

1. 东北大学 计算机科学与工程学院, 辽宁 沈阳 110169;
2. 东北大学 医学与生物信息工程学院, 辽宁 沈阳 110169;
3. 沈阳东软智能医疗科技研究院有限公司, 辽宁 沈阳 110167
收稿日期:2021-01-04
基金项目:中央高校基本科研业务费专项资金资助项目(N181604006); 辽宁省自然科学基金资助项目(20170540312); 国家自然科学基金资助项目(61773110); 沈阳市科学技术计划基金资助项目(20-201-4-10)。
作者简介:王璐(1980-),女,辽宁沈阳人,东北大学副教授;
徐礼胜(1975-),男,安徽安庆人,东北大学教授,博士生导师。
摘要:为改善图像中遮挡和小尺寸行人的检测精度, 提出一种基于语义分割注意力和可见区域预测的行人检测方法.具体地, 在SSD(single shot multi-box detector)目标检测网络的基础上, 首先优化SSD的超参数设置, 使其更适于行人检测; 然后在主干网络中引入基于语义分割的注意力分支来增强行人检测特征的表达能力; 最后提出一种检测预测模块, 它不仅能同时预测行人整体和可见区域, 还能利用可见区域预测分支所学的特征去引导整体检测特征的学习, 提升检测效果.在Caltech行人检测数据集上进行了实验, 所提方法的对数平均缺失率为5.5 %, 与已有方法相比具有一定的优势.
关键词:行人检测卷积神经网络语义分割注意力行人可见区域预测多任务网络
Pedestrian Detection Based on Semantic Segmentation Attention and Visible Region Prediction
WANG Lu1, WANG Shuai1, ZHANG Guo-feng1, XU Li-sheng2,3
1. School of Computer Science & Engineering, Northeastern University, Shenyang 110169, China;
2. School of Medicine and Biological Information Engineering, Northeastern University, Shenyang 110169, China;
3. Neusoft Research of Intelligent Healthcare Technology, Co., Ltd., Shenyang 110167, China
Corresponding author: XU Li-sheng, E-mail: xuls@bmie.neu.edu.cn.
Abstract: To improve the detection performance on occluded and small pedestrians in images, a pedestrian detection method based on semantic segmentation attention and visible region prediction was proposed. Specifically, based on the single shot multi-box detector(SSD)object detection network, the hyperparameter setting of the SSD was firstly optimized to make it more suitable for pedestrian detection. Then the semantic segmentation attention branch was introduced into the network to enhance the pedestrian detection features learned by the network. Finally, a detection prediction module which can simultaneously detect the full bodies and visible regions of pedestrians was developed. This module has the advantage of leveraging the features learned from visible regions to guide the learning of the full-body detection features, hence improving the overall detection accuracy. The experiment carried out on the Caltech pedestrian detection benchmark shows that the log-average miss rate of the proposed method is 5.5 %, which is competitive compared with existing pedestrian detection approaches.
Key words: pedestrian detectionconvolutional neural networksemantic segmentation attention(SSA)pedestrian visible region detectionmulti-task network
基于图像的行人检测是指在图片中找到所有行人实例并将它们的位置标记出来的任务.行人检测在智能视频监控、无人驾驶系统、智能机器人、人体行为分析和客流统计系统等领域都有重要应用.行人检测研究在过去的十多年里取得了较大的进展, 从基于运动的方法[1]到基于机器学习的方法[2], 再到现在基于深度学习的方法[3-11].行人检测的主要问题在于: 1)局部遮挡会导致检测所需的信息量大幅减少进而引起漏检; 2)小尺寸行人实例较难提取到判别力强的特征, 进而导致检测效果不理想.目前的绝大多数前沿的行人检测研究工作都是基于深度学习开展的, 下面进行简要介绍.
为了能够更好地检测出尺寸差异较大的不同行人实例, 研究人员提出了多尺度的行人检测方法[3-4].MS-CNN[3]提出在多个不同尺度的特征图上分别得到区域提议框, 并在检测特征中引入上下文信息来辅助提升检测效果.SA-FastRCNN[4]引入多个子网络检测不同尺度的行人实例, 然后再选取响应最大的子网络的检测结果作为最终检测结果.
