 , 冯敏
, 冯敏Data fusion and accuracy evaluation of multi-source global land cover datasets
BAIYan, FENGMin收稿日期:2018-01-24
修回日期:2018-08-22
网络出版日期:2018-11-25
版权声明:2018《地理学报》编辑部本文是开放获取期刊文献,在以下情况下可以自由使用:学术研究、学术交流、科研教学等,但不允许用于商业目的.
基金资助:
作者简介:
-->
展开
摘要
关键词:
Abstract
Keywords:
-->0
PDF (2326KB)元数据多维度评价相关文章收藏文章
本文引用格式导出EndNoteRisBibtex收藏本文-->
1 引言
土地覆被空间分布及其变化反映了人类社会经济活动过程,被视为全球陆地生态系统变化最为重要的影响因素之一[1]。大尺度土地覆被分类制图工作尤为重要,它为全球陆地表层过程与生态系统碳水循环模拟[2,3,4,5]、气候变化[6]、土壤侵蚀[7]、生物多样性[8]、人地关系及区域可持续发展[9]等研究提供了基础的输入数据源。国际社会十分重视全球地表覆被及其变化研究,自20世纪90年代起,世界各国许多组织(如美国地质调查局、欧空局、中国国家测绘地理信息局等)相继运用不同的遥感影像和分类技术,开展了以土地覆被为主体的遥感制图研究,形成了一系列不同时空分辨率的全球土地覆被数据集[10,11,12,13,14,15,16,17,18,19],并在全球或区域尺度的科学研究和应用中发挥了重要作用。然而,由于数据生产者采用了不同的输入数据源、分类系统和制图技术,目前已经建立的全球土地覆被数据集彼此之间存在明显的差异,包括类型数量及其空间分布在相同区域尺度上的不一致性[20,21,22,23],从而导致用户在具体应用中使用这些数据时存在很多不确定性,主要体现在:① 全球土地覆被数据集的第三方精度评价并不高;② 数据生产者各自使用了不同的验证框架和参考数据,使得这些独立完成的土地覆被数据集精度评价结果之间没有可比性。因此,在具体应用中,用户面临如何选择以及为什么选择某种土地覆被数据的不确定性挑战。此外,单一的土地覆被数据集不能满足研究应用需求的问题日益凸显出来。在多源数据共存和集成研究的背景下,采用信息融合技术进行土地覆被分类制图是全球变化研究的主要发展趋势之一。数据融合是一个多层次、多方面的数据处理过程,可用来处理不同数据之间分类系统的不兼容,并在一定程度上提高数据的精度[24]。许多国际组织,如全球森林和土地覆被动态变化监测站(Global Observation of Forest and Land Cover Dynamics, GOFC-GOLD)、国际粮农组织(Food and Agricultural Organizations, FAO)以及全球陆地观测系统(Global Terrestrial Observing Systems, GTOS)等共同合作,致力于融合两种或两种以上全球土地覆被数据集信息,以期生产精度更高的土地覆被数据产品的研究[25],并于2014年共同发布了一套全球土地覆被数据库GLC-SHARE(Global Land Cover SHARE),主要是以欧洲空间局的GlobCover-2009为主要信息,采用数据融合技术将质量较高的全球不同国家级尺度土地覆被数据以图注的形式实现了全球范围内的可视化展示[16]。
在已有的对5套全球宏观尺度土地覆被数据集GLCC、UMD、GLC2000、MODIS LC和GlobCover的类型、空间一致性及其精度进行系统的对比评价,在了解它们各自的优缺点的基础上[22, 26],本文从相关性分值的定义和融合规则出发,结合利用土地覆被辅助数据集,提出并设计一种基于模糊逻辑思想的证据融合方法实现多源土地覆被信息的综合,产出一套精度较高的全球土地覆被融合数据产品,并对其与5套源土地覆被数据集的一致性精度进行对比评价与分析。本研究不仅能够有效解决现存的土地覆被数据集之间不兼容及其数据精度有限的问题,同时能为在多种数据并存的背景下,利用多源数据决策融合技术进行大尺度土地覆被制图研究提供技术支持与科学指导。
