
 , 雷志浩, 齐林
, 雷志浩, 齐林 东北大学 信息科学与工程学院, 辽宁 沈阳 110819
收稿日期:2020-07-23
基金项目:国家自然科学基金资助项目(61871106);辽宁省重点研发项目(2020JH2/10100029)。
作者简介:魏颖(1968-),女,辽宁本溪人,东北大学教授,博士生导师。
摘要:在婴幼儿脑组织分割领域中, 婴幼儿脑组织存在对比度低、灰度不均匀等问题, 这些问题导致现有方法的精度仍然达不到满意的结果.因此, 本文提出了一种基于三维U-Net网络的脑部核磁共振图像组织分割方法, 融合注意力机制模块和金字塔结构模块, 可以更好地在不同的层次和位置提供模型信息, 图像的上下文信息得到充分的应用以降低图像信息损失, 同样还可以挖掘通道映射之间的相互依赖关系和特征映射, 提高特定语义的特征表示.在Iseg2017数据集中所提出算法的WM(白质), GM(灰质)的DICE指标结果与此前最优结果相比提高了0.7 %, 0.7 %, CSF(脑脊液)则具有可对比性.在Iseg2019跨数据集挑战的评估当中, WM, GM的分割结果在DICE, ASD两个指标均取得了第一名, CSF的指标获得第二名.
关键词:婴幼儿脑MR图像脑组织分割多模态数据3D深度学习
3D U-Net Infant Brain Tissue MR Image Segmentation Based on Attention Mechanism
WEI Ying
, LEI Zhi-hao, QI Lin School of Information Science & Engineering, Northeastern University, Shenyang 110819, China
Corresponding author: WEI Ying, E-mail: weiying@ise.neu.edu.cn.
Abstract: In the field of infant brain tissue segmentation, infant brain tissue has problems such as low contrast and uneven gray scale. These problems lead to the unsatisfied accuracy of the existing methods. A brain MRI image tissue segmentation method was proposed based on a three-dimensional U-Net network(3D U-Net), which combines the attention mechanism module and the pyramid structure module, to better provide model information at different levels and positions. The contextual information of the image is fully applied to reduce the loss of image information. It can also mine the interdependence and feature mapping between channel mappings to improve the feature representation of specific semantics.The DICE index results of WM (white matter) and GM (gray matter) of the algorithm proposed in the Iseg2017 dataset have increased by 0.7 % compared with the previous optimal results, and the CSF (cerebrospinal fluid) index is with comparability. In the evaluation of the Iseg2019 cross-dataset challenge, the segmentation results of WM, GM in DICE ratio and ASD achieved first place, while the CSF index won the second place.
Key words: infant brain MR imagesbrain tissue segmentationmultimodality data3D deep learning
近年来, 人类对大脑的研究更加深入, 人类的生长发育和各种疾病被认为和大脑的某些特定结构息息相关.在大脑的研究中, 脑组织的分割是其中相当重要的一环, 多模态数据分析在脑组织分割中的应用越来越广泛, 通过不同技术获取相同目标结构的图像, 利用这些互补的信息精确地描述感兴趣的结构.多模态场景中常用的分割方法为多图谱分割方法, 然而传统方法在精度和速度方面的性能并不令人满意.随着计算机运算能力的增强, 深度学习的方法越来越普及, 例如FCN[1], U-Net[2], Deep-Lab[3], Refine-Net[4]等深度学习方法被提出用于建立新的二维图像分割, 这些模型在医学分割领域都取得了相当优异的成果.
即使目前有较多的深度学习方法, 但是由于脑组织结构中边界模糊, 存在大量噪声并且样本过少等问题, 这些方法的精度仍然达不到满意的结果.研究人员对于脑组织的分割大多采用基于U-Net的基本框架并且采用整张图片输入的方式进行模型的训练, U-Net采用Encoder-Decoder结构, 结构简单但有效, Encoder负责特征提取, Decoder恢复原始分辨率, 类似于一种U型结构.该框架有以下几个优点: ①网络的结构和数据增强方式使这个网络学习少量的标注数据便可以获得很好的泛化能力;②适当地应用刚性变换和轻微的弹性变形, 仍然可以产生生物学上合理的图像.此方法用于成人脑组织分割有着显著的效果.但是存在的问题是: 连续池化操作或卷积中的步长导致的特征分辨率降低, 同时与成人的脑组织相比,婴幼儿脑组织还存在对比度低、灰度不均匀等问题, 特征图经过多次降采样之后信息损失会逐渐增多, 解码器部分并不能很好地还原.
