元数据从本质来说是一种描述数据的数据,是从原始数据提取出的一种上层数据.元数据由于其对数据资源的描述能力以及简单的数据结构,成为信息共享的常用手段.文献[1]建立了基于元数据的多源异构信息共享平台,实现了对大规模的多个来源的信息的集成管理和相互交流.文献[2]是本文之前取得的研究成果,通过设计两层元数据结构,实现了在同一系统中多个种类数据的共享.但是,元数据由于缺乏语义描述能力,不能解决数据集的语义异构问题.例如同一个概念在不同的数据集中可能使用不同的术语,相同的术语在多个数据集中可能表示不同的概念,各数据集中概念之间的隐含联系不能体现出来.
本体是用来描述某个领域甚至更广范围内的概念以及概念之间的关系,使得这些概念和关系在共享的范围内具有大家共同认可的、明确的、唯一的定义,这样,人机之间以及机器之间就可以进行交流[3].本体由于其丰富的语义表达能力和强大的推理能力,能够在描述数据的同时分析概念之间的内部联系,成为解决语义异构问题的重要手段.因此,越来越多的****将本体与元数据相结合[4, 5, 6, 7],赋予元数据语义信息,形成语义元数据,以解决不同数据集的结构异构和语义异构问题.但是本体在实际应用中仍存在以下问题:
1) 数据的自动语义标注仍是本体应用的瓶颈,当数据量较大时需耗费很大的人力进行标注工作.
2) 本体与元数据之间的映射关系复杂,元数据的结构变化会直接影响本体的结构和推理规则.
3) 由于本体通常以OWL(Web Ontology Language)[8]语言编写的XML文件存在,当个体数量庞大时,本体文件变得很大,检索速度很难令人满意.
4) 任何组织和个人都可以建立和发布本体知识,这些本体知识是全局的、开放的,而且是平等的[9],权威组织和普通个人发布的知识没有任何区别,这与信息共享分层次、分权限管理的发展方向发生冲突.
根据上述对元数据和本体在数据共享应用中的优缺点的分析,提出了一种结合元数据和本体各自优点的数据共享方法.首先利用元数据良好的结构性,通过两层结构的元数据实现多源、多类、异构数据在结构上的共享.然后在语义描述方面,创建描述元数据类别的本体,将本体与元数据的类别相关联.这样本体只负责元数据类别之间的关系推理,数据个体则通过元数据进行管理.元数据的类别相对数据个体在数量和变动频率上都是很小的,有利于本体知识的稳定性和减轻本体推理的负担.基于以上分析,建立了基于元数据与本体的信息共享系统(Information Sharing System based on Metadata and Ontology,ISSMO),对元数据检索技术进行了改进,将Lucene全文搜索引擎[10, 11]与本体SPARQL(Simple Protocol and RDF Query Language)[12]查询相结合,提高了元数据检索的检索速度以及查全率.为了验证本文的方法,选取了足球领域数据作为实验数据,实现了信息的共享和语义检索.