一些方法则通过引入语义分割任务来提升行人检测效果.F-DNN+SS[5]将通用物体检测器SSD(single shot multi-box detector)[12]作为基础检测器找到候选的行人实例, 然后引入语义分割网络来对SSD得到的检测结果进行修正, 通过计算预测框和语义分割模块得到的掩码的重合率来修正最后结果, 该方法证明了通过引入语义分割模块确实可以提升行人检测的效果.SDS-RCNN[6]在生成候选区域阶段和对候选区域进行分类阶段都增加了语义分割任务, 并在训练时进行联合优化, 进而增强网络中的特征表达, 使网络对遮挡行人的检测更加鲁棒.FRCN+A+DT[7]首先在Faster R-CNN[13]的区域提议阶段加入语义分割分支来提高提议框质量, 然后在检测阶段则学习特征变换, 使行人和非行人能够更好地被区分, 以此来应对遮挡.
注意力机制也被研究者采用来应对遮挡, 进而提高行人检测质量.Faster R-CNN+ATT[8]探索利用注意力机制对不同的卷积特征通道进行加权来处理行人的局部遮挡问题.SSA-CNN[9]将语义分割特征作为自注意力融入到区域提议和分类两个阶段, 提升对遮挡行人检测的鲁棒性.
此外, RPN+BF[10]结合深度学习和机器学习的优势, 提出首先使用Faster R-CNN的区域提议网络生成候选框, 然后在主干网络的卷积层上提取深度特征, 最后使用随机森林方法对得到的特征进行分类.与仅使用单帧图像作为输入不同, TFAN[11]利用视频中的时间一致性信息改善行人检测结果.该方法为当前帧的被遮挡行人在相邻帧迭代地搜索其对应部分以形成时间管道(temporal tube), 再对来自时间管道的特征进行自适应加权, 然后聚集到当前帧, 从而增强当前帧被遮挡行人的特征表示.
尽管在行人检测领域已经有一些较好的研究成果, 但是局部遮挡以及目标尺寸较小的问题还值得作进一步的探讨.不仅如此, 现有行人检测方法一般都只能输出整体的检测框, 而如果能为后续应用提供行人的可见区域预测, 则能更有效地利用可见部分特征去更好地完成相应任务.据此, 本文提出一种基于SSD检测器[12]的可同时进行行人整体和可见区域检测的方法.
SSD是通用物体检测中表现较好的一种算法, 是一步法(one-stage method)的代表, 其特点是速度快, 检测精度也比较高.但直接用SSD默认的超参数训练行人检测器并不能得到很好的检测效果, 其原因包括: 1)SSD的默认超参数是针对通用目标检测设计的, 对于行人检测而言不是优化的; 2)一般的行人检测数据集中小尺度行人占主导地位, 但SSD对小尺度目标检测准确率偏低; 3)遮挡在行人数据集中普遍存在, 但SSD对被遮挡行人的检测效果不理想.针对上述问题, 本文首先通过调整原始SSD算法的输入尺寸、各检测层检测尺度的划分和默认框生成, 使SSD在行人检测任务上的效果有较大提升.接下来, 本文引入语义分割注意力来增强行人检测浅层特征的语义表达能力和准确性, 进而提升各尺度级别行人检测的效果.最后, 本文提出一种新的检测预测模块, 它不仅能同时预测出行人整体和可见区域, 还能让全身检测分支接收到可见区域标注信息的引导, 改善特征学习质量, 进而提高行人检测精度.在Caltech行人检测数据集[14]的Reasonable评估标准下, 本文所提方法的对数平均缺失率(log-average miss rate, LAMR)[14]为5.5 %, 达到了前沿的检测效果.本文方法的源代码下载链接为https://github.com/wangironman/ssa and vrg for pedestrian detection.
1 方法本文所提出的行人检测方法的网络结构如图 1所示.在SSD目标检测算法的基础上, 本文首先面向行人检测任务对SSD的超参数设置进行了优化, 然后分别引入语义分割注意力和行人可见部分预测任务来进一步提高行人检测精度.
