全文HTML
--> --> -->目前链路预测相关理论方法研究主要围绕基于马尔科夫链、最大似然估计、概率模型、网络结构相似性等数学领域和统计物理的观点和方法展开. 早期的链路预测领域普遍关注的是马尔科夫链和机器学习, 主要存在着计算复杂度较高, 参数设置不具有普适性等问题[8]. 也有****提出从似然分析的角度构建链路预测框架, 比较经典的有层次结构模型[9]和随机分块模型[10]. Pan等[11]提出的闭路模型, 拥有比前两者更好的预测精度. 似然分析的优点在于能够从理论上帮助我们理解网络结构特征, 然而受限其自身理论的复杂性, 这类方法不是应用性很强的方法, 即使构思巧妙, 在处理大规模网络时也会显得吃力. 最早由 Taskar等[12]提出的概率模型是数据挖掘领域的传统模型, 该模型在预测时同时运用了网络的结构信息和节点的属性信息, 概率模型拥有较高的预测精确度, 但是同时产生的高计算复杂度以及其参数设置存在非普适性, 都限制了该类方法的应用范围. 得益于David和Kleinberg[13]在2007年有关链路预测结构相似性的论文, 基于网络结构相似性的链路预测问题在近年受到越来越多的关注. Zhou等[14] 把链路预测问题和评价指标都进行了简化, 很多研究人员开始利用同样的数据和指标分析链路预测问题. 基于相似性的算法, 作为最简单的链路预测算法框架, 其中一系列算法复杂性低但预测精度不错的局部相似性指标的提出, 大幅度增加了链路预测在超大规模网络中的可应用性.
利用链路预测算法精准地预测网络的未知结构有着广泛的应用前景. 例如, 在军事对抗中, 通常只能侦测到敌方作战网络的部分结构信息, 如果我们可以获得更多更准确的信息, 就可以制定一定的优先级规则或重要性标准来选择性地攻击网络中的关键节点或连边[15,16]; 在生物实验中, 研究人员需要通过大量的实验研究去推断探索细胞组分内部的交互作用, 一个具有指导作用的预测结果能有效降低实验成本并帮助人类理解生物网络连边演化机制的规律[17,18]; 社交网络中, 读懂用户的兴趣偏好和喜怒哀乐, 对企业的发展事至关重要, 一个好的“猜你要关注”推荐能够牢牢地黏住老用户、吸引新用户[19,20]. 此外, 一个优秀的链路预测算法往往蕴含着一种可能的网络演化机制[21-24]. 遗憾的是, 除非站在上帝视角, 否则没有人能判断一个链路预测算法是否足够精准. 如果网络的节点对之间随机连接, 任何算法可能都会无功而返, 难以做出有效预测; 相反, 面对一个有特定的连边演化机制, 非常规则的网络, 一个足够优秀的方法能够实现精度很高的预测. 此外, 即使是同一个网络, 不同链路预测算法的准确性也不尽相同, 这种精度值只能相对地反映出网络对于某种特定预测算法的预测精度, 算法不同, 精度也随之改变, 并不能刻画网络自身的固有的链路可预测性, 很多时候, 我们都面临着是预测算法不合适还是网络本身就难以预测这样一个网络与算法的选择和匹配问题.
显然, 网络中待预测的连边集合与网络中不存在的连边集合交集为空集, 无论预测的准确性和效率如何, 理论上我们总可以通过无限加边命中所有待预测的链接. 然而这种上界是没有价值的, 不考虑成本的加边会带来巨大的成本消耗和结构噪音, 这样的情况显然偏离了链路预测的初衷. 如果能够获悉一个网络的链路信息能够多大程度被预测出来, 就能够提供一个导向, 确定当前算法是否接近或者已经达到目标网络的可预测上限. 因此, 刻画网络多大程度上能够被预测是链路预测中首先需要解决的问题, 这个问题在相关文献中被称为复杂网络的链路可预测性问题.
近年来链路预测的理论和实证研究发展迅速, 但绝大部分研究的目的都是希望提出更准确的预测算法[25,26], 关于复杂网络链路可预测性的研究起步较晚, 相关成果少见报道. 许小可等[27] 最早从理论上比较了各种算法的优劣, 分析多个网络演化过程中形成链接的两个节点之间的拓扑距离分布, 阐明了传统基于共同邻居相似性指标可有效进行链路预测的机理, 从理论上分析了9 种基于共同邻居相似性算法的预测上限. Lü等[28] 提出结构一致性的概念, 认为网络“可被预测的程度”, 是网络的一种重要固有属性. 通过对已知网络进行扰动, 刻画重构的邻接矩阵和真实邻接矩阵的差异. 如果丢失的连边没有显著改变网络的结构, 那么这个网络是可预测的, 即网络的结构一致性越强, 网络可预测性越好. 熵被广泛用来测量物理系统中的无序度, Yin等[29]设计了基于证据推理(Dempster-Shafer theory) 的链路预测算法, 从香农信息熵的视角出发, 分析了网络链路信息的可预测性.
本文拟从特征谱的视角去理解网络拓扑信息, 并刻画网络的链路可预测性. 首先基于特征谱理论给出复杂网络链路可预测性的数学描述, 提出可预测性指标. 在此基础上, 通过计算和分析不同实证网络的链路可预测性, 验证该指标的有效性.





