
 , 余春雪2, 张正健3, 汪嘉杨1
, 余春雪2, 张正健3, 汪嘉杨11. 成都信息工程大学, 资源环境学院, 成都 610225;
2. 东莞理工学院, 生态环境工程技术研究中心, 东莞 523808;
3. 中国科学院成都山地灾害与环境研究所, 成都 610041
收稿日期: 2020-05-20; 修回日期: 2020-07-10; 录用日期: 2020-07-10
基金项目: 国家重点研发计划(No.2017YFC0404506);国家自然科学基金青年基金(No.51709045);四川省社科规划项目(No.SC18B027);四川省科技厅项目(No.19JDJQ0006)
通讯作者(责任作者): 李祚泳(1944-), 男, 教授, E-mail:lizuoyong@cuit.edu.cn
余春雪, E-mail:yucx@dgut.edu.cn
摘要:网络结构和样本集复杂性是影响BP网络泛化能力的两个最重要因素.对一个给定的训练样本集,为了构造一个与样本集复杂性相匹配的网络结构,使BP网络具有最佳泛化能力,在分析BP网络的泛化能力(用检测误差E2表示)与网络结构和样本集复杂性之间关系的基础上,建立了含参数的BP网络检测误差E2与网络隐节点数H、样本的因子数n、样本数N和样本集的复相关系数R之间的一般关系表达式,并提出了用于定量描述样本集复杂性的"广义"复相关系数Rn的新概念.借助于222个复杂函数的模拟仿真实验,应用免疫进化算法,对表达式中的参数进行优化,得到参数优化后的网络检测误差E2的定量解析表达式;依据误差理论和灵敏度概念,对优化得到的最小检测误差E20的表达式进行了可靠性论证.在此基础上导出了具有最佳泛化能力的BP网络隐节点数H0与"广义"复相关系数Rn之间满足的H0-Rn反比关系式.分别用满足H0-Rn反比关系式的隐节点数和6个经验公式的隐节点数构造的BP网络用于100个模拟检测函数进行仿真实验,发现前者构造的BP网络具有最佳泛化能力(即最小检测误差)的函数个数达到76个,远远多于后者构造的BP网络具有最佳泛化能力的函数个数;还将二者构造的BP网络用于环境预测的7个具体实例,进行预测效果比较,结果表明,前者预测的相对误差绝对值的平均值和最大值小于或远小于后者的相应值.从而验证了由H0-Rn反比关系式得出的BP网络隐节点数计算公式的可行性和实用性,为具有最佳泛化能力的BP网络的结构设计指出了新途径.
关键词:BP网络泛化能力网络结构隐节点数广义复相关系数H0-Rn反比关系式预测模型
An environment prediction model based on the inverse relation of hidden nodes of BP network with the best normalization ability
LI Zuoyong1
, YU Chunxue2, ZHANG Zhengjian3, WANG Jiayang11. College of Resources and Environment, Chengdu University of Information Technology, Chengdu 610225;
2. Research Center of Ecological Environment Engineering Technology, Dongguan Institute of Technology, Dongguan 523808;
3. Institute of Mountain Hazards and Environment, Chinese Academy of Sciences, Chengdu 610041
Received 20 May 2020; received in revised from 10 July 2020; accepted 10 July 2020
Abstract: Network structure and sample set complexity are the two most important factors that affect the generalization ability of BP network. For a given training sample set, the purpose is to construct a network structure matching the given complexity of the sample set, so that the BP network has the best generalization ability. Based on the analysis of the relationship between the generalization ability of BP network (expressed by detection error E2) and the network structure and sample set complexity, the general expression between the detection error E2 of BP network with parameters and the number of hidden nodes H, the number of sample factors n, the number of samples N and the complex correlation coefficient R of sample set is established, and a new concept of "generalized" complex correlation coefficient Rn is proposed to quantitatively describe the complexity of samples set. With the help of 222 complex function simulation experiments, the parameters in the expression are optimized by using immune evolution algorithm, and the quantitative analytical expression of the network detection error E2 is obtained. According to the error theory and the concept of sensitivity, the reliability of the expression E20 of the minimum generalization error is demonstrated. On this basis, the H0-Rn inverse relation between the hidden nodes H0 of BP network and the "generalized" complex correlation coefficient Rn with the best generalization ability is derived. The BP network constructed by the number of hidden nodes satisfying H0-Rn inverse relation and the number of hidden nodes satisfying 6 empirical formulas are used in 100 simulated detection functions for simulation experiments. The number of functions with the best generalization ability (i.e. the minimum detection error) of the BP network constructed by the former reaches 76, far more than the number of functions with the best generalization ability of the BP network constructed by the latter. In addition, the BP networks constructed by the two methods were applied to 7 specific cases of environmental prediction, and compared the prediction effects, The results show that the average value and the maximum value of the absolute value of the relative error predicted by the former are less than or far less than the corresponding value of the latter. Thus, the feasibility and practicability of the calculation formula of hidden node numbers of BP network derived from H0-Rn inverse relation are verified, and a new way for the structural design of BP network with the best generalization ability is pointed out.