图 1(Fig. 1)
 | 图 1 本文的行人检测网络结构示意图Fig.1 The overall network architecture of the proposed pedestrian detection approach |
具体地, 首先将图像输入到SSD的基础网络(VGG)[15], 依次得到7个不同层级的多尺度特征.然后, 将前两个层级的特征(Conv4-3和Conv7)经过语义分割注意力(semantic segmentation attention, SSA)模块得到由语义分割注意力加权后的特征.接着这两个特征以及后面的5个层级的特征都通过可见区域指导的检测模块VRG(visible region guide)模块得到各尺度下的预测结果.最后将7个层级的结果汇总, 通过对行人整体的预测框进行非极大抑制(non-maximum suppression, NMS)操作得到最终的预测结果.下面将详细阐述该方法.
1.1 面向行人检测任务优化的SSD检测器SSD是经典的一步目标检测方法, 其核心思想是: ①直接通过设置默认框(default box)而不是生成区域提议框(region proposal)来预测目标物体的置信度分数和位置坐标, 进而显著提高计算速度; ②使用卷积层而不是全连接层得到预测结果, 减少参数量和计算时间; ③在不同大小的特征图上进行多尺度检测, 能较好地应对物体的尺度变化.基于以上优点, 本文选择SSD作为基础检测器.针对行人检测任务的特点, 本文对SSD的超参数设置进行了如下4点调整, 得到面向行人检测优化的SSD检测器AD-SSD(adapted-SSD).
1) 与原始的SSD使用正方形图像作为输入不同, 本文保持检测网络输入的宽高比与图像原始的宽高比一致, 这样做可以使SSD在经过数据增广之后, 所得图像的行人宽高比不发生改变.
2) 原始SSD为了识别多类不同的目标, 为默认框设置多个不同的宽高比, 以便能够顾及到各类不同目标的形状分布.而对于行人检测任务而言, 行人都是直立的, 边框宽高比相对集中, 因此本文将SSD所有默认框的宽高比调整为行人宽高比的平均值.
3) 为提高检测成功率, 本文对原始SSD各个检测层检测的尺寸范围进行重新划分, 提出在检测层的相邻两层使用相同的检测尺度范围.以该种方式进行设置, 如果在某一特征层上目标物体被检测的效果不好, 还可以在下一层该目标进行再次检测.
4) 针对原始SSD中默认框在各个检测层上使用的尺寸较少(仅有2个), 对于行人检测效果不佳的问题, 本文提出在每个特征图上生成更加密集的默认框, 以此来应对不同尺度的行人, 具体设定方法如式(1)所示:
 | (1) |
1.2 语义分割注意力(SSA)模块SSD直接在不同层次和尺度的特征图上分别进行相同的目标检测, 这样做的问题在于, 小物体通常是在浅层特征图上进行检测的, 而浅层特征是较为低级的特征, 它的语义表达能力较弱, 会导致大量小物体不能被准确地检测到.此外, 由于深层特征是基于浅层特征得来的, 所以浅层特征的质量也直接决定了深层特征的优劣.基于该分析, 本文提出一种提升SSD检测效果的思路, 即在基础网络中的浅层添加语义分割分支, 再将该分支所得特征同浅层的检测特征进行融合, 进而获得具有更强表达能力的检测特征, 提升检测器的精度.其中, 语义分割又分为全身语义分割和可见区域语义分割两部分.全身语义分割特征能够更准确地区分行人区域与背景区域; 可见区域语义分割特征则能进一步提供更准确的行人可见部分的外观特征及其位置信息.联合这两类特征来增强检测特征, 理论上讲是能够有效提升行人检测准确性的.
