2]的不断创新、大数据的持续积累和计算能力的稳健提升,更是推动了人工智能技术的跨越式发展。而语音识别作为人工智能领域最成熟的技术之一,已经广泛应用于教育、医疗等行业。语音识别不仅改变了人机交互的模式,使人类能够以最自然的方式与机器进行对话,而且具备将非结构化的语音转换成结构化文本的能力,大幅提升了相关从业人员的工作效率。语音识别作为实现人机交互等智能应用的关键技术,主要通过信号处理和模式识别等技术研究,让机器能够“听懂”人类的声音。语音识别技术的研究可以追溯到上世纪50年代,贝尔实验室首次实现了十个英文数字的识别系统[3]。而从20世纪60年代开始,语音识别主要集中在孤立词以及小词汇量的研究,使用的方法也以简单的模板匹配为主[4]。进入80年代以后,语音识别的研究方向逐渐转向基于统计模型的技术思路。以高斯混合分布-隐马尔可夫模型(GMM-HMM)为主导的语音识别框架在语音识别研究中占据了主流地位[5,6],并实现了从孤立词识别到大词汇量语音识别的突破性发展。虽然主流的GMM-HMM框架日趋稳定,但语音识别系统却始终没有在实际应用中得到普遍的认可和推广,这主要是因为语音识别的精度和速度远没有达到实用的门槛。
语音识别的研究瓶颈一直持续到了2006年。随着深度置信网络(Deep Belief Networks, DBN)的提出[1],基于深度神经网络的研究(Deep Neural Network,DNN)再次迎来了复苏,也进一步推动了语音识别技术的发展。语音识别技术逐渐走出了传统的GMM-HMM框架,走向了以前馈深度神经网络(Feedforward Deep Neural Network, DNN)[7,8,9,10,11]、循环神经网络(Recurrent Neural Networks, RNN)[12,13]和卷积神经网络(Convolutional Neural Networks, CNN)[14,15,16,17,18,19]为代表的深度学习框架,并取得了很好的实用效果。基于DNN的语音识别框架使用前馈神经网络结构替换传统的混合高斯模型,可以使用一个模型对HMM的所有状态后验概率分布进行预测;同时,相比GMM模型,DNN可以利用上下文相关的语音特征拼接所包含的结构化信息。DNN框架被引入到语音识别领域具有重要的意义,不仅大幅改善了连续语音识别的效果,而且带来了思路的转变,自此以后深度学习领域中的各种模型结构不断被引入语音识别领域,并与语音的特点相结合,将语音识别带入了快速发展期。因为语音具有天然的上下文长时相关性,而RNN模型可以利用反馈连接对历史信息和未来信息进行有效的记忆和利用,基于RNN的语音识别框架取得了较DNN模型更优的效果。而基于CNN的语音识别框架,则从另一个角度推动了语音识别技术的又一次重大改进。卷积神经网络采用局部感受野的机制,对语音信号中的干扰信息,如噪声、说话人变化等,具有更强的鲁棒性;同时,通过多个卷积层和池化层的累积,保证了CNN网络可以看到非常长的历史信息和未来信息,从而具备出色的时序表达能力。
尽管深度学习的发展将语音识别系统的效果提升到了前所未有的高度,但语音识别在大规模的商用过程中仍面临诸多挑战。本文首先重点介绍了最新的基于端到端的语音识别框架及其面临的问题和解决方案。其次,针对语音识别应用过程中遇到四大挑战问题,包括恶劣场景的识别问题、中英文混合的识别问题、专业术语优化问题以及低资源小语种识别问题,给出可能的解决方案。
1 端到端语音识别框架
