电话号码识别的核心技术是印刷体数字识别,这是模式识别的重要研究领域,具有较高的学术研究价值和广泛的商业应用前景。现有的印刷体数字识别方法主要包括2类:一类为基于结构特征的方法,如罗佳和王玲[1]提出了一种基于凹凸特性笔顺编码的识别方法。倪桂博和梁晓尊[2]通过分析印刷体数字的形状,提出了一种基于结构形状的印刷体数字识别方法。陈爱斌和陆丽娜[3]提出了基于多特征的印刷体数字识别方法,采用提取数字区域像素、水平过线和垂直过线的特征进行识别。另一类为基于统计特征的方法,如曾志军和孙国强[4]提出了一种基于改进的BP网络实现字符识别的方法。刘春丽和吕淑静[5]提出了方向特征和密度特征相混合的识别方法。上述2类方法均需手工设计特征模板,依赖设计者的先验知识和手工参数调配,因而只能支持相对有限的特征,且不具备可移植性。手工设计特征工程量大、耗时长,难以应对多种字体、字形的识别。虽然市面上的光学字符识别(Optical Character Recognition,OCR)软件如汉王、ABBYY和云脉OCR等能够识别多种字体、字形的数字,但需要对整个图像进行处理和识别,不能只针对图像中的某个号码进行识别,执行速度较慢,难以满足实际应用需求。
本文采用深度学习(deep learning)和交互式方法解决上述传统印刷体数字识别方法存在的问题。深度学习由Hinton和Salakhutdinov[6]在2006年提出,是机器学习的一个新领域。深度学习与传统模式识别方法的最大不同在于,其能从数据中自动学习特征表示,可以包含成千上万的参数。相比于传统的模式识别方法,识别精度更高、抗干扰能力更强。目前深度学习已成功应用于人脸识别[7-9]、行人检测[10]、机器翻译[11]、图像分类[12-13]、场景识别[14]和门牌识别[15]等领域。采用深度学习方法可以自动提取并学习印刷体数字的特征,可以更有效地支持多种字体、字形的印刷体数字识别。利用交互式识别方法,通过鼠标双击图像中的电话号码,并只针对包含该号码的目标区域进行处理和识别,有助于提高识别速度,能够满足实际应用需求。
1 电话号码图像预处理 图像预处理是电话号码识别的重要步骤,预处理的效果将直接影响最终识别结果,具体流程如图 1所示。
 |
| 图 1 预处理流程图 Fig. 1 Preprocessing flowchart |
| 图选项 |
1.1 鼠标双击截取目标区域 如图 2所示,物流配货软件中包含大量的电话号码,在实际应用中只需对单一号码进行拨号。传统的光学字符识别需要对整个图像进行预处理和识别,执行速度较慢。本文采用交互式的识别方法,通过鼠标双击图像中的电话号码,根据点击的坐标截取出包含该电话号码的目标区域(见图 3),然后对目标区域进行后续的预处理和识别,有效减少了程序的执行时间。
 |
| 图 2 原始图像 Fig. 2 Original image |
| 图选项 |
 |
| 图 3 电话号码目标区域图像 Fig. 3 Image of target area containing telephone numbers |
| 图选项 |
1.2 灰度化 将彩色图像转换成灰度图像,减少后续图像处理的计算量,且灰度图像仍然能反应图像整体及局部的亮度、色度等重要特征,不影响最后的识别效果。本文采用加权平均值法,将R、G和B 3个分量赋予合适的权值进行加权平均,得到灰度化图像(见图 4)。
 |
| 图 4 灰度化图像 Fig. 4 Grayscale image |
| 图选项 |
1.3 二值化 本文采用最大类间方差(OTSU)算法[16],通过阈值来计算图像中目标区域和背景区域的类间方差,将原图像区分出前景和背景,经过OTSU算法,得到二值化图像(见图 5)。
 |
| 图 5 二值化图像 Fig. 5 Binary image |
| 图选项 |
根据背景区域和目标区域的颜色差异,有可能生成白底黑字或黑底白字2类二值化图像。本文的训练集均为白底黑字图像,为提高识别精度,需要将黑底白字二值化图像转成白底黑字图像。方法是计算二值化图像中黑色像素占总像素的比例,当该值大于50%时,进行颜色反转操作,将其转化为白底黑字图像。
1.4 目标区域定位 目标区域定位是本文提出的交互式识别方法的关键步骤。截取到的电话号码目标区域图像(见图 3)可能包含多个号码,相邻电话号码间通常会以空格符区分。因此,需要区分出多个电话号码间的空格(见图 3中的①), 以及同一电话号码内部的连续数字之间的空白(见图 3中的②),由此定位出鼠标双击的号码。随着字号的增大,空格符的大小和连续数字的间隔大小也会增大。本文采用字符高度与其间距的比值作为划分电话号码边界的特征值。为此,选取了宋体、仿宋、楷体、黑体、微软雅黑、隶书、幼圆、Times New Roman、Cambria和Calibri 10种常见字体,9号、10号、11号、12号、14号和16号6种常见字号,计算其数字横向宽度,找出横向宽度最小和最大的数字。显然,横向宽度最小的2个数字间空白最大,横向宽度最大的2个数字间的空白最小。因此,计算区分连续数字、数字间存在空格2种情况的阈值T,只需计算横向宽度最大的2个数字间存在空格的情况下,字符高度与其间距的比值tdown,即可确定出下界。然后,计算横向宽度最小的2个连续数字(二者间无空格)情况下,数字高度与其间距的比值tup,即可确定出上界。最终,阈值T的取值范围是tdown<T<tup。以宋体和黑体为例,当数字为宋体时,横向宽度最小的是1,而其余9个数字宽度相等; 当数字为黑体时,横向宽度最小的数字是1,最大的数字是4,计算结果如表 1和表 2所示。