具体地, 如图 1中的SSA模块所示, 本文在SSD的Conv7层之后引出2个基于FCN-8s全卷积分割网络[16]的分支来分别进行全身和可见区域的语义分割预测.由于FCN网络的原始输入为待分割图像, 而本文的输入为特征图, 因此本文使用的是FCN从pool3层到pool5层的子网络来计算语义分割特征, 该特征经8倍上采样后即得到语义分割结果.然后, 将所得的全身语义分割特征Conv7_all_ss和可见区域语义分割特征Conv7_vis_ss与Conv4-3层对应的检测特征进行融合, 再将Conv7_all_ss和Conv7_vis_ss进行2倍下采样后与Conv7层的特征融合.融合方式一般有三种: 级联融合(concatenation)、逐元素相加融合和逐元素相乘融合.实验证明, 逐元素相乘能更有效地提高检测的效果, 这相当于给原始检测特征加上要强调的部分, 属于一种注意力机制.该操作能够使浅层特征语义信息较弱的问题得到明显改善, 进而使网络在浅层检测尺度较小的行人的能力得到增强.此外, 由于深层特征是基于浅层特征计算的, 该操作也同时提高了所有后续深层特征的表达能力.实验证明, 只用SSA增强Conv4-3和Conv7这两层特征与用SSA增强全部7个检测层的特征相比, 性能上差别非常小, 这是因为浅层特征改善后, 深层特征也会得到相应的改善.由于增强两层特征的计算量比增强全部特征更小, 本文选择只对Conv4-3和Conv7这两层的特征进行SSA的计算.
由于公共的行人检测数据集通常不包含行人像素级的语义分割标注, 因此本文通过对行人边框标注进行填充来生成训练所需的弱语义分割图(所谓“弱”就是不十分精确的意思).同样地, 可以基于行人可见区域标注边框来生成类似于弱语义分割标注的行人可见区域语义分割标注.
1.3 可见区域引导(VRG)的检测模块除了预测行人整体的边界框, 本文还希望能够进一步为后续任务提供边框级的可见区域的信息.为此, 重新设计了一个能够同时进行行人全身和可见区域预测的检测模块, 如图 1中的VRG检测模块所示.具体地, 对于全身预测分支, 将特征依次经过两个卷积层和一个预测层得到全身的预测结果, 即边框回归偏移量Loc以及预测置信度Conf.对于可见区域预测分支, 将输入特征进行一次卷积操作后所得的特征与全身预测特征进行拼接, 然后经过一个卷积层进行两个分支特征的融合以及预测特征的提取, 最后经过预测层得到最终的可见区域预测结果, 即边框回归偏移量Loc_vis以及预测置信度Conf_vis.
其中的两分支特征拼接操作使得在反向传播时, 全身分支也可以学习到可见区域的监督信息, 即可见区域的信息能够指导全身分支学习到更加准确的检测特征, 进而能够提升最终的行人整体检测效果.
1.4 损失函数和多任务网络训练本文所提出的网络为多任务网络, 整体的目标损失函数为各子任务损失函数之和, 如式(2)所示:
 | (2) |
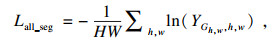 | (3) |
2 实验与结果2.1 实验设置使用Caltech行人检测数据集[14]对算法进行评估.该数据集包含约35万个行人标注框, 约2 300名独立的行人.该数据集将所有数据分为两个部分, 其中S0到S5这六个序列作为训练集, S6到S10这五个序列用作测试集.Caltech数据集的图片大小为640×480.本文使用最为常用的Reasonable标准进行评估, 它要求行人的高度至少为50个像素、可见区域大于等于全身框的65 %.经统计, 其中约4.5 % 的行人实例是被遮挡的.本文使用行人检测任务通用的对数平均缺失率LAMR[14]来对行人检测方法的准确性进行评估.LAMR计算的是不同误检率下的平均检测缺失率, 是对检测器准确性的一种综合度量, 能全面反映检测器的精确度.
在面向行人优化的AD-SSD检测器中, 网络的输入尺寸设为640×480(与Caltech数据集的图片大小一致), SSD所有默认框的宽高比统一设置为0.41, 各检测层检测尺寸范围的划分如表 1所示, 式(1)中的NStep设定为10.
