2.
3.
Geographical association between dietary tastes and chronic diseases in China:An exploratory study using crowdsourcing data mining techniques
LI Hanqi1, JIA Peng2,3, FEI Teng11. 2.
3.
收稿日期:2018-11-26修回日期:2019-06-4网络出版日期:2019-08-25
Received:2018-11-26Revised:2019-06-4Online:2019-08-25
作者简介 About authors
李瀚祺(1994-),女,硕士生,研究方向为健康地理学、空间数据分析E-mail:

摘要
关键词:
Abstract
Keywords:
PDF (4086KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
李瀚祺, 贾鹏, 费腾. 基于众源数据挖掘的中国饮食口味与慢性病的空间关联. 地理学报[J], 2019, 74(8): 1637-1649 doi:10.11821/dlxb201908011
LI Hanqi.
1 引言
慢性病,也称为非传染性疾病,每年导致4100万人死亡,相当于全球死亡人数的71%[1,2]。2016年,中国居民慢性病死亡率为739/10万,死亡人数占总死亡的89%,远高于传染病、交通事故等引发的死亡率[3]。慢性病对社会、经济和公共卫生造成了破坏性影响[4,5]。世界卫生组织(WHO)已明确指出慢性病的4项可改变的行为风险因素,包括不健康饮食、吸烟、饮酒和缺乏运动[1]。其中,不健康饮食居于所有风险因素的首位,2017年,全球疾病负担(GDB)研究结果显示,全世界归因于不健康饮食的死亡人数达到1090万[6]。饮食因素是影响慢性病发生发展的最普遍因素[7,8],因此,全面地估计和比较关于饮食因素的疾病负担,将有助于制定具体有效的疾病防控策略[9,10]。对此,已有大量研究分析了中国不同地区居民的饮食行为,包括就餐时间与频率、荤素搭配、乳制品、盐、油摄入量、粗细粮占比等[11,12,13,14];但在众多饮食行为的研究中,与饮食口味相关的研究较少,而且口味信息大多基于被试者的主观定性评价[14,15],缺乏对地区口味偏好与慢性病关系的定量研究。中国幅员辽阔,人口众多,风俗各异,不同地区的物产、气候、历史文化、宗教等因素造就了每个地区特有的饮食文化,进而演变成口味各异的中国菜系文化[16,17];尽管随着交通水平发展和社会变革带来的人口流动加剧,不同地区的饮食文化相互融合,地区之间口味差异逐渐减小,但在大尺度,如省级行政单位的空间尺度上,不同地区仍然存在明显的口味特色[18,19,20],因此在中国非常适合开展与地区口味差异相关的研究。
众源数据具有来源广,数据量大,真实全面等诸多优点[21,22],已广泛应用于公共卫生和医疗领域的众多方面,例如疾病预测、循证公共卫生决策、健康管理与监测、个性化医疗[23]。利用众源数据挖掘地区居民整体口味偏好,即可有效避免个体调查结果缺乏客观性的不足,可以更加全面合理地代表一个地区的整体口味情况。
本文利用众源网络菜谱与地区餐饮商铺数据,从调味料使用频率角度,在省级行政区尺度上,对群体口味偏好进行量化和分析;以出血性卒中、胰腺癌和上呼吸道感染作为3种慢性病研究示例,建立慢性病与饮食口味的联系,使用地理探测器[24]方法分析二者之间的空间关联,试图探究饮食口味偏好对慢性疾病发生的影响,以期为有关疾病的致病机制研究,以及公共卫生领域制定对慢性病饮食风险因素的干预措施提供基础资料。