Keywords: BP networkgeneralization abilitynetwork structurehidden node numbergeneralized complex correlation coefficient generalizedH0-Rninverse relationprediction model
1 引言(Introduction)进入21世纪以来, 虽然以深度学习算法为代表的新型神经网络的理论和应用研究取得了长足的进展(焦李成等, 2016), 但比较而言, 传统的BP网络因其原理简单、编程简便, 尤其是具有只需三层的网络结构就可以实现以任意精度逼近任意非线性函数这一优势, 而使其在环境的分类、识别、评价和预测等方面的应用仍十分广泛(Paschalidou et al., 2011;Liu, et al., 2015;李佟等, 2016;孙宝磊等, 2017).然而BP网络也存在易陷入局部极小、参数选择困难、学习效率低、泛化能力差、易出现“过拟合”和结构设计的理论依据不足等缺陷(Funahashi, 1989).在BP网络的的诸多缺陷中, 网络的泛化能力和学习效率是衡量BP网络性能的两个主要指标.因为没有泛化能力或泛化能力差的网络没有任何理论意义, 学习效率低则降低了网络的实用价值, 因而这两个指标备受人们的关注, 但却又是难以解决的问题(魏海坤等, 2001).关于提高网络的学习效率、加速收敛的方法目前已有很多讨论(Wang et al., 2011);虽然网络初始参数和学习参数的选择、调整和所用的学习算法也会对网络的泛化能力产生影响, 但网络结构和样本集复杂性才是影响泛化能力的两个重要因素.因此, 这两个问题的解决在BP网络研究中具有重要的理论意义和实用价值.目前针对网络泛化能力、过拟合及网络结构设计的理论和方法研究已取得若干进展(胡铁松等, 2016), 例如, Setiono(1997)提出采用权重惩罚来提高泛化能力;郭海如等(2014)给出了一种基于随机GA的提高BP网络泛化能力的方法;李祚泳等(2003)确立了BP网络出现过拟合时泛化能力与学习能力之间满足的不确定关系式, 并由此不确定关系式指出为改进泛化能力的训练最佳停止方法.由于网络结构设计难度很大, 因此, 已有的研究多是一些网络结构设计的定性分析结论或选择隐节点数的经验公式(Benardos et al., 2007; Goh et el., 2008; Islam et al., 2009).经验公式不仅缺乏严格的理论依据, 不能保证构建的网络具有最佳泛化能力, 而且对同一训练样本集, 不同经验公式计算的隐节点数存在差异, 具有不确定性(焦斌等, 2013; 蔡荣辉, 2017).关于样本集的复杂性仅对由因子数和样本数引起的样本规模复杂性有所研究, 而对由样本集的数据分布和变化规律特性所确定的样本质量复杂性的定量研究, 目前在国内外尚未见报道.因此, 对于一个给定的训练样本集, 在选择适当的网络初始参数和学习参数的情况下, 如何根据样本集的复杂性构造一个具有最佳泛化能力的BP网络结构, 是一个具有重要的理论意义和实用价值的问题.这个问题的解决, 将极大地推动BP网络的理论和应用的发展.