目前,主流的基于深度神经网络的语音识别框架主要由声学模型、语言模型[20,21,22,23,24]以及发音模型三部分构成。语音识别的过程是在声学与语言模型条件独立性假设的基础上,实现各个模块的串联,进而逐步实现语音信号序列到文本序列的转化,而这些假设在某些场景下是不合理的。同时,因为声学模型和语言模型是独立训练的,并通过后端的解码器将两者融合,这就造成了声学模型与语言模型之间的关联性较弱。另一方面,这种语音识别方案需要针对不同的语种,甚至是不同的方言,构建不同的发音字典,存在专业门槛高、构建成本高、周期长以及质量差等多种问题。针对这些问题,基于深度学习的语音识别技术近期的研究热点是如何进行端到端的语音识别[25,26,27],即将语音识别问题转为序列到序列直接转换的问题。端到端的模型不仅可以一步实现语音的输入到解码结果的解析,更是可以省去大量繁杂的前期准备工作,如帧级别对齐标注的获取和发音词典的制作等。结合神经网络的端到端语音识别技术目前主要分成两类:一类是连接时序分类算法(Connectionist Temporal Classification,CTC)[28]方法,另一类是基于注意力(Attention)机制的编码-解码(Encoder Decoder)[26]方法。
CTC算法主要用来改善训练的音频序列和文本序列难以一一对应的问题。传统的语音识别框架中对于声学模型的训练,每一帧的输入都需要一个标签才能对数据进行有效的利用和训练。标签的获取本身就需要通过反复的优化确保强制对齐(Force Alignment,FA)的准确性。而基于CTC作为损失函数的声学模型训练方案更关注预测输出的结果序列与真实序列之间是否相近,不需要预先对训练数据进行对齐处理,只要保证提供输入特征和输出预测序列即可。即对于一段语音特征输入,只需要通过引入Blank表示标注序列即可,而CTC所对应的预测输出尖峰位置就是其对应的建模单元,而其他位置均是Blank。因此,相较于传统的声学模型的帧级别的训练方案,CTC本身已经初步具备了端到端的声学建模能力。但是,对于CTC的使用也存在一定的限制和瓶颈。如CTC并没有单独的语言模型模块,缺乏一定的语言模型信息构建能力,本质上无法实现声学模型和语言模型联合优化的初衷。
基于注意力机制的编码-解码方案,则更好的解决了这一问题。编码-解码方法最早在机器翻译领域取得效果的提升。而在2017年,Google将其应用于语音识别领域并在大数据量获得了领先于传统语音识别方案的效果[29]。基于注意力机制的编码-解码语音识别框架主要由编码端、注意力模块和解码端构成。编码端和传统的声学模型建模框架类似,主要是将输入的语音特征信号经过深层神经网络编码,映射成高级的隐层特征;然后将该部分隐层特征作为输入,利用注意力模块学习输入与预测输出之间的对齐方式;最后将注意力模块的输出传递给解码端,生成一系列预测输出的概率分布,由于解码端的当前时刻的输出与上一时刻的输出相关,因此解码端也具备语言模型的建模能力。
端到端语音识别技术的突破,不再需要利用HMM来描述音素内部状态的变化情况,而是将语音识别的声学模型、语言模型和解码模块统一成一个神经网络模型,使语音识别建模框架朝着更简单和更高效的方向发展。虽然端到端语音识别系统在整体效果上已经超过了传统语音识别框架,但是其稳定性有所不足。目前的问题主要集中在以下几个方面:
首先,基于注意力机制的编码-解码方案引入了Attention机制实现对于输入特征与输出序列之间的对齐,但是,目前的方案还无法对Attention机制实现完全准确的控制。同时,因为上一时刻的解码结果又会对当前时刻的识别结果产生影响,所以端到端的解码结果容易出现一些传统语音识别框架不会出现的错误,如重复出词、乱出词等。为了尽可能的降低因输入特征的干扰造成的Attention结果的波动,科大讯飞提出了一种带有强化和过滤功能的Attention机制,如图1所示。对于通过全序列深度卷积神经网络提取出的语谱图特征,经过多层次、分辨率极高的卷积门控操作,能够进一步强化特征之间的联系并过滤掉特征中的干扰信息,最终得到的特征经过注意力机制嵌入到端到端的语音识别系统中,有效的改善了识别效果的鲁棒性。同时,为了更直接的加强对Attention机制的控制,可以将CTC方案与Attention机制结合起来,如通过CTC的输出对Attention的分布加以约束,使得Attention模型能够更准确的实现对于关键信息的筛选,从而缓解各种不稳定情况。
图1
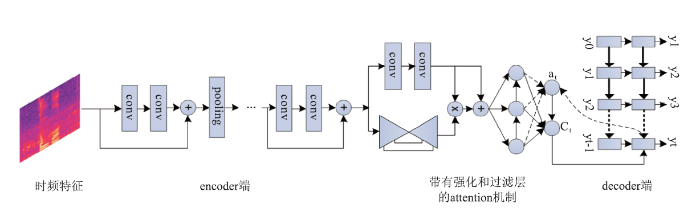 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1带有强化和过滤功能的注意力机制
Fig.1Attention mechanism with enhanced and filtering
其次,基于注意力机制的编码-解码方案实现了声学模型与语言模型的联合训练,但由于声学训练语料的量级远少于语言模型训练语料的量级,导致了端到端模型在语言模型覆盖度方面有一定程度的减弱,所以在领域相关的专业术语的识别效果方面较传统语音识别方案依然有明显的差距。针对这个问题,可以考虑在解码端结合语言模型进行训练,使编码-解码模型的解码路径能够有更大的选择空间,如Cold Fusion[30]和Deep Fusion[31]是两种常见的方法。其中Deep Fusion将端到端模型和语言模型各自训练好,再通过门控操作将两者结合并进行微调,结合的位置通常在Decoder端的输入部分。而Cold Fusion则是在端到端模型训练过程中直接加入预训练好语言模型进行联合训练,并通过门控操作在输出层前融合,相比Deep Fusion结合程度更浅。同时,我们也可以考虑增加额外的文本语料作为Decoder端的输入[32],对解码端所包含的语言模型信息进行进一步的辅助优化。
端到端语音识别模型虽然实现更为简单,结果更加准确,但是在复杂的场景下语音识别结果稳定性不足的缺点仍然会对用户使用体验带来较大的影响,所以端到端语音识别系统在各种场景的大规模推广仍然任重而道远。
2 语音识别挑战性问题
得益于深度学习的快速发展,语音识别系统的准确率取得了大幅提升,语音输入、语音搜索以及语音交互等产品已经逐步达到了实用门槛,并日臻成熟。但是,要想真正实现语音识别系统在各种场景中更自然、更便利、更高效的应用,仍然面临说话风格、口音、录音质量等诸多的挑战。本节将重点介绍语音识别领域目前亟需研究和解决的四大挑战性问题,包括恶劣场景的识别问题、中英文混合识别问题、专业术语的识别问题以及低资源小语种识别问题,这些问题的解决很大程度上影响了语音识别系统进一步商用的进程。
2.1 恶劣场景下的识别问题
语音识别系统面临的第一个挑战性问题是恶劣场景下的识别问题。具体的,在远距离、带噪等复杂的使用场景中,各种噪声、混响、甚至是其他人说话的插入,容易造成语音信号的混叠与污染,对语音识别的准确性产生较大的影响,因而需要对语音识别的模型鲁棒性提出更高的要求。下面重点介绍语音混叠问题及远场噪声问题的解决方案。2.1.1 语音混叠问题
语音识别的真实场景复杂而多变,尤其是当同时说话的人数已经不再局限于一个人,而是同时出现两人或者多人的时候,语音识别的效果就会出现大幅的下降。这一难题就是语音混叠问题,也就是著名的鸡尾酒会问题(Cocktail Party Problem)。鸡尾酒会的问题对于具备听力选择能力的人来说并非难事,因为人能够将注意力集中在某个人的谈话之中而忽略背景噪声或者其他人的谈话。而对于语音识别系统来说,解决鸡尾酒问题的任务就是在这种高度重叠的音频中,如何能够将不同说话人的内容分离和识别出来。