2 数据来源
2.1 网络菜谱
饮食口味数据从美食杰网站(http://www.meishij.net/)获取,该网站根据菜系发源地,将“中华菜系”分为川菜、东北菜、粤菜等共20个子类。本文使用每道菜菜谱中的辅料与调料信息(例如,川菜“麻辣水煮鱼”使用的辅料与调料有盐、糖、干红辣椒、花椒、葱、蒜等),作为提取饮食口味的主要数据来源。2.2 地区餐饮类商铺数据
2017年餐饮类商铺兴趣地点(Place of Interest, POI)数据集来源于对高德地图的爬取,该数据集采集于2017年8月,收录了中国34个省级行政单位约700万条餐饮类商铺的POI数据,每条数据包含餐饮商铺名称、详细位置坐标、经营类别等信息。本文提取其中经营类别信息标注有明确菜系(如“川菜”)的餐饮POI,作为研究区内可用于提取口味信息的餐饮类商铺的类别分布数据。2.3 慢性病死因数据
常规检测中的死因监测数据是慢性疾病数据来源之一[25]。本文使用的疾病死因监测数据来源于中国疾病预防控制中心(http://ncncd.chinacdc.cn/)发布的2013年“中国居民主要疾病死亡原因地图集(数据库)”[26]。该数据库提供的死因别死亡率,单位为1/10万,指某地每10万人中因某种疾病死亡的人数,它反映了各类病伤死亡对居民生命的危害程度[27]。本文根据已有研究资料,按照疾病与口味的相关程度,使用其中的出血性卒中、胰腺癌和上呼吸道感染死因数据,作为慢性病的3个研究对象。数据覆盖中国的33个省级行政单元(暂无台湾省数据),分布如图1所示。图1
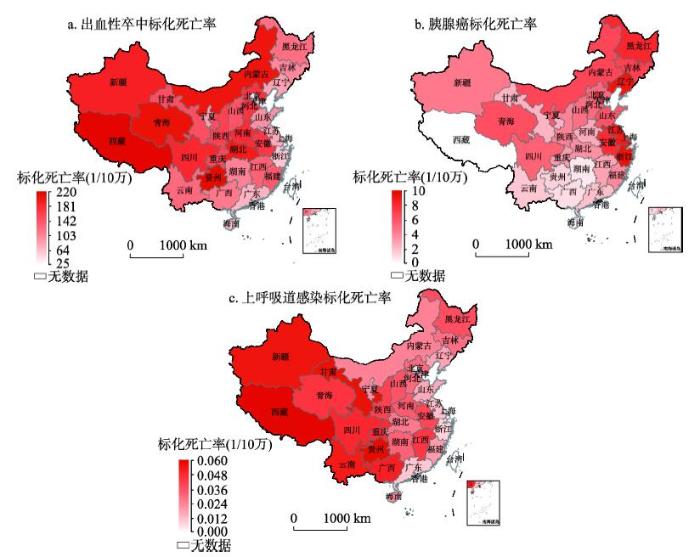 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1出血性卒中、胰腺癌和上呼吸道感染中国分省标化死亡率分布图
注:该图基于国家测绘地理信息局标准地图服务网站下载的审图号为GS(2016)1569号的标准地图制作,底图无修改。
Fig. 1Standardized mortality distribution maps of hemorrhagic stroke (a), pancreatic cancer (b) and upper respiratory infections (c) by province
3 研究方法
数据处理与研究流程如图2所示。首先,从众源菜谱数据中分析得到不同菜系7个维度上的口味特征量化值;利用餐饮POI数据,计算每个省级单元内各类菜系占比;然后,将菜系口味与各个省级单元菜系占比结合,得到每个省级单元的7维口味特征;最后,采用地理探测器方法探测口味与3种慢性病死亡归因数据之间的关联(图2)。图2
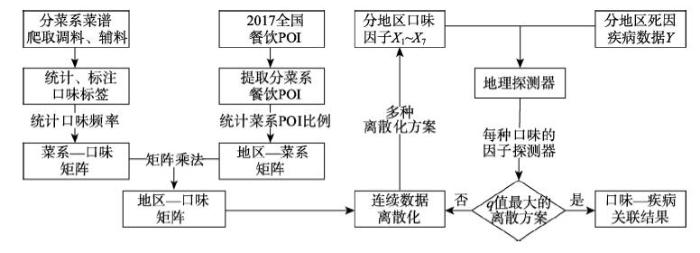 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2数据处理与研究流程
Fig. 2Data processing and research flow
3.1 菜系口味提取