本文在分析BP网络的泛化能力与网络结构、样本复杂性之间关系的基础上, 提出用复相关系数定量描述由样本数据分布特性和变化规律所引起的样本集复杂性, 建立了用检测误差E2表示的BP网络泛化能力与网络隐节点数H、样本因子数n、样本数N和样本集的复相关系数R之间含参数的一般关系表达式.通过222个复杂函数的模拟仿真实验, 应用免疫进化算法对表达式中参数进行优化, 得出参数优化后的解析表达式, 并对优化得到的最优泛化能力(即最小检测误差E20)的解析表达式进行可靠性论证.在提出用“广义”复相关系数Rn新概念描述包括样本规模和样本质量在内的样本集的复杂性基础上, 导出具有最佳泛化能力的BP网络隐节点数H0与样本集的“广义”复相关系数Rn之间满足的反比关系式(建立BP算法的H0-Rn关系式流程如图 1所示).文中除了模拟100个仿真测试函数, 对导出的隐节点数反比关系式和6个传统的隐节点数经验公式构建的BP预测模型进行对比检验外, 还将反比关系式与6个传统的隐节点数经验公式用于环境预测的7个具体实例, 进行模型的预测效果比较.
图 1(Fig. 1)
 |
| 图 1 BP算法的H0-Rn关系式流程图 Fig. 1H0-Rn relation flow chart of BP algorithm |
2 BP网络泛化能力表示式和最佳泛化能力的网络隐节点数满足的反比关系式(The expression of BP network generalization ability and the inverse relation of the number of hidden nodes of the network with the best generalization ability)2.1 BP网络泛化能力的一般表示式国内外****对只有一个隐层的BP网络训练的动态过程进行分析后发现, 随着网络结构复杂性增加, 用检测误差表示的泛化能力与用训练误差表示的学习能力的变化趋势分为3个阶段:①训练误差和检测误差皆单调减小;②训练误差单调减小, 检测误差变化较复杂, 但最终达到最小, 即网络泛化能力达到最佳;③训练误差单调减小, 而检测误差单调增加, 即泛化能力逐渐减弱, 出现“过拟合”现象.对于只有一个隐层的BP网络, Barron给出了样本集学习过程中用检测误差表示的总泛化能力的表示式, 具体如式(1)所示(Barron, 1994).
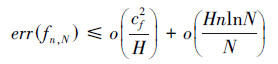 | (1) |
式(1)右端第1项称为逼近误差, 表征了样本集包含的关于未知函数的信息, 由样本集的复杂性(cf)和网络结构复杂性(H)共同决定;第2项称为估计误差, 表征了网络结构所能表示的函数集对未知函数的拟合能力, 由网络结构复杂性(H)和样本数N和因子数n决定.可见, 在训练样本集已确定的情况下, 由于因子数n、训练样本数N和样本集的复杂性cf已确定, 故随着网络结构复杂性的增加(H增大), 第1项将逐渐减小, 而第2项将逐渐增大.因此, 好的泛化能力取决于选择一个适当的隐节点数H, 使式(1)的第1项逼近误差和第2项估计误差得到协调.
根据式(1)不难发现, 样本集的复杂性cf主要体现在样本规模和样本质量两个方面.样本规模可简单理解为训练样本数N和因子数n;样本质量指样本数据反映总体分布的程度, 它与采样过程相关;训练样本的复杂性决定了训练集所包含的信息.虽然样本质量对网络的泛化能力有很大影响, 但有关样本质量对泛化能力影响的定量研究目前尚未见报道.为此, 本文提出用样本集的复相关系数R的倒数1/R表征样本的复杂程度cf, 即cf =1/R;并引入参数α、β分别替代式(1)右端的两个无穷小量o.若将检测误差下界记为E2, 则由式(1)可得网络的检测误差下界E2(式(1)取等号, 变为等式)与网络的隐节点数H、样本因子数n、训练样本数N及样本复相关系数R之间含参数的一般关系表达式, 具体如式(2)所示.
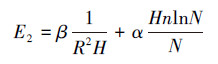 | (2) |
2.2 具有最佳泛化能力的网络隐节点数H0与样本集的广义复相关系数Rn之间的反比关系式由前述可知, 给定一个训练样本集, 存在一个与样本集复杂性相匹配的最佳隐节点数H0的网络结构, 使该结构下的网络有最佳泛化能力.即好的泛化能力取决于式(2)中右端两项的协调.于是问题转化为求E2为最小值时的最佳隐节点数H0.为此, 先将H视作正实数, 对式(2)求E2关于H的一阶偏导数, 得到式(3).