1 ISSMO总体框架ISSMO的框架结构如图 1所示,ISSMO从下至上包含4层结构:数据层、元数据层、本体层和业务层,不同层次分别向上提供不同的数据表现形式和操作接口.
 |
| 图 1 ISSMO总体框架Fig. 1 General architecture of ISSMO |
| 图选项 |
数据层包含分布存储的不同种类的数据集,是整个ISSMO的数据来源.元数据层包含了两层元数据,本文将位于最上层格式统一的元数据定义为全局元数据(Global Metadata,GM),将全局元数据下一层针对不同种类数据设计的不同格式的元数据定义为分类元数据(Category Metadata,CM).每一种CM对应于一种数据集,作为这种数据集的格式标准,从数据集合中提取出该类元数据.而GM则是对CM的一种元数据描述,相当于描述CM的元数据.元数据层是数据资源与ISSMO之间的联系枢纽.本体层为GM提供语义描述,建立了全局元数据各元素到本体概念的映射.本体的推理能力能够分析概念之间的隐含联系,进而得出分类元数据之间的联系,这是单纯依靠元数据做不到的.依靠本体层,元数据检索由以前的关键字检索演化为基于本体知识的语义检索,检索结果的查全率和查准率都会得到提高.Protégé是由美国斯坦福大学开发的开源本体开发工具,提供了友好的图形化界面和一致性检查机制.借助Protégé用户可以把精力集中在本体内容的组织上,而不必了解本体描述语言的细节,而且避免了很多错误的发生,方便了本体的构建.Jena是Apache公开发布的开源本体数据引擎工具包,封装了本体数据的标识、查询、推理、持久存储等功能,其作用类似于关系数据库引擎[13].Jena为编程语言和Protégé创建的本体文件提供了联系的桥梁.ISSMO业务层采用SOA(Service-Oriented Architecture)[14]的软件架构,主要功能包括信息发布、信息检索、用户认证以及日志.这4个功能分别封装成可以被重复利用的Web服务.其中信息发布服务和信息检索服务部署在同一服务器节点,该节点安装存储元数据信息的数据库.用户认证和日志服务部署在同一节点,同样安装存储用户信息以及日志信息的数据库.另外通过一个管理节点运行服务器端程序,接受用户的访问以及调用其他节点的Web服务,以友好的用户界面方式呈现给用户.采用SOA的软件架构可以有效地减轻服务器端的负担,将一些频繁的执行操作分配给其他服务节点,提高了计算能力.
2 元数据与本体2.1 两层元数据结构对于分散存储的数据集,ISSMO为每一个类别的数据都制定与之相符的CM格式,同一类数据具有相同的描述标准.GM是在所有类别的CM格式之上抽象出来的一层元数据,GM有唯一的格式.GM屏蔽了不同的CM格式的差异,每个类别的数据都可以使用通用的全局元数据来描述.GM与CM,以及CM和数据资源都是一一对应的.CM的组成元素包含必选项元素和可选项元素.必选项元素包括:元数据索引、发布用户、数据源IP、数据库名、表名、数据标识、发布日期、更新日期和数据类别.可选项元素与数据的类别相关,不同类别的CM有不同的可选项元素名称.考虑到信息描述的完整性,一般至少包含两个可选项元素,而且可选项元素的个数可以扩展.GM的元素包括:标识符、发布用户、主题、主题属性、分类元数据索引、元数据更新时间、元数据描述、元数据级别.这里的主题属性和CM的可选项相对应,个数与可选项相同.图 2为包含两个可选项元素的两层元数据结构.
|
| 图 2 两层元数据结构Fig. 2 Structure of two-layer metadata |
| 图选项 |
由图 2可以看出,各类CM的必选项元素名称是相同的,GM中的一些元素可以直接关联这些必选项元素.如GM的发布用户就是CM的发布用户,主题就是CM的数据类别.而不同类别的CM的可选项元素名称是不同的,GM的主题属性不能直接使用CM的可选项信息,这样会造成描述的不清晰.为了消除可选项的差异,分别将每个CM的可选项元素的名称和对应的内容合并为一个整体作为GM的一个主题属性.这样GM的主题属性既对所有CM的可选项有了统一的描述格式,又不会丢失CM的信息.
在ISSMO中,不同用户发布的元数据的重要性会不同.用户在完成注册后,会分配一定的级别,级别的大小由管理用户负责分配.元数据的级别由GM中的元数据级别表示,级别的大小与用户的级别相关.这样不同用户发布的元数据的重要性就区分开来,级别高的用户发布的元数据一般认为具有较高的可靠性.在检索元数据时,相关度相同的检索结果将按元数据级别由大到小排列,保证将质量最高的数据优先呈献给用户.