利用网络爬虫,获取美食杰网站上20类菜系中每一道菜的菜谱信息。由于菜谱对食材用料的使用量没有统一的度量标准,本文从食材使用频度的角度入手,对口味进行量化。① 汇总所有菜谱中的“辅料”和“调料”,合并同物异名的用料,并以此确定本研究中使用到的口味种类。通过查阅有关食材用料口味的资料[28,29],选择7种大众常见的口味描述方式,分别是“酸”“甜”“鲜”“咸”“油”“辣”“辛”[30](这里的口味“辣”指来自辣椒种类调味料的“辣”味,口味“辛”指除去辣椒来源以外的各种辛辣刺激口味,例如芥末、蒜的口味),建立“用料—口味”对照表。② 对每种用料标记口味标签,进而得到每道菜品被标记的口味。每种用料可以被标记0至多种口味,例如,“海鲜酱油”被标记为“咸”和“鲜”;如果一道菜品中使用了多种包含某口味的调味料,则这道菜会被多次标记这种口味;统计每一道菜被标记的各种口味的次数,得到每道菜品的7种口味的使用频度。③ 按照菜系类别汇总菜品,得到每种菜系7种口味的使用频度,根据菜系的菜品数量,进而计算菜系口味频率,作为某种菜系某一口味的量化指数,由此得到20种菜系的7种口味的定量描述。3.2 计算各地口味特征
餐饮POI数据划分餐馆类别使用的16类菜系全部落在菜谱数据的20类菜系范围内,本文将使用两类数据共有的16类菜系所对应的POI提取区域口味。16类菜系对应的有效POI共有387509个,广东省的有效POI数量最多,共63420个,澳门最少,共71个。分别统计33个省级单元内16类菜系的餐饮POI数量占总有效餐饮POI的比例,并根据每种菜系口味特征计算出每个省级单元的7维口味特征量化值。以四川省的口味“辣”为例,计算川菜类餐饮POI占省内所有有效POI的比例,以此为权值,乘以川菜的辣口味指数,作为川菜对四川省口味辣的贡献值,以此类推,累计16种菜系对四川省口味辣的贡献值,得到四川省口味辣度的量化值。3.3 口味数据预处理
口味数值是通过计算调味料的使用频率之和得到的连续型数据,需对其进行离散化处理。本文借鉴曹峰等[31]的离散化方法,由平均间隔法(EI)、几何区间法(GI)、自然分级法(NB)、分位数法(QU)和标准偏差法(SD)5种连续数据离散化算法,与2至8个离散等级数这7种等级化方式,依次组合构成35种离散化方案。每种口味逐一尝试35种离散化方案,进行口味数据等级划分,并且保证每种方法每个等级内的省级单元数量不少于2个,使预处理后的数据满足使用地理探测器的前提条件[32]。对某种口味因子按照上述某一方案进行离散化,相当于对33个省级单元按照该口味使用频率等级进行分层聚类,将整个研究区划分为不同口味等级的子区域。
3.4 地理探测器
地理探测器是由王劲峰于2010年提出的衡量地理事物空间分异性,以及揭示其背后驱动力的一组统计学方法[32]。该方法首次应用于地方性疾病NTD形成原因的探测[24],近年来被广泛运用到景观科学、社会科学、土地利用、环境科学和人类健康等方面[33]。本文引入地理探测器方法发掘不同地区饮食口味偏好与当地人群慢性病风险的关联。地理探测器包含风险探测器、因子探测器、生态探测器和交互作用探测器[33],分别从4个不同的角度定量表达某疾病的空间异质性,以及不同的口味因子对于某种疾病空间分异性的影响能力。风险探测器用于判断两个子区域的疾病均值是否有显著的差别;因子探测器用于探测某口味因子对疾病的空间分异现象的解释程度,用q值表示:
式中:
生态探测器用于比较每两种口味因子对疾病空间分布格局的影响是否有显著的差异;交互作用探测器用于评估多个口味因子共同作用时是否会增加或减弱单一口味因子对疾病空间分异现象的解释力。q值的范围是[0, 1],值越大说明某疾病的空间分异性越明显;如果这种疾病的空间分异性在一定程度上是由于不同地域对某种口味使用程度的差异导致的,则q值越大表示该种口味因子对这种疾病空间分异现象的解释力越强,反之则越弱。q值为1则表示口味因子对疾病空间分异结果的解释能力达到100%。