 | (3) |


 | (4) |
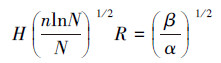 | (5) |
 | (6) |
 | (7) |
 | (8) |
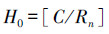 | (9) |
对于一个给定的样本集, 具有N个样本的n个自变量(因子)和因变量y之间的复相关系数定义为:
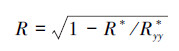 | (10) |
3 最佳泛化能力的泛化误差表达式中参数α和β的优化(Optimization of parameters α and β in generalization error expression of optimal generalization ability)3.1 构建模拟测试函数和网络结构进行仿真实验为得到适用于任何复杂训练样本集的H0-Rn反比关系式(9)中的组合优化参数C, 需要确定对大量不同训练样本集都适合的BP网络的检测误差表示式(2)中的优化参数α、β值.为此, 模拟构建了222个不同复杂函数, 用BP网络进行模拟仿真实验.为使模拟实验函数能更好地仿真现实中的各种复杂问题, 这222个函数包括由若干个典型测试函数、代数函数和超越函数(对数函数、指数函数、幂函数、各种三角函数、反三角函数、双曲函数、反双曲函数)的任意随机组合成的复杂函数.为简化计算, 且不失一般性, 本实验只构建包含1个输入层、1个隐层和1个输出节点的输出层的3层BP网络用于训练和检验.模拟函数实验过程中, BP网络的结构(输入节点数n与隐节点数H)及网络的初始权值wij设置和训练样本数N1\检验样本数N2等的变化范围如表 1所示.采用各模拟函数定义域内样本因子随机值的极差归一化值作为样本的网络因子输入值, 各模拟函数样本的计算值的极差归一化值作为样本的网络期望(目标)输出值.
表 1(Table 1)
| 表 1 BP网络的结构和参数的设置范围 Table 1 Bp network structure and parameter setting range | ||||||||||||
表 1 BP网络的结构和参数的设置范围 Table 1 Bp network structure and parameter setting range
| ||||||||||||
3.2 参数α和β的优化为了优化确定具有最佳泛化能力的检测误差表达式(2)中的参数α和β, 需要构造满足如式(11)所示的优化目标函数式.
 | (11) |
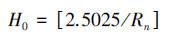 | (12) |
[ ]表示取整.由于优化得出的参数β0、α0存在一定的不确定性, 则由β0、α0计算得出的参数C0=2.5025也存在不确定性, 因此, 由2.5025/Rn计算得出的值也是不能完全确定的.故式(12)右边的[ ]既可向上取整, 也可向下取整.多数情况下, 需要用向上和向下都取整得到的隐节点数构建网络预测模型, 进行预测效果比较, 从中选择拟合和预测的综合效果较好者作为网络结构模型.
H0- Rn反比关系式(12)表明, 随着样本集复杂性增加, “广义”复相关系数Rn减小, 为使网络具有最佳泛化能力, 网络的最佳隐节点数H0应与“广义”复相关系数Rn成反比增加, 即网络结构复杂性也相应增加.
4 最小检测误差公式的可靠性分析(Reliability analysis of the formula of minimum detection error)将网络具有最佳泛化能力(即最小理论检测误差E20)时参数β0、α0、H0之间的关系式(7)和式(9)代入泛化误差E2的表达式(2)中, 可得网络的最小检测误差理论值, 见式(13)或式(14).
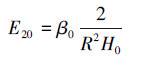 | (13) |
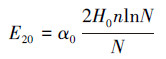 | (14) |
优化得出的参数β0和α0存在的不确定性对最小检测误差E20的影响程度可以通过对式(13)和式(14)的灵敏度分析来确定.而检测误差公式(13)或(14)的灵敏度是指网络最小检测误差E20对优化得出的参数β0和α0的不确定性(相对误差)的响应程度.通过对式(13)或式(14)的分析, 估计最小检测误差E20计算结果的偏差.根据灵敏度分析理论, 由式(13)和式(14)可得最小检测误差E20的相对误差ΔE2/E20与参数β0、α0的相对误差和灵敏度Sβ、Sα之间的关系分别如式(15)和式(16)所示.