表 1(Table 1)
| 表 1 检测范围在SSD网络不同级别特征图上的重新设定 Table 1 Detection range setting for the feature maps of different levels on SSD |
实验基于Python语言在深度学习框架PyTorch上实现, GPU为GeForce GTX 1080.网络的训练采用随机梯度下降法, Batch Size设为2.网络训练的学习率为0.000 1, 动量为0.9, 迭代次数为12万次, 分别在6万、8万、10万次迭代时, 将学习率调整为原来的1/10.式(2)中的α, β和γ分别设置为1, 5和5.
2.2 实验结果2.2.1 针对行人检测优化的AD-SSD检测器检测结果表 2对比了原始的SSD以及本文的针对行人检测优化的AD-SSD检测器在不同输入尺寸下的检测缺失率.可以看到, AD-SSD的缺失率明显低于原始的SSD检测器.
表 2(Table 2)
| 表 2 不同输入尺寸下AD-SSD与SSD的检测结果比较 Table 2 Detection accuracy comparison between the proposed AD-SSD detector and the original SSD detector with varied input resolutions |
2.2.2 剥离实验为了展示本文所提方法中各组件的作用, 将AD-SSD作为baseline检测器进行了剥离实验, 所得结果如表 3所示.其中+ALL_SEG表示加入全身语义分割注意力, +VIS_SEG表示加入可见区域语义分割注意力, +VRG表示使用本文的可见区域引导的预测模块替代原始的SSD预测模块.由表 3可见, 加入两种语义分割注意力后, 行人检测的缺失率从11.3 % 下降到6.3 %, 而进一步使用本文所提出的预测模块则能使检测缺失率下降到5.5 %, 达到前沿的检测精度.究其原因在于, 语义分割注意力能对检测特征进行有效地增强, 而可见区域预测任务提供的额外的监督信息能使网络学习到更准确的行人特征.
表 3(Table 3)
| 表 3 本文所提的行人检测方法的剥离实验 Table 3 Ablation experiment of the proposed pedestrian detection approach | |||||||||||||||||||||||||||||||||||||||||||||
2.2.3 可见区域预测结果本文还进一步评估了可见区域预测的准确性, 如表 4所示.评估时, 每个可见框的置信度取其对应的全身框的置信度.可以看到, 若评估时将预测框与标注框的交并比(intersection over union, IoU)阈值设为0.5(即预测框与标注框的IoU大于0.5时认为检测成功), 可见区域预测的缺失率LAMR为15.5 %, 比全身框预测的准确性低了10 %.这是由于可见部分的区域面积相对于全身会小, 在同样的偏差下, 可见区域预测对应的IoU会更低.另一方面, 可见区域真实值标注本身就存在一定歧义, 这也会导致可见框预测的准确性降低.
表 4(Table 4)
| 表 4 行人可见区域预测结果 Table 4 Pedestrian visible region prediction results |
2.2.4 与已有的行人检测方法比较本文所提方法与一些主流的行人检测方法比较的结果如表 5所示.其中MS-CNN和SA-FastRCNN为多尺度行人检测方法; FRCN+A+DT,F-DNN+SS和SDS-RCNN利用了语义分割提高行人检测精度; RPN+BF结合了深度学习和机器学习各自的优势; TFAN是基于视频时间一致性的行人检测方法.可以看到, 一些方法试图通过提高输入图片的分辨率来提高检测的准确性, 而本文所提方法在维持输入图片分辨率不变的前提下, 得到了较高的精度, 在GTX 1080 GPU上的计算速度达到4帧/s.
表 5(Table 5)
| 表 5 与已有方法的运行时间和检测精度比较 Table 5 Comparison of detection accuracy and running time with existing methods |
2.3 可视化检测结果展示图 2给出了本文所提方法在Caltech数据集上的检测结果示例(从上到下依次为示例1,示例2,示例3,示例4), 真实值标注图像中蓝色和黄色分别表示整体框和可见区域框, 检测结果图像中绿色和红色分别为所提方法预测的整体框和可见区域框, 只有黄色框或红色框表明可见框和全身框完全重合.由图 2可见, 本文所提的方法能够对大多数行人(包括遮挡和小目标)进行正确检测, 同时给出相对准确的可见区域的预测, 具有较好的检测效果.但是对于严重遮挡目标和极小的目标实例本方法还存在漏检的情况(示例2和示例3), 而对于场景中与行人外形特别相似的物体也会出现误检(示例4).