表 1 宋体数字高度与数字间距离的比值 Table 1 Ratio of number's height to distance in SimSun font
| 字号 | 下界(tdown) | 上界(tup) |
| 9号 | 1.33 | 2.67 |
| 10号 | 1.13 | 2.25 |
| 11号 | 1.00 | 3.33 |
| 12号 | 1.10 | 3.67 |
| 14号 | 1.30 | 4.33 |
| 16号 | 1.67 | 3.50 |
表选项
表 2 黑体数字高度与数字间距离的比值 Table 2 Ratio of number's height to distance in SimHei font
| 字号 | 下界(tdown) | 上界(tup) |
| 9号 | 1.33 | 4.00 |
| 10号 | 1.29 | 4.50 |
| 11号 | 1.25 | 2.50 |
| 12号 | 1.57 | 3.67 |
| 14号 | 1.30 | 2.60 |
| 16号 | 1.36 | 3.00 |
表选项
由表 1可知,宋体9号字时,阈值范围为1.33~2.67;10号字时,阈值范围为1.13~2.25;11号字时,阈值范围为1.00~3.33;12号字时,阈值范围为1.10~3.67;14号字时,阈值范围为1.30~4.33;16号字时,阈值范围为1.67~3.50。选取所有下界中的最大值和所有上界中的最小值,即阈值范围为1.67~2.25时,区分连续数字和数字间存在空格2种情况的效果最好。最后,统计10种字体的阈值范围如表 3所示,取最大的下界tdown为2.00,最小的上界tup为2.25,得到阈值范围为2.00~2.25,然后,取上界和下界的平均值,得到T=2.125,此时区分效果最好。
表 3 10种字体的阈值范围 Table 3 Threshold ranges of ten types of fonts
| 字体 | 阈值范围 |
| 宋体 | 1.67~2.25 |
| 黑体 | 1.57~2.50 |
| 仿宋 | 1.33~2.25 |
| 楷体 | 1.33~2.25 |
| 微软雅黑 | 2.00~3.00 |
| 隶书 | 1.38~2.50 |
| 幼圆 | 1.10~2.25 |
| Times New Roman | 1.71~2.50 |
| Cambria | 2.00~3.00 |
| Calibri | 1.86~4.00 |
表选项
目标区域定位主要方法是,获取电话号码所在位置的坐标,并以该坐标为基准上下移动扫描,当扫描结果全为白色像素线时,则确定其为上下边界。以该坐标为基准纵向扫描,记录连续白色像素的列数即2个数字间的距离,然后计算数字高度与数字间距离的比值X。当X小于阈值T时,为数字间存在空格的情况,即可确定出号码的左右边界;反之,为连续数字情况,应归类为同一个号码。目标区域定位后截取图像如图 6所示。
 |
| 图 6 截取后图像 Fig. 6 Cropped image |
| 图选项 |
1.5 字符分割与图片补白 电话号码中包含多个字符,识别时将其转化为单个字符进行判断,因此需要进行分割操作,将电话号码分割为单个字符。屏幕中电话号码的常见字号为6磅(8像素)~20磅(26像素),因此本文的训练集采用28像素×28像素的图像。因字号大小不同,分割后的图像大小也会不同(见图 7(a))。为保证其特征不变,需要进行归一化操作,将分割后长宽大于28像素的字符图像进行等比例缩放,再通过补白操作,将其调整为28像素×28像素(见图 7(b))。
 |
| 图 7 补白前后图像对比 Fig. 7 Comparison of image before and after padding |
| 图选项 |
2 基于改进LeNet-5网络的识别方法 卷积神经网络(Convolutional Neural Network, CNN)的LeNet-5模型,最初是由Lecun等[17]提出的用于二维图像识别。原始的LeNet-5模型采用Sigmoid激活函数为
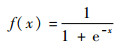 | (1) |
但Sigmoid函数容易产生梯度消失,导致训练出现问题。因此本文对原始LeNet-5模型进行改进,将Sigmoid激活函数替换为ReLU函数为
 | (2) |
和Sigmoid函数相比,使用ReLU可以大幅加快随机梯度下降算法的收敛速度,并通过简单阈值就可以得到激活值,减少了复杂的计算。