2.2 本体研究本体是共享概念模型的明确的形式化规范说明.本体的结构是一个五元组:
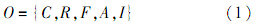
式中:C为概念(也称作类),是对现实事物的抽象,本体中的这些概念通常按照一定的关系形成一个层次结构;R为概念之间的关系,如“subclass-of”关系以及“part-of”关系;F为一种特殊的函数关系,可表示为
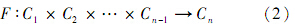
A为概念之间关系所满足的公理,是一个被公认为真的命题;I为领域内的概念实例的集合,实例表示具体的元素.本体数据集成具有自顶向下的特征,利用本体建模共享数据的语义视图,并将不同数据源的异构数据映射为规范化的本体实例数据,能最大程度地减小甚至消除分布式业务系统内部对共享数据的二义性理解,是一种更为先进的数据集成方式[13].由于关系具有传递性,很多概念之间也许并没有直接建立关系,但可以通过与其他概念之间的联系推理出隐含的联系,这就是本体的推理作用,推理作用进一步补充了语义关系网的信息.
在实际应用中,本体实例的个数往往很多,实例包含的信息也十分丰富,本体文件变得十分庞大.本体的存储以及推理的实时性会面临很大的挑战,本体的优势会随之削弱.为了充分利用本体语义描述的作用,在ISSMO中,本体只负责创建概念模型和推理概念与概念之间的联系,具体实例的组织由两层元数据实现.简化后的本体结构为

通过两层元数据实现了多源、异构数据的整合之后,需要关联到本体层才能获得本体的语义支持.GM是所有类别元数据共同的描述,本体层与元数据层的映射也就是本体和GM之间的映射.GM中的主题、主题属性1和主题属性2分别映射到本体的概念,同时创建本体属性HasProperty,将主题作为HasProperty的定义域(domain),将主题属性1和主题属性2作为HasProperty的值域(range).GM中的其他元素对于每一类的元数据都是相同的,可以不必映射到本体.GM的主题表示数据的类别,主题属性1和主题属性2为每一类分类元数据所特有的属性,和主题一样能够区分不同元数据的类别.
3 元数据检索3.1检索流程ISSMO利用本体和两层元数据实现多源、多类异构数据的共享之后,如何高效地从系统中得到感兴趣的数据是用户最关心的问题.评价数据检索的标准主要有查全率、查准率和检索速度.搜索引擎的查全率是指查询关键词时,搜索引擎返回的相关信息数与全部相关信息个数的比率.查准率是指检出的相关信息数与检出的全部信息数的比率.英国情报检索专家Cleverdon[15]通过Cranfield试验揭示了查全率与查准率一般为互逆负相关的关系,即提高查全率往往要降低查准率,反之亦然.使查全率和查准率都同时提高,并不是十分现实.而过分强调一方面,忽视另一方面,也是不妥当的.因此ISSMO的搜索引擎在尽量保证查准率的条件下,针对查全率和检索速度进行了改进研究.
ISSMO引入本体的一个重要目的就是提高检索的查全率,以往基于关键词的检索只能检索到涉及关键词及其分词的信息,缺乏语义关系的判断,会漏掉许多符合条件的信息.ISSMO首先将分词处理后的关键词作为本体概念检索的输入,通过本体SPARQL查询语言和Jena工具包从本体OWL文件中查找与关键词语义一致的概念集合,从而与检索关键词相关的概念集合得到了扩充,检索结果也会相应地增加.图 3为ISSMO搜索引擎的检索流程.
|
| 图 3 ISSMO检索流程Fig. 3 Retrieval process of ISSMO |
| 图选项 |
3.2 SPARQL检索SPARQL是W3C提出的一种查询标准语言,用于资源描述框架(Resource Description Framework,RDF)数据的查询.SPARQL共有4种查询方式,分别为SELECT、CONSTRUCT、DESCRIBE和ASK.目前最常用的是SELECT查询方式,它与SQL的语法相似,用来返回满足条件的数据[16].OWL是对RDF的一个扩充,可以使用RDF类和属性并支持更为丰富的表达元素,使用SPARQL同样能够对OWL数据进行查询操作.
在本文中,本体模型通过Protégé编辑创建,创建完本体类别,以及设定好各类别之间的关系后,使用Protégé自带的FaCT+ +推理机完成推理,得到推理后的本体模型(Inferred model).将Inferred model保存为本地的OWL文件,保存后的OWL文件就是SPARQL查询的对象.由于Protégé目前尚不支持中文的类名称,在本体建模时,类名称使用英文,另外为每个类添加两个标签,标签的内容分别为中文类名称和英文类名称,这样就可以通过标签来查找中文名称对应的本体类.