图 2(Fig. 2)
 | 图 2 检测结果展示Fig.2 Illustration of the detection results of the proposed method |
3 结语本文在通用目标检测器SSD的基础上构建了一个基于语义分割注意力机制和可见区域预测的行人检测器.本方法首先对原始SSD的输入尺寸、检测尺寸范围和默认框的设置进行调整, 使其更好地适应行人检测任务; 然后引入语义分割注意力来增强网络对浅层检测特征的学习, 进而达到提升各级检测特征质量、提高小尺度目标检测的准确性和减少背景干扰的目的; 最后在预测模块中加入行人可见区域预测任务, 使检测器能够接收行人可见区域监督信息的引导, 学习到更有效的行人特征, 进而提高检测的准确性.在Caltech数据集上本文方法的对数平均缺失率为5.5 %, 显示了本文所提方法的有效性.
行人检测算法仍有很大的改进空间, 下一步的工作包括: ①研究如何利用视频中相邻帧的时间一致性信息来缓解小物体和遮挡引起的漏检; ②探讨结合可见区域预测结果的非极大抑制(NMS)方法来减少严重遮挡情况下的漏检.
参考文献
| [1] | Wang L, Yung N. Extraction of moving objects from their background based on multiple adaptive thresholds and boundary evaluation[J]. IEEE Transactions on Intelligent Transportation Systems, 2010, 11(1): 40-51. DOI:10.1109/TITS.2009.2026674 |
| [2] | Dalal N, Triggs B. Histograms of oriented gradients for human detection[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego: IEEE, 2005: 886-893. |
| [3] | Cai Z, Fan Q, Feris R S, et al. A unified multi-scale deep convolutional neural network for fast object detection[C] //European Conference on Computer Vision. Amsterdam: Springer, Cham, 2016: 354-370. |
| [4] | Li J, Liang X, Shen S M, et al. Scale-aware fast R-CNN for pedestrian detection[J]. IEEE Transactions on Multimedia, 2018, 20(4): 985-996. |
| [5] | Du X, El-Khamy M, Morariu V I, et al. Fused deep neural networks for efficient pedestrian detection[J]. arXiv Preprint arXiv, 2018, 1805.08688. |
| [6] | Brazil G, Yin X, Liu X. Illuminating pedestrians via simultaneous detection & segmentation[C]//Proceedings of IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 4960-4969. |
| [7] | Zhou C, Yang M, Yuan J. Discriminative feature transformation for occluded pedestrian detection[C]// Proceedings of IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 9556-9565. |
| [8] | Zhang S, Yang J, Schiele B. Occluded pedestrian detection through guided attention in CNNs[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6995-7003. |
| [9] | Zhou C, Wu M, Lam S. SSA-CNN: semantic self-attention CNN for pedestrian detection[J]. arXiv Preprint arXiv, 2019, 1902.09080.. |
| [10] | Zhang L, Lin L, Liang X, et al. Is faster R-CNN doing well for pedestrian detection?[C]//European Conference on Computer Vision. Amsterdam: Springer, Cham, 2016: 443-457. |
| [11] | Wu J, Zhou C, Yang M, et al. Temporal-context enhanced detection of heavily occluded pedestrians[C]//Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 13427-13436. |
| [12] | Liu W, Anguelov D, Erhan D, et al. SSD: single shot multibox detector[C]//European Conference on Computer Vision. Amsterdam: Springer, Cham, 2016: 21-37. |
| [13] | Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. DOI:10.1109/TPAMI.2016.2577031 |
| [14] | Dollár P, Wojek C, Schiele B, et al. Pedestrian detection: an evaluation of the state of the art[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 743-761. DOI:10.1109/TPAMI.2011.155 |
| [15] | Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv Preprint arXiv, 2014, 1409-1556. |
| [16] | Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3431-3440. |
| [17] | Girshick R. Fast R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision. SanDiego: IEEE, 2015: 1440-1448. |