如图 8所示,本文改进的LeNet-5模型由7层组成(不含输入层),以28像素×28像素的字符图像作为输入,其中网络C1是由20个特征图组成的卷积层,每层神经元与输入图像的一个5像素×5像素的邻域相连接,每个特征图的大小是24像素×24像素。本文在C1~S2层中加入ReLU激活函数,在训练的初始化阶段对神经元进行抑制和激活,稀疏后的模型能够更好地挖掘数据相关特征。网络层S2是由20个12像素×12像素的特征图组成的降采样层,特征图的每个神经元与C1层的一个大小为2像素×2像素的邻域连接。网络层C3是由50个8像素×8像素的特征图组成的卷积层,特征图的每个神经元与S2层的若干个特征图的5像素×5像素的邻域连接。网络层S4是由50个4像素×4像素的特征图组成的降采样层,特征图的每个神经元与C3层的一个2像素×2像素的邻域连接。网络层C5是由500个1像素×1像素的特征图组成的卷积层,每个神经元与S4层的所有特征图的4像素×4像素的邻域相连。网络层F6包括500个神经元,与C5层进行全连接,本文将这里原始的Sigmoid激活函数替换为ReLU函数。最后,根据本文数据集的类别个数,将输出层调整为13个神经元,数据的分类判断在这一层完成。
 |
| 图 8 改进的LeNet-5 CNN结构 Fig. 8 Improved LeNet-5 CNN structure |
| 图选项 |
3 实验 本文实验流程如图 9所示,主要包括训练和测试2部分组成。训练部分包括数据集生成、改进的LeNet-5神经网络搭建、模型训练与生成;测试部分包括电话号码图像预处理,以及调用生成的模型进行号码识别。
 |
| 图 9 实验流程图 Fig. 9 Experimental flowchart |
| 图选项 |
3.1 数据集建立 传统模式识别任务中,构造适用于多种字体的特征模板是一个耗时和繁琐的工作。本文采用自动生成图像数据集的方法,设计一款数据集生成器。原理是通过读取系统字库文件,自动生成不同的字体、字号和字形的字符图像,这样既缩短数据集的准备时间,又达到数据增强的目的,使数据集包含更多的不同字体、字形和字号特征的字符(见图 10)。
 |
| 图 10 数据集生成器 Fig. 10 Dataset generator |
| 图选项 |
电话号码一般包括0~9十个阿拉伯数字、冒号、横线和汉字(电话:010-1234567)。为提高识别精度,在0~9十个数字类的数据集基础上,添加冒号类、横线类和汉字类,在识别过程中将这3类字符区分出来,从而更好地识别数字字符。通过本文的数据集生成器生成宋体、仿宋、楷体、黑体、幼圆、微软雅黑、隶书、Times New Roman、Cambria和Calibri 10种常见字体,9号、10号、11号、12号、14号和16号6种常见字号,以及常规、倾斜、粗体和粗体倾斜4种常见字形的字符图像,这样每类字符有240张图片。为了进一步增加数据集大小和一定程度上避免过拟合,对生成图片进行任意角度旋转、上下左右平移操作,使每类数据增加到2 700张。
本文数据集共13类,每类2 700张,总共35 100张字符图像。随机选取75%的数据用作训练集,另外25%的数据用作验证集。
3.2 模型训练 本文在Linux环境下,利用深度学习框架Caffe搭建改进的LeNet-5神经网络模型,并利用NVIDIA GTX 970 GPU加速模型训练。如图 11所示,验证集上的识别精度曲线(黄色)识别精度稳定在99%以上,具有较好的识别效果。
 |
| 图 11 模型训练的损失和识别精度曲线 Fig. 11 Loss and recognition accuracy curves of model training |
| 图选项 |
目前Windows平台在桌面领域占据垄断地位,为避免网络延迟、服务器过载等问题,本文没有采用传统的服务器远程识别方法,而是将Caffe框架移植到Windows平台,构造模型进行本地识别,这样不依赖网络环境和第三方服务,能更好地优化识别速度。
3.3 识别速度优化 为了提高电话号码的识别速度,主要在5个方面进行优化。第一,整个识别任务在用户本地电脑进行,不依赖网络环境和第三方服务,避免网络延迟导致识别速度降低。第二,与传统OCR识别相比,通过交互式的识别方法,不需要对整个版面进行处理,只对鼠标双击的号码区域进行处理,缩短了预处理时间;第三,生成的训练模型文件较大,将模型文件常驻内存,避免重复加载模型;第四,在内存中完成图像预处理和字符识别操作,减少IO操作时间;第五,在字符分割时会产生多个字符图像,由于所申请字符图像内存块的大小不一,频繁使用时会产生大量的内存碎片,进而降低性能。因此,采用内存池分配方式进行优化,提高内存分配效率,进而提高识别速度。
4 实验结果与分析 为了检验本文方法的识别效果,实现了一个基于深度学习的交互式电话号码识别系统。随机选取物流配货信息中1 000个包含多种字体、字号和字形的电话号码进行测试。实验机配置: CPU Intel Core i5-4590、8G内存、64-bit Windows 7旗舰版。