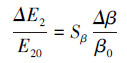 | (15) |
 | (16) |
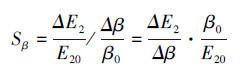 | (17) |
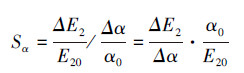 | (18) |
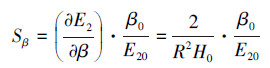 | (19) |
 | (20) |
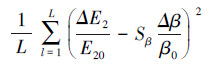

5 模型的验证(Model validation)5.1 BP网络隐节点数的6个经验公式相关文献(焦斌等, 2013)给出了BP网络隐节点数计算的若干经验公式:
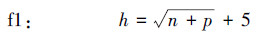 | (21) |
 | (22) |
 | (23) |
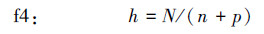 | (24) |
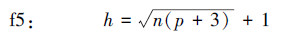 | (25) |
 | (26) |
5.2 不同隐节点数计算公式的效果比较与分析为了验证具有最佳泛化能力的BP网络的隐节点数H0与训练样本的广义复相关系数Rn之间的H0-Rn反比关系式的正确性和实用性, 重新任意模拟了100个检测函数用于验证.为了有可比性, 对同一个模拟检测函数, 网络的初始权值在[-1, 1]区间内随机选取情况下, 都用生成的同一组训练样本, 分别对由6个隐节点数经验公式(21)~(26)和H0-Rn反比关系式(12)确定的隐节点数构造的网络进行训练, 并用同一组检测样本进行效果检验.此100个检测函数的变量个数n(即网络的输入节点数)、训练样本数N1、检测样本数N2、总样本数N(N= N1+ N2)、计算得到函数的复相关系数R和广义复相关系数Rn、由H0-Rn反比关系式(12)计算得到的理论最佳隐节点数H0及网络具有最佳泛化能力时的实际最小检测误差E2及其相应的实际最佳隐节点数Hm, 如表 2所示.在100个模拟检测函数中, 用H0-Rn关系式(12)和用6个经验公式(21)~(26)计算得到的不同隐节点数构造的网络, 能达到实际最小检测误差E2(即具有最佳泛化能力)的不同网络结构, 如表 2的第12列所示, 其中, fc代表用 H0-Rn关系式(12)计算得到的隐节点数构建的网络, f1~f6分别代表用6个经验公式(21)~(26)计算得到的隐节点数构建的网络.用不同隐节点数公式计算得到隐节点数构造的网络在100个模拟检测函数中达到实际最小泛化误差的函数个数如表 3所示.
表 2(Table 2)
| 表 2 100个检测函数的有关参数及理论最佳隐节点数H0和网络具有实际最小检测误差E2时的最佳隐节点数Hm Table 2 Relevant parameters of 100 detection functions and theoretical optimal hidden node H0 and optimal hidden node Hm when the network has the actual minimum detection error E2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
表 2 100个检测函数的有关参数及理论最佳隐节点数H0和网络具有实际最小检测误差E2时的最佳隐节点数Hm Table 2 Relevant parameters of 100 detection functions and theoretical optimal hidden node H0 and optimal hidden node Hm when the network has the actual minimum detection error E2
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
表 3(Table 3)
| 表 3 不同隐节点数的网络在100个模拟测试函数中具有最小检测误差的函数个数 Table 3 Numbers of functions with minimum detection error in 100 simulated test functions for networks with different hidden node numbers | ||||||||||||||||
表 3 不同隐节点数的网络在100个模拟测试函数中具有最小检测误差的函数个数 Table 3 Numbers of functions with minimum detection error in 100 simulated test functions for networks with different hidden node numbers
| ||||||||||||||||
从表 3可见, 在100个测试函数中, 以H0-Rn反比关系式(12)计算得到的隐节点数构建的网络, 能达到最小检测误差的函数个数有76个, 远远大于用6个经验公式(21)~(26)计算得到的隐节点数构建的网络所能达到的最小检测误差的函数个数, 从而表明H0-Rn反比关系式(12)的可行性和实用性.