为了推进鸡尾酒会问题的解决,被称为“史上最难语音识别任务”的国际多通道语音分离和识别大赛CHiME-5[33]设置了日常家庭环境中的远场语音识别任务。比赛数据由二十个针对真实的家庭晚餐聚会场景录制数据组成,每个晚宴均有四名参与者,并且其中两人担任主人角色,两名担任客人角色,他们四人互相之间都很了解对方,因而会在晚宴过程中产生很自由的对话。由于是四人自由交谈,抢话和同时对话时常存在,此时对于其中一个目标人来说,其他三个说活人的语音就是干扰语音,在进行语音识别时会造成很强的干扰。
针对CHiME-5设置的鸡尾酒会问题,科大讯飞提出的解决方案取得了该项赛事的四项冠军。针对使用场景中频繁出现的人声干扰,通常采用基于深度学习的说话人相关的语音分离框架进行解决。然而,由于从 CHiME-5 中能够得到的单一目标人的数据非常有限,这些数据量难以支撑语音分离模型的训练。在这种资源受限的情况下,我们提出两阶段的语音分离方案[34,35],具体框架如图2所示。该方案能够有效解决针对当前目标人训练数据不足的问题,使得语音分离模型在经过两个阶段的训练之后性能得到显著的改善。具体地,在第一阶段,使用有限的非混叠的目标说话人数据和干扰人数据训练分离模型 SS1,该模型能够去除人声干扰,并且目标人数据的分离纯度可以得到保证。在第二阶段,先对大量的真实混叠数据使用 SS1 模型进行语音分离,然后把分离后的数据补充到非混叠数据中,同样混合干扰人数据制作第二阶段分离模型的训练数据,得到分离模型SS2,这样用于语音分离的训练数据将大幅增加。同时,为了缓解SS1模型对于目标语音的破坏,SS2模型采用预测时频掩蔽的方式进行训练以避免语音的失真。实验结果表明,两阶段的语音分离框架在 CHiME-5 的真实数据上得到了成功应用,使得语音分离在资源受限的场景下也能取得很好的分离性能。
图2
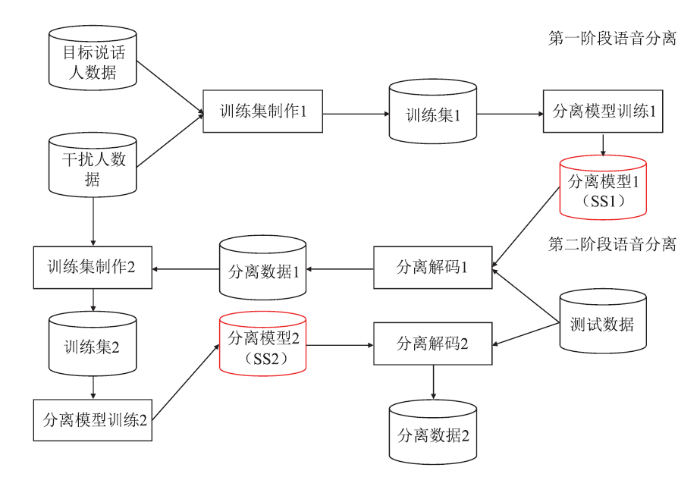 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2两阶段语音分离框架结构图
Fig.2Two-stage speech separation framework
2.1.2 远场噪声识别问题
鸡尾酒会折射出来的问题是语音识别在真实使用中的困境之一,恶劣场景下的另一个困境是高混响和高噪问题。目前针对远场、高噪等恶劣环境的技术方案主要是使用前端信号处理和后端语音识别模型给合的方案。前端主要使用麦克风阵列进行降噪、解混响,具体地,根据实际使用场景设计麦克风阵列,并利用多个麦克风采集多路时频信号,进而利用卷积神经网络学习波束形成,从而在目标信号的方向形成一个拾音波束,并衰减来自其他方向的反射声,从而提高输入语音识别系统的语音质量。同时为了提升后端语音识别模型的鲁棒性,通常会选择对干净的语音进行加噪,或者加混响等操作,并与干净语音一起进行混合训练。
为了更好的解决恶劣环境下的语音识别问题,目前的解决思路主要集中在两类:
(1)基于前端信号处理和后端语音识别联合建模的方案:传统波束形成技术的目标是信号层面提高语音的质量,而不是直接优化语音识别的正确率,联合建模的方案可以采用神经网络来模拟波束形成相关的滤波器,并且直接采用识别的目标来进行优化。联合建模将多通道数据形成的一个增强后的单通道信号并与传统的单通道的信号进行融合送入识别网络。当然,联合建模方案还可以结合说话人分离等多任务学习的技术来提升整体的效果。这种针对前端网络的降噪和解混响方案,对于提高语音识别准确率更具有针对性和有效性。