本文共33个省级单元,即N =33。将33个省级单元的疾病数据作为地理探测器响应变量,将符合要求的每一种口味离散化结果作为自变量,依次对3种疾病与7种口味进行地理探测器检验。对于某一种疾病而言,当某个口味因子采用某种离散方案后,使得因子探测器获得的
4 结果分析
4.1 菜系口味计量
本文爬取获得20种菜系的菜谱数量如表1所示。汇总菜品的调味料数据并标记口味标签后,统计得到每种菜系7种口味使用程度数据,其数值表示某菜系平均每道菜使用某种口味调味料的数量。比较各个口味在20类菜系中的使用程度,可以看出“辛”味使用频度最高,其次是“咸”,使用频率较低的是“辣”和“酸”味调味料;比较20类菜系对7种口味的使用情况,发现港台菜重“甜”、川菜重“辣”、湖北菜重“辛”,以上结果基本符合人们的普遍认知。Tab. 1
表1
表1菜谱数量与口味频率
Tab. 1
| 序号 | 使用情况 | 菜系 | 菜谱数量 | 酸 | 甜 | 鲜 | 咸 | 油 | 辣 | 辛 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 菜谱与POI数据共有的16类菜系 | 川菜 | 1008 | 0.27 | 0.54 | 0.51 | 1.75 | 0.72 | 0.95 | 2.23 |
| 2 | 东北菜 | 896 | 0.25 | 0.43 | 0.64 | 1.61 | 0.68 | 0.26 | 1.34 | |
| 3 | 港台菜 | 67 | 0.15 | 0.78 | 0.6 | 1.66 | 0.84 | 0.34 | 1.79 | |
| 4 | 湖北菜 | 233 | 0.22 | 0.48 | 0.85 | 1.59 | 0.89 | 0.26 | 2.35 | |
| 5 | 沪菜 | 328 | 0.19 | 0.64 | 0.91 | 1.43 | 0.97 | 0.06 | 1.38 | |
| 6 | 徽菜 | 327 | 0.17 | 0.6 | 0.69 | 1.18 | 0.77 | 0.13 | 1.16 | |
| 7 | 京菜 | 360 | 0.21 | 0.58 | 0.57 | 1.26 | 0.68 | 0.11 | 1.26 | |
| 8 | 鲁菜 | 757 | 0.18 | 0.36 | 0.57 | 1.24 | 0.68 | 0.16 | 1.14 | |
| 9 | 闽菜 | 661 | 0.17 | 0.47 | 0.83 | 1.13 | 0.74 | 0.10 | 1.14 | |
| 10 | 清真菜 | 141 | 0.28 | 0.61 | 0.94 | 1.68 | 0.92 | 0.38 | 2.01 | |
| 11 | 苏菜 | 449 | 0.15 | 0.51 | 0.58 | 1.26 | 0.69 | 0.09 | 1.17 | |
| 12 | 西北菜 | 339 | 0.21 | 0.46 | 0.92 | 1.58 | 0.91 | 0.34 | 2.01 | |
| 13 | 湘菜 | 720 | 0.15 | 0.32 | 0.67 | 1.63 | 0.82 | 0.63 | 1.32 | |
| 14 | 粤菜 | 1007 | 0.13 | 0.48 | 0.45 | 1.28 | 0.54 | 0.12 | 1.01 | |
| 15 | 云贵菜 | 187 | 0.25 | 0.52 | 0.74 | 1.68 | 0.92 | 0.66 | 1.90 | |
| 16 | 浙菜 | 570 | 0.16 | 0.47 | 0.7 | 1.26 | 0.74 | 0.09 | 1.09 | |
