 ,1, 毕重科,1,*, 黄元琪,1, 邓亮,2, 王岳青,2, 王昉,2
,1, 毕重科,1,*, 黄元琪,1, 邓亮,2, 王岳青,2, 王昉,2Virtual Viewpoint Based Interactive In-situ Visualization of Large-Scale Simulation
SHI Xiaolin,1, BI Chongke,1,*, HUANG Yuanqi,1, DENG Liang,2, WANG Yueqing,2, WANG Fang,2通讯作者: *毕重科(E-mail:bichongke@tju.edu.cn)
收稿日期:2021-06-10
| 基金资助: |
Received:2021-06-10
作者简介 About authors

石晓霖,天津大学智能与计算学部,硕士研究生,主要研究方向为科学可视化。
本文主要承担算法实现和论文修改工作。
SHI Xiaolin is currently a master's student in the College of Intelligence and Computing at Tianjin University, China. His research field includes scientific visualization.
In this paper, he is mainly responsible for algorithms implemen-tation and paper revision.
E-mail:

毕重科,天津大学智能与计算学部,副教授,主要研究科学可视化和高性能计算。
本文主要承担论文总体框架,并指导基于特征区域的三维重建方法的实现。
BI Chongke is currently an associate professor in the College of Intelligence and Computing at Tian-jin University, China. His research interests include scientific visualization and high performance computing.
In this paper, he is responsible for the design for the framework of the paper; and he is the director for the design and implemen-tation of the 3D reconstruction method.
E-mail:

黄元琪,天津大学智能与计算学部,硕士,主要研究方向为科学可视化和高性能计算。
本文主要承担文献调研和实验。
HUANG Yuanqi received his master's degree from the College of Intelligence and Computing at Tianjin University, China. His research inter-ests include scientific visualization and high performance com-puting.
In this paper, he is mainly responsible for the survey and experimental evaluation.
E-mail:

邓亮,中国空气动力研究与发展中心计算空气动力研究所,助理研究员,主要研究方向为高性能计算和计算流体力学。
本文主要承担指导原位可视化框架的实现。
DENG Liang is currently an assistant researcher of Computational Aerodynamics Institute, China Aerodynamics Research and Development Center. His research interests include high performance computing and CFD.
In this paper, he is the director for design and implementation of the in-situ visualization framework.
E-mail:

王岳青,中国空气动力研究与发展中心计算空气动力研究所,助理研究员,主要研究方向为高性能计算和计算流体力学。
本文主要承担指导虚拟视点合成方法的实现。
WANG Yueqing is currently an assistant researcher of Comput-ational Aerodynamics Institute, China Aerodynamics Research and Development Center. His research interests include high performance computing and CFD.
In this paper, he is the director for design and implementation of the virtual viewpoint synthesis method.
E-mail:

王昉,中国空气动力研究与发展中心计算空气动力研究所,高级工程师,主要研究方向为高性能计算和计算流体力学。
本文主要承担指导基于特征点的图像拼接方法的实现。
WANG Fang is currently a senior engineer of Computational Aerodynamics Institute, China Aerodyna-mics Research and Development Center. His research interests include high performance computing and CFD.
In this paper, he is the director for design and implementation of the image stitching method.
E-mail:

摘要
【目的】原位可视化是解决大规模数值模拟结果数据难以输出到磁盘进行后处理可视化的有效途径,但是当前的原位可视化主要是为专家提供浏览模式,难以进行交互式探索。所以研究原位可视化的交互技术对帮助专家分析数值模拟结果具有重要意义。【方法】本文提出了一种基于虚拟视点的可交互式原位可视化方法。为了解决原位可视化图像采样不全的问题,我们设计了基于深度图的虚拟视点合成方法,补充了用于三维重建的虚拟视点图像。然后为了展示数值模拟结果的整体特征,将生成的虚拟视点图像和原始图像进行图像拼接。最后对拼接而成的完整图像进行三维重建生成了可供交互的模型,解决了原位可视化图像难以帮助专家在空间上交互的问题。【结果】我们使用了二维和三维等不同数值模拟生成的原位可视化图像进行实验验证,证明了本文提出的可交互式原位可视化方法的有效性。【局限】图像处理技术在不断发展,未来希望对原位可视化数据与图像处理的交互式结合进行更多的探索。【结论】本文设计了一种基于虚拟视点的可交互式原位可视化方法,可以有效地帮助专家准实时观察和分析大规模数值模拟所有中间结果的细节。
关键词:
Abstract
[Objective] In-situ visualization is an effective way to solve the problem of outputting large-scale numerical simulation results to the hard disk for post-processing visualization. However, the current in-situ visualization methods mainly provide browsing mode for experts, which fails to conduct interactive exploration. Therefore, the study of interactive technology for in-situ visualization is essential for helping experts in analyzing the results of numerical simulations. [Methods] We present an interactive in-situ visualization method based on virtual viewpoint to help experts visually explore numerical simulations. Firstly, in order to resolve the problem of incomplete sampling of in-situ visualization images, a virtual viewpoint synthesis method is designed to supplement virtual viewpoint images for 3D reconstruction. Then, based on raw images and the generated virtual viewpoint images, an image stitching method is proposed to show the overall characteristics of in-situ visualization images. Finally, the interactive model can be generated through 3D reconstruction from the stitched images. [Results] In order to demonstrate the effectiveness of the proposed interactive in-situ model, several different numerical simulations are carried out. As a result, the generated in-situ visualization results can be interactively explored by domain scientists. [Limitations] Because that the image processing technology is constantly evolving, we hope to conduct more explorations on combination of in-situ visualization image data and interactive image processing in the future. [Conclusions] In this paper, a virtual viewpoint-based interactive in-situ visualization method is proposed. It can successfully help experts to interactively explore the intermediate output data of large-scale simulation.