6 H0-Rn反比关系式用于环境预测建模的实例验证(Example verification of H0-Rn inverse relationship used in environmental prediction modeling)为了验证隐节点数反比关系式H0-Rn用于实际问题的可行性和实用性, 对洛河BOD5(李世玲, 2005)、青弋江CODCr(李俊等, 2008)、南昌市降水酸度(pH)(徐源蔚等, 2015)、郭庄泉流量(Q)(高波, 2002)、滦河地下水位(曹邦兴, 2010)、新疆伊犁河雅马渡站径流(崔东文等, 2016)和某水文站径流量(阎俊爱等, 2003)等7个环境的具体实例, 分别用H0-Rn反比关系式(12)和6个隐节点数经验公式(21)~(26)计算得到的不同隐节点数, 构建BP网络的预测模型.7个实例的因子和预测变量的原始数据分别见相应文献, 其因子和预测变量的归一化一般变换式如式(27)所示.
 | (27) |
7个实例的因子Xj和预测变量Y的归一化变换式(27)中xjM和xjm的设置如表 4所示.为了有可比性, 对同一个实例, 隐节点数的H0-Rn反比关系式和6个经验公式的因子和预测变量的归一化变换式设置为相同, 7个实例的因子数n、训练样本数N1和预测(检验)样本数N2如表 5所示.根据各个实例训练样本因子和预测变量的原始数据, 由式(10)和式(6), 计算得出7个实例的广义复相关系数Rn, 具体见表 5;再由式(12)和6个隐节点数经验公式(21)~(26), 计算得到7个实例建模的隐节点数, 如表 6所示.
表 4(Table 4)
| 表 4 7个实例的因子Xj和预测变量Y归一化公式中xjM和xjm的设置及优化目标函数值minQ Table 4 The setting of xjM and xjm in the normalization formula of factors Xj and prediction variables Y of 7 examples and the optimization objective function value minQ | ||||||||||||||||||||||||||||||||||||||
表 4 7个实例的因子Xj和预测变量Y归一化公式中xjM和xjm的设置及优化目标函数值minQ Table 4 The setting of xjM and xjm in the normalization formula of factors Xj and prediction variables Y of 7 examples and the optimization objective function value minQ
| ||||||||||||||||||||||||||||||||||||||
表 5(Table 5)
| 表 5 7个实例的影响因子数n、训练样本数N1、检验样本数N2和广义复相关系数Rn Table 5 Number of influence factors n, number of training samples N1, number of test samples N2 and generalized complex correlation coefficient Rn of 7 examples | ||||||||||||||||||||||||||||||||||||||||
表 5 7个实例的影响因子数n、训练样本数N1、检验样本数N2和广义复相关系数Rn Table 5 Number of influence factors n, number of training samples N1, number of test samples N2 and generalized complex correlation coefficient Rn of 7 examples
| ||||||||||||||||||||||||||||||||||||||||
表 6(Table 6)
| 表 6 用H0-Rn反比律公式和6个经验公式计算得到不同实例的BP网络隐节点数 Table 6 The number of hidden nodes in different examples of BP network is calculated by H0-Rn inverse law formula and 6 empirical formulas | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
表 6 用H0-Rn反比律公式和6个经验公式计算得到不同实例的BP网络隐节点数 Table 6 The number of hidden nodes in different examples of BP network is calculated by H0-Rn inverse law formula and 6 empirical formulas
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
对每个实例, 分别构建如表 6所示的不同隐节点数的BP网络预测模型;初始权值wij在[-1, 1]和阈值在(-1, 1)之间随机赋予, 设置优化目标函数式, 如式(28)所示.
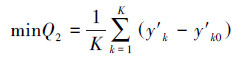 | (28) |
表 7(Table 7)
| 表 7 不同结构的BP网络对各实例预测样本预测的相对误差ri比较 Table 7 Comparison of relative error ri of BP network with different structures for each sample prediction | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
表 7 不同结构的BP网络对各实例预测样本预测的相对误差ri比较 Table 7 Comparison of relative error ri of BP network with different structures for each sample prediction
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
图 2(Fig. 2)
 |
| 图 2 不同结构的BP网络对各实例预测的最大、最小和平均相对误差比较 Fig. 2Comparison of the maximum, minimum and average relative errors of BP networks with different structures for each instance |
从图 2可见, 7个预测实例中, 除实例2用H0-Rn构建的网络预测的相对误差绝对值的均值(5.82%)和最大值(9.01%)分别略大于用f4经验公式(24)构建的网络预测的相对误差绝对值的均值(5.36%)和最大值(7.55%)外, 其余用H0-Rn关系式(12)构建的模型预测的相对误差绝对值的均值和最大值, 皆小于或远小于(个别实例等同于经验公式f2)用6个隐节点数经验公式构建的模型预测的相对误差绝对值的均值和最大值.