2 数据源及其预处理
2.1 多源土地覆被信息
本文用到的多源土地覆被相关数据集包括以下8个,其基本特征如表1所示:Tab. 1
表1
表1多源土地覆被数据集的基本特征
Tab. 1Characteristics of multi-source land cover datasets
| 数据集 | 传感器 | 数据时间 | 空间分辨率 | 分类方法 |
|---|---|---|---|---|
| GLCC | AVHRR | 1992.4-1993.3 | 1 km | 非监督分类,分类后处理 |
| UMD | AVHRR | 1992.4-1993.3 | 1 km | 监督分类决策树 |
| GLC2000 | SPOT-4 | 1999.11-2000.12 | 1 km | 非监督分类 |
| MODIS LC | MODIS | 2001.1-2002.12 | 500 m | 决策树,人工神经网络 |
| GlobCover | MERIS | 2004.12-2006.7 | 300 m | 非监督分类 |
| MODIS VCF | MODIS | 2000 | 250 m | 回归树 |
| MODIS Cropland Probability | MODIS | 2000 | 250 m | 决策树 |
| AVHRR CFTC | AVHRR | 1992.4-1993.3 | 1 km | 线性混合 |
新窗口打开
(1)美国地质调查局(United States Geological Survey, USGS)建立的国际地圈生物圈计划(International Geosphere-Biosphere Programme, IGBP)分类(17类)的全球土地覆被数据(Global Land Cover Characterization, GLCC)[10];
(2)美国马里兰大学建立的简化IGBP分类(14类)的全球土地覆被数据UMD[12];
(3)欧洲联合研究中心建立的FAO LCCS(Land Cover Classification System)分类(23类)的全球土地覆被数据GLC2000(Global Land Cover 2000 project data)[13];
(4)波士顿大学建立的IGBP分类(17类)的全球土地覆被数据MODIS LC(Moderate Resolution Imaging Spectro-radiometer annual land cover product, Collection 5)[11];
(5)欧洲空间局建立的联合国LCCS分类(22类)的全球土地覆被GlobCover(Global Land Cover Map)[27];
(6)美国马里兰大学建立的全球植被连续覆盖数据MODIS VCF(Vegetation Continuous Field)[28];
(7)美国南达科他州立大学建立的全球农田分布概率数据MODIS Cropland Probability[29];
(8)美国马里兰大学建立的全球森林连续覆盖数据AVHRR CFTC(Advanced Very High Resolution Radiometer-Continuous Fields of Tree Cover)[30],包括森林覆盖类型的叶型(阔叶/针叶)和叶物候(常绿/落叶)的覆盖率信息。
2.2 数据预处理
为了便于后续多源信息融合工作的开展,首先需要将上述8个具有不同空间坐标参考和空间分辨率的土地覆被相关数据源进行相应的预处理,主要包括:① 数据统一转换为正弦曲线Sinusoidal投影,其空间范围为(180°W~180°E、55°S~90°N),即不包含主要分布着海洋和南极洲的55°S以南区域;② 利用最邻近算法将数据统一转换为1 km空间分辨率。同时,为了便于从AVHRR CFTC数据中获取森林类型的叶型及叶物候属性信息,本文将该数据中的叶型和叶物候覆盖率数据层分别进行合并处理,即将阔叶与针叶覆盖率数据层、常绿与落叶覆盖率数据层分别合并成对应的叶型、叶物候数据,合并规则如表2所示。