在网络进行链路预测之前, 我们并不知道网络缺失的部分和未来演化中可能出现的连边连接情况, 因此, 在实验中, 将网络中已有的连边集合











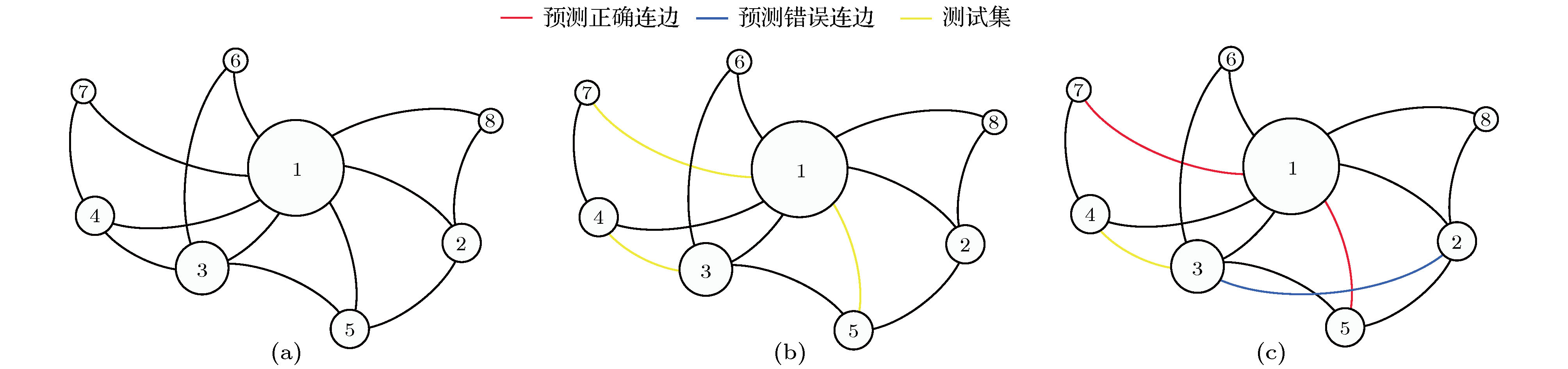 图 1 链路预测问题示意图
图 1 链路预测问题示意图Figure1. Illustration of link prediction problem
在这个例子中我们选择资源分配算法[14]进行链路预测, 选取该算法认为存在可能性最高的3 条连边添加到网络中, 如图1(c) 所示, 红色连边表示正确预测, 蓝色连边表示错误预测, 可以看到, 算法正确预测了连边