Keywords:
PDF (10450KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
石晓霖, 毕重科, 黄元琪, 邓亮, 王岳青, 王昉. 基于虚拟视点的大规模数值模拟的可交互式原位可视化[J]. 数据与计算发展前沿, 2021, 3(4): 30-43 doi:10.11871/jfdc.issn.2096-742X.2021.04.003
SHI Xiaolin, BI Chongke, HUANG Yuanqi, DENG Liang, WANG Yueqing, WANG Fang.
引言
近年来,随着超级计算机的快速发展,数值模拟技术取得重大突破,而科学可视化是帮助专家分析理解数值模拟结果的有效方法[1]。传统的科学可视化普遍采用后处理模式,即先将数值模拟结果保存到磁盘,然后从磁盘中读取数据进行可视化处理[2]。但是随着数值模拟问题的规模不断增长,由于磁盘I/O性能有限,大部分中间数据无法输出至外存进行后处理可视化,只能被丢掉[3]。原位可视化是指在同一超算系统上,数值模拟与可视化处理紧密结合,对模拟结果数据在内存原来的位置(原位)直接进行可视化[4],可以更多地利用数值模拟的中间数据。原位可视化满足了专家对大规模数值模拟结果的可视分析需求,但是当前的原位可视化主要是为专家提供浏览模式,即将原位生成的图像保存下来,然后提供给专家进行查看。但是这种模式无法满足专家的交互需求。具体来说,专家只能进行图像数据的检索、查看等操作,无法进行三维交互等深层次的探索。
针对原位可视化的交互问题,本文提出了一种基于虚拟视点的可交互式原位可视化方法。我们设计使用了针对性的图像处理技术,使专家可以对原位可视化生成的图像做进一步的处理,从而满足专家对数值模拟结果数据进行交互式探索和分析的需求。大规模数值模拟在原位可视化时通常只对有限视点进行采样生成可视化图像,我们通过虚拟视点合成的方法生成了虚拟视点图像,有效地解决了这一问题。在进行原位可视化的时候一些图像数据由于采样距离太近,视角不足以覆盖整个数据范围,专家无法通过单一图像获得完整的数据信息,我们利用虚拟视点图像进行图像拼接生成完整图像,弥补了这一不足。原位可视化将模拟结果以二维图像的形式输出,无法为专家提供三维特征的交互式探索,使用拼接后的完整图像进行三维重建可以生成交互模型,从而满足专家需求。最后,为了验证方法的有效性,本文设计了一种混合模式的原位可视化框架,还提供了不同数值模拟语言的可视化接口。
本文的贡献主要有以下几个方面:
(1)提出了虚拟视点合成的方法,生成了可供交互的虚拟视点图像,解决了利用原位可视化图像进行三维重建时缺少视点图像的问题。
(2)设计了图像拼接的方法将多个视点的细节图像进行还原,使专家既可以查看原始细节图像,又能进行拼接并观察完整图像。
(3)提出了基于视点图像进行三维重建的方法,生成了空间模型,使得专家可以交互式地对空间特征进行探索。
后文组织如下:第1章节讨论一些相关工作;第2、3、4章节详细讨论我们结合图像处理的相关技术对原位可视化生成的图像进行交互式处理的方法;第5章节在设计实现原位可视化框架的基础上对本文提出的交互方法进行实验验证;第6章节对本文进行总结。
1 相关工作
原位可视化是指在同一高性能计算系统上对数值模拟计算的结果数据在原位直接进行可视化处理的过程。在这个过程中,模拟计算与可视化处理紧密结合在一起,只需要保存原位生成的图像等数据,从而有效地减少了数据传输产生的系统资源开销,提高了可视化的效率[4]。在原位可视化的交互研究中,Kageyama等[5]提出了一种对批处理模拟作业产生的原位可视化图像进行分析的方法,将原位可视化生成的图像序列压缩成视频文件,然后使用特定的视频播放器对其进行分析,用户可以通过更换视角等方式从视频数据集中选择适当的图像序列进行查看。Ahrens等[6]给用户提供图形界面预先设定可视化操作、摄像机参数等,最后生成可视化图像并存入数据库,该方法将原位数据参数与图像进行关联,组建起了以时间、空间、可视化操作和数据参数为索引的,支持查询、组合以及一些可视分析手段的图像数据库。上述方法只需保存少量数据,有效地降低了数据规模,同时生成图像使用的并行绘制对数值模拟计算影响很小。但是它们仅仅提供了可视化内容的检索与查看,没有更多交互内容。