| 17 | 仅菜谱数据包含的4类菜系 | 广西菜 | 98 | 0.35 | 0.53 | 1.01 | 1.91 | 0.69 | 0.39 | 1.84 |
| 18 | 江西菜 | 87 | 0.16 | 0.25 | 0.77 | 1.24 | 0.76 | 0.59 | 1.48 | |
| 19 | 山西菜 | 175 | 0.27 | 0.43 | 0.75 | 1.43 | 1.03 | 0.19 | 2.22 | |
| 20 | 豫菜 | 167 | 0.21 | 0.53 | 1.01 | 1.43 | 0.91 | 0.17 | 1.61 |
新窗口打开|下载CSV
4.2 各个研究单元口味特征
数据统计后,得到33个省级行政单元的16类菜系的餐饮POI数据共387509条,分布情况如图3所示。从图3中可以明显地看出,在大部分省级行政单元,川菜和清真菜的POI均占较高比重;此外,每种菜系分别在各自的发源地区占比也较其他地区更高,例如徽菜在安徽省最多,浙菜在浙江省最多。图3
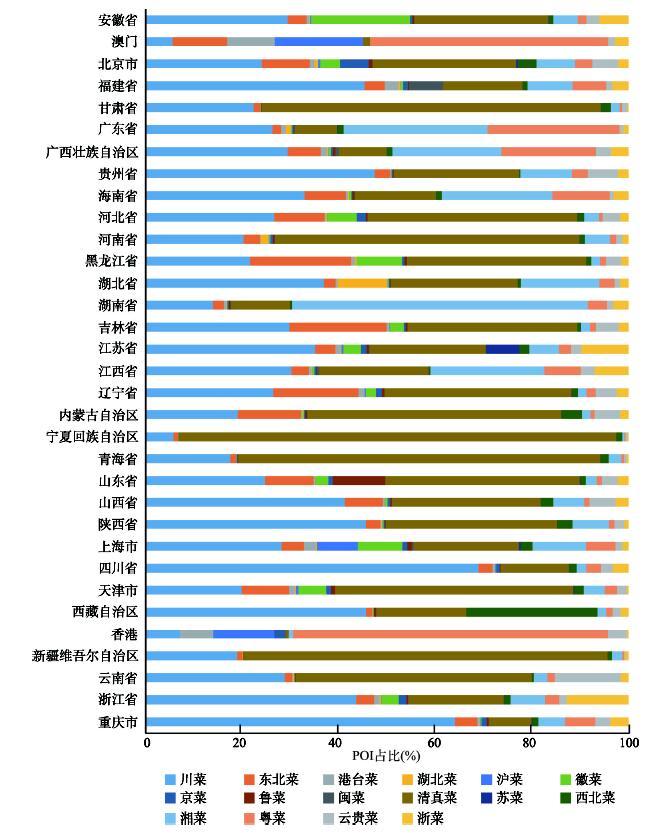 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3中国省级单元各类餐饮POI占比
Fig. 3Proportion of POI by category in provincial units in China
将各个省级研究单元内各类菜系占比与各类菜系的7种口味特征值结合后,得到7种口味在省级单元的的使用情况。为方便在整个研究区上对不同口味的使用程度进行比较,本文将每个省级单元的口味使用频率值进行z-score标准化,得到以研究区均值为衡量标准的各个口味的量化指标,用色阶图表示如图4所示。澳门和香港地区除了“甜”,其他口味使用程度均较弱;甘肃省、宁夏回族自治区、青海省整体口味偏重;在所有省级单元中,四川省食辣最多,宁夏回族自治区使用“鲜”味调味料最多。
图4
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4中国省级单元7种口味频率值标准化
注:该图基于国家测绘地理信息局标准地图服务网站下载的审图号为GS(2016)1569号的标准地图制作,底图无修改。
Fig. 4Standardization of frequency values of 7 tastes in provincial units
4.3 口味离散化结果
本文对出血性卒中、胰腺癌和上呼吸道感染3种疾病分别与7种口味的结合进行口味数据离散,最优离散化方案如表2所示。Tab. 2
表2
表2口味数据最优离散化方案
Tab. 2
| 疾病 | 离散方案 | 酸 | 甜 | 鲜 | 咸 | 油 | 辣 | 辛 |
|---|---|---|---|---|---|---|---|---|
| 出血性卒中 | 方法 | QU | QU | QU | NB | QU | QU | QU |
| 级数 | 7 | 7 | 8 | 6 | 8 | 7 | 7 | |
| 胰腺癌 | 方法 | NB | QU | QU | QU | QU | QU | NB |
| 级数 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | |
| 上呼吸道感染 | 方法 | NB | QU | QU | QU | SD | QU | NB |
| 级数 | 7 | 7 | 8 | 7 | 7 | 7 | 7 |
新窗口打开|下载CSV
4.4 地理探测器结果