为了解决上述提到的问题, 受到空间金字塔结构和空洞卷积[5]的启发, 本文提出了在降采样段采用Dila-Block模块, 该模块主要作用是能很好地获取特征图当中的多尺度信息, 并且能够支持扩张感受野的同时而不损失分辨率和覆盖范围.图像金字塔的结构能够提供多尺度的输入信息, 较小尺寸的特征能够提供长距离的语义信息, 大尺寸可以提供更多的细节信息.通过采用不同空洞率的卷积, 可以捕捉多尺度对象, 因而在降采样阶段避免过多的信息丢失.
对于解码部分, 特征图的空间尺寸通过上采样逐渐增大.而在以前的模型中使用的最流行的上采样操作是反卷积.然而, 反卷积应用相同的本地内核来扫描每个位置, 而不考虑全局信息.当输入特征图的空间尺寸大于内核尺寸时, 反卷积无法在上采样过程中恢复所有必要的信息.于是本文提出了基于non-local的注意力方法, 适用于医学图像分割任务, 解码侧的特征图经过反卷积和注意力模块后再传输到下一层当中.通过此模块, 能够捕捉序列中的长依赖关系, 图像中的全局信息通过此模块可以被聚合到一起,能够实现模型的性能提升.
1 基于3D U-Net网络结构模型1.1 算法框架和模型结构本文的算法框架包括两部分: 图像预处理、模型结构.本文在预处理和模型架构阶段的方法如图 1所示.由于本文的三维结构的计算能力有限, 为了使模型的训练过程更有效率, 本文将训练集和测试集裁剪为32×32×32, 重叠步长设置为8, 然后将它们输入到深度网络的卷积层中, 卷积核的大小决定了接受域的大小, 即学习特征[6]的大小.
图 1(Fig. 1)
 | 图 1 模型框架Fig.1 Model architecture |
1.1.1 深层卷积池化模块(DCP-Block)在不同卷积核大小的情况下, 不同尺度的卷积大小可以成为特征, 这对于提高深度网络的分割性能具有重要意义, 即多尺度特征.如图 1所示, 如果使用大的卷积核来获得感受野, 训练参数会变得过于复杂, 易导致过拟合问题.针对大规模特征与计算代价的冲突, 本文采用了空洞卷积.通过改变空洞率的大小, 可以得到多尺度特征.
在编码器阶段, 本文通过DCP(dense convolution-pyramid)模块来实现这个功能.针对脑组织边缘分割的精度不高的问题, 本文采用了计算机视觉中常见的注意机制来增强图像的边缘显著性区域, 使输出的特征更加分化.
已有研究[7]表明, 残差网络可以在一定程度上改善深度学习模型的训练.此外, 由于所采用的3D脑图像分割, 因此输入图像受到很大的限制, 随着网络结构逐渐深入, 最底层特征图的大小仅仅只有8×8×8.在特征图减小的过程中, 图像的许多细节信息会丢失, 也是造成图像在边缘等结构复杂区域分割精度降低的主要原因.特别是婴幼儿脑图像, 脑组织对比度比成人低, 且灰度更加不均匀.
为解决此问题, 本文首先尝试在降采样中使用了一个基于残差网络的结构.取消了池化层, 用一个步长为2的卷积替换了常用的池化层.左边是1×1×1与一个步长为2的卷积;右侧包含一个Dila-Block模块和一个激活的调节层, 此Dila-Block模块的主要功能就是为了较大程度减小特征图较少所带来的损失.该调节层的卷积核大小为3×3×3, 步长为2.其结构如图 1所示, 包括预激活层, 中间为四个空洞卷积.卷积核的大小为3×3×3, 前三个空洞率分别为1, 2, 4, 最后一个是1×1×1的卷积.在卷积之后, 四个块被叠加到一起, 然后连接到下一阶段的卷积层.通过这个模块, 可以利用到图像的浅层信息, 金字塔结构也可以充分利用到图像的多尺度信息.