(2)基于音视频结合的多模态融合方案:在远场、高噪的场景下,语音信号的损失较大,但视觉信息可以不受外部环境噪音的影响,而说话人的唇形可以一定程度上辅助语音识别系统提高识别准确率。所以在恶劣场景下,考虑语音和视觉信息结合的方式,即音视频多模态识别来提升说话人分离和语音识别的效果也是一个重要的研究方向。
2.2 中英文混合识别问题
语音识别系统面临的第二个挑战性问题是多语言混合识别问题。随着不同国家之间文化交流的日益增进,多语种混合的说话风格越来越频繁的出现在日常交流场景甚至是正式会谈等场合,其中又以中英文混杂的说话风格最具代表性。例如:“你今天要不要去shopping?”,“听说最近好多商场都有很大的discount”。语种混合问题也是当前语音识别技术领域面临的重要难题,因为在传统语音识别方案中,不同语种的语音识别系统是分别独立建模的,所以如何针对不同的语种进行建模单元的有效融合和区分、以及如何处理中英文混合场景中语音数据、文本数据的获取等问题,都是中英文混合识别的难点问题。针对中英文混合场景面临的易混淆的问题,传统的解决方案通常考虑利用语言学知识对不同语种的建模单元进行有效融合,如将英文按照中文发音的方式进行建模,或者是考虑对中文和英文的建模单元进行部分共享、部分独立的建模方式。而针对训练语料稀缺的问题,通常考虑利用机器翻译等方法生成更多的中英文混合文本语料,然后通过合成的方式模拟平行的声学数据加入训练,同时将更大量级的文本语料用来进行优化传统语言模型的中英文分布。但是,这些解决方案对于中英文混合场景下中文、英文区分度的改善有限,中英文混合识别的准确率距离实用仍然有较大的距离。
端到端语音识别方案的出现,给中英文混合问题的解决提供了一个新的思路。因为建模单元的选择空间更大,在端到端识别框架中,可以更好的实现中文、英文甚至是多语种的融合。中英文场景下英文误识别为中文,或者中文误识别为英文的情况较传统方案大幅减少。但是,中英文混合场景要想真正的实现好用,仍然面临很多挑战,包括数据稀疏的问题以及英文发音不规范的问题等。针对这些问题的解决方案包括:
(1)基于中英文语料的生成提升中英文语言模型的覆盖度:类似端到端语音识别框架中通过增加额外的文本语料辅助解码端语言模型优化的方案,中英文场景也可以通过增加大量的中英文混合文本进行辅助优化。但是,使用传统的机器翻译方式构造的中英文文本与人们的真实使用习惯仍有较大的区别。如何利用已经获取的有限的中英文文本生成更加符合用户习惯的中英文混合语料,成为了攻破中英文语料稀疏问题的关键。我们可以考虑结合生成式对抗网络(Generative Adversarial Networks, GAN)[36]的方案,通过已有的真实场景中收集到的有限中英文数据,对通过GAN生成的中英文文本语料的分布进行约束,尤其是英文部分的替换位置,使其符合真实的使用场景,从而可以生成更自然的中英文混合语料。
(2)基于中英文发音的模糊矩阵缓解中英文场景的英文混淆度:考虑到中英文混合场景中的发音人大多存在英文发音不够准确或者中英文发音的音素交融等问题,我们需要进一步考虑在解码端给予英文更大的解码空间。例如,当解码端预测出下一个识别单词为英文时,通过提前构建的英文单词发音模糊矩阵,提供更多的近似英文路径以供选择。而当解码端预测出来的下一个单词为中文时,因为在端到端框架下英文多采用子词方案,与中文建模单元的混淆程度较高,为了避免对英文路径的完全割离,同样需要通过中文与英文子词之间的发音混淆矩阵提供部分英文候选,并结合语言模型对最终的解码结果路径进行确定。通过使用这种方案有可能进一步提高中英文混合场景下英语识别的准确率。
2.3 专业术语识别问题