Tab. 2
表2
表2AVHRR CFTC叶型和叶物候数据合并规则
Tab. 2Reclassifying rules for leaf type and leaf longevity of AVHRR CFTC
| AVHRR CFTC | 叶型 | 叶物候 |
|---|---|---|
| 覆盖率> 66% | 针叶 | 常绿 |
| 覆盖率>66% | 阔叶 | 落叶 |
| 覆盖率< 66% | 混交 | 混交 |
新窗口打开
3 多源土地覆被数据融合决策方法
多源土地覆被信息融合的目标就是采用一种能够灵活处理源数据不同分类体系与目标分类系统之间模糊性的方法,将几种不同分类系统的土地覆被数据源进行融合处理,生成一套在目标分类系统下最佳估计的土地覆被综合数据集。本文设计一种基于模糊逻辑思想的证据融合方法,并结合MODIS VCF、MODIS Cropland Probability、AVHRR CFTC等辅助数据,实现对5套全球土地覆被数据集的高效融合。3.1 目标分类系统的定义
本文面向陆面过程模型应用,并依据植物功能型PFTs(Plant Functional Types)的划分标准,包括生物形态(如乔木、灌木和草本等)、乔木叶型(针叶、阔叶和混交)及其叶物候(常绿、落叶和混交)综合定义了一个新的目标土地覆被分类系统,共包括12类(表3)。该分类系统满足以下两个基本要求:① 所有的分类信息都能从输入数据中获得;② 分类易于在遥感影像上识别。Tab. 3
表3
表3目标土地覆被分类系统
Tab. 3Land cover legends defined by life forms and leaf attributes
| 目标类型 | 生物形态 | 叶属性 | |
|---|---|---|---|
| 叶型 | 叶物候 | ||
| 常绿针叶林 | 森林 | 针叶 | 常绿 |
| 常绿阔叶林 | 森林 | 阔叶 | 常绿 |
| 落叶针叶林 | 森林 | 针叶 | 落叶 |
| 落叶阔叶林 | 森林 | 阔叶 | 落叶 |
| 针阔混交林 | 森林 | 针叶 | 混交 |
| 森林 | 阔叶 | 混交 | |
| 森林 | 混交 | 常绿 | |
| 森林 | 混交 | 落叶 | |
| 森林 | 混交 | 混交 | |
| 灌丛 | 灌丛 | - | - |
| 草地 | 草地 | - | - |
| 耕地 | 耕地 | - | - |
| 城镇建筑 | 城镇建筑 | - | - |
| 湿地 | 湿地 | - | - |
| 水体 | 水体 | - | - |
| 其他(如冰雪、裸地等) | 其他 | - | - |
新窗口打开
3.2 相关性分值的定义
相关性分值是建立多源土地覆被数据集中各类型与目标类型之间的模糊隶属关系的一种定量化表达方法,也是基于模糊逻辑思想的多源数据融合方法的核心内容。本文从以下3个层面分别定义了源数据集中不同的土地覆被类型与目标分类(生物形态和叶属性)之间的相关性分值。3.2.1 源数据集中土地覆被类型与森林类型的相关性分值 参考IGBP和FAO森林资源评估对森林类型的定义描述[31,32],本文依据森林树冠覆盖度大小和类型之间的语义相关关系,用0~100的分值确定源土地覆被数据集中各类型与森林类型的相关性分值。规则如下(示例如表4所示)。
Tab. 4
表4
表4根据树冠覆盖度定义的与森林的相关性分值示例
Tab. 4Definition example of affinity scores for trees according to percentage of canopy cover
| 源土地覆被类型 | 树冠覆盖度(%) | 相关性分值 | 目标类型(生物形态) |
|---|---|---|---|
| 裸地 | 0 | 0 | 森林 |
| 草地 | < 10 | 0 | 森林 |
| 火灾烧毁林地 | > 15 | 30 | 森林 |