3.1.复杂网络的特征谱
复杂网络的特征谱是代数图论的基本研究课题, 经过多年的研究, 如文献[33] 所述, 已有成熟的理论体系和丰富的研究成果. 网络的特征谱提供了包含网络功能和动力学行为在内的大量信息, 可以被形容为网络的“指纹”, 即网络与其特征谱是一一对应的, 不同类别的网络有着完全不同的特征谱. 因此, 通过分析和识别特征谱, 我们就能够锁定目标网络. 进一步, 特征谱不仅是网络的“指纹”, 还是网络的“脉象”. 通过分析特征谱这一网络“脉象”, 可以得到大量的网络结构信息. 例如, 通过拉普拉斯矩阵(Laplace matrix) 的最大特征根我们可以估计网络的度序列; 分析特征谱还可以挖掘网络社区结构; 网络的中心性和二部分性也可从特征谱得出[34-37]. 最近有研究表明, 网络的特征值谱还可以表现网络结构和动力学(例如神经与激发序列)的层次性[38].令





















2
3.2.基于特征谱视角的网络链路可预测性
近年来, 很多统计物理领域的****基于特征谱研究了图的沟通性(communicability)[34] 和可扩张性(good expansion, GE)[39]. 图的沟通性指网络中不同节点之间进行交流或传递信息的能力, 而可扩张性指那些既稀疏同时又高度连通的节点间的沟通能力. 实际上, 统计物理角度的沟通和扩张, 在网络信息的视角中, 可以理解为网络结构某种程度上的演化和发展. 链路预测, 作为网络信息挖掘的技术手段, 一个很重要的功能便是预测缺失连边和未来可能存在的连边. 可以说, 链路预测算法与网络连边形成机制相辅相成, 好的链路预测算法本身就给出了很多网络演化可能机制的暗示; 反之网络的链路可预测性也可以理解为网络连边演化机制的另一种表现形式. 因此, 我们可以认为, 沟通性和可扩张性这两个指标所刻画的拓扑信息从某种程度上来说和网络的链路可预测性是相似的, 即具备较好的链路可预测性的网络, 一般也具有较好的沟通性和可扩张性.已有研究表明, 可扩张性好的网络同时也表现出良好的沟通性, 且这些网络特征谱的最大特征根





 图 2 无标度网络特征谱直方图
图 2 无标度网络特征谱直方图Figure2. The histograms of eigenvalues of random sacle-free networks
2
3.3.可预测性的数学表达式
在各种各样衡量网络结构属性的指标中, 文献[41]提出的子图中心性是基于网络特征谱的指标. 其认为闭环回路的路径长度越小, 回路信息交流越便利, 节点之间的联系越紧密, 对节点的中心性贡献越大. 节点

































4.1.模型网络的可预测性分析
相比于随机网络, BA无标度网络具有节点生长和边的偏好链接(preferential attachment)两种明确的生成机制, 即新加入的节点更倾向于与那些具有较大连接度的节点相连. 一个新节点与一个已经存在的节点












 图 3 不同节点规模下, 模型网络可预测性
图 3 不同节点规模下, 模型网络可预测性

Figure3. The link predictability of model network versus


同时, 为了清晰地对比各种链路预测算法在这两类模型网络中的表现, 我们生成一个节点数为1000, 平均度为6的BA无标度网络和与之同样规模的随机网络进行对比实验, 实验结果如图4 和表1所示. 表1给出了12种基于相似性的链路预测算法在这两个模型网络中的精确度(precision). 包括 6种基于节点局部信息的相似性指标: 共同邻居(CN), Adamic-Adar(AA), 资源分配(RA), 偏好连接(PA), Individual Attraction(IA) 和CAR指标; 3 种基于路径的相似性指标: 局部路径(LP), Katz和LHN-II指标; 3种基于随机游走的相似性指标: 平均通勤时间(ACT), 重启的随机游走(RWR), 局部随机游走指标(LRW), 具体的算法原理参见文献[25]. 实验通过随机抽样的方式, 将训练集和测试集按照 9∶1 的比例进行划分, 我们固定预测连边的比例, 令L等于测试集中的连边数量.
| 网络 | $ p $ | CN | AA | RA | LP | IA | CAR | PA | Katz | RWR | ACT | LRW | LHN-II |
| BA网络 | 0.975 | 0.423 | 0.324 | 0.272 | 0.415 | 0.271 | 0.283 | 0.594 | 0.412 | 0.136 | 0.507 | 0.085 | 0.003 |
| 随机网络 | 0.543 | 0.015 | 0.008 | 0.009 | 0.008 | 0.009 | 0 | 0.030 | 0.008 | 0.002 | 0.020 | 0 | 0.001 |
表1链路预测算法在模型网络中的表现
Table1.Performance of link prediction algorithms in model networks.
 图 4 无标度网络和随机网络可预测性示意图
图 4 无标度网络和随机网络可预测性示意图Figure4. The link predictability of BA scale-free network and random graph
可以看到, 由于BA无标度网络中, 新的节点进入网络后会选择网络中已存在的大度节点产生链接. 网络具有固定的网络连边演化机制, 连边都是按照优先链接产生, 因此, 网络具有很好的可预测性. 在图4(c)中表现为