4.1 识别精度 在上述1 000个号码的测试结果中,单个字符的识别率为99.86%,整个电话号码的识别率为99.50%。文献[3]中报告的单个字符最好的识别率为99.70%,本文方法的单个字符识别精度略高于文献[3]中提及的最优方法,同时其方法所选用的测试集均为白底黑字的印刷体数字图片,不能处理复杂背景的印刷体数字,而本文选用测试集如图 2所示,包含不同背景颜色和多种文本信息的物流信息图片,复杂度更高,识别难度更大。
4.2 识别速度 在验证识别精度的同时,也进行了识别速度的验证,图 12给出了其中一次测试结果。本文选用了3款主流商用OCR软件:“ABBYY FineReader 12”、“汉王PDF OCR 8.0”和开源OCR引擎“Tesseract-OCR v3.05”。利用上述软件,对1 000个电话号码图像进行识别。对比结果如表 4所示,可以看出,3款软件识别1 000个电话号码平均识别时间均在200 ms以上,而本文方法的平均识别时间为91 ms, 速度明显优于上述3种主流OCR软件。本文采用交互式识别方法,只对图像中感兴趣的号码区域进行处理和识别,缩短了预处理时间。同时通过本地化识别、内存中完成预处理、内存池优化等操作,进一步提高识别速度。
 |
| 图 12 识别速度测试实例 Fig. 12 An example of recognition speed test |
| 图选项 |
表 4 本文方法与3种软件方法识别速度对比 Table 4 Comparison of recognition speed between proposed method and three software methods
| ms | |
| 识别方法 | 单个电话号码平均识别时间 |
| 本文方法 | 91 |
| Tesseract-OCR v3.05 | 225 |
| 汉王PDF OCR 8.0 | 383 |
| ABBYY FineReader 12 | 433 |
表选项
5 结论 本文提出了一种基于深度学习的交互式电话号码识别方法,主要结论如下:
1) 本文方法可达到较为优异的识别效果,单个字符的识别率99.86%,整个电话号码的识别率99.50%,略高于传统方法中最好的识别率。本文方法避免了传统手工构造特征模板的不足,利用卷积神经网络自动提取和学习字符图像特征,识别精度更高、适应能力更强。
2) 本文提出的交互式识别方法,通过鼠标双击图像中的号码,截取包含该号码的目标区域进行预处理,并通过目标区域定位方法提取号码,避免了传统识别方法需要对整个版面进行处理的不足,大幅提高了识别速度。同时,将模型文件常驻内存,避免了重复加载,将图像处理和字符识别操作在内存中完成,并利用高效的内存池分配方式等方法优化了识别速度,相比文中提及3种主流的OCR软件,速度提升了2倍以上。
3) 统计了常见的字体、字号的印刷体数字高度与数字间距离的比值。实验结果表明,该值能作为划分电话号码边界的特征,是实现交互式识别方法的重要特征。
4) 改进了原始的LeNet-5卷积神经网络方法,使用ReLU激活函数代替Sigmoid函数,防止梯度消失,增加了稀疏激活性,加快了计算速度。
5) 通过自动读取系统字库文件自动生成不同字体、字形和字号的字符图片,解决了字符识别中数据集准备繁琐、耗时和字符特征单一的问题。
参考文献
| [1] | 罗佳, 王玲. 基于凹凸特性笔顺编码的手写体数字识别方法[J].计算机工程与科学, 2010, 29(5): 69–70. LUO J, WANG L. A new method for the off-line recognition ofhandwritten digits based on convex-concave coding[J].Computer Engineering & Science, 2010, 29(5): 69–70.(in Chinese) |
| [2] | 倪桂博, 梁晓尊. 基于结构形状的印刷体数字识别方法[J].软件导刊, 2010, 9(5): 67–68. NI G B, LIANG X Z. The method of printed figures based on structure[J].Software Guide, 2010, 9(5): 67–68.(in Chinese) |
| [3] | 陈爱斌, 陆丽娜. 基于多特征的印刷体数字识别[J].计算技术与自动化, 2011, 30(3): 105–108. CHEN A B, LU L N. The printed number character recognition based on feature[J].Computing Technology and Automation, 2011, 30(3): 105–108.(in Chinese) |
| [4] | 曾志军, 孙国强. 基于改进的BP网络数字字符识别[J].上海理工大学学报, 2008, 30(2): 201–204. ZENG Z J, SUN G Q. Number character recognition based on improved BP neural network[J].Journal of University of Shanghai for Science and Technology, 2008, 30(2): 201–204.(in Chinese) |