语音识别应用中的另一个重要挑战是特定领域专业术语的识别问题。专业词汇的识别准确率很大程度上依赖于语言模型训练语料的覆盖度。由于行业应用领域的广泛性,训练语料不可避免的存在稀疏性问题,而且专业词汇出现的概率通常明显低于通用域词汇,因此专业词汇有较大风险识别成发音相近的通用词汇。目前常见的解决专业术语识别问题的方案通常有两种。一种是基于高速缓存(Cache)的快速自适应方案,即通过记录连续语音中已经出现过的专业词语,然后通过插值的方法提升该专业词的概率。但是因为这种方式对于语音识别系统的识别效果依赖性较大,只能改善识别结果中出现并且正确的专业词汇。同时,对于专业词汇的上下文利用不足,所以整体上对于专业词汇的效果提升相对有限,难以广泛推广。另一种方案是使用N-gram插值的方式,即通过训练当前专业词汇所属领域相关的语言模型,并与通用语言模型插值,提升该领域专业词汇的N-gram概率。当用户能够提供该领域相关素材和资料的时候,可以直接利用该部分专业资料进行专业领域语言模型的训练;当用户无法提前获取该领域相关文本资料的时候,可以考虑利用无监督的方案,通过对识别结果进行关键词的抽取,并利用互联网产生的大数据文本搜索相关的文本资料作为当前专业领域的文本语料,进而实现领域语言模型的训练。当然,这种使用场景下,我们也可以提前训练好多个专业领域的语言模型,然后在解码时通过利用识别结果选择合适的领域,以实现专业术语识别效果的优化。基于N-gram插值的方式使用代价较大,存储和生成插值后的语言模型以及解码资源相对比较耗时。所以,目前主流的研究方向多集中在保证改善专业词汇的识别效果的同时,如何提升解码的效率。
而端到端语音识别系统的应用,同样给专业术语问题的效果提升带来了新的挑战。如第1节所介绍,在专业术语的识别准确率方面,端到端语音识别系统与传统方案相比,受限于训练语料的原因而处于劣势。因此,在端到端的框架下专业术语的效果改善也是一个重要的研究方向,目前的主流方案包括:
(1)基于CLAS的端到端热词方案:语音识别任务中,一个用户的说话内容通常与他所在的特定的上下文环境相关,而CLAS(Contextual Listen Attend Spell,CLAS)[37]是一种新颖的将这种上下文信息应用于端到端语音识别框架的方法。因为端到端框架中的解码端通过Attention机制可以有效的“关注”到输入语音的对应部分,而CLAS在此基础上引入了对上下文文本的Attention,即解码端除了对语音特征输入部分Attention外,还对上下文文本进行Attention,结构上较通用端到端框架多了一个上下文文本的编码和Attention。CLAS方案通过联合优化热词和语音部分的Attention机制,使得模型可以有效的利用上下文信息,从而使得专业术语的识别效果更准确。
(2)基于专业领域的语言模型融合方案:如第1节所述的解码端结合语言模型进行优化的Cold Fusion和Deep Fusion方案对于通用语言模型的优化是一种很好的补充。但是,当需要针对性解决某一领域的识别效果问题时,需要重新进行端到端模型的训练,优化代价较大。另一个方案是Component Fusion[38],在训练的时候考虑使用训练数据相关的文本得到的语言模型与解码端进行联合训练,而在测试的时候使用与测试集所属领域相关的专业领域语言模型进行解码。进一步地,对于多领域的使用场景,为了避免频繁的语言模型的切换,可以在训练时增加门控机制,解码时在多个领域语言模型之间自主选择。
2.4 低资源小语种识别问题