2
4.2.真实网络的链路可预测性分析
本节进一步考察可预测性指标在真实世界网络中的表现. 我们选取了各个不同领域的15个真实网络作为实验网络. 网络拓扑属性如表2所列,





| 网络 | V | E | r | $\langle k\rangle$ | $\langle l\rangle$ | C |
| C_elegans | 297 | 2148 | –0.163 | 14.47 | 2.46 | 0.308 |
| Windsurfers | 43 | 336 | –0.147 | 15.63 | 1.70 | 0.564 |
| Adolescent health | 2539 | 12969 | 0.251 | 10.22 | 4.52 | 0.142 |
| Jazz | 198 | 2742 | 0.020 | 27.69 | 2.21 | 0.520 |
| USAirport | 1574 | 28236 | –0.113 | 35.87 | 3.14 | 0.384 |
| Metabolic | 453 | 4596 | –0.226 | 20.29 | 2.64 | 0.124 |
| Yeast | 2375 | 11693 | 0.454 | 9.85 | 5.10 | 0.388 |
| US powergrid | 4941 | 6594 | 0.003 | 2.67 | 20.09 | 0.103 |
| Physicians | 241 | 1098 | –0.056 | 9.11 | 3.02 | 0.552 |
| Air Traffic Control | 1226 | 2615 | –0.015 | 4.27 | 6.10 | 0.063 |
| Contiguous USA | 49 | 107 | 0.233 | 4.37 | 4.26 | 0.406 |
| 1133 | 5451 | 0.078 | 9.62 | 3.65 | 0.166 | |
| King James Bible | 1773 | 9131 | –0.048 | 10.30 | 3.38 | 0.163 |
| Protein Stelzl | 1706 | 6207 | –0.191 | 7.28 | 5.09 | 0.006 |
| Router | 5022 | 6258 | –0.138 | 2.49 | 6.45 | 0.033 |
表2不同领域真实网络拓扑属性
Table2.Basic statistics of real networks.
在实验中, 我们采用随机抽样的方法, 将训练集和测试集按照9∶1的比例进行划分, 即测试集包含10%的真实连边. 针对预测结果采取precision衡量算法的表现, 由于真实网络规模不同, 在实验时固定预测连边的比例, 令L等于测试集中的连边数量.
表3为链路预测算法在真实网络中的最大精确度 (precision)测试结果, 每个链路预测算法在每个网络运行100次取平均. 从网络间纵向比较来看, 算法在可预测性高的网络上的预测精度要明显高于可预测低的网络, 如图5大图所示, 不同颜色的圆代表不同的网络, 圆的大小与网络可预测性