| 稀疏林地 | 40~60 | 50 | 森林 |
| 常绿针叶林 | > 60 | 80 | 森林 |
新窗口打开
(1)若源数据集中的某种土地覆被类型在语义上与森林类型完全匹配,那么其与森林的相关性分值取该类型的定义中树冠覆盖度大小的中值。
(2)若源数据集中的土地覆被类型为森林和其他植被的混合类型,并且其定义描述中的树冠覆盖度> 15%,那么根据混合类型中森林所占的比例及其与森林类型的语义关系,该混合类型与森林类型的相关性分值取其树冠覆盖度的最小值和中值之间的分值;如果植被混合类型的定义中树冠覆盖度< 10%,那么其与森林类型的相关性分值为0。
(3)若源数据集中的土地覆被类型与森林类型没有任何语义相关关系,那么其与森林类型的相关性分值为0。
3.2.2 源数据集中土地覆被类型与耕地类型的相关性分值 本文根据耕地的分布概率大小和类型的语义相关关系,定义了源土地覆被数据集中各类型与耕地的相关性分值,分值范围为0~100。规则如下(示例如表5所示):
Tab. 5
表5
表5根据语义关系定义的与耕地的相关性分值示例
Tab. 5Definition example of affinity scores for cropland according to semantic rules
| 源土地覆被类型 | 语义规则 | 相关性分值 | 目标类型(生物形态) |
|---|---|---|---|
| 稀疏草原 | 不是 | 0 | 耕地 |
| 自然植被/耕地混合体:草地/灌木/林地(50%~70%)/耕地(20%~50%) | 占少数 | 40 | 耕地 |
| 耕地与自然植被混合体 | 占半数 | 50 | 耕地 |
| 耕地/灌木/草地混合体 | 占多数 | 60 | 耕地 |
| 耕地 | 是 | 100 | 耕地 |
新窗口打开
(1)若源数据集中的土地覆被类型在语义上与耕地完全匹配,那么其与耕地的相关性分值为100,即是耕地的概率为100%;
(2)若源数据集中的土地覆被类型为耕地和其他植被的混合类型,那么其与耕地的相关性分值根据混合类型中耕地所占的比例及其与耕地的语义关系来灵活确定;
(3)若源数据集中的土地覆被类型在语义上与耕地没有任何关系,那么其与耕地的相关性分值为0,即是耕地的概率为0。
3.2.3 源数据集中土地覆被类型与其他目标分类之间的相关性分值 本文分别从土地覆被类型的生物形态和叶属性(叶型/叶物候)两方面,根据语义来定义源数据集中各土地覆被类型与目标分类之间的相关性分值,即依据如表6所示的语义规则,用0~100内的5个分值来表示全球土地覆被数据集中各个类型与一个或多个目标分类系统中定义的土地覆被类型之间的模糊隶属度。
Tab. 6
表6
表6根据语义规则定义的与其他分类之间的相关性分值示例
Tab. 6Definition example of affinity scores for other legends according to sematic rules
| 源土地覆被类型 | 语义规则 | 相关性分值 | 目标类型(生物形态) |
|---|---|---|---|
| 裸地 | 不是 | 0 | 耕地 |
| 稀疏林地 | 占少数 | 25 | 草地 |
| 稀疏草原 | 占半数 | 50 | 森林 |
| 稀疏灌木林 | 占多数 | 75 | 灌丛 |
| 城镇 | 是 | 100 | 城镇建筑 |
新窗口打开
3.3 数据融合方法
3.3.1 多源土地覆被数据融合的技术方法 本文采用基于模糊逻辑思想的证据融合方法,结合MODIS VCF、MODIS Cropland Probability和AVHRR CFTC数据,将GLCC、UMD、GLC2000、MODIS LC和GlobCover 5套全球土地覆被数据集进行融合,生成包含两级类的全球土地覆被融合数据,包括土地覆被生物形态类型融合数据(8类),以及目标类型融合数据(12类)。多源数据融合方法的总体技术路线如图1所示。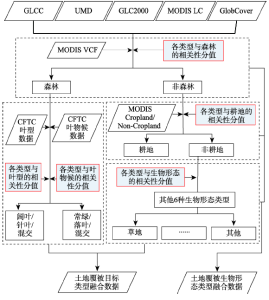 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图1基于模糊逻辑思想的多源证据融合技术方法