1.1.2 注意力模块在网络的解码器阶段, 使用了通道注意力和空间注意力, 并且注意力模块可以将更广泛的上下文信息编码到空间的局部特征中, 从而增强它们的表示能力.在通道注意力模块中, 通道的每一个高级特征都可以看作是一种特定的响应.通过挖掘通道映射之间的相互依赖关系, 可以强调相互依赖特征映射, 改善特定语义的特征表示.
注意力机制在计算机视觉应用中的一个常见例子是解码阶段使用自注意力, 它通过聚焦于输入的每个位置来计算一个位置的输出.这些研究[8-10]均用于捕获长依赖关系, 即对特征图的信息进行汇总.
通过采用空间金字塔和残差网络的结构, 很好地利用了图像的局部信息和多尺度信息, 但是为了提高脑图像的分割DICE等指标, 还需要更好地聚合输入特征图中的全局信息, 使其能够更好地从全局信息出发, 放大有价值的特征通道的同时抑制无用的特征通道.与卷积和反卷积等局部操作相反, 全局信息意味着特征图中的每一个体素都与整个特征图相关.因此在解码器最底层, 为了使反卷积过程中能够更好地利用到全局信息, 本文采用了一个自注意力模块来实现此功能, 在分割过程中, 模型能够根据全局信息来判断该体素与哪个结构更类似, 进而提高分割准确率.此注意力模块采用了双通道输入设置, 此前在场景分割中也有类似结构DA-Net[11].本文是在三维图像中添加自注意力机制模块.以往的研究多基于二维图像的分割.与二维图像相比, 在处理数据时需要将三维图像处理成二维向量.结构如图 2所示.空间注意力具体步骤: 本文首先将特征图中代表D×W×H(长×宽×高)立方体的表示为三维向量D×W×H×C(长×宽×高×通道数).经过铺平操作后, 这些向量折叠成一个矩阵的大小(D×H×W) ×C.对于由3D块B生成的每个向量, 将其乘以C的转置, 然后通过soft-max得到一个特征映射F.
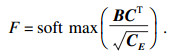 |
 | 图 2 注意力机制模块Fig.2 Attention mechanics block |
其中,
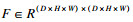
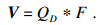 |
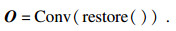 |
通道注意力模块: 每个高级特性的通道映射可以看作是一个类特定的响应, 具有不同的语义响应.可以挖掘通道映射之间的相互依赖关系来强调相互依赖的特征映射.因此, 本文建立了一个通道注意力模块来显式地建模通道之间的依赖关系.与位置注意力不同的是, 本文直接在输入图像计算通道特征, 将其进行flatten操作后, 变成(D×W×H) ×CA, 将其转置相乘后得到新的通道特征图FC∈RAC×CA, 最终将FC与原始图像相乘操作后得到KC:
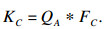 |
本文将双通道注意力模块并行连接, 并将其用于解码器部分.该模块利用空间注意力和通道注意力信息对特征图的长语义依赖关系进行建模, 有效地提高了模型的表示能力和判别能力.
2 结果与讨论2.1 数据集Iseg2017[12]来自婴儿连接项目(BCP), UNC和UMN的研究人员对500名0~5岁的正常发育儿童进行了为期四年的安全、非侵入性的多模态研究.使用脑磁共振成像(MRI)扫描包括T1和T2加权结构MRI, DTI和rsf-MRI, 并使用10名健康6个月大的婴儿的T1和T2磁共振图像.数据集共包括10个训练集和13个测试集.
在Iseg2019交叉数据集中, 测试集包含其他三个数据集的样本, 这些数据集由BCP、斯坦福大学、埃默里大学提供.对于预处理, 这些图像被重新采样到1 mm×1 mm×1 mm以消除分辨率的影响, 并使用相同的工具进行颅骨剥离和强度不均匀性校正.
Iseg2017, Iseg2019数据集由专业人员手动标注而成, 具有相当的专业性, 训练集和测试集数据也较为丰富, 通过申请获取其训练集和测试集后, 可在个人的模型上进行试验, 并且该组织也会提供所提交测试集的最终分割结果.