陈呈等[7]实现的NNW-TopViz流场可视分析系统基于头戴式显示设备和手势传感器构建了沉浸式虚拟显示与交互平台,实现了手势交互和眼球凝视两种交互方法,它利用了外部设备进行可视化交互。本文对可视化图像本身进行研究,在原位可视化图像数据集的基础上使用图像处理的相关技术,为用户提供了深层次的交互。数字图像处理是指通过各种算法对图像数据进行处理的过程,图像处理将极大地改变未来的人机交互。近年来图像处理已经在各个领域得到广泛应用,并且产生了许多实用的相关技术。虚拟视点合成是指利用已有视点图像合成虚拟视点图像的过程,在基于图像的虚拟视点合成算法中[8],基于深度图的算法[9]由于可任意渲染视点和低带宽消耗成为交互式3D视频系统的主要方法[10]。大规模数值模拟单一时间步产生的数据量可达PB 级,在原位生成可视化图像时通常进行视点采样然后保存有限视点的图像,而虚拟视点合成的方法可以有效地解决这一问题。图像拼接技术是指将两个或两个以上场景相同且部分重叠的图像组成一个大的、完整的图像,图像拼接的关键是找出两幅图像重叠的位置,然后确定两幅图像之间的变换关系[11]。Lowe[12]提出了一个特征点匹配算法—SIFT,SIFT以及它的改进算法成功应用于图像拼接,基于特征点匹配的图像拼接方法具有特征提取和特征匹配的双重优势,效果优良。将基于SIFT的图像拼接方法应用于原位可视化,解决了在某些数值模拟可视化时生成的图像仅包含部分内容的问题,让专家可以动态地选择相应的不完整重叠图像进行拼接,然后观察整体特征。基于图像的三维重建是从一幅或多幅二维图像中推断出物体和场景的三维几何形状和结构[13]。以立体为基础的技术是基于图像进行三维重建的有效方法,它要求在从略微不同的视角捕捉到的图像之间匹配特征,然后使用三角测量原理来恢复图像像素的3D坐标,最后生成3D模型。对于原位可视化的交互而言,该方法过程简洁,易于操作,有效地还原了原位可视化图像的空间特征,为专家提供了更进一步的交互式探索。
最后,为了验证本文原位可视化图像数据集交互方法的有效性,我们设计实现了混合模式的原位可视化框架。原位可视化框架分为紧耦合模式、松耦合模式以及混合模式[14]。紧耦合模式在很多可视化应用集成的插件中被实现,如VisIt的LibSim[15],Paraview的Catalyst[16]等,这些插件可以被数值模拟应用调用并生成可视化数据结构,如VTK数据,然后使用可视化应用本身进行交互。紧耦合框架存在内存竞争、可视化时间阻塞模拟进程运行等问题。松耦合模式完成了模拟应用与可视化应用的解耦合,使它们可以异步运行。但是随着模拟数据规模的扩大,I/O开销和时间延迟难以避免。混合原位可视化方法由松耦合模式发展而来,它将部分计算量不大的工作在模拟节点上完成, 数据处理后转移到其他节点异步进行可视化处理[2]。它通常会使用降维和聚类等方式降低模拟数据量,比如分析专家知识和先验数据进行机器学习聚类等[17,18]。本文提出的原位可视化方法属于混合模式,使用图像作为中间数据进行下一步交互操作,同时还提供了不同数值模拟语言的可视化接口。
2 基于深度图的虚拟视点合成
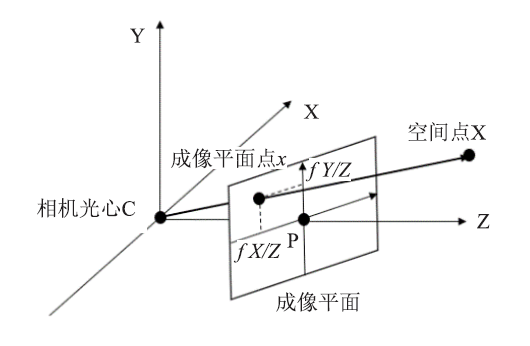
图像序列的一种生成模式是在自定义相机位置下,相机朝向数据中心,确定正方向后,以中心为球心沿经纬方向采样,这是图像数据库普遍的生成方式。原位可视化可以采用该方式生成图像数据集,专家可以直接查看图像,而采用虚拟视点合成的方法可以填补两个相邻图像间的空白。基于深度图像的三维变换能得到其周围的虚拟视点:把Z-Buffer的值映射到0-255的灰度区间内可以得到深度图,用深度值和对应视点相机外参矩阵,可以获得原始视点到虚拟视点的变换矩阵,通过这个变换矩阵进行三维变换操作,能得到所需的虚拟视点图像。本文实现了相关方法并针对与原位可视化的结合做了针对性处理。本文方法涉及到世界坐标系、相机坐标系和图像坐标系。世界坐标系是为了确定相机位置的基础坐标系,描述的是真实空间中的点;相机坐标系是为了从相机的角度描述物体的位置而建立,通过平移和旋转可从世界坐标系映射为相机坐标系;图像坐标系则是通过相机成像之后建立的坐标系,从相机坐标系到图像坐标系的转换是3D到2D的转换,属于透视投影关系。方法首先需要根据相机参数得到一个相机矩阵,相机矩阵是世界坐标下点到成像平面点的对应关系。如图1所示,一个确定的相机中心C和焦距f会依照相似关系把空间中某一点(X, Y, Z)映射到图像坐标系下($U=x*\frac{Z}{f}, v=Y*\frac{Z}{f}$)的位置上,若世界坐标下点X用(X, Y, Z, 1)T表示, 图像点x表示成3维矢量;P表示3*4相机投影矩阵,上式记为:x=PX;可视化相机默认设置窗口中心的坐标为(0, 0),也就是将图像中心始终定位在焦点位置,因此可以不必考虑投影时的偏移问题。