7 分析与比较(Analysis and comparison)① 网络泛化能力(E2)下界的定量关系表达式(2)揭示了网络结构复杂性(H)与样本集复杂性(复相关系数R)两个重要因素对网络泛化能力的影响.并依据误差理论和灵敏度概念, 对最佳泛化能力时的表达式(2)进行了可靠性论证, 从而表明由式(2)导出的最佳隐节点数的反比关系式(12)的可靠性和合理性.
② 由于用隐节点数经验公式(21)~(26)构造的网络只与因子数n、样本数N、输出节点数p有关, 没有考虑训练样本质量(数据分布特征和变化规律)的复杂性对网络泛化能力的影响;而用隐节点数H0-Rn反比关系式(12)构造的网络, 其中的广义复相关系数Rn包含了用因子数n和样本数N表示的样本集规模的复杂性和用复相关系数R表示的样本集质量的复杂性二者对泛化能力的影响, 因而构造的网络的复杂性与样本集的复杂性更相匹配.
③ 用隐节点数H0-Rn反比关系式(12)构建的网络用于100个模拟仿真函数实验和环境预测的7个具体实例, 其预测效果皆优于或远优于用6个隐节点数经验公式构建的网络的预测效果, 验证了隐节点数H0-Rn反比关系式(12)的可行性和实用性.
④ 若存在多个因变量对应于同一组影响因子, 可分别将每个因变量与该组影响因子建模, 则同样可用隐节点数H0-Rn反比关系式(12)计算的隐节点数构建网络预测模型.
8 结论(Conclusions)本文获得的主要结果为:在分析网络结构和样本集的复杂性对BP网络泛化能力影响的基础上, 提出用广义复相关系数Rn新概念来定量描述包括样本集规模和样本质量在内的样本集的复杂性;提出用含参数的检测误差E2表示BP网络的泛化能力的定量关系表达式;基于具有最佳泛化能力的检测误差E2达到最小时的逼近误差与估计误差相协调, 导出BP网络隐节点数H与样本的复杂性R之间满足的H0-Rn反比关系式.与隐节点数经验公式相比, 用H0-Rn反比关系式确定隐节点数有严格的理论依据, 并具有可靠性;与确定隐节点数的试凑法相比, 省时、快速、简单.
BP网络隐节点数H0-Rn反比关系式的重要意义在于:对于包括环境系统在内的任意系统的一个给定的训练样本集, 在选择适当的网络初始参数和学习参数的情况下, 为如何构造一个与训练样本集的复杂性相匹配的最佳隐节点数的网络结构, 使BP网络具有最佳泛化能力这一基本问题的解决开辟了新途径.由于该方法具有普适性, 因而具有重要的理论意义和实用价值.
H0-Rn反比关系式的局限为:该公式是网络初始参数被限定在[-1, 1]情况下导出的, 若网络初始参数选择在其他不同区间, 对具有最佳泛化能力时的H0-Rn反比关系式中的组合参数C的优化结果是否有影响, 还有待于进一步深入探索.