2.2 实验设置在实验中, Iseg2019数据集(斯坦福大学所提供)的结果远远低于另外两组, 作者发现样本的亮度和对比度都很差, 影响了最终的结果.考虑到这一点, 本文对所有的图像进行了gamma校正和对比度变换, 以使数据的影响最小: 首先将T1图像裁剪为32×32×32, 然后将随机对比度调整为4.64 ~ 4.66.作者对T2图像做了同样的处理, 不同之处在于只对T2图像进行了gamma校正, 将其调整到1.8.对T1和T2图像进行归一化处理后, 将其放入网络中, 并对训练集进行一些数据扩充操作, 如图像翻转、图像平移等.
网络参数的优化是通过Adam optimizer来完成的.初始化学习率为3.3×10-3, 每1 000次迭代设置权值衰减为2e-6.Patch-size设置为32×32×32, batch-size设置为5.本文参考了文献[13]的参数设置.通过实验证明, 其中一些参数是最佳选择.
本文的评价指标使用了DICE系数(DSC)和ASD(average symmetric surface distance).DICE是预测分割结果与Ground-truth重叠的度量.定义为
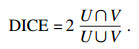 |
ASD的定义如下: R, G分别表示分割图像和金标准, S (R)和S (G)分别代表了R, G表面体素的集合, 定义S(R)到S(G)上的任意点V为V到S(G)上所有点的欧氏距离的最小值, 表示为
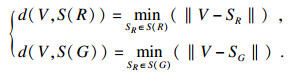 |
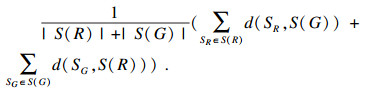 |
2.3 实验结果由于3D U-Net的优秀特性, 本文使用3D U-Net作为baseline(基线).更具体地说, 本文取消了提出的Dila-Block块, 以一个3×3×3的卷积来取代, Dila-Block块被直接删除.在模型训练过程中, 由于训练集中样本较少, 本文使用了leave-one-subject-out交叉验证来评估分割性能和无效偏差.对于每个训练过程, 本文使用一个样本作为试验的验证集, 其余9个样本作为训练集.这样就可以评估模型的有效性.
Iseg2017数据集的实验结果如表 1所示.
表 1(Table 1)
| 表 1 Iseg2017数据集的分割结果对比 Table 1 Comparison of segmentation results of Iseg2017 dataset | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
可以看出, CSF的结果明显高于WM和GM, 与baseline和其他方法相比, 本文的GM, WM结果有较大的改善, 比之前的最佳结果高出0.7 %, 而CSF的结果基本上没有较大变化.整体而言, 白质灰质的总体分割DICE结果低于脑脊液的结果, 而本文的结果在此数据集上的提高主要是基于灰质和白质的分割结果, 原因有以下两点: ①所采用的金字塔结构充分利用了图像的多尺度信息, 减少采样期间特征图变化所带来的图像损失; ②灰质白质间边界过于模糊, 导致灰质白质的分割结果相较于脑脊液相差较大, 可以适当针对边缘部分提高分割准确率.
在Iseg2019交叉数据集中, 由于有三个完全不同的数据集, 图像的灰度值和对比度有很大的不同, 图像预处理是非常必要的, 本文在将测试图像和训练图像输入网络之前进行相同的预处理.
最后的分割结果由比赛组织者进行评估.到目前为止, 还没有发表过可以比较的论文, 本文用来评价的标准是与其他参与者进行比较.截至目前, 本文的分割结果还是该挑战最优的分割结果, 队伍名称(QL111111).实验结果如表 2所示.在9个指标中, GM和WM的5个指标排名第一, 在CSF指标上,本文方法和TAO方法的差距很小, 只有0.1的差距并且相较于其他方法有比较大的领先.本文在WM的分割结果上有明显的领先优势, DSC值比第二名高1.4.在GM上领先第二名0.5, 可以看出本文的结果整体而言是比较有优势的.也证明本文所提出的模型在跨数据集分割上具有非常优异的表现.与此前的Iseg2017的分割结果相比, 不同之处在于WM在这个数据集上有更好的结果, 而CSF和GM的分割结果过低.该挑战的排名可以在以下网址查看:
表 2(Table 2)
| 表 2 Iseg2019数据集的分割结果对比 Table 2 Comparison of segmentation results of iseg2019 dataset | ||||||||||||||||||||||||||||||||||||||||||||||||||||
http://iseg2019.web.unc.edu/evaluation-results/
同时本文也将训练过程可视化.图 3为通过tensorboard可视化的训练过程.本文提出的模型可以更快地收敛损失, 在较短的时间内得到更优秀的结果.实验结果经过45 000~50 000迭代次数后得到最优模型.训练过程中, 本文不仅观察了损失函数的变化, 同时也对每个阶段的模型进行了验证.如图 4、图 5所示,在使用空间金字塔、残差网络结构和注意力机制后的分割结果从左到右分别是金标准, 训练次数达到26 200和52 000时验证集分割结果.训练次数达到26 200时, 图像已经有基础的分割轮廓, 但是很明显能看出边缘和一些狭长的勾回结构中仍然存在分割错误的情况, 而当训练次数达到52 000时, 虽然模型的分割结果已经有了很大的改进, 却仍然需要更有效地提高边缘分割的准确性, 这也是本文在已有的改进上提出注意力机制的一个原因.