因子探测器得到的3种疾病7种口味因子的q值结果如表3的3个下三角矩阵的对角线上的数值所示。对于每种疾病,单一口味因子对疾病空间分异的解释能力,由高到低依次表现为:① 出血性卒中:辣(52.3%)>辛(51.4%)>咸(49.9%)>甜(45.1%)>酸(36.6%)>油(36.3%)>鲜(16.2%)② 胰腺癌:甜(62.8%)>辣(44.6%)>咸(42.6%)>辛(42.5%)>油(29.8%)>酸(26.4%)>鲜(12.2%)③ 上呼吸道感染:辛(56.0%)>咸(53.5%)>辣(50.5%)>酸(44.1%)>油(44.0%)>甜(43.4%)>鲜(16.3%)Tab. 3
表3
表3因子与交互作用探测结果
Tab. 3
| 疾病 | 口味风险因子 | 酸 | 甜 | 鲜 | 咸 | 油 | 辣 | 辛 |
|---|---|---|---|---|---|---|---|---|
| 出血性卒中 | 酸 | 0.366 | ||||||
| 甜 | 0.792 | 0.451* | ||||||
| 鲜 | 0.857↑ | 0.855↑ | 0.162 | |||||
| 咸 | 0.748 | 0.737 | 0.921↑ | 0.499** | ||||
| 油 | 0.878↑ | 0.851↑ | 0.646↑ | 0.926↑ | 0.363 | |||
| 辣 | 0.805 | 0.794 | 0.969↑ | 0.780 | 0.868 | 0.523* | ||
| 辛 | 0.835 | 0.881 | 0.922↑ | 0.820 | 0.905 | 0.859 | 0.514* | |
| 胰腺癌 | 酸 | 0.264 | ||||||
| 甜 | 0.859 | 0.628** | ||||||
| 鲜 | 0.766↑ | 0.944↑ | 0.122 | |||||
| 咸 | 0.860↑ | 0.817 | 0.808↑ | 0.426 | ||||
| 油 | 0.759↑ | 0.816 | 0.654↑ | 0.705 | 0.298 | |||
| 辣 | 0.763↑ | 0.952 | 0.848↑ | 0.886 | 0.856↑ | 0.446 | ||
| 辛 | 0.529 | 0.962 | 0.798↑ | 0.850 | 0.852↑ | 0.838 | 0.425 | |
| 上呼吸道 感染 | 酸 | 0.441 | ||||||
| 甜 | 0.800 | 0.434 | ||||||
| 鲜 | 0.854↑ | 0.816↑ | 0.163 | |||||
| 咸 | 0.848 | 0.818 | 0.971↑ | 0.535* | ||||
| 油 | 0.545 | 0.786 | 0.702↑ | 0.891 | 0.440 | |||
| 辣 | 0.887 | 0.862 | 0.966↑ | 0.955 | 0.919 | 0.505* | ||
| 辛 | 0.757 | 0.819 | 0.922↑ | 0.806 | 0.724 | 0.906 | 0.560** |
新窗口打开|下载CSV
以显著性检验的p ≤ 0.01为条件,筛选得到3种疾病中q值显著的口味因子,认为这种口味因子与疾病之间在统计上存的显著关联,以此作为这种疾病的首要口味风险因子。结果分别是,出血性卒中、胰腺癌和上呼吸道感染的首要口味风险因子分别是“咸”“甜”和“辛”。