图1
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1相机坐标系到图像坐标系映射
Fig.1Mapping from camera coordinate system to image coordinate system
图1说明了一个位置在世界坐标系原点的相机如何进行三维空间点到二维成像平面点的变化映射。对于自定义的相机位置,需要确定另一个矩阵来完成世界坐标系到相机坐标系的位置转化,然后将相机坐标系映射为图像坐标系。世界坐标系中的点Xw,对应相机坐标系点$X_{c}=\left[\begin{array}{ll}R & t \\ 0 & 1\end{array}\right] * X_{w}$,t表示相机中心相对于世界坐标系中心的平移变换,R是一个3*3的旋转矩阵,用于计算相机坐标系的方位。
可视化相机可以通过预设相机参数推导旋转矩阵R和平移矩阵t,预设参数一般包括相机位置、相机朝向点以及相机正方向。这些可以确定一个视角变换矩阵Vt,用来将顶点由相机坐标系转换到世界坐标系。使用可视化相机可以访问到这个矩阵并直接输出,或者通过计算相机原点位移以及相机正方向相对坐标轴正方向的旋转,也可以得到。那么相机的外参矩阵就是该矩阵的逆矩阵。由此,可以得到任意视角的旋转矩阵R和平移矩阵t。
从已有视点到所需虚拟视点的三维变换首先需要由已知视点的图像结合深度图像计算出每一个像素点对应的世界坐标。假设某点的图像坐标系坐标为p=(u, v, 1)T,该点的深度值为λ,世界坐标系对应点坐标为pw=(Xw, Yw, Zw, 1)T,那么可得:
其中K代表内参矩阵,计算求解可得到:
公式(2)可以计算每一个图像点在世界坐标系的坐标,得到这些坐标集合后,使用同样的三维成像方法即可得到它们在虚拟视点下的像素坐标。当多个点映射到同一个虚拟视点像素坐标下时,可以通过计算这些点与相机中心的距离盘点应当映射哪一个。
以上方案合成的虚拟视点存在两个问题:(1)某些图像像素位置可能会找不到对应的点而产生空洞;(2)某些位置的点在虚拟视点下应当被遮挡但是遮挡点在原视点内不存在造成错误显示。一般来说,这些问题会导致将虚拟视点朝着固定方向移动会在成像的一侧产生伪影或空洞,在只有单一视角的情况下,可以使用反向映射方法解决这个问题:由合成的虚拟视点深度图得到所需空间坐标点,再求得所需的真实坐标点,具体操作细节及结果可以参考实验结果5.2部分。针对原位可视化生成的图像数据集,整个处理流程简洁有效地生成了新视点图像。专家利用该方法进行交互,可以动态合成虚拟视点并观察,更进一步理解数值模拟结果数据。
3 基于特征点的图像拼接
在原位可视化时一些图像数据由于采样距离太近,视角不足以覆盖整个数据范围。对于这种情况,可以使用基于特征点匹配的图像处理方案进行图像交互。在真实场景中,这种方法需要使用双目视点图像进行拼接。在模拟数据生成的可视化图像中,可以使用同一视点附近的同轴等焦距的图像进行替代。使用特征点完成图像拼接的原理是通过特征点计算两幅图像的变换关系,然后通过变换矩阵得到左右视点在同一视角下的结果。特征点检测方法包括特征寻找以及特征点匹配。通过匹配点的像素坐标计算出变换矩阵后将图像结果进行拼接并融合。这种方法能够通过一系列图像快速得到全景图像,适用于在较小尺度对可视化结果进行观察的图像序列或切片图等。
具体操作时,首先使用特征点匹配方法寻找图像上的对应匹配点,因为进行图像拼接所需的匹配特征点数较少,只需要精确匹配特征点对获取左右视点的变换矩阵,所以可以使用SURF算法获取匹配点集[19],并使用RANSAC算法进一步筛选可靠匹配并计算两个成像平面之间的单应矩阵[20]。RANSAC 算法通过随机选取至少4对匹配点计算出对应的单应矩阵,然后使用这个矩阵计算其他匹配点正确匹配数,多次迭代选取正确匹配数最多的匹配点集作为下一步使用点集。将匹配点集划分为随机i个点的子集,已知对应匹配点在两张图像上的坐标为(xi, yi)和(x'i, y'i),两张图像的点的单应矩阵为保证误差率最小的3*3矩阵H:
单应矩阵H就是待配准图到参考图的变换矩阵,将待配准图每一个像素点p位置变换到参考图相机坐标系相应位置p'=H*p,使用图像融合方法处理拼接边界。单应矩阵可以很好地完成一张图像的图像坐标系到另一张的图像坐标系的转化,在经过后续图像融合之后可以完整地展示整个图像。将原位可视化过程中生成的一些细节图像整体性展示给专家,弥补了原位可视化在低焦距、大视角下生成的图像在交互方面的不足。
4 基于特征区域的部分三维重建
原位可视化通过生成图像数据集有效减少了数据传输和存储的资源消耗,但是也失去了后续交互过程数值模拟结果数据三维特性的直接展示能力,不利于领域专家理解数据的空间特性。而使用基于特征区域的部分三维重建能够快速筛选出图像特征点并还原模拟数据各个部分之间的空间关系,便于专家进行交互。图像颜色特征匹配可以用于检测成像特征区域,空间特征可以用于计算三角面之间的空间关系,最终生成可供交互的三维模型。使用双目图像寻找特征点重建三维模型是已经存在的研究方向:通常会通过匹配特征点进行相机定标,通过定标相机矩阵计算特征点的三维坐标,然后使用点云重建方法完成三维模型。但是这种方案不能应对轮廓不规则的模型,复杂模型很难通过有限数量的特征点完成重建。因此本文的方案还是使用图像本身的特征区域进行模型重建,即较为显著的特征点围成的在原图上连续的图像面片,使用这些原始图像本身的特征区域能够避免引入点云重建导致误差。
对于数据模型特征区域的交互查看,本文提出了一种根据特征点生成三角面,然后在空间中组合查看的方案,这种方法能够将保留的模型特征区域聚集为图像,避免进行点云重建产生的误差,同时通过各组三角面之间的三维扭曲还原数据模型之间的空间关系。
使用特征点匹配方法获取特征点集后,得到的特征点包括深度变化特征点以及彩色变化特征点,需要从这些点中再取出深度变化的特征点进行三角面片化。通过立体匹配获取的视差图可以表现深度变化特征,根据视差图可以进一步筛选出深度变化特征点。三角化方法可以由图像坐标系特征点得到一组三角片,保存这些三角片的顶点与纹理,将这些三角片贴图到对应的世界坐标系中,三角片的顶点在世界坐标系中的位置可以由像素坐标系计算得出。
具体操作中,本文尝试了基于图像灰度变化值进行检测的Harris检测法和基于局部特征进行检测的SIFT检测法以及基于SIFT发展的SURF算法。通过匹配的特征点数量与分布情况结果来看,SIFT算法[21]可以检测出更多的匹配特征点。筛选特征点采用RANSAC算法,得到正确匹配的深度变化特征和颜色变化特征。采用SGBM算法获取视差图,得到深度变化的特征进行三角化。SGBM算法通过动态规划来最小化全局能量函数寻找每一个像素点的最优视差[22]。使用均值滤波填补由于遮挡带来的视差空洞,平滑后的视差图可以转换为深度图筛选出深度变化特征点。转换方式为:
其中depth代表深度图中该像素位置深度值,f指焦距,baseline指双目相机光心距离,disparity就是该像素位置视差值。使用sobel算子计算深度图梯度幅值。在梯度图中降序搜索像素点,为了控制特征点密度,将得到的像素点周围梯度幅值清零,重复直到梯度幅值小于预定阈值。使用Delaunay三角化方法可以由像素坐标特征点得到三角面片,计算这些三角顶点世界坐标并贴图到三维坐标系中。最终生成了用于交互的三维模型。通过将三维重建的部分流程针对性地同原位可视化图像数据集进行结合,数值模拟结果数据的部分空间特性得以还原,专家可以进行后续的三维交互。
5 实验
本文的实验分为两个部分,首先实现了可视化框架并观察了运行效率,使用这个框架成功地对接了数值模拟应用,得到了可视化对象,并且通过这些对象进一步得到了模拟结果的图像数据集。然后利用了不同数据的可视化方法得到的图像数据,以这些图像数据为基础,验证了本文提出的原位可视化图像交互方法的有效性。本文方法的创新性在于能够对大规模数值模拟数据在原位进行交互式分析,满足了专家的多种交互需求。在该领域,之前的相关工作都基于后处理可视化,所以目前并没有在原位可视化的基础上进行交互式三维模型重建的方法。而我们的工作在原位可视化的基础上实现了交互式处理流程,提供了交互模型。因此我们结合具体的实践说明了方法的有效性。