图 3(Fig. 3)
 | 图 3 训练过程损失大小可视化结果Fig.3 Visual vesults of loss during training |
图 4(Fig. 4)
 | 图 4 验证集二维可视化分割结果第140切片Fig.4 Validation set 2D visual segmentation results 140-slice (a)—金标准;(b)—训练次数26 200;(c)—训练次数52 000. |
图 5(Fig. 5)
 | 图 5 验证集二维可视化分割结果第150切片Fig.5 Validation set 2D visual segmentation results 150-slice (a)—金标准;(b)—训练次数26 200;(c)—训练次数52 000. |
2.4 消融实验除了上述的对比实验之外, 本文还进行了消融实验.本文baseline的结果是10个样本的平均值.本文的CSF结果和GM结果在模型上的结果比baseline高3和2.6, WM增加了6.8.同时, 为了验证每个模块的有效性, 本文又提出如下两个模型进行实验验证:
模型1:在消融实验中, 该模型基于本文提出的模型去除自注意力模块.
模型2:从提出的模型中去掉降采样部分中的DCP模块.
本文对这两个模型和baseline的训练策略是相同的.采用交叉验证的方法, 将训练集中的9个样本作为训练集, 剩下的一个作为验证集.最后得到10个模型, 计算出实验结果的平均值.最后通过多数投票的方式得到最终实验结果, 如表 3所示.
表 3(Table 3)
| 表 3 消融实验的结果 Table 3 Results of the ablation experiments |
从表 3可以看出, 本文所提出的模型的每个模块对最终的结果都是非常有帮助的, 与baseline比有了很大的改进.更具体地说, 提出的注意力机制模块提升2.3 %, 原因是在baseline的基础上, 脑组织分割中的边缘分割更为重要, 而注意力模块因为在图像卷积过程中能够更好地对特征图的长语义依赖关系进行建模, 进一步提高边缘分割的准确率.同时, DCP模块所带来的提升达到了3.3 %, 可以说DCP模块在多尺度信息使用中的作用是不可低估的, 很大程度地降低图像卷积过程中的特征损失, 这也说明多尺度信息在脑组织分割任务中是非常重要的.图 6展示了本文在Iseg2017中最终的分割可视化结果.从左到右分别是金标准, baseline和本文的模型.上面的三张图片显示了WM在金标准、baseline和本文提出模型的结果.可以清楚地看到, 底线的边缘并不光滑, 边界外有很多部分, 而本文模型在大部分区域(白色圆圈)取得了较好的效果.通过下面三张图像, 可以看到GM的baseline在脑回结构中并不清晰.相比之下, 本文模型结果可以清晰地看到脑回结构(黑色圆圈), 这与DSC和ASD值的改善是分不开的.
图 6(Fig. 6)
 | 图 6 灰质白质分割结果Fig.6 Gray and white matter segmentation results |
2.5 实验参数的选择对结果的影响对于本文所提出的金字塔结构, 为了研究最优空洞率的选择提出了如下几个实验.通过此前的实验, 认识到逐步增大的空洞率能有效提高最终的实验结果, 但是随着特征图减小, 最后一个空洞率过大反而很难取得满意的效果.本文尝试修改文中提出的Dila-Block中最后一个空洞卷积的空洞率.
本文进行了如下几个实验:
实验1,将空洞率分别设置为1, 2, 4, 1, 并且只有最底层的DCP模块包含Dila-Block.
实验2,将空洞率分别设置为1, 2, 4, 2, 并且只有最底层的DCP模块包含Dila-Block.