对于检索词query,首先在本体中查询包含检索词的类别,SPARQL语句如下:
PREFIX rdfs:
SELECT ?x
Where
{
?x rdfs:label query
}
查询结果为Result,如果Result不为空,继续查询该本体类的子类作为概念集的扩充,对应的SPARQL语句为:
PREFIX
SELECT ?x
Where
{
?x rdfs:SubClassOf Result
}
经过两次SPARQL查询,得到了包含查询词所属的本体概念和子概念集合.
3.3 Lucene检索本体的引入提高了ISSMO检索引擎的查全率,但由于概念集规模增加,会引起检索时间的增加以及查准率的下降.为了解决上述问题,ISSMO在关键词检索中使用Lucene全文检索引擎工具包.Lucene检索引擎引入了匹配度的概念,检索结果按照匹配度由大到小的顺序排列,匹配度用来衡量查询词语检索文档的匹配程度,文献[17, 18]给出了Lucene匹配度的计算公式为
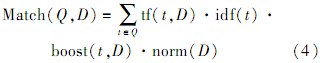
式中:Q为用户查询分词后的词语集合;D为被检索的文档;t为当前查询词;tf(t,D)为词语t在文档D中出现的频率,词语t出现的在文档D中出现的频率越高,匹配度就越大;idf(t)为词语t的逆向文档频率,是一个词语普遍重要性的度量,表示词语t在所有的文档中在多少个文档中出现次数,词语在文本集合的多篇文本中出现次数越多,该词语的区分能力越差,出现次数越少,匹配度就越大;boost(t,D)为与词语t和查询D有关的加权因子;norm(D)为一个规范化因子,在搜索的时候起作用,使得不同查询间的匹配度可比较.
选用Lucene基于以下原因:
1) Lucene全文检索在性能上接近数据库全文检索,检索耗时约为“like”子句检索的1/5.
2) Lucene支持中文分词,在对中文检索方面能达到超过70%的查全率,大大高于数据库全文检索[19].
3) Lucene每次将匹配度最高的前100条返回,这样能够保证准确度高的结果优先呈现给用户,而相关度低的则会放到最后显示,从用户体验的角度保证了检索的查准率.而且降低了返回结果数据加载的压力,尤其当数据量特别多时,优势更加明显.
4) Lucene对网页、文本等非结构化数据的全文检索同样有非常好的性能,与ISSMO未来对非结构化数据进行共享研究的方向相吻合.
在ISSMO中,Lucene对存储在数据库中的元数据资源进行检索,元数据也属于结构数据,因此需要额外的处理.Lucene实现元数据的全文检索需要以下3个步骤:
1) 建立索引文件:遍历元数据库,根据元数据库已有的数据建立Lucene索引文件,索引文件存储在硬盘中.
2) 通过索引文件搜索:有了索引后,即可使用标准的词法分析器进行全文检索,为了加快速度,可以先检索出数据的主键,然后在数据库中取值.
3) 维护索引文件:元数据库中的信息会不断地变动,包括新增、修改及删除等,这些信息的变动需要更新到索引文件中.
4 实 验4.1 实验环境本实验包含4个客户端主机和3个服务器(1个管理节点,2个Web服务节点).4个客户端节点分别注册用户:user1、user2、user3、user4.实验的运行环境如下.
服务器硬件平台:Pentium Dual 2.4GHz处理器,2GB内存.
软件环境:JDK1.7,MyEclipse 10.0开发平台,Apache Tomcat 7.0Web服务器,Oracle Database 11g Release数据库,Windows XP Professional操作系统.