参考文献
| Barron A R. 1994. Approximation and estimation bounds for artificial neural networks[J]. Machine Learning, 14: 115-133. |
| Benardos P G, Vosniakos G C. 2007. Optimzing feedforword artificial neural network architecture[J]. Engineering Application of Artificial Intelligence, 20(3): 365-382. DOI:10.1016/j.engappai.2006.06.005 |
| 蔡荣辉, 崔雨轩, 薛培静. 2017. 三层BP神经网络隐层节点数确定方法探究综述[J]. 电脑与信息技术, 25(5): 29-33. DOI:10.3969/j.issn.1005-1228.2017.05.009 |
| 曹邦兴. 2010. 基于蚁群径向基函数网络的地下水预测模型[J]. 计算机工程与应用, 46(2): 224-226. DOI:10.3778/j.issn.1002-8331.2010.02.066 |
| 崔东文, 金波. 2016. 鸟群算法-投影寻踪回归模型在多元变量年径流预测中的应用[J]. 人民珠江, 37(11): 26-30. DOI:10.3969/j.issn.1001-9235.2016.11.006 |
| Funahashi K I. 1989. On the approximate realization of continuous mappings by neural networks[J]. Neural Networks, 2(3): 183-192. DOI:10.1016/0893-6080(89)90003-8 |
| 高波. 2002. 郭庄泉流量衰减原因分析及对策[J]. 水资源保护, (1): 64-65. DOI:10.3969/j.issn.1004-6933.2002.01.020 |
| Goh C K, Teoh L J, Tan K C. 2008. Hybrid muliobjective evolutionary design for artificial neural networks[J]. IEEE Trans on Neural Network, 19(9): 1531-1547. DOI:10.1109/TNN.2008.2000444 |
| 郭淳.2010.BP神经网络结构设计及其在水环境中的应用[D].成都: 成都信息工程学院.31-40 |
| 郭海如, 李志敏, 万兴, 等. 2014. 一种基于随机GA的提高BP网络泛化能力的方法[J]. 计算机技术与发展, 24(1): 105-108. |
| 胡铁松, 严铭, 赵萌. 2016. 基于领域知识的神经网络泛化性能研究进展[J]. 武汉大学学报(工学版), 49(3): 321-328. |
| Islam M M, Sattar M A, Amin F, et al. 2009. A new adaptive merging and growing algorithm for designing artificial neural theory networks[J]. IEEE Trans on Systems, Man and Cybernetics Part B:Cybernetics, 39(3): 705-718. DOI:10.1109/TSMCB.2008.2008724 |
| 焦斌, 叶明星. 2013. BP神经网络隐层单元数确定方法[J]. 上海电机学院学报, 16(3): 113-116. DOI:10.3969/j.issn.2095-0020.2013.03.002 |
| 焦李成, 杨淑媛, 刘芳, 等. 2016. 神经网络七十年:回顾与展望[J]. 计算机学报, 39(8): 1697-1716. |
| 李峻, 孙世群. 2008. 基于BP网络模型的青弋江水质预测研究[J]. 安徽工程科技学院学报(自然科学版), 23(2): 23-26. |
| 李世玲. 2005. 基于投影寻踪和遗传算法的一种非线性系统建模方法[J]. 系统工程理论与实践, 25(4): 22-28. DOI:10.3321/j.issn:1000-6788.2005.04.004 |
| 李祚泳, 彭荔红. 2003. BP网络学习能力与泛化能力满足的不确定关系式[J]. 中国科学(E辑), 33(10): 887-895. |
| 李佟, 李军. 2016. 基于BP神经网络与马尔可夫链的污水处理厂脱氮效果模拟预测[J]. 环境科学学报, 36(2): 576-581. |
| Liu Y H, Zhu Q, Yao D, et el. 2015. Forecasting urban air quality via a back-propagation neural networks and a selection sample rule[J]. Atmosphere, 6(7): 891-907. DOI:10.3390/atmos6070891 |
| Paschalidou A K, Karaktisios S, Kleanthous S, et el. 2011. Forecasting hourly PM10 concentration in Cyprus through artificial neural networks and multiple regression models:implications to local environmental management[J]. Environmental Science and Pollution Research, 18(2): 316-327. DOI:10.1007/s11356-010-0375-2 |
| Setiono R. 1997. A penalty-function approach for pruning feedforward neural networks[J]. Neural Computation, 9(1): 185-204. DOI:10.1162/neco.1997.9.1.185 |
| 孙宝磊, 孙暠, 张朝能, 等. 2017. 基于BP神经网络的大气污染物浓度预测[J]. 环境科学学报, 37(5): 1864-1871. |
| Wang J, Wu W, Zurada J M. 2011. Deterministic convergence of conjugate gradient method for feedforward neural networks[J]. Neurocomputing, 74(14/15): 2368-2376. |
| 魏海坤, 徐嗣鑫, 宋文忠. 2001. 神经网络的泛化理论和泛化方法[J]. 自动化学报, 27(6): 806-815. |
| 徐源蔚, 李祚泳, 汪嘉杨. 2015. 基于集对分析的降水酸度及水质相似预测模型研究[J]. 环境污染与防治, 37(2): 59-62, 88. |
| 阎俊爱, 钟登华. 2003. 基于遗传算法的神经网络优化预测模型及其在年径流预报中的应用[J]. 水利水电技术, 34(6): 1-4, 67. |