实验3,将空洞率分别设置为1, 2, 4, 4, 并且只有最底层的DCP模块包含Dila-Block.
实验4,将空洞率分别设置为1, 2, 4, 1, 并且所有DCP模块都包含一个Dila-Block.
实验结果如表 4所示.此实验结果充分证明了本文所提出残差网络结合空间金字塔结果在脑组织分割任务中的有效性.并且能够看出当空洞率选择分别为1, 2, 4, 1的时候此结构具有最优效果.最终本文的分割结果如图 7所示.
表 4(Table 4)
| 表 4 不同空洞率对比实验的结果 Table 4 Results of comparison experiments with different void ratio |
图 7(Fig. 7)
 | 图 7 原始图和二维切片分割结果对比Fig.7 Comparison between original image and 2D slice segmentation results |
3 结语本文提出了一个基于金字塔结构和自注意力机制的双重聚合网络来对婴儿进行多模态MRI分割.现有的3D U-Net分割方法在降采样阶段容易造成全局信息丢失.在解码器部分, 反卷积操作在上采样过程无法恢复所有必要的信息, 降低了图像分割的准确性.本文提出的基于空间金字塔的下采样和自注意力机制最小化图像卷积过程中避免图像丢失.同时, 提出的模型在跨数据集的分割方面也有很好的表现, 说明其具有很好的泛化性能.可以说, 本文提出的模型在婴儿脑组织分割任务中表现优异.
参考文献
| [1] | Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4): 640-651. |
| [2] | Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]// International Conference on Medical Image Computing & Computer-Assisted Intervention. Munich, 2015: 234-241. |
| [3] | Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[J]. Computer Science, 2014(4): 357-361. |
| [4] | Zeng G D, Zheng G Y. Multi-stream 3D FCN with multi-scale deep supervision for multi-modality isointense infant brain MR image segmentation[J/OL]. [2020-07-23]. https://arxiv.org/format/1711.10212v2. |
| [5] | Yu F, Koltun V, Funkhouser T, et al. Dilated residual networks[C]//Computer Vision and Pattern Recognition. Phoenix, 2017: 636-644. |
| [6] | Coates A, Ng A Y, Lee H, et al. An analysis of single-layer networks in unsupervised feature learning[C]// International Conference on Artificial Intelligence and Statistics. Lauderdale, 2011: 215-223. |
| [7] | 罗会兰, 卢飞, 孔繁胜. 基于区域与深度残差网络的图像语义分割[J]. 电子与信息学报, 2019, 41(11): 2777-2786. (Luo Hui-lan, Lu Fei, Kong Fan-sheng. Image semantic segmentation based on region and depth residual network[J]. Journal of Electronics and Information, 2019, 41(11): 2777-2786. DOI:10.11999/JEIT190056) |
| [8] | Laskar Z, Kannala J. Context aware query image representation for particular object retrieval[C]//Candinavian Conference on Image Analysis. Cham, 2017: 88-99. |
| [9] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J/OL]. [2020-07-23]. https://arxiv.org/abs/1706.03762v5. |
| [10] | Chen L, Zhang H, Xiao J, et al. SCA-CNN: spatial and channel-wise attention in convolutional networks for image captioning[C]//Computer Vision and Pattern Recognition. College Park, 2017: 6298-6306. |
| [11] | Fu J, Liu J, Tian H, et al. Dual attention network for scene segmentation[C]//2019 IEEE/CVF Conference on computer Vision and Pattern Recognition. LongBeach, 2019: 19263391. |
| [12] | Wang L, Nie D, Li G, et al. Benchmark on automatic 6-month-old infant brain segmentation algorithms: the Iseg-2017 challenge[J]. IEEE Transactions on Medical Imaging, 2019, 38(9): 2219-2230. DOI:10.1109/TMI.2019.2901712 |
| [13] | Mondal A K, Dolz J, Desrosiers C. Few-shot 3D multi-modal medical image segmentation using generative adversarial learning[J/OL]. [2020-01-23]. https://arxiv.org/abs/1810.12241v1. |
| [14] | Dolz J, Gopinath K, Jing Y, et al. Hyper dense-net: a hyper-densely connected CNN for multi-modal image segmentation[J]. IEEE Transactions on Medical Imaging, 2018, 38(5): 1116-1126. |