5.1 原位可视化框架实现
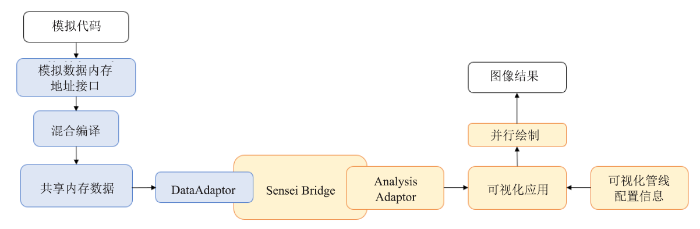
本文的方法使用混合模式原位框架,首先通过访问模拟程序内存,创建模拟程序到可视化程序的数据地址接口,使用开源工具Sensei[23]和VTK将模拟数据转化为可视化数据,Sensei是一个开源的原位可视化框架,VTK数据模型被广泛应用于科学可视化与可视分析中。模拟数据是记录在内存的数组,使用相关函数进行处理形成可视化数据。然后再使用并行绘制方法将数据输出为图像,以上工作是在模拟进程上完成的。可视化交互是在其他进程访问图像数据进行拼接、拓展等交互操作,这些任务是异步于模拟进行的,并且可以重复访问,避免了紧耦合过程数据难以回溯的问题。本文基于Sensei框架使用CFL3D进行模拟,使用VTK进行数据处理与可视化。为了支持CFL3D的编译,gcc的版本采用7.1.0,Cmake的版本采用3.1.0,cgns的版本采用2.5.3,还需要OpenMPI-1.8.5以支持并行模式。对于Sensei,使用5.5.2版本的Paraview。在模拟过程中添加原位分析需要考虑到接口设计的通用性和转化数据格式的负担。接口设计要适用于多种模拟程序,模拟进程的数据输出模块都是在指定时间步调用,输出该时间步某块模拟数据地址下的内容为指定文件格式。原位接口也要在相同的位置调用数据,把内存空间中待输出数据转化为可视化数据。本文使用开源的原位可视化框架Sensei解决了这两个问题:首先,Sensei提供了一个通用的数据接口DataAdaptor,负责将模拟数据转化为可视化数据,我们使用VTK作为可视化数据模型。Sensei也能控制数据转化负担,DataAdaptor避免了在不需要时将模拟数据映射到VTK。当不需要分析时,Sensei开销几乎不存在。同时在需要数据转化时,Sensei能够将模拟数据映射到VTK数据而无需额外的内存复制[24]。本方法的紧耦合部分整体流程如图2所示,Sensei接口由三个组件组成:Data Adaptor,将模拟数据映射为可视化数据,提供了用于执行分析的数据接口;Analysis Adaptor,将可视化数据映射到分析人员编写的分析方法,从而执行特定的分析例程;Sensei Bridge,主要作用是将Data Adaptor和Analysis Adaptor连接在一起,并且为模拟提供了用来触发分析例程的API。本文设计了一个在模拟源代码输出时同步调用的内存地址接口,根据不同的模拟源码语言取出地址内数据,使用DataAdaptor 转化为VTK数据交付给可视化程序。
图2
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2原位可视化框架的紧耦合部分
Fig.2Tight coupling part of in-situ visualization framework
本方案使用共享内存地址方法访问模拟数据内存地址空间,实验使用Sensei结合Fortran编写的CFD模拟应用与VTK可视化代码,通过传递Fortran数组内存地址与规模参数,改变格式转化为数值数组,然后使用SenseiDataAdaptor生成VTK对象,交付给VTK可视化管线处理。通过对比CFD代码运行时间与Sensei初始化、转化对象并通过管线可视化的时间占比,可以发现,整个原位过程占据模拟计算时间大约为20%左右。根据之前的研究[6],生成图像数据的时间占比是可以控制的,因此本文提出的紧耦合原位部分算法流程的额外开销是可以接受的。
5.2 基于原位可视化图像的交互实验结果
通过DataAdaptor可以将不同模拟数据转化为可视化管线能够处理的形式,并且前文中的方法转化后的图像数据与模拟流程解耦合,因此可以使用任意管线处理数据生成的图像结果验证本文方法的有效性。5.2.1 基于深度图的虚拟视点合成
本文使用CT扫描获得的点云数据重建后的模型图像进行实验。可视化管线加载点云数据对象,处理为Surface形式。可以得到由三角面组建的模型,然后记录点云相较于视点的深度信息并可视化,能够得到参考深度图,由于这个深度图是原始数据生成的,所以无需进行降噪处理,图3中(a)和(b)分别代表原始模型图像和对应的深度图像。