-->Fig. 1Principle of the decision-fuse method with multi-source land cover information using fuzzy logic
-->
3.3.2 多源土地覆被数据融合的计算方法
(1)森林/非森林的确定
土地覆被融合数据中森林和非森林类型的确定方法如下:① 将MODIS VCF数据所反映的树冠覆盖度大小(0~100),作为该信息源与森林类型的相关性分值大小(0~100)。
② 结合利用5套土地覆被数据集中各类型与森林的相关性分值以及MODIS VCF数据中相应的相关性分值,按照如下公式逐像元计算其与森林的相关性分值:
式中:
③ 融合数据像元类型森林/非森林的确定规则是:参考IGBP分类中将森林类型定义为“树冠覆盖度在30%以上的乔木植被”,如果像元
(2)耕地/非耕地的确定
对于土地覆被融合数据中非森林类型的像元,本文结合利用MODIS Cropland Probability数据的重分类数据MODIS Cropland/Non-Cropland,以及5套源土地覆被数据集中各类型与耕地的相关性分值,将其进一步分为耕地和非耕地类型,方法如下:
① 将MODIS Cropland/Non-Cropland数据中的值0和1,分别对应转换成各土地覆被类型与耕地类型的相关性分值大小0和100;
② 利用5套土地覆被数据集中各类型与耕地的相关性分值及其在MODIS Cropland/Non-Cropland数据中相应的分值,按照如下公式逐像元计算其与耕地的相关性分值:
式中:
③ 参考美国南达科他州立大学将MODIS Cropland Probability重分类成Cropland/Non-Cropland数据时所使用的全球尺度的阈值,融合数据中像元耕地/非耕地类型的确定规则是:如果像元
(3)其他生物形态类型的确定
对于土地覆被融合数据中非耕地类型的像元,本文利用5套源土地覆被数据集中各类型与目标分类中生物形态类型的相关性分值,将其进一步划分为除森林和耕地之外的其他6种类型,计算方法如下:
式中:
利用公式(3)计算得到的
(4)森林类型叶属性的确定
对于土地覆被融合数据中类型为森林的像元,结合利用AVHRR CFTC叶型和叶物候数据,以及5套源土地覆被数据集中各类型与叶属性之间的相关性分值,确定了其叶型(阔叶/针叶/混交)和叶物候(常绿/落叶/混交)的分类信息,从而将森林类型进一步划分为表1中所示的5种类型。
融合数据中某像元的叶型和叶物候分值的计算方法分别如下:
式中:
从公式(4)和公式(5)可以得出,融合数据中像元
4 土地覆被融合数据的一致性精度评价
利用上述基于模糊逻辑思想的多源证据融合方法得到的全球1 km土地覆被融合数据集SYNLCover(Synergy of Land Cover)如图2所示。其中,图2a和图2b显示的分别是土地覆被生物形态类型和包含叶属性信息的目标分类融合数据。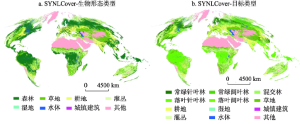 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图2全球土地覆被融合数据SYNLCover
-->Fig. 2The SYNLCover datasets with: (a) life forms, and (b) objective legends
-->
本文分别从土地覆被生物形态类型和目标分类两个层面,对比分析全球土地覆被融合数据(SYNLCover)与5套源土地覆被数据集(GLCC、UMD、GLC2000、MODIS LC和GlobCover)彼此之间的一致性精度,包括:① 数据集的平均总体一致性;② 土地覆被类型的平均一致性。
4.1 土地覆被数据集的平均总体一致性