4.2 实验数据及分析4.2.1 数据共享实验在本次实验中,以足球领域数据为例,创建了本体模型,并设计了两层元数据结构,实现了足球领域数据的共享.ISSMO并非单纯针对足球领域数据,选取足球领域数据的原因是此类数据相比其他类别的数据容易获取、受众更广、更容易被理解.ISSMO的本体模型按照文献[20]的足球数据本体模型创建,本体模型如图 4所示,实验数据采用的是2014—2015赛季欧洲足球冠军联赛的比赛数据,包含球员和赛事信息.数据来自于http://www.uefa.com/uefachampionsleague官方网站,图 5为球员数据的样例.由于ISSMO的共享对象是结构化数据,用户需要在本地数据库创建数据表,将比赛数据内容保存在表中,之后登陆共享系统选择数据注册为元数据对外发布.
|
| 图 4 比赛数据本体模型Fig. 4 Ontology model of match data |
| 图选项 |
|
| 图 5 2014—2015赛季欧洲足球冠军联赛的比赛数据样例Fig. 5 Example of 2014—2015 UEFA Champions League data |
| 图选项 |
本体编辑器选用的是Protégé 4.3,本体解析与查询工具包选用Jena 2.4.由于Jena查询引擎与关系数据库相关联,这使得查询存储在关系数据库中的本体时能够达到更高的效率.当本体概念较多,本体文件较大时,ISSMO预先通过Jena将本体OWL文件导入到Oracle数据库中.为了体现多类多源异构数据的统一共享,user1发布德甲球队的前锋信息,user2发布西甲球队的中场信息,user3发英超球队的后卫信息,user4发布意甲球队的守门员信息.每个用户发布的数据都分别存储在各自计算机的本地数据库中.
由图 6可以看出,本系统可以实现分布存储的不同种类数据的统一集成.图 7为与图 6中第一条元数据对应的CM信息,前7行为CM的必选项元素信息,后9行为可选项的元素信息.必选项的IP、数据库SID、数据库表名和标识符共同组成数据存储地址,通过该地址可以直接访问分布存储的原始数据资源.
|
| 图 6 已注册元数据资源Fig. 6 Registered metadata records |
| 图选项 |
|
| 图 7 CM信息Fig. 7 CM information |
| 图选项 |
4.2.2 数据检索实验在检索实验中,将本文提出的Lucene全文搜索引擎结合SPARQL本体查询的语义检索方法与目前基于Oracle的信息系统中最常用的Oracle全文检索进行对比,比较的内容是查全率和检索时间,Lucene的分词器选择IKAnalyzer.检索实验的测试数据为全局元数据库,包含48000条数据,测试关键词选择“罗本”、“前锋”和“England”3个词.
表 1为Lucene+SPARQL语义检索与Oracle全文检索之间的查全率对比.由表 1可以看出,两种方法对于英文检索词都有很高的查全率;对于中文关键词“罗本”,Lucene+SPARQL和Oracle全文检索的查全率相对英文单词均有一定程度的下降,但前者的分词查询效果优于后者.对于“前锋”的检索结果,两种方法的查全率差距较大,这是因为Oracle只是对“前锋”这个词进行了查询,而本文方法在Lucene检索前进行了SPARQL本体查询,根据图 5的本体模型,“左边锋”、“中锋”和“右边锋”都属于前锋这个概念,查询的结果包括了上述关键词的检索结果集合,因此有相对较高的查全率.另外Lucene每次将匹配度最高的前100条查询结果放在缓存集中返回,这100条数据基本满足98.5%用户的检索需求[21].而Oracle全文检索是遍历整个数据库表,返回的结果按其在数据库中的存储顺序排列,并没有考虑匹配度,因此从用户应用角度分析,返回结果的准确度相对本文方法较低.
表 1 两种检索方式查全率比较Table 1 Comparison of recall for two retrieval methods
| 关键词 | Lucene+SPARQL | Oracle全文检索 | ||
| 查全率/% | 匹配度 | 查全率/% | 匹配度 | |
| 罗本 | 89.1 | 有 | 84.7 | 无 |
| 前锋 | 84.5 | 有 | 54.2 | 无 |
| England | 100 | 有 | 100 | 无 |
表选项
表 2为两种检索方法的检索时间的对比情况,中文关键词和英文测试关键词分别选择“罗本”和“England”. 由表 2可以看出数据量越大,Lucene+SPARQL的检索方法相对Oracle全文检索的优势越大.而且当数据量很大时,Oracle全文检索对于中文的检索时间增幅很快,这说明Oracle全文检索目前对中文的检索效果还不尽满意,而Lucene+SPARQL的检索方法对于中文和英文的检索耗时差别很小,能够适应中英文检索的需求.