图3
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3(a) 原始视点图;(b) 原始视点对应深度图
Fig.3(a) Original view; (b) Depth map corresponding to original viewpoint
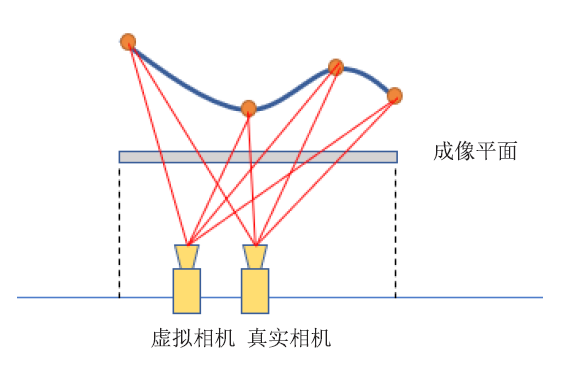
实验使用反向映射方法进行3D扭曲获取参考视点左侧的一个新视点,平移量为1/4的数据范围,如图4中所示。实现过程如下:首先根据内参矩阵得到一个像素在对应相机坐标系下的空间坐标:
图4
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4虚拟视点相机变化图
Fig.4Change diagram of virtual viewpoint camera
计算新视点下相机坐标系中空间点的变化情况,对于向左的虚拟视点,只需要对X方向进行操作:
同理,如果新虚拟视点存在其他变换方法,只需按照相机外参矩阵计算出变换矩阵然后对原始相机坐标系中的点依次进行变换。接下来将虚拟相机坐标系点映射到虚拟视点的图像坐标系中:
通过这种方法可以得到虚拟视点的深度图,由于一些像素位置下点的深度值没有对应,所以需要对虚拟深度图进行插值平滑填补空洞。最后通过虚拟深度图求得虚拟视点下的某点对应原始图像下的坐标,然后在原始图像上取近邻点进行插值作为虚拟视点该像素的信息。图5(a)为反向映射虚拟视点、5(b) 为该视点下的真实图像。可以看到,大部分中间区域的深度关系都被还原了, 并且空洞得到了消除,其中的伪影是反向映射过程中空洞填充时附近深度插值产生的,可以通过背景检测手段消除。消除后效果如图5(c)所示。
图5
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图5(a) 反向映射虚拟视点;(b) 同位置下真实视点结果;(c) 消除伪影后的虚拟视点结果
Fig.5(a) Reverse mapping of virtual viewpoint; (b) Result of real viewpoint in the same position; (c) Result of virtual viewpoint after eliminating artifacts
5.2.2 基于特征点的图像拼接
使用特征点进行图像拼接主要是为了能够在近距离观察图像时生成更完整的视点图像,对于流场,可视化有时需要在低焦距,大视角下观察细节,这样生成的图像无法包含全部特征区域,同时深度图无法显示属性(颜色)特征。这种情况下,可以使用基于特征点的图像拼接方法还原全部的特征区域。
本文分别采用空间中二维和三维两种数值模拟形成的图像进行实验,实验对二维数据和三维数据的处理结果分别如图6与图7所示。其中(a)是双目视点下近距离观测图像;(b)是SURF检测匹配点以及 RANSAC筛选的匹配点集;(c)是拼接后图像结果。可以看到,在匹配点基本正确的情况下,单应矩阵可以很好的完成一张图像的图像坐标系到另一张的图像坐标系的转化。
图6
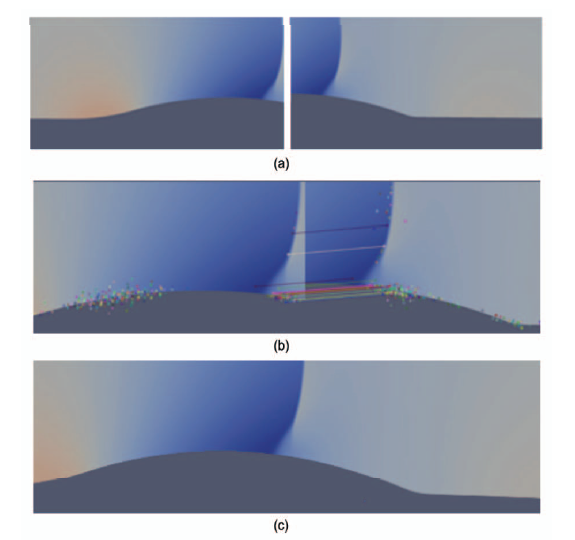 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图6(a) 双目视点左图(参考图)和右图(待配准图);(b) 特征点以及匹配特征点;(c) 拼接结果
Fig.6(a) Reference image and registration image of binocular view; (b) Feature points and matching feature points; (c) Splicing result
图7
 新窗口打开|下载原图ZIP|生成PPT
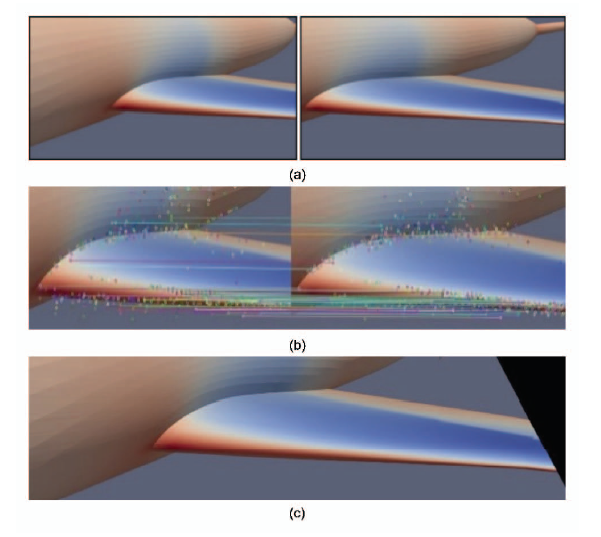
新窗口打开|下载原图ZIP|生成PPT图7(a) 双目视点左图(参考图)和右图(待配准图);(b) 特征点以及匹配特征点;(c) 拼接结果