| 网络 | p | CN | AA | RA | LP | IA | CAR | PA | Katz | RWR | ACT | LRW | SRW |
| C_elegans | 0.999 | 0.100 | 0.107 | 0.105 | 0.101 | 0.108 | 0.094 | 0.058 | 0.101 | 0.105 | 0.055 | 0.110 | 0.108 |
| Windsurfers | 0.999 | 0.379 | 0.396 | 0.413 | 0.370 | 0.393 | 0.381 | 0.214 | 0.369 | 0.360 | 0.247 | 0.402 | 0.426 |
| Adolescent health | 0.422 | 0.103 | 0.103 | 0.088 | 0.089 | 0.101 | 0.094 | 0.003 | 0.088 | 0.053 | 0.008 | 0.042 | 0.047 |
| Jazz | 1.000 | 0.502 | 0.523 | 0.542 | 0.489 | 0.535 | 0.517 | 0.133 | 0.489 | 0.352 | 0.168 | 0.342 | 0.393 |
| USAirport | 0.998 | 0.333 | 0.336 | 0.364 | 0.332 | 0.332 | 0.330 | 0.280 | 0.332 | 0.087 | 0.294 | 0.076 | 0.080 |
| Metabolic | 0.999 | 0.137 | 0.195 | 0.269 | 0.141 | 0.168 | 0.132 | 0.104 | 0.141 | 0.196 | 0.092 | 0.214 | 0.215 |
| Yeast | 0.998 | 0.154 | 0.177 | 0.267 | 0.158 | 0.161 | 0.148 | 0.094 | 0.174 | 0.073 | 0.211 | 0.045 | 0.059 |
| US powergrid | 0.362 | 0.054 | 0.032 | 0.028 | 0.058 | 0.047 | 0.037 | 0.000 | 0.057 | 0.016 | 0.034 | 0.015 | 0.018 |
| Physicians | 0.368 | 0.119 | 0.126 | 0.121 | 0.117 | 0.122 | 0.106 | 0.014 | 0.117 | 0.119 | 0.015 | 0.132 | 0.127 |
| Air Traffic Control | 0.480 | 0.036 | 0.024 | 0.018 | 0.037 | 0.021 | 0.025 | 0.007 | 0.037 | 0.002 | 0.015 | 0.002 | 0.002 |
| Contiguous USA | 0.540 | 0.096 | 0.130 | 0.132 | 0.005 | 0.000 | 0.000 | 0.012 | 0.004 | 0.067 | 0.053 | 0.133 | 0.121 |