表 2 两种检索方式检索时间比较Table 2 Comparison of response time for two retrieval methods
| 数据库数据个数 | 检索时间/s | |||
| Lucene+SPARQL | Oracle全文检索 | |||
| 中文 | 英文 | 中文 | 英文 | |
| 200 | 0.047 | 0.040 | 0.032 | 0.036 |
| 2400 | 0.049 | 0.051 | 0.243 | 0.056 |
| 48000 | 0.286 | 0.291 | 1.986 | 0.253 |
表选项
综上所述Lucene+SPARQL的检索方法在查全率及检索时间上相对Oracle全文检索都有一定的改进,尤其是在数据量较大的情况,前者的优势会更大.当然在使用Lucene全文检索前需要对数据库字段做索引,会占用一定的硬盘空间,但相对其取得的检索性能还是值得的.
5 结 论针对多源、多类、异构结构化数据的共享需求,提出了本体与元数据相结合的信息共享方案.将分布于不同数据源的异构数据按照统一的元数据标准描述,并赋予数据类别的语义特征.提出了Lucene全文检索引擎结合SPARQL本体查询语言的元数据检索方法.实验结果表明:
1) 基于两层元数据和本体的共享方法可以有效地实现分散存储的多类异构数据的统一共享.
2) Lucene结合SPARQL本体查询的元数据检索方法有效地提高了检索的查全率,尤其是中文检索的查全率,并降低了检索时间.
本文工作仍存在一些不足之处.ISSMO只支持结构化数据的共享,尚不能共享非结构化数据和半结构化数据,未来的研究工作会针对这两类数据开展.
参考文献
| [1] | Guo X M, Ma L L,Su K,et al.Research and design of multi-source heterogeneous information integration platform for metadata service[J].Applied Mechanics and Materials,2014,513-517:1485-1489. |
| Click to display the text | |
| [2] | Li X T, Hu X H,Liu X,et al.Research on metadata-based multiclass information sharing technology[C]//2014 IEEE Workshop on Electronics,Computer and Applications.Piscataway,NJ:IEEE Press,2014:404-407. |
| Click to display the text | |
| [3] | 杜小勇,李曼, 王珊.本体学习研究综述[J].软件学报,2006,17(9):1837-1847. Du X Y,Li M,Wang S.A survey on ontology learning research[J].Chinese Journal of Software,2006,17(9):1837-1847(in Chinese). |
| Cited By in Cnki (505) | Click to display the text | |
| [4] | Rajpathak D, Chougule R.A generic ontology development framework for data integration and decision support in a distributed environment[J].International Journal of Computer Integrated Manufacturing,2011,24(2):154-170. |
| Click to display the text | |
| [5] | Stasinopoulou T, Bountouri L,Kakali C,et al.Ontology-based metadata integration in the cultural heritage domain[C]//Proceedings of 10th International Conference on Asian Digital Libraries.Heidelberg:Springer Verlag,2007:165-175. |
| Click to display the text | |
| [6] | Kakali C, Lourdi I,Stasinopoulou T,et al.Integrating Dublin core metadata for cultural heritage collections using ontologies[C]//Proceedings of International Conference on Dublin Core and Metadata Applications.Singapore,Dublin:Dublin Core Metadata Initiative,2007:128-139. |
| Click to display the text | |
| [7] | Arch-int N, Arch-int S.Semantic ontology mapping for interoperability of learning resource systems using a rule-based reasoning approach[J].Expert Systems with Applications,2013,40(18):7428-7443. |
| Click to display the text | |
| [8] | Zuo Z H, Zhou M T.Web ontology language OWL and its description logic foundation[C]//Proceedings of International Conference on Parallel and Distributed Computing,Applications and Technologies.Piscataway,NJ:IEEE Press,2003:157-160. |
| Click to display the text | |
| [9] | 董慧. 本体与数字图书馆[M].武汉:武汉大学出版社,2008:222-223. Dong H.Ontology and digital Library[M].Wuhan:Wuhan University Press,2008:222-223(in Chinese). |