Fig.7(a) Reference image and registration image of binocular view; (b) Feature points and matching feature points; (c) Splicing result
5.2.3 基于特征区域的部分三维重建
本文对原位可视化图像数据集进行的三维重建主要是通过两个图像的匹配特征点获取像素的空间坐标,从而还原出三维模型。此处的三维模型由于视点的原因,只能表示原始模拟结果数据的部分三维特征,但是也能满足专家的空间交互需求。
实验结果如图8所示。(a)图中为左右视点图像的正确匹配点集;(b)图为基于特征点的三角面划分;(c)图是初始视点下部分特征区域三维重建的结果;(d)图为该模型旋转后视点结果。可以看到,检测到的深度变化特征点密集区域得到了较好的重建。在进行三角划分的时候,没有图像特征的区域被舍弃,被舍弃的特征区域不影响观察和分析,并且旋转视点后也基本保留了空间关系。
图8
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图8(a) 左右视点图像正确匹配点;(b) 三角划分;(c) 三维特征重建;(d) 模型旋转
Fig.8(a) Correct matching points of left and right view images; (b) Triangulation; (c) 3D feature reconstruction; (d) Model rotation
6 总结
本文提出了一种基于虚拟视点的大规模数值模拟的可交互式原位可视化方法。在进行交互式处理时,本文使用了一些真实场景处理图像的技术并结合模拟结果图像进行改进。最后在超级计算机中实验了原位可视化紧耦合部分并测试了效率,在个人电脑上实现了图像交互方法并且评估了结果。实验结果表明,本文设计的原位可视化方案在性能上可以满足超级计算机与大规模数值模拟原位可视化的时间与空间开销要求。本文提出的几种原位可视化图像交互方法可以帮助领域专家完成初步特征浏览,第一时间判断特征点时间步、空间分布情况,满足了大规模数值模拟中间结果数据的原位可视化交互需求。
在气象领域和数值风洞领域,我们已经在千核级的数值模拟中进行了成功应用,满足了专家的原位可视化交互需求,同时正在尝试应用于更大规模数值模拟的原位可视化。希望后续工作中能够与更多的领域结合。
本文的方法基于原位可视化图像数据。由于I/O的限制,数值模拟结果数据无法全部输出到外部存储,只能利用原位可视化输出为图像。但是图像无法交互,所以我们在图像的基础上提出了基于虚拟视点的原位可视化交互方法。只是图像的精度是有限制的,最终能够提供的交互角度有限。希望在后续工作中通过探索用户需求在原位可视化时输出特定的图像数据,以满足不同专家的交互需求,增强可扩展性。
利益冲突声明
所有作者声明不存在利益冲突关系。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[J].
[本文引用: 1]
[J].
[本文引用: 2]
[J].
[本文引用: 1]
[J].
[本文引用: 2]
[J].
[本文引用: 1]
[C].
[本文引用: 2]
[J].
[本文引用: 1]
[J].
DOI:10.1016/j.image.2008.10.010URL [本文引用: 1]
[C].
[本文引用: 1]
[J].
DOI:10.1109/Access.6287639URL [本文引用: 1]
[C].
[本文引用: 1]
[J].
DOI:10.1023/B:VISI.0000029664.99615.94URL [本文引用: 1]
[J].
DOI:10.1109/TPAMI.34URL [本文引用: 1]
[J].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
DOI:10.1109/TVCG.2016.2598604URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]
[J].
DOI:10.1109/TPAMI.2007.1166URL [本文引用: 1]
[C].
[本文引用: 1]
[C].
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}