| 0.950 | 0.144 | 0.158 | 0.143 | 0.142 | 0.159 | 0.145 | 0.018 | 0.141 | 0.065 | 0.024 | 0.052 | 0.051 | |
| King James Bible | 0.960 | 0.167 | 0.270 | 0.446 | 0.163 | 0.256 | 0.176 | 0.078 | 0.163 | 0.186 | 0.069 | 0.197 | 0.224 |
| Protein Stelzl | 0.441 | 0.001 | 0.002 | 0.001 | 0.001 | 0.002 | 0.006 | 0.014 | 0.001 | 0.006 | 0.013 | 0.006 | 0.006 |
| Router | 0.511 | 0.051 | 0.029 | 0.020 | 0.056 | 0.031 | 0.055 | 0.022 | 0.055 | 0.006 | 0.164 | 0.005 | 0.005 |
表3链路预测算法在真实网络中的precision值
Table3.The precision of link prediction algorithms in real networks
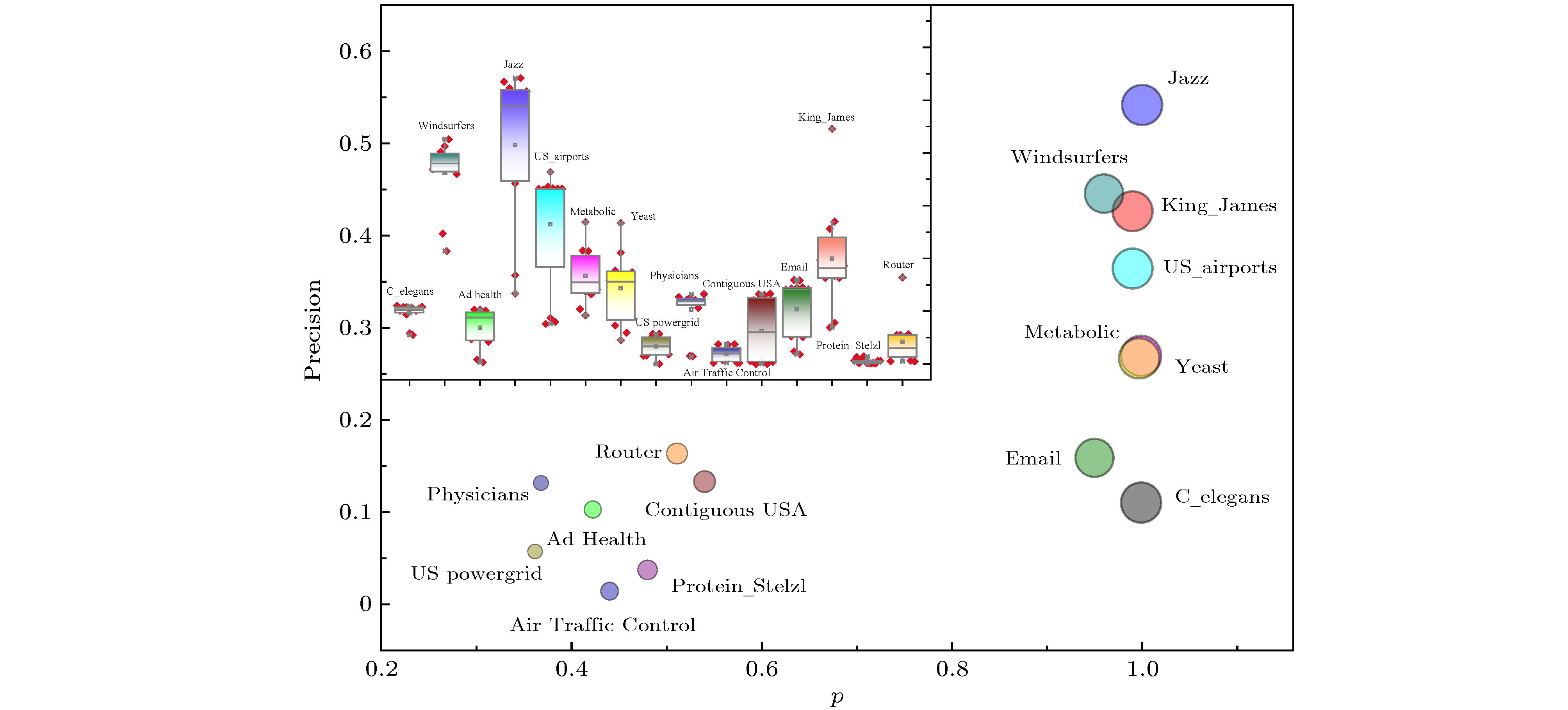 图 5 预测算法在真实网络上的表现
图 5 预测算法在真实网络上的表现Figure5. The performance of prediction algorithms in real networks
本文从统计物理中图的可扩张性得到启发, 提出了一种基于特征谱的链路可预测性度量指标. 通过对网络特征谱的分析, 构造了一个指标来评价网络缺失链路的“可被预测的程度”. 模型网络和大量真实网络中的实验结果证明, 该指标能够有效地刻画网络的链路可预测性, 且能够就链路预测算法选择提供建议. 例如, 随机网络的可预测性较差, 而无标度网络的可预测性较好. 然而, 虽然各类算法在无标度网络中的精确度明显优于随机网络, LHN-II算法却不是适用于该网络的合适的链路预测算法; 在实证网络中, Jazz网络具有较好的可预测性, 一些基于共同邻居的相似性指标如CN, AA, RA表现较好, 然而优先链接指标PA的精确度却很差. 这是因为网络中音乐家之间的合作关系不是以优先链接的形式展开的, 依靠节点度乘积来刻画相似性的PA算法不是适合Jazz网络的链路预测算法. 事实上, 我们认为网络的可被预测的程度差并不绝对, 可预测性差的网络也许只是没能遇到理解它结构特征的链路预测算法. 一个好的链路预测算法背后往往有一套贴近网络生长演化的连边机制, 同样道理, 一个重要的机制往往能够提取出一种精确的链路预测算法. 链路预测的研究与网络的结构和演化密切相关, 即算法与网络连边形成机制相辅相成, 是互通的, 网络的链路可预测性即是网络连边演化机制的另一种表现形式. 我们把基于特征谱视角计算可预测性, 获取网络能够被预测的难易程度的工作视作基础, 在下一步的研究中, 拟通过对具有典型演化机制的网络进行分析, 说明预测背后的主要机制以及预测正确或者错误的原因, 去探索一些因果关系. 同时, 考虑基于特征谱挖掘和学习不同网络的拓扑结构信息, 对网络拓扑结构进行标记分类, 针对不同类型网络的连边机制, 提出与之相匹配的链路预测算法.