土地覆被数据集的平均总体一致性的计算分两个步骤:① 分别计算SYNLCover和GLCC、UMD、GLC2000、MODIS LC以及GlobCover两两之间的一致性,即两套土地覆被数据集中相同土地覆被类型的个数与土地覆被类型总数的百分比;② 将其中一套土地覆被数据集与其他5套数据集两两之间的一致性求平均,即可得到该土地覆被数据的平均总体一致性:式中:
图3a和图3b分别显示了在中国区域尺度上,SYNLCover和5套源土地覆被数据集在生物形态类型和目标类型两个层面上的总体一致性精度对比结果。其中,两幅图中对角线上的值分别为每套土地覆被数据集的平均总体一致性精度(%),而非对角线的数值则是上述6套土地覆被数据集之间两两比较的总体一致性精度(%)。
 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图36套土地覆被数据集的总体一致性精度对比
-->Fig. 3Overall consistencies between SYNLCover, GLCC, UMD, GLC2000, MODIS LC, and GlobCover based on (a) life forms, and (b) objective legends
-->
(1)整体上来说,6套全球土地覆被生物形态类型数据集的平均总体一致性精度高于其目标类型的平均总体一致性精度;
(2)在6套土地覆被数据集中,SYNLCover的生物形态类型和目标类型的平均总体一致性精度都是最高的,分别约为65.6%和59.4%,其次依次是MODIS LC、GLC2000、GLCC和GlobCover,UMD的生物形态类型和目标类型的平均总体一致性精度最低,分别为48.9%和42.6%左右;
(3)就6套数据集两两比较的总体一致性精度而言,在土地覆被生物形态类型和目标类型两个层次上,SYNLCover与GLCC、UMD、GLC2000、MODIS LC和GlobCover两两之间的总体一致性都是最好的,而且生物形态类型总体一致性均在55%以上,目标类型总体一致性也都超过50%;特别是SYNLCover与GLC2000的生物形态类型和目标类型总体一致性最好,分别高达74.4%和67.4%。
4.2 土地覆被类型的平均一致性
任意两套土地覆被数据集中各类型的一致性计算方法如下:式中:
类似地,每套土地覆被数据集中的各类型的平均一致性可以利用公式(6)计算得到,将该式中的
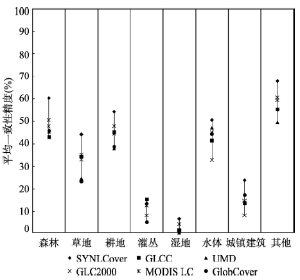
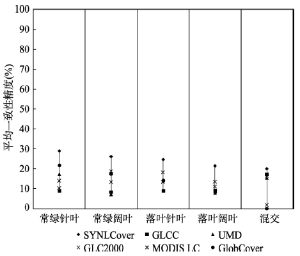
结合利用公式(6)和公式(7)计算得到的SYNLCover和5套源土地覆被数据集中各生物形态类型和森林类型叶属性的平均一致性精度(%)对比分别如图4和图5所示。
 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图4SYNLCover与5套源土地覆被数据集中各生物形态类型的平均一致性精度对比
-->Fig. 4Comparison of average consistencies for life forms among SYNLCover and five original land cover datasets
-->
 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图5SYNLCover与5套源土地覆被数据集中森林叶属性的平均一致性精度对比
-->Fig. 5Comparison of average consistencies for leaf attributes of trees among SYNLCover and five original land cover datasets
-->