| [5] | 刘春丽, 吕淑静. 基于混合特征的孟加拉手写体数字识别[J].计算机工程与应用, 2007, 43(20): 214–215. LIU C L, LV S J. Bangla handwritten numeral recognition based on blend features[J].Computer Engineering & Applications, 2007, 43(20): 214–215.DOI:10.3321/j.issn:1002-8331.2007.20.063(in Chinese) |
| [6] | HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J].Science, 2006, 313(5786): 504–507.DOI:10.1126/science.1127647 |
| [7] | SUN Y, WANG X, TANG X. Deep learning face representation from predicting 10, 000 classes[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2014: 1891-1898. |
| [8] | TAIGMAN Y, YANG M, RANZATO M, et al. DeepFace: Closing the gap to human-level performance in face verification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2014: 1701-1708. |
| [9] | SUN Y, CHEN Y, WANG X, et al. Deep learning face representation by joint identification-verification[C]//International Conference on Neural Information Processing Systems. London: MIT Press, 2014: 1988-1996. |
| [10] | ZHANG L, LIN L, LIANG X, et al. Is faster R-CNN doing well for pedestrian detection?[C]//European Conference on Computer Vision. Berlin: Springer, 2016: 443-457. |
| [11] | SINGH S P, KUMAR A, DARBARI H, et al. Machine translation using deep learning: An overview[C]//International Conference on Computer, Communications and Electronics. Piscataway, NJ: IEEE Press, 2017: 162-167. |
| [12] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2016: 770-778. |
| [13] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems. London: MIT Press, 2012: 1097-1105. |
| [14] | CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2016: 3213-3223. |
| [15] | FARABET C, COUPRIE C, NAJMAN L, et al. Learning hierarchical features for scene labeling[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1915–1929.DOI:10.1109/TPAMI.2012.231 |
| [16] | OTSU N. A threshold selection method from gray-level histograms[J].IEEE Transactions on Systems, Man, and Cybernetics, 1979, 9(1): 62–66.DOI:10.1109/TSMC.1979.4310076 |
| [17] | LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J].Proceedings of the IEEE, 1998, 86(11): 2278–2324.DOI:10.1109/5.726791 |