风险探测器的结果如图5所示,横坐标代表采用最优离散方案时划分的口味等级,等级数值越高,表示该口味使用程度越高;纵坐标表示某口味等级对应省级单元的疾病数据平均值。图5呈现了3种疾病各自首要风险因子影响趋势。对于出血性卒中(图5a),疾病数据随着口味“咸”程度的增加整体上表现为上升趋势;对于胰腺癌(图5b),当口味“甜”按照分位数法划分为第3等级时,疾病数据达到峰值,随着“甜”度等级的继续上升,疾病数值波动式下降,但始终高于1、2等级“甜”度对应的疾病数据;对于上呼吸道感染(图5c),当口味“辛”达到自然分级法的第3、4等级时,疾病数据值有所下降,之后又恢复上升,最终的最高值出现在第7等级。此外,对于这3种疾病的首要口味风险因子,都是在口味等级最低时对应的疾病数值最小。
图5
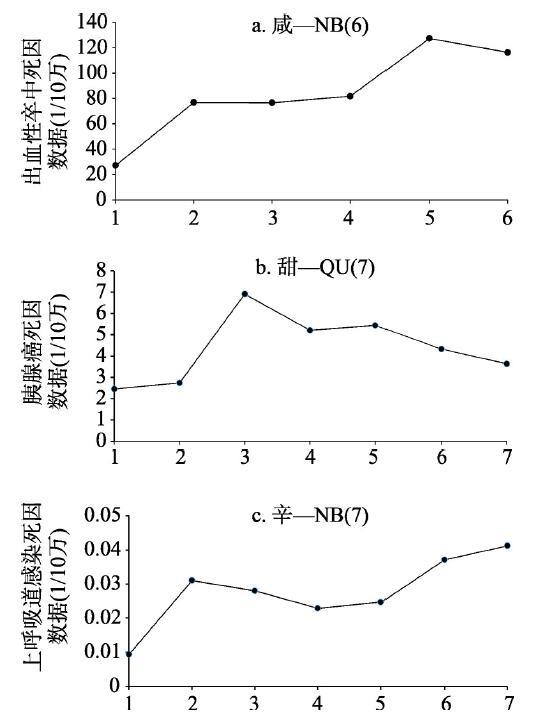 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图53种疾病首要风险因子的风险探测器的结果
注:NB(6):自然分级法,分6等级;QU(7):分位数法,分7等级。
Fig. 5Results of risk detector for the first risk factors of three diseases (NB (6): natural breaks method, 6 strata, QU (7): quantile method, 7 strata)
交互探测器的结果(表3)表明,对于3种疾病,口味“鲜”与其他6种口味的组合均产生
5 结论与讨论
5.1 结论
基于现有文献资料,本文选择出血性卒中、胰腺癌和上呼吸道感染为疾病研究对象,原因是这3种疾病与某种饮食口味之间的关系分别得到专家认证[34,35]、潜在相关[36,37,38,39,40,41]以及研究证据不足。因此,首先选择出血性卒中为本研究探索方法的测试疾病对象,验证研究方法的可行性,然后进行另外两种慢性病的饮食口味疾病的探索,结论如下:(1)出血性卒中结果为,在7种口味中,“咸”是出血性卒中的首要口味风险因子,并且出血性卒中的死亡风险随着饮食口味“咸”度的提升有所增加,该结果与现有研究结果一致[34,35],符合先验知识,说明从地理空间分异性角度探测口味与疾病之间关系的研究方法具有实际参考价值,可以推广应用到其他疾病的分析。
(2)胰腺癌实验结果显示,在7种口味中,“甜”对该疾病空间分布的解释能力最强,并且通过显著检验。已有****研究饮食因素与其之间的联系,口味“甜”得到的结论大都为食用含糖量高的“甜”味食物导致胰岛素大量分泌,使胰岛功能受损,进而增加糖尿病风险,而糖尿病与胰腺癌之间的联系密切[36],间接得到口味“甜”与胰腺癌风险呈正相关的结论[37,38,39,40]。而本文单纯建立口味“甜”与胰腺癌死因空间分布的联系,也得到在99%置信度下二者具有显著统计关联性的结果,为上述实验结论提供数据资料支持。
(3)上呼吸道感染的实验结果表明,在7种口味中,“辛”对该疾病空间分布的解释能力最强,并且通过显著检验。整体上,该疾病的风险随着口味“辛”程度的加重而上升,但在中间局部也有下降。有研究表明,有些“辛”味调味料,例如大蒜、洋葱等,具有抗菌功效,适当食用“辛”味调料可以减少食源性疾病和食物中毒[41],但具体机制尚不清楚,是否存在新关系有待进一步做病理学研究得出。
此外,口味之间的交互也可以增加本文3种目标疾病的患病风险,特别是口味“鲜”,和其他6种口味的交互作用均使得对目标疾病的致病风险非线性增强,类似催化剂的效果,但有趣的是,作为单一口味因子,口味“鲜”对3种疾病的解释能力都相对最弱。这其中的机理,还需要进一步研究。