| [10] | Qian L P, Wang L D.An evaluation of Lucene for keywords search in large-scale short text storage[C]//Proceedings of 2010 International Conference on Computer Design and Applications (ICCDA).Piscataway,NJ:IEEE Press,2010:206-209. |
| Click to display the text | |
| [11] | Li S D, Lv X Q,Ling F,et al.Study on efficiency of full-text retrieval based on Lucene[C]//Proceedings of Information Engineering and Computer Science.Piscataway,NJ:IEEE Press,2009:1-4. |
| Click to display the text | |
| [12] | Manuel S, Horridge M,Paul R.Using SPARQL to query bioportal ontologies and metadata[J].Lecture Notes in Computer Science,2012,7650(2):180-195. |
| Click to display the text | |
| [13] | 李文雄,闫茂德, 王建伟.智能交通系统本体数据集成[J].中南大学学报:自然科学版,2013,44(7):3038-3097. Li W X,Yan M D,Wang J W.Ontology-based data integration for intelligent transport systems[J].Journal of Central South University:Science and Technology,2013,44(7):3038-3097(in Chinese). |
| Cited By in Cnki (8) | |
| [14] | 毛新生. SOA原理·方法·实践[M].北京:电子工业出版,2007:3-4. Mao X S.SOA principles methods practice[M].Beijing:Publishing House of Electronics Industry,2007:3-4(in Chinese). |
| [15] | Cleverdon C. On the inverse relationship and precision[J].Journal of Documentation,1972,28(3):195-202. |
| Click to display the text | |
| [16] | 杜方,陈跃国, 杜小勇.RDF数据查询处理技术综述[J].软件学报,2013,24(6):1222-1242. Du F,Chen Y G,Du X Y.Survey of RDF query processing techniques[J].Journal of Software,2013,24(6):1222-1242(in Chinese). |
| Cited By in Cnki (25) | |
| [17] | 白培发,王成良, 徐玲.一种融合词语位置特征的Lucene相似度评分算法[J].计算机工程与应用,2014,50(2):129-132. Bai P F,Wang C L,Xu L.Scoring algorithm of similarity based on terms' position feature combination for Lucene[J].Computer Engineering and Applications,2014,50(2):129-132(in Chinese). |
| Cited By in Cnki (4) | |
| [18] | 黄承慧,印鉴, 陆寄远.一种改进的Lucene语义相似度检索算法[J].中山大学学报:自然科学版,2011,50(2):11-15. Huang C H,Yin J,Lu J Y.An improved retrieve algorithm incorporated semantic similarity for Lucene[J].Acta Scientiarum Naturalium Universitatis Sunyatseni:Science and Technology, 2011,50(2):11-15(in Chinese). |
| Cited By in Cnki (17) | Click to display the text | |
| [19] | 吴代文,杨方琦. Lucene在数据库全文检索中的性能研究[J].微计算机应用,2011,32(6):53-61. Wu D W,Yang F Q.The Performance study of database full-text retrieval based on Lucene[J].Microcomputer Applications,2011,32(6):53-61(in Chinese). |
| Cited By in Cnki (6) | |
| [20] | Kara S, Alan O,Sabuncu O,et al.An ontology-based retrieval system using semantic indexing[J].Information Systems,2012,37(4):294-305. |
| Click to display the text | |
| [21] | 王富强,王青山, 张立朝,等.基于Lucene的是数据库全文信息检索[J].测绘科学,2008,33(3):184-187. Wang F Q,Wang Q S,Zhang L C,et al.Database full-text search based on Lucene[J].Science of Surveying and Mapping,2008,33(3):184-187(in Chinese). |
| Cited By in Cnki (16) | Click to display the text |