从图4可以看出,在中国区域尺度上:① 与5套源土地覆被数据集相比,除灌丛类型外,SYNLCover中其他的7种生物形态类型的平均一致性精度均是最高的。其中,SYNLCover中森林的平均一致性精度为60.23%,草地的平均一致性精度为43.89%,耕地的平均一致性精度为54.13%,水体的平均一致性精度为50.32%,其他的平均一致性精度为67.73%,均高于相应类型在任意一套源土地覆被数据中的一致性精度;② 除灌丛和湿地类型外,森林、草地、耕地、水体、城镇建筑和其他6种类型在SYNLCover中的平均一致性精度均比其在5套源数据集中的平均一致性精度的最大值提高了10%~15%左右。
就森林叶属性的平均一致性精度(图5)而言:① 与5套源土地覆被数据集相比,SYNLCover中森林类型的5种叶属性的平均一致性精度最高。其中,SYNLCover中常绿针叶林的一致性精度最高,为29.21%;② 5套源土地覆被数据集的叶属性的平均一致性精度都很低,其最大值不超过20%;但是,5种叶属性在融合数据SYNLCover中的平均一致性精度比其在源土地覆被数据集中的一致性精度提高了约10%。
5 结论与讨论
5.1 结论
在多源数据共存的背景下,信息融合技术能在一定程度上减少源数据集之间的不一致性,并生成精度较高的融合数据产品,从而有利于扩展这些数据集的应用范围。本文从相关性分值的概念出发,设计了一种基于模糊逻辑思想的证据融合方法,实现了GLCC、UMD、GLC2000、MODIS LC、GlobCover、MODIS VCF、MODIS Cropland Probability以及AVHRR CFTC等多源土地覆被信息的综合集成,生成了一套全球1 km土地覆被融合数据集SYNLCover。在此基础上,本文从土地覆被生物形态类型和目标分类两个层面对融合数据SYNLCover与源土地覆被数据集的总体一致性和类型一致性精度进行了评价。结果显示:在中国区域尺度上,与5套源土地覆被数据集相比,SYNLCover的平均总体一致性精度最高;除灌丛和湿地类型之外的6种生物形态类型在SYNLCover中的平均一致性精度均比其在5套源数据集中的一致性精度的最大值提高了10%~15%左右,而且5种叶属性信息在SYNLCover中的平均一致性精度比其在源数据集中的一致性精度提高了10%左右。研究结果在一定程度上反映出本研究设计的基于模糊逻辑思想的证据融合方法的可行性和有效性,同时为该数据融合方法的使用和推广提供了实践基础和技术支持。
5.2 讨论
首先,全球土地覆被数据集的一致性精度评价对比是建立在统一的分类系统基础上的。因此,本文结合PFTs定义了一个面向陆面过程模型应用的土地覆被分类系统,作为数据集精度对比所需要的统一的目标分类。但与IGBP分类或FAO LCCS分类不同的是,该目标分类系统中没有关于各土地覆被类型的定义描述,不同数据的分类系统与目标分类之间的映射仅仅依据语义关系进行转换,从而导致会对数据集之间的一致性精度对比评价结果产生一定的误差影响。然而,从已有的相关研究和实际经验来看,不同分类系统中关于各个土地覆被类型指标的定量描述只是个理论值[33],在目前关于宏观尺度的土地覆被遥感制图研究中,这些定量指标信息并不能被准确的反映出来。其次,本文设计的多源土地覆被信息决策融合方法的关键和核心是相关性分值的定义,该分值是基于模糊逻辑思想并结合专家经验知识建立的定量化表达了源土地覆被类型与目标类型之间的模糊隶属度关系,具有一定的主观性,可通过采用多位专家经验知识定义的分值综合考虑的方式最终确定相关性分值的大小,从而尽量将主观认识对融合结果的影响减少到最低。此外,基于模糊逻辑思想的证据融合方法从分层次、分类型的建立相关性分值,到定义约束规则从而实现多源土地覆被数据融合,可以为多源信息决策融合相关研究提供技术支撑和科学指导。
最后,利用高精度的土地覆被验证样点数据对全球土地覆被融合数据SYNLCover与5套源数据的精度定量评价与对比分析将会是下一步的研究内容,以此来补充完善这6套数据直接验证的精度评价体系,更加充分、突出反映本研究设计的基于模糊逻辑思想的证据融合方法的应用价值。
The authors have declared that no competing interests exist.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}