迄今为止,已有许多细胞生物学关于味觉机制的研究,证明味觉在人类进化中有着重要作用,比如负责评价食物的营养含量、口味偏好与营养缺乏存在一定的联系、不同的口味承担着识别不同化学物质的角色,以帮助识别和区分关键的饮食成分,防止摄入有毒物质[42,43],以及当机体发生疾病或不适时会干扰味觉的功能,从而影响机体对食物的摄取[44]。增加对味觉生物学和遗传学的理解可能会预防或影响慢性病风险的发展轨迹[45]。上述研究成果均由对个体的实验性研究得出,尽管具有较为严谨的科学依据,然而研究成本较高,研究方法移植性较差。本研究的特色之处在于从疾病的空间分布格局着手,在空间大尺度上,利用众源数据进行公共卫生领域的研究,得出的结果具有更强的普适性和探索意义,因此可以作为验证实验之前的关联性探索。
相比于简单的双变量相关性分析,地理探测器的优势在于探测出口味与疾病之间不限于直线性的相关关系,而且通过将口味数据离散化,能够将非直线型的相关关系通过聚类的方式更加直观的呈现出来。如果这种统计上的相关关系在医学实验上能够进一步得到因果关联的证实,对于公共卫生领域制定干预措施,离散后的口味等级值也更具有实践意义。
5.2 讨论
本文作为利用众源数据定量挖掘疾病风险因子的一次探索性尝试,取得了统计意义上表现显著的结果,但对于结果的不确定性与适用性,仍然需要进一步讨论与思考。一方面,本文受到数据源的制约,使用2017年的餐饮POI得到的口味数据尝试解释2013年的疾病死因数据,考虑到饮食口味对慢性病的影响具有迟滞性,故实验在数据的时间设计上未能做到逻辑最优,只能服从数据可获取性优先。但由于一个地区的饮食习惯是经过长期实践后累积下来的结果,饮食口味并不会在较短的时间内发生大幅度变化。因此本文使用了一年餐饮POI数据作为地区餐饮类别情况的一个缩影,来反映当地的口味特征,是存在科学意义的。但如果有更长时间阶段的地区餐饮数据和在此之后收集到的慢性病数据,利用空间生命历程流行病学研究方法进行分析,则可以最大化消除上述时间效应的影响,得出更加科学的结论[46]。另一方面,从饮食文化地理学[17]角度来看,不同地区的饮食文化相互融合,饮食口味差异并不具有明显的地理区域划分,选用不同的空间尺度对该问题的敏感性也是不同的,受到可变面域单元问题(MAUP)的影响。因此需要强调,本研究受疾病数据源所限,实验是在省域空间尺度之上展开的,所得结论是针对全国尺度的(暂不包括台湾省),并不一定适用于其他空间尺度,因而结论具有空间尺度效应问题。另外,本实验结论仅适用于中国地区,对不同国家或地区,实验需要因地制宜。如果能够获取到空间分辨率更高的慢性病数据,便可将本实验思路拓展到不同尺度的研究上,以探索得出更具区域针对性的慢性病风险因子,由此制定的公卫政策才能做到有的放矢。
致谢:感谢中国科学院地理科学与资源研究所王劲峰研究员、中国疾病预防控制中心环境所常君瑞研究员在成文过程中提出的建议;感谢中国科学院地理科学与资源研究所徐成东副研究员、澳大利亚科廷大学宋勇泽博士对地理探测器R包的维护;感谢武汉大学资源与环境科学学院硕士研究生邱伟楷在实验数据处理部分做出的贡献,感谢Stephan Angsuesser老师对文中英语部分的修改与润色。
参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
URL [本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
URL [本文引用: 1]
URL [本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}