连续语音识别系统依赖于大量的有监督数据,对于常用的语种如中文、英文等,数据资源丰富,效果已经达到可用的水平。而随着全球化进程的推进,小语种识别在旅游、商务等场景的应用需求愈发迫切。因此,如何在低资源下构建高准确率的小语种语音识别系统也是识别领域的一个研究热点。小语种的识别效果首先受限于数据资源。小语种因使用人口基数少,使用范围小,导致数据资源收集相对困难,标注成本较高。其次,在传统语音识别框架下,需要相关的语言专家为每一个小语种标注发音词典等,技术难度较大;同时,需要为每一个语种构建声学模型与语言模型,导致训练流程复杂。因此,低资源小语种识别目前的解决方案一般围绕训练数据增广以及多语种融合的端到端识别框架的研究展开。
(1)训练数据增广方案:常规的训练数据增广方案包括加噪、加混响以及音频变速等。另外,利用多说话人的合成系统也可以一定程度上增加小语种语音识别系统的训练数据,缓解低资源现状。基于多说话人的语音合成数据增广方案描述如下,首先,需要基于多说话人的领域数据训练语音合成系统,并且在训练过程中使用说话人的Embedding引入说话人信息;其次,利用合成器和目标领域文本,通过随机选择说话人的标识合成多个说话人的语音数据。最后,将真实数据和合成数据混合进行语音识别模型训练,提高小语种语音识别的准确率。
(2)多语种融合的端到端识别框架:多语种联合建模方案采用端到端的识别框架[39],该框架将多语种训练语音全部输入同一个编码网络中,接着采用Unicode作为第一级解码器的输出单元。因为Unicode是计算机科学领域里的一项业界标准,包括字符集、编码方案等,Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求,所以采用Unicode作为一级解码器输出单元,可以将所有语种语音统一建模且不需要发音词典,真正做到端到端的多语种混合建模。该框架实现了多语种数据之间的共享,由于不同语种在发音上存在相似性,因而低资源的小语种系统可以共享高资源的数据,从而可以提高低资源小语种识别系统的鲁棒性。
在此基础上,针对一级解码器统一解码成Unicode编码,可能存在语种相互串扰的问题,可以尝试增加语言模型约束解码模型,即在一级解码器后增加二级解码器,采用特定语种的单语种文本语料训练语言模型,结合加权有限状态机与一级解码器串联,实现二级约束解码,将识别结果约束在特定语种内,从而提高特定语种的语音识别的准确率。
3 总结与展望
本文对语音识别当前的研究进展及其所面临的挑战进行了详细的介绍。首先介绍了语音识别领域最为热门的端到端语音识别框架,然后讨论了语音识别系统的四个挑战性难题,即恶劣场景下的识别问题、中英文混合识别问题、专业术语识别问题以及低资源小语种识别问题,针对每种问题,给出了可能的解决方案和未来的研究方向。当然,除了上述重点介绍的难题外,语音识别的研究热点还包括口音和方言、个性化、多模态识别等。虽然语音识别系统还无法实现在任意人群、任意场景、任意资源下都可以取得较好的效果,但是如果研究人员能够逐步攻克上述难题,并在与实际产品的结合方面更近一步,将会满足更多行业的需求,解决更多实际的问题。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[C]//
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[C]//
[本文引用: 1]
[C]//
[本文引用: 1]
[C] //
[本文引用: 1]
[D].
[本文引用: 1]
[J].
[本文引用: 1]
[J].
[本文引用: 1]
[本文引用: 1]
[